這下對阿里java這幾條規範有更深理解了
背景
阿里java開發規範是阿里巴巴總結多年來的最佳程式設計實踐,其中每一條規範都經過仔細打磨或踩坑而來,目的是為社群提供一份最佳程式設計規範,提升程式碼質量,減少bug。
這基本也是java業界都認可的開發規範,我們團隊也是以此規範為基礎,在結合實際情況,補充完善。最近在團隊遇到的幾個問題,加深了我對這份開發規範中幾個點的理解,下面就一一道來。
紀錄檔規約

這條規範說明了,在異常傳送記錄紀錄檔時,要記錄案發現場資訊和異常堆疊資訊,不處理要往上throws,切勿吃掉異常。
堆疊資訊比較好理解,就是把整個方法呼叫鏈列印出來,方便定位具體是哪個方法出錯。而案發現場資訊我認為至少要能說明:「誰發生了什麼錯誤」。
例如,哪個uid下單報錯了,哪個訂單支付失敗了,原因是什麼。否則滿屏列印:「user error」,看到你都無從下手。
在我們這次出現的問題就是有一個feign,呼叫外部介面報錯了,降級列印了不規範紀錄檔,導致排查問題花了很多時間。虛擬碼如下:
@Slf4j
@Component
class MyClientFallbackFactory implements FallbackFactory<MyClient> {
@Override
public MyClient create(Throwable cause) {
return new MyClient() {
@Override
public Result<DataInfoVo> findDataInfo(Long id) {
log.error("findDataInfo error");
return Result.error(SYS_ERROR);
}
};
}
}
發版後錯誤紀錄檔開始告警,開啟kibana看到了滿屏了:「findDataInfo error」,然後開始一頓盲查。
因為這個介面本次並沒有修改,所以猜測是目標服務出問題,上伺服器curl介面,發現呼叫是正常的。
接著猜測是不是熔斷器有問題,熔斷後沒有恢復,但重啟服務後,還是繼續報錯。開始各種排查,arthas跟蹤,最後實在沒辦法了,還是老老實實把異常列印出來,走發版流程。
log.error("{} findDataInfo error", id, cause);
有了異常堆疊資訊就很清晰了,原來是返回引數反序列失敗了,介面提供方新增一個不相容的引數導致反序列失敗。(這點在下一個規範還會提到)
可見紀錄檔列印不清晰給排查問題帶來多大的麻煩,記住:紀錄檔一定要列印關鍵資訊,異常要列印堆疊。
二方庫依賴

上面提到的返回引數反序列化失敗就是列舉造成的,原因是這個介面返回新增一個列舉值,這個列舉值原本返回給前端使用的,沒想到還有其它服務也呼叫了它,最終在反序列化時就報錯了,找不到「xxx」列舉值。
比如如下介面,你提交一個不認得的黑色BLACK,就會報反序列錯誤:
enum Color {
GREEN, RED
}
@Data
class Test {
private Color color;
}
@PostMapping(value = "/post/info")
public void info(@NotNull Test test) {
}
curl --location 'localhost/post/info' \
--header 'Content-Type: application/json' \
--data '{
"testEnum": "BLACK"
}'
關於這一點我們看下作者孤盡對它的闡述:

這就是我們出問題的場景,提供方新增了一個列舉值,而使用方沒有升級,導致錯誤。可能有的同學說那通知使用方升級不就可以了?是的,但這出現了依賴問題,如果使用方有成百上千個,你會非常頭痛。
那又為什麼說不要使用列舉作為返回值,而可以作為輸入引數呢?
我的理解是:作為列舉的提供者,不得隨意新增/修改內容,或者說修改前要同步到所有列舉使用者,讓大家知道,否則使用者就可能因為不認識這個列舉而報錯,這是不可接受的。
但反過來,列舉提供者是可以將它作為輸入引數的,如果呼叫者傳了一個不存在的值就會報錯,這是合理的,因為提供者並沒有說支援這個值,呼叫者正常就不應該傳遞這個值,所以這種報錯是合理的。
ORM對映

以下是規範裡的說明:
1)增加查詢分析器解析成本。
2)增減欄位容易與 resultMap 設定不一致。
3)無用欄位增加網路消耗,尤其是 text 型別的欄位。
這都很好理解,就不過多說明。
在我們開發中,有的同學為了方便,還是使用了select *,一直以來也風平浪靜,執行得好好的,直到有一天對該表加了個欄位,程式碼沒更新,報錯了~,你沒看錯,程式碼沒動,加個欄位程式就報錯了。
報錯資訊如下:

陣列越界!問題可以在本地穩定復現,先把程式跑起來,執行 select * 的sql,再add column給表新增一個欄位,再次執行相同的sql,報錯。
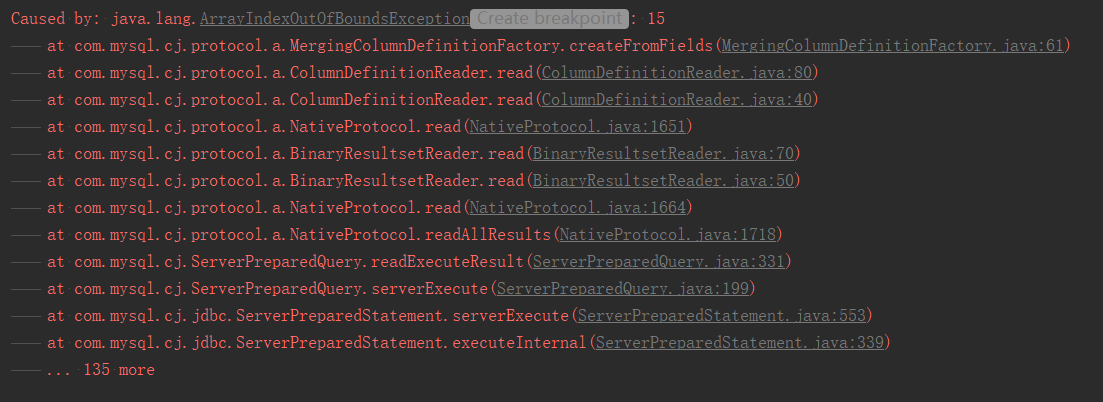
具體原因是我們程式使用了sharding-jdbc做分表(5.1.2版本),它會在服務啟動時,載入欄位資訊快取,在查詢後做欄位匹配,出錯就在匹配時。
具體程式碼位置在:com.mysql.cj.protocol.a.MergingColumnDefinitionFactory#createFromFields

這個快取是跟資料庫連結相關的,只有連結失效時,才會重新載入。主要有兩個引數和它相關:
spring.shardingsphere.datasource.master.idle-timeout 預設10min
spring.shardingsphere.datasource.master.max-lifetime 預設30min
預設快取時間都比較長,你只能趕緊重啟服務解決,而如果服務數量非常多,又是一個生產事故。
我在sharding sphere github搜了一圈,沒有好的處理方案,相關連結如:
https://github.com/apache/shardingsphere/issues/21728
https://github.com/apache/shardingsphere/issues/22824
大體意思是如果真想這麼做,資料庫ddl需要通過sharding proxy,它會負責重新整理使用者端的快取,但我們使用的是sharding jdbc模式,那隻能老老實實遵循規範,不要select * 了。如果select具體欄位,那新增的欄位也不會被select出來,和快取的就能對應上。
那麼以後面試除了上面規範說到的,把這一點親身經歷也擺出來,應該可以加分吧。
總結
每條開發規範都有其背後的含義,都是經驗總結和踩坑教訓,對於團隊的開發規範我們都要仔細閱讀,嚴格遵守。可以看到上面每個小問題都可能導致不小的生產事故,保持敬畏之心,大概就是這個意思了吧。
更多分享,歡迎關注我的github:https://github.com/jmilktea/jtea