解密Prompt系列20. LLM Agent之再談RAG的召回多樣性優化
幾個月前我們就聊過RAG的經典方案解密Prompt系列14. LLM Agent之搜尋應用設計。前幾天剛看完openAI在DevDay閉門會議上介紹的RAG相關的經驗,有些新的感悟,藉此機會再梳理下RAG相關的優化方案。推薦直接看原視訊(外網)A Survey of Techniques for Maximizing LLM Performance
RAG最關鍵的一環其實不是LLM而是相關內容的召回,作為大模型推理的上文,優秀的內容召回應該滿足以下條件:
- 多樣性和召回率:召回的內容要可以回答問題,並且內容豐富度,包括同一問題多個觀點,多角度
- 相關性和準確率:召回內容和問題相關,總不能召回100篇裡面只有2篇和問題有關
- 一致性和低衝突:召回內容間的觀點一致性較高
- 更高要求:高時效性,權威性,觀點完整性,內容重複度低
這裡不妨借鑑前人經驗,參考搜尋的主流框架:Query理解和擴充套件 -> 多路召回 -> 合併排序 -> 重排和打散。過去幾個月RAG的論文也像是把傳統搜尋的方案,使用LLM輪番做了一遍正規化更新。本章我們先圍繞召回內容的多樣性嘮上兩句。
直接使用使用者Query進行向量檢索,召回率往往不高,原因有以下幾個
- query較短,本身資訊有限
- 短文字的embedding效果較差
- query短文字向量和document長文字向量存在空間表徵差異
- 使用者對自己想問的內容比較模糊
- 使用者的query提問可能需要多個方向的資訊聚合才能回答
以上問題其實覆蓋了兩個點:Query本身包含資訊的多樣性,搜尋索引的多樣性。下面我們結合新老論文,以及langchain新增的一些功能,來分別介紹~
1. Query多樣性
- 2019 Query Expansion Techniques for Information Retrieval: a Survey
傳統搜尋Query的擴充套件,有基於使用者搜尋紀錄檔挖掘的相似Query,有基於相同召回檔案關聯的相似Query,也有基於SMT的Query改寫方案。那和大模型時代更搭配的自然是改寫方案,LLM的加持很大程度上降低了Query改寫的難度,也為改寫提供了更多的可能性。
1.1 相似語意改寫
- Learning to Rewrite Queries,雅虎(2016)
- webcpm: Interactive Web Search for Chinese Long-form Question Answering,清華(2023)
比較早在16年yahoo就探索過query改寫的方案,那時還是個seq2seq的LSTM。再就是之前介紹的webcpm也有使用大模型進行query改寫來提高內容召回。近期langchain也整合了MultiQueryRetriever的類似功能。邏輯就是把使用者的Query改寫成多個語意相近的Query,使用多個Query一起進行召回,如下

1.2 雙向改寫
- Query2doc: Query Expansion with Large Language Models,微軟(2023)
- Query Expansion by Prompting Large Language Models, 谷歌(2023)
除此之外還有一種另類Query的改寫方案,就是Query2doc中提到的把Query改寫成document。論文使用4-shot prompt讓LLM先基於query生成一個pseudo-document,然後使用生成的答案來進行相關內容的召回。這種改寫方案確實有一些顯著的優點
- 緩解短文字query向量化效果較差的問題
- 緩解document長文字向量和query短文字向量存在空間差異的問題
- 提高BM25等離散索引抽取的效果,畢竟文字長了更容易抽出有效關鍵詞
當然缺點也很顯著,一個是pseudo-docuemnt可能發生語意漂移,幻覺回答會引入錯誤的關鍵詞降低召回的準確率,以及解碼的耗時較長~

這裡Query2Doc反過來寫,Doc2Query也是另外一個優化方向,就是給每篇檔案都生成N個關聯Query(pseudo-query),使用關聯Query的embedding向量來表徵檔案,和真實Query進行相似度計算。langchain的MultiVector Retriever也整合了類似的功能。
谷歌也做了類似的嘗試。分別對比了Query2Doc(Q2D), Query2Keyword(Q2E), Query2COT幾種改寫方案,以及使用zero-shot,few-shot,召回檔案增強等不同prompt指令的效果。其中Query2Doc採用了和上面微軟相同的prompt指令,其他指令如下

結果顯示,當模型規模足夠大之後,Query2COT展現出了顯著更優的效果。甚至超越了在上文中加入相關檔案的COT/PRF 方案。一方面COT會對Query進行多步拆解,一方面思考的過程會產生更有效的關鍵詞,以及不使用相關檔案可以更有效的釋放模型本身的知識召回能力和創造力。

1.3 強化學習改寫
- ASK THE RIGHT QUESTIONS: ACTIVE QUESTION REFORMULATION WITH REINFORCEMENT LEARNING,谷歌(2018)
- Query Rewriting for Retrieval-Augmented Large Language Models,微軟(2023)
以上的改寫方案在openai的閉門會都有提到,確實一定程度上可以提升RAG的效果,可以用於初期的嘗試。不過這種改寫是無監督的,也就是基於相似語意進行改寫,並不能保證改寫後的query搜尋效果一定更好。那我們不妨引入一個目標來定向優化改寫效果。
2018年穀歌就曾嘗試使用強化學習來優化改寫模型,把搜尋系統視作Environment,seq2seq模型生成多個Query的改寫候選作為Action。把原始Query的召回內容,和改寫Query的召回內容,一起送入後面的排序模組,使用排序模組TopK內容中改寫Query召回內容的召回率作為Reward打分,來梯度更新改寫模型,最大化改寫召回率。畢竟不論你改寫的多麼花裡胡哨,能有效提高內容召回,擁有更高的獨佔召回率才是真正有用的改寫模型。
而在大模型時代,改寫模組被升級為LLM。在微軟提出的rewrite-retrieve-read框架中,使用大模型作為rewriter,Bing搜尋作為Retriever,chatgpt作為Reader,在QA任務上,嘗試使用PPO微調改寫模型,Reward模型的目標是不同改寫query召回後推理內容和真實答案的Exact Match和F1。不過真實場景中,這種有標準答案的QA問答其實佔比很小,更多都是開放式問答。那麼其實可以類比以上的傳統方案,使用大模型推理的參照率,作為Reward目標。畢竟大模型選擇哪幾條輸入的上文進行推理,和精排原理其實是相似的。
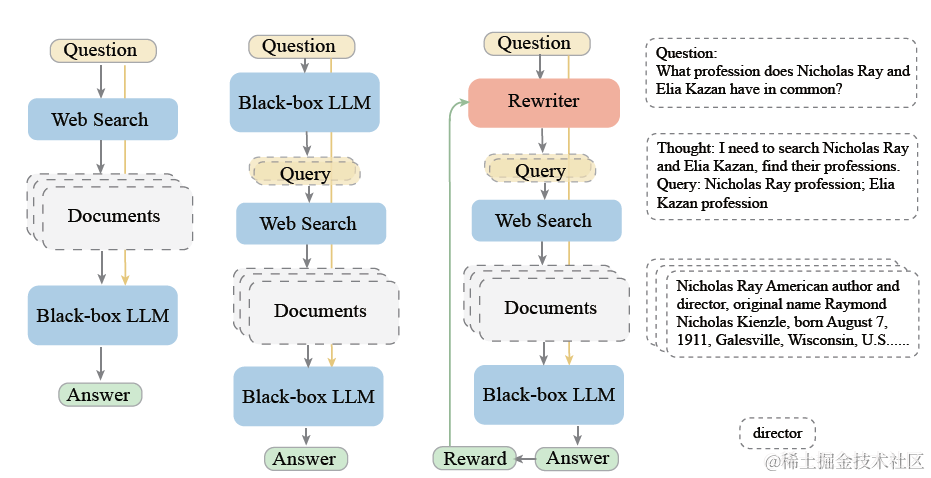
2. 索引擴充套件
簡單說完query擴充套件,我們再來看下索引擴充套件。當前多數RAG得召回索引還是以單一的Embedding向量模型為主,但單一向量作為召回索引有以下幾個常見問題
- 文字的相似有不同型別:有語意相似,有語法結構相似,有實體關鍵詞相似,單一維度無法區分etc
- 文字的相似有不同粒度:有些場景下需要召回精準匹配的內容,有些則需要模糊匹配,多數向量模型的區分度有限
- 不同領域相似定義不同:在垂直領域存在向量模型適配度較低的問題
- 長短文字間的相似問題:長短文字向量可能不在一個向量空間
下面我們看下還有哪些索引型別可以作為單一向量的補充
2.1 離散索引擴充套件
- Query Expansion by Prompting Large Language Models, 谷歌(2023)
- ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases
傳統搜尋中往往會使用到大量的離散索引,在很多垂直領域的內容召回中往往和向量召回有很好的互補效果,部分離散索引例如實體的召回準確率可能會顯著高於向量召回。一些常見的Query理解生成離散索引的方案包括:
- 抽取: 分詞,新詞ngram識別,詞性識別,實體抽取,關鍵詞抽取etc
- 分類:意圖分類,話題分類,概念分類,地點分類etc
- 多跳:實體連結,同義詞擴充套件,KG查詢etc
最先想到使用大模型來進行正規化改良的方向,大家都不約而同把目光放在了關鍵詞擴充套件。
雖然在上面谷歌的論文中嘗試query2Keyword的效果並沒有超越query2Doc和Query2COT。但是關鍵詞生成本身低耗時,以及在一些垂直領域其實有很好的效果。例如ChatLaw一個法律領域的大模型,就是用了LLM進行法律條文的關鍵詞聯想。論文使用LLM針對使用者Query生成法律相關聯想關鍵詞,並使用關鍵詞的Ensemble Embedding來召回對應的法律條款。當然也可以使用關鍵詞直接進行召回。這種設計其實是針對在法律領域,領域關鍵詞往往有顯著更好的召回效果而設計的。

2.2 連續索引擴充套件
- https://github.com/FlagOpen/FlagEmbedding
- https://github.com/shibing624/text2vec
- https://github.com/Embedding/Chinese-Word-Vectors
- AUGMENTED EMBEDDINGS FOR CUSTOM RETRIEVALS, 微軟2023
向量索引的擴充套件,最先想到的就是同時使用多種不同的連續向量索引,包括
- 樸素模式:不同的Embedding模型,常見的就是OpenAI的Ada,智源的BGE,還有Text2vec系列,使用多路embedding模型同時召回,或者加權召回的方案,取長補短。
- 簡單模式:使用以上抽取的關鍵詞,使用詞向量加權進行召回。相比文字向量,詞向量的召回率往往更高,在一些垂直領域有很好的效果。當然反過來就是詞向量可能準確率偏低,不過召回階段本來就是廣撒網多斂魚
- Hard模式:訓練領域Embedding。成本最高,可以放在最後面嘗試,在openai devday上提及的觀點也是領域模型對比通用模型提升有限,且成本較高
不過微軟近期提出了一個相比微調領域embedding模型更加輕量化的方案,和lora微調的思路類似,咱不動基座模型,但是在上面微調一個adapter來定向優化query和document的匹配效果。
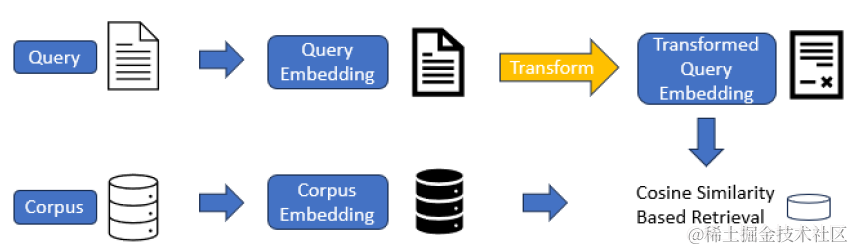
向量變化的adapter,論文使用了向量加法,就是在原始模型輸出的D維embedding的基礎上加一個residual,residual的計算是一個Key-Value lookup函數,包含兩個相同shape的變數K和v。例如針對openai的向量輸出是D =1536維,residual會選用h<<D來進行變換,h的取值在16~128,則K和V都分別是h*D維的矩陣,也就是adapter部分只需要梯度更新2hD量級的引數,如下
微調損失函數使用了對比學習的GlobalNegative Loss,也就是每個(query,content)pair是正樣本,其餘樣本內所有content均是負樣本,學習目標是query和正樣本的相似度>和其餘所有負樣本相似度的最大值。看起來似乎是很輕量的方案,有機會準備去試一下~

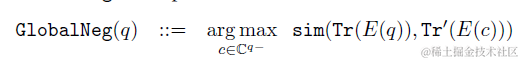
2.3 混合索引召回
把BM25等離散索引召回和Embedding向量等連續索引召回進行混合召回,langchain的Ensemble Retriever整合了這個功能。不過混合召回最大的問題是不同召回的打分較難進行排序。因此當多路混合召回內容較多時,需要引入排序模組對內容做進一步篩選過濾,這個我們放到後面再說啦~
想看更全的大模型相關論文梳理·微調及預訓練資料和框架·AIGC應用,移步Github >> DecryPrompt
reference
- Query 理解和語意召回在知乎搜尋中的應用
- 美團搜尋理解和召回
- Query理解在美團搜尋中的應用
- 電商搜尋QP:Query改寫
- 丁香園搜尋中的Query擴充套件技術
- 美團搜尋中查詢改寫技術的探索與實踐