C#簡化工作之實現網頁爬蟲獲取資料
公眾號「DotNet學習交流」,分享學習DotNet的點滴。
1、需求
想要獲取網站上所有的氣象資訊,網站如下所示:
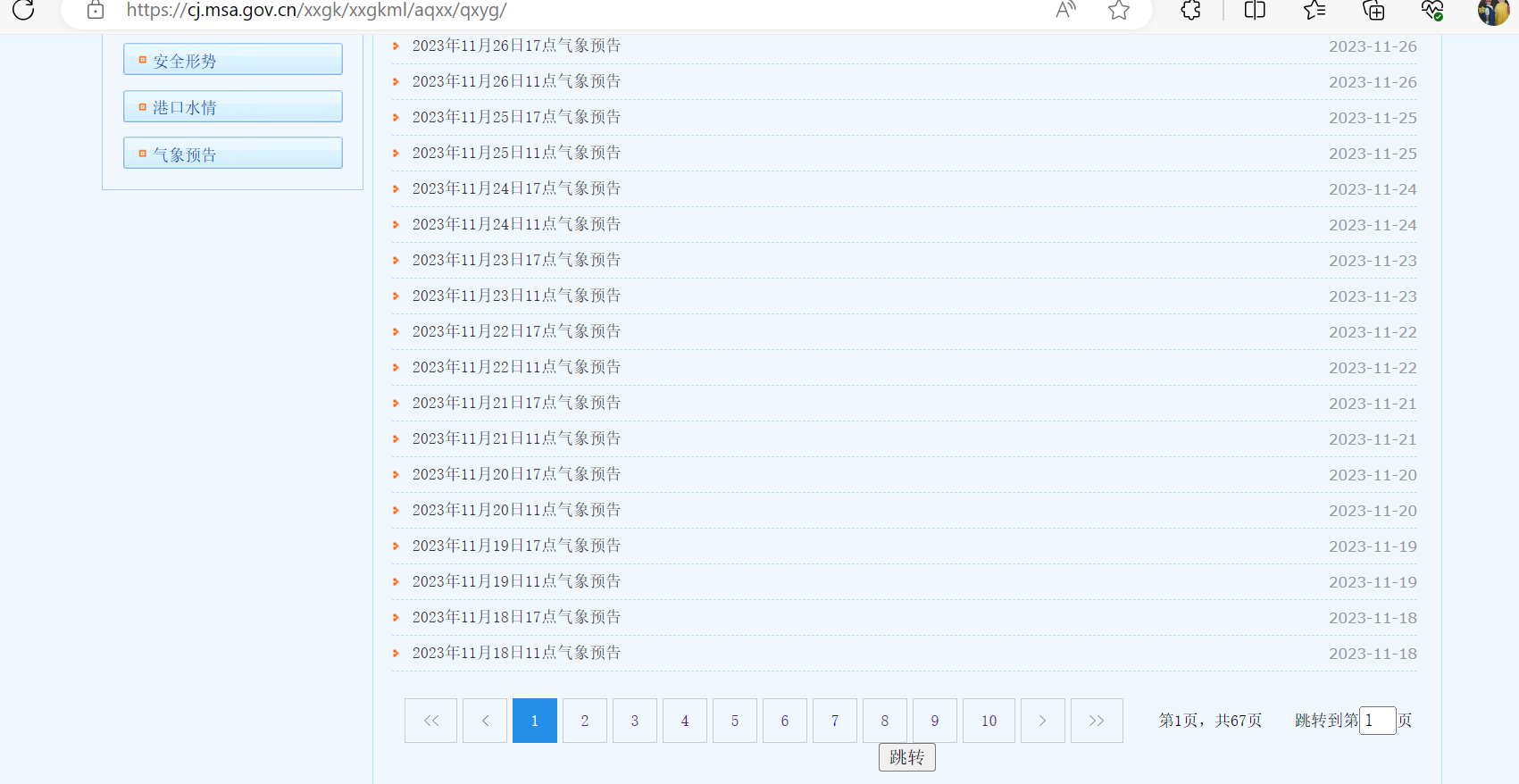
目前總共有67頁,隨便點開一個如下所示:
需要獲取所有天氣資料,如果靠一個個點開再一個個複製貼上那麼也不知道什麼時候才能完成,這個時候就可以使用C#來實現網頁爬蟲獲取這些資料。
2、效果
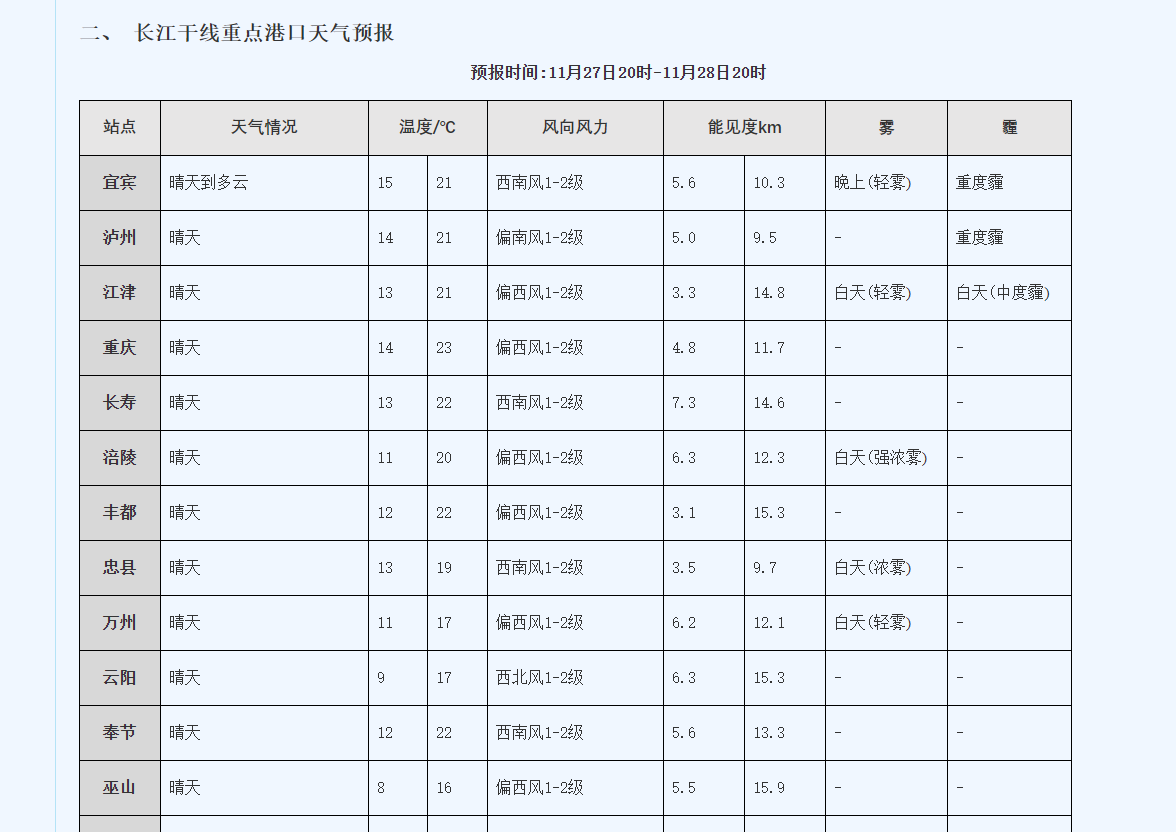
先來看下實現的效果,所有資料都已存入資料庫中,如下所示:
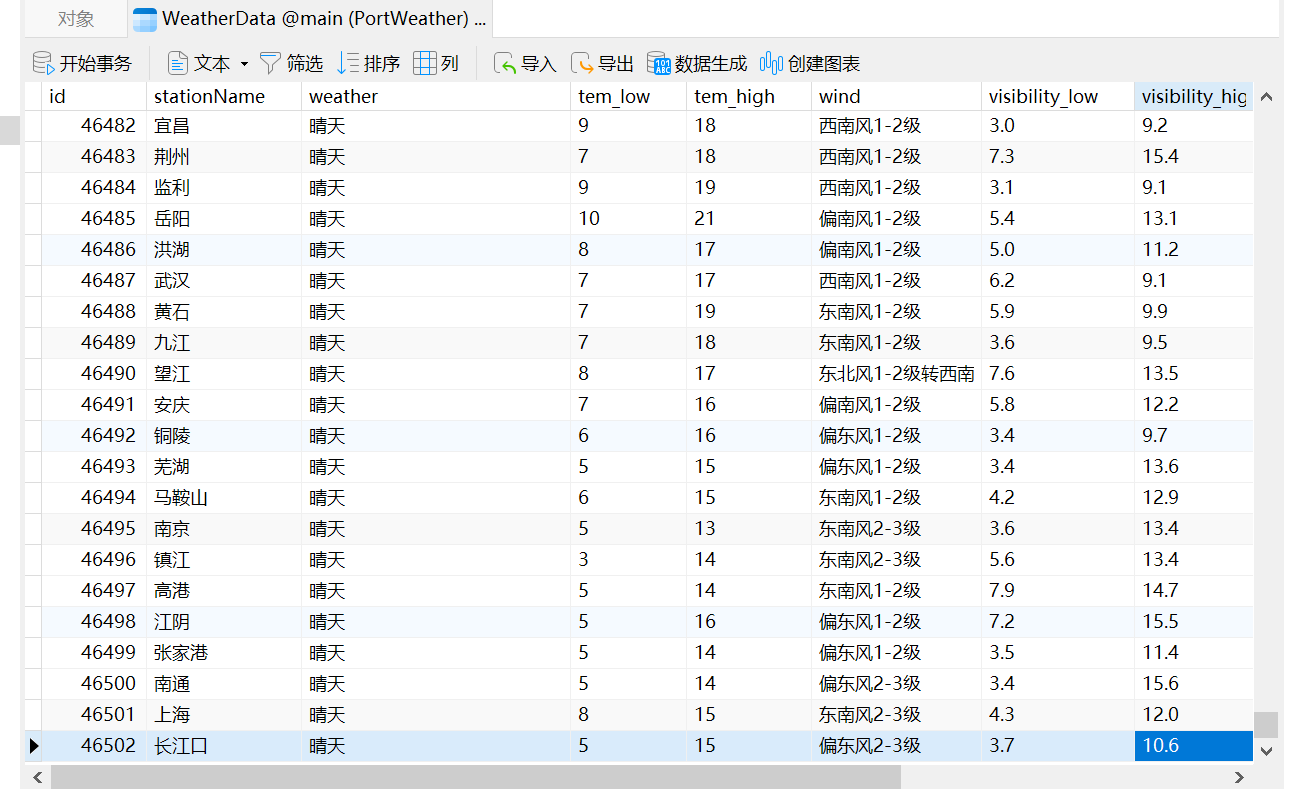
總共有4萬多條資料。
3、具體實現
構建每一頁的URL
第一頁的網址如下所示:

最後一頁的網址如下所示:
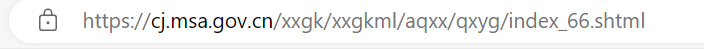
可以發現是有規律的,那麼就可以先嚐試構建出每個頁面的URL
// 傳送 GET 請求
string url = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/";
HttpResponseMessage response = await httpClient.GetAsync(url);
// 處理響應
if (response.IsSuccessStatusCode)
{
string responseBody = await response.Content.ReadAsStringAsync();
doc.LoadHtml(responseBody);
//獲取需要的資料所在的節點
var node = doc.DocumentNode.SelectSingleNode("//div[@class=\"page\"]/script");
string rawText = node.InnerText.Trim();
// 使用正規表示式來匹配頁數資料
Regex regex = new Regex(@"\b(\d+)\b");
Match match = regex.Match(rawText);
if (match.Success)
{
string pageNumber = match.Groups[1].Value;
Urls = GetUrls(Convert.ToInt32(pageNumber));
MessageBox.Show($"獲取每個頁面的URL成功,總頁面數為:{Urls.Length}");
}
}
//構造每一頁的URL
public string[] GetUrls(int pageNumber)
{
string[] urls = new string[pageNumber];
for (int i = 0; i < urls.Length; i++)
{
if (i == 0)
{
urls[i] = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/index.shtml";
}
else
{
urls[i] = $"https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/index_{i}.shtml";
}
}
return urls;
}
這裡使用了HtmlAgilityPack

HtmlAgilityPack(HAP)是一個用於處理HTML檔案的.NET庫。它允許你方便地從HTML檔案中提取資訊,修改HTML結構,並執行其他HTML檔案相關的操作。HtmlAgilityPack 提供了一種靈活而強大的方式來解析和處理HTML,使得在.NET應用程式中進行網頁資料提取和處理變得更加容易。
// 使用HtmlAgilityPack解析網頁內容
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml("需要解析的Html");
//獲取需要的資料所在的節點
var node = doc.DocumentNode.SelectSingleNode("XPath");
那麼XPath是什麼呢?
XPath(XML Path Language)是一種用於在XML檔案中定位和選擇節點的語言。它是W3C(World Wide Web Consortium)的標準,通常用於在XML檔案中執行查詢操作。XPath提供了一種簡潔而強大的方式來導航和操作XML檔案的內容。
構建每一天的URL
獲取到了每一頁的URL之後,我們發現在每一頁的URL都可以獲取關於每一天的URL資訊,如下所示:
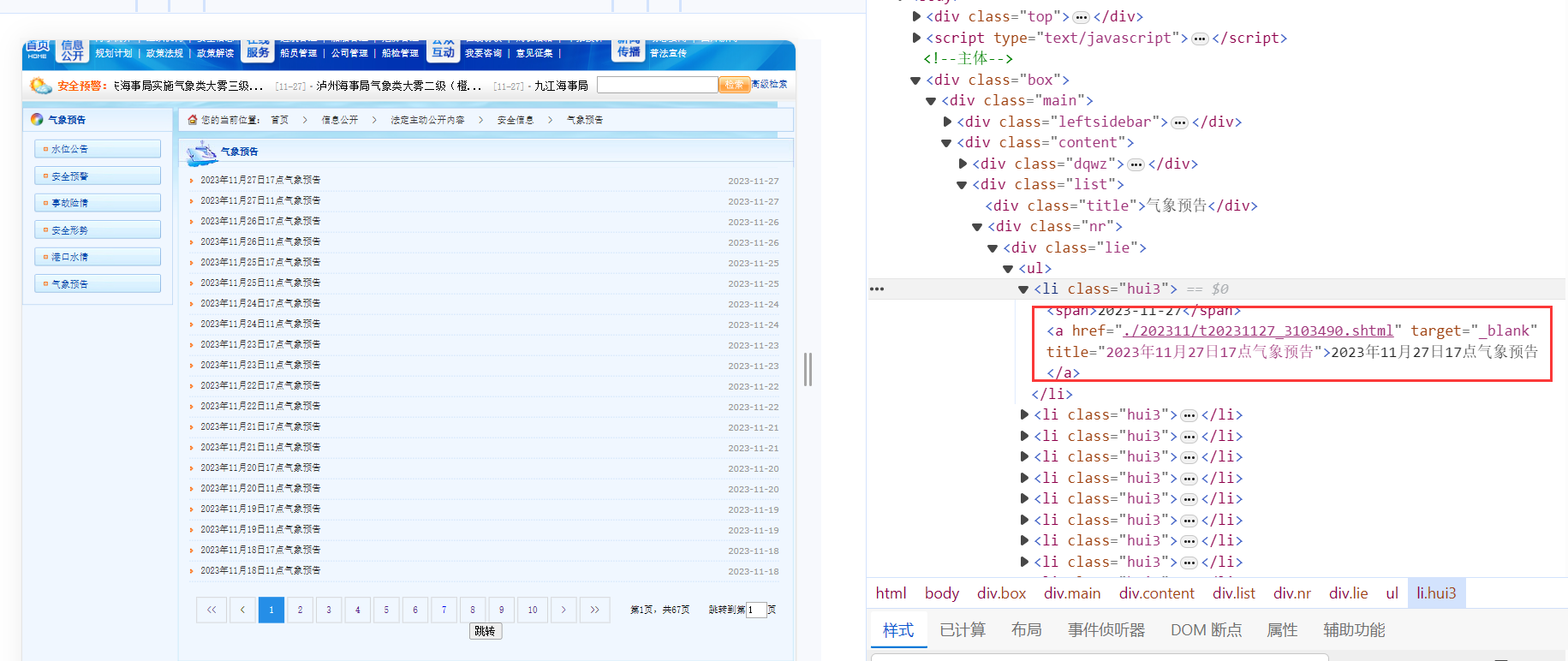
可以進一步構建每一天的URL,同時可以根據a的文字獲取時間,當然也可以通過其他方式獲取時間,但是這種可以獲取到11點或者17點。
程式碼如下所示:
for (int i = 0; i < Urls.Length; i++)
{
// 傳送 GET 請求
string url2 = Urls[i];
HttpResponseMessage response2 = await httpClient.GetAsync(url2);
// 處理響應
if (response2.IsSuccessStatusCode)
{
string responseBody2 = await response2.Content.ReadAsStringAsync();
doc.LoadHtml(responseBody2);
var nodes = doc.DocumentNode.SelectNodes("//div[@class=\"lie\"]/ul/li");
for (int j = 0; j < nodes.Count; j++)
{
var name = nodes[j].ChildNodes[3].InnerText;
//只有name符合下面的格式才能成功轉換為時間,所以這裡需要有一個判斷
if (name != "" && name.Contains("氣象預告"))
{
var dayUrl = new DayUrl();
//string format;
//DateTime date;
// 定義日期時間格式
string format = "yyyy年M月d日H點氣象預告";
// 解析字串為DateTime
DateTime date = DateTime.ParseExact(name, format, null);
var a = nodes[j].ChildNodes[3];
string urlText = a.GetAttributeValue("href", "");
string newValue = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/";
string realUrl = "";
realUrl = newValue + urlText.Substring(1);
dayUrl.Date = date;
dayUrl.Url = realUrl;
dayUrlList.Add(dayUrl);
}
else
{
Debug.WriteLine($"在{name}處,判斷不符合要求");
}
}
}
}
// 將資料存入SQLite資料庫
db.Insertable(dayUrlList.OrderBy(x => x.Date).ToList()).ExecuteCommand();
MessageBox.Show($"獲取每天的URL成功,共有{dayUrlList.Count}條");
}
在這一步驟需要注意的是XPath的書寫,以及每一天URL的構建,以及時間的獲取。
XPath的書寫:
var nodes = doc.DocumentNode.SelectNodes("//div[@class=\"lie\"]/ul/li");
表示一個類名為"lie"的div下的ul標籤下的所有li標籤,如下所示:
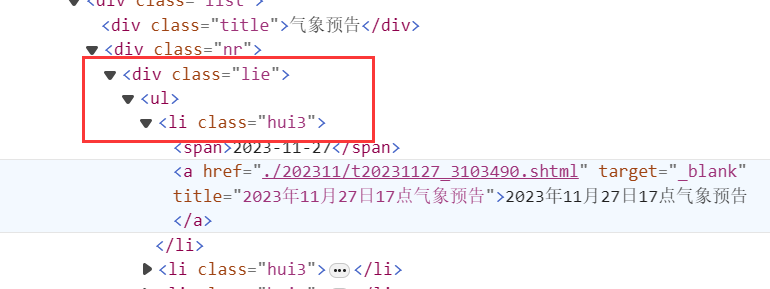
構建每一天的URL:
var a = nodes[j].ChildNodes[3];
string urlText = a.GetAttributeValue("href", "");
string newValue = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/";
string realUrl = "";
realUrl = newValue + urlText.Substring(1);
這裡獲取li標籤下的a標籤,如下所示:
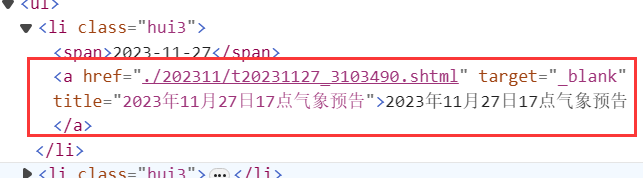
string urlText = a.GetAttributeValue("href", "");
這段程式碼獲取a標籤中href屬性的值,這裡是./202311/t20231127_3103490.shtml。
string urlText = a.GetAttributeValue("href", "");
string newValue = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/";
string realUrl = newValue + urlText.Substring(1);
這裡是在拼接每一天的URL。
var name = nodes[j].ChildNodes[3].InnerText;
// 定義日期時間格式
string format = "yyyy年M月d日H點氣象預告";
// 解析字串為DateTime
DateTime date = DateTime.ParseExact(name, format, null);
這裡是從文字中獲取時間,比如文字的值也就是name的值為:「2023年7月15日17點氣象預告」,name獲得的date就是2023-7-15 17:00。
// 將資料存入SQLite資料庫
db.Insertable(dayUrlList.OrderBy(x => x.Date).ToList()).ExecuteCommand();
MessageBox.Show($"獲取每天的URL成功,共有{dayUrlList.Count}條");
這裡是將資料存入資料庫中,ORM使用的是SQLSugar,類DayUrl如下:
internal class DayUrl
{
[SugarColumn(IsPrimaryKey = true, IsIdentity = true)]
public int Id { get; set; }
public DateTime Date { get; set; }
public string Url { get; set; }
}
最後獲取每一天URL的效果如下所示:
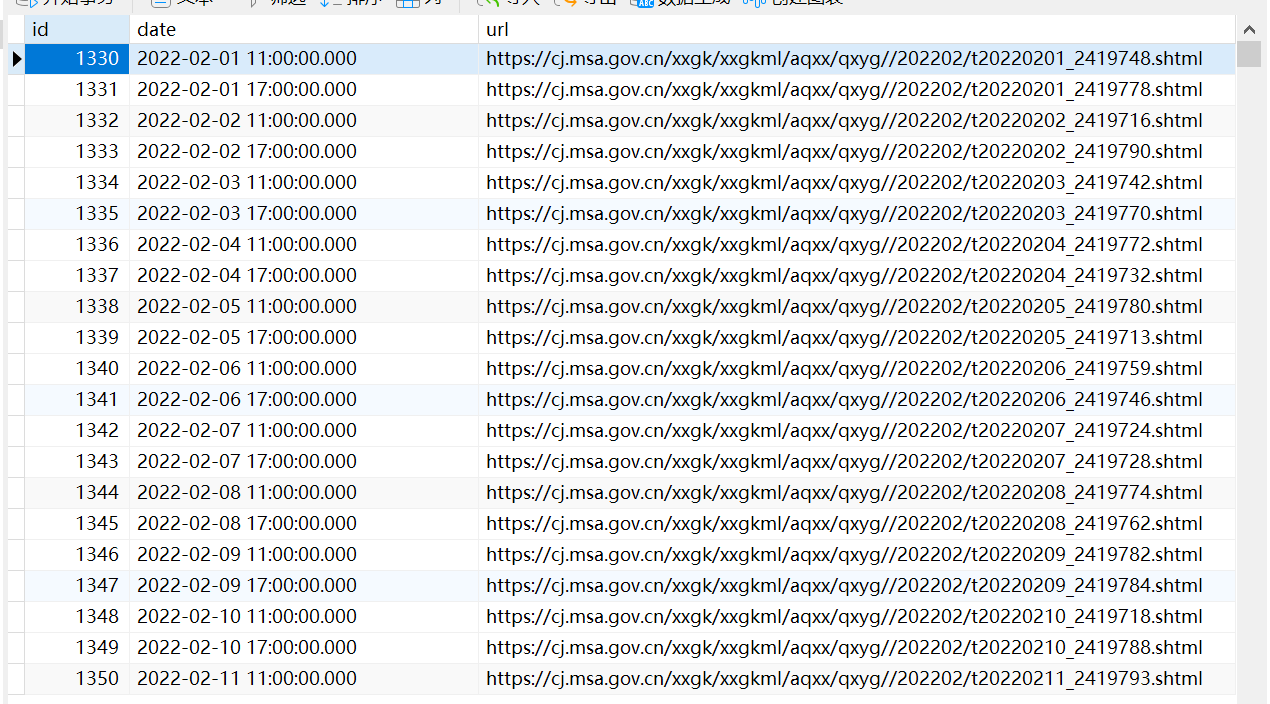
獲取溫度資料
需要獲取的內容如下:

設計對應的類如下:
internal class WeatherData
{
[SugarColumn(IsPrimaryKey = true, IsIdentity = true)]
public int Id { get; set; }
public string? StationName { get; set; }
public string? Weather { get; set; }
public string? Tem_Low { get; set; }
public string? Tem_High { get; set; }
public string? Wind { get; set; }
public string? Visibility_Low { get; set; }
public string? Visibility_High { get; set; }
public string? Fog { get; set; }
public string? Haze { get; set; }
public DateTime Date { get; set; }
}
增加了一個時間,方便以後根據時間獲取。
獲取溫度資料的程式碼如下:
var list = db.Queryable<DayUrl>().ToList();
for (int i = 0; i < list.Count; i++)
{
HttpResponseMessage response = await httpClient.GetAsync(list[i].Url);
// 處理響應
if (response.IsSuccessStatusCode)
{
string responseBody2 = await response.Content.ReadAsStringAsync();
doc.LoadHtml(responseBody2);
var nodes = doc.DocumentNode.SelectNodes("//table");
if (nodes != null)
{
var table = nodes[5];
var trs = table.SelectNodes("tbody/tr");
for (int j = 1; j < trs.Count; j++)
{
var tds = trs[j].SelectNodes("td");
switch (tds.Count)
{
case 8:
var wd8 = new WeatherData();
wd8.StationName = tds[0].InnerText.Trim().Replace(" ", "");
wd8.Weather = tds[1].InnerText.Trim().Replace(" ", "");
wd8.Tem_Low = tds[2].InnerText.Trim().Replace(" ", "");
wd8.Tem_High = tds[3].InnerText.Trim().Replace(" ", "");
wd8.Wind = tds[4].InnerText.Trim().Replace(" ", "");
wd8.Visibility_Low = tds[5].InnerText.Trim().Replace(" ", "");
wd8.Visibility_High = tds[6].InnerText.Trim().Replace(" ", "");
wd8.Fog = tds[7].InnerText.Trim().Replace(" ", "");
wd8.Date = list[i].Date;
weatherDataList.Add(wd8);
break;
case 9:
var wd9 = new WeatherData();
wd9.StationName = tds[0].InnerText.Trim().Replace(" ", "");
wd9.Weather = tds[1].InnerText.Trim().Replace(" ", "");
wd9.Tem_Low