🔥🔥Java開發者的Python快速實戰指南:探索向量資料庫之影象相似搜尋-文字版
首先,我要向大家道個歉。原本我計劃今天向大家展示如何將圖片和視訊等形式轉換為向量並儲存在向量資料庫中,但是當我檢視檔案時才發現,騰訊的向量資料庫尚未完全開發完成。因此,今天我將用文字形式來演示相似圖片搜尋。如果您對騰訊的產品動態不太瞭解,可以檢視官方網址:https://cloud.tencent.com/document/product/1709/95477
在開始講解之前,我想給大家介紹一個很有用的第三方包,它就是gradio。如果你想與他人共用你的機器學習模型、API或資料科學工作流的最佳方式之一,可以建立一個互動式應用,讓使用者或同事可以在瀏覽器中試用你的演示。而gradio正是可以幫助你在Python中構建這樣的演示,並且只需要幾行程式碼即可完成!
作為一個後端開發者,我瞭解如果要我開發前端程式碼來進行演示,可能需要花費很長時間,甚至可能需要以月為單位計算。所幸,我發現了gradio這個工具的好處,它可以幫助我解決這個問題。使用gradio,我只需要專注於實現我的方法,而不需要關心如何實現介面部分,這對於像我這樣不擅長前端開發的人來說非常合適。gradio為我提供了一個簡單而有效的解決方案。
原始碼倉庫地址:https://github.com/StudiousXiaoYu/tx-image-search
Gradio
關於gradio的環境設定和官方檔案,我就不再贅述了,有興趣的同學可以去官方檔案地址https://www.gradio.app/guides/quickstart 檢視。對於後端開發者來說,上手使用gradio非常容易。

接下來,我們將搭建一個最簡單的圖片展示應用。由於我要實現的功能是圖片展示,所以我將直接上程式碼。
資料準備
首先,我們需要準備資料。我已經從官方獲取了訓練資料,並將圖片的資訊和路徑儲存到了我的向量資料庫中。幸運的是,這些資料已經被整理成了一個CSV檔案。現在,我想要將這些資料插入到資料庫中。這是一個很好的機會來練習一下我們的Python語法,比如讀取檔案、參照第三方包以及使用迴圈。讓我們來看一下具體的實現方法。
我的csv檔案是這樣的:
id,path,label
0,./train/brain_coral/n01917289_1783.JPEG,brain_coral
1,./train/brain_coral/n01917289_4317.JPEG,brain_coral
2,./train/brain_coral/n01917289_765.JPEG,brain_coral
3,./train/brain_coral/n01917289_1079.JPEG,brain_coral
4,./train/brain_coral/n01917289_2484.JPEG,brain_coral
5,./train/brain_coral/n01917289_1082.JPEG,brain_coral
6,./train/brain_coral/n01917289_1538.JPEG,brain_coral
在這個檔案中,第一行是列名,從第二行開始,我可以開始解析資料了。
之前已經完成了資料庫的建立,所以我就不再演示了。現在,我們將直接開始設計集合,並將資料插入到我們的集合中。
import gradio as gr
import numpy as np
import tcvectordb
from tcvectordb.model.collection import Embedding
from tcvectordb.model.document import Document, Filter, SearchParams
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency,EmbeddingModel
from tcvectordb.model.index import Index, VectorIndex, FilterIndex, HNSWParams
client = tcvectordb.VectorDBClient(url='http://*****',
username='root', key='1tWQ*****',
read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
db = client.database('db-xiaoyu')
上面提到的這些流程是基本的,我就不再詳細解釋了。我們可以直接開始連線,但是在此之前,我們需要先建立一個專門用於圖片搜尋的集合。之前我們建立的是用於文字搜尋的集合,現在我們需要建立一個新的集合來區分。以下是相應的程式碼:
# -- index config
index = Index(
FilterIndex(name='id', field_type=FieldType.String, index_type=IndexType.PRIMARY_KEY),
VectorIndex(name='vector', dimension=768, index_type=IndexType.HNSW,
metric_type=MetricType.COSINE, params=HNSWParams(m=16, efconstruction=200))
)
# Embedding config
ebd = Embedding(vector_field='vector', field='image_info', model=EmbeddingModel.BGE_BASE_ZH)
# create a collection
coll = db.create_collection(
name='image-xiaoyu',
shard=1,
replicas=0,
description='this is a collection of test embedding',
embedding=ebd,
index=index
)
由於目前向量資料庫尚未完全支援影象檔案轉換為向量的功能,因此我們決定將其改為儲存影象描述資訊,並將影象路徑直接儲存為普通欄位。由於我們對路徑沒有過濾要求,因此將其作為普通欄位進行儲存。所有資訊已經成功儲存在CSV檔案中,因此我們只需直接讀取該檔案內容並將其存入向量資料庫中即可。以下是相關程式碼範例:
data = np.genfromtxt('./reverse_image_search/reverse_image_search.csv', delimiter=',', skip_header=1, usecols=[0, 1, 2], dtype=None)
doc_list = []
for row in data:
id_row = str(row[0])
image_url = row[1].decode()
image_info = row[2].decode()
doc_list.append(Document(id=id_row,image_url=image_url,image_info=image_info))
res = coll.upsert(
documents=doc_list,
build_index=True
)
在這段程式碼中,我使用了 import numpy as np 語句來匯入 numpy 庫。為什麼我使用它呢?因為我在搜尋中發現它可以處理 CSV 檔案。畢竟,在Python程式設計中總是喜歡使用現成的工具。最後,我將 Document 封裝成一個列表,並將其全部插入到集合中。
構建Gradio互動介面
資料準備工作已經完成,接下來我們需要考慮如何建立一個互動介面。我知道Python有很多優秀的庫,其中有一個可以一鍵構建互動介面的庫,這真的很厲害。與Java的自定義介面相比,它們是完全不同的東西,因為他倆沒得比。為了實現互動介面的功能,我們需要在一個新的py檔案中編寫以下程式碼:
import gradio as gr
import tcvectordb
from tcvectordb.model.document import SearchParams
from tcvectordb.model.enum import ReadConsistency
client = tcvectordb.VectorDBClient(url='http://lb-m*****',
username='root', key='1tWQ*****',
read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
db = client.database('db-xiaoyu')
coll = db.collection('image-xiaoyu')
def similar_image_text(text):
doc_lists = coll.searchByText(
embeddingItems=[text],
params=SearchParams(ef=200),
limit=3,
retrieve_vector=False,
output_fields=['image_url', 'image_info']
)
img_list = []
for i,docs in enumerate(doc_lists.get("documents")):
for my_doc in docs:
print(type(my_doc["image_url"]))
img_list.append(str(my_doc["image_url"]))
return img_list
def similar_image(x):
pass
with gr.Blocks() as demo:
gr.Markdown("使用此演示通過文字/影象檔案來找到相似圖片。")
with gr.Tab("文字搜尋"):
with gr.Row():
text_input = gr.Textbox()
image_text_output = gr.Gallery(label="最終的結果圖片").style(height='auto', columns=3)
text_button = gr.Button("開始搜尋")
with gr.Tab("影象搜尋"):
with gr.Row():
image_input = gr.Image()
image_output = gr.Gallery(label="最終的結果圖片").style(height='auto', columns=3)
image_button = gr.Button("開始搜尋")
with gr.Accordion("努力的小雨探索AI世界!"):
gr.Markdown("先將圖片或者路徑儲存到向量資料庫中。然後通過文字/影象檔案來找到相似圖片。")
text_button.click(similar_image_text, inputs=text_input, outputs=image_text_output)
image_button.click(similar_image, inputs=image_input, outputs=image_output)
demo.launch()
我建立了一個帶有兩個分頁的介面。由於本次專案不需要使用影象相似搜尋功能,所以等到該功能推出後,我會再次進行影象方面的相似搜尋演示。目前,我們只能通過圖片描述來查詢並顯示圖片。這部分沒有太多值得講的,我只是對 Gardio 官方範例進行了一些修改。如果你還不清楚的話,我建議你檢視官方範例和介紹。現在,讓我們來看一下我的執行介面吧。
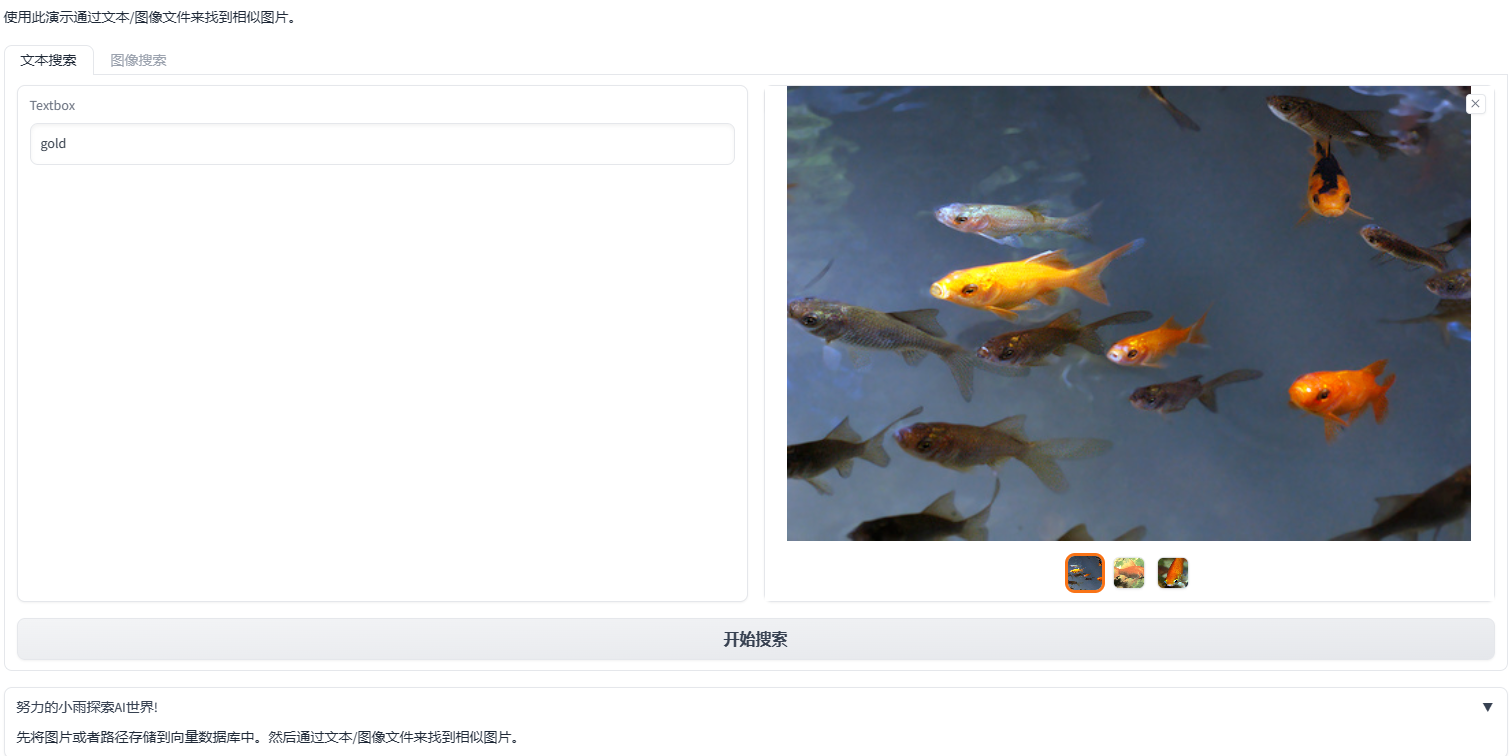
當我輸入"gold"後,根據我所儲存的圖片描述是"gold fish",所以可以找到對應的匹配項。當我看到三種金魚的圖片時,就說明我們的執行是正常的。我已經為圖片相似搜尋留出來了,以便及時更新。
總結
今天我們寫程式碼時,基本上已經熟練掌握了Python的語法。剩下的就是學習如何使用第三方包,以及在編寫過程中遇到不熟悉的包時,可以通過百度搜尋來獲取答案。雖然並沒有太大難度,但是對於使用gradio來說,可能需要花費一些時間上手。有時會遇到一些錯誤,不像Java那樣能夠一眼識別出問題所在,需要上網搜尋來解決。