京東廣告研發近期入選國際頂會文章系列導讀——CIKM 2023篇
近年來,放眼業界廣告推薦領域的演演算法獲得了長足的發展,從幾篇奠定基礎的序列學習、大規模圖學習、線上學習&增強學習、多模態推薦問題等起步,業內演演算法不斷迭代發展並在學術和工業場景上取得不錯的應用。
京東廣告團隊不僅在工業場景上非常重視實踐,並不斷為由「廣告主」、「消費者」、「京東」三方的生態正迴圈中進行技術加碼,提供更優的匹配效率、更好的使用者體驗、更健康的廣告生態建設。此外,在近期的學術會議CIKM 2023 (Conference on Information and Knowledge Management )上也在這幾個領域發表了學術論文,獲得了學術領域的認可。
一、近年來廣告演演算法發展及要突破的問題
排序演演算法、多模態演演算法是推薦系統中的關鍵組成部分,用於根據使用者的興趣和歷史行為來推薦個性化內容。以下是近年來的演進:
1. 深度學習方法的興起:
近年來,深度學習在排序演演算法中的應用迅速增加。通過使用深度神經網路來建模使用者和物品之間的複雜關係,推薦系統能夠更準確地理解使用者的興趣。這些方法包括各種神經網路架構,如折積神經網路(CNN)、迴圈神經網路(RNN)和自注意力機制(Transformer)。例如,YouTube的深度學習排序模型可以根據使用者的觀看歷史和行為來推薦視訊。
2. 序列建模:
推薦系統越來越注重對使用者行為序列的建模。這意味著演演算法不僅考慮使用者當前的興趣,還考慮他們的歷史行為。這可以通過RNN、LSTM(長短時記憶網路)等模型來實現。這使得推薦系統能夠更好地理解使用者的演變興趣,例如新聞閱讀歷史或商品瀏覽歷史。
3. 自監督學習:
自監督學習方法在排序演演算法中也有廣泛應用。這種方法通過從未標記的資料中自動生成標籤來進行訓練。例如,通過使用使用者點選行為生成正樣本和負樣本,可以訓練排序模型。這種方法降低了標記資料的依賴性,提高了模型的可延伸性。
4. 線上學習和增強學習:
排序演演算法也在採用線上學習和增強學習技術。線上學習可以實時調整推薦模型,以適應使用者行為的快速變化。增強學習方法則允許模型通過與使用者的互動來進行優化,以最大化長期獎勵。這些方法在工業界應用中具有潛力,尤其是在廣告推薦領域。
5. 多模態推薦:
隨著多模態資料(如文字、影象和視訊)的普及,排序演演算法也越來越關注如何融合和利用多種型別的資訊來進行推薦。這涉及到多模態嵌入、多模態對齊和跨模態推薦等領域的研究。
6. 可解釋性和公平性:
排序演演算法的可解釋性和公平性問題也備受關注。研究人員努力開發可解釋的推薦模型,以增強使用者對推薦的信任,並確保模型的決策不會引入不公平性或偏見。
而在上述的發展中,京東廣告業務發展中重點解決了_「更高效學習」、「更精細建模」、「更優互動能力」、「更美觀智慧」_四個要點進行了突破,後文將分別闡釋。
二、四個主要突破
1. 「更高效學習」——基於資料先驗的增量學習框架 《An Incremental Update Framework for Online Recommenders with Data-Driven Prior》
1.1 簡介
線上推薦系統引起了廣泛的關注,併為企業創造了巨大的收益。在眾多使用者和物品的情況下,增量更新成為工業場景中學習大規模模型的主流正規化,其中只有滑動視窗內的最新資料被送到模型中,以滿足線上快速響應的目的。然而,這種策略模型容易過擬合新增的資料上。
當資料分佈存在顯著偏移時,長期資訊將被丟棄,這會損害推薦效能。傳統方法通過基於模型的持續學習方法來解決這個問題,而沒有分析線上推薦系統的資料特性。為了解決上述問題,我們提出了一種帶有資料驅動先驗(DDP)的線上推薦系統增量更新框架,它由特徵先驗(FP)和模型先驗(MP)組成。FP對每個特定值進行點選率估計,以增強訓練過程的穩定性。MP根據貝葉斯法則,將先前的模型輸出合併到當前更新中,從而得到一個在理論上可證的用於穩健更新的先驗。通過這種方式,FP和MP都被很好地整合到統一框架中,該框架與模型無關,並且可以適應各種先進的互動模型。在兩個公開可用的資料集以及一個工業資料集的大量實驗證明了所提出框架的卓越效能。
1.2 介紹
隨著網際網路應用的快速發展,推薦系統已經成為解決資訊超載問題的有效解決方案,旨在為使用者在眾多候選集中找到潛在的偏好。許多電子商務公司從推薦系統中獲得了重要的收入,其中點選率越高,獲得更大收益的可能性就越高。因此,點選率(CTR)預測在當今的線上推薦中起著至關重要的作用。近年來,為了更好地適應大規模資料,提出了多種表達能力強的模型,用於捕捉多個特徵之間的複雜互動。這些模型傾向於更復雜的結構,以充分捕捉多個高階組合特徵。然而,在大量使用者和商品情況下,這些模型需要大量的計算資源,阻礙了線上推薦的快速部署和更新。主流框架是將模型與增量資料(即滑動視窗內的新資料)一起輸入,以連續訓練最新的模型,而不是從頭訓練。這種策略大大減少了時間開銷,並適應線上資料分佈的動態變化。
然而,當線上資料的分佈發生顯著變化時,這種框架容易出現對最近資料過擬合的現象。例如,在雙11購物狂歡節和黑色星期五等大型促銷活動中,特定商品在短時間內會受到很大關注,導致其分佈與以前收集到的反饋不同。訓練框架會因此受到影響,傾向於最近的曝光情況。造成模型過多地關注新到達的資料,並逐漸忽視使用者興趣的長期資訊,限制了推薦效能。此外,由於長尾商品的相對曝光比例減少,模型對這些專案的關注度較低,加劇了長尾效應的發生。
現有研究已經應用持續學習來緩解線上推薦系統中的這個問題。現有研究通過利用基於模型的先驗知識,直接預測每個範例的CTR,從而解決了這個問題。然而,這些研究是受傳統持續學習的策略啟發,沒有分析線上推薦中的資料特點。資料的極端稀疏性和特徵的多樣性是其中兩個顯著的特點。在眾多使用者和商品中,使用者的點選非常稀疏,這使得準確估計使用者偏好變得困難。最近的研究表明,每個物品需大約10,000次的顯示才能收斂。有限的曝光量在增量更新過程中阻礙了穩健的估計。CTR預測的最近成功歸功於使用複雜特徵,其中具有與熱門物品相似特徵的長尾物品獲得了更準確的估計。此外,考慮到特徵也是影響模型效果的最重要因素,我們動機是將特徵先驗知識納入模型學習以提高效能。
為此,我們提出了一個具有資料驅動先驗(DDP)的穩健統一增量學習框架,以改進現今主流的訓練框架下的效能。它以端到端的方式整合了特徵先驗,並提供了更具理論證明的模型先驗。具體而言,特徵先驗旨在明確估計特定特徵值的平均CTR。在特徵粒度上,CTR值的分佈比範例級別上的分佈更穩定,因為資料更集中在每個特徵上。特徵先驗最終起到輔助特徵資訊的作用,併為模型的更新提供更穩定的學習方向,從而有利於優化長尾專案。此外,基於貝葉斯法則,我們構建了模型先驗,通過在增量資料上最大化似然函數,並降低當前模型到先前模型的函數空間距離,來近似完整資料上的後驗估計。因此,可以將以前模型的輸出輕鬆整合到框架中,以實現模型先驗,其中以前模型的輸出用於監督當前模型。
1.3 方法
1.3.1 預備知識


1.3.2 框架總覽
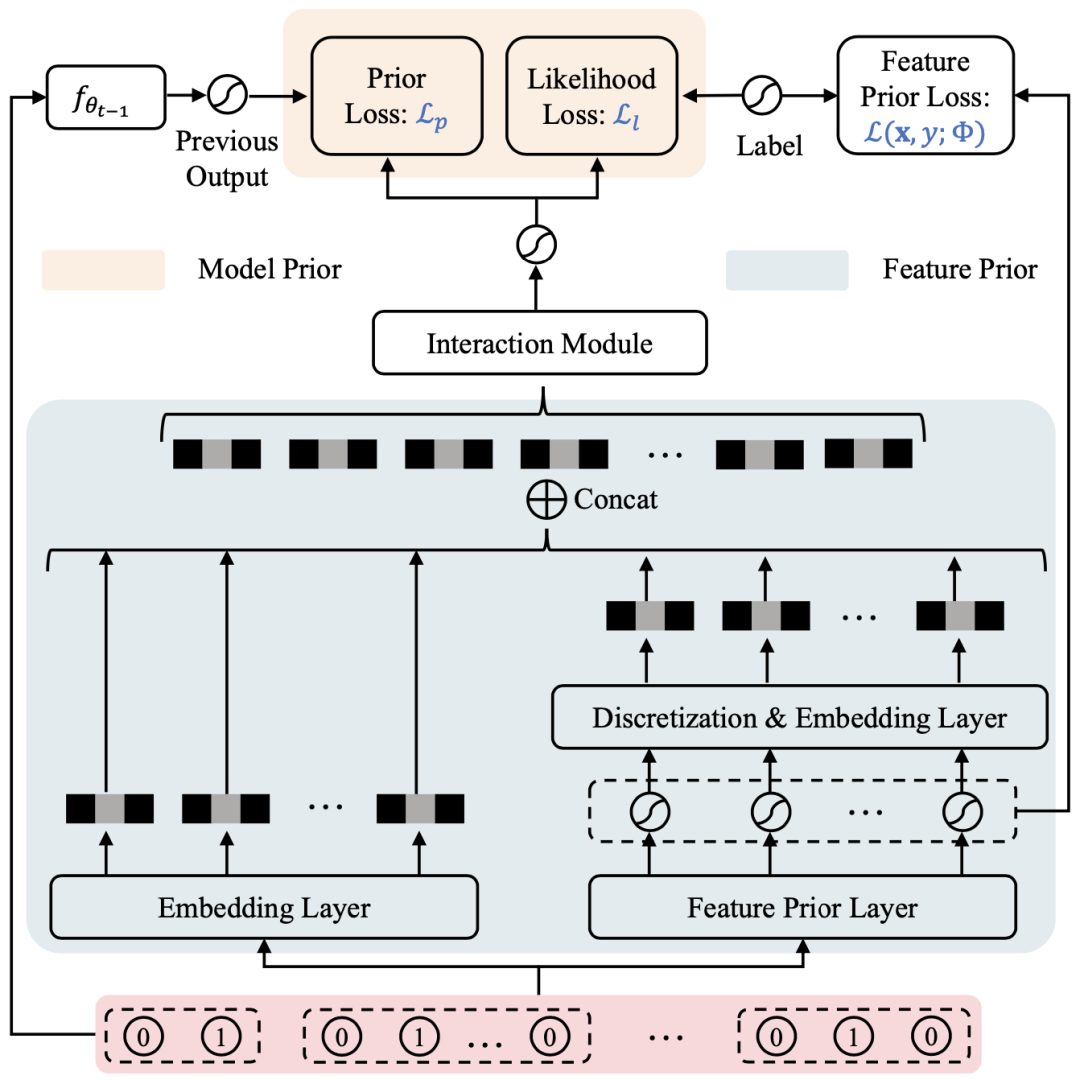
我們提出了一個統一的框架,即基於資料驅動先驗知識的增量更新框架 (Data-Driven Prior, DDP),它由兩個重要元件組成,如上圖所示:
- 特徵先驗 (FP) 估計每個特徵欄位特定值的平均CTR,其動機在於相比範例級別的CTR頻繁變化,特徵級別的分佈更為穩定。FP 的目標是幫助模型更穩健地學習,並對長尾資料進行更準確的CTR估計。
- 模型先驗 (MP) 基於貝葉斯法則提供更穩健的更新,作為正則化項來最小化增量更新與整體資料訓練之間的差異。MP 的目的是輔助模型穩定學習,並避免在增量資料上過擬合。
這兩個基於資料驅動的部分可以輕鬆整合到現有的先進模型中,從而產生一個與模型無關且通用的框架。此外,該框架可以以端到端的方式進行更新,很容易整合到線上推薦系統中。
1.3.3 特徵先驗
先前的研究採用樸素的持續學習方法,通過利用基於模型的資訊幫助學習每個範例的CTR。一個主要的問題是增量更新所加劇的極度資料稀疏問題。模型引數對這些資料非常敏感,稀疏的資料會導致模型的不穩定性,從而使其過度擬合最新的資料。直觀上,範例中的特徵資料出現更加頻繁,估計結果比範例本身更加穩定。因此,我們受到啟發,設計了一個模組來估計特徵的CTR值,並將其作為穩定且有用的資訊輸入CTR模型,以提高推薦系統的效能。這種特徵級別的值可以泛化到長尾專案中,使CTR模型能夠更準確地估計長尾特徵。為此,我們提出了特徵先驗 (FP),它可以為每個特徵維護長期的先驗資訊,從而更穩定地表達長尾特徵。


其中,Concat(⋅)表示連線函數。通過這種方式,特徵先驗被很好地整合到原始的嵌入模組中,然後通過任何互動模組來捕捉不同特徵之間的互動。
1.3.4 模型先驗



1.4 實驗
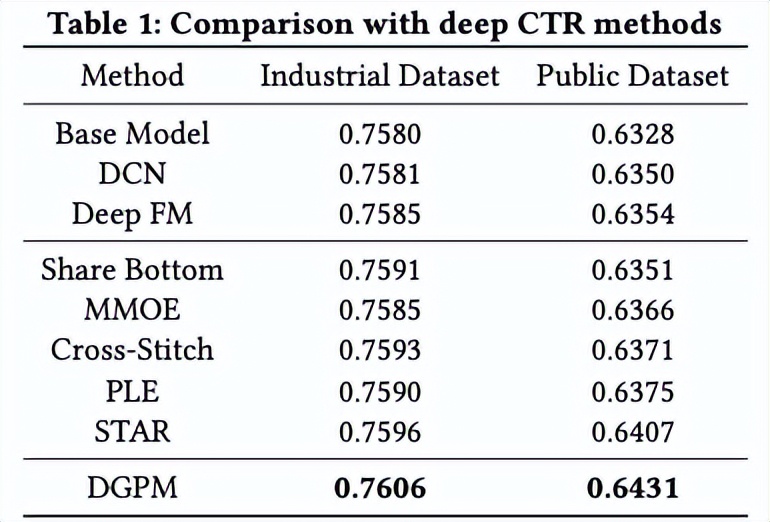
我們在公開資料集上做了大量實驗,實驗效果如上表格所示,我們的最終框架DDP和只引入特徵先驗的FP,在Criteo資料集和CIKM2019資料集上,增量學習下的整體表現和在長尾表現都體現了我們方法的優越性。同時,長尾資料上的效果證明了特徵先驗在長尾資料上估計的穩定性。
2. 「更精細建模」——從「千人一模」、「千人千模」到「千群千模」 《Dynamic Group Parameter Modeling for Click-Through-Rate Prediction》
2.1 摘要
點選率預估模型在推薦系統和線上廣告系統中發揮著重要作用。近年來,許多工作致力於通過挖掘資料的潛在模式來提高點選率預估的準確度。這些工作通常將資料劃分為多個群體,為每個群體學習其獨特的引數,從而提升模型引數的多樣性。然而,當前工作中的群體通常通過手動劃分的方式完成,這種方式難以獲取最優的群體劃分結果,限制了使用者的興趣表達。
針對該問題,我們提出了一種新的動態群體引數建模方法(DGPM),實現自動的群體劃分與群體引數學習。 我們的方法包括三個模組:群體資訊選擇模組用來獲取與使用者群體劃分相關的資訊、群體表示學習模組用於學習每個群體的有效表示,群體引數生成模組用於為每個群體動態生成引數。我們在公開資料集和工業資料集上進行了實驗,實驗結果證明了DGPM的有效性。 同時,我們還在線上廣告系統中部署了該模型,在點選率和RPM指標上都取得了顯著提升。
2.2 背景
點選率預估是線上廣告系統中的一個重要環節。隨著近年來深度學習的不斷髮展,基於深度網路的CTR模型也取得了重大進步。然而,當前大多數 CTR 模型使用相同的結構和引數來預測所有樣本,這種方式很難適應所有樣本或使用者的特性,因此通常不是最優的。實際上,使用者興趣具有明顯的群體模式,通過將使用者劃分為不同的群體,每個群體的分佈和點選率也會表現出較大差異。從這個角度來看,點選率預估可以通過分群的方式進行,以同時考慮群體的特性和群體之間的共性,提升預估準確率。
基於分群的點選率預估通常有兩個主要挑戰:一是如何進行群體劃分,二是如何學習群體特有模型。對於第一個挑戰,大多數現有工作都用一些手動定義的準則來劃分資料,例如使用者的屬性、所屬的任務或域。然而,這種分群方式不夠靈活,且難以得到效能最優的結果。基於不同的劃分準則,使用者可以劃分到多個群體中,一方面,我們很難窮盡所有的劃分方式;另一方面,資料的分佈可能會隨時間而變化,因此當前劃分方式的效果可能可能在後期會出現下降。對於第二個挑戰,常見的方法是採用現有的多工學習和多域學習的方式,為每個群體設立其特有的結構,並將群體特有結構和共用結構相結合,來同時學習群體特性與共性。這種方式的問題是在分組固定後,每個使用者所對應的結構和引數也是固定的,僅依靠共用結構部分難以使使用者學習到使用者跨群體的興趣。
針對上述問題,我們提出了一種新的動態群體引數建模的方法,實現自動的群體劃分與動態的群體引數學習。我們的方法主要包含三個階段:首先是群體資訊選擇階段,用於獲取最相關的使用者特徵進行群體劃分。在這個階段,我們利用SENET模組這種典型的特徵互動方法來計算特徵重要性並組合不同型別的特徵。之後,在群體表示學習模組,我們根據選定的群體特徵使用Memory Network學習顯式的群體表示。最後,我們以「軟劃分」的方式進行群體選擇,生成使用者屬於不同群體的概率,並組合來自多個群體的引數,以更好地表達使用者興趣。
2.3 方法
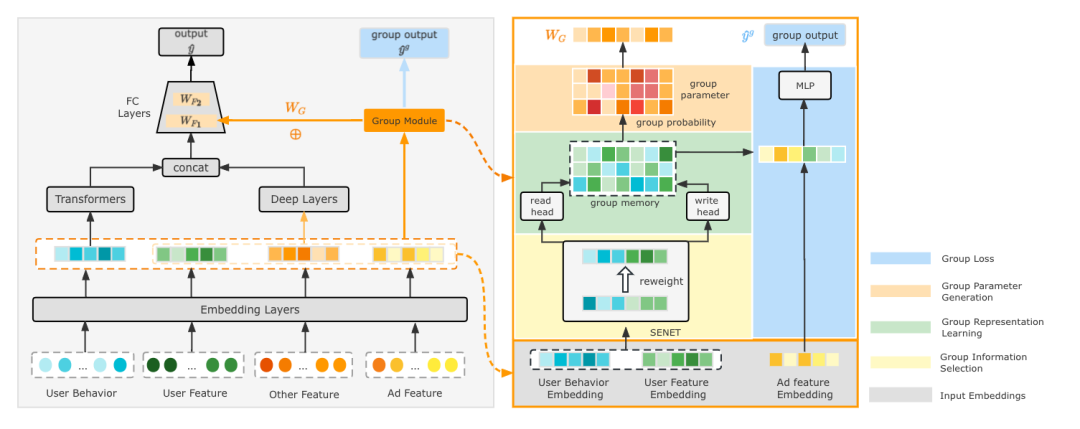
2.3.1 CTR預估模型
在推薦系統中,每個使用者請求會依次經過召回、粗排等環節,最終有大概幾百個廣告會到達精排模組。精排模組需要對每個候選廣告進行評分,以選擇最合適的廣告進行展示,其中CTR預估為精排模組的主要任務。

2.3.2 群體資訊選擇

2.3.3 群體表示學習

2.3.4 群體引數生成

2.3.5 損失函數

2.4 實驗
我們在公開資料集與工業資料集都進行了實驗,並與多個經典的CTR模型進行了對比,實驗結果證明了方法的有效性。我們同樣將模型部署到了線上廣告系統中,取得了CTR和RPM的顯著提升。
3. 「更優互動能力」——雙向考慮大規模圖上的使用者/商品 《BI-GCN: Bilateral Interactive Graph Convolutional Network for Recommendation》
3.1 背景
在資訊爆炸的時代,推薦系統(Recommender System, RS)可以幫助我們過濾掉大量無用資訊並直接接觸到感興趣的資訊。推薦系統從電子商務、廣告、社交媒體到新聞媒體等許多線上服務中都發揮著核心作用。深入推薦系統的本質,其核心任務是預測一個基本問題:目標使用者與目標商品發生互動(點選、購買、評分等)的可能性有多大。協同過濾(Collaborative Filtering, CF)利用大量使用者-商品歷史互動行為,成功地解決了這個互動預測問題,這使得它成為了許多現實世界推薦系統的預設框架。
一般來說,協同過濾通常是利用學習到的代表使用者和商品潛在特徵的嵌入/表達(Embeddings)進行融合以預估出使用者對商品的偏好/互動概率,而融合手段通常是內積,歐式距離,或者多層感知機。因此,如何得到特徵富有表現力的使用者/商品嵌入對於預測準確性至關重要。早期的協同過濾演演算法,例如矩陣分解 (Matrix Factorization),大多直接將使用者/商品 ID 投影到嵌入向量。後來,許多工作通過在嵌入表達學習中引入使用者的歷史互動行為,以增強目標使用者嵌入。
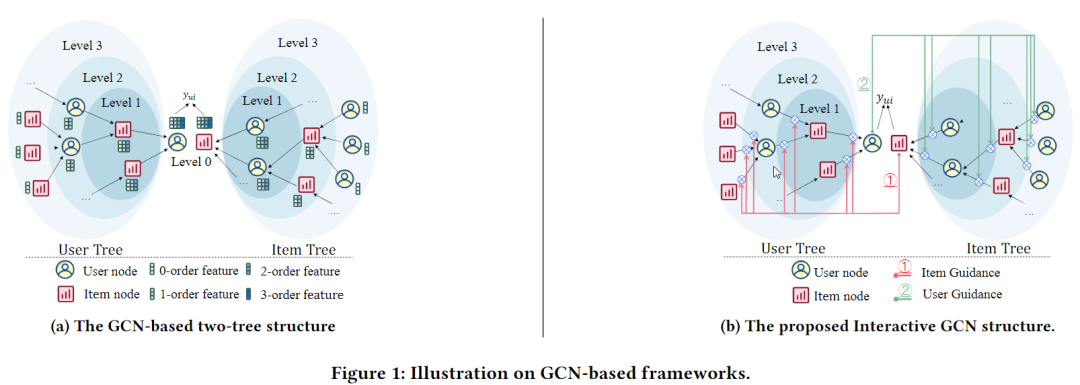
近年湧現了許多基於圖折積神經網路(Graph Convolutional Neural Network, GCN)的協同過濾演演算法的新興研究,這些研究通過使用者-商品之間的多跳連線進一步增強了嵌入表達能力。具體而言,協同過濾的資料可以天然的用二分圖組織:使用者u和商品i作為節點,互動行為作為邊。節點u/i的k階特徵是由k層堆疊的圖折積層聚合而來,彙總了其k跳鄰域內的資訊。而這樣k跳鄰域形成了一個樹狀結構,使用者/商品樹。圖1(a)給出了推薦系統中圖折積的雙樹結構。
3.2 我們的方案
儘管基於GCN的協同過濾演演算法已經被廣泛研究,但現有的方法都有一個主要的侷限:在協同過濾層進行最終融合之前,使用者樹和商品樹缺乏互動。這主要歸因於現有的聚合方式大都繼承自傳統的針對節點分類任務而提出的GCN演演算法。然而,推薦任務和分類任務是十分不同的,它並未要求對使用者或者商品進行通用刻畫,如使用者購買力或是商品評分,而是需要使用者和商品的互動特徵,即使用者選擇商品時的考量或是商品吸參照戶的部分特性,來進行使用者商品偏好預估。
現有方法僅在最終融合使用者商品表達,這樣的次優結構缺乏對有價值的互動特徵的捕捉,導致它們在使用者商品偏好預估上效果有限。當要預估使用者對某個商品的偏好時,使用者樹和商品樹獨立地聚合自己的鄰居來學習各自的表達。因此,使用者樹聚合時無法感知目標商品,反之亦然。現有的圖注意力方法大部分都應用於節點包含豐富資訊的圖中,並不適合使用者-商品這樣的只包含ID類特徵的二分圖。並且,注意力機制的權重的計算也侷限在中心節點和它鄰居之間,即自注意力機制。
考慮到後融合使用者商品高階特徵帶來的負面影響,本文提出了一種互動式圖折積網路結構(Interactive Graph Convolutional Neural Network, IA-GCN),用於基於協和過濾的推薦系統。它採用了一種早融合方式,通過在使用者樹和商品樹之間建立互動引導來提取互動特徵,可以為使用者提供更為有效精確的個性化推薦服務(參見圖1(b))。
本文提出的IA-GCN是業界首個在推薦系統領域針對動態互動式圖折積網路的嘗試。IA-GCN利用外部注意力機制,強調特定於目標的資訊,可以以端到端(end-to-end)的方式與各種已有的基於圖神經網路的協同過濾演演算法相結合,兼備可解釋性和可延伸性。我們在三個基準資料集的廣泛實驗以及和多個sota基線的對比,驗證了BI-GCN的有效性和優越性。
4. 「更美觀智慧」——藉助幾何關係感知生成更優美的海報佈局 《Relation-Aware Diffusion Model for Controllable Poster Layout Generation》
4.1 摘要
海報佈局是海報設計的一個重要環節,過去的方法主要關注視覺內容與佈局元素之間的關係。然而一個高質量的佈局也應該考慮到視覺與文字內容之間的關係以及佈局元素彼此之間的關係。在這項研究中,我們構建了一個考慮到上述兩種關係的擴散模型用於佈局海報生成。首先,我們設計了一個視覺文字關係感知模組用於對齊視覺和文字之間的模態,通過傳遞文字資訊進而增強佈局效果。隨後我們提出了一個幾何關係感知模組用於綜合考慮元素之間上下文資訊進而學習元素之間的幾何關係。除此之外,所提出的方法可以基於使用者約束生成不同的佈局。為促進這一領域的研究,我們構建了一個名為CGL-Dateset V2的海報佈局資料集,我們提出的方法在該資料集上取得了SOTA結果。
4.2 背景
海報佈局的生成旨在預測影象上視覺元素的位置和類別。此任務對於海報的美學吸引力和資訊傳播起到了至關重要的作用。建立一流的海報佈局需要同時考慮到佈局元素的彼此關係和影象組成,因此這項要求很高的任務通常由專業設計師完成。但是人工設計是一件既耗時又費財的事情。為了以低成本生成高質量的海報佈局,自動佈局生成在學術界和工業界越來越流行。
隨著深度學習的出現,一些內容無關的方法被提出用於學習佈局元素之間的關係。但這些方法更關注元素之間的圖形關係而忽略視覺內容對海報佈局的影響,直接將這些方法用於海報佈局生成可能會產生負面影響。為了解決這些問題,一些內容有關的方法被提出用於佈局生成。儘管這些方法考慮了影象本身的內容資訊,甚至額外引入了圖片的空間資訊,但是兩個重要的因素仍該被考慮進去。一方面,文字在海報的資訊傳遞中扮演了重要的作用;另一方面,一個好的佈局不僅要考慮單個元素的座標是否準確,也要考慮到元素之間的座標關係。
針對上述問題,我們提出了一個關係感知擴散模型用於海報佈局生成領域,該模型同時考慮了視覺-文字和幾何關係因素。 由於擴散模型有在許多生成任務中取得了巨大成功,我們遵循噪聲到佈局的正規化,通過學習去噪模型逐漸調整噪聲來生成海報佈局。在每個取樣步驟中,給定一組以高斯取樣的框分佈或最後一個取樣步驟的估計框為輸入,我們通過影象編碼器提取RoI特徵作為生成的特徵圖。 然後是視覺文字關係感知模組(VTRAM)被提出用於建模視覺和文字特徵之間的關係,這使得佈局結果由影象和文字內容同時決定。 與此同時,我們設計一個幾何關係感知模組 (GRAM)基於RoI彼此的相對位置關係增強每個 RoI 的特徵表達,這使得模型能夠更好地理解佈局元素之間的上下文資訊。受益於新提出的VTRAM和GRAM模組,使用者可以通過預定義佈局或改變文字內容以控制佈局生成過程。
4.3 資料集

CGL-Dataset V2是用於廣告海報設計自動佈局任務的資料集,包含60548個訓練樣本和1035個測試樣本。 它是CGL-Dataset的擴充套件。原始的CGL-Dataset包含4種型別的元素:logo、文字、襯底和裝飾如圖(a)所示。 每個元素由類別和座標資訊組成,然而它不包含文字的內容資訊,這對於海報的佈局有著至關重要的影響。 如圖(a)所示,為了研究文字內容對於佈局的影響,我們補充了文字內容標籤。在訓練集中,為了獲得乾淨的背景影象模型訓練,我們使用一個inpaiting模型來擦除佈局元素,結果如圖(b)所示。
由於文字資訊在原始CGL-Dataset的測試集中沒有提供,所以我們另外收集 1035 張帶有可用文字描述的海報影象來替換原來的測試集。 如圖(c)所示,收集海報影象的處理方式與訓練集相同進而獲得乾淨的背景影象。與此同時,我們收集了當前商品的所有促銷資訊以分析不同文字內容對於海報佈局的影響。 由於收集到的文字內容聚焦於電商領域,我們使用基於海量電商文字語料預訓練的模型來提取文字特徵。
4.4 方法
我們的方法的概述如上圖所示。方法由四部分組成:特徵提取器、視覺文字關係感知模組 (VTRAM)、幾何關係感知模組(GRAM)和佈局解碼器。 特徵提取器分別提取文字和影象的特徵,VTRAM模組建模佈局的視覺和文字關係,GRAM用於增強RoI特徵的彼此位置關係表達能力。 最後,基於VTRAM和GRAM的輸出以及RoI特徵,佈局解碼器預測元素的座標和類別。
4.4.1 基於擴散模型的海報佈局生成
擴散模型是一類使用馬爾可夫鏈將噪聲轉換為資料樣本的概率生成模型。 如圖所示,我們將海報佈局生成問題作為一個噪聲到佈局的生成過程,通過學習去噪模型以逐步調整噪聲佈局。 因此擴散模型生成的海報佈局也同樣包括兩個過程:擴散過程和去噪過程。 給定一個海報佈局,我們逐漸新增高斯噪聲以破壞確定性的佈局結果,我們稱這個操作為擴散過程。相反給定初始隨機佈局,我們通過逐步去噪的方式獲得最終海報佈局稱為去噪過程。
4.4.2 基於擴散模型的海報佈局生成
影象編碼
給定一個乾淨的背景影象,我們使用ResNet-50與特徵金字塔網路(FPN)提取視覺特徵。ResNet-50由於在計算機視覺方面的卓越效能已獲得廣泛應用。 除此之外,我們使用 FPN 生成多尺度特徵圖