🔥🔥Java開發者的Python快速實戰指南:探索向量資料庫之文字搜尋
前言
如果說Python是跟隨我的步伐學習的話,我覺得我在日常開發方面已經沒有太大的問題了。然而,由於我沒有Python開發經驗,我思考著應該寫些什麼內容。我回想起學習Java時的學習路線,直接運算元據庫是其中一項重要內容,無論使用哪種程式語言,與資料庫的互動都是不可避免的。然而,直接操作MySQL資料庫似乎缺乏趣味性,畢竟每天都在寫SQL語句。突然我想到了我之前寫過的一系列私人知識庫文章,於是我想到了向量資料庫,畢竟這是當前非常熱門的技術之一。
如果AI離開了向量資料庫,就好像失去了靈魂一樣。市面上有很多向量資料庫產品,我選擇了最近騰訊推出的向量資料庫,並且我還有一張免費試用卡,趁著還沒過期,我決定寫一些相關文章。而且我看了一下,這個資料庫對於新手來說非常友好,因為它有視覺化介面。對於一個新手來說,能夠看到實際效果是最客觀的。就像當初學習SQL時,如果沒有Navicat這個視覺化工具,就會感覺力不從心一樣。
向量資料庫
向量資料庫具有將複雜的非結構化資料轉化為多維邏輯座標值的能力,簡而言之,它可以將我們所瞭解的所有事物轉化為可計算的數位。一旦資料進入數學領域,我們就能夠對其進行計算。此外,向量資料庫還可以作為一個外部知識庫,為大型模型提供最新、最全面的資訊,以應對需要及時回答的問題。同時,它也能夠賦予大型語言模型長期記憶的能力,避免在對話過程中產生"斷片"的情況。可以說,向量資料庫是大型語言模型的最佳合作伙伴。
如果你對任何內容有任何疑問,請點選以下官方檔案連結檢視更多資訊:https://img-bss.csdnimg.cn/1113tusoutuanli.pdf
雖然這是官方的檔案,裡面存在許多錯誤,我已經積極提供了反饋,但可惜沒有得到有效處理。儘管如此,這並不會妨礙我們的閱讀。檔案最後還有一個官方的案例程式碼倉庫,對於有興趣的同學可以直接滑動到最後進行查閱。不過,對於新手而言,可能並不太友好,原因在於程式碼量較大,很難一下子消化。就好比剛學習Java的時候,要看別人的業務邏輯一樣,即使有大量註釋,也會感到吃力。
好的,廢話不多說,我們直接進入正題吧。如果你還有未領取的,可以免費領取一下。
騰訊官方體驗地址:https://cloud.tencent.com/product/vdb
建立資料庫連線
領取完畢後,你需要建立一個新的免費範例,這個過程不難,大家都會。成功之後,你需要開啟外網存取,否則無法進行原生的測試和聯調。在開啟外網存取時,需要將外網白名單ip設定為0.0.0.0/0,這將接受所有IP的請求。

好的,接下來我們需要獲取資料庫的登入名和密碼。這些資訊將用於連線和管理資料庫。

建立資料庫
import tcvectordb
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency
#create a database client object
client = tcvectordb.VectorDBClient(url='http://*******', username='root', key='1*******', read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
# create a database
db = client.create_database(database_name='db-xiaoyu')
print(db.database_name)
# list databases
db_list = client.list_databases()
for db in db_list:
print(db.database_name)
好的,我們現在開始替換所需的內容,完成資料庫的建立。一旦資料庫建立完成,我們還需要建立集合,而不是傳統的表,因為在向量資料庫中,它們被稱為集合。因此,我們接下來要建立集合。
建立集合
建立集合和建立表的過程類似,但前提是集合需要儲存向量,而表用於儲存資料。在這裡,我們選擇使用整合了embedding的集合。如果不使用整合的embedding,你需要使用其他embedding模型來輸出向量,然後將其輸入到集合中進行儲存。除非你想手動輸入向量值,否則這是必要的。
設計索引(不是設計 Collection 的結構)
在使用向量對應的文字欄位時,不建議建立索引。這樣做會佔用大量記憶體資源,而且沒有實際作用。除了向量對應的文字欄位外,如果需要進行業務過濾,也就是在查詢時需要使用where條件,那麼必須單獨為這個條件欄位定義一個索引。也就是說,你需要用哪個欄位進行過濾,就必須為該欄位定義一個索引。向量資料庫支援動態模式(Schema),在寫入資料時可以寫入任意欄位,無需提前定義,類似於MongoDB。目前,主鍵id和向量欄位vector是固定且必需的,欄位名稱也必須一致,否則會報錯。
在之前講解私人知識庫的時候,我會單獨引入其他embedding模型,因為向量資料庫沒有繼承這些模型。不過,騰訊已經將embedding模型整合在了他們的系統中,這樣就不需要來回尋找模型了。需要注意的是,為了確保一致性,你選擇的embedding模型後面的vector欄位要設定為768維。
db = client.database('db-xiaoyu')
# -- index config
index = Index(
FilterIndex(name='id', field_type=FieldType.String, index_type=IndexType.PRIMARY_KEY),
VectorIndex(name='vector', dimension=768, index_type=IndexType.HNSW,
metric_type=MetricType.COSINE, params=HNSWParams(m=16, efconstruction=200)),
FilterIndex(name='author', field_type=FieldType.String, index_type=IndexType.FILTER),
FilterIndex(name='bookName', field_type=FieldType.String, index_type=IndexType.FILTER)
)
# Embedding config
ebd = Embedding(vector_field='vector', field='text', model=EmbeddingModel.BGE_BASE_ZH)
# create a collection
coll = db.create_collection(
name='book-xiaoyu',
shard=1,
replicas=0,
description='this is a collection of test embedding',
embedding=ebd,
index=index
)
print(vars(coll))
我們已經成功建立了資料庫和集合,並且現在讓我們來看一下它們的結構。實際上,它們的原理與MySQL和其他資料庫相似,只是儲存的內容和術語發生了變化。我們可以將其視為資料庫操作。
插入/替換資料
當插入資料時,如果集合中已經存在具有相同ID的檔案,則會刪除原始檔案並插入新的檔案資料。需要注意的是,很多欄位我們都沒有指定,例如page、text等。你可以繼續新增這些欄位,因為它們類似於MongoDB。但請注意,text欄位必須與你在設定embedding時指定的欄位相同,否則無法將其轉換為向量。
coll = db.collection('book-emb')
# 寫入資料。
# 引數 build_index 為 True,指寫入資料同時重新建立索引。
res = coll.upsert(
documents=[
Document(id='0001', text="話說天下大勢,分久必合,合久必分。", author='羅貫中', bookName='三國演義', page=21),
Document(id='0002', text="混沌未分天地亂,茫茫渺渺無人間。", author='吳承恩', bookName='西遊記', page=22),
Document(id='0003', text="甄士隱夢幻識通靈,賈雨村風塵懷閨秀。", author='曹雪芹', bookName='紅樓夢', page=23)
],
build_index=True
)
當我們完成資料插入後,我們可以立即執行查詢操作。但請注意,如果你將 "build_index" 欄位設定為 "false",即使插入成功,查詢時也無法檢索到資料。因此,如果要立即生效並能查詢到資料,你必須將其設定為 "true"。這個是重建索引的過程
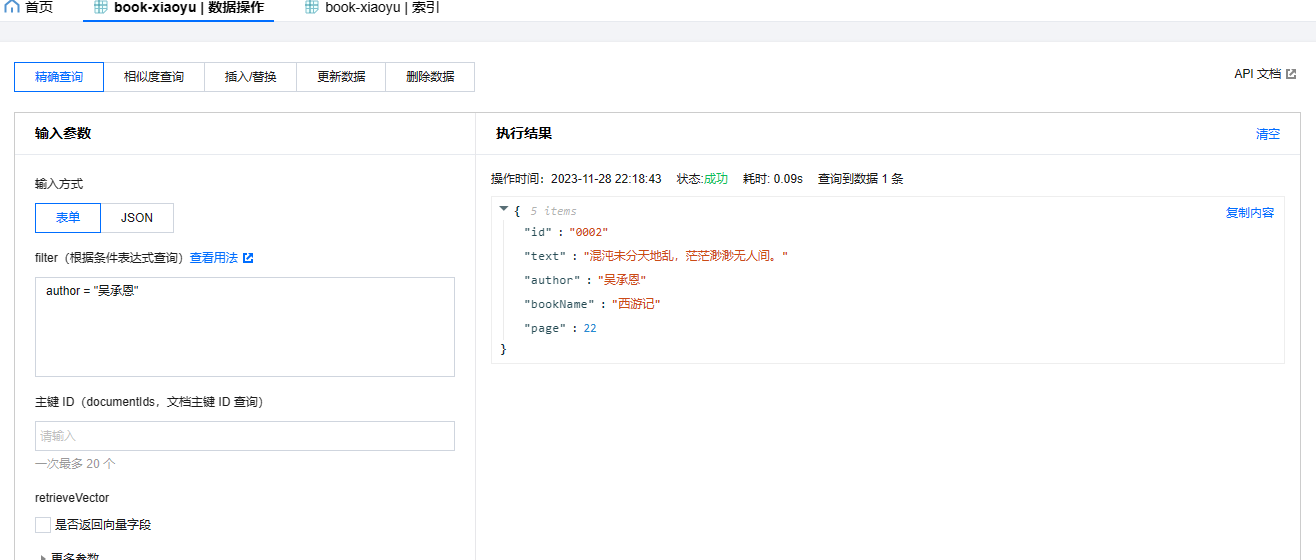
查詢資料
這裡的查詢可以分為精確查詢和相似度查詢兩種。精確查詢是指除了向量欄位外的其他欄位查詢條件都是精確匹配的。由於我們在建立索引時已經對作者(author)和書名(bookName)建立了索引,所以我們可以直接對它們進行資料過濾,但是我不會在這裡演示。現在我將演示一下模糊查詢,即對向量欄位匹配後的結果進行查詢,並同時加上過濾條件。
doc_lists = coll.searchByText(
embeddingItems=['天下大勢,分久必合,合久必分'],
filter=Filter(Filter.In("bookName", ["三國演義", "西遊記"])),
params=SearchParams(ef=200),
limit=3,
retrieve_vector=False, # 不返回向量
output_fields=['bookName','author']
)
# printf
for i, docs in enumerate(doc_lists.get("documents")):
for doc in docs:
print(doc)
除了上面提到的Python的寫法,我們還可以通過介面來進行精確查詢。只需要在介面中填寫where後的條件即可。
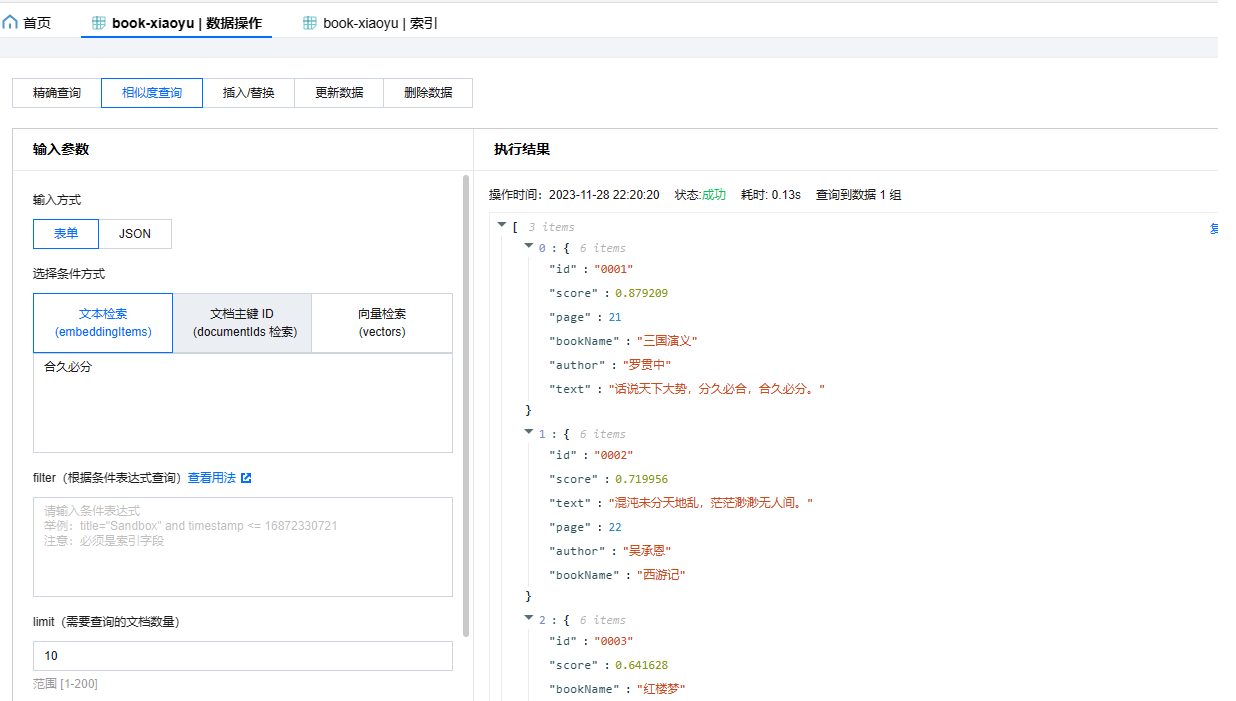
要進行模糊查詢,可以直接使用text文字進行查詢,或者定義過濾欄位來進行查詢優化。
總結
剩下的刪除資料這部分我就不演示了。今天先跟向量資料庫熟悉一下介面操作,感覺就像在使用Kibana查詢ES資料一樣。不知道你們有沒有類似的感覺。好了,今天我們先只關注文字操作,下一期我會嘗試處理影象或者視訊資料。總的來說,相比Java,Python的SDK使用起來更加舒適。如果你曾經使用過Java SDK與平臺介面對接,就會發現Python SDK上手更快。