帶你瞭解大語音模型的前世今生
本文分享自華為雲社群《大語言模型的前世今生》,作者: 碼上開花_Lancer 。
大規模語言模型(Large Language Models,LLM),也稱大規模語言模型或大型語言模型,是一種由包含數百億以上引數的深度神經網路構建的語言模型,使用自監督學習方法通過大量無標註文字進行訓練。自2018 年以來,Google、OpenAI、Meta、百度、華為等公司和研究機構都相繼釋出了包括BERT,GPT 等在內多種模型,並在幾乎所有自然語言處理任務中都表現出色。2019 年大模型呈現爆發式的增長,特別是2022 年11 月ChatGPT(Chat Generative Pre-trained Transformer)釋出後,更是引起了全世界的廣泛關注。使用者可以使用自然語言與系統互動,從而實現包括問答、分類、摘要、翻譯、聊天等從理解到生成的各種任務。大型語言模型展現出了強大的對世界知識掌握和對語言的理解。
一、大規模語言模型基本概念
語言是人類與其他動物最重要的區別,而人類的多種智慧也與此密切相關。邏輯思維以語言的形式表達,大量的知識也以文字的形式記錄和傳播。如今,網際網路上已經擁有數萬億以上的網頁資源,其中大部分資訊都是以自然語言描述。因此,如果人工智慧演演算法想要獲取知識,就必須懂得如何理解人類使用的不太精確、可能有歧義、混亂的語言。語言模型(Language Model,LM)目標就是建模自然語言的概率分佈。詞彙表V 上的語言模型,由函數P(w1w2...wm) 表示,可以形式化地構建為詞序列w1w2...wm 的概率分佈,表示詞序列w1w2...wm 作為一個句子出現的可能性大小。由於聯合概率P(w1w2...wm) 的引數量十分巨大,直接計算P(w1w2...wm) 非常困難。按照《現代漢語詞典(第七版)》包含7 萬單詞,句子長度按照20 個詞計算,模型引數量達到7.9792×1096的天文數位。中文的書面語中超過100 個單詞的句子也並不罕見,如果要將所有可能都納入考慮,模型的複雜度還會進一步急劇增加,無法進行儲存和計算。為了減少P(w1w2...wm) 模型的引數空間,可以利用句子序列通常情況下從左至右的生成過程進行分解,使用鏈式法則得到:
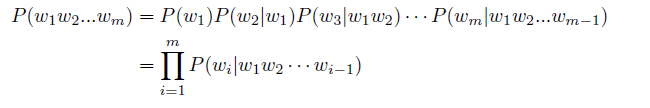
由此,w1w2...wm 的生成過程可以看作單詞逐個生成的過程。首先生成w1,之後根據w1 生成w2,再根據w1 和w2 生成w3,以此類推,根據前m− 1 個單詞生成最後一個單詞wm。例如:對於句子「把努力變成一種習慣」的概率計算,使用上述公式可以轉化為:

通過上述過程將聯合概率P(w1w2...wm) 轉換為了多個條件概率的乘積。但是,僅通過上述過程模型的引數空間依然沒有下降,P(wm|w1w2...wm.1) 的引數空間依然是天文數位。為了解決上述問題,可以進一步假設任意單詞wi 出現的概率只與過去n − 1 個詞相關,即:
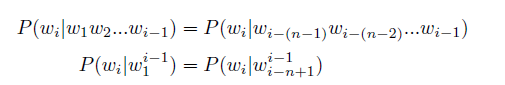
滿足上述條件的模型被稱為n 元語法或n 元文法(n-gram) 模型。其中n-gram 表示由n 個連續單詞構成的單元,也被稱為n 元語法單元。儘管n 元語言模型能緩解句子概率為0 的問題,但語言是由人和時代創造的,具備無窮的可
能性,再龐大的訓練語料也無法覆蓋所有的n-gram,而訓練語料中的零頻率並不代表零概率。因此,需要使用平滑技術(Smoothing)來解決這一問題,對所有可能出現的字串都分配一個非零的概率值,從而避免零概率問題。平滑是指為了產生更合理的概率,對最大似然估計進行調整的一類方法,也稱為資料平滑(Data Smoothing)。平滑處理的基本思想是提高低概率,降低高概率,使整體的概率分佈趨於均勻。這類方法通常稱為統計語言模型(Statistical Language models,SLM)。n 語法模型整體上來看與訓練語料規模和模型的階數有較大的關係,不同的平滑演演算法在不同情況下的表現有較大的差距。平滑演演算法雖然較好的解決了零概率問題,但是基於稀疏表示的n 元語言模型仍然有三個較為明顯的缺點:(1)無法建模長度超過n 的上下文;(2)依賴人工設計規則的平滑技術;(3)當n 增大時,資料的稀疏性隨之增大,模型的引數量更是指數級增加,並且模型受到資料稀疏問題的影響,其引數難以被準確的學習。此外,n 語法中單詞的離散表示也忽略了詞之間的相似性。
因此,基於分散式表示和神經網路的語言模型逐漸成為了研究熱點。Bengio 等人在2000 年提出了使用前饋神經網路對P(wi|wi−n+1...wi−1) 進行估計的語言模型。詞的獨熱編碼被對映為一個低維稠密的實數向量,稱為詞向量(Word Embedding)。此後,迴圈神經網路、折積神經網路、端到端記憶網路等神經網路方法都成功應用於語言模型建模。相較於n 元語言模型,神經網路方法可以在一定程度上避免資料稀疏問題,有些模型還可以避免對歷史長度的限制,從而更好的建模長距離依賴關係。這類方法通常稱為神經語言模型(Neural Language Models,NLM)。深度神經網路需要採用有監督方法,使用標註資料進行訓練,因此,語言模型的訓練過程也不可避免需要構造訓練語料。但是由於訓練目標可以通過無標註文字直接獲得,從而使得模型的訓練僅需要大規模無標註文字即可語言模型也成為了典型的自監督學習(Self-supervised Learning)任務。網際網路的發展,使得大規模文字非常容易獲取,因此訓練超大規模的基於神經網路的語言模型也成為了可能。受到計算機視覺領域採用ImageNet對模型進行一次預訓練,使得模型可以通過海量影象充分學習如何提取特徵,然後再根據任務目標進行模型精調的正規化影響,自然語言處理領域基於預訓練語言模型的方法也逐漸成為主流。以ELMo 為代表的動態詞向量模型開啟了語言模型預訓練的大門,此後以GPT和BERT 為代表的基於Transformer 模型的大規模預訓練語言模型的出現,使得自然語言處理全面進入了預訓練微調正規化新時代。將預訓練模型應用於下游任務時,不需要了解太多的任務細節,不需要設計特定的神經網路結構,只需要「微調」預訓練模型,即使用具體任務的標註資料在預訓練語言模型上進行監督訓練,就可以取得顯著的效能提升。這類方法通常稱為預訓練語言模型(Pre-trained Language Models,PLM)。2020 年Open AI 釋出了包含1750 億引數的生成式大規模預訓練語言模型GPT-3(GenerativePre-trained Transformer 3)。開啟了大規模語言模型的時代。由於大規模語言模型的引數量巨大,如果在不同任務上都進行微調需要消耗大量的計算資源,因此預訓練微調正規化不再適用於大規模語言模型。但是研究人員發現,通過語境學習(Incontext Learning,ICL)等方法,直接使用大規模語言模型就可以在很多工的少樣本場景下取得了很好的效果。此後,研究人員們提出了面向大規模語言模型的提示詞(Prompt)學習方法、模型即服務正規化(Model as a Service,MaaS)、指令微調(Instruction Tuning)等方法,在不同任務上都取得了很好的效果。與此同時,Google、Meta、百度、華為等公司和研究機構都紛紛釋出了包括PaLM、LaMDA、T0等為代表的不同大型語言模型。
2022 年底ChatGPT 的出現,將大規模語言模型的能力進行了充分的展現,也引發了大規模語言模型研究的熱潮。Kaplan 等人在文獻中提出了縮放法則(Scaling Laws),指出模型的效能依賴於模型的規模,包括:引數數量、資料集大小和計算量,模型的效果會隨著三者的指數增加而線性提高。如圖1.1所示,模型的損失(Loss)值隨著模型規模的指數增大而線性降低。這意味著模型的能力是可以根據這三個變數估計的,提高模型引數量,擴巨量資料集規模都可以使得模型的效能可預測地提高。這為繼續提升大模型的規模給出了定量分析依據。
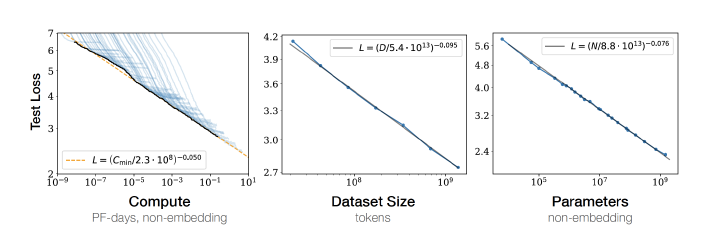
圖1.1 大規模語言模型的縮放法則(Scaling Laws)
二、大規模語言模型發展歷程
大規模語言模型的發展歷程雖然只有短短不到五年的時間,但是發展速度相當驚人,截止2023年6 月,國內外有超過百種大模型相繼釋出。中國人民大學趙鑫教授團隊在文獻按照時間線給出2019 年至2023 年5 月比較有影響力並且模型引數量超過100 億的大規模語言模型,如圖2.1 所示。大規模語言模型的發展可以粗略的分為如下三個階段:基礎模型、能力探索、突破發展。
基礎模型階段主要集中於2018 年至2021 年,2017 年Vaswani 等人提出了Transformer[ 架構,在機器翻譯任務上取得了突破性進展。2018 年Google 和Open AI 分別提出了BERT[1] 和GPT-1 模型,開啟了預訓練語言模型時代。BERT-Base 版本引數量為1.1 億,BERT-Large 的引數量為3.4 億,GPT-1 的引數量1.17 億。這在當時,相比其它深度神經網路的引數量已經是有數量級上提升。2019 年Open AI 又釋出了GPT-2,其引數量達到了15 億。此後,Google 也釋出了引數規模為110 億的T5 模型。2020 年Open AI 進一步將語言模型引數量擴充套件到1750 億,釋出了GPT-3。此後,國內也相繼推出了一系列的大規模語言模型,包括清華大學ERNIE(THU)、百度ERNIE(Baidu)、華為盤古-α 等。這個階段研究主要集中語言模型本身,包括僅編碼器(Encoder Only)、編碼器-解碼器(Encoder-Decoder)、僅解碼器(Decoder Only)等各種型別的模型結構都有相應的研究。模型大小與BERT 相類似的演演算法,通常採用預訓練微調正規化,針對不同下游任務進行微調。但是模型引數量在10 億以上時,由於微調的計算量很高,這類模型的影響力在當時相較BERT 類模型有不小的差距。
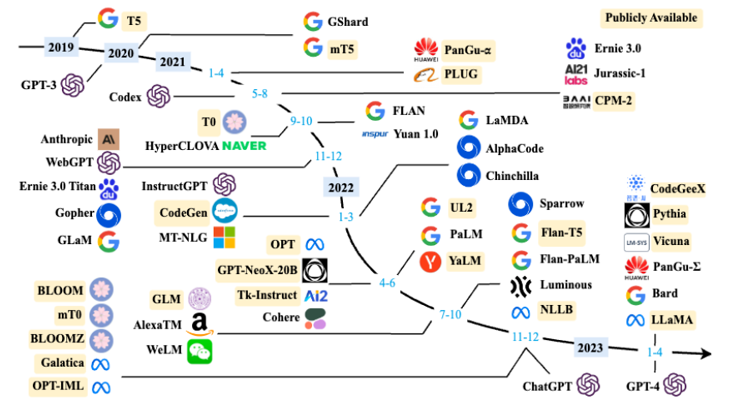
圖2.1 大規模語言模型發展時間線
能力探索階段集中於2019 年至2022 年,由於大規模語言模型很難針對特定任務進行微調,研究人員們開始探索在不針對單一任務進行微調的情況下如何能夠發揮大規模語言模型的能力。2019 年Radford 等人 就使用GPT-2 模型研究了大規模語言模型在零樣本情況下的任務處理能力。在此基礎上,Brown 等人在GPT-3模型上研究了通過語境學習(In-Context Learning)進行少樣本學習的方法。將不同任務的少量有標註的範例拼接到待分析的樣本之前輸入語言模型,用語言模型根據範例理解任務並給出正確結果。在包括TriviaQA、WebQS、CoQA 等評測集合都展示出了非常強的能力,在有些任務中甚至超過了此前的有監督方法。上述方法不需要修改語言模型的引數,模型在處理不同任務時無需花費的大量計算資源進行模型微調。但是僅依賴基於語言模型本身,其效能在很多工上仍然很難達到有監督學習效果,因此研究人員們提出了指令微調(Instruction Tuning)方案,將大量各型別任務,統一為生成式自然語言理解框架,並構造訓練語料進行微調。
突破發展階段以2022 年11 月ChatGPT 的釋出為起點。ChatGPT 通過一個簡單的對話方塊,利用一個大規模語言模型就可以實現問題回答、文稿撰寫、程式碼生成、數學解題等過去自然語言處理系統需要大量小模型訂製開發才能分別實現的能力。它在開放領域問答、各類自然語言生成式任務以及對話上文理解上所展現出來的能力遠超大多數人的想象。2023 年3 月GPT-4 釋出,相較於ChatGPT 又有了非常明顯的進步,並具備了多模態理解能力。GPT-4 在多種基準考試測試上的得分高於88% 的應試者,包括美國律師資格考試(Uniform Bar Exam)、法學院入學考試(Law School Admission Test)、學術能力評估(Scholastic Assessment Test,SAT)等。它展現了近乎「通用人工智慧(AGI)」的能力。各大公司和研究機構也相繼釋出了此類系統,包括Google 推出的Bard、百度的文心一言、科大訊飛的星火大模型、智譜ChatGLM、復旦大學MOSS 等。表1.1 給出了截止2023 年6 月典型開源和未開源大規模語言模型的基本情況。可以看到從2022 年開始大模型呈現爆發式的增長,各大公司和研究機構都在釋出各種不同型別的大模型。
三、 大規模語言模型構建流程
根據OpenAI 聯合創始人Andrej Karpathy 在微軟Build 2023 大會上所公開的資訊,OpenAI 所使用的大規模語言模型構建流程如圖2.2所示。主要包含四個階段:預訓練、有監督微調、獎勵建模、強化學習。這四個階段都需要不同規模資料集合、不同型別的演演算法,產出不同型別的模型,所需要的資源也有非常大的差別。

圖2.2 OpenAI 使用的大規模語言模型構建流程
預訓練(Pretraining)階段需要利用海量的訓練資料,包括網際網路網頁、維基百科、書籍、GitHub、論文、問答網站等,構建包含數千億甚至數萬億單詞的具有多樣性的內容。利用由數千塊高效能GPU 和高速網路組成超級計算機,花費數十天完成深度神經網路引數訓練,構建基礎語言模型(Base Model)。基礎大模型構建了長文字的建模能力,使得模型具有語言生成能力,根據輸入的提示詞(Prompt),模型可以生成文字補全句子。也有部分研究人員認為,語言模型建模過程中也隱含的構建了包括事實性知識(Factual Knowledge)和常識知識(Commonsense)在內的世界知識(World Knowledge)。根據他們的文獻介紹,GPT-3 完成一次訓練的總計算量是3640PFlops,按照NVIDIA A100 80G 和平均利用率達到50% 計算,需要花費近一個月時間使用1000 塊GPU 完成。
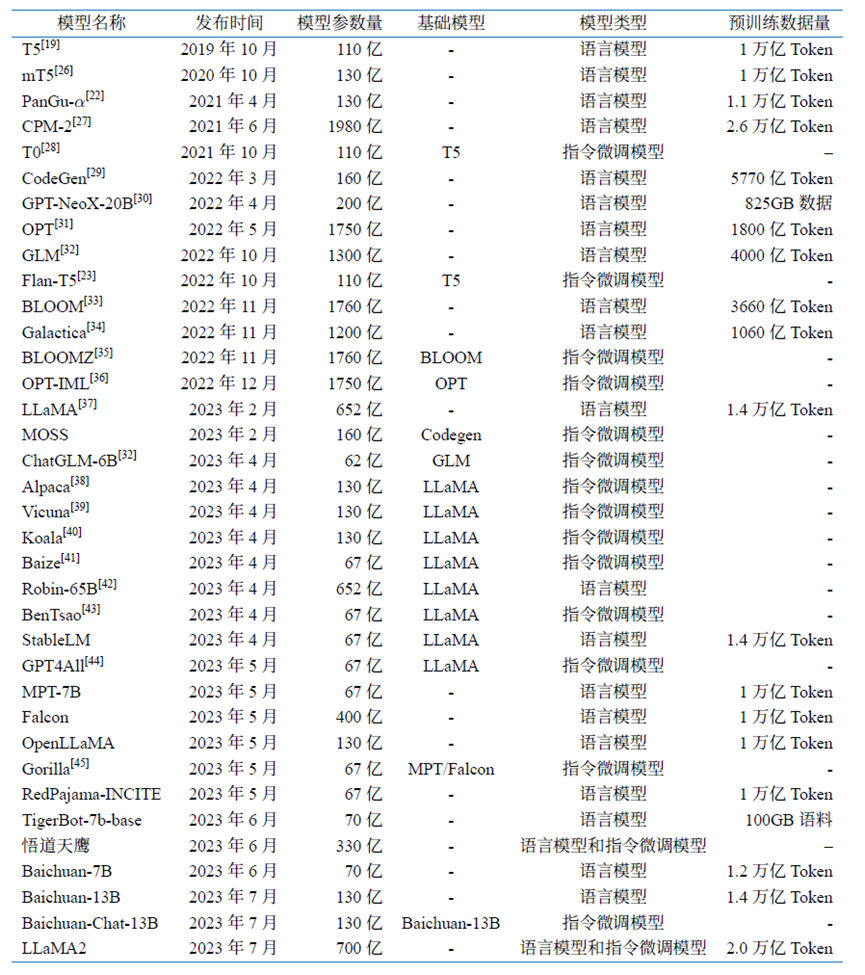
表1.1 典型開源大規模語言模型彙總
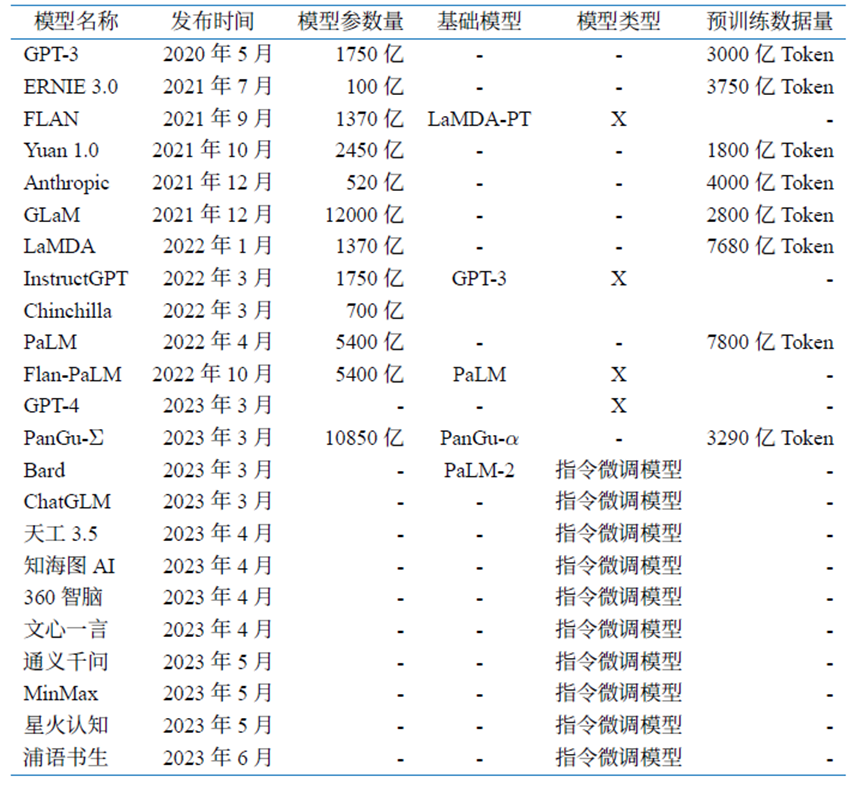
表1.2 典型閉源大規模語言模型彙總
有監督微調(Supervised Finetuning),也稱為指令微調(Instruction Tuning),利用少量高質量資料集合,包含使用者輸入的提示詞(Prompt)和對應的理想輸出結果。使用者輸入包括問題、閒聊對話、任務指令等多種形式和任務。
例如:提示詞(Prompt):復旦大學有幾個校區?
理想輸出:復旦大學現有4 個校區,分別是邯鄲校區、新江灣校區、楓林校區和張江校區。其中邯鄲校區是復旦大學的主校區,邯鄲校區與新江灣校區都位於楊浦區,楓林校區位於徐彙區,張江校區位於浦東新區。
利用這些有監督資料,使用與預訓練階段相同的語言模型訓練演演算法,在基礎語言模型基礎上再進行訓練,從而得到有監督微調模型(SFT 模型)。經過訓練的SFT 模型具備了初步的指令理解能力和上下文理解能力,能夠完成開放領域問題、閱讀理解、翻譯、生成程式碼等能力,也具備了一定的對未知任務的泛化能力。由於有監督微調階段的所需的訓練語料數量較少,SFT 模型的訓練過程並不需要消耗非常大量的計算。根據模型的大小和訓練資料量,通常需要數十塊GPU,花費數天時間完成訓練。SFT 模型具備了初步的任務完成能力,可以開放給使用者使用,很多類ChatGPT的模型都屬於該型別,包括:Alpaca、Vicuna、MOSS、ChatGLM-6B 等。很多這類模型效果也非常好,甚至在一些評測中達到了ChatGPT 的90% 的效果。當前的一些研究表明有監督微調階段資料選擇對SFT 模型效果有非常大的影響,因此如何構造少量並且高質量的訓練資料是本階段有監督微調階段的研究重點。
目標是構建一個文字質量對比模型,對於同一個提示詞,SFT模型給出的多個不同輸出結果的質量進行排序。獎勵模型(RM 模型)可以通過二分類模型,對輸入的兩個結果之間的優劣進行判斷。RM 模型與基礎語言模型和SFT 模型不同,RM 模型本身並不能單獨提供給使用者使用。獎勵模型的訓練通常和SFT 模型一樣,使用數十塊GPU,通過幾天時間完成訓練。由於RM 模型的準確率對於強化學習階段的效果有著至關重要的影響,因此對於該模型的訓練通常需要大規模的訓練資料。Andrej Karpathy 在報告中指出,該部分需要百萬量級的對比資料標註,而且其中很多標註需要花費非常長的時間才能完成。圖2.3給出了InstructGPT 系統中獎勵模型訓練樣本標註範例。可以看到,範例中文字表達都較為流暢,標註其質量排序需要制定非常詳細的規範,標註人員也需要非常認真的對標規範內容進行標註,需要消耗大量的人力,同時如何保持眾包標註人員之間的一致性,也是獎勵建模階段需要解決的難點問題之一。此外獎勵模型的泛化能力邊界也在本階段需要重點研究的另一個問題。如果RM 模型的目標是針對所有提示詞系統所生成輸出都能夠高質量的進行判斷,該問題所面臨的難度在某種程度上與文字生成等價,因此如何限定RM 模型應用的泛化邊界也是本階段難點問題。

圖2.3 InstructGPT 系統中獎勵模型訓練樣本標註範例
強化學習(Reinforcement Learning)階段根據數十萬使用者給出的提示詞,利用在前一階段訓練的RM 模型,給出SFT 模型對使用者提示詞補全結果的質量評估,並與語言模型建模目標綜合得到更好的效果。該階段所使用的提示詞數量與有監督微調階段類似,數量在十萬量級,並且不需要人工提前給出該提示詞所對應的理想回復。使用強化學習,在SFT 模型基礎上調整引數,使得最終生成的文字可以獲得更高的獎勵(Reward)。該階段所需要的計算量相較預訓練階段也少很多,通常也僅需要數十塊GPU,經過數天時間的即可完成訓練。文獻[給出了強化學習和有監督微調的對比,在模型引數量相同的情況下,強化學習可以得到相較於有監督微調好得多的效果。關於為什麼強化學習相比有監督微調可以得到更好結果的問題,截止到2023 年9 月也還沒有完整和得到普遍共識的解釋。此外,Andrej Karpathy 也指出強化學習也並不是沒有問題的,它會使得基礎模型的熵降低,從而減少了模型輸出的多樣性。在經過強化學習方法訓練完成後的RL 模型,就是最終提供給使用者使用具有理解使用者指令和上下文的類ChatGPT 系統。由於強化學習方法穩定性不高,並且超引數眾多,使得模型收斂難度大,再疊加RM 模型的準確率問題,使得在大規模語言模型如何能夠有效應用強化學習非常困難。
大語言模型研究進展之快,讓在自然語言處理領域開展了近三十年工作的我們也難以適從。其研究之火爆程度令人咋舌,自然語言處理領域重要國際會議EMNLP,2022年語言模型相關論文投稿佔比只有不到5%。然而,2023 年語言模型相關投稿則超過了EMNLP 整體投稿的20%。如何能夠兼顧大語言模型的基礎理論,又能夠在快速發展的各種研究中選擇最具有代表性的工作介紹給大家,是寫作中面臨的最大挑戰之一,受限於我們的認知水平和所從事的研究工作的侷限,對其中一些任務和工作的細節理解可能存在不少錯誤,也懇請專家、讀者批評指正!