每天5分鐘複習OpenStack(十一)Ceph部署
在之前的章節中,我們介紹了Ceph叢集的元件,一個最小的Ceph叢集包括Mon、Mgr和Osd三個部分。為了更好地理解Ceph,我建議在進行部署時採取手動方式,這樣方便我們深入瞭解Ceph的底層。今天我們將進行較長的章節講解,希望您能耐心閱讀完(個人建議可以動手實踐一次,效果更佳)。因為Ceph官方檔案中對該過程進行了過於簡單的描述,許多細節都被隱藏了,然而這些細節對於理解Ceph概念至關重要。
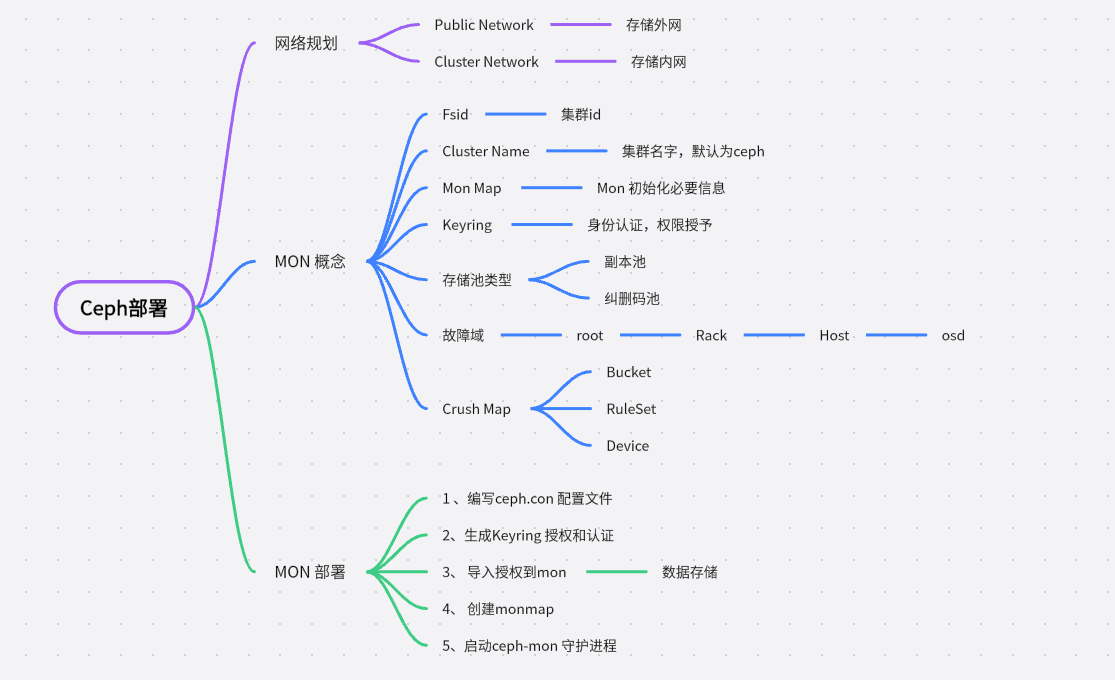
1、網路規劃
在部署之前我們先介紹下Ceph的網路,Ceph叢集是劃分了兩種網路(叢集網路)Cluster Network、(公共網路)Public Network 。
-
Cluster Network: 就是Ceph 叢集元件內部通訊時使用的網路,也稱為儲存內網。如mon之間相互通訊,osd向mon上報其狀態資訊,主osd向從osd 複製資料等內部操作。
-
Public Network: Ceph叢集中用於使用者端存取和管理的網路。它是叢集與外部世界(使用者端、管理員等)通訊的主要通道。也稱為儲存外網。說簡單點就是叢集外部使用者端存取叢集內部時的網路。
總結:叢集內部存取走Cluster Network ,叢集外存取叢集內時走Public Network,叢集內外怎麼區分了? 叢集內部元件有 Mon Mgr OSD Mds 等這些內部元件自身通訊就是走Cluster Network ,客戶或者運維人員使用ceph命令與叢集通訊,此時走的就是Public Network 。
思考1 :OpenStack 將Ceph作為後端儲存時,對Ceph的存取是走哪個網路了? 當我們上傳映象到Ceph儲存池時走的是哪個網路了?
做過OpenStack運維的小夥伴們,一定少不了映象製作和上傳,如果後端儲存是Ceph時,該網路的流量是怎麼走了的呢?
#OpenStack 映象上傳命令如下:
openstack image create --container-format bare --disk-format qcow2 \
--public --file /path/to/centos-image.qcow2 centos-image
### 引數說明
--container-format bare 表示容器格式是裸(bare)。
--disk-format qcow2 表示磁碟格式是qcow2。
--public 表示將映象設定為公共映象。
--file /path/to/centos-image.qcow2 指定CentOS映象檔案的路徑。
centos-image 是你給映象起的名稱。
此時的流量是先是走了OpenStack的管理網,存取了Glance映象服務,然後Glance作為使用者端走Public 網路存取Ceph叢集,將資料儲存在後端Ceph叢集中。(管理網一般是千兆網路,而Ceph 無論是Public 還是 Cluster 網路一般都是萬兆及以上高速網路。)
window映象動輒10GB的大小,上傳一個映象少則幾分鐘,多則1個小時,那映象上傳的過程可以發現,瓶頸是在OpenStack管理網上,如果我們傳檔案時不走OpenStack管理網,就能解決該問題。
openstack image create命令建立一個空映象並記錄其uuid .- 通過rbd命令直接將映象檔案傳到Ceph後端,然後給其做快照,並打上快照保護的標記.
- 設定glance映象location url 為rbd的路徑。
此過程只是在第一步,建立空映象時使用了OpenStack管理網,後面所有的操作都是走Public 網路。其效率提高了至少10倍。
思考2: Ceph兩個網段是必須的嗎?
測試環境中是可以將兩個網路合併為一個網路,但是生產環境中是強烈不建議這樣使用的。
- 從隔離角度來說會造成Public 網路流量過高時,影響叢集的穩定性,
- 從安全的角度,Public網路是非安全網路,而Cluster網路是安全的網路。
此時我們是一個測試環境就簡單規劃為一個網路 192.168.200.0/24
2、 Mon 部署
一個Ceph叢集至少需要一個Mon和少量OSD,部署一個Mon 需要提前先了解下如下幾個概念
-
Unique Identifier: 叢集唯一識別符號,在叢集中顯示為fsid, (由於最初的ceph叢集主要支援檔案系統,所以最初fsid代表檔案系統ID,現在ceph叢集也支援了塊儲存和物件儲存,但是這個名字確保留下來。檔案儲存是最先被規劃的,相對物件儲存和塊儲存,卻是最後生產可用的。)

-
Cluster Name 叢集名字,如果不指定預設為ceph,注意如果是多個ceph叢集的環境需要指定。
當一個節點做為使用者端要存取兩個Ceph叢集 cluster1 和 cluster2 時,需要在ceph 命令指定引數
ceph --cluster CLUSTER cluster name
-
Monitor Name: Mon名字,預設mon使用主機名為自Mon節點的名字,因此需要做好域名解析。
-
Monitor Map:啟動初始monitor需要生成monitor map。monitor對映需要fsid,叢集的名字以及一個主機名或IP地址。( 在生活中我們去一個陌生地方會先查地圖(map),同理mon第一次初始化和查詢同伴時也需要Mon Map)
-
Keyring :Ceph 認證金鑰環,用於叢集身份認證。Cephx認證的不僅有使用者端使用者(比如某使用者端要想執行命令來操作叢集,就要有登入Ceph的金鑰),也有Ceph叢集的伺服器,這是一種特殊的使用者型別MON/OSD/MDS。也就是說,Monitor、OSD、MDS都需要賬號和密碼來登入Ceph系統。因此這裡的Keyring既有叢集內元件的,也有用於管理的Keyring 。(這一點和K8s叢集的認證很類似,都是採用雙向認證)
瞭解上述這些是為了能看懂Ceph的組態檔,但是我們在部署時可以不寫組態檔,但是在生產環境中強烈建議是手動編寫組態檔
2.1 MON 部署前置任務
環境說明:
部署環境 vmware 虛擬機器器
虛擬機器器系統 CentOS Linux release 7.9.2009 (Core)
部署ceph版本: 14.2.22 nautilus (stable)
| ip | 主機名 | 角色 | 磁碟 |
|---|---|---|---|
| 192.168.200.11 | mon01 | mon mgr osd | sdb,sdc,sde,sdf |
1 修改主機名,新增hosts 檔案解析
hostnamectl set-hostname mon01
echo "192.168.200.11 mon01" >> /etc/hosts
2 關閉防火牆和seliux
systemctl stop firewalld
setenforce 0
getenforce
#Disabled
3 設定ceph 的yum 源,這裡使用國內的aliyun的映象站點
cat > /etc/yum.repos.d/ceph.repo <<EOF
[ceph]
name=ceph
baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/
gpgcheck=0
EOF
4 檢查repo
yum repolist
5 自身免密
ssh-keygen -t rsa
#自己的管理IP
ssh-copy-id mon01:
6 安裝ceph 包和其依賴包
yum install -y snappy leveldb gdisk python-argparse gperftools-libs ceph
檢查安裝包

檢查ceph使用者端的版本
[root@mon01 ~]# ceph -v
ceph version 14.2.22 (ca74598065096e6fcbd8433c8779a2be0c889351) nautilus (stable)
【注意】安裝了ceph 的基礎元件包之後,系統預設在/var/lib/ceph目錄下生成了一系列的目錄如下

而且其屬主和屬組都是ceph使用者。為什麼強調這個,在很多利舊的環境中,在清理叢集時清理目錄要清理這些目錄下的檔案。如果不清理,或者清理不乾淨,在ceph多次部署時會產生各種問題,本人在生產環境中就遇見過多次。檔案清理不徹底,檔案許可權不正確的問題。
這裡提供一個生產環境中清理ceph叢集的命令
#停止服務
systemctl stop ceph-osd.target
systemctl stop ceph-mon.target
systemctl stop ceph-mgr.target
#刪除檔案
rm -f /var/lib/ceph/bootstrap-mds/ceph.keyring
rm -f /var/lib/ceph/bootstrap-mgr/ceph.keyring
rm -f /var/lib/ceph/bootstrap-osd/ceph.keyring
rm-f /var/lib/ceph/bootstrap-rbd/ceph.keyring
rm -f /var/lib/ceph/bootstrap-rbd-mirror/ceph.keyring
rm -f /var/lib/ceph/bootstrap-rgw/ceph.keyring
rm -rf /etc/ceph/*
rm -fr /var/lib/ceph/mon/*
rm -fr /var/lib/ceph/mgr/*
rm -rf /etc/systemd/system/multi-user.target.wants/ceph-volume*
rm -rf /etc/systemd/system/ceph-osd.target.wants/ceph-osd*
取消osd掛載
umount /var/lib/ceph/osd/*
rm -rf /var/lib/ceph/osd/*
rm -f /var/log/ceph/*
#刪除lv vg pv 分割區資訊
for i in `ls /dev/ | grep ceph-`; do j=/dev/$i/osd*; lvremove --force --force $j; done
for i in $(vgdisplay |grep "VG Name"|awk -F' ' '{print $3}'); do vgremove -y $i; done
for j in $(pvdisplay|grep 'PV Name'|awk '{print $3}'); do pvremove --force --force $j; done
vgscan --cache
pvscan --cache
lvscan --cache
2.2 Mon 部署
1 生成uuid 即叢集的fsid,即叢集的唯一識別符號
[root@mon01 ~]# uuidgen
51be96b7-fb6b-4d68-8798-665278119188
2 安裝完ceph元件包之後,已經生成了/etc/ceph目錄
接下來我們補充下ceph.conf 的組態檔
cat > /etc/ceph/ceph.conf <<EOF
fsid = 51be96b7-fb6b-4d68-8798-665278119188
mon_initial_members = mon01
mon_host = 192.168.200.11
public_network = 192.168.200.0/24
#cluster_network = 192.168.200.0/24
EOF
- fsid 對應叢集id
- mon_initial_member 對應初始化的mon主機名,
- mon_host 對應其IP地址
- public_network 和cluster_network 則對應了之前介紹的公共網路和叢集網路。
3、生成mon的私鑰檔案,進行身份驗證
上文中提到叢集內的元件存取也是需要認證的,Ceph 預設是使用Cephx 協定進行認證,此時分別給mon 和bootstrap-osd 和client.admin 來生成私鑰檔案
- mon mon 私鑰檔案,用於mon進行身份認證
- bootstrap-osd 是當你新增一個新的 OSD 到 Ceph 叢集時,需要向叢集引導這個 OSD。這個引導過程涉及到向 OSD 分配一個獨特的識別符號,併為其生成一個金鑰以便在叢集內進行身份驗證。
- client.admin 用於叢集管理員進行管理使用的身份認證。
# mon key
ceph-authtool --create-keyring /tmp/ceph.mon.keyring \
--gen-key -n mon. --cap mon 'allow *'
#bootstarp-osd key
ceph-authtool --create-keyring /var/lib/ceph/bootstrap-osd/ceph.keyring \
--gen-key -n client.bootstrap-osd --cap mon 'profile bootstrap-osd' \
--cap mgr 'allow r'
#client.admin key
ceph-authtool --create-keyring /etc/ceph/ceph.client.admin.keyring \
--gen-key -n client.admin --cap mon 'allow *' --cap osd 'allow *'\
--cap mds 'allow *' --cap mgr 'allow *'
cat /etc/ceph/ceph.client.admin.keyring
檢視其結構也很容易理解,key 表示其私鑰檔案,caps mds = allow * ,表示對mds 擁有了所有的許可權,其他同理。
[client.admin]
key = AQCni2NlDuN7ERAAYr/aL5A5R0OJFeBkwmrBjQ==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
4、匯入key到mon.keyring 檔案中
將client.admin 和bootstrap-osd key,匯入到mon的 keyring 檔案中。並將keyring 檔案複製到/etc/ceph/目錄下
ceph-authtool /tmp/ceph.mon.keyring --import-keyring \
/etc/ceph/ceph.client.admin.keyring
#將bootstap-osd的key 檔案匯入並複製到了 /var/lib/ceph/bootstrap-osd/ceph.keyring
ceph-authtool /tmp/ceph.mon.keyring --import-keyring \
/var/lib/ceph/bootstrap-osd/ceph.keyring
importing contents of /var/lib/ceph/bootstrap-osd/ceph.keyring into /tmp/ceph.mon.keyring
檢視mon此時的keyring 檔案,驗證client.admin和client.bootstrap-osd keyring 已經匯入
[root@mon01 ceph]# cat /tmp/ceph.mon.keyring
[mon.]
key = AQD8h2NlYzQWLRAA306ur5iOEjoHwarGx77FFg==
caps mon = "allow *"
[client.admin]
key = AQCni2NlDuN7ERAAYr/aL5A5R0OJFeBkwmrBjQ==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
[client.bootstrap-osd]
key = AQCKi2NlASwkDxAAPPXUeSwX8nQJJcJao+bgCw==
caps mgr = "allow r"
caps mon = "profile bootstrap-osd"
5 修改許可權為ceph
chown ceph:ceph /tmp/ceph.mon.keyring
6、建立monmap
#單節點mon環境
monmaptool --create --add {hostname} {ip-address} --fsid {uuid} /tmp/monmap
monmaptool --create --add mon01 192.168.200.11 \
--fsid 51be96b7-fb6b-4d68-8798-665278119188 /tmp/monmap
#多節點mon環境
monmaptool --create --add mon01 192.168.200.11 \
--add node2 192.168.200.12 --add node3 192.168.200.13 \
--fsid 51be96b7-fb6b-4d68-8798-665278119188 /tmp/monmap
6.1、什麼是monmap? monmap是做什麼用的?
-
Monitor Map: Ceph 叢集中的 Monitors 負責維護叢集的狀態資訊、監控資料等。monmap 包含了 Monitors 的資訊,包括它們的主機名、IP地址以及叢集的唯一標識(FSID)等。
-
啟動 Monitors: 在 Ceph 叢集的啟動過程中,Monitors 首先需要從 monmap 中獲取叢集的初始資訊。monmaptool 的這個命令就是為了生成一個初始化的 monmap 檔案,以供 Monitors 使用。這個檔案會在 Monitors 啟動時被載入。
-
維護叢集狀態: 一旦 Monitors 啟動,它們會使用 monmap 檔案來維護叢集的狀態。Monitors 之間會相互通訊,共用叢集的狀態資訊。monmap 中包含的資訊幫助 Monitors 確定其他 Monitor 節點的位置,從而進行叢集管理和資料的一致性。
-
Monitor 選舉: 當一個 Monitor 節點發生故障或新的 Monitor 節點加入叢集時,叢集需要進行 Monitor 的選舉。monmap 包含的資訊有助於叢集中的 OSD(Object Storage Daemon)和使用者端找到 Monitor 節點,並確保選舉過程正確進行。
6.2 、怎麼驗證和檢視當前叢集的monmap ?
[root@mon01 tmp]# monmaptool --print /tmp/monmap
monmaptool: monmap file monmap
epoch 0
fsid 51be96b7-fb6b-4d68-8798-665278119188 #叢集id
last_changed 2023-11-27 03:23:10.956578
created 2023-11-27 03:23:10.956578
min_mon_release 0 (unknown)
0: v1:192.168.200.11:6789/0 mon.mon01 #mon節點資訊
6.3 、寫錯了怎麼覆蓋寫?
# --clobber 引數 將會覆蓋寫
monmaptool --create --add mon01 192.168.200.12 --fsid \
91e36b46-8e6b-4ac6-8292-0a8ac8352907 /tmp/monmap --clobber
7 修改ceph 許可權
chown -R ceph:ceph /tmp/{monmap,ceph.mon.keyring}
8 建立mon01 工作目錄
#mkdir /var/lib/ceph/mon/{cluster-name}-{hostname}
sudo -u ceph mkdir /var/lib/ceph/mon/ceph-mon01 #預設cluster-name 就是ceph
9 用monitor map和keyring填充monitor守護程式,生mon01的資料庫檔案
#sudo -u ceph ceph-mon [--cluster {cluster-name}] \
#--mkfs -i {hostname} --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring
sudo -u ceph ceph-mon --cluster ceph --mkfs -i mon01 \
--monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring
驗證
[root@mon01 ceph-mon01]# cat keyring
[mon.]
key = AQD8h2NlYzQWLRAA306ur5iOEjoHwarGx77FFg==
caps mon = "allow *"
[root@mon01 ceph-mon01]# ls
keyring kv_backend store.db
[root@mon01 ceph-mon01]# pwd
/var/lib/ceph/mon/ceph-mon01
【提示】mon 完成之後,即使key誤刪了,但admin keyring還在,可以使用ceph auth list 檢視叢集所有的keyring
完成第9步之後,在以systemd的方式拉起mon01的守護進場就算完成了mon的安裝,但是在拉其服務之前,我們先介紹下兩個概念,副本和糾刪碼
3、副本 or 糾刪碼
Ceph儲存池在設定有兩種分別是 副本池(Replicated Pool)和糾刪碼池(Erasure-coded Pool),這兩種型別也很好理解,如果是副本池,其存放是以副本的方式存放的,每份副本其資料是完全一致的,相當於1份資料存多份來冗餘。
糾刪碼池一般Ceph是採用向前錯誤更正碼(Forward Error Correction,FEC)
FEC程式碼將K個chunk(以下稱為塊)資料進行冗餘校驗處理,得到了N個塊資料。這N個塊資料既包含原資料,也包括校驗資料。這樣就能保證K個塊中如果有資料丟失,可以通過N個塊中包含的校驗資料進行恢復。
具體地說,在N=K+M中,變數K是資料塊即原始數量;變數M代表防止故障的冗餘塊的數量;變數N是在糾刪碼之後建立的塊的總數。這種方法保證了Ceph可以存取所有原始資料,可以抵抗任意N–K個故障。例如,在K=10、N=16的設定中,Ceph會將6個冗餘塊新增到10個基本塊K中。在M=N–K(即16–10=6)的設定中,Ceph會將16個塊分佈在16個OSD中,這樣即使6個OSD掉線,也可以從10個塊中重建原始檔案,以確保不會丟失資料,提高容錯能力。
簡單來說就是 K個資料塊 + M 個冗餘塊 = N個總塊
【思考3】生產環境中我們是選副本還是糾刪碼呢?
效能優先選副本池,容量優先選糾刪碼。(本質上糾刪碼就是犧牲部分計算效能換儲存容量)
4 故障域也稱為冗餘級別
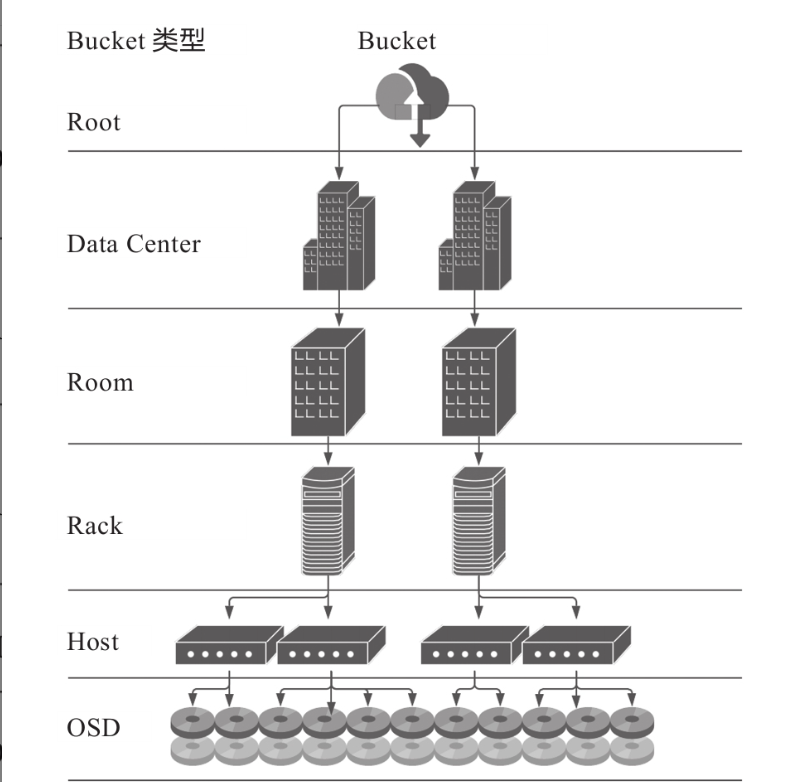
在實際的生產環境中我們的資料都是儲存在磁碟中的,磁碟對應OSD ,磁碟是伺服器上的一個元件,伺服器對應Host 而伺服器是在機架中存放的,一個機櫃RACK中有N個機架,而機櫃是屬於一個房間的ROOM,一個大型的資料中心(Data Center)可能有N個房間,而每個房間可能在同一個地區,也可以在不同地區。
對應其關係為 1Data Center = NRoom = NRACK = NHost = NOSD
總結:Ceph叢集中有很多硬體裝置,從上到下可能涉及某些邏輯單元,類似資料中心→裝置所在機房→機架→行→伺服器→OSD槽等的關係。那麼,如何描述這些邏輯單元的關係、
Bucket 專門用於描述以上提到的這些邏輯單元屬性,以便將來對這些屬性按樹狀結構進行組織。(Bucket邏輯檢視)(選取規則RuleSet) (磁碟裝置Device) 組成了ceph的Crush Map.(混個臉熟即可,將來會重點介紹)
在ceph中使用 ceph osd tree 就可用檢視該檢視
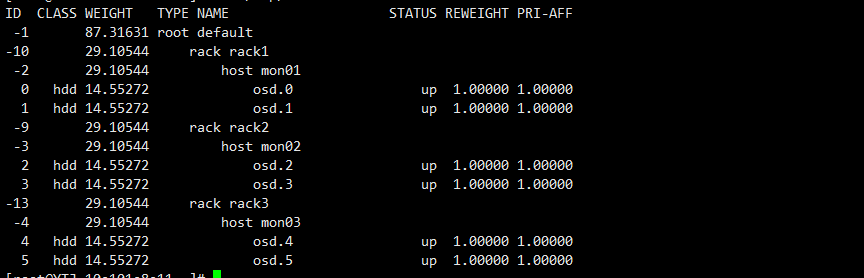
上述檢視中有3個機架 rack1 rack2 rack3 ,每個rack下分別由一個mon主機和兩個osd 裝置。
無論是副本池還是糾刪碼池,資料都是儲存在osd中的,如果是副本池,預設3副本,那這3個osd,怎麼選取了?
我們先不討論Crush演演算法選取OSD的問題,我們就考慮一個問題,資料冗餘問題。如果我們3個OSD 都在同一個節點,該節點down了,則我們資料都存取不了了,則我們稱我們資料的冗餘級別是OSD的級別的(Host下一級)。
如果我們的選取的3個OSD都在不同節點上(Host),但是這三個節點都在同一個機櫃中(Rack),如果機櫃斷電了,則我們的資料無法存取了,我們稱我們的冗餘級別是節點級別(Host),同理3個OSD 在不同的機櫃中,但在同一個ROOM中,我們稱我們資料的冗餘級別是RACK級別。
那我們怎麼定義資料冗餘級別了,osd_crush_chooseleaf_type 引數則可以定義,其值是一個數位 代表了型別。
ceph osd crush dump #可以檢視到其type
# types
type 0 osd
type 1 host
type 2 chassis #一般不使用,伺服器機框。
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
數位0 代表了其故障域是osd級別,雖然這種說法不嚴謹但是方便理解。後面我們在學習了Crush演演算法第二步之後就知道其OSD 是如何通過Bucket 和RuleSet 來選取OSD的,這裡我們簡單理解就是將3副本分散到3個osd就能滿足要求。如果是數位1 表示其冗餘級別是host 級別。要在不同的節點上,其他同理。
此實驗環境中我們osd都在同一個節點上因此我們將其引數值設定為0
最後ceph.conf 檔案修該為如下

最後我們啟動mon服務
systemctl daemon-reload
systemctl start ceph-mon@mon01
systemctl enable ceph-mon@mon01
檢視叢集狀態
[root@mon01 ceph-mon01]# ceph -s
cluster:
id: 51be96b7-fb6b-4d68-8798-665278119188
health: HEALTH_WARN
mon is allowing insecure global_id reclaim
1 monitors have not enabled msgr2
services:
mon: 1 daemons, quorum mon01 (age 6s)
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
如果ceph狀態顯示如上圖,恭喜你,表示第一個mon已經成功部署了.

mon元件可以說是Ceph最重要的元件了,因此本章節對其每一步操作都做了詳細說明,剩下的mgr osd的部署則會簡單很多,由於篇幅所限,我們將在下一章節繼續。
