聊聊 神經網路模型 範例程式——數位的推理預測
之前學習瞭解過了神經網路、CNN、RNN、Transformer的內容,但除了在魔塔上玩過demo,也沒有比較深入的從範例去梳理走一遍神經網路的執行流程。從數位推測這個常用的範例走一遍主流程。
MNIST資料集
MNIST是機器學習領域 最有名的資料集之一,被應用於從簡單的實驗到發表的論文研究等各種場合。 實際上,在閱讀影象識別或機器學習的論文時,MNIST資料集經常作為實驗用的資料出現。
MNIST資料集是由0到9的數位影像構成的。訓練影象有6萬張, 測試影象有1萬張,這些影象可以用於學習和推理。MNIST資料集的一般使用方法是,先用訓練影象進行學習,再用學習到的模型度量能在多大程度上對測試影象進行正確的分類。
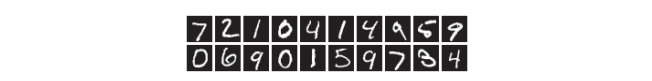
MNIST的影象資料是28畫素 × 28畫素的灰度影象(1通道),各個畫素的取值在0到255之間。每個影象資料都相應地標有"7" "2" "1"等標籤。
使用如下指令碼可以下載資料集
# coding: utf-8
try:
import urllib.request
except ImportError:
raise ImportError('You should use Python 3.x')
import os.path
import gzip
import pickle
import os
import numpy as np
url_base = 'http://yann.lecun.com/exdb/mnist/'
key_file = {
'train_img':'train-images-idx3-ubyte.gz',
'train_label':'train-labels-idx1-ubyte.gz',
'test_img':'t10k-images-idx3-ubyte.gz',
'test_label':'t10k-labels-idx1-ubyte.gz'
}
dataset_dir = os.path.dirname(os.path.abspath(__file__))
save_file = dataset_dir + "/mnist.pkl"
train_num = 60000
test_num = 10000
img_dim = (1, 28, 28)
img_size = 784
def _download(file_name):
file_path = dataset_dir + "/" + file_name
if os.path.exists(file_path):
return
print("Downloading " + file_name + " ... ")
urllib.request.urlretrieve(url_base + file_name, file_path)
print("Done")
def download_mnist():
for v in key_file.values():
_download(v)
def _load_label(file_name):
file_path = dataset_dir + "/" + file_name
print("Converting " + file_name + " to NumPy Array ...")
with gzip.open(file_path, 'rb') as f:
labels = np.frombuffer(f.read(), np.uint8, offset=8)
print("Done")
return labels
def _load_img(file_name):
file_path = dataset_dir + "/" + file_name
print("Converting " + file_name + " to NumPy Array ...")
with gzip.open(file_path, 'rb') as f:
data = np.frombuffer(f.read(), np.uint8, offset=16)
data = data.reshape(-1, img_size)
print("Done")
return data
def _convert_numpy():
dataset = {}
dataset['train_img'] = _load_img(key_file['train_img'])
dataset['train_label'] = _load_label(key_file['train_label'])
dataset['test_img'] = _load_img(key_file['test_img'])
dataset['test_label'] = _load_label(key_file['test_label'])
return dataset
def init_mnist():
download_mnist()
dataset = _convert_numpy()
print("Creating pickle file ...")
with open(save_file, 'wb') as f:
pickle.dump(dataset, f, -1)
print("Done!")
def _change_one_hot_label(X):
T = np.zeros((X.size, 10))
for idx, row in enumerate(T):
row[X[idx]] = 1
return T
def load_mnist(normalize=True, flatten=True, one_hot_label=False):
"""讀入MNIST資料集
Parameters
----------
normalize : 將影象的畫素值正規化為0.0~1.0
one_hot_label :
one_hot_label為True的情況下,標籤作為one-hot陣列返回
one-hot陣列是指[0,0,1,0,0,0,0,0,0,0]這樣的陣列
flatten : 是否將影象展開為一維陣列
Returns
-------
(訓練影象, 訓練標籤), (測試影象, 測試標籤)
"""
if not os.path.exists(save_file):
init_mnist()
with open(save_file, 'rb') as f:
dataset = pickle.load(f)
if normalize:
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].astype(np.float32)
dataset[key] /= 255.0
if one_hot_label:
dataset['train_label'] = _change_one_hot_label(dataset['train_label'])
dataset['test_label'] = _change_one_hot_label(dataset['test_label'])
if not flatten:
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].reshape(-1, 1, 28, 28)
return (dataset['train_img'], dataset['train_label']), (dataset['test_img'], dataset['test_label'])
if __name__ == '__main__':
init_mnist()
load_mnist函數以"(訓練影象 ,訓練標籤 ),(測試影象,測試標籤 )"的多元組形式返回讀入的MNIST資料。
load_mnist(normalize=True, flatten=True, one_hot_label=False) 這 樣,設 置 3 個 參 數。
第 1 個引數normalize設定是否將輸入影象正規化為0.0~1.0的值。如果將該引數設定為False,則輸入影象的畫素會保持原來的0~255。
第2個引數flatten設定是否展開輸入影象(變成一維陣列)。如果將該引數設定為False,則輸入影象為1 × 28 × 28的三維陣列;若設定為True,則輸入影象會儲存為由784個元素構成的一維陣列。
第3個引數one_hot_label設定是否將標籤儲存為one-hot表示(one-hot representation)。one-hot表示是僅正確解標籤為1,其餘皆為0的陣列,就像[0,0,1,0,0,0,0,0,0,0]這樣。當one_hot_label為False時,只是像7、2這樣簡單儲存正確解標籤;當one_hot_label為True時,標籤則 儲存為one-hot表示。
可以通過如下程式碼讀出下載的圖片
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 為了匯入父目錄的檔案而進行的設定
import numpy as np
from DeepLearn_Base.dataset.mnist import load_mnist
from PIL import Image
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
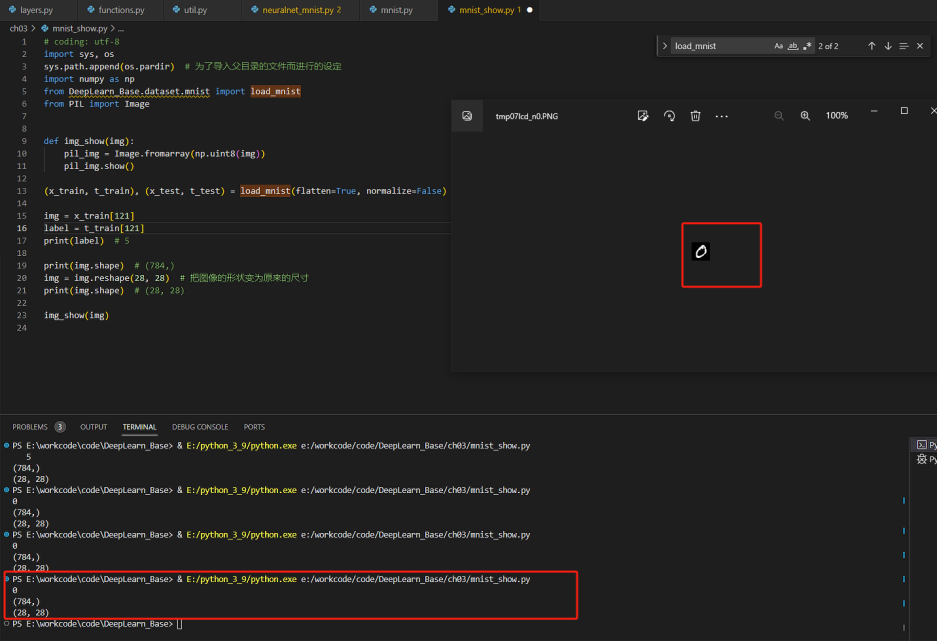
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
img = x_train[1]
label = t_train[1]
print(label) # 5
print(img.shape) # (784,)
img = img.reshape(28, 28) # 把影象的形狀變為原來的尺寸
print(img.shape) # (28, 28)
img_show(img)
讀出來的資料如下所示:
神經網路的推理
現在使用python的numpy結合神經網路的演演算法來推理圖片的內容。整個流程其實就是兩個部分:資料集準備、權重與偏置超引數準備。
資料集準備
使用如下程式碼塊下載準備測試資料集:
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
# 下載mnist資料集
# 分別下載測試影象包、測試標籤包、訓練影象包、訓練標籤包
x, t = get_data()
列印輸出x, t引數shape

讀取實現準備好的權重引數檔案pkl,同時列印出來看看其引數shape
def init_network():
with open("E:\\workcode\\code\\DeepLearn_Base\\ch03\\sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
# 獲取預訓練好的權重與偏置引數
network = init_network()
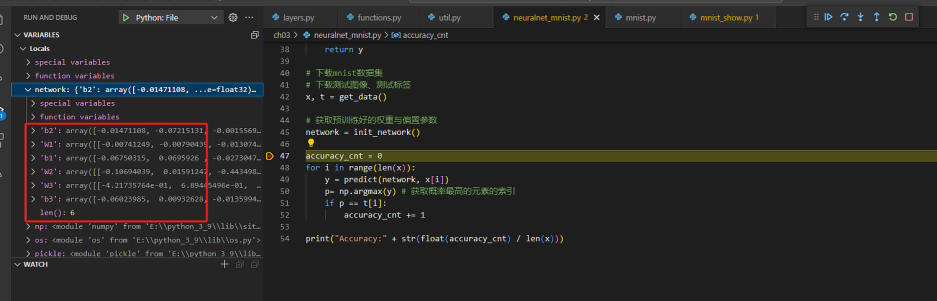
可以看到,超引數分別是3個權重引數與3個偏置引數,為了方便,稍後再列印出其shape .
超引數檔案 sample_weight.pkl 是預訓練好的,本文主要是從神經網路的推理角度考慮,預訓練檔案的準備,暫不涉及。
推理
開始執行神經網路的推理,同時列印出其各個引數的shape
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
# 第一層計算
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
# 第二層計算
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
# 輸出層
y = softmax(a3)
return y
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network, x[i])
p= np.argmax(y) # 獲取概率最高的元素的索引
if p == t[i]:
accuracy_cnt += 1
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
在predict方法中,執行了推理過程,主要是各個數學公式的計算(sigmoid,softmax,線性計算),這些公式都是在numpy的基礎上根據公式用程式語言表述出來的,具體的計算邏輯可以查閱functions.py檔案。
這裡的第一層計算,第二層計算,對應是神經網路中的隱藏層,其數量是2個,而softmax則是輸出層。
看看各個引數的shape:
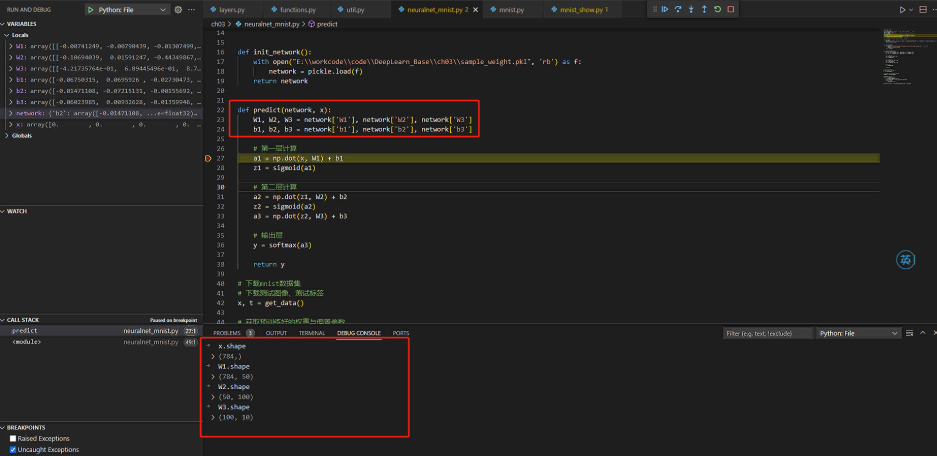
可以看看計算過程中的各個資料維度是否滿足匹配:
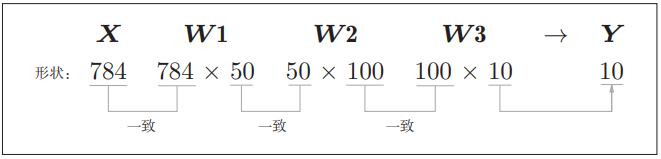
也就是推理的最後會輸出一維陣列且該陣列個數是10個. 取得陣列中概率值最大的資料所對應的索引,就是預測的數位,在最後與測試標籤值比對,得到最後的精確度。
本文的內容來自 <<深度學習入門:基於Python的理論與實現>> 第三章,結合自己的一些思考與總結
本文所有的程式碼可以在: https://www.ituring.com.cn/book/1921 上獲取下載.
執行程式碼前先參考此文 深度學習入門筆記_ch04_No module named ‘mcommon‘調整程式碼路徑,才能成功執行。