聊一聊大模型
事情還得從ChatGPT說起。
2022年12月OpenAI釋出了自然語言生成模型ChatGPT,一個可以基於使用者輸入文字自動生成回答的人工智慧體。它有著趕超人類的自然對話程度以及逆天的學識。一時間引爆了整個人工智慧界,各大巨頭也紛紛跟進發布了自家的大模型,如:百度-文心一言、科大訊飛-星火大模型、Meta-LLama等
那麼到底多大的模型算大模型呢?截至目前仍沒有明確的標準,但從目前各家所釋出的模型來看,模型引數至少要在B(十億)級別才能算作入門級大模型,理論上還可以更大,沒有上限。以上只是個人理解,目前還沒有人對大模型進行詳細的定義。
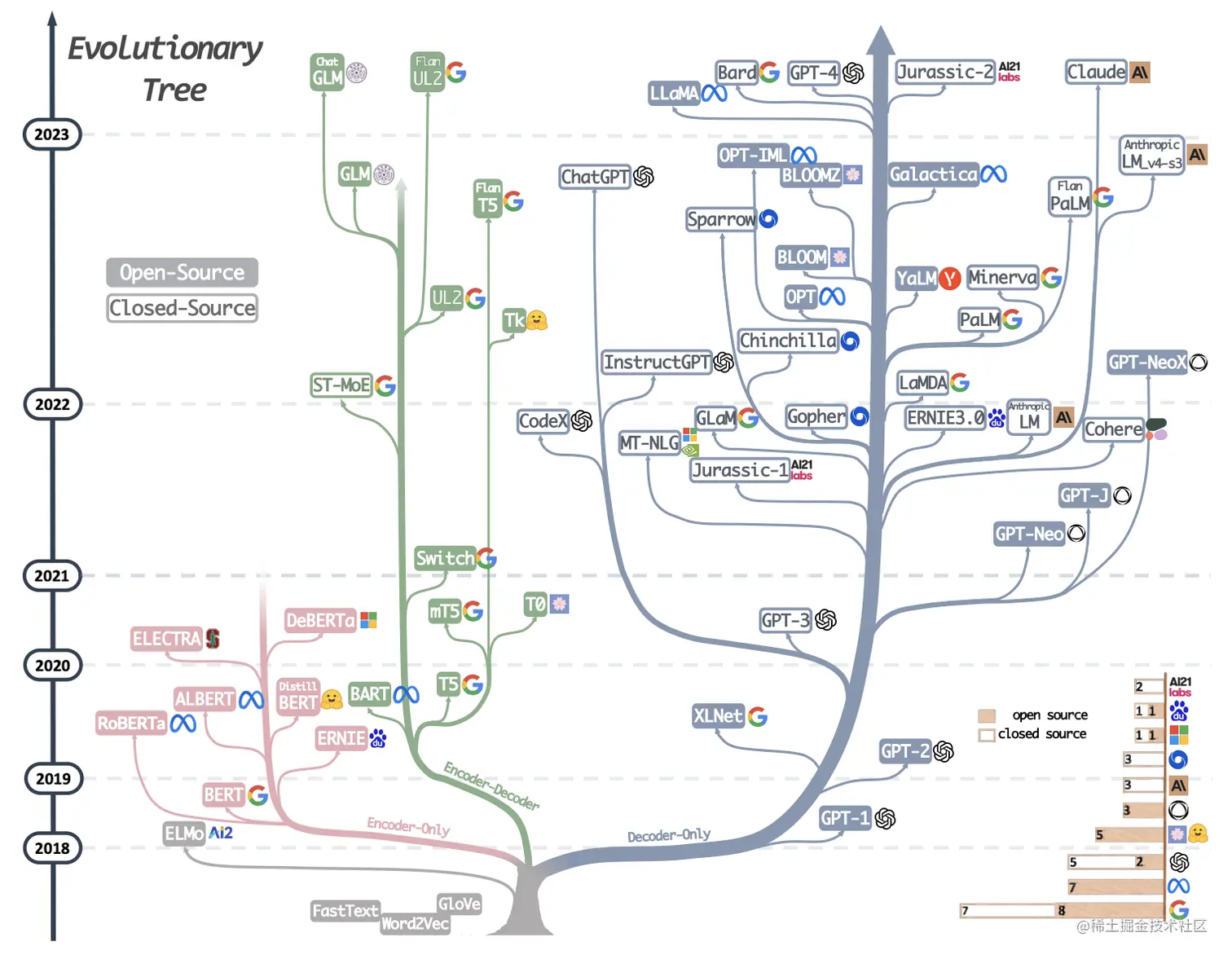
來一張圖我們瞭解一下大模型的發展歷程,從圖中可以看到所謂大模型家族都有同一個根(elmo這一支除外)即Transformer,我們知道transformer由encoder-decoder兩部分組成,encoder部分負責編碼,更側重於資訊理解;而decoder部分負責解碼,更側重於文字生成;這樣在模型選型方面就會有3種不同的選型,即:【only-encoder】這部分以大名鼎鼎的Bert為代表、【only-decoder】這部分的代表就是我們的當紅炸子雞GPT系列、【encoder-decoder】這部分相比於其他兩個部分就顯得略微暗淡一些,但同樣也有一些相當不錯的成果,其中尤以T5為代表。個人理解T5更像一個過渡產品,通過新增一些prefix或者prompt將幾乎所有NLP任務都可以轉換為Text-to-Text的任務,這樣就使得原本僅適合encoder的任務(classification)也可以使用decoder的模式來處理。
圖中時間節點可以看到是從2018年開始,2018年應該算是NLP領域的中興之年,這一年誕生了大名鼎鼎的Bert(僅使用Transformer的Encoder部分),一舉革了以RNN/LSTM/GRU等為代表的老牌編碼器的命。Bert確立了一種新的正規化,在Bert之前我們的模型是與任務強相關的,一個模型繫結一個任務,遷移性差。而Bert將NLP任務劃分為預訓練+微調的兩階段模式:預訓練階段使用大量的無標記資料訓練一個Mask Language Model,而具體的下游任務只需要少量的資料在預訓練的基礎上微調即可。這樣帶來兩個好處:(a)不需要針對專門的任務設計模型,只需要在預訓練模型上稍作調整即可,遷移性好,真的方便。(b)效果是真的好,畢竟預訓練學了那麼多的知識。所以在接下來的幾年內幾乎所有的工作都是在圍繞Bert來展看,又好用又有效果,誰能不愛呢?如下圖就是Bert家族的明星們。
Transformer解決了哪些問題?
在沒出現Transformer之前,NLP領域幾乎都是以RNN模型為主導,RNN有兩個比較明顯的缺陷:(a)RNN模型是一個序列模型,只能一個時序一個時序的依次來處理資訊,後一個時序需要依賴前一個時序的輸出,這樣就導致不能並行,時序越長效能越低同時也會造成一定的資訊丟失。(b)RNN模型是一個單向模型,只能從左到右或者從右到左進行處理,無法實現真正的雙向編碼。

Transformer摒棄了RNN的順序編碼方式,完全使用注意力機制來對資訊進行編碼,如上圖所示,Transformer的計算過程是完全並行的,可以同時計算所有時序的注意力得分。另外Transformer是真正的雙向編碼,如上圖所示,在計算input#2的注意力得分時,input#2是可以同時看見input#1、input#3的且對於input#2而言input#1、input#3、甚至input#n都是同等距離的,沒有所謂距離的概念,真正的天涯若比鄰的感覺。
Tranformer的廬山真面目。
接下來我們從頭更加深入的剖析一下Transformer結構,以及為什麼大模型都要基於Transformer架構。以及在大模型時代我們都對Transformer做了哪些調整及修改。
同樣來一張圖,下面這張圖就是我們Transformer的架構圖,從圖中可以看出,Transformer由左右兩部分組成,左邊這部分是Encoder,右邊這部分就是Decoder了。Encoder負責對資訊進行編碼而Decoder則負責對資訊解碼 。下面我們從下往上對下圖的每個部分進行解讀。
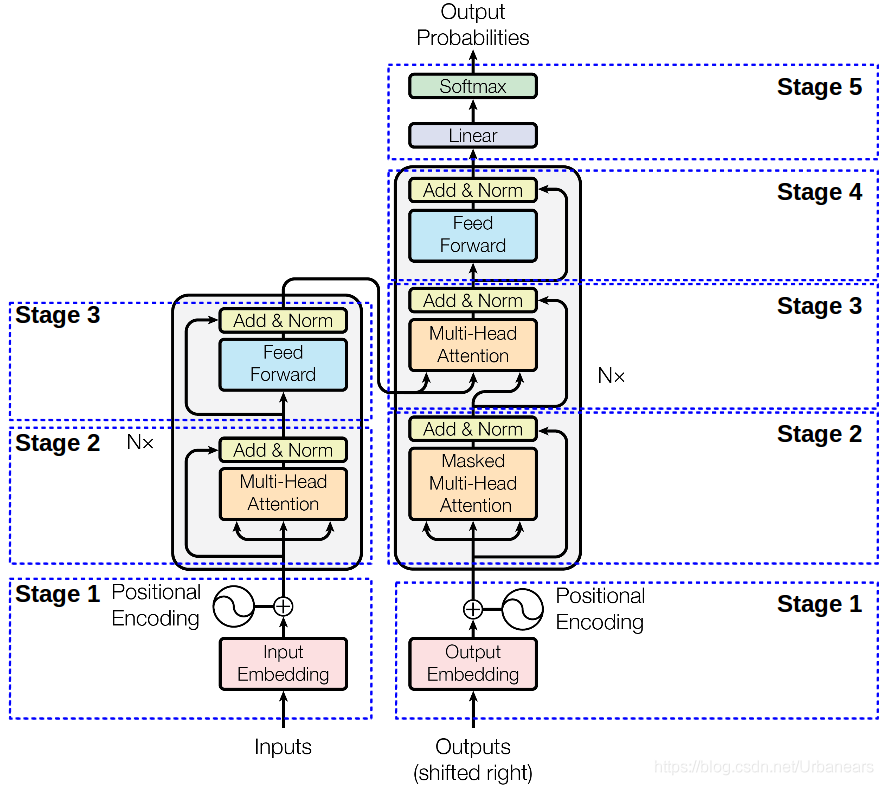
Stage-1部分就做兩件事:對輸入的文字進行編碼、對文字位置進行編碼。
Token Embedding
這部分主要是對文字進行編碼,其核心部分為如何切分Token。典型的做法有Sentence Piece、Word Picece、BPE、甚至UniGram切詞等。切詞方式沒有定數,個人理解切詞的一個原則是:在能夠覆蓋到你的資料集的同時詞彙表儘可能的小。故對切詞方式不在贅述。下面囉嗦一下如何得到Token Embedding:

Positional Encoding
位置編碼,前面我們有提到過在計算注意力的時候是沒有所謂位置的概念的(見圖-3),而對於任何一門語言,單詞在句子中的位置以及排列順序是非常重要的,它們不僅是一個句子的語法結構的組成部分,更是表達語意的重要概念。一個單詞在句子的位置或排列順序不同,可能整個句子的意思就發生了偏差,比如:」我喜歡你「和」你喜歡我「對於self attention來說可能會被處理為同一個意思,但真實意思卻不盡相同。再比如下面這句話「天上飛來一隻鳥,它的頭上插著一支旗子;地上躺著一隻狗,它的顏色是黑色的。」,當我們在計算」鳥「的注意力分值的時候,第一個「它」與第二個「它」理論上對「鳥」的貢獻程度是不一樣的,同樣若沒有位置資訊則這兩個」它「對於」鳥「來說就會有同樣的貢獻度,這顯然是不合理的。為了消除上述這些問題,Transformer裡引入了Position Encoding的概念。那麼如何對位置進行編碼?
用整數值編輯位置。一種很樸素的做法是按照token序列依次進行編碼,即:0,1,2,3,……_n_。這種方式會有一些缺陷如:(a)無法處理更長的序列,外推性差。(b)模型的位置表示是無界的,隨著序列長度的增加,位置值會越來越大。這種和Bert的可學習的編碼方式原理一致,不再贅述。
用[0,1]範圍標記位置。為了解決整數值帶來的問題,我們可以考慮將範圍編碼限制在[0,1]之間,0表示第一個token,1表示最後一個token,然後按照token的多少平均劃分[0,1]區間,這樣一來我們的編碼就是有界的。舉個例子:當有3個token時位置資訊就表示為
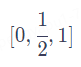
4個token時則表示為
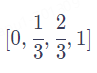
等以此類推。但這樣同樣會遇到一些問題,比如當序列長度不一樣時,token之間的相對距離就會不同。比如當token數為3時,token之間的相對值為
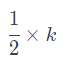
若token數為4時則相對值變為
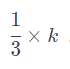

1.它能為每個時間步驟輸出一個獨一無二的編碼,即編碼是唯一且確定的;
2.在序列長度不同的情況下,不同序列中token的相對位置/距離也要保持一致;
3.模型應該能毫不費力地泛化到更長的句子,它的值應該是有界的;


大模型時代常用的位置編碼方式。
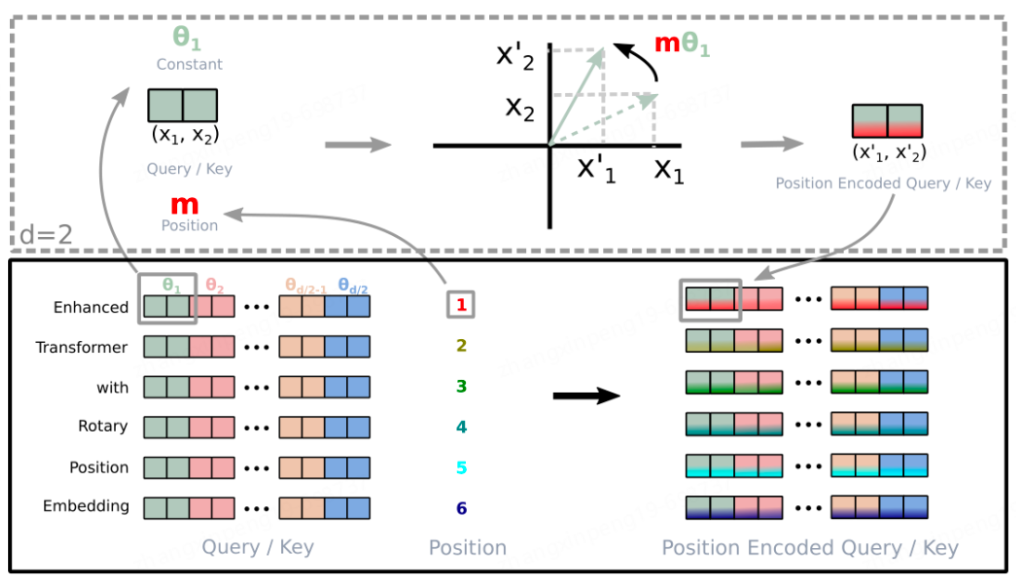
大模型時代如何編碼能夠獲得更好的外推性顯得尤為重要,那麼為什麼要強調外推性?一個很現實的原因是在隨著模型不斷的變大,動輒幾千張卡甚至幾萬張卡的計算資源就把絕大部分的從業者擋在了門外,而我們面臨的問題也越來越複雜,輸入越來越長。我們沒辦法根據不同的問題去調整模型,這樣就需要一個全能的基座模型,它能夠處理比訓練長度更長的輸入。以下面兩種編碼方式為代表。




具體操作流程如下圖所示:
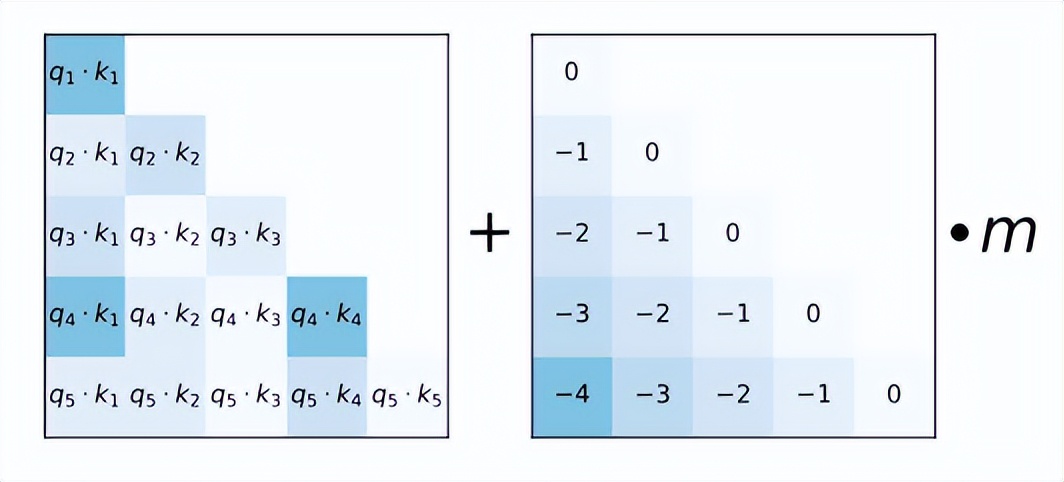
AliBi。AliBi的做法相較於正弦波或RoPE編碼來的簡單粗暴,與傳統方法不同,ALiBi不會向token embedding中新增position embedding,取而代之的是直接將token的相對距離直接加到了AttentionScore矩陣上,比如_q_和_k_相對位置差 1 就加上一個 -1 的偏置,兩個 token 距離越遠這個負數就越大,代表他們的相互貢獻越低。如下圖,左側的矩陣展示了每一對query-key的注意力得分,右側的矩陣展示了每一對query-key之間的距離,m是固定的引數,每個注意頭對應一個標量。原有注意力矩陣_A_,疊加了位置偏移矩陣_B_之後為 A+B_×_m
Attention注意力機制

公式-5就是Self Attention的核心,只要理解了這個公式也就理解了Transformer。
我們仔細看一下圖-4中的Stage-2部分會發現Encoder和Decoder這部分是不太一樣的,Encoder這部分叫做Multi Head Attention而Decoder部分叫做Masked Multi Head Attention。多了個Masked,先記下來後面我們來對這部分做解釋。
在【那麼為什麼要提出Transformer架構?】部分我們講到了,Transformer摒棄了RNN的順序編碼方式,採用了一種叫做注意力機制的方法來進行編碼,那麼什麼是注意力機制?如下:
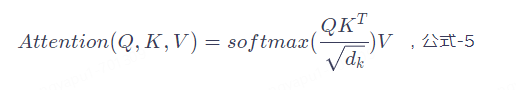
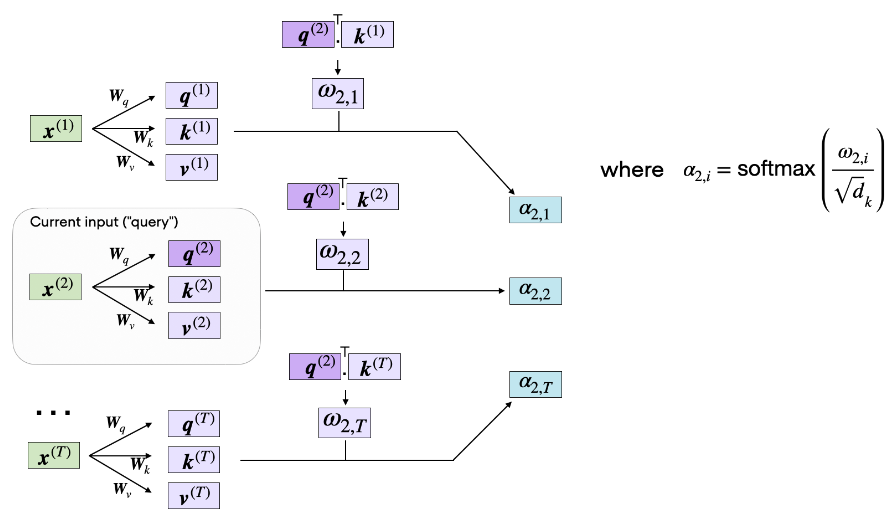
這個公式的輸出就是注意力得分,怎麼來理解這個式子,我們用一個例子來類比。想象一下我們在百度進行搜尋的一個場景,_Q_就相當於我們在輸入框輸入的關鍵詞,當我們輸入關鍵詞之後搜尋引擎會根據我們的關鍵詞與檔案的相似度輸出一個快照列表,_K_就是這個快照列表,每個檔案與我們輸入的關鍵詞的相似度不同,所以排在第一個的是搜尋引擎認為最重要的檔案,打分就高,其他依次降序排列;然後你點進去閱讀了這篇文章,那麼這篇文章的內容我們就可以類比為_V_。這是一個搜尋引擎的檢索過程,而Attention的計算過程與搜尋的過程幾乎完全相同,我們結合下面這張圖來詳細的說明一下注意力的計算過程。


Multi Head Attention(MHA)
先來看一下Multi Head Attention的計算方法,很清晰是吧。前面說到的Attention就是在一個頭裡的計算,那麼多頭就是把這個計算多跑幾次,分別得到每個頭的輸出,然後將所有的頭輸出進行連結,最後再乘一個矩陣_WO_將輸出拉回到某個維度空間(Transformer裡為512維),如下圖有8個注意力頭。

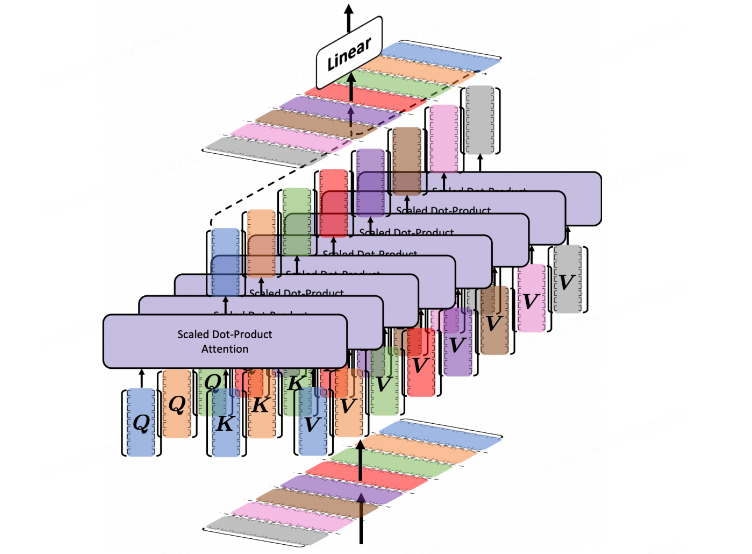
為什麼要使用多頭注意力?多頭注意力機制提供了多個表示子空間,每個頭獨享不同得_Q_,K,_V_權重矩陣,這些權重矩陣每一個都是隨機初始化,在訓練之後,每個頭都將輸入投影到不同的表示空間,多個head學習得注意力側重點可能略微不同,這樣給了模型更大的容量。(可以想象一下CNN中不同的濾波器分別關注著不同的特徵一樣)。
這裡說一下Multi Query Attention(MQA),這也是在一些大模型中使用的對MHA進行改造的手段,比如:Falcon、PaLM等。MQA就是在所有的注意力頭上共用_K_,V,提升推理效能、減少視訊記憶體佔用。就這麼簡單。
殘差連結、Norm、FFN、啟用函數。
在深度神經網路中,當網路的深度增加時,模型過擬合以及梯度消失、爆炸的問題發生的概率也會隨之增加,導致淺層網路引數無法更新,殘差連結正是為了解決這些問題;Norm可以將每一層的輸出通過歸一化到符合某個分佈,可以使模型更加穩定。常見的Norm的方法有BatchNorm、LayerNorm。NLP任務中由於輸入長度不一致的問題一般都是用LayerNorm來做歸一化。在大模型時代,很多模型都使用RMSNorm來替代LayerNorm,比如LLaMA、ChatGLM等,只不過大家在使用Norm的時候位置不同罷了。有些模型可能會將Norm放在殘差之前(LLaMA)、有些可能會在殘差之後(ChatGLM)、甚至Embedding之後甚至放在整個Transformer之後等,至於哪個效果好,仁者見仁。
下面是LayerNorm和RMSNorm的計算公式,RMSNorm想相較於LayerNorm去除了計算均值平移的部分,計算速度更快,且效果與LayerNorm相當。公式如下所示。

啟用函數如果非要提的話那就提一下SwiGLU,在很多大模型中都有用到,比如LLaMA2、ChatGLM2等,扔個公式,體會一下。

至此我們幾乎已經聊完了Transformer的核心部分。圖-4中Stage-2(左)部分與Stage-3(右)完全相同,Stage-3(左)與Stage-4(右)完全相同,Stage-2(右)部分幾乎與Stage-2(左)部分完全相同,只不過右側部分的Attention需要掩碼,這是因為右側是一個Decoder的過程,而Decoder是一個從左到右的自迴歸的過程,想象一下我們在寫下一句話【今天的天很藍】,你是從左到右依次寫出的這幾個字,當你在寫「今」的時候這時候還沒「天」所以「天」這個位置對於「今」這個位置的注意力應該為0,以此類推。這時候就要對t+1時刻做掩碼。即計算t時刻的注意力分值的時候將t+1時刻對t時刻的注意力設為0即可。如下圖所示,將查詢矩陣的上三角設定為一個極小值即可,不再贅述。
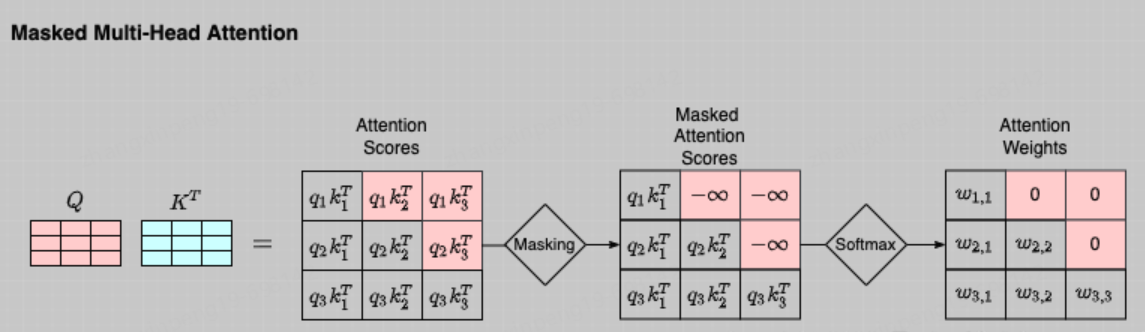
接下來說一下在大模型時代我們對Attention部分有哪些改造。常見的改造方法即Flash Attention
Flash Attention。
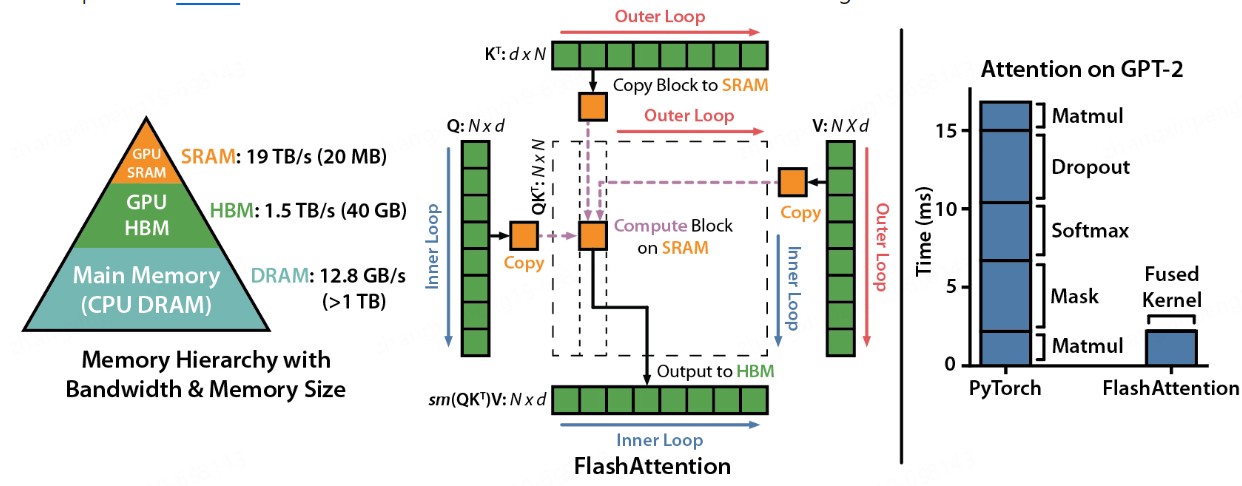




3.依次迭代,直至計算完畢。因整個計算全部在GPU SRAM中進行僅有個別中間值的儲存需要與HBM進行互動,減少了與HBM的互動,提升計算效能。
預訓練及微調方法
介紹完了Transformer的原理以及大模型時代針對於Transformer的每個元件都做了哪些修改。接下來我們聊一下如何訓練以及如何微調大模型。
前面我們說到Bert時代將所有的NLP任務統一劃分為了預訓練+微調兩階段,預訓練負責從大量無標記的資料中學習語言特徵,微調使用有標記的資料調整模型適應具體的下游任務。這個模式同樣適用於大模型。
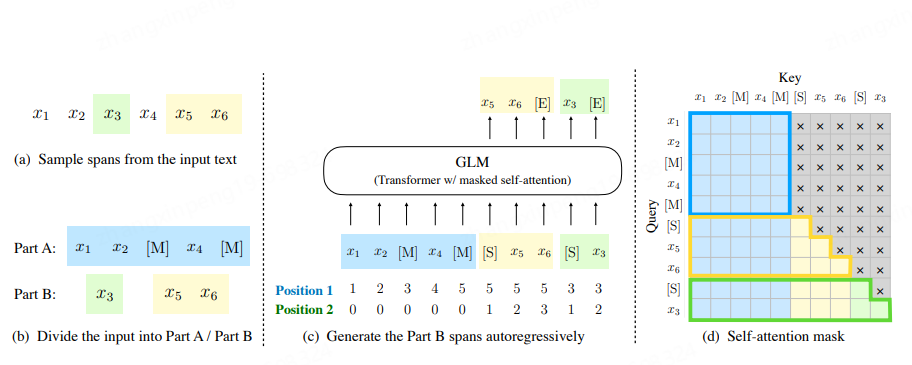
預訓練。市面上絕大部分的大模型都是only-decoder的自迴歸模型,即用前n個token預測第n+1個token的值得概率。這是一個語言模型,不再贅述。但也有比較特殊的,比如ChatGLM,如下圖,它既有Encoder部分也有Decoder部分。稍微複雜一點,首先它會在輸入中隨機Mask一些span,然後將Mask後的span隨機的拼接在原始輸入的後邊。訓練的時候分兩步:(1)對[S]後進行續寫,這部分是個Decoder的部分,單向的。(2)對Mask掉的部分進行預測,使用第(1)步的生成結果進行調整。從而使模型達到收斂。
總之預訓練的任務就是從大量無標號得資料中學習到某些知識,因為是很自然得語言模型,所以不需要人工打標,只要能收集到大量得文字資料就可以訓練,前提是算力夠,理論上預訓練得資料越多越好。大模型時代幾乎都是幾十億token的資料。
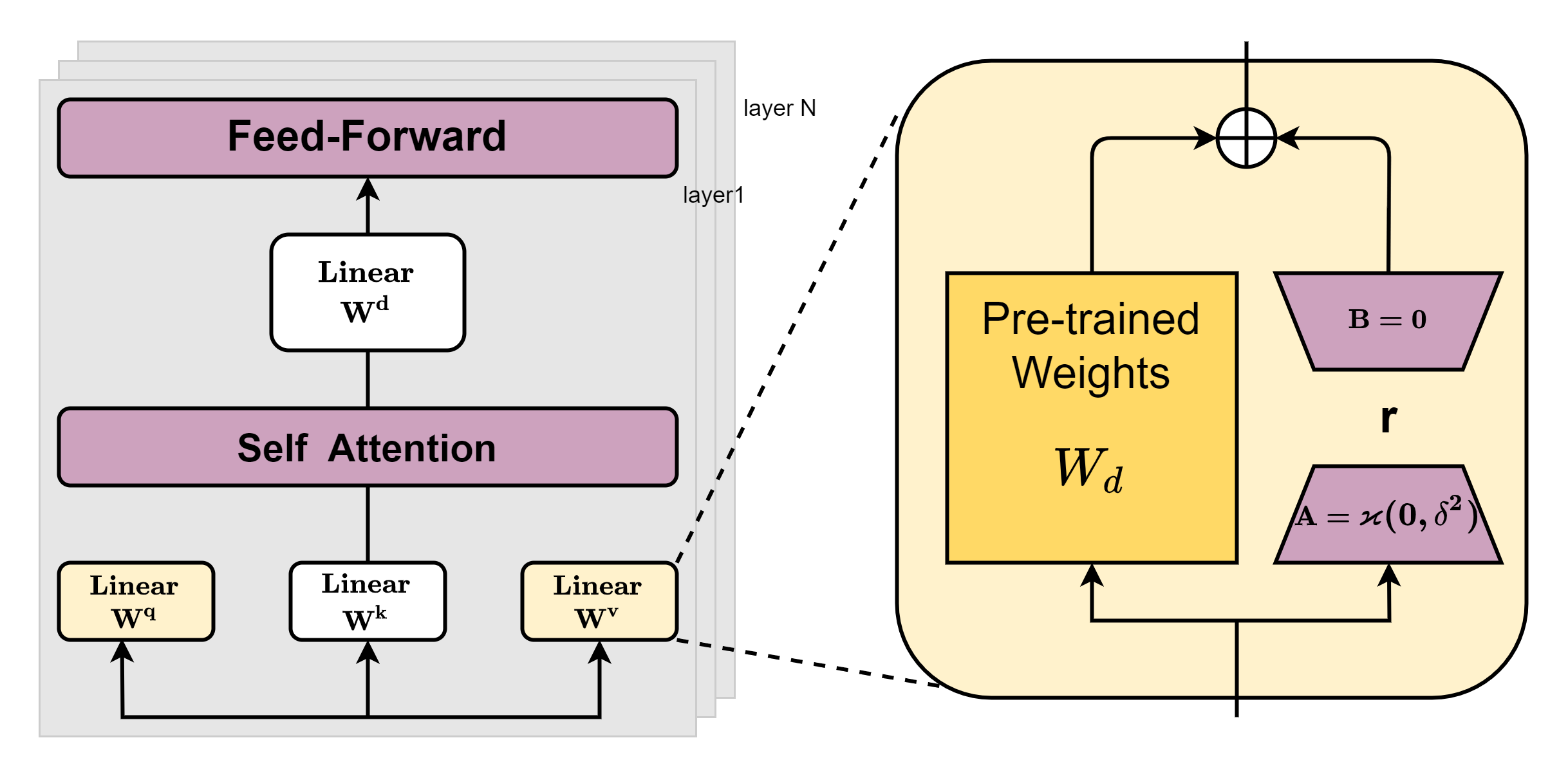
微調(Fine Tuning)。微調是為了適應具體得下游任務,使用特定的有標記的資料集對模型進行進一步調整從而往模型中注入某些知識的手段。如果你有足夠的資源全引數微調是個不錯的選擇,它可以更加充分的學習到你的特定資料的特性,理論上效果應該是最好的。但大模型動輒幾十個G,訓練起來儲存至少還要再翻一倍,非常耗費資源。那麼有沒有別的方法也能往模型中注入特定域的知識呢?還是有一些方法的,既然全引數跑不動那麼我們就調整部分引數,這就是引數高效微調(Parameter-Efficient Fine-Tuning)這一類方法的思想。下面我們說一些幾種引數高效微調的方法。
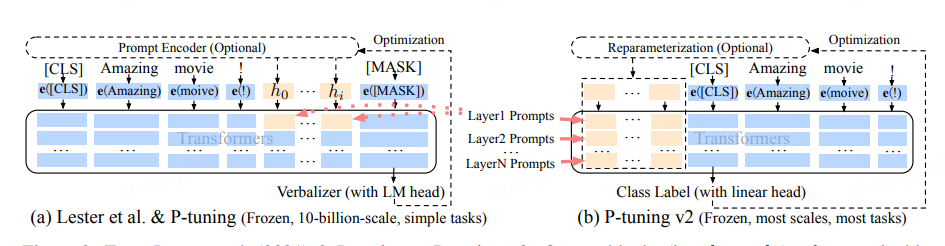
P-Tuning。這是一類方法(prompt tuning、prefix tuning、p-tuning、p-tuning v2),雖然實現不同但思路大同小異,至於那個名字對應到那個方法我也記不清,所以這塊我們把這些放在一塊來說。p-tuning這一類方法的做法是在模型原有結構上增加一部分引數,比如:在原輸入上寫死增加一些提示詞、在原始Embedding前面拼接上一些可訓練的張量等。當然這些張量的生成上也有不同,有些是跟模型一起訓練的、有些是專門針對這部分搞個編碼器;其次拼接位置也有所不同,有的是拼接在Embedding上,有的可能每個層都拼接。總之就是搞了一部分可學習的引數然後放在模型裡面一起訓練,只更新這部分引數的權重,從而達到往模型中注入知識的目的。來張圖體驗一下。這一類的方法的缺陷是會佔用原有模型的一部分空間,這樣可能會降低原有模型能夠處理的文字長度的上限。
Adapter。Adapter的做法是在預訓練模型的某些層中間新增Adapter塊(如下圖中間部分所示),微調的時候主體模型凍結,只更新Adapter塊的權重,由Adapter塊學習特定的下游任務。每個Adapter由兩個前饋層組成,第一個前饋層將輸入從原始維度投影到一個相對較小的維度,然後再經過一層非線性轉換,第二個前饋層再還原到原始輸入維度,作為Adapter的輸出,與預訓練其他模型進行連線。與前面提到的P-Tuning系列不同,P-Tuning是在預訓練模型的某些層上增加一些可訓練的引數,而Adapter是在預訓練模型的層之間新增可訓練引數。一個更形象的說法P-Tuning使模型變胖了(實際上是壓縮了一部分原有空間),Adapter使模型變高了。Adapter的插入可以分為序列和並行兩種,如下圖左右兩圖所示,很好理解。
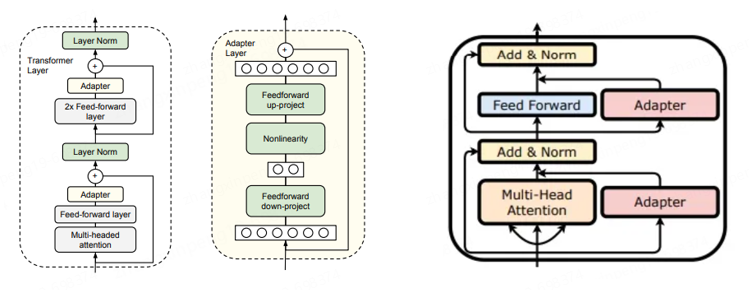

訓練方式。
最後我們再聊一下在現有算力下如何訓練一個大模型。大模型訓練是一個複雜的任務,隨著模型和資料規模的增大意味著訓練時間的增長。 傳統的單卡訓練幾乎無法來完成這個事情,於是就要藉助於分散式訓練來大規模的訓練模型。分散式的思想其實也很簡單,總結一句話就是:化繁為簡、化整為零。將整個訓練拆解到不同的卡上,各卡之間共同作業來完成訓練。那麼如何來拆解整個訓練過程?大提升可以分為以下幾種:
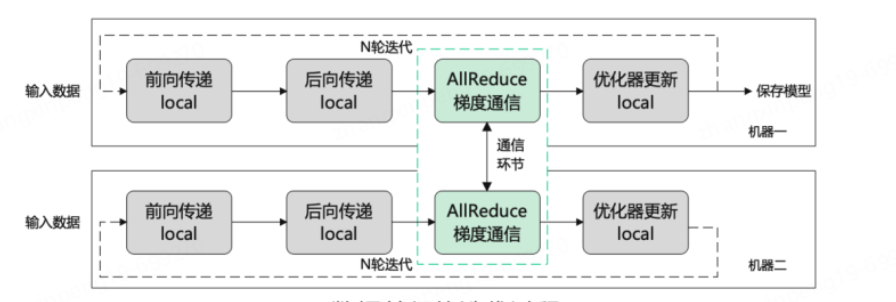
資料並行:所謂資料並行就是將樣本資料切分成不同的更小的輸入,每張卡只需要處理更小的一部分資料,最終在合併計算梯度,然後將梯度分別更新到每個節點上。資料並行的前提是單卡能夠吃得下整個模型。
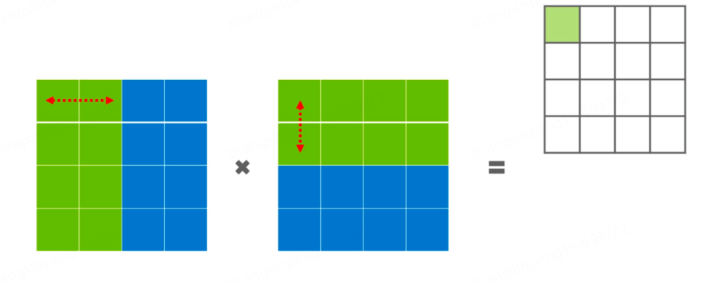
模型並行:模型並行可細分為流水線並行和張量並行。流水線並行是將模型的不同層分發到不同的機器上,每個機器負責某些層的計算。比如:03層由gpu0來處理、48層由gpu1來處理等最終再彙總計算梯度進行更新。張量並行相對於流水線並行切分的更細,流水線並行是對層進行切分,但每個層仍然是完整的分在一張卡上,而張量並行是對層內進行切分,將一個層切分為由多個張量組成的部分,每個張量由不同的機器進行運算。如下圖所示,可能綠色部分在一張卡上,藍色部分在另一張卡上進行計算。
在模型訓練這塊也有很多現成的框架以供使用,如:DeepSpeed、Megatron-LM等,本次介紹主要已模型框架及原理為主,相關訓練框架不在本次介紹範圍之內,後續我們再針對訓練框架做一些專門的介紹。
總結:
本文對大模型從原理及結構上做了簡單的介紹,希望能給各位在瞭解大模型的路上提供一些幫助。個人經驗有限,說的不對的地方還請及時提出寶貴的意見,也可以聯絡本人線下討論。下期會結合我們在財富領域訓練大模型的經驗寫一篇偏實踐的文章出來。
參考文獻:
1.Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
2.Fast Transformer Decoding: One Write-Head is All You Need
3.GLU Variants Improve Transformer
4.GAUSSIAN ERROR LINEAR UNITS (GELUs)
5.Root Mean Square Layer Normalization
6.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
7.Language Models are Few-Shot Learners
8.Attention Is All You Need
9.TRAIN SHORT, TEST LONG: ATTENTION WITH LINEAR BIASES ENABLES INPUT LENGTH EXTRAPOLATION
10.ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING
11.GLM: General Language Model Pretraining with Autoregressive Blank Infilling
12.FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
13.Parameter-Efficient Transfer Learning for NLP
14.The Power of Scale for Parameter-Efficient Prompt Tuning
15.Prefix-Tuning: Optimizing Continuous Prompts for Generation
16.P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
17.LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
18.Training language models to follow instructions with human feedback
19.https://spaces.ac.cn/archives/8265
作者:京東科技 張新朋
來源:京東雲開發者社群 轉載請註明來源