Netty原始碼學習6——netty編碼解碼器&粘包半包問題的解決
零丶引入
經過《Netty原始碼學習4——伺服器端是處理新連線的&netty的reactor模式和《Netty原始碼學習5——伺服器端是如何讀取資料的》的學習,我們瞭解了伺服器端是如何處理新連線並讀取使用者端傳送的資料的:
- netty的reactor:主reactor中的NioEventLoop監聽accept事件,然後呼叫NioServerSocketChannel#Unsafe讀取資料——依賴JDK ServerSockectChannel#accept,獲取到新連線——SockectChannel後,會包裝為NioSocketChannel然後呼叫channelRead,隨後ServerBootstrapAcceptor 會負載均衡的選擇一個子reactor 註冊NioSocketChannel對read事件感興趣
- read事件:子reactor中的NioEventLoop會監聽read事件,呼叫NioSocketChannel讀取使用者端傳送資料(依賴JDK SocketChannel#read(ByteBuffer)),netty會使用ByteBufAllocator優化ByteBuf的分配,使用AdaptiveRecvByteBufAllocator對ByteBuf進行擴容縮容,以及控制是否繼續讀取。
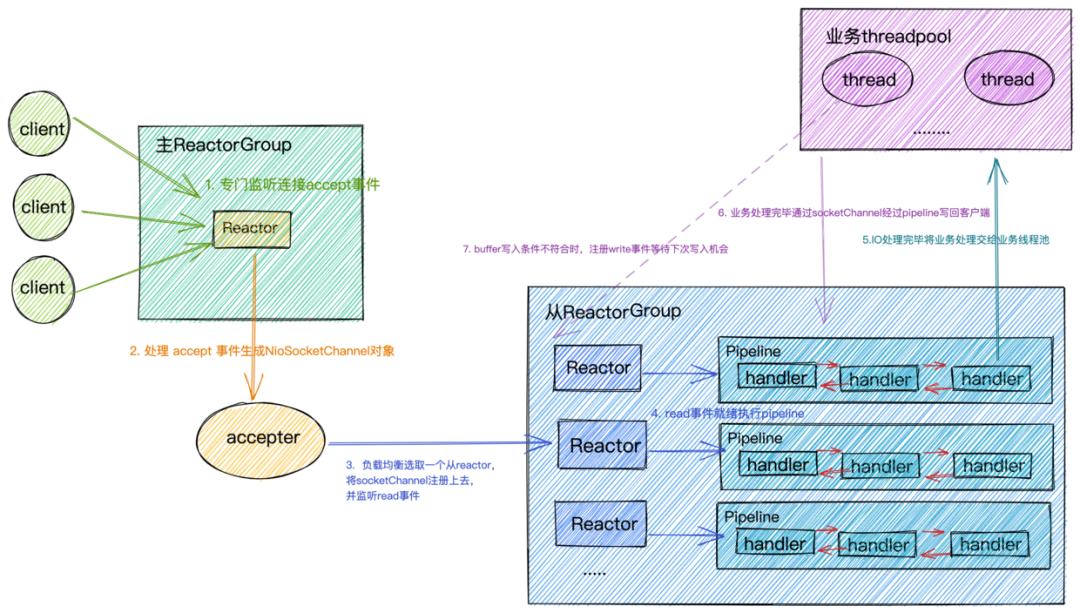
——至此資料以及讀取到了ByteBuf中,伺服器端需要先解碼ByteBuf中的資料,然後我們業務處理器才能根據傳送的訊息進行響應,業務執行結果還需要進行編碼才能傳送,so 這一篇和大家一起學習以下Netty中的編碼解碼。
一丶看看其他開源框架是如何使用Netty的編碼解碼的
1.Dubbo
Apache Dubbo 是一款 RPC 服務開發框架,用於解決微服務架構下的服務治理與通訊問題,使用 Dubbo 開發的微服務原生具備相互之間的遠端地址發現與通訊能力, 利用 Dubbo 提供的豐富服務治理特性,可以實現諸如服務發現、負載均衡、流量排程等服務治理訴求。
Dubbo 中的網路通訊可以基於Netty,Dubbo 官方原始碼如下
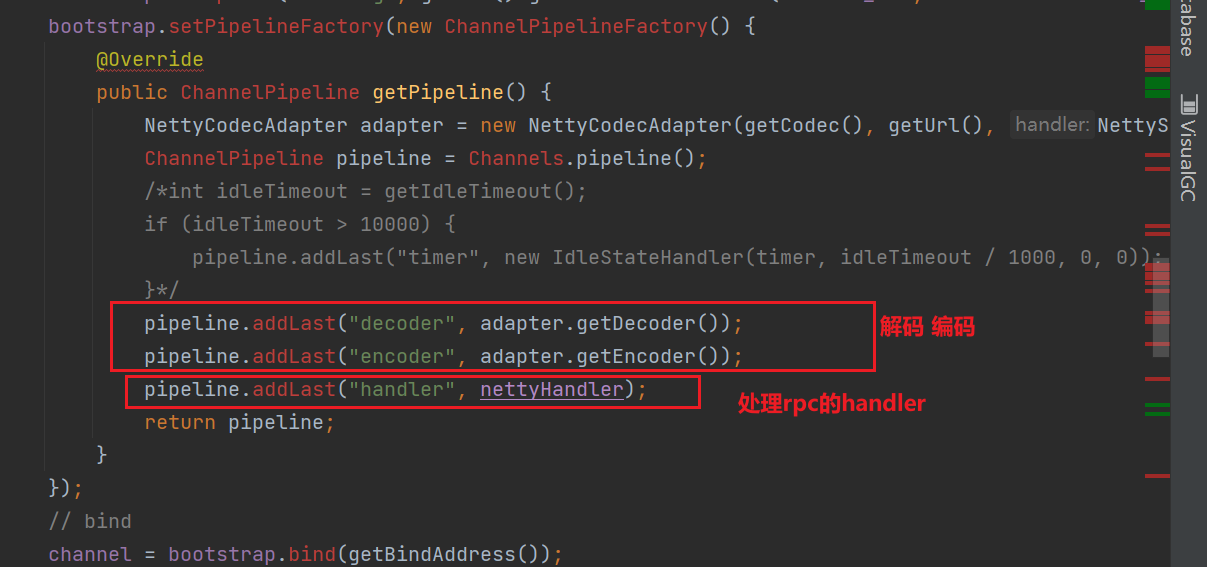
可以看到Dubbo會向ChannelPipeline中加入decoder和encoder,負責編碼解碼。
2.Sentinel
Sentinel 是面向分散式、多語言異構化服務架構的流量治理元件,主要以流量為切入點,從流量路由、流量控制、流量整形、熔斷降級、系統自適應過載保護、熱點流量防護等多個維度來幫助開發者保障微服務的穩定性。(詳細學習:《Sentinel基本使用與原始碼分析》)
sentinel提供了叢集限流的能力,本質是伺服器端控制令牌的下發,使用者端通過網路通訊申請令牌,如下是叢集限流中,使用netty實現伺服器端的原始碼:
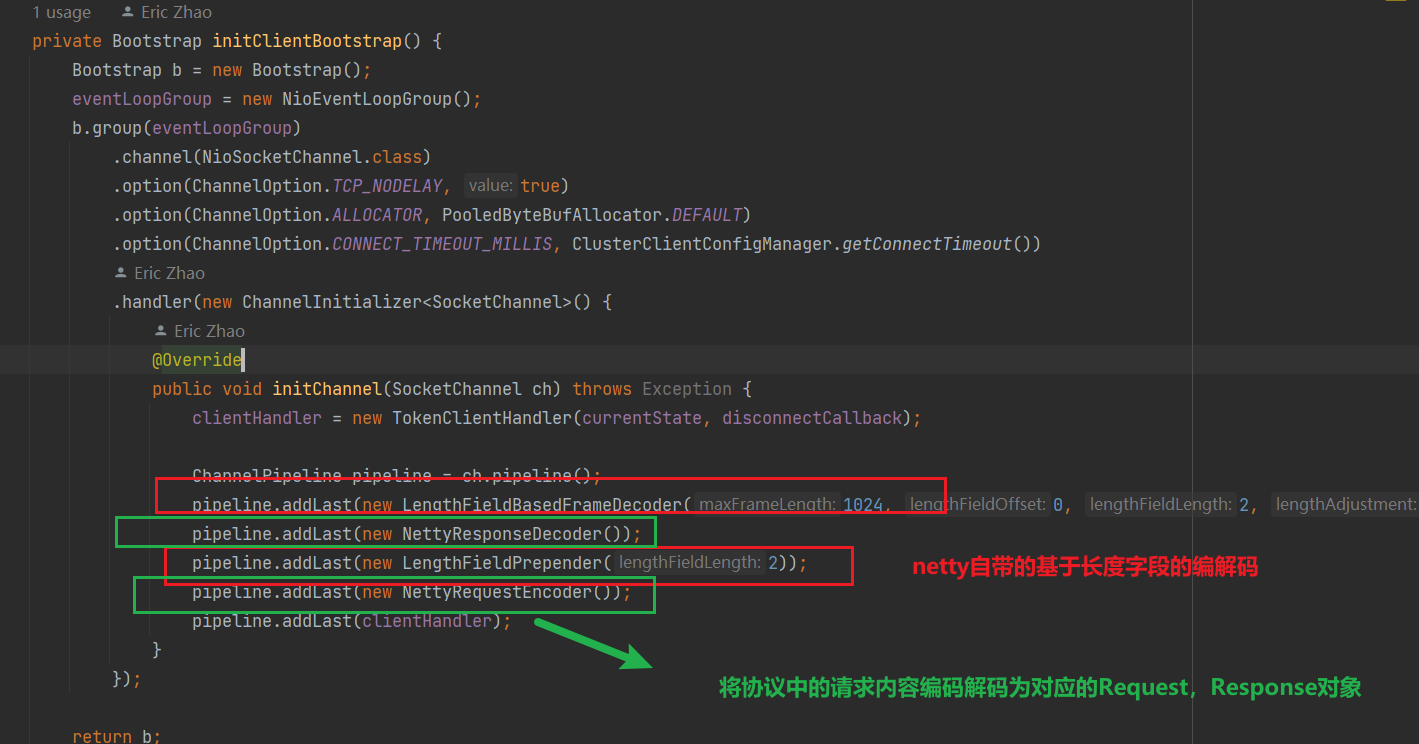
可以看到sentinel叢集限流會向ChannelPipeline中增加
-
LengthFieldBasedFrameDecoder:基於長度欄位的解碼器——一級解碼器,根據frame中的長度欄位,解碼出訊息
-
NettyRequestDecoder:請求解碼器——二次解碼器,將一次解碼器解碼出的訊息,反序列化為請求物件
-
LengthFieldPrepender:長度放在frame頭部的編碼器,將伺服器端響應的訊息新增上長度資訊
-
NettyResponseEncoder:將伺服器端處理返回的java物件,編碼成ByteBuf
3.對比Dubbo和Sentinel對netty的使用
相比於Sentinel,Dubbo的使用更加簡潔,直接將編碼解碼的邏輯封裝到自己的adapter之中
Sentinel的使用也是非常標準,也利於我們理解netty的編解碼執行機制——即編碼解碼其實是ChannelHandler的一種實現,通過將編碼解碼加入到ChannelPipline中實現資料的逐環處理。
二丶什麼是編碼,解碼器,為什麼需要編碼解碼器
netty中的編碼解碼器是負責將應用程式的資料格式轉換為可以在網路中傳輸的位元組流,以及將接收到的位元組流轉換回為應用程式可以處理的資料格式的元件。編解碼器是網路通訊的關鍵元件,因為它們抽象掉了網路層和應用層之間的複雜轉換細節。
主要作用有:
-
資料序列化與反序列化:
- 編碼(序列化):將應用資料結構(如物件、訊息)轉換成位元組流,以便能夠通過網路傳送。
- 解碼(反序列化):將網路中接收到的位元組流轉換回應用資料結構。
-
協定實現:
編解碼器實現了網路通訊中所需遵守的特定協定規則,如 HTTP、WebSocket,SMTP。
它們確保資料符合協定格式,並能夠正確地被傳送和接收方理解。
處理流控制問題: -
對於面向流的協定(如 TCP),解決粘包和半包等問題,確保資料的完整性。
-
解耦應用與網路層&擴充套件性與靈活性:
編解碼器允許開發者專注於業務邏輯,而無需關心底層的位元組處理。應用邏輯可以與網路傳輸邏輯分離,使得程式碼更加清晰和可維護。
應用開發者也可以隨機的切換不同的編碼解碼器,提升擴充套件性和靈活性。
三丶Netty解決tcp粘包,半包的編解碼器
1.tcp是基於流的協定&為什麼會出現粘包,半包
TCP 傳輸的資料被視為一個連續的、無邊界的位元組流。網路上的兩個應用程式通過建立一個 TCP 連線來交換資料,而這個資料流就像是從一個地方倒水到另一個地方,水(資料)會連續不斷地流動,而不是一杯一杯分開倒(即不像獨立的訊息或封包)。
-
TCP 資料傳送:
當應用程式要傳送資料時,它會
將資料寫入到 TCP 通訊端的傳送緩衝區。這個寫入操作通常是通過像 write() 或 send() 這樣的系統呼叫完成的。TCP 協定會從傳送緩衝區中取出資料,
並將資料分割成合適大小的段,此大小受多個因素影響,包括最大傳輸單元(MTU)和網路擁塞視窗(congestion window)。然後,TCP 將每個段封裝在一個 TCP 封包中,並加上 TCP 頭部,其中包含序列號等資訊,再將封包傳送到網路中。這裡的關鍵點是,
TCP 不關心應用程式傳遞給它的資料是一條訊息還是多條訊息,它只是簡單地將這些資料作為位元組序列處理。因此,即使應用程式以多個 write() 呼叫傳送多條訊息,TCP 仍可能將它們合併成一個封包傳送,這就可能導致粘包問題。 -
TCP 資料接收:
在接收端,
TCP 封包到達後,TCP 協定會解析 TCP 頭部資訊,並根據序列號將資料放入接收緩衝區中的正確位置。接收端的應用程式通過 read() 或 recv() 等系統呼叫從 TCP 通訊端的接收緩衝區中讀取資料。這裡也是不考慮訊息邊界的,應用程式可能一次讀取任意大小的資料,這可能導致一次讀取操作包含了多條訊息(粘包),或只有部分訊息(半包)。
2.netty是怎麼解決粘包,半包問題的
解決粘包,半包問題的關係,是如何分辨那一部分是一條完整的訊息。
Netty 通過提供一系列編解碼器(Decoder 和 Encoder)來解決 TCP 粘包和半包問題。這些編解碼器位於 Netty 的管道(ChannelPipeline)中,它們對進出的資料流進行處理,確保資料的完整性和邊界的正確性。
-
FixedLengthFrameDecoder:
這個解碼器按照固定的長度對接收到的資料進行分割。如果傳送的資料小於固定長度,那麼傳送方需要進行填充。
-
LineBasedFrameDecoder:
這個解碼器基於換行符(\n 或 \r\n)拆分資料流。它適用於文字協定,如 SMTP 或 POP3。 -
DelimiterBasedFrameDecoder:
這個解碼器根據指定的分隔符來拆分資料流。分隔符可以是任意的位元組序列,如特定的字元或者字串。 -
LengthFieldBasedFrameDecoder:
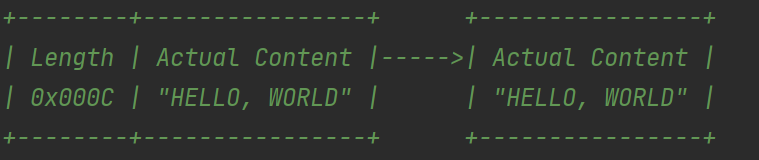
這是一個更加通用和靈活的解碼器,它基於訊息頭的長度欄位來確定每個訊息的長度。傳送方在訊息頭中指定了訊息體的長度,接收方通過解碼器讀取指定長度的資料,從而確保完整性。 -
LengthFieldPrepender:
這個編碼器在傳送訊息的前面新增長度欄位,與 LengthFieldBasedFrameDecoder 配合使用,可確保粘包和半包問題不會發生
3.原始碼學習
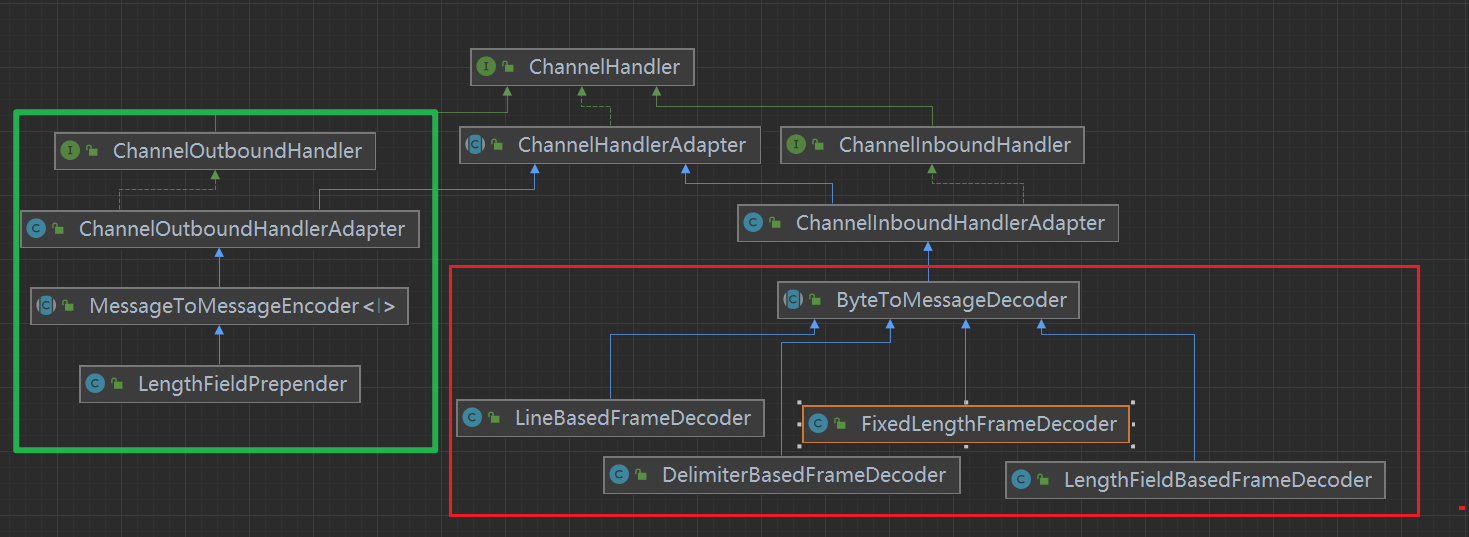
可以看到解碼器都是ByteToMessageDecoder的子類,編碼器只有LengthFieldPrepender是MessageToMessageEncoder的子類(和LengthFieldBasedFrameDecoder是一對)
3.1 ByteToMessageDecoder
以類似流的方式將位元組從一個ByteBuf解碼為另一個訊息型別,是一個ChannelInboundHandler,意味著可以處理入站事件
其中最關鍵的是channelRead方法
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
// 只處理ByteBuf型別
if (msg instanceof ByteBuf) {
selfFiredChannelRead = true;
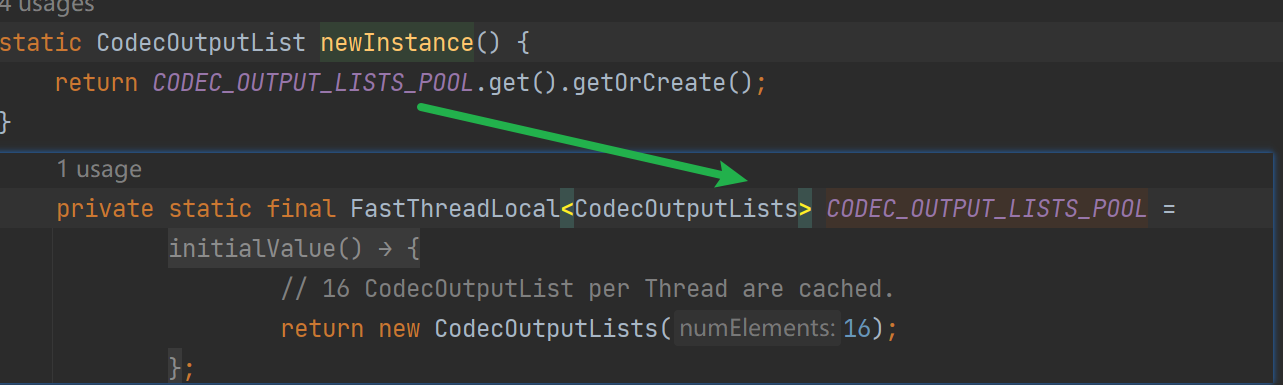
// List的一種實現 clear方法不會清空內容,recycle方法會清空
// newInstance方法使用FastThreadLocal快取已有物件,避免重複構造
CodecOutputList out = CodecOutputList.newInstance();
try {
first = cumulation == null;
// cumulation累積器 ,第一次會把傳入的byteBuf和空buf累計
// 後續會和原有的內容進行累計
cumulation = cumulator.cumulate(ctx.alloc(),
first ? Unpooled.EMPTY_BUFFER : cumulation, (ByteBuf) msg);
// 呼叫子類進行解碼
callDecode(ctx, cumulation, out);
} catch (DecoderException e) {
throw e;
} catch (Exception e) {
throw new DecoderException(e);
} finally {
try {
// 省略資源釋放部分
int size = out.size();
firedChannelRead |= out.insertSinceRecycled();
// 編碼後內容觸發channelRead
fireChannelRead(ctx, out, size);
} finally {
// 釋放資源
out.recycle();
}
}
} else {
// 只處理ByteBuf型別
ctx.fireChannelRead(msg);
}
}
-
netty使用了CodecOutputList來記錄解碼生成的內容,也就是說子類實現decode方法時,如果得到了完整的訊息,需要將訊息加入到CodecOutputList中,CodecOutputList#newInstance是從FastThreadLocal中獲取的,執行緒安全,每一個執行緒進行復用
-
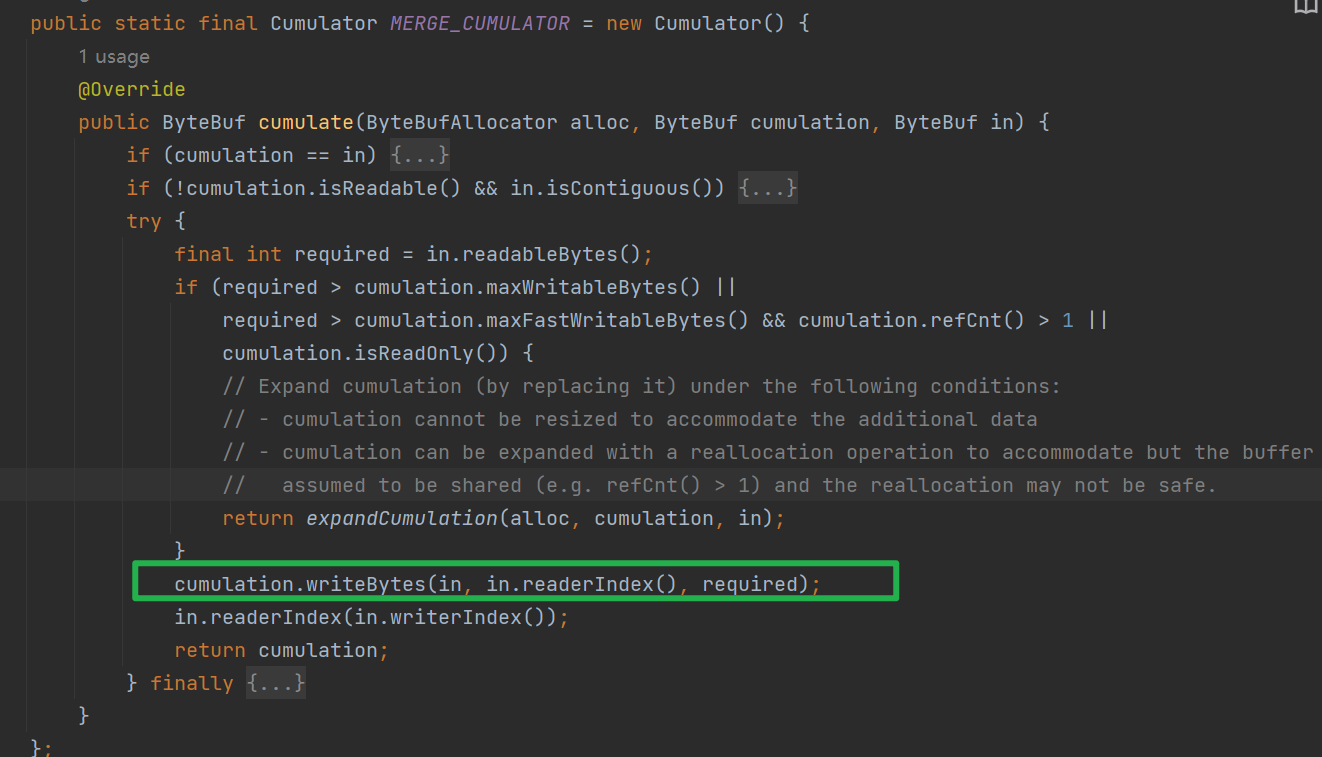
Cumulator:累積器,由於TCP存在粘包,半包的情況,NioSockectChannel在讀取的時候不一定可以讀取到一個完整的訊息,所有需要使用Cumulator進行累計,netty提供了兩種累積器的實現
-
合併:顧名思義,會將已經積攢的ByteBuf和當前需要累計的ByteBuf進行合併,是真真切切發生記憶體拷貝的
-
組合:這種策略下,會將已經積攢的ByteBuf和當前需要累計的ByteBuf進行組合——生成一個邏輯檢視:CompositeByteBuf
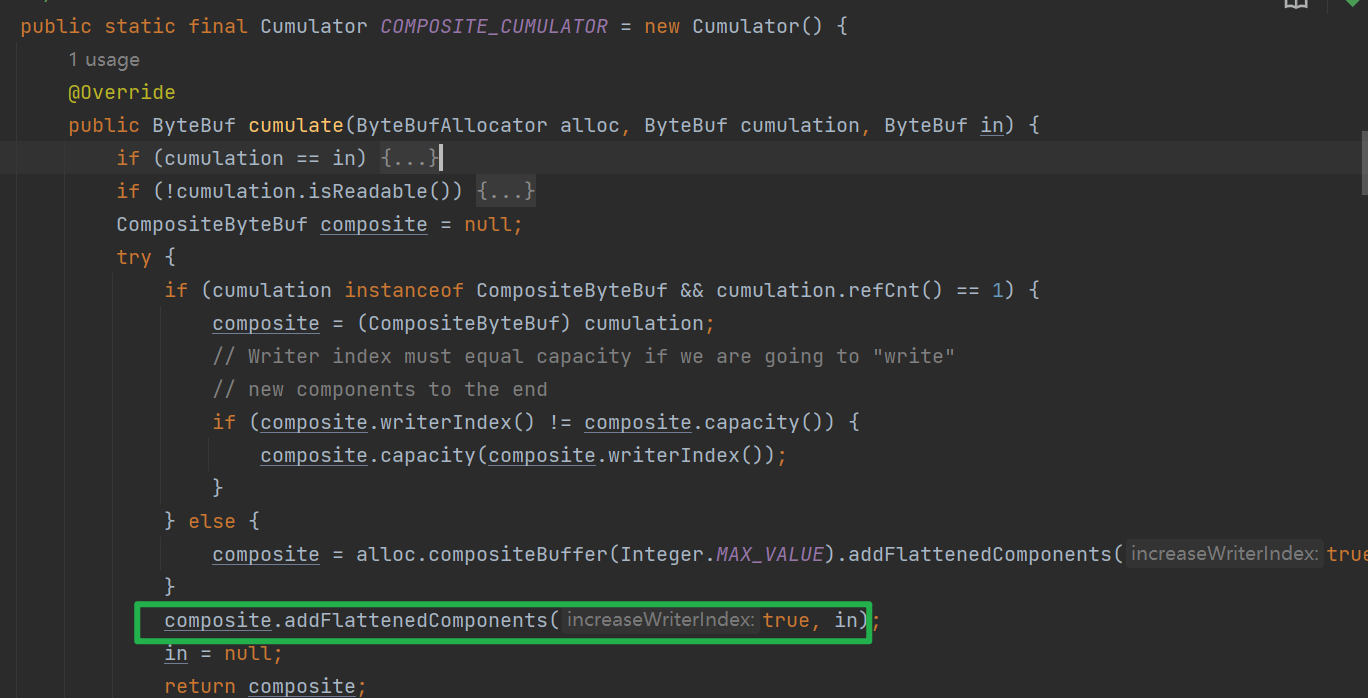
-
-
模板模式:ByteToMessageDecoder將累積的過程進行了抽象,子類只需要實現decode將解碼生成的訊息寫入到CodecOutputList中即可

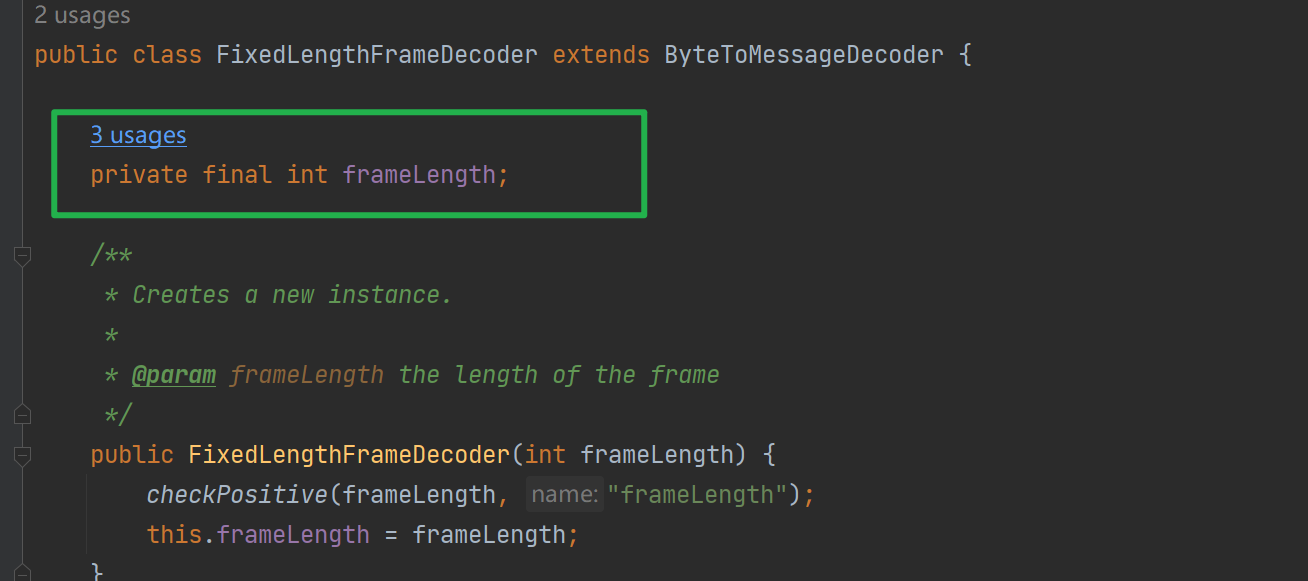
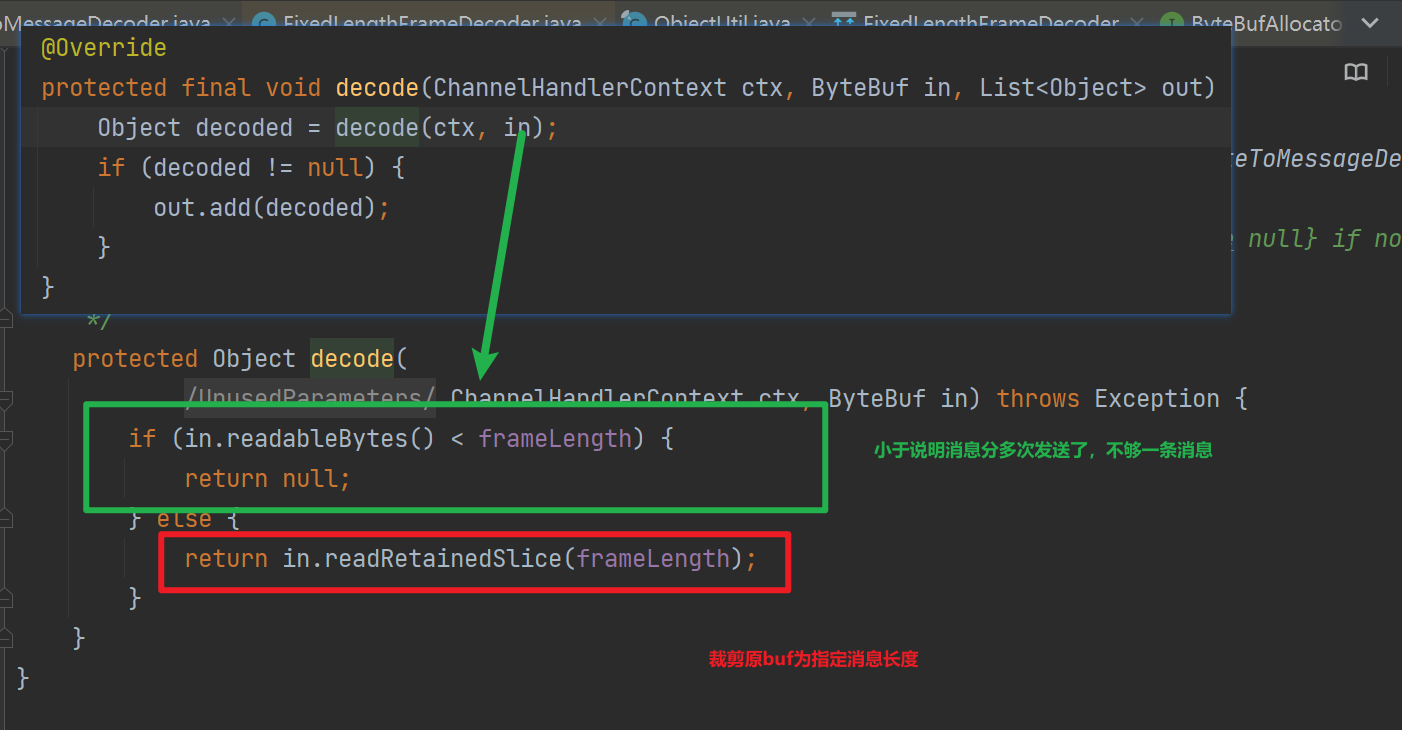
3.1 FixedLengthFrameDecoder 定長訊息
使用子類進行解碼,需要保證傳送來的訊息長度是一致的!其使用欄位frameLength記錄完整訊息的長度
如下是解碼原始碼:
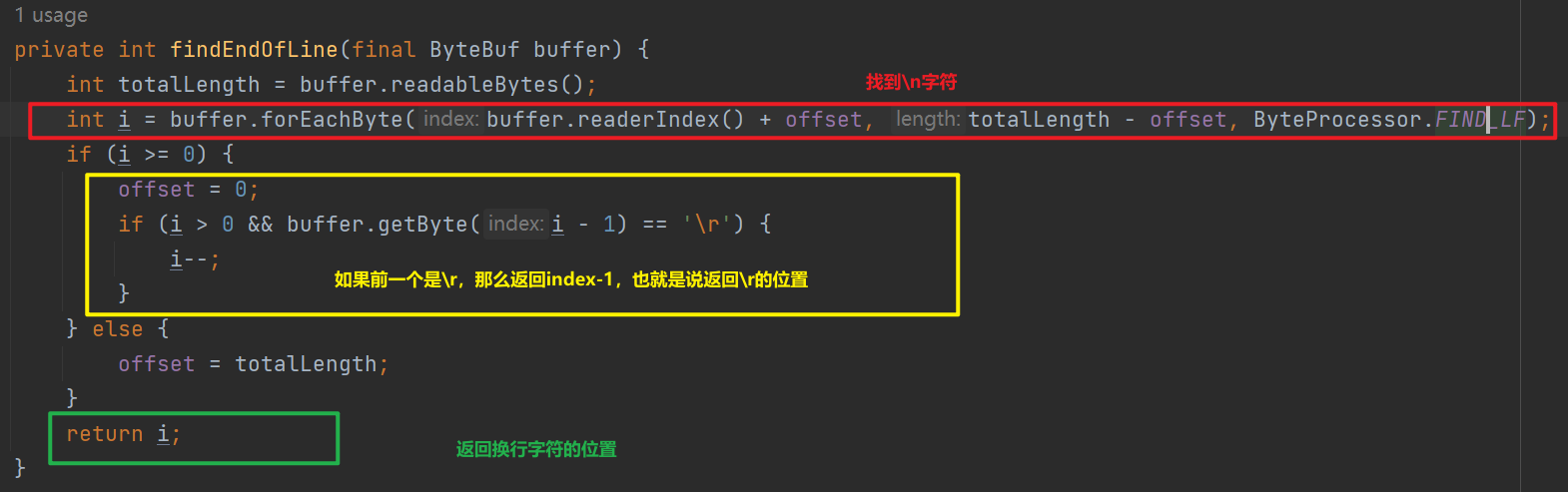
3.2 LineBasedFrameDecoder 換行符解碼器
顧名思義就是找到換行符所在的位置,分割出一條訊息
這個累有點雞肋,因為不支援自定義換行符,如果換行符需要支援指定可以使用DelimiterBasedFrameDecoder
3.3 DelimiterBasedFrameDecoder 支援自定義分割符的解碼器
原理和LineBasedFrameDecoder 類似,內部使用delimiters陣列記錄分割符是什麼

3.4 LengthFieldBasedFrameDecoder
基於訊息頭的長度欄位來確定每個訊息的長度來解碼出訊息,相比於上面幾種,它使用更加廣泛的解碼器(訊息定長如果訊息太短需要補齊,浪費網路資源,換行和分割符解碼同樣會浪費一些網路資源)
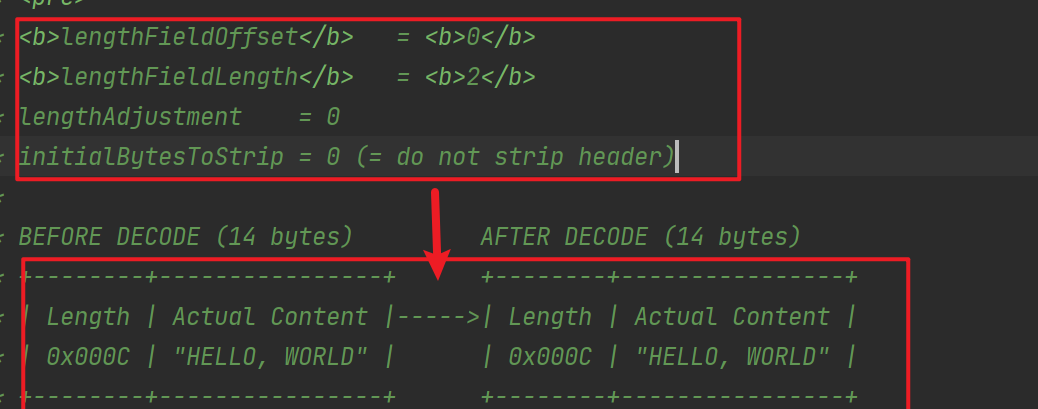
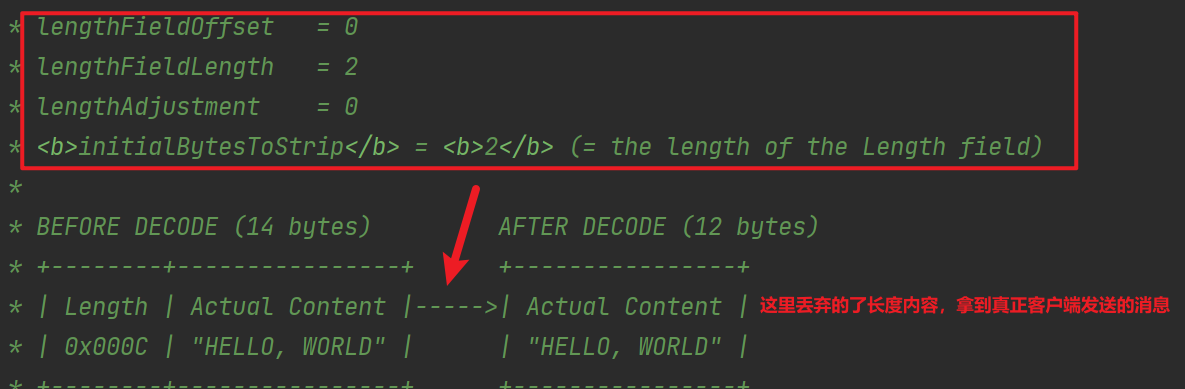
此類原始碼上的註釋詳細解釋瞭如何使用,它有如下幾個重要的引數:
- maxFrameLength : 傳送的封包最大長度;
- lengthFieldOffset :長度域偏移量,指的是長度域位於整個封包位元組陣列中的下標;
- lengthFieldLength :長度域的自己的位元組數長度。
- lengthAdjustment :長度域的偏移量矯正。 如果長度域的值,除了包含有效資料域的長度外,還包含了其他域(如長度域自身)長度,那麼,就需要進行矯正。矯正的值為:包長 - 長度域的值 – 長度域偏移 – 長度域長。
- initialBytesToStrip :丟棄的起始位元組數。丟棄處於有效資料前面的位元組數量。比如前面有4個節點的長度域,則它的值為4。
例子:
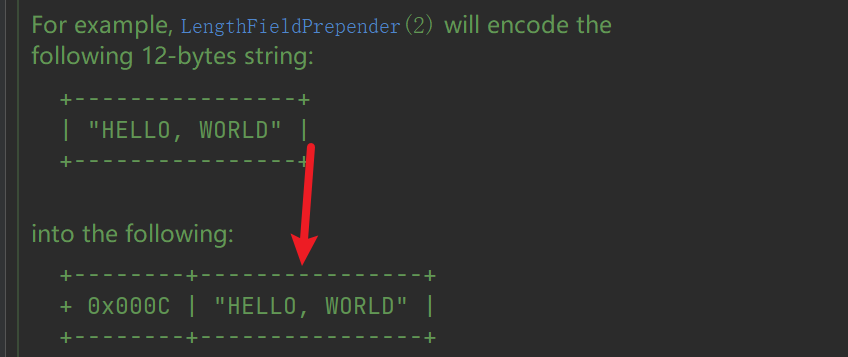
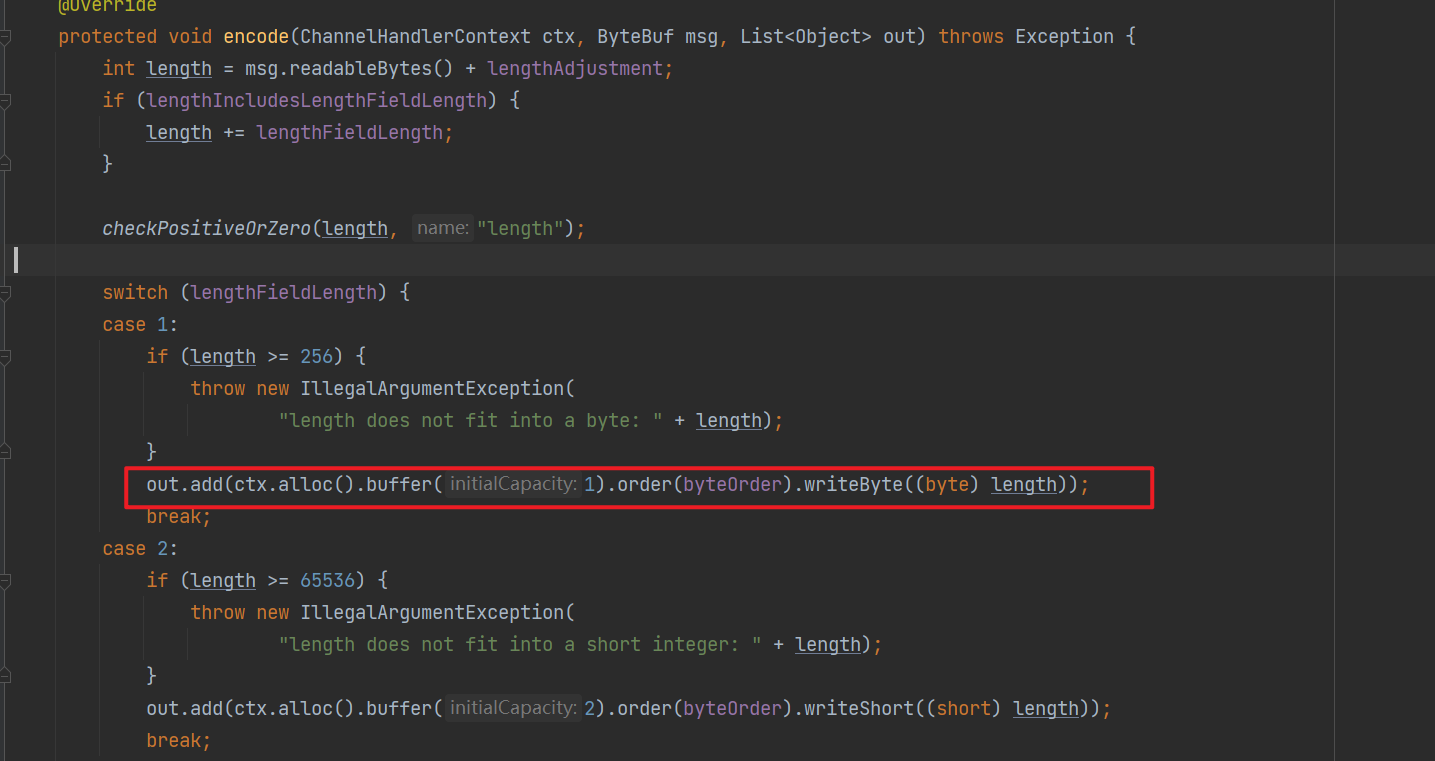
3.5 LengthFieldPrepender
在傳送訊息的前面新增長度欄位,與 LengthFieldBasedFrameDecoder 配合使用,可確保粘包和半包問題不會發生。
因此它是一個ChannelOutboundHandler,其原理也比較簡單,在傳送訊息前加上長度資訊
四丶總結&啟下
這一篇我們學習了netty是如何解決TCP協定中粘包半包的問題,以及粘包半包問題為何會出現,並學習netty中常用的編碼解碼器原始碼
其實netty對於其他協定,如:udp,websockect,http,smtp都有對應的實現,這也是為啥開發者喜歡使用netty的原因——不需要重複造輪子
另外netty還支援多種序列化反序列化方式:json,xml,Protobuf等
後續應該會更新netty追求卓越效能打造的一些輪子,如FastThreadLocal,物件池,記憶體池,時間輪。以及和學習交流群的小夥伴們一起基於netty寫一個簡陋的rpc框架,鞏固一下netty的使用。