C++ 通過CryptoPP計算Hash值
Crypto++ (CryptoPP) 是一個用於密碼學和加密的 C++ 庫。它是一個開源專案,提供了大量的密碼學演演算法和功能,包括對稱加密、非對稱加密、雜湊函數、訊息鑑別碼 (MAC)、數位簽章等。Crypto++ 的目標是提供高效能和可靠的密碼學工具,以滿足軟體開發中對安全性的需求。
該庫包含了許多常見的密碼學演演算法,如AES、DES、RSA、DSA、SHA等,使開發者能夠輕鬆地在他們的應用程式中實現安全性和加密功能。Crypto++ 是以物件導向的方式設計的,因此它的使用通常涉及使用類和物件來表示不同的密碼學概念和演演算法。
Crypto++ 提供了許多特性,包括多平臺支援(Windows、Linux、macOS等)、容易使用的 API、高效能的實現、豐富的檔案和社群支援。在使用 Crypto++ 之前,你需要確保正確地設定和連結 Crypto++ 庫到你的專案中。
編譯Crypto庫
目前Crypto庫的最新版本為8.90,讀者可自行下載對應的庫原始碼,下載好以後使用Visual Studio工具開啟原始檔中的cryptest.sln檔案。
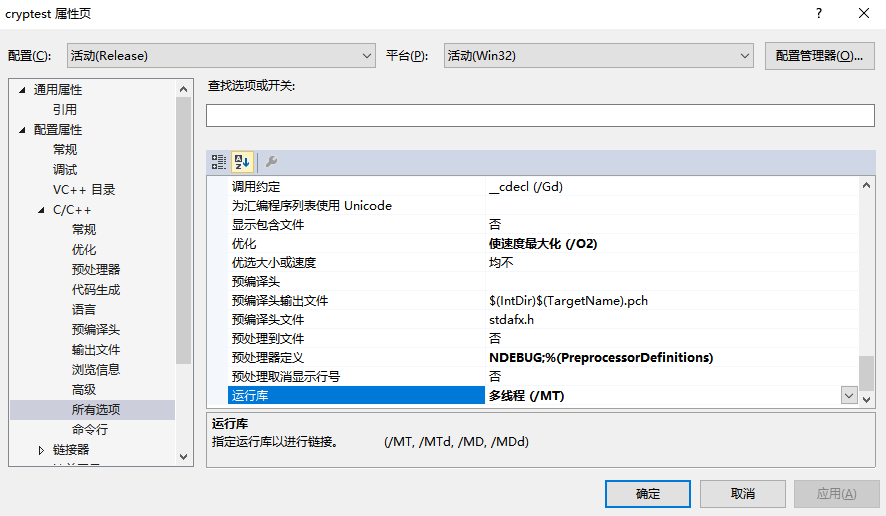
開啟以後選中偵錯選單中的屬性頁面,此時將執行庫修改為多執行緒/MT模式,否則雖可以編譯通過但這個庫卻無法被正常使用,此處是一個坑。
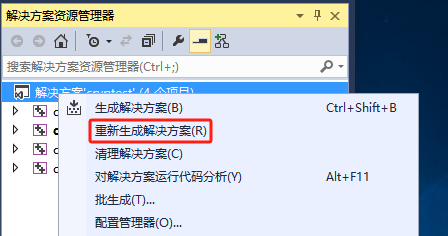
此時選中解決方案,並直接點選重新編譯庫,這個過程可能需要等待一段時間,更具裝置的設定而不同讀者可在最底部看到輸出進度;
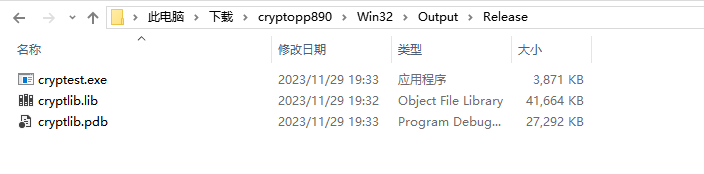
當編譯成功以後,讀者可以來到cryptopp890\Win32\Output\Release目錄下,該目錄下的則是編譯成功後的lib庫檔案,可以將這3個檔案全部儲存在新建的lib資料夾內。
接著在cryptopp890資料夾下直接搜尋所有的*.h標頭檔案,並放入到新建的include資料夾內,此時我們就有了最新版本的開發工具包了。
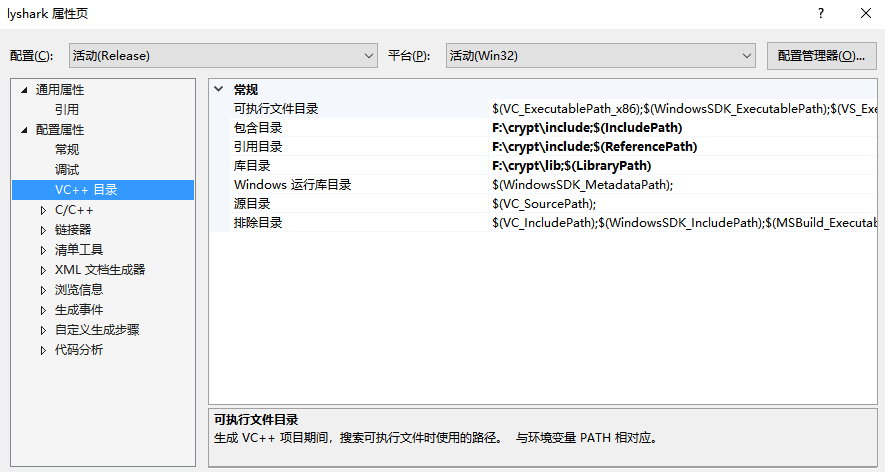
使用該庫也很容易,只需要包含Include與Lib庫檔案即可,如下圖所示設定;
使用MD5演演算法
MD5(Message Digest Algorithm 5)是一種常見的雜湊函數,用於產生128位元的雜湊值(通常以32位元的十六進位制數表示)。MD5廣泛用於檢查資料完整性、數位簽章、密碼儲存等領域。
以下是 MD5 演演算法的基本概述:
- 輸入處理: MD5 接受任意長度的輸入,但輸出是固定長度的128位元。輸入被劃分為512位元的塊,每個塊包含16個32位元的字。
- 填充: 如果輸入的位數不是512的倍數,就需要填充資料,使其長度滿足這個條件。填充是通過在訊息的末尾新增一個'1'和零位元,然後新增一個表示原始訊息長度的64位元整數來完成的。
- 初始化: MD5 有四個32位元的暫存器(A、B、C、D),初始化為特定的常數。這些暫存器將在處理每個訊息塊時進行更新。
- 處理塊: 對於每個512位元塊,MD5 執行64個操作輪次。每個輪次都使用一個非線性函數,一個常數和一個訊息塊的子集。這些輪次通過迴圈結構連線起來。
- 輸出: MD5 的輸出是四個32位元字的級聯,通常以32位元的十六進位制數表示。這四個字的順序是 A、B、C、D。
MD5 演演算法的設計目標是產生一個唯一的(或極其難以相同)雜湊值,以便在密碼儲存、數位簽章和資料完整性檢查等場景中使用。然而,由於MD5存在一些安全性問題,特別是其易受碰撞攻擊的漏洞,現在不再被推薦用於安全性要求較高的場景。對於安全性要求較高的應用,推薦使用更強大和安全的雜湊函數,如SHA-256或SHA-3。
如下這段程式碼中涉及到一些特殊的類,這裡將分別介紹功能;
-
FileSource: 用於從檔案中讀取資料。
-
StringSource: 用於從字串或二進位制資料中讀取資料。
-
HashFilter: 表示一個用於計算雜湊的過濾器。它接受一個雜湊函數作為引數,這裡是
md5。 -
md5: 用於計算輸入資料的 MD5 雜湊值。
-
HexEncoder: 用於將二進位制資料編碼為十六進位製表示。
-
StringSink(dst 或 digest): 用於將資料寫入字串。在這裡,它將最終的雜湊值以十六進位制字串的形式寫入到
dst或digest中。
#include <Windows.h>
#include <iostream>
#include <md5.h>
#include <files.h>
#include <hex.h>
using namespace std;
using namespace CryptoPP;
#pragma comment(lib,"cryptlib.lib")
int main(int argc, char* argv[])
{
// 定義MD5類
MD5 md5;
// 計算字串MD5
string src = "Hello World";
string dst;
StringSource(src, true, new HashFilter(md5, new HexEncoder(new StringSink(dst))));
std::cout << "字串hash = " << dst << std::endl;
// 計算位元組陣列MD5
string digest;
BYTE pData[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
DWORD dwDataSize = sizeof(pData);
StringSource(pData, dwDataSize, true, new HashFilter(md5, new HexEncoder(new StringSink(digest))));
std::cout << "陣列長度 = " << dwDataSize << std::endl;
std::cout << "陣列hash = " << digest << std::endl;
system("pause");
return 0;
}
執行後則可分別輸出字串與陣列的MD5值,如下圖所示;

如果需要從檔案中讀取則需要使用FileSource類,在計算MD5之前先將檔案讀入記憶體在進行計算,如下所示;
#include <Windows.h>
#include <iostream>
#include <md5.h>
#include <files.h>
#include <hex.h>
using namespace std;
using namespace CryptoPP;
#pragma comment(lib,"cryptlib.lib")
// 計算檔案MD5
string CalMD5ByFile(char *pszFileName)
{
string value;
MD5 md5;
FileSource(pszFileName, true, new HashFilter(md5, new HexEncoder(new StringSink(value))));
return value;
}
// 計算資料MD5
string CalMD5ByMemory(PBYTE pData, DWORD dwDataSize)
{
string value;
MD5 md5;
StringSource(pData, dwDataSize, true, new HashFilter(md5, new HexEncoder(new StringSink(value))));
return value;
}
int main(int argc, char* argv[])
{
// 定義MD5類
MD5 md5;
// 計算檔案的MD5
string md51 = CalMD5ByFile("d://lyshark.exe");
printf("md5 = %s\n", md51.c_str());
// 計算檔案記憶體的MD5
HANDLE hFile2 = CreateFile("d://lyshark.exe", GENERIC_READ, FILE_SHARE_READ, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_ARCHIVE, NULL);
// 取檔案長度
DWORD dwFileSize2 = GetFileSize(hFile2, NULL);
BYTE *pData2 = new BYTE[dwFileSize2];
// 讀檔案到記憶體
ReadFile(hFile2, pData2, dwFileSize2, NULL, NULL);
// 計算MD5
string md52 = CalMD5ByMemory(pData2, dwFileSize2);
printf("md5 = %s\n", md52.c_str());
system("pause");
return 0;
}
如下圖所示,是計算後得到的檔案的MD5值;

使用CRC32演演算法
CRC32(Cyclic Redundancy Check,迴圈冗餘校驗)是一種廣泛用於資料校驗的錯誤檢測演演算法。它基於多項式除法,在計算機領域中常用於檢測資料傳輸或儲存過程中的錯誤。
以下是CRC32演演算法的基本概述:
- 多項式選擇: CRC32使用一個32位元的二進位制多項式,通常表示為一個32位元的二進位制數。這個多項式在CRC計算中充當除數。
- 資料處理: 要計算CRC32,首先需要將資料按位元劃分成塊,每個塊的長度等於多項式的次數。通常,CRC32使用位元組為單位進行處理。
- 初始值: CRC32計算開始前,需要初始化一個32位元的暫存器為一個特定的初始值,通常為全1或全0。
- 除法運算: 對於每個資料塊,將它與32位元的暫存器中的值進行互斥或操作。然後,將暫存器中的值右移一位,再與多項式進行互斥或操作。這個過程重複進行,直到所有資料塊都被處理完。
- 最終值: 在處理完所有資料塊後,暫存器中的值就是CRC32的最終校驗值。
- 校驗值附加: 通常,CRC32的結果會附加在原始資料的末尾,形成一個帶有校驗值的完整資料塊。
CRC32廣泛應用於檔案傳輸、儲存系統、乙太網通訊等領域,用於檢測資料傳輸中的錯誤。由於其簡單性和高效性,CRC32在實際應用中被廣泛採用。然而,需要注意的是,CRC32主要用於錯誤檢測而非安全性,不適用於對惡意操作的防範。在一些對安全性要求較高的場景中,其他更強大的校驗演演算法可能更為合適。
crc32演演算法的使用只需要包含<crc.h>標頭檔案,並將程式內的MD5類改為CRC32即可,其他的無任何差異,程式碼如下所示;
#include <Windows.h>
#include <iostream>
#include <crc.h>
#include <files.h>
#include <hex.h>
using namespace std;
using namespace CryptoPP;
#pragma comment(lib,"cryptlib.lib")
// 計算檔案CRC32
string CalCRCByFile(char *pszFileName)
{
string value;
CRC32 crc;
FileSource(pszFileName, true, new HashFilter(crc, new HexEncoder(new StringSink(value))));
return value;
}
// 計算資料CRC32
string CalCRCByMemory(PBYTE pData, DWORD dwDataSize)
{
string value;
CRC32 crc;
StringSource(pData, dwDataSize, true, new HashFilter(crc, new HexEncoder(new StringSink(value))));
return value;
}
int main(int argc, char* argv[])
{
// 定義CRC32類
CRC32 crc32;
// 計算檔案的MD5
string crc = CalCRCByFile("d://lyshark.exe");
printf("crc32 = %s\n", crc.c_str());
// 計算檔案記憶體的crc
HANDLE hFile2 = CreateFile("d://lyshark.exe", GENERIC_READ, FILE_SHARE_READ, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_ARCHIVE, NULL);
// 取檔案長度
DWORD dwFileSize2 = GetFileSize(hFile2, NULL);
BYTE *pData2 = new BYTE[dwFileSize2];
// 讀檔案到記憶體
ReadFile(hFile2, pData2, dwFileSize2, NULL, NULL);
// 計算crc
string crc2 = CalCRCByMemory(pData2, dwFileSize2);
printf("crc32 = %s\n", crc2.c_str());
system("pause");
return 0;
}
程式執行後將會計算檔案的CRC32值,如下圖所示;

使用SHA1演演算法
SHA-1(Secure Hash Algorithm 1)是一種常見的雜湊函數,用於生成160位元的雜湊值。與MD5類似,SHA-1也被廣泛用於數位簽章、資料完整性驗證等領域。然而,由於SHA-1存在一些安全性漏洞,特別是對碰撞攻擊的脆弱性,因此在對安全性要求較高的應用中,不再推薦使用SHA-1,而是轉向使用更安全的雜湊演演算法,如SHA-256或SHA-3。
以下是SHA-1演演算法的基本概述:
- 輸入處理: SHA-1同樣接受任意長度的輸入,但輸出為160位元。輸入被劃分為512位元的塊,每個塊包含16個32位元字。
- 填充: 與MD5類似,如果輸入長度不是512的倍數,需要對輸入進行填充,使其滿足條件。填充的方式是在訊息的末尾新增一個'1'和零位元,然後新增一個64位元整數,表示原始訊息長度。
- 初始化: SHA-1有五個32位元的暫存器(A、B、C、D、E),初始化為特定的常數。這些暫存器將在處理每個訊息塊時進行更新。
- 處理塊: SHA-1的處理方式類似於MD5,但使用了不同的非線性函數和常數。每個訊息塊經過80個操作輪次,其中包括迭代、位運算和條件操作。
- 輸出: SHA-1的輸出是五個32位元字的級聯,通常以40位的十六進位制數表示。這五個字的順序是A、B、C、D、E。
由於SHA-1存在安全性問題,特別是在2017年被證明對碰撞攻擊不再是安全的,因此已經不再被推薦用於安全性要求較高的應用。取而代之的是,SHA-256和SHA-3等更安全的雜湊演演算法,它們提供更長的輸出長度和更強的抗碰撞能力。
與MD5的計算方法一致,SHA系列計算方式只需引入<sha.h>系列標頭檔案,並使用SHA1 sha1;類進行計算即可,如下程式碼所示;
#include <Windows.h>
#include <iostream>
#include <sha.h>
#include <files.h>
#include <hex.h>
using namespace std;
using namespace CryptoPP;
#pragma comment(lib,"cryptlib.lib")
// 計算檔案SHA1
string CalSHA1ByFile(char *pszFileName)
{
string value;
SHA1 sha1;
FileSource(pszFileName, true, new HashFilter(sha1, new HexEncoder(new StringSink(value))));
return value;
}
// 計算資料SHA1
string CalSHA1ByMemory(PBYTE pData, DWORD dwDataSize)
{
string value;
SHA1 sha1;
StringSource(pData, dwDataSize, true, new HashFilter(sha1, new HexEncoder(new StringSink(value))));
return value;
}
int main(int argc, char* argv[])
{
// 定義SHA類
SHA1 sha1;
// 計算檔案的sha1
string sha11 = CalSHA1ByFile("d://lyshark.exe");
printf("sha1 = %s\n", sha11.c_str());
// 計算檔案記憶體的sha1
HANDLE hFile2 = CreateFile("d://lyshark.exe", GENERIC_READ, FILE_SHARE_READ, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_ARCHIVE, NULL);
// 取檔案長度
DWORD dwFileSize2 = GetFileSize(hFile2, NULL);
BYTE *pData2 = new BYTE[dwFileSize2];
// 讀檔案到記憶體
ReadFile(hFile2, pData2, dwFileSize2, NULL, NULL);
// 計算sha1
string sha12 = CalSHA1ByMemory(pData2, dwFileSize2);
printf("sha1 = %s\n", sha12.c_str());
system("pause");
return 0;
}
sha1計算結果如下圖所示;

使用SHA256演演算法
SHA-256(Secure Hash Algorithm 256-bit)是SHA-2(Secure Hash Algorithm 2)家族中的一種雜湊函數,用於生成256位的雜湊值。SHA-256是目前廣泛應用於各種安全領域的強大雜湊演演算法,包括數位簽章、證書籤名、資料完整性驗證等。SHA-256提供了更高的安全性,相對於之前的SHA-1和MD5來說更為強大。
以下是SHA-256演演算法的基本概述:
- 輸入處理: SHA-256同樣接受任意長度的輸入,但輸出為256位。輸入被劃分為512位元的塊,每個塊包含16個32位元字。
- 填充: 與SHA-1和MD5相似,如果輸入長度不是512的倍數,需要對輸入進行填充,以滿足條件。填充的方式包括新增一個'1'和零位元,然後新增一個64位元整數,表示原始訊息長度。
- 初始化: SHA-256有八個32位元的暫存器(A、B、C、D、E、F、G、H),初始化為特定的常數。這些暫存器將在處理每個訊息塊時進行更新。
- 處理塊: SHA-256的處理方式包括64個操作輪次,每個輪次使用一個非線性函數、常數和訊息塊的子集。這些輪次通過迴圈結構連線起來。
- 輸出: SHA-256的輸出是八個32位元字的級聯,通常以64位元的十六進位制數表示。這八個字的順序是A、B、C、D、E、F、G、H。
SHA-256相對於SHA-1和MD5提供了更高的抗碰撞能力和更強的安全性,使其成為當前廣泛使用的雜湊演演算法之一。然而,隨著計算能力的增強,一些專家逐漸傾向於使用更長的雜湊演演算法,如SHA-3,以適應未來更高的安全性需求。
程式碼呼叫上與sha1保持一致,Sha256同樣只需要少量的更改,只要掌握了這個規律,那麼則可以完成其他演演算法的呼叫,程式碼如下所示;
#include <Windows.h>
#include <iostream>
#include <sha.h>
#include <files.h>
#include <hex.h>
using namespace std;
using namespace CryptoPP;
#pragma comment(lib,"cryptlib.lib")
// 計算檔案SHA1
string CalSHA1ByFile(char *pszFileName)
{
string value;
SHA256 sha256;
FileSource(pszFileName, true, new HashFilter(sha256, new HexEncoder(new StringSink(value))));
return value;
}
// 計算資料SHA1
string CalSHA1ByMemory(PBYTE pData, DWORD dwDataSize)
{
string value;
SHA256 sha256;
StringSource(pData, dwDataSize, true, new HashFilter(sha256, new HexEncoder(new StringSink(value))));
return value;
}
int main(int argc, char* argv[])
{
// 定義SHA類
SHA256 sha256;
// 計算檔案的sha256
string sha11 = CalSHA1ByFile("d://lyshark.exe");
printf("sha256 = %s\n", sha11.c_str());
// 計算檔案記憶體的sha256
HANDLE hFile2 = CreateFile("d://lyshark.exe", GENERIC_READ, FILE_SHARE_READ, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_ARCHIVE, NULL);
// 取檔案長度
DWORD dwFileSize2 = GetFileSize(hFile2, NULL);
BYTE *pData2 = new BYTE[dwFileSize2];
// 讀檔案到記憶體
ReadFile(hFile2, pData2, dwFileSize2, NULL, NULL);
// 計算sha256
string sha12 = CalSHA1ByMemory(pData2, dwFileSize2);
printf("sha256 = %s\n", sha12.c_str());
system("pause");
return 0;
}
執行後則可輸出檔案的sha256值,如下圖所示;
