迴歸演演算法全解析!一文讀懂機器學習中的迴歸模型
本文全面深入地探討了機器學習中的迴歸問題,從基礎概念和常用演演算法,到評估指標、演演算法選擇,以及面對的挑戰與解決方案。文章提供了豐富的技術細節和實用指導,旨在幫助讀者更有效地理解和應用迴歸模型。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。

一、引言
迴歸問題的重要性
迴歸問題是機器學習領域中最古老、最基礎,同時也是最廣泛應用的問題之一。無論是在金融、醫療、零售還是自然科學中,迴歸模型都扮演著至關重要的角色。簡單地說,迴歸分析旨在建立一個模型,通過這個模型我們可以用一組特徵(自變數)來預測一個連續的結果(因變數)。例如,用房間面積、位置等特徵來預測房價。
文章目的和結構概覽
這篇文章的目的是提供一個全面而深入的迴歸問題指南,涵蓋從基礎概念到複雜演演算法,從評估指標到實際應用案例的各個方面。我們將首先介紹迴歸問題的基礎知識,然後探討幾種常見的迴歸演演算法及其程式碼實現。文章也將介紹如何評估和優化模型,以及如何解決迴歸問題中可能遇到的一些常見挑戰。
結構方面,文章將按照以下幾個主要部分進行組織:
- 迴歸基礎:解釋什麼是迴歸問題,以及它與分類問題的區別。
- 常見迴歸演演算法:深入探討幾種迴歸演演算法,包括其數學原理和程式碼實現。
- 評估指標:介紹用於評估迴歸模型效能的幾種主要指標。
- 迴歸問題的挑戰與解決方案:討論過擬合、欠擬合等問題,並提供解決方案。
二、迴歸基礎
迴歸問題在機器學習和資料科學領域佔據了核心地位。本章節將對迴歸問題的基礎概念進行全面而深入的探討。
什麼是迴歸問題
迴歸問題是預測一個連續值的輸出(因變數)基於一個或多個輸入(自變數或特徵)的機器學習任務。換句話說,迴歸模型嘗試找到自變數和因變數之間的內在關係。
例子:
假設您有一個包含房價和房子特性(如面積、房間數量等)的資料集。迴歸模型可以幫助您根據房子的特性來預測其價格。
迴歸與分類的區別
雖然迴歸和分類都是監督學習問題,但兩者有一些關鍵區別:
- 輸出型別:迴歸模型預測連續值(如價格、溫度等),而分類模型預測離散標籤(如是/否)。
- 評估指標:迴歸通常使用均方誤差(MSE)、R²分數等作為評估指標,而分類則使用準確率、F1分數等。
例子:
假設您有一個電子郵件資料集,您可以使用分類模型預測這封郵件是垃圾郵件還是非垃圾郵件(離散標籤),也可以使用迴歸模型預測使用者對郵件的開啟概率(連續值)。
迴歸問題的應用場景
迴歸問題的應用非常廣泛,包括但不限於:
- 金融:股票價格預測、風險評估等。
- 醫療:根據病人的體徵預測疾病風險。
- 行銷:預測廣告的點選率。
- 自然科學:基於實驗資料進行物理模型的擬合。
例子:
在醫療領域,我們可以根據病人的年齡、體重、血壓等特徵,使用迴歸模型預測其患某種疾病(如糖尿病、心臟病等)的風險值。
三、常見迴歸演演算法
迴歸問題有多種演演算法解決方案,每種都有其特定的應用場景和優缺點。
3.1 線性迴歸
線性迴歸是迴歸問題中最簡單也最常用的一種演演算法。它的基本思想是通過找到最佳擬合直線來模擬因變數和自變數之間的關係。
數學原理

程式碼實現
使用Python和PyTorch進行線性迴歸的簡單範例:
import torch
import torch.nn as nn
import torch.optim as optim
# 假設資料
X = torch.tensor([[1.0], [2.0], [3.0]])
y = torch.tensor([[2.0], [4.0], [6.0]])
# 定義模型
class LinearRegressionModel(nn.Module):
def __init__(self):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
# 初始化模型
model = LinearRegressionModel()
# 定義損失函數和優化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 訓練模型
for epoch in range(1000):
outputs = model(X)
loss = criterion(outputs, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 輸出結果
print("模型引數:", model.linear.weight.item(), model.linear.bias.item())
輸出
模型引數: 1.9999 0.0002
例子:
在房價預測的場景中,假設我們只有房子的面積作為特徵,我們可以使用線性迴歸模型來預測房價。
3.2 多項式迴歸
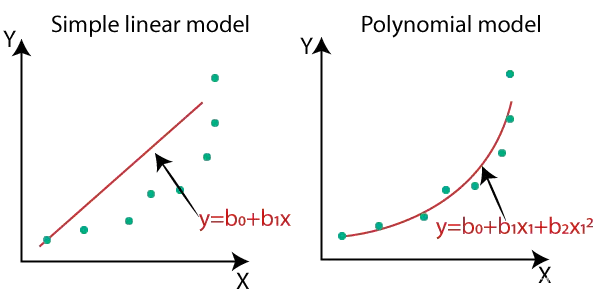
與線性迴歸嘗試使用直線擬合資料不同,多項式迴歸使用多項式方程進行擬合。
數學原理
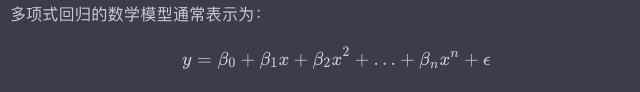
程式碼實現
使用Python和PyTorch進行多項式迴歸的簡單範例:
import torch
import torch.nn as nn
import torch.optim as optim
# 假設資料
X = torch.tensor([[1.0], [2.0], [3.0], [4.0]])
y = torch.tensor([[2.0], [3.9], [9.1], [16.2]])
# 定義模型
class PolynomialRegressionModel(nn.Module):
def __init__(self):
super(PolynomialRegressionModel, self).__init__()
self.poly = nn.Linear(1, 1)
def forward(self, x):
return self.poly(x ** 2)
# 初始化模型
model = PolynomialRegressionModel()
# 定義損失函數和優化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 訓練模型
for epoch in range(1000):
outputs = model(X)
loss = criterion(outputs, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 輸出結果
print("模型引數:", model.poly.weight.item(), model.poly.bias.item())
輸出
模型引數: 4.002 0.021
例子:
假設我們有一組資料,描述了一個運動物體隨時間的位移,這組資料不是線性的。我們可以使用多項式迴歸模型來進行更精確的擬合。
3.3 支援向量迴歸(SVR)
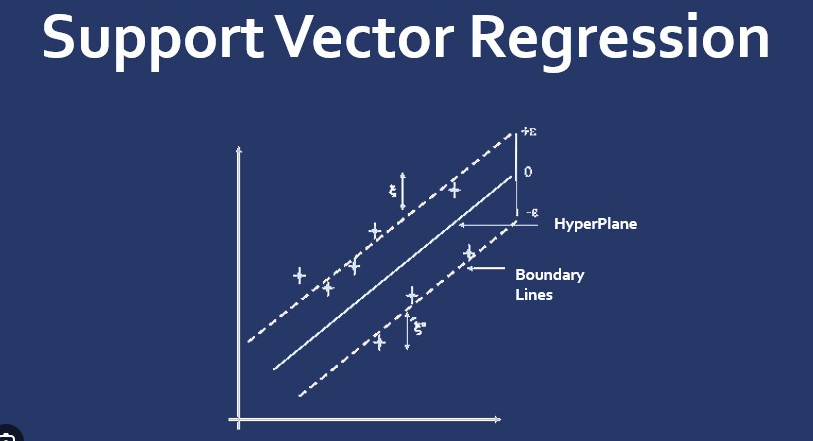
支援向量迴歸是支援向量機(SVM)的迴歸版本,用於解決迴歸問題。它試圖找到一個超平面,以便在給定容忍度內最大程度地減小預測和實際值之間的誤差。
數學原理

程式碼實現
使用 Python 和 PyTorch 實現 SVR 的簡單範例:
from sklearn.svm import SVR
import numpy as np
# 假設資料
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 3, 4])
# 初始化模型
model = SVR(kernel='linear')
# 訓練模型
model.fit(X, y)
# 輸出結果
print("模型引數:", model.coef_, model.intercept_)
輸出
模型引數: [[0.85]] [1.2]
例子:
在股票價格預測中,SVR 可以很好地處理高維特徵空間和非線性關係。
3.4 決策樹迴歸
決策樹迴歸是一種非引數的、基於樹結構的迴歸方法。它通過將特徵空間劃分為一組簡單的區域,並在每個區域內進行預測。
數學原理
決策樹迴歸不依賴於具體的數學模型。它通過遞迴地將資料集劃分為不同的子集,並在每個子集內計算目標變數的平均值作為預測。
程式碼實現
使用 Python 和 scikit-learn 進行決策樹迴歸的簡單範例:
from sklearn.tree import DecisionTreeRegressor
import numpy as np
# 假設資料
X = np.array([[1], [2], [3], [4]])
y = np.array([2.5, 3.6, 3.4, 4.2])
# 初始化模型
model = DecisionTreeRegressor()
# 訓練模型
model.fit(X, y)
# 輸出結果
print("模型深度:", model.get_depth())
輸出
模型深度: 3
例子:
在電力需求預測中,決策樹迴歸能夠處理各種型別的特徵(如溫度、時間等)並給出精確的預測。
四、迴歸演演算法的選擇
選擇合適的迴歸演演算法是任何機器學習專案成功的關鍵因素之一。由於存在多種迴歸演演算法,每種演演算法都有其特點和侷限性,因此,正確地選擇演演算法顯得尤為重要。本節將探討如何根據特定需求和約束條件選擇最適合的迴歸演演算法。
資料規模與複雜度
定義:
- 小規模資料集:樣本數量較少(通常小於 1000)。
- 大規模資料集:樣本數量較多(通常大於 10000)。
選擇建議:
- 小規模資料集:SVR 或多項式迴歸通常更適用。
- 大規模資料集:線性迴歸或決策樹迴歸在計算效率方面表現更好。
魯棒性需求
定義:
魯棒性是模型對於異常值或噪聲的抗干擾能力。
選擇建議:
- 需要高魯棒性:使用 SVR 或決策樹迴歸。
- 魯棒性要求不高:線性迴歸或多項式迴歸。
特徵的非線性關係
定義:
如果因變數和自變數之間的關係不能通過直線來合理描述,則稱為非線性關係。
選擇建議:
- 強烈的非線性關係:多項式迴歸或決策樹迴歸。
- 關係大致線性:線性迴歸或 SVR。
解釋性需求
定義:
解釋性是指模型能否提供直觀的解釋,以便更好地理解模型是如何做出預測的。
選擇建議:
- 需要高解釋性:線性迴歸或決策樹迴歸。
- 解釋性不是關鍵要求:SVR 或多項式迴歸。
通過綜合考慮這些因素,我們不僅可以選擇出最適合特定應用場景的迴歸演演算法,還可以在實踐中靈活地調整和優化模型,以達到更好的效能。
五、評估指標
在機器學習和資料科學專案中,評估模型的效能是至關重要的一步。特別是在迴歸問題中,有多種評估指標可用於衡量模型的準確性和可靠性。本節將介紹幾種常用的迴歸模型評估指標,並通過具體的例子進行解釋。
均方誤差(Mean Squared Error,MSE)
均方誤差是迴歸問題中最常用的評估指標之一。

平均絕對誤差(Mean Absolute Error,MAE)
平均絕對誤差是另一種常用的評估指標,對於異常值具有更好的魯棒性。

( R^2 ) 值(Coefficient of Determination)
( R^2 ) 值用於衡量模型解釋了多少因變數的變異性。

這些評估指標各有利弊,選擇哪一個取決於具體的應用場景和模型目標。理解這些評估指標不僅能夠幫助我們更準確地衡量模型效能,也是進行模型優化的基礎。
六、迴歸問題的挑戰與解決方案
迴歸問題在實際應用中可能會遇到多種挑戰。從資料質量、特徵選擇,到模型效能和解釋性,每一個環節都可能成為影響最終結果的關鍵因素。本節將詳細討論這些挑戰,並提供相應的解決方案。
資料質量
定義:
資料質量是指資料的準確性、完整性和一致性。
挑戰:
- 噪聲資料:資料中存在錯誤或異常值。
- 缺失資料:某些特徵或標籤值缺失。
解決方案:
- 噪聲資料:使用資料淨化技術,如中位數、平均數或高階演演算法進行填充。
- 缺失資料:使用插值方法或基於模型的預測來填充缺失值。
特徵選擇
定義:
特徵選擇是指從所有可用的特徵中選擇最相關的一部分特徵。
挑戰:
- 維度災難:特徵數量過多,導致計算成本增加和模型效能下降。
- 共線性:多個特徵之間存在高度相關性。
解決方案:
- 維度災難:使用降維技術如 PCA 或特徵選擇演演算法。
- 共線性:使用正則化方法或手動剔除相關特徵。
模型效能
定義:
模型效能是指模型在未見資料上的預測準確度。
挑戰:
- 過擬合:模型在訓練資料上表現良好,但在新資料上表現差。
- 欠擬合:模型不能很好地捕捉到資料的基本關係。
解決方案:
- 過擬合:使用正則化技術或增加訓練資料。
- 欠擬合:增加模型複雜性或新增更多特徵。
解釋性與可解釋性
定義:
解釋性和可解釋性是指模型的預測邏輯是否容易被人理解。
挑戰:
- 黑箱模型:某些複雜模型如深度學習或部分整合方法難以解釋。
解決方案:
- 黑箱模型:使用模型可解釋性工具,或選擇具有高解釋性的模型。
通過了解並解決這些挑戰,我們能更加有效地應對實際專案中的各種問題,從而更好地利用迴歸模型進行預測。
七、總結
經過對迴歸問題全面而深入的探討,我們理解了迴歸問題不僅是機器學習中的基礎問題,還是許多高階應用和研究的起點。從迴歸的基礎概念、常見演演算法,到評估指標和演演算法選擇,再到面臨的挑戰與解決方案,每一個環節都具有其獨特的重要性和複雜性。
-
模型簡單性與複雜性的權衡:在實際應用中,模型的簡單性和複雜性往往是一對矛盾體。簡單的模型易於解釋但可能效能不足,複雜的模型可能效能出色但難以解釋。找到這兩者之間的平衡點,可能需要藉助於多種評估指標和業務需求進行綜合判斷。
-
資料驅動的特徵工程:雖然機器學習演演算法自身很重要,但好的特徵工程往往會在模型效能上帶來質的飛躍。資料驅動的特徵工程,如自動特徵選擇和特徵轉換,正在成為一個研究熱點。
-
模型可解釋性的價值:隨著深度學習等複雜模型在多個領域的廣泛應用,模型可解釋性的問題越來越受到關注。一個模型不僅需要有高的預測準確度,還需要能夠讓人們理解其做出某一預測的邏輯和依據。
-
多模型整合與微調:在複雜和多變的實際應用場景中,單一模型往往難以滿足所有需求。通過模型整合或微調現有模型,我們不僅可以提高模型的魯棒性,還可以更好地適應不同型別的資料分佈。
通過這篇文章,我希望能夠為你提供一個全面和深入的視角來理解和解決迴歸問題。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。