聊聊分散式 SQL 資料庫Doris(八)
稀疏索引
密集索引:檔案中的每個搜尋碼值都對應一個索引值,就是葉子節點儲存了整行.
稀疏索引:檔案只為索引碼的某些值建立索引項.
稀疏索引的建立過程包括將集合中的元素分段,並給每個分段中的最小元素建立索引。在搜尋時,先定位到第一個大於搜尋值的索引的前一個索引,然後從該索引所在的分段中從前向後順序遍歷,直到找到該搜尋值的元素或第一個大於該搜尋值的元素。
Doris中的字首索引、Bloom Filter屬於稀疏索引.
以mysql為例,主鍵索引是稠密索引; 非主鍵索引(非聚簇索引)是稀疏索引. 如下是mysql的B+樹索引結構圖.
主鍵索引, 注意葉子節點的主鍵值時有序的.
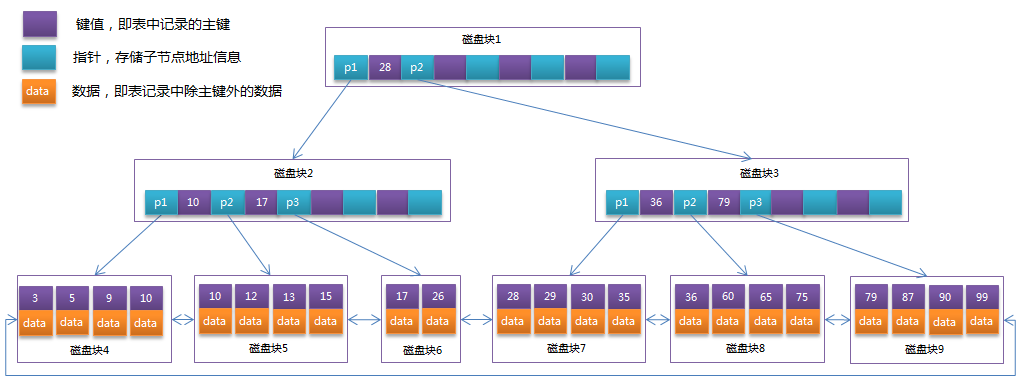
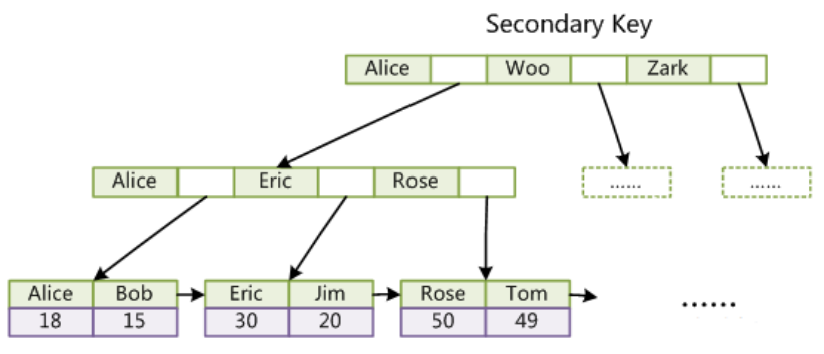
非主鍵索引
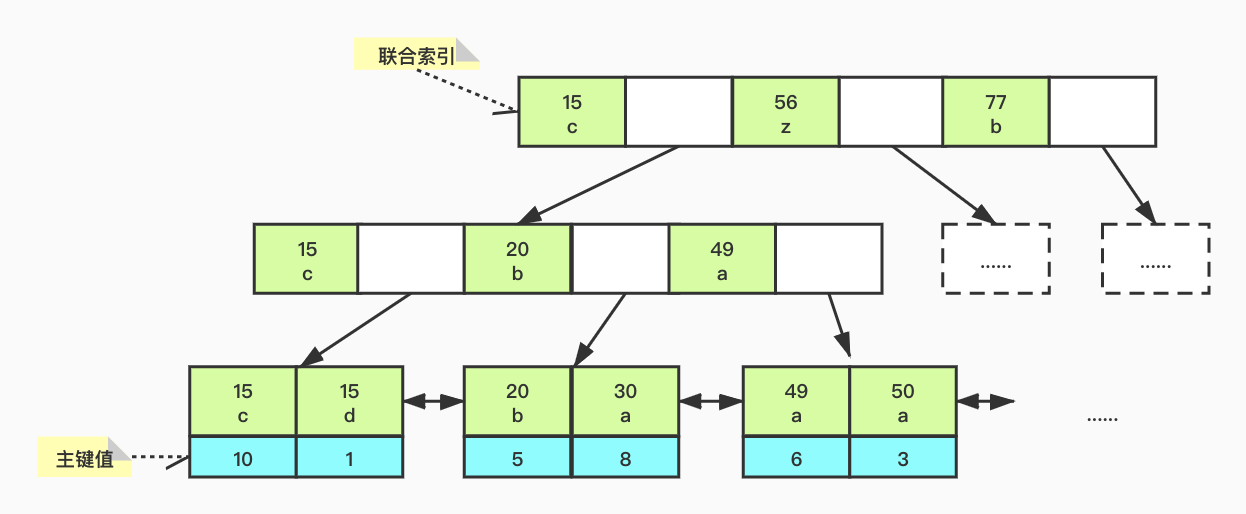
聯合索引
稀疏索引佔用空間少,但是在查詢的精確率上還是相對於稠密索引還是比較慢的,因為不需要順序查詢,還有回表。
稠密索引那就是相對來說比較快,因為他可以精確定位資料,但是佔用的空間比較大。
參考:
delete
delete: 本質上是儲存了一個刪除條件,在查詢時會對每一行記錄應用這個刪除條件做過濾,因此當有大量刪除條件時,查詢效率就會降低。
批次刪除: 僅適用於 UNIQUE KEY 模型,解決了delete大批次資料的效能問題; Doris內部會增加一個隱藏列__DORIS_DELETE_SIGN__. 該列的型別為bool,聚合函數為replace. 在匯入與讀取時,增加隱藏列的判斷,篩選過濾掉不必要的資料.
參考:
更新
Doris中儲存的資料都是以追加(Append)的方式進入系統,這意味著所有已寫入的資料是不可變更(immutable)的。所以Doris採用標記的方式來實現資料更新的目的; 利用查詢引擎自身的 where 過濾邏輯,從待更新表中篩選出需要被更新(被標記)的行。再利用 Unique 模型自帶的 Value 列新資料替換舊資料的邏輯,將待更新的行變更後,再重新插入到表中,從而實現行級別更新。
適用場景
- 對滿足某些條件的行,修改其取值;
- 點更新,小範圍更新,待更新的行最好是整個表的非常小的一部分;因為大批次資料下整行更新,會導致效能較低。
- update 命令只能在 Unique 資料模型的表中執行;因為只有該模型可以保證主鍵的唯一性,從而支援按主鍵對資料進行更新。
假設 Doris 中存在一張訂單表,其中 訂單id 是 Key 列,訂單狀態,訂單金額是 Value 列。資料狀態如下:
| 訂單 | 訂單金額 | 訂單狀態 |
|---|---|---|
| 1 | 100 | 待付款 |
這時候,使用者點選付款後,Doris 系統需要將訂單id 為 '1' 的訂單狀態變更為 '待發貨',就需要用到 Update 功能。
UPDATE test_order SET order_status = '待發貨' WHERE order_id = 1;
更新結果如下:
| 訂單 | 訂單金額 | 訂單狀態 |
|---|---|---|
| 1 | 100 | 待發貨 |
使用者執行 UPDATE 命令後,系統會進行如下三步:
-
第一步:讀取滿足 WHERE 訂單id=1 的行 (1,100,'待付款')
-
第二步:變更該行的訂單狀態,從'待付款'改為'待發貨' (1,100,'待發貨')
-
第三步:將更新後的行再插入原表中,從而達到更新的效果。
| 訂單 | 訂單金額 | 訂單狀態 |
|---|---|---|
| 1 | 100 | 待付款 |
| 1 | 100 | 待發貨 |
由於表 test_order 是 UNIQUE 模型,所以相同 Key 的行,之後後者才會生效,所以最終效果如下:
| 訂單 | 訂單金額 | 訂單狀態 |
|---|---|---|
| 1 | 100 | 待發貨 |
部分列更新
Doris預設的更新是行更新. 列更新可以很大程度上提高寫入與並行效能.
Unique Key模型的Merge-on-Write結合MVCC支援部分列更新.
Aggregate Key模型將聚合函數設定為REPLACE_IF_NOT_NULL支援部分列更新.
更新原理
Unique Key模型的列更新實現:使用者通過正常的匯入方式將一部分列的資料寫入Doris的Memtable,此時Memtable中並沒有整行資料,在Memtable下刷的時候,會查詢歷史資料,用歷史資料補齊一整行,並寫入資料檔案中,同時將歷史資料檔案中相同key的資料行標記刪除。
Aggregate Key模型,則是直接利用聚合函數篩選過濾。
使用建議:
- 對寫入效能要求較高,查詢效能要求較低的使用者,建議使用Aggregate Key模型
- 對查詢效能要求較高,對寫入效能要求不高(例如資料的寫入和更新基本都在凌晨低峰期完成),或者寫入頻率不高的使用者,建議使用Unique Key模型merge-on-write實現
參考: