Spring Cloud 整合
前言
玩SpringCloud之前最好懂SpringBoot,別搞撐死駱駝的事。Servlet整一下變成Spring;SSM封裝、加入東西就變為SpringBoot;SpringBoot再封裝、加入東西就變為SpringCloud
架構的演進
單體應用架構
單體架構:表示層、業務邏輯層和資料存取層即所有功能都在一個工程裡,打成一個jar包、war包進行部署,例如:GitHub 是基於 Ruby on Rails 的單體架構,直到 2021 年,為了讓超過一半的開發人員在單體程式碼庫之外富有成效地開展工作,GitHub 以賦能為出發點開始了向微服務架構的遷移
下圖伺服器用Tomcat舉例
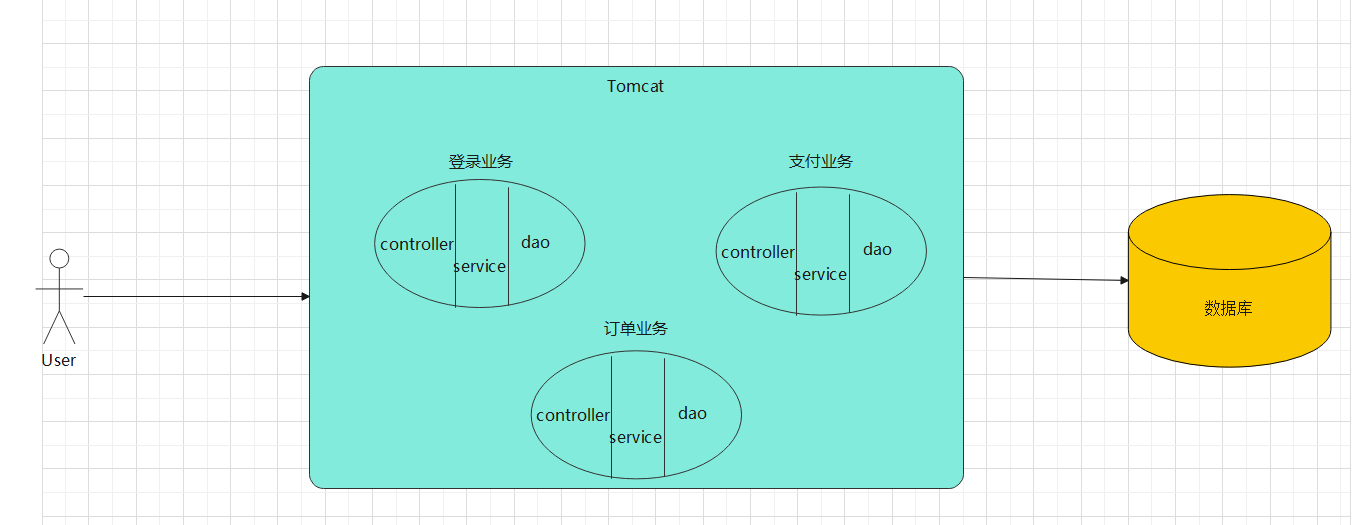
優點:
- 單體架構開發簡單,容易上手,開發人員只要集中精力開發當前工程
- 容易修改,只需要修改對應功能模組的程式碼,且容易找到相關聯的其他業務程式碼
- 部署簡單,由於是完整的結構體,編譯打包成jar包或者war包,直接部署在一個伺服器上即可
- 容易擴充套件,可以將某些業務抽出一個新的單體架構,用於獨立分擔壓力,也可以方便部署叢集
- 效能最高,對於單臺伺服器而言,單體架構獨享記憶體和cpu,不需要api遠端呼叫,效能損耗最小
缺點:
- 靈活度不高,隨著程式碼量增加,程式碼整體編譯效率下降
- 規模化,無法滿足團隊規模化開發,因為共同修改一個專案
- 應用擴充套件性比較差,只能橫向擴充套件,不能深度擴充套件,擴容只能只對這個應用進行擴容,不能做到對某個功能點進行擴容,關鍵性的程式碼改動一處多處會受影響
- 健壯性不高,任何一個模組的錯誤均可能造成整個系統的宕機
- 技術升級,如果想對技術更新換代,代價很大
演進:增加本地快取和分散式快取
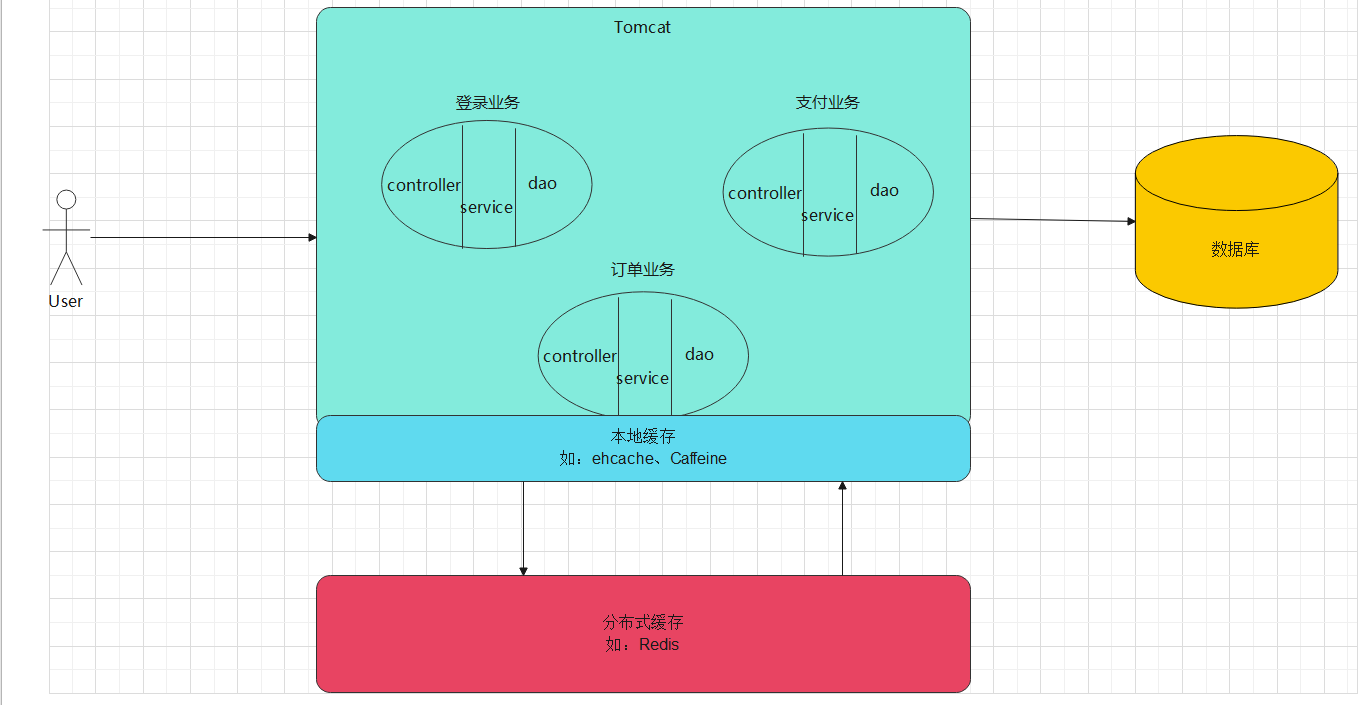
快取能夠將經常存取的頁面或資訊存起來,從而不讓其去直接存取資料庫,從而增巨量資料庫壓力,但是:這就會把壓力變成單機Tomcat來承受了,因此缺點就是:此時單機的tomcat又不足以支撐起高並行的請求
垂直應用架構:引入Nginx
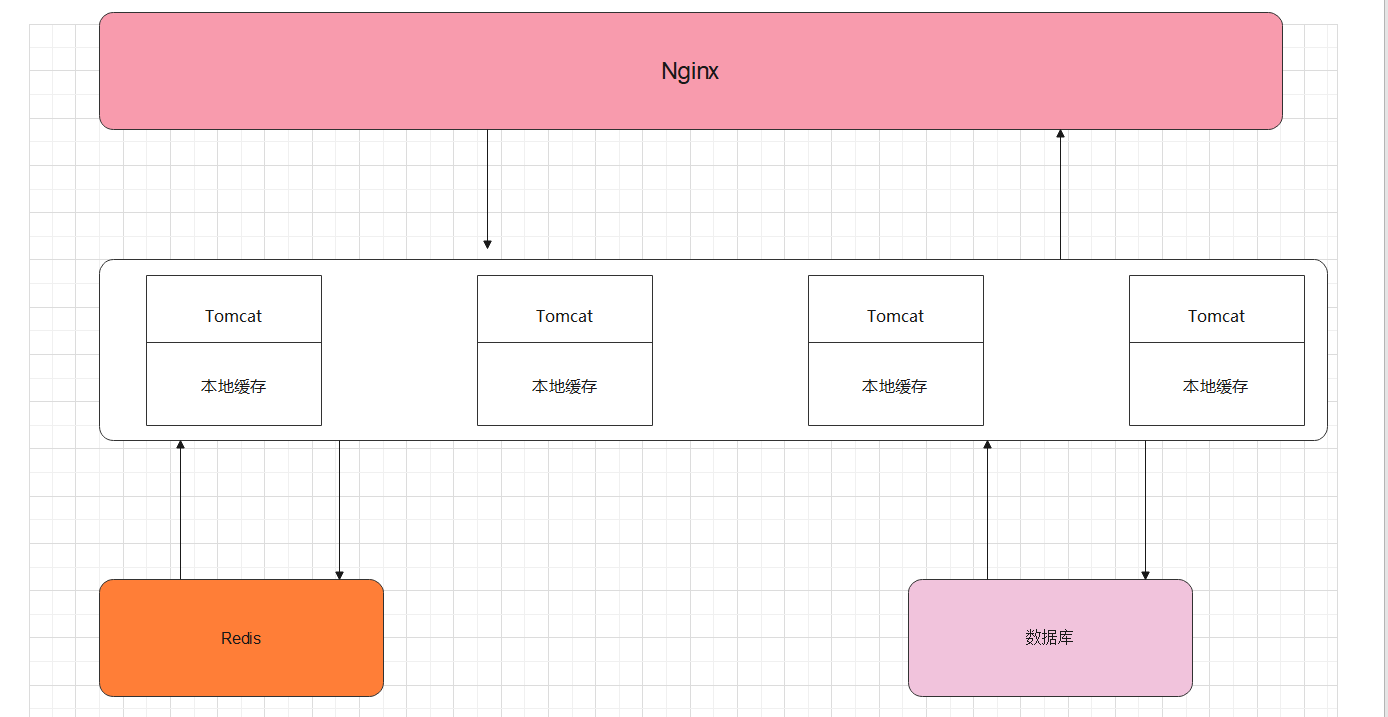
搭配N個tomcat,從而對請求"均衡處理",如:如果Nginx可以處理10000條請求,假設一個 tomcat可以處理100個請求,那麼:就需要100個tomcat從而實現每個tomcat處理100個請求(假設每個tomcat的效能都一樣 )
缺點就是資料庫不足以支撐壓力
後面就是將資料庫做讀寫分離
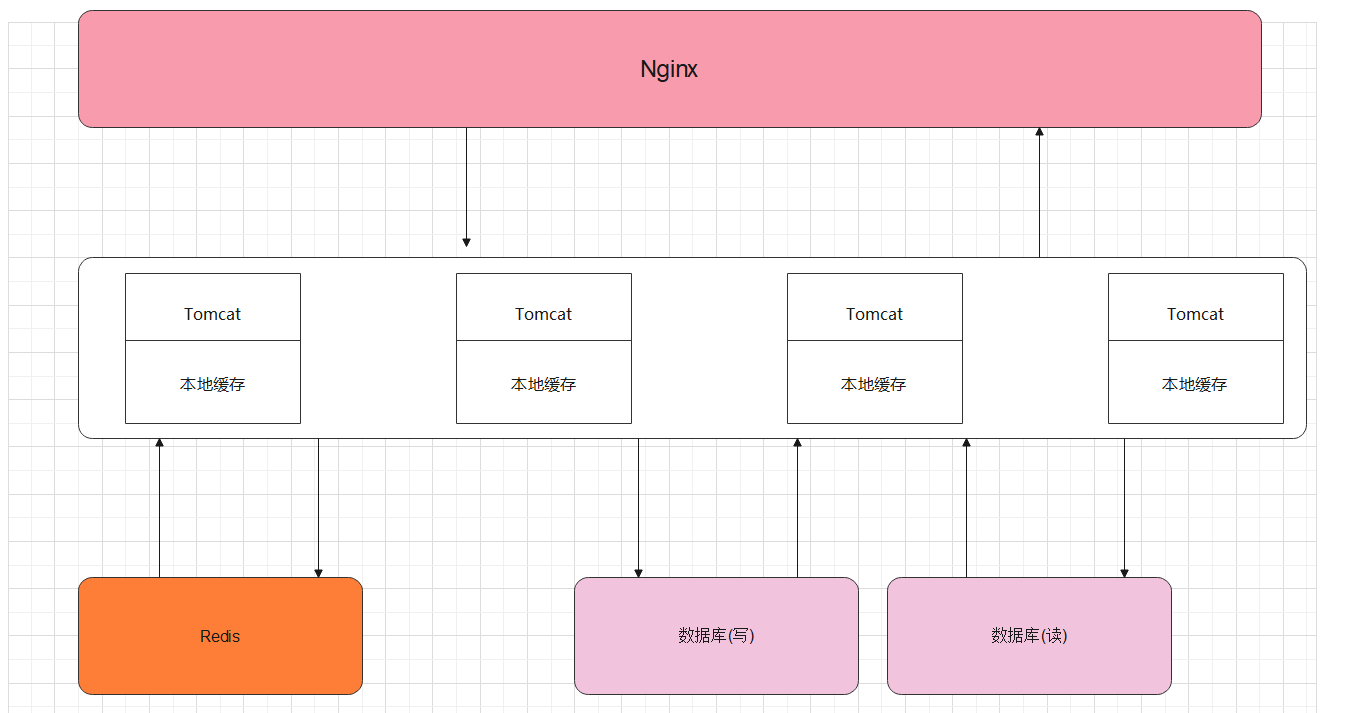
後面還有資料庫大表拆小表、大業務拆為小業務、複用功能抽離..............
面向服務架構:SOA
SOA指的是Service-OrientedArchitecture,即面向服務架構
隨著業務越來越多,程式碼越來越多,按照業務功能將本來一整塊的系統拆分為各個不同的子系統分別提供不同的服務,服務之間會彼此呼叫,錯綜複雜
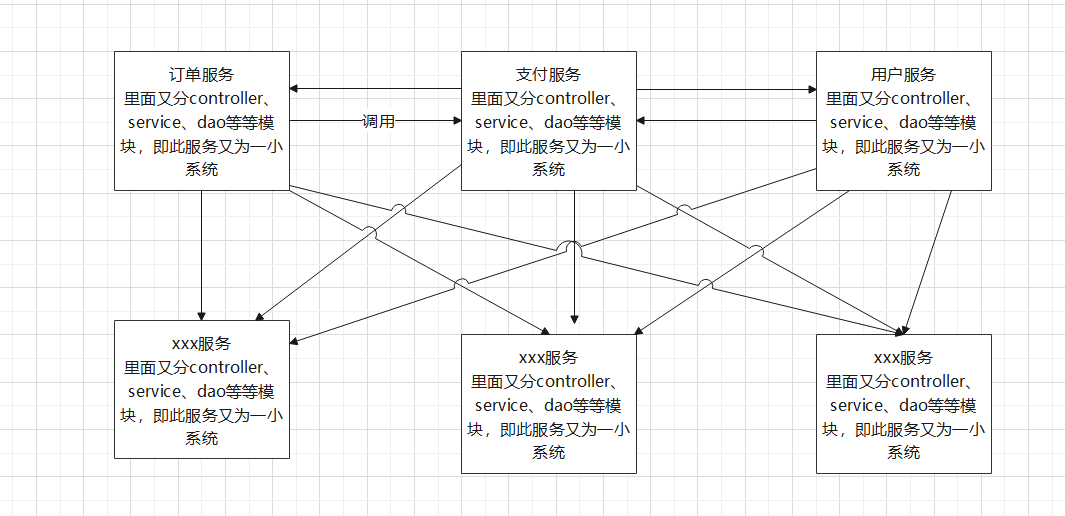
而SOA的思想就是基於前面拆成不同的服務之後,繼續再抽離一層,搞一個和事佬,即下圖的「統一介面」
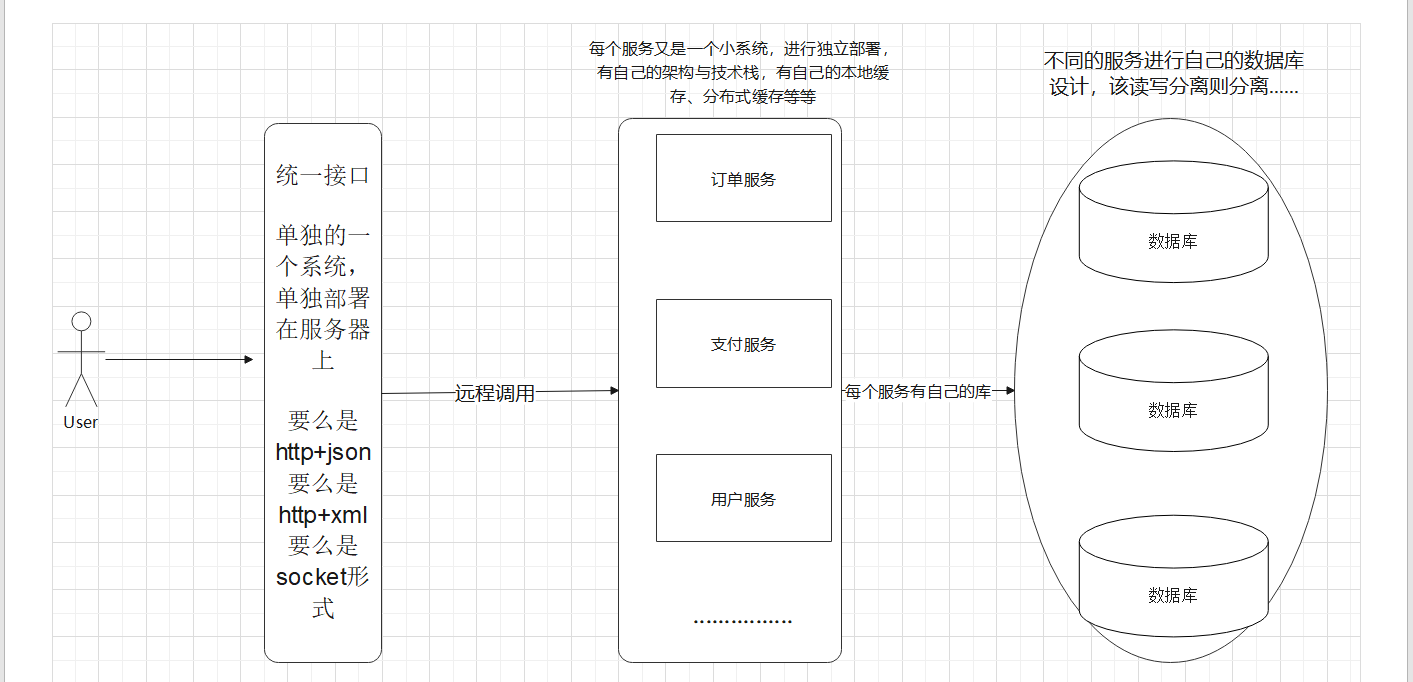
這樣不同服務之間呼叫就可以通過統一介面進行呼叫了,如:使用者服務需要呼叫訂單服務,那麼使用者服務去找統一介面,然後由統一介面去呼叫訂單服務,從而將訂單服務中需要的結果通過統一介面的http+json或其他兩種格式返回給使用者服務,這樣訂單服務就是服務提供者,使用者服務就是服務消費者,而統一介面就相當於是服務的註冊與發現
- 注意:上面這段話很重要,和後面要玩的微服務架構SpringCloud技術棧有關
學過設計模式的話,上面這種不就類似行為型設計模式的「中介者模式」嗎
上面這種若是反應不過來,那拆回單體架構就懂了
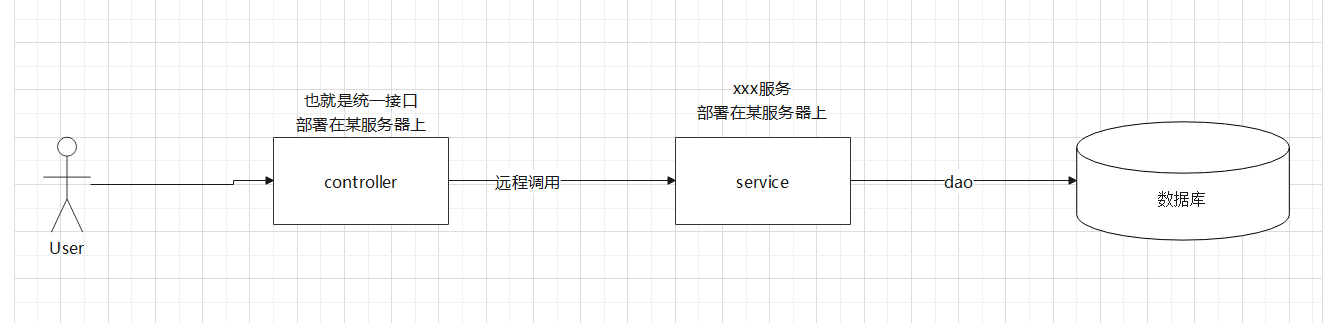
微服務架構
微服務架構是分散式架構的具體實現方式,和Spring的IOC控制反轉和DI依賴注入的關係一樣,一種是理論,一種是具體實現方案
微服務架構和前面的SOA架構是孿生兄弟,即:微服務架構是在SOA架構的基礎上,通過前人不斷實踐、不斷踩坑、不斷總結,新增了一些東西之後(如:鏈路追蹤、設定管理、負債均衡............),從而變出來的一種經過良好架構設計的分散式架構方案
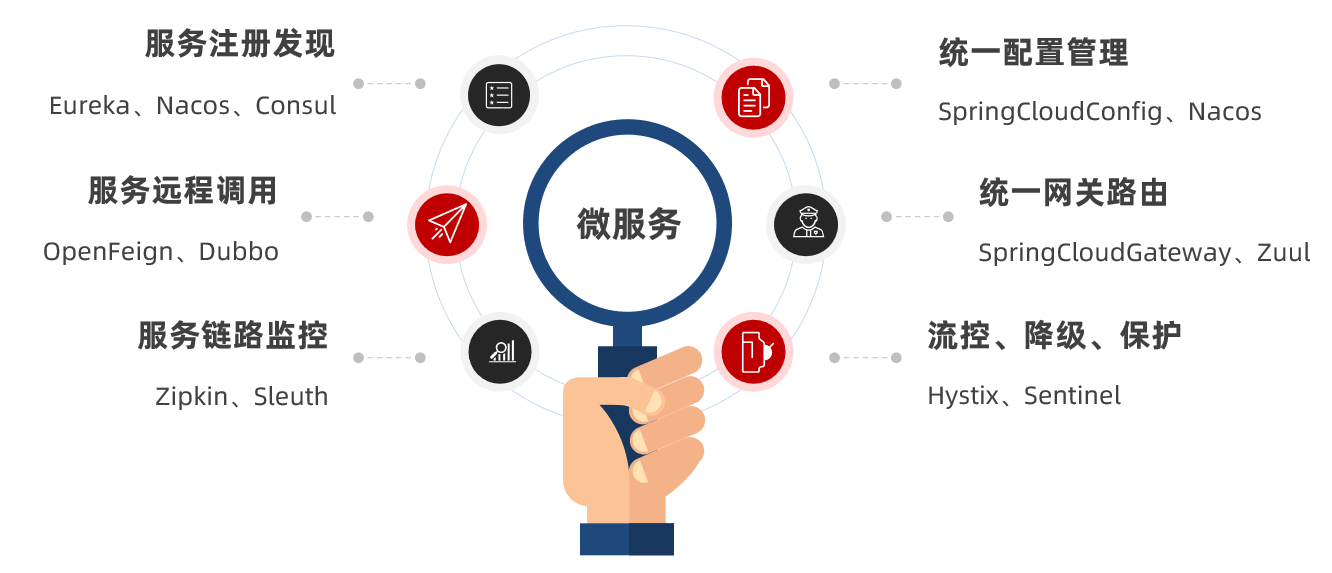
而廣泛應用的方案框架之一就是 SpringCloud
其中常見的元件包括:
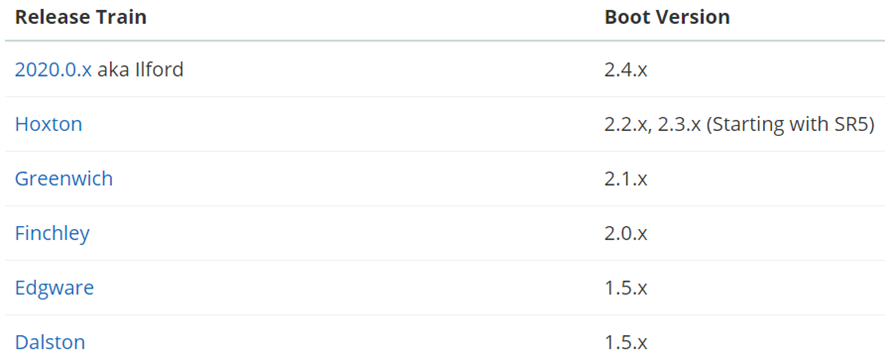
另外,SpringCloud底層是依賴於SpringBoot的,並且有版本的相容關係,如下:
因此。現在系統架構就變成了下面這樣,當然不是一定是下面這樣架構設計,還得看看架構師,看領導
因此,微服務技術知識如下
Eureka註冊中心
SpringCloud中文官網:https://www.springcloud.cc/spring-cloud-greenwich.html
SpringCloud英文網:https://spring.io/projects/spring-cloud
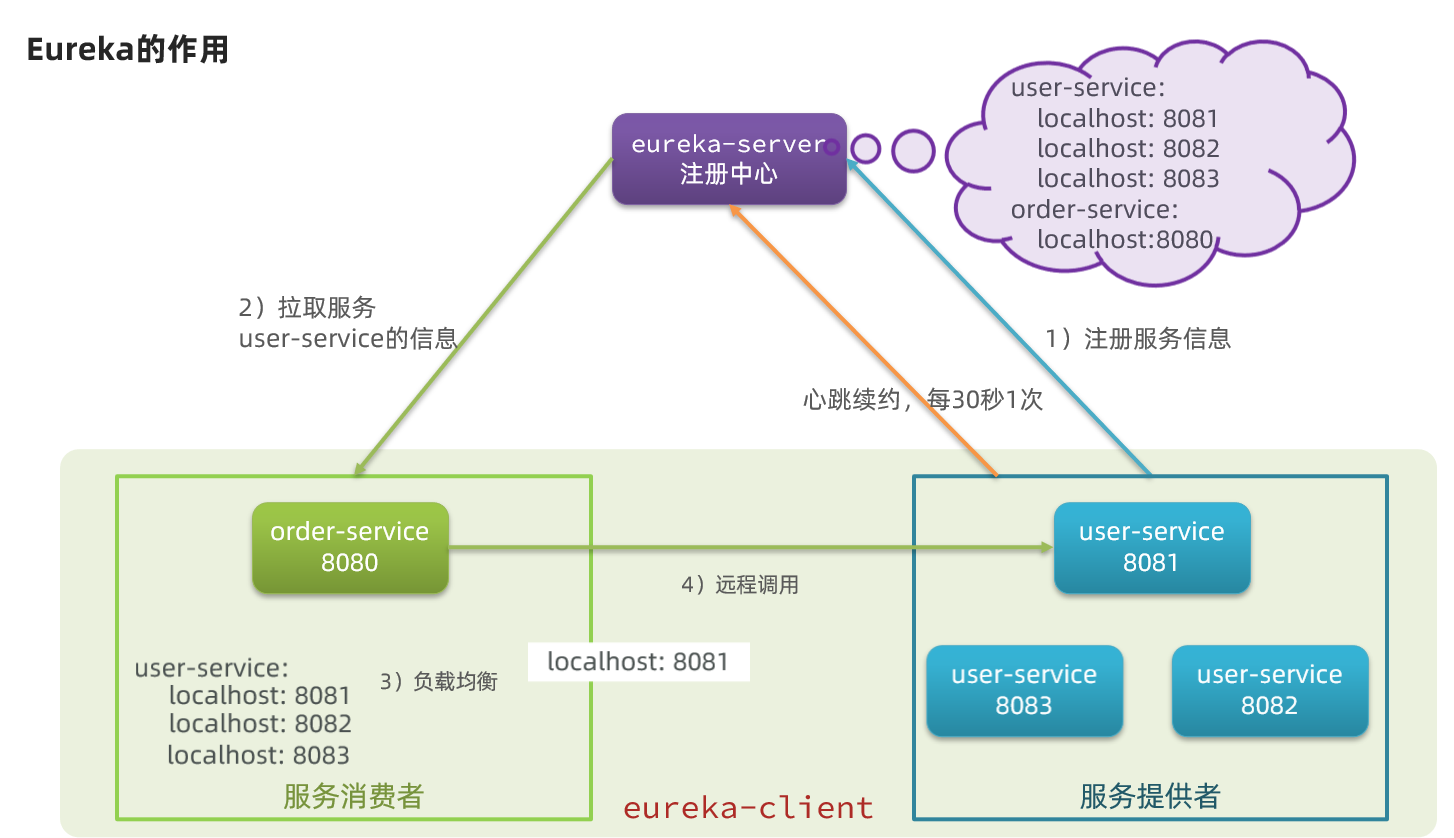
Eureka是什麼?
Eureka是Netflix開發的服務發現框架,本身是一個基於REST的服務,主要用於定位執行在AWS域中的中間層服務,以達到負載均衡和中間層服務故障轉移的目的。
SpringCloud將它整合在其子專案spring-cloud-netflix中,以實現SpringCloud的服務發現功能
偷張圖更直觀地瞭解一下:
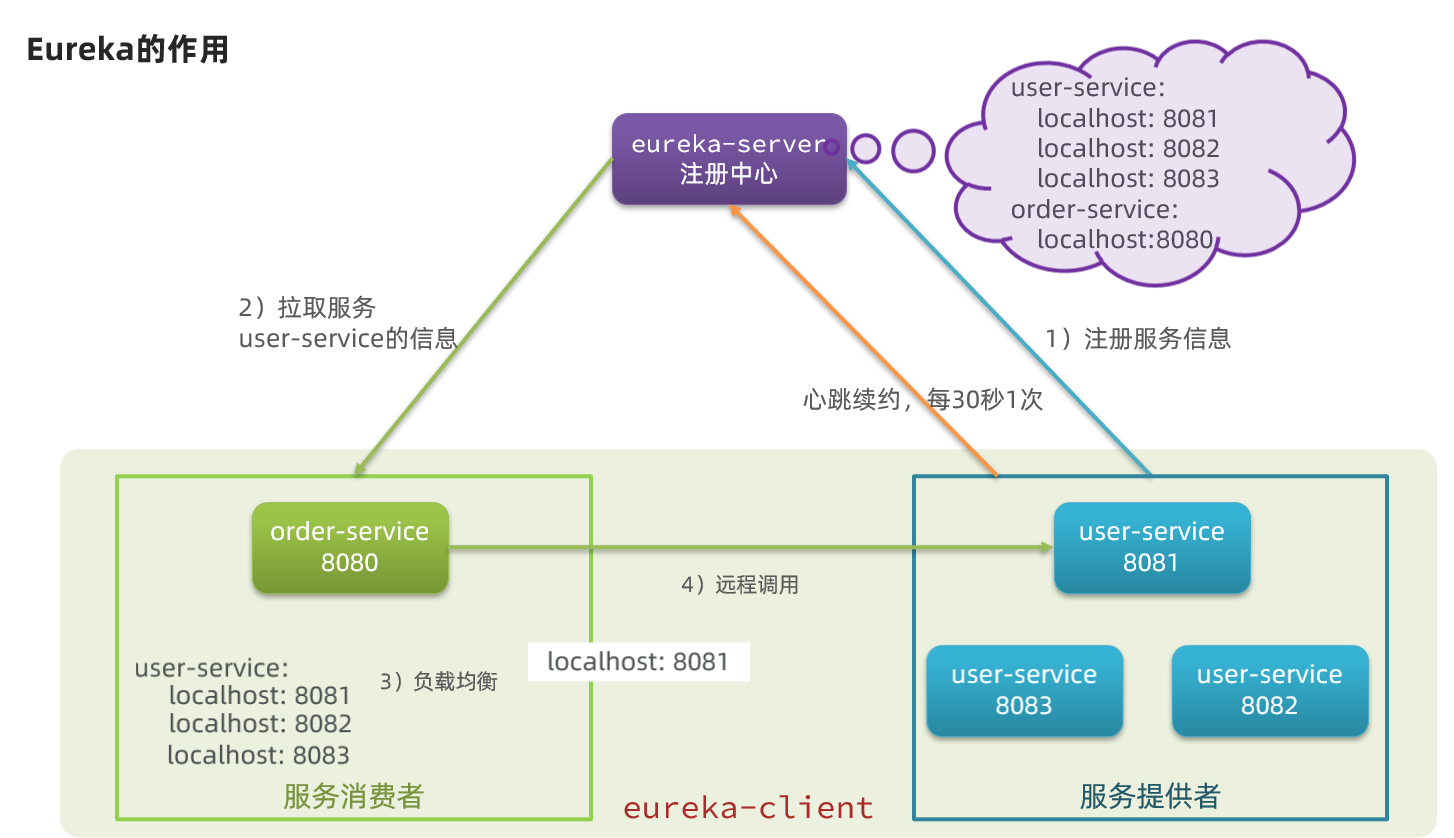
如上圖所示,服務提供方會將自己註冊到EurekaServer中,這樣EurekaServer就會儲存各種服務資訊,而服務消費方想要呼叫服務提供方的服務時,直接找EurekaServer拉取服務列表,然後根據特定地演演算法(輪詢、隨機......),選擇一個服務從而進行遠端呼叫
- 服務提供方:一次業務中,被其它微服務呼叫的服務。(提供介面給其它微服務)
- 服務消費方:一次業務中,呼叫其它微服務的服務。(呼叫其它微服務提供的介面)
服務提供者與服務消費者的角色並不是絕對的,而是相對於業務而言
如果服務A呼叫了服務B,而服務B又呼叫了服務C,服務B的角色是什麼?
- 對於A呼叫B的業務而言:A是服務消費者,B是服務提供者
- 對於B呼叫C的業務而言:B是服務消費者,C是服務提供者
因此,服務B既可以是服務提供者,也可以是服務消費者
Eureka的自我保護機制
這張圖中EurekaServer和服務提供方有一個心跳檢測機制,這是EurekaServer為了確定這些服務是否還在正常工作,所以進行的心跳檢測
eureka-client啟動時, 會開啟一個心跳任務,向Eureka Server傳送心跳,預設週期為30秒/次,如果Eureka Server在多個心跳週期內沒有接收到某個節點的心跳,Eureka Server將會從服務登入檔中把這個服務節點移除(預設90秒)
eureka-server維護了每個範例的最後一次心跳時間,使用者端傳送心跳包過來後,會更新這個心跳時間
eureka-server啟動時,開啟了一個定時任務,該任務每60s/次,檢查每個範例的最後一次心跳時間是否超過90s,如果超過則認為過期,需要剔除
但是EurekaClient也會因為網路等原因導致沒有及時向EurekaServer傳送心跳,因此EurekaServer為了保證誤刪服務就會有一個「自我保護機制」,俗稱「好死不如賴活著」
如果在短時間內EurekaServer丟失過多使用者端時 (可能斷網了,低於85%的使用者端節點都沒有正常的心跳 ),那麼Eureka Server就認為使用者端與註冊中心出現了網路故障,Eureka Server自動進入自我保護狀態 。Eureka的這樣設計更加精準地控制是網路通訊延遲,而不是服務掛掉了,一旦進入自我保護模式,那麼 EurekaServer就會保留這個節點的屬性,不會刪除,直到這個節點恢復正常心跳
- 85% 這個閾值,可以通過如下設定來設定:
eureka:
server:
renewal-percent-threshold: 0.85
這裡存在一個問題,這個85%是超過誰呢?這裡有一個預期的續約數量,計算公式如下:
自我保護閥值 = 服務總數 * 每分鐘續約數(60S/使用者端續約間隔) * 自我保護續約百分比閥值因子
在自我保護模式中,EurekaServer會保留登入檔中的資訊,不再登出任何服務資訊,當它收到正常心跳時,才會退出自我保護模式,也就是:寧可保留錯誤的服務註冊資訊,也不會盲目登出任何可能健康的服務範例,即:好死不如賴活著
因此Eureka進入自我保護狀態後,會出現以下幾種情況:
- Eureka Server仍然能夠接受新服務的註冊和查詢請求,但是不會被同步到其他節點上,保證當前節點依然可用。Eureka的自我保護機制可以通過如下的方式開啟或關閉
eureka:
server:
# 開啟Eureka自我保護機制,預設為true
enable-self-preservation: true
- Eureka Server不再從註冊列表中移除因為長時間沒有收到心跳而應該剔除的過期服務,如果在保護期內這個服務提供者剛好非正常下線了,此時服務消費者就會拿到一個無效的服務範例,此時會呼叫失敗,對於這個問題需要服務消費者端要有一些容錯機制,如重試,斷路器等!
Eureka常用設定
eureka:
client: # eureka使用者端設定
register-with-eureka: true # 是否將自己註冊到eureka伺服器端上去
fetch-registry: true # 是否獲取eureka伺服器端上註冊的服務列表
service-url:
defaultZone: http://localhost:8001/eureka/ # 指定註冊中心地址。若是叢集可以寫多個,中間用 逗號 隔開
enabled: true # 啟用eureka使用者端
registry-fetch-interval-seconds: 30 # 定義去eureka伺服器端獲取服務列表的時間間隔
instance: # eureka使用者端範例設定
lease-renewal-interval-in-seconds: 30 # 定義服務多久去註冊中心續約
lease-expiration-duration-in-seconds: 90 # 定義服務多久不去續約認為服務失效
metadata-map:
zone: hangzhou # 所在區域
hostname: localhost # 服務主機名稱
prefer-ip-address: false # 是否優先使用ip來作為主機名
server: # eureka伺服器端設定
enable-self-preservation: false #關 閉eureka伺服器端的自我保護機制
使用Eureka
實現如下的邏輯:
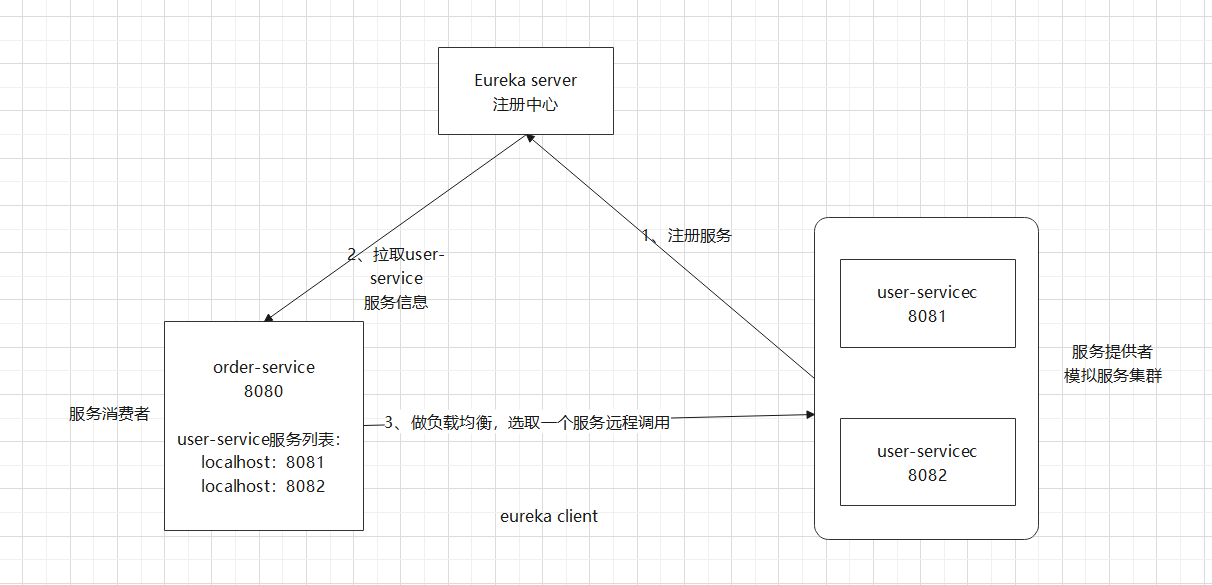
搭建Eureka Server
自行單獨建立一個Maven專案,匯入依賴如下:
<!--Eureka Server-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
在YAML檔案中一般可設定內容如下:
server:
port: 10086
spring:
application:
name: EUREKA-SERVER
eureka:
instance:
# Eureka的主機名,是為了eureka叢集伺服器之間好區分
hostname: 127.0.0.1
# 最後一次心跳後,間隔多久認定微服務不可用,預設90
lease-expiration-duration-in-seconds: 90
client:
# 不向註冊中心註冊自己。應用為單個註冊中心設定為false,代表不向註冊中心註冊自己,預設true 註冊中心不需要開啟
# registerWithEureka: false
# 不從註冊中心拉取自身註冊資訊。單個註冊中心則不拉取自身資訊,預設true 註冊中心不需要開啟
# fetchRegistry: false
service-url:
# Eureka Server的地址
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka
# server:
# # 開啟Eureka自我保護機制,預設為true
# enable-self-preservation: true
- 注:在SpringCloud中組態檔YAML有兩種方式,一種是
application.yml另一種是bootstrap.yml,這個知識後續Nacos註冊中心會用到,區別去這裡:https://www.cnblogs.com/sharpest/p/13678443.html
啟動類編寫內容如下:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
/**
* <p>@description : 該類功能 eureka server啟動類
* </p>
* <p>@author : ZiXieqing</p>
*/
/*@EnableEurekaServer 開啟Eureka Server功能*/
@EnableEurekaServer
@SpringBootApplication
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class, args);
}
}
服務提供者
新建一個Maven模組專案,依賴如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<!--eureka client-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
YAML設定內容如下:
server:
port: 8081
spring:
application:
name: USER-SERVICE
eureka:
client:
service-url:
# 將服務註冊到哪個eureka server
defaultZone: http://localhost:10086/eureka
啟動類內容如下:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class UserApplication {
public static void main(String[] args) {
SpringApplication.run(UserApplication.class, args);
}
}
關於開啟Eureka Client的問題
上一節中啟動類裡面有些人會看到是如下的方式:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
@SpringBootApplication
@EnableEurekaClient // 多了這麼一個操作:開啟eureka client功能
public class UserApplication {
public static void main(String[] args) {
SpringApplication.run(UserApplication.class, args);
}
}
在eureka client啟動類中,為什麼有些人會加 @EnableEurekaClient 註解,而有些人不會加上,為什麼?
要弄這個問題,首先看yml中的設定,有些是在yml中做了一個操作:
eureka:
client:
service-url:
# 向哪個eureka server進行服務註冊
defaultZone: http://localhost:10086/eureka
# 開啟eureka client功能,預設就是true,差不多等價於啟動類中加 @EnableEurekaClient 註解
enabled: true
既然上面設定預設值都是true,那還有必要在啟動類中加入 @EnableEurekaClient 註解嗎?
答案是根本不用加,加了也是多此一舉(前提:yml設定中沒有手動地把值改為false),具體原因看原始碼:答案就在Eureka client對應的自動設定類 EurekaClientAutoConfiguration 中
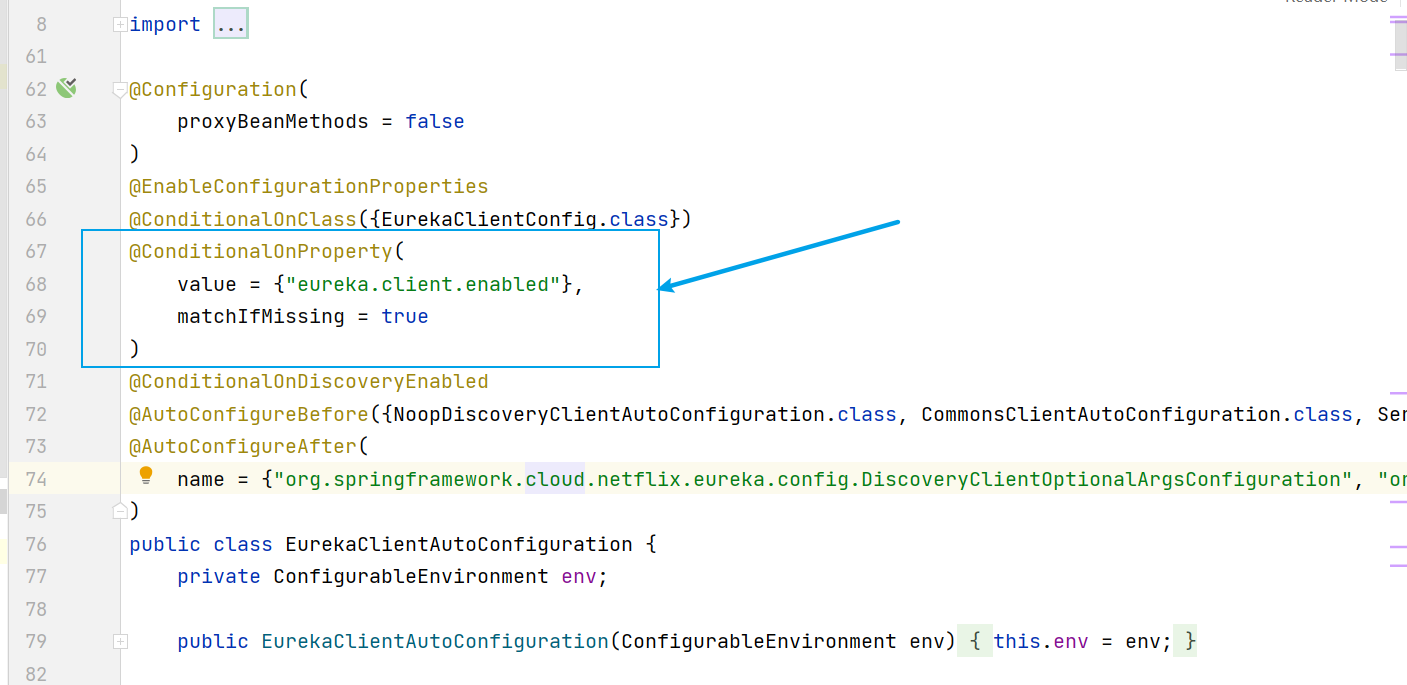
上圖中這一行的意思是隻有當application.yaml(或者環境變數,或者系統變數)裡,eureka.client.enabled這個屬性的值為true才會初始化這個類(如果手動賦值為false,就不會初始化這個類了)
另外再加上另一個原因,同樣在 EurekaClientAutoConfiguration 類中還有一個 eurekaAutoServiceRegistration() 方法
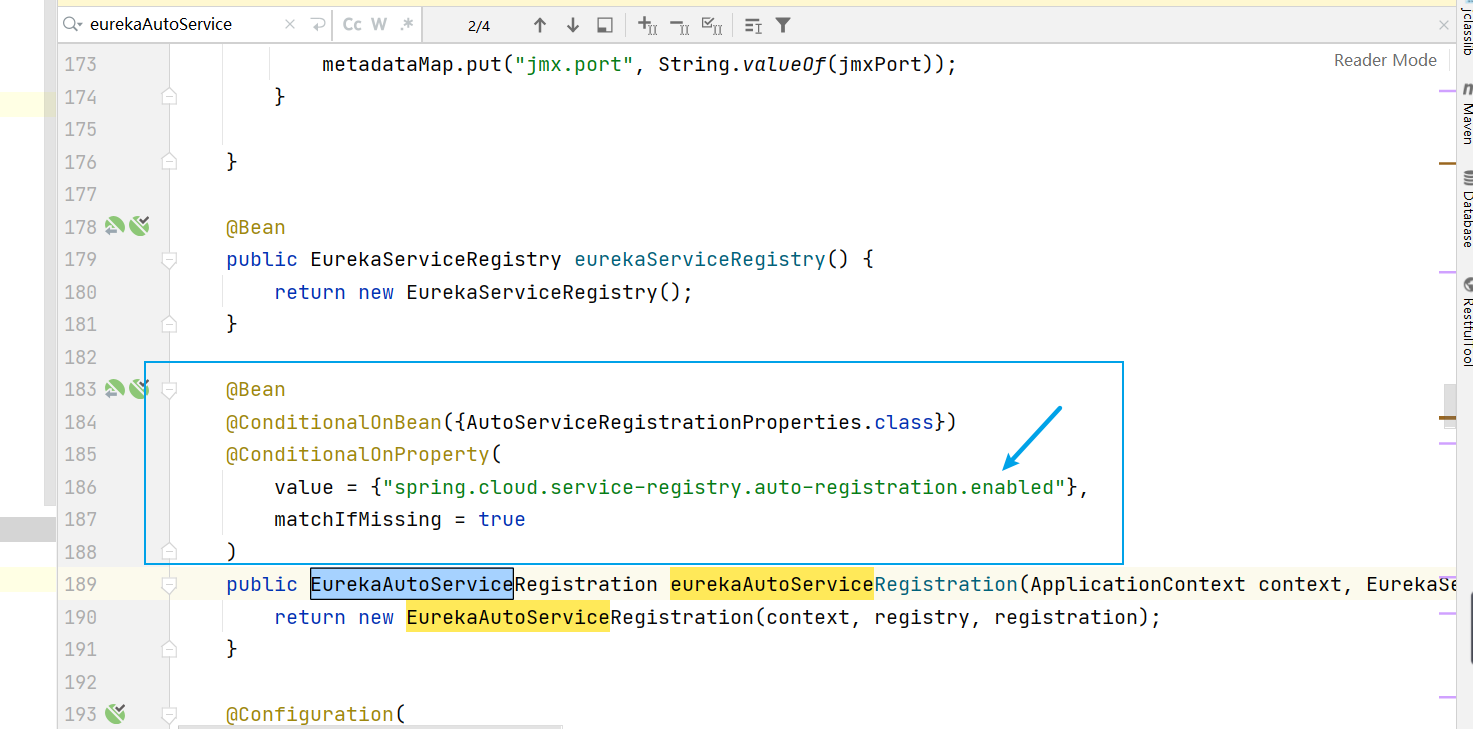
在這裡使用 EurekaAutoServiceRegistration類+@Bean註解 意思就是通過 @Bean 註解,裝配一個 EurekaAutoServiceRegistration 物件作為Spring的bean,而我們從名字就可以看出來EurekaClient的註冊就是 EurekaAutoServiceRegistration 物件所進行的操作
同時,在這個方法上,也有這麼一行 @ConditionalOnProperty(value = "spring.cloud.service-registry.auto-registration.enabled", matchIfMissing = true)
綜上所述:我們可以看出來,EurekaClient的註冊和兩個設定項有關的,一個是 eureka.client.enabled ,另一個是 spring.cloud.service-registry.auto-registration.enabled ,只不過這兩個設定預設都是true。這兩個設定無論哪個我們手動設定成false,我們的服務都無法進行註冊,測試自行做
另外還有一個原因:上圖中不是提到了 EurekaAutoServiceRegistration類+@Bean註解 嗎,那去看一下
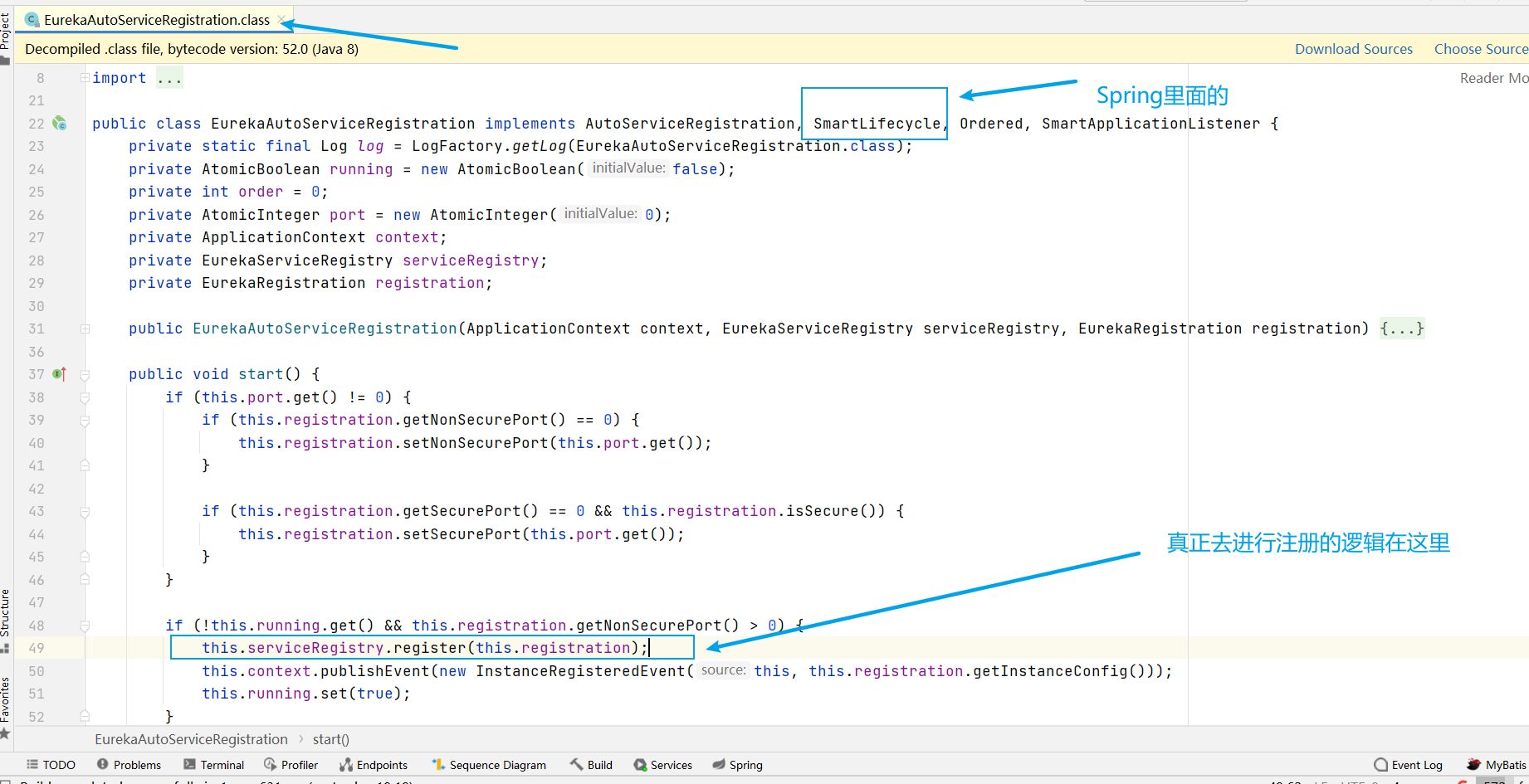
可以看到 EurekaAutoServiceRegistration 類實現了Spring的 SmartLifecycle 介面,這個介面的作用是幫助一個類在作為Spring的Bean的時候,由Spring幫助我們自動進行一些和生命週期有關的工作,比如在初始化或者停止的時候進行一些操作。而我們最關心的 註冊(register) 這個動作,就是在SmartLifecycle介面的 start() 方法實現裡完成的
而上一步講到,EurekaAutoServiceRegistration 類在 EurekaClientAutoConfiguration 類裡恰好被設定成Spring的Bean,所以這裡的 start() 方法是會自動被Spring呼叫的,我們不需要進行任何操作
總結
當我們參照了EurekaClient的依賴後,並且 eureka.client.enabled 和 spring.cloud.service-registry.auto-registration.enabled 兩個開關不手動置為false,Spring就會自動幫助我們執行 EurekaAutoServiceRegistration 類裡的 start() 方法,而註冊的動作就是在該方法裡完成的
所以,我們的EurekaClient工程,並不需要顯式地在SpringBoot的啟動類上標註 @EnableEurekaClient 註解
服務消費者
建立Maven模組,依賴如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
YAML設定如下:
server:
port: 8080
spring:
application:
name: ORDER-SERVICE
eureka:
client:
service-url:
# 向哪個eureka server進行服務拉取
defaultZone: http://localhost:10086/eureka
啟動類如下:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@SpringBootApplication
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
/**
* RestTemplate 用來進行遠端呼叫服務提供方的服務
* LoadBalanced 註解 是SpringCloud中的
* 此處作用:賦予RestTemplate負載均衡的能力 也就是在依賴注入時,只注入範例化時被@LoadBalanced修飾的範例
* 底層是 Spring的Qualifier註解,即為spring的原生操作
*/
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
@Qualifier 註解很重要:
@Autowired 預設是根據型別進行注入的,因此如果有多個型別一樣的Bean候選者,則需要限定其中一個候選者,否則將丟擲異常
@Qualifier 限定描述符除了能根據名字進行注入,更能進行更細粒度的控制如何選擇候選者
@LoadBalanced很明顯,"繼承"了註解@Qualifier,RestTemplates通過@Autowired注入,同時被@LoadBalanced修飾,所以只會注入@LoadBalanced修飾的RestTemplate,也就是我們的目標RestTemplate
通過 RestTemplate +eureka 遠端呼叫服務提供方中的服務
import com.zixieqing.order.mapper.OrderMapper;
import com.zixieqing.order.pojo.Order;
import com.zixieqing.order.pojo.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private RestTemplate restTemplate;
public Order queryOrderById(Long orderId) {
// 1.查詢訂單
Order order = orderMapper.findById(orderId);
// 2、遠端呼叫服務的url 此處直接使用服務名,不用ip+port
// 原因是底層有一個LoadBalancerInterceptor,裡面有一個intercept(),後續玩負載均衡Ribbon會看到
String url = "http://USER-SERVICE/user/" + order.getUserId();
// 2.1、利用restTemplate呼叫遠端服務,封裝成user物件
User user = restTemplate.getForObject(url, User.class);
// 3、給oder設定user物件值
order.setUser(user);
// 4.返回
return order;
}
}
不會玩 RestTemplate 用法的 戳這裡
測試
依次啟動eureka-server、user-service、order-service,然後將user-service做一下模擬叢集即可,將user-service弄為模擬叢集操作方式如下:不同版本IDEA操作有點區別,出入不大
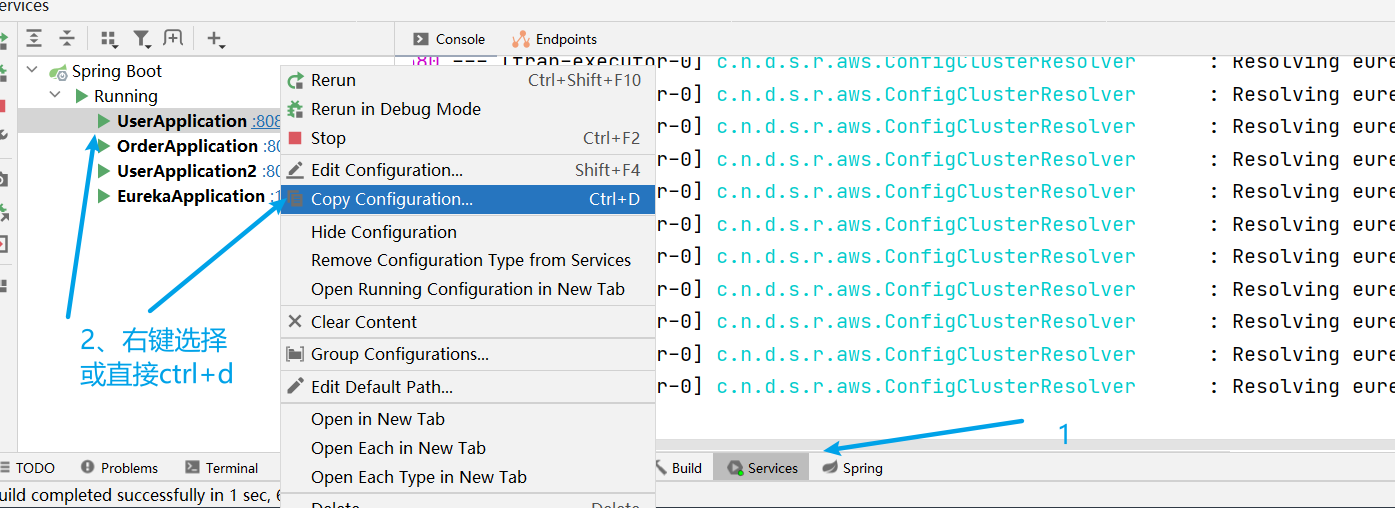
再將復刻的use-service2也啟動即可,啟動之後點一下eureka-server的埠就可以在瀏覽器看到服務qingk
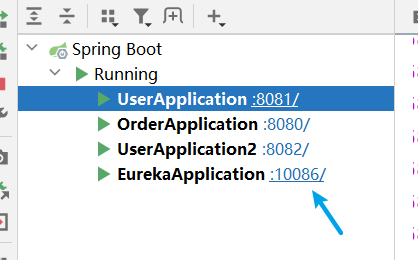
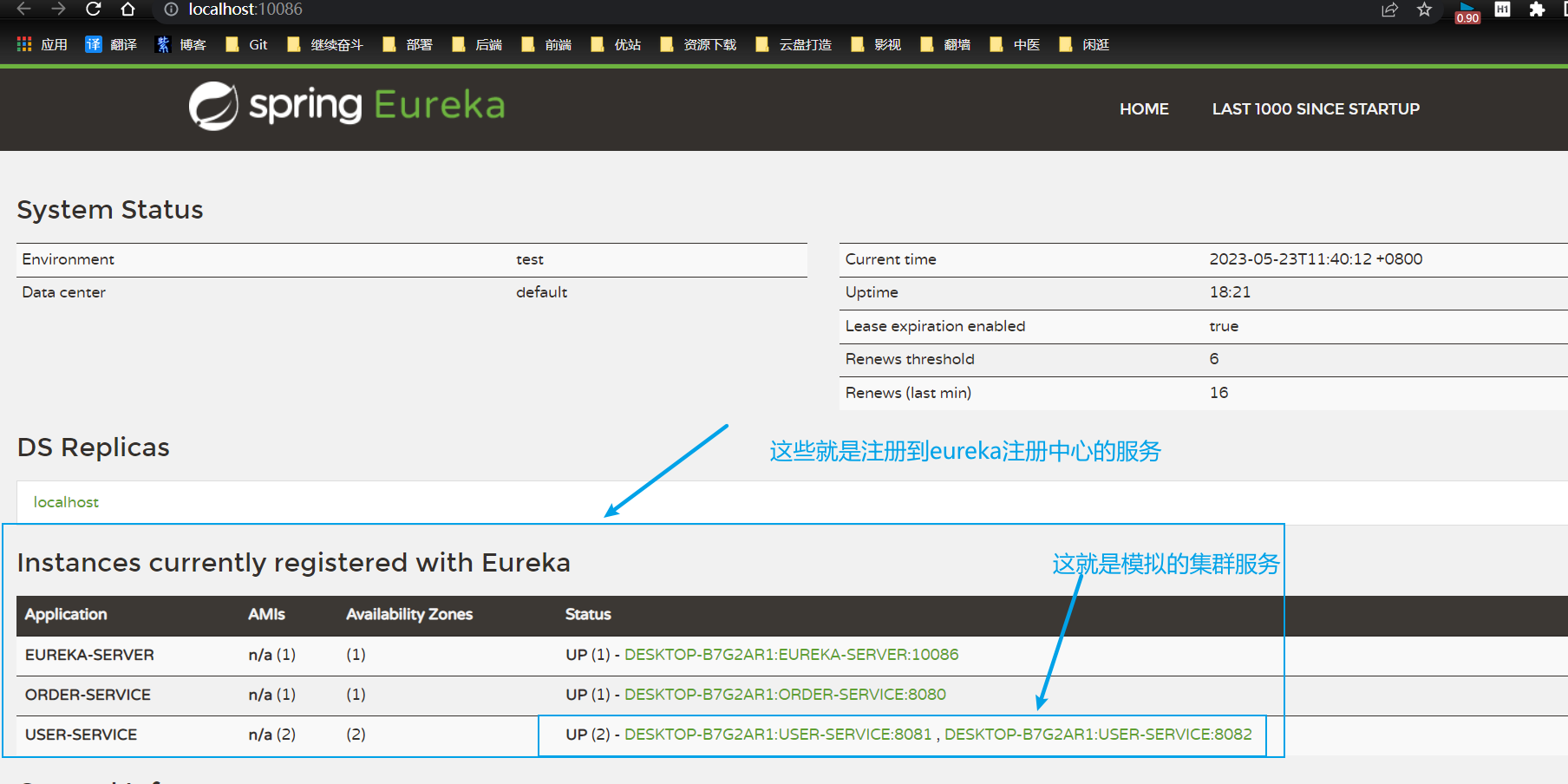
可以自行在服務提供方和服務消費方編寫邏輯,去連結資料庫,然後在服務消費方呼叫服務提供方的業務,最後存取自己controller中定義的路徑和引數即可
Ribbon負載均衡
Ribbon是什麼?
Ribbon是Netflix釋出的開源專案,Spring Cloud Ribbon是基於Netflix Ribbon實現的一套使用者端負載均衡的框架
Ribbon屬於哪種負載均衡?
LB負載均衡(Load Balance)是什麼?
- 簡單地說就是將使用者的請求平攤的分配到多個服務上,從而達到系統的HA(高可用)
- 常見的負載均衡有軟體Nginx,硬體 F5等
什麼情況下需要負載均衡?
-
現在Java非常流行微服務,也就是所謂的面向服務開發,將一個專案拆分成了多個專案,其優點有很多,其中一個優點就是:將服務拆分成一個一個微服務後,我們很容易地來針對性的進行叢集部署。例如訂單模組用的人比較多,那就可以將這個模組多部署幾臺機器,來分擔單個伺服器的壓力
-
這時候有個問題來了,前端頁面請求的時候到底請求叢集當中的哪一臺?既然是降低單個伺服器的壓力,所以肯定全部機器都要利用起來,而不是說一臺用著,其他空餘著。這時候就需要用負載均衡了,像這種前端頁面呼叫後端請求的,要做負載均衡的話,常用的就是Nginx
Ribbon和Nginx負載均衡的區別
- 當後端服務是叢集的情況下,前端頁面呼叫後端請求,要做負載均衡的話,常用的就是Nginx
- Ribbon主要是在「伺服器端內」做負載均衡,舉例:訂單後端服務 要呼叫 支付後端服務,這屬於後端之間的服務呼叫,壓根根本不經過頁面,而後端支付服務是叢集,這時候訂單服務就需要做負載均衡來呼叫支付服務,記住是訂單服務做負載均衡 「來呼叫」 支付服務
負載均衡分類
- 集中式LB:即在服務的消費方和提供方之間使用獨立的LB設施(可以是硬體,如F5, 也可以是軟體,如nginx),由該設施負責把存取請求通過某種策略轉發至服務的提供方
- 程序內LB:將LB邏輯整合到「消費方」,消費方從服務註冊中心獲知有哪些地址可用,然後自己再從這些地址中選擇出一個合適的伺服器
Ribbon負載均衡
- Ribbon就屬於程序內LB,它只是一個類庫,整合於服務消費方程序
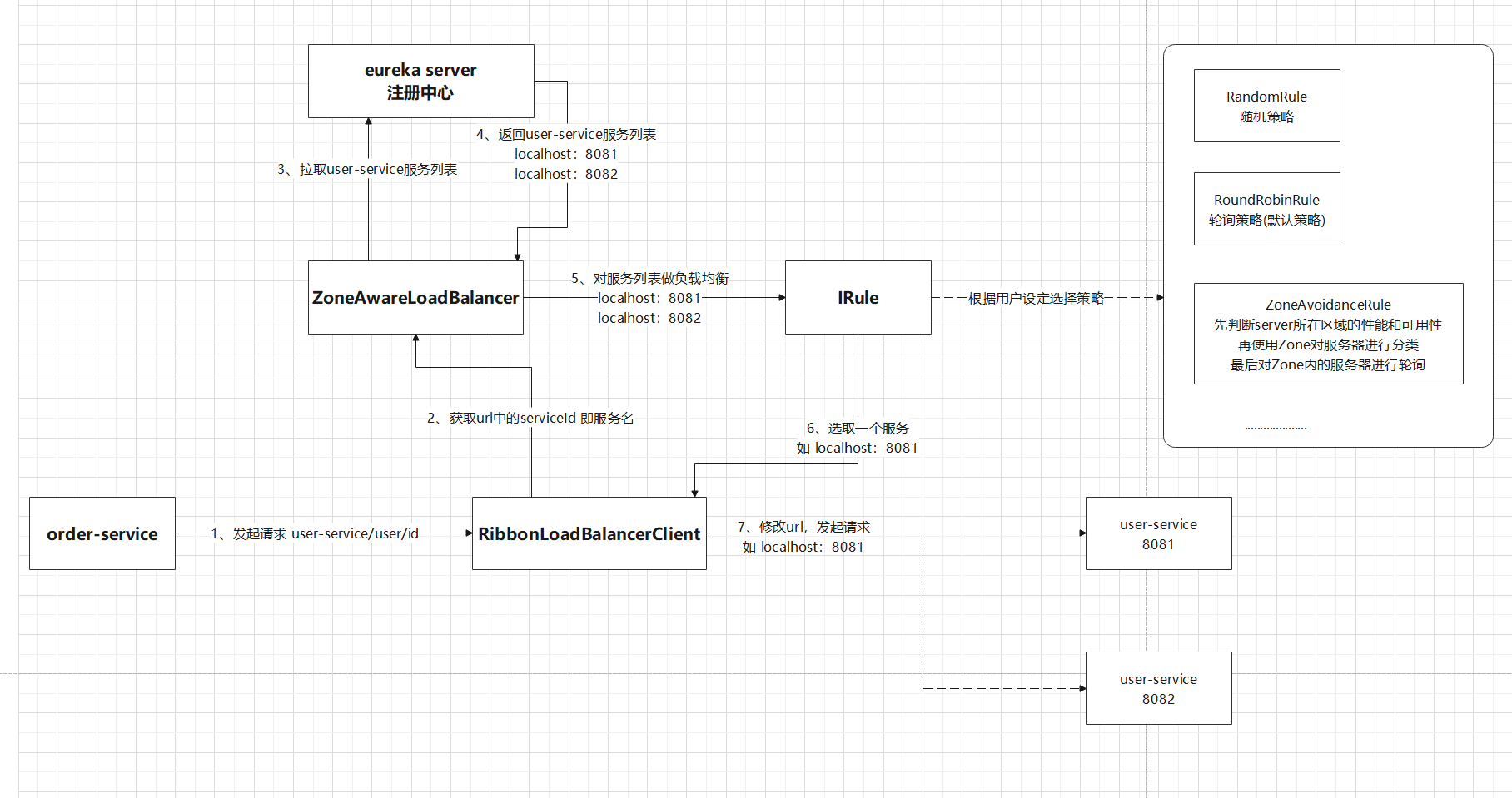
Ribbon的流程
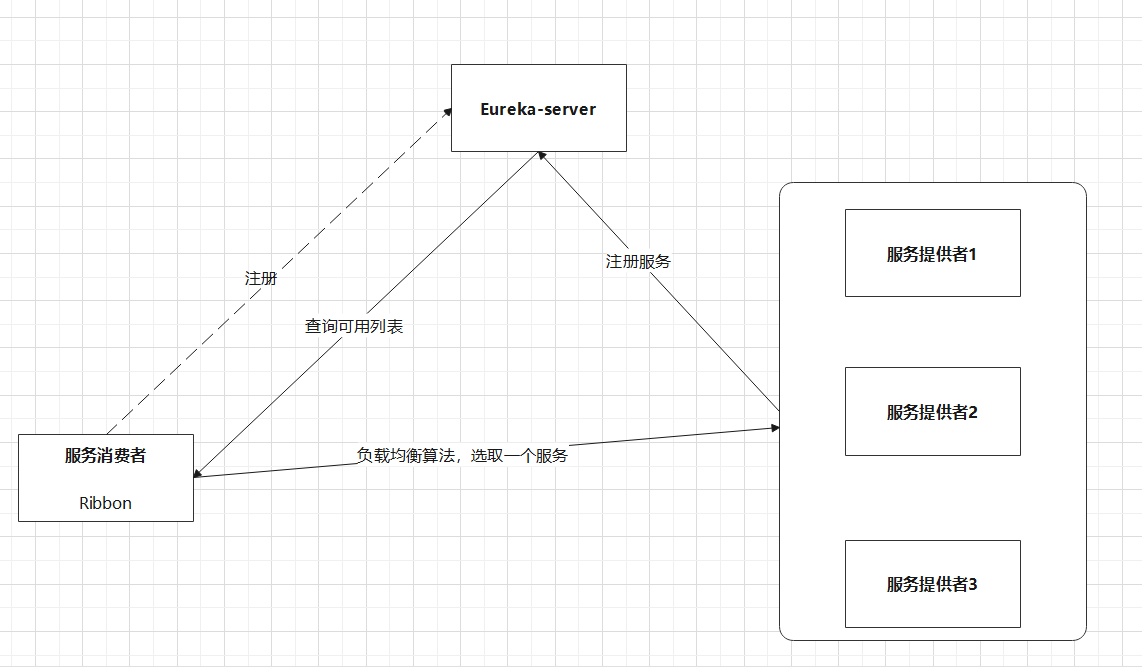
通過上圖一定要明白一點:Ribbon一定是用在消費方,而不是服務的提供方!
Ribbon在工作時分成兩步(這裡以Eureka為例,consul和zk同樣道理):
- 第一步先選擇 EurekaServer ,它優先選擇在同一個區域內負載較少的server
- 第二步再根據使用者指定的策略(輪詢、隨機、響應時間加權.....),從server取到的服務註冊列表中選擇一個地址
請求怎麼從服務名地址變為真實地址的?
只要引入了註冊中心(Eureka、consul、zookeeper),那Ribbon的依賴就在註冊中心裡面了,證明如下:
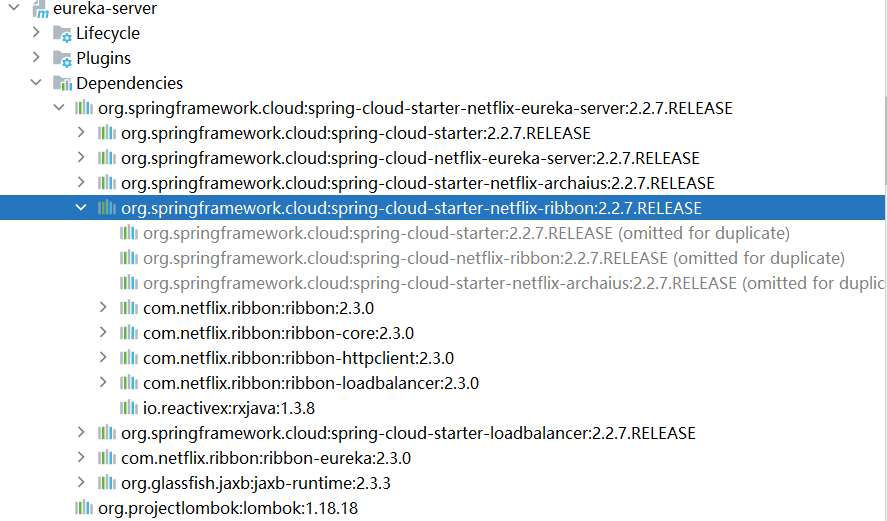
回到正題:為什麼下面這樣使用服務名就可以調到服務提供方的服務,即:請求 http://userservice/user/101 怎麼變成的 http://localhost:8081 ??因為它長得好看?
import com.zixieqing.order.mapper.OrderMapper;
import com.zixieqing.order.pojo.Order;
import com.zixieqing.order.pojo.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private RestTemplate restTemplate;
public Order queryOrderById(Long orderId) {
// 1.查詢訂單
Order order = orderMapper.findById(orderId);
// 2、遠端呼叫服務的url 此處直接使用服務名,不用ip+port
// 原因是底層有一個LoadBalancerInterceptor,裡面有一個intercept(),後續玩負載均衡Ribbon會看到
String url = "http://USER-SERVICE/user/" + order.getUserId();
// 2.1、利用restTemplate呼叫遠端服務,封裝成user物件
User user = restTemplate.getForObject(url, User.class);
// 3、給oder設定user物件值
order.setUser(user);
// 4.返回
return order;
}
}
// RestTemplate做了下面操作,使用了 @Bean+@LoadBalanced
/**
* RestTemplate 用來進行遠端呼叫服務提供方
* LoadBalanced 註解 是SpringCloud中的
* 此處作用:賦予RestTemplate負載均衡的能力 也就是在依賴注入時,只注入範例化時被@LoadBalanced修飾的範例
* 底層是 Spring的Qualifier註解,即為spring的原生操作
*/
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
想知道答案就得Debug了,而要Debug,就得找到 LoadBalancerInterceptor 類
LoadBalancerInterceptor類
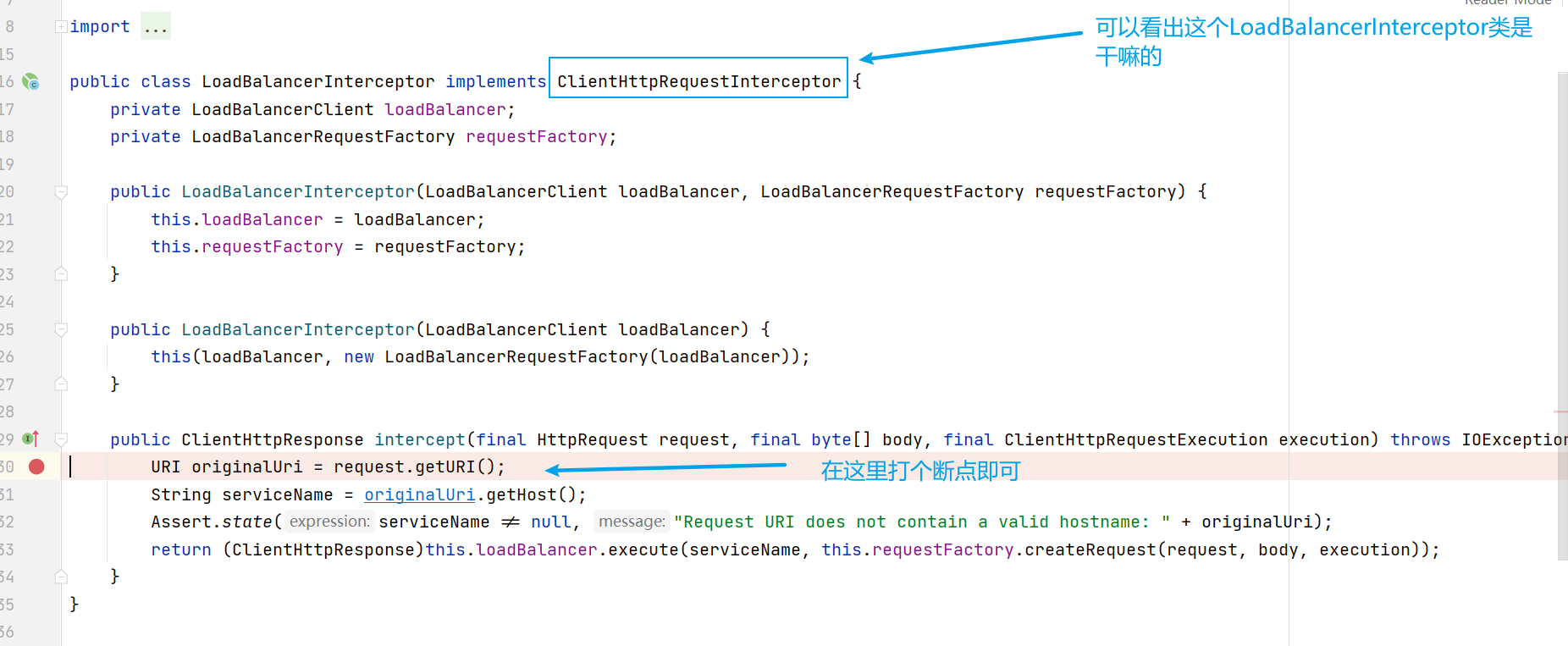
然後對服務消費者進行Debug
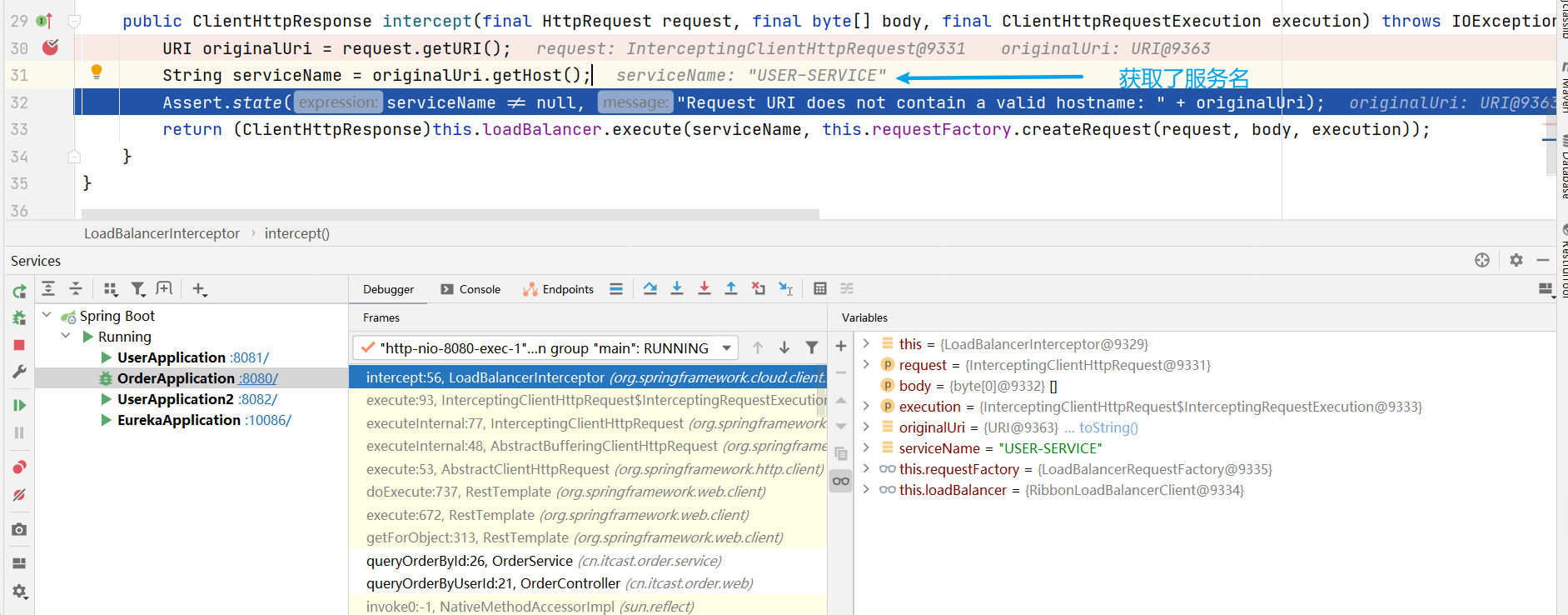
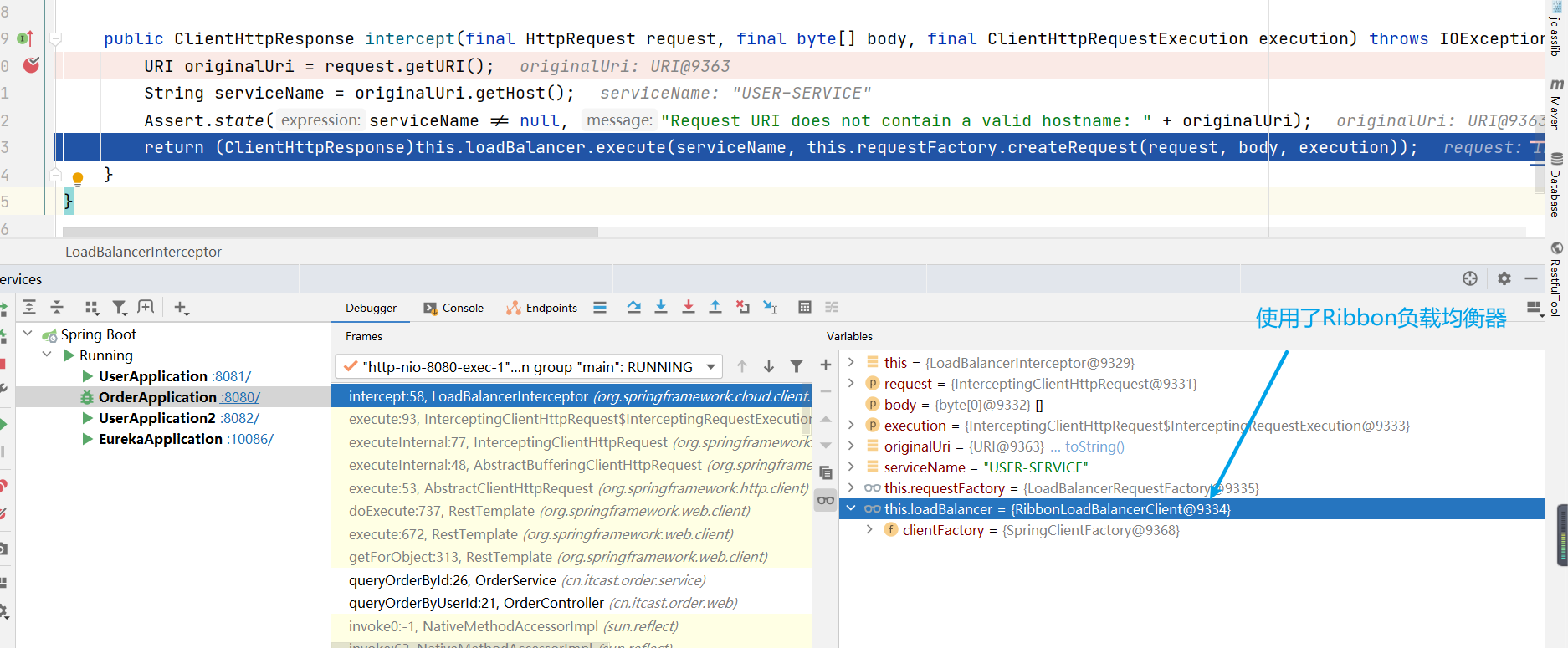
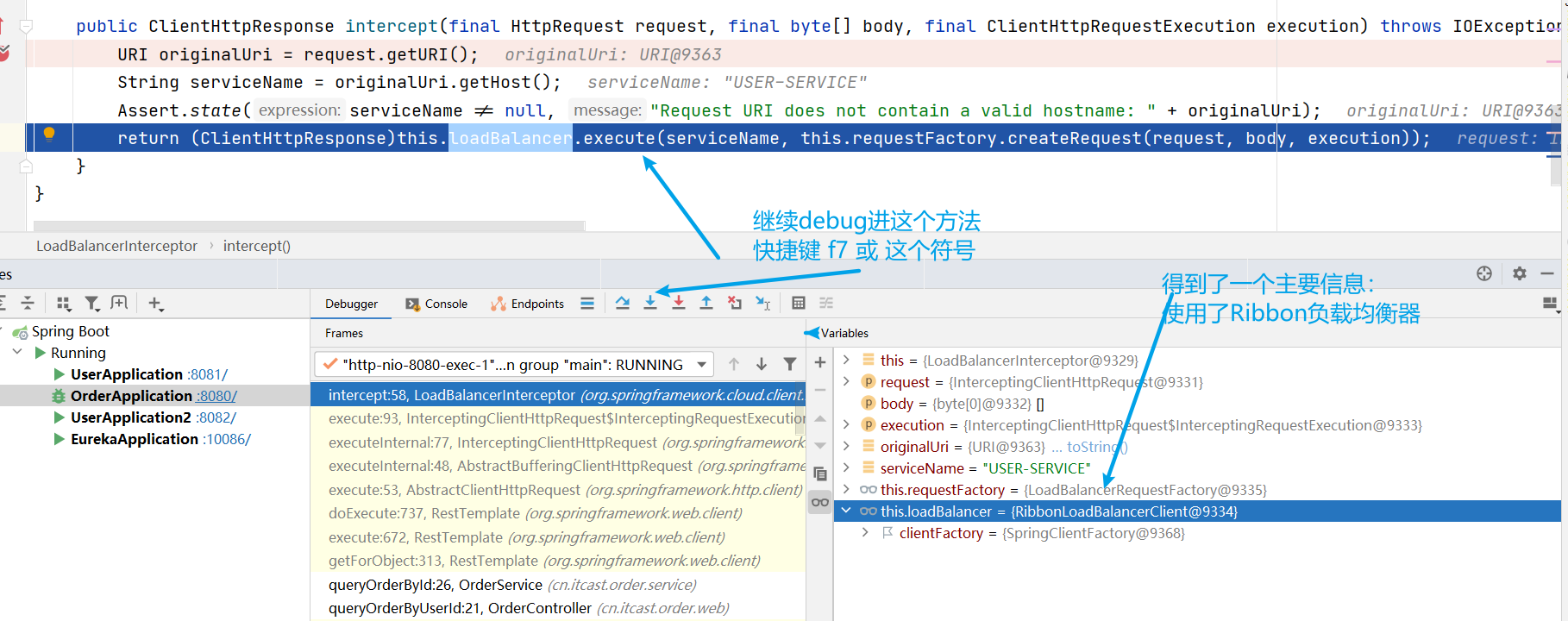
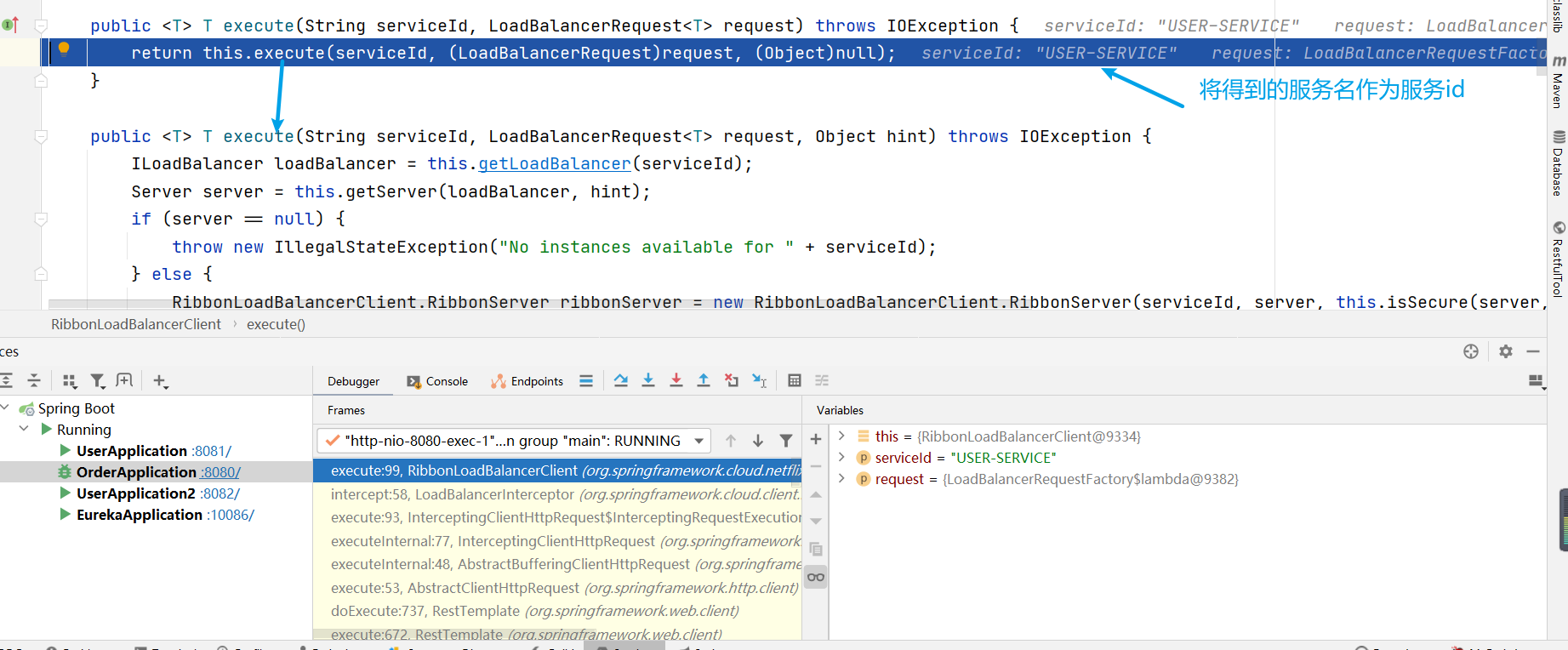
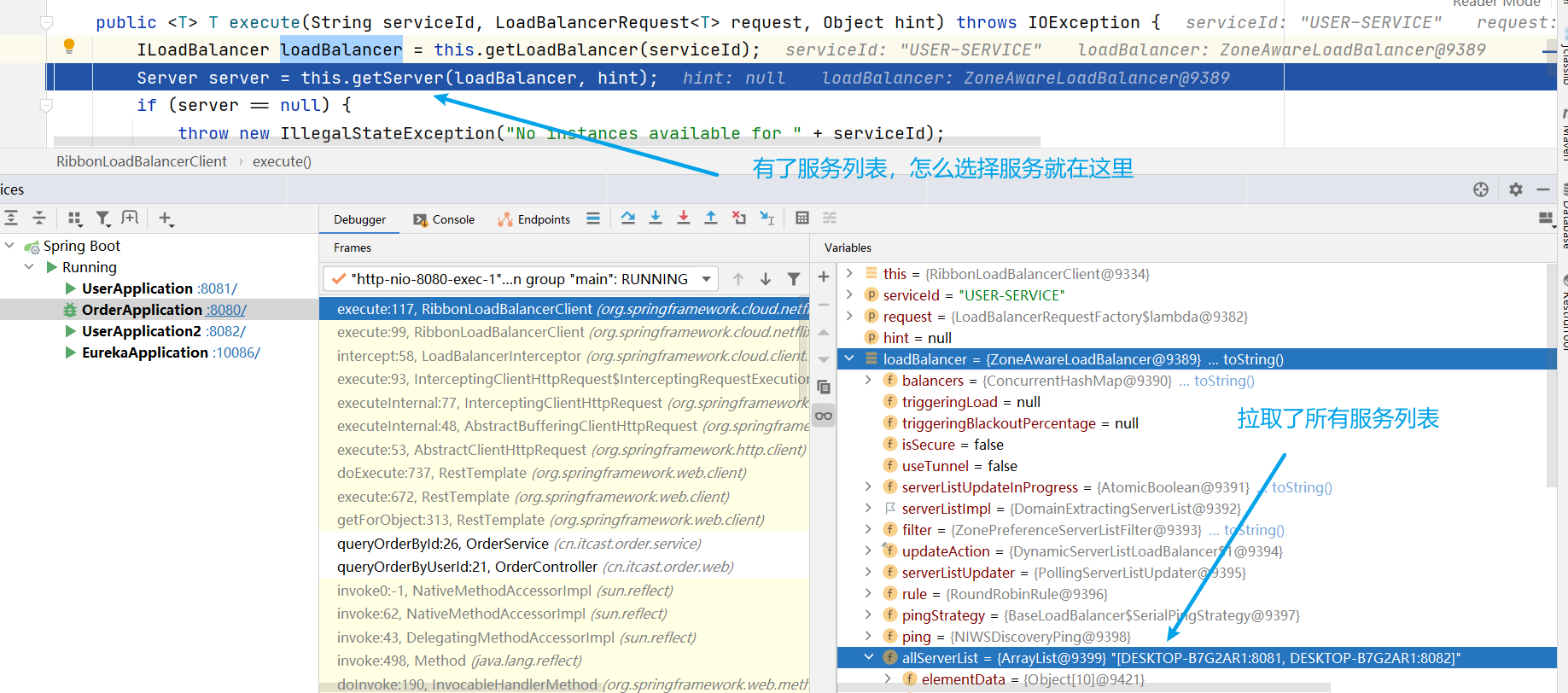


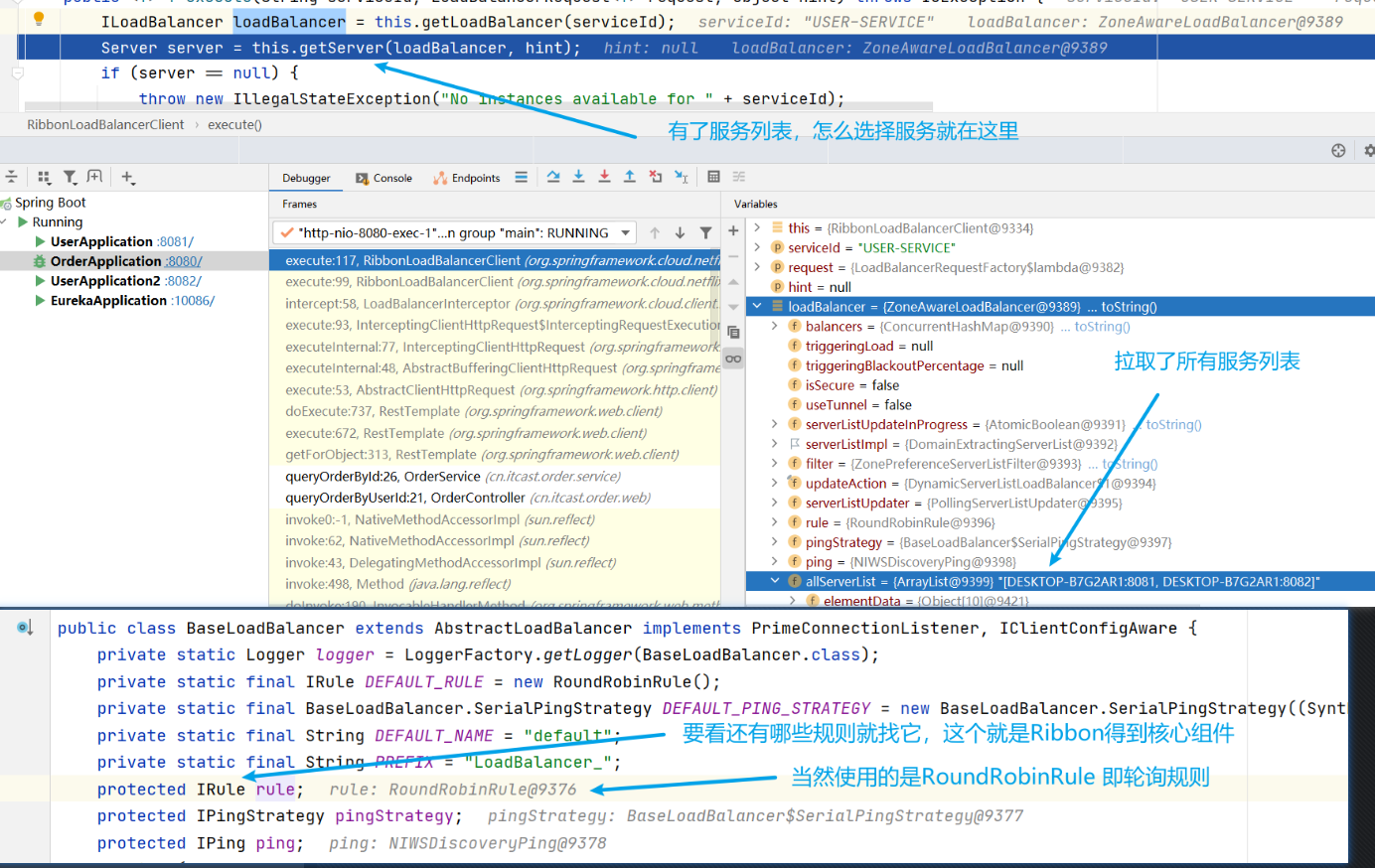
問題的答案已經出來了:為什麼使用服務名就可以調到服務提供方的服務,即:請求 http://userservice/user/101 怎麼變成的 http://localhost:8081 ??
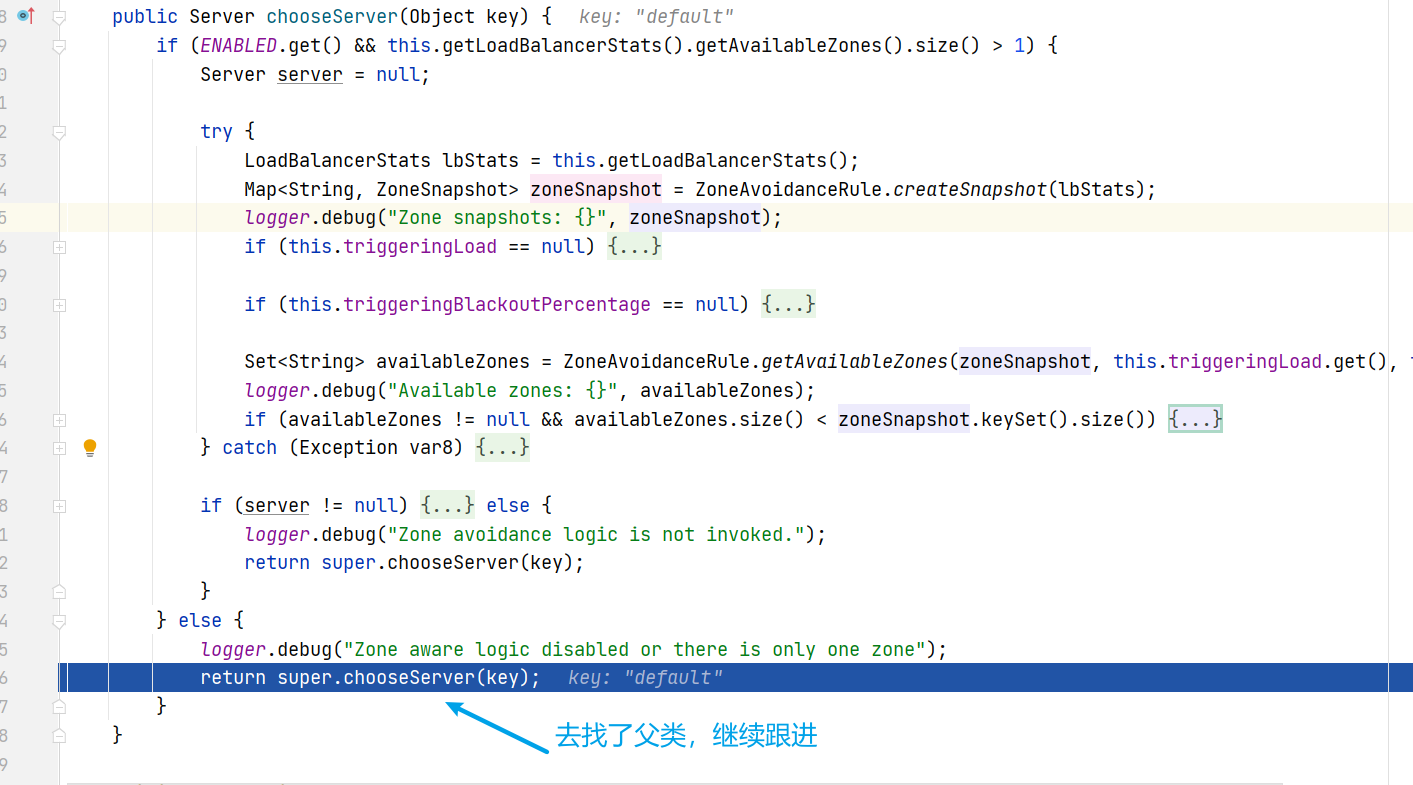
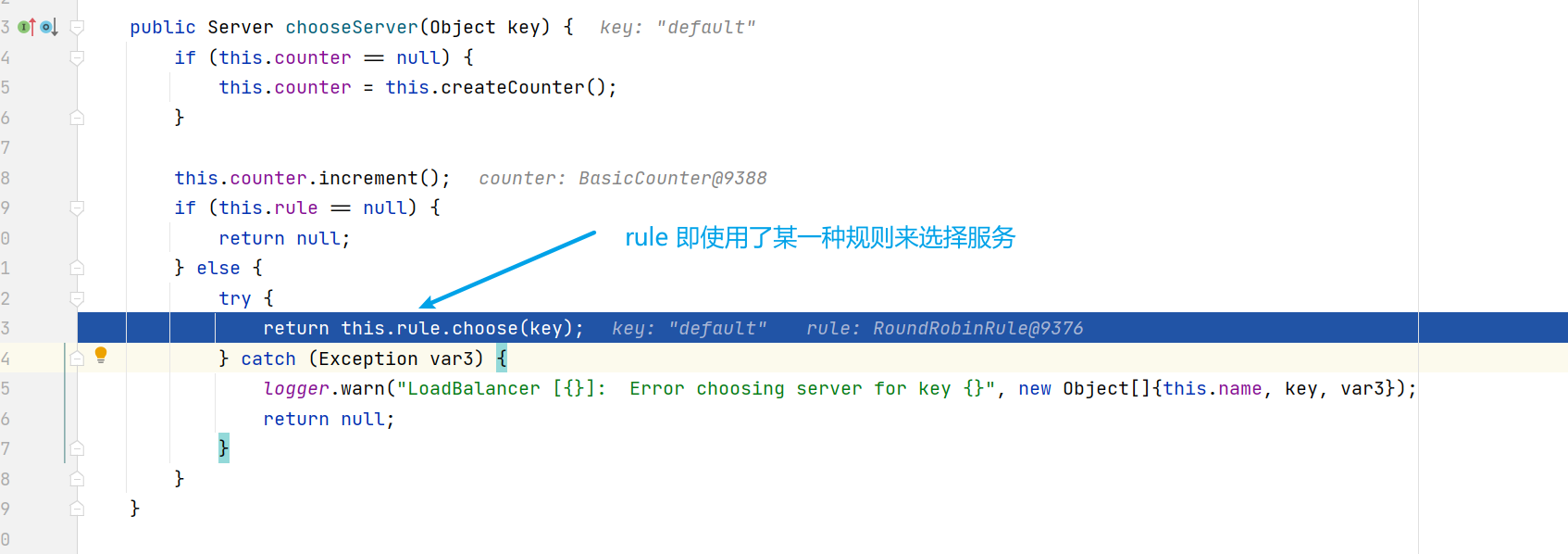
- 原因就是使用了RibbonLoadBalancerClient+loadBalancer(預設是 ZoneAwareLoadBalance 從服務列表中選取服務)+IRule(預設是 RoundRobinRule 輪詢策略選擇某個服務)
總結
SpringCloudRibbon的底層採用了一個攔截器LoadBalancerInterceptor,攔截了RestTemplate發出的請求,對地址做了修改
負載均衡策略有哪些?
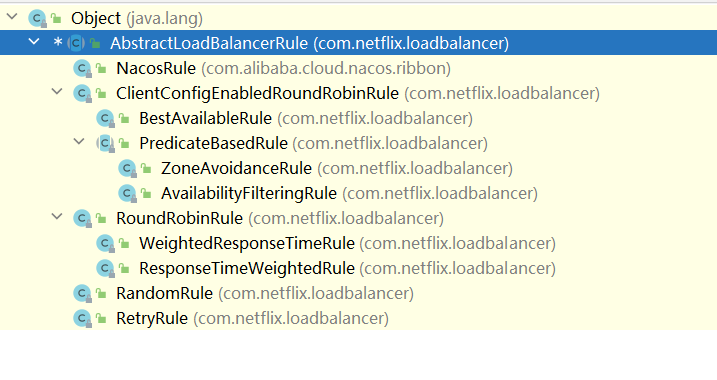
根據前面的鋪墊,也知道了負載均衡策略就在 IRule 中,那就去看一下
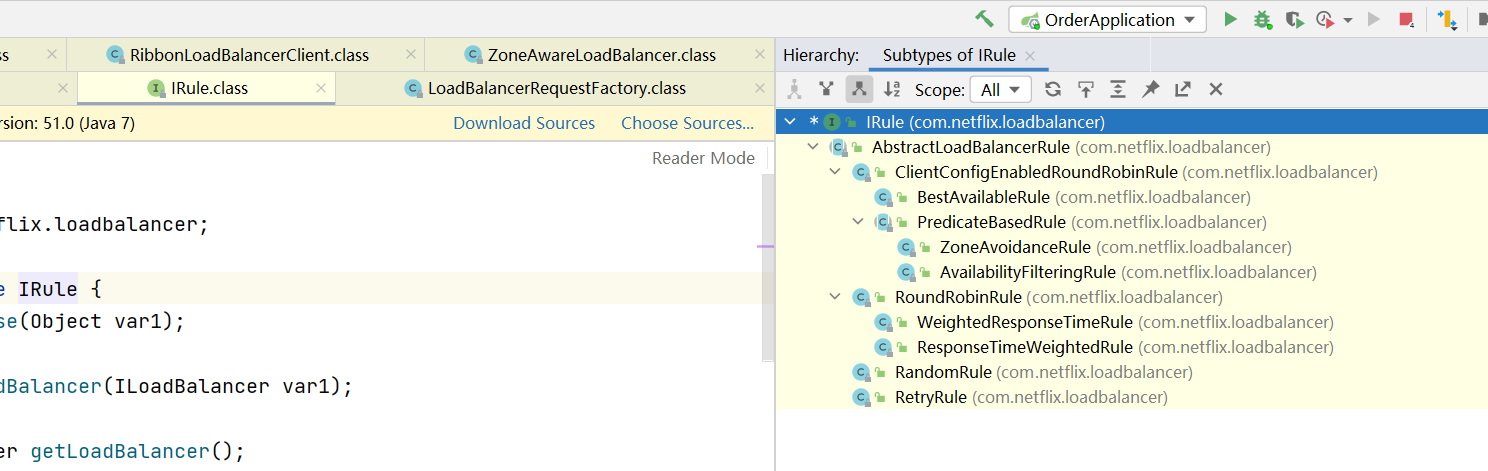
轉換一下:
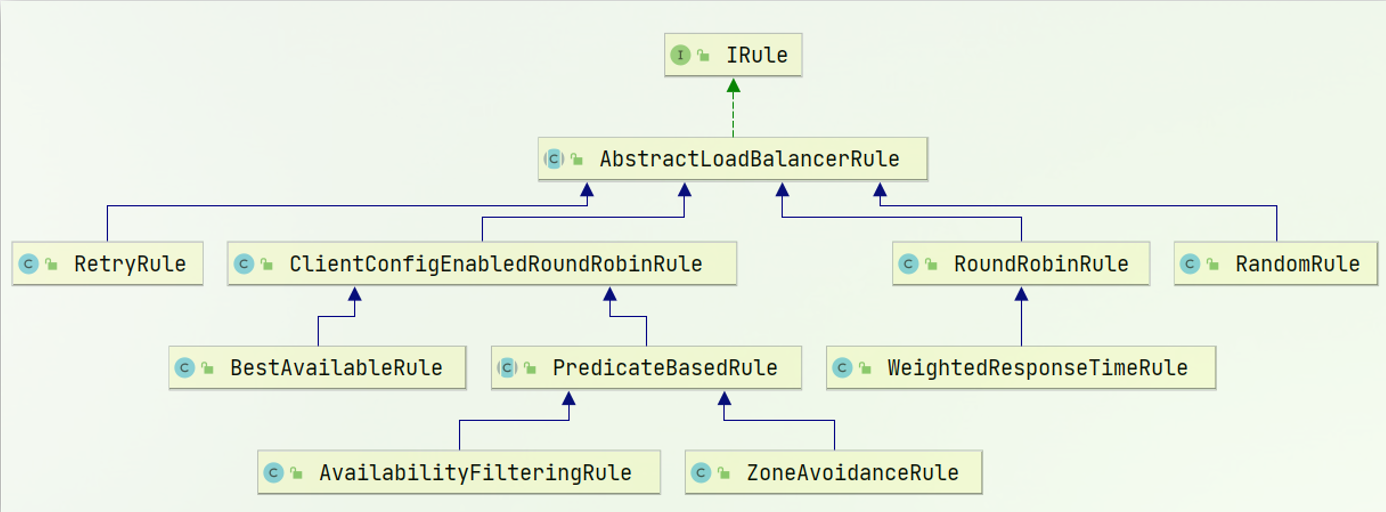
ClientConfigEnabledRoundRobinRule:該策略較為特殊,我們一般不直接使用它。因為它本身並沒有實現什麼特殊的處理邏輯。一般都是可以通過繼承他重寫一些自己的策略,預設的choose()就實現了線性輪詢機制
BestAvailableRule:繼承自ClientConfigEnabledRoundRobinRule,會先過濾掉由於多次存取故障而處於斷路器跳閘狀態的服務,然後選擇一個並行量最小的服務,該策略的特性是可選出最空閒的範例
PredicateBasedRule:繼承自ClientConfigEnabledRoundRobinRule,抽象策略,需要重寫方法,然後自定義過濾規則
AvailabilityFilteringRule:繼承PredicateBasedRule,先過濾掉故障範例,再選擇並行較小的範例。過濾掉的故障伺服器是以下兩種:- 在預設情況下,這臺伺服器如果3次連線失敗,這臺伺服器就會被設定為「短路」狀態。短路狀態將持續30秒,如果再次連線失敗,短路的持續時間就會幾何級地增加
- 並行數過高的伺服器。如果一個伺服器的並行連線數過高,設定了AvailabilityFilteringRule規則的使用者端也會將其忽略。並行連線數的上限,可以由使用者端的
<clientName>.<clientConfigNameSpace>.ActiveConnectionsLimit屬性進行設定
ZoneAvoidanceRule:繼承PredicateBasedRule,預設規則,複合判斷server所在區域的效能和server的可用性選擇伺服器
com.netflix.loadbalancer.RoundRobinRule:輪詢 Ribbon的預設規則
WeightedResponseTimeRule:對RoundRobinRule的擴充套件。為每一個伺服器賦予一個權重值,伺服器響應時間越長,其權重值越小,這個權重值會影響伺服器的選擇,即:響應速度越快的範例選擇權重越大,越容易被選擇ResponseTimeWeightedRule:對RoundRobinRule的擴充套件。響應時間加權
com.netflix.loadbalancer.RandomRule:隨機
com.netflix.loadbalancer.StickyRule:這個基本也沒人用
com.netflix.loadbalancer.RetryRule:先按照RoundRobinRule的策略獲取服務,如果獲取服務失敗則在指定時間內會進行重試,從而獲取可用的服務
ZoneAvoidanceRule:先複合判斷server所在區域的效能和server的可用性選擇伺服器,再使用Zone對伺服器進行分類,最後對Zone內的伺服器進行輪詢
自定義負載均衡策略
在前面已經知道了策略是 IRule ,所以就是改變了這個玩意而已
1、程式碼方式 :服務消費者的啟動類或重開config模組編寫如下內容即可
@Bean
public IRule randomRule(){
// new前面提到的那些rule物件即可,當然這裡面也可以自行篡改策略邏輯返回
return new RandomRule();
}
注: 此種方式是全域性策略,即所有服務均採用這裡定義的負載均衡策略
2、@RibbonClient註解:用法如下
/**
* 在服務消費者的啟動類中加入如下註解即可 如下註解指的是:呼叫 USER-SERVICE 服務時 使用MySelfRule負載均衡規則
*
* 這裡的MySelfRule可以弄為自定義邏輯的策略,也可以是前面提到的那些rule策略
*/
@RibbonClient(name = "USER-SERVICE",configuration=MySelfRule.class)
這種方式可以達到只針對某服務做負載均衡策略,但是:官方給出了明確警告 configuration=MySelfRule.class 自定義設定類一定不能放到@ComponentScan 所掃描的當前包下以及子包下,否則我們自定義的這個設定類就會被所有的Ribbon使用者端所共用,達不到特殊化客製化的目的了(也就是一旦被掃描到,RestTemplate直接不管呼叫哪個服務都會用指定的演演算法)
springboot專案當中的啟動類使用了@SpringBootApplication註解,這個註解內部就有@ComponentScan註解,預設是掃描啟動類包下所有的包,所以我們要達到客製化化一定不要放在它能掃描到的地方
cloud中文官網:https://www.springcloud.cc/spring-cloud-greenwich.html
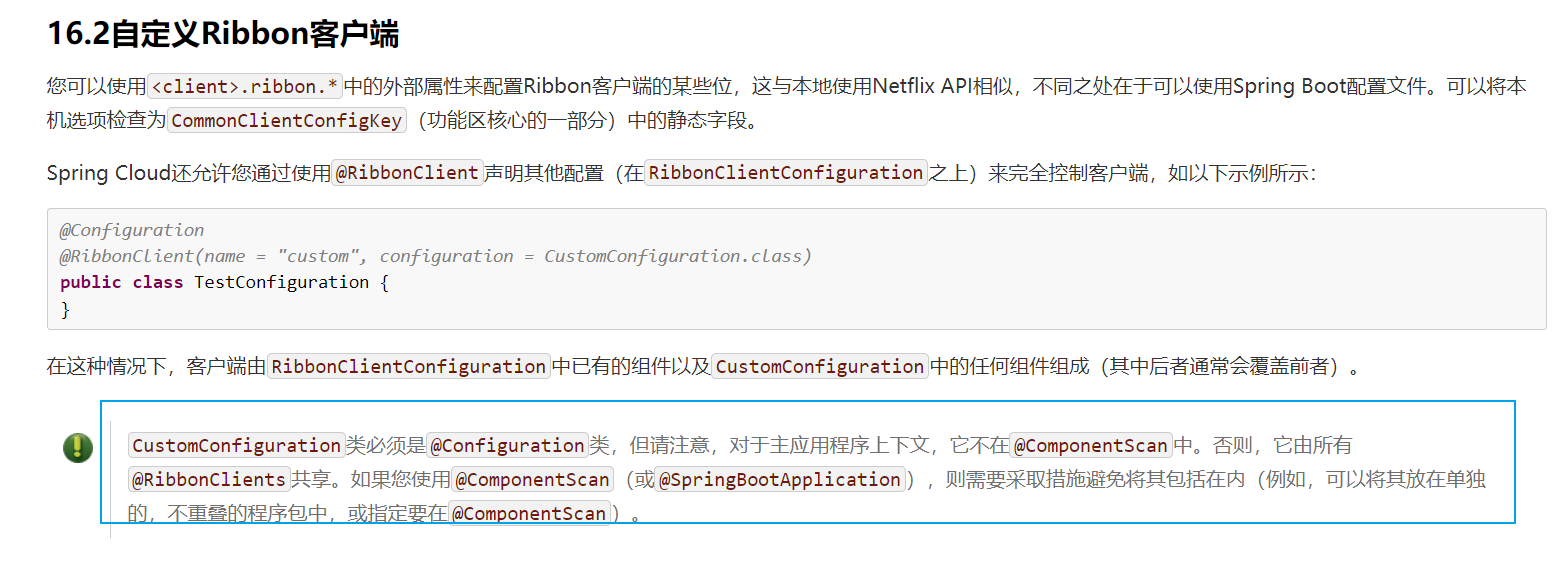
3、使用YAML組態檔方式 在服務消費方的yml組態檔中加入如下格式的內容即可
# 給某個微服務設定負載均衡規則,這裡是user-service服務
user-service:
ribbon:
# 負載均衡規則
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
注意,一般用預設的負載均衡規則,不做修改
Ribbon餓漢載入
Ribbon預設是採用懶載入,即第一次存取時才會去建立LoadBalanceClient,請求時間會很長。
而餓漢載入則會在專案啟動時建立,降低第一次存取的耗時,通過下面設定開啟飢餓載入:
ribbon:
eager-load:
# 開啟負載均衡餓漢載入模式
enabled: true
# clients是一個String型別的List陣列,多個時採用下面的 - xxxx服務 的形式,單個時直接使用 clients: 服務名 即可
clients:
- USER-SERVICE
Nacos註冊中心
國內公司一般都推崇阿里巴巴的技術,比如註冊中心,SpringCloudAlibaba也推出了一個名為Nacos的註冊中心
Nacos 是阿里巴巴的產品,現在是 SpringCloud 中的一個元件。相比 Eureka 功能更加豐富,在國內受歡迎程度較高
安裝Nacos
windows安裝
GitHub中下載:https://github.com/alibaba/nacos/releases
下載好之後直接解壓即可,但:別解壓到有「中文路徑」的地方
Nacos的預設埠是8848,若該埠被佔用則關閉該程序 或 修改nacos中的預設埠(conf/application.properties)
啟動Nacos:密碼和賬號均是 nacos
startup.cmd -m standalone
-m modul 模式
standalone 單機
Linux安裝
Nacos是基於Java開發的,所以需要JDK支援,因此Linux中需要有JDK環境
上傳Linux版的JDK
# 解壓
tar -xvf jdk-8u144-linux-x64.tar.gz
# 設定環境變數
export JAVA_HOME=/usr/local/java # =JDK解壓後的路徑
export PATH=$PATH:$JAVA_HOME/bin
# 重新整理環境變數
source /etc/profile
上傳Linux版的Nacos
# 解壓
tar -xvf nacos-server-1.4.1.tar.gz
# 進入 nacos/bin 目錄中,輸入命令啟動Nacos
sh startup.sh -m standalone
# 有8848埠衝突和windows中一樣方式解決
註冊服務到Nacos中
拉取Nacos的依賴管理,伺服器端加入如下依賴
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.5.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
使用者端依賴如下:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
注:不要有其他註冊中心的依賴,如前面玩的Eureka,有的話註釋掉
修改使用者端的yml組態檔:
server:
port: 8081
spring:
application:
name: USER-SERVICE
cloud:
nacos:
# Nacos伺服器地址
server-addr: localhost:8848
#eureka:
# client:
# # 去哪裡拉取服務列表
# service-url:
# defaultZone: http://localhost:10086/eureka
啟動之後,在 ip+port/nacos 就在Nacos控制檯看到資訊了
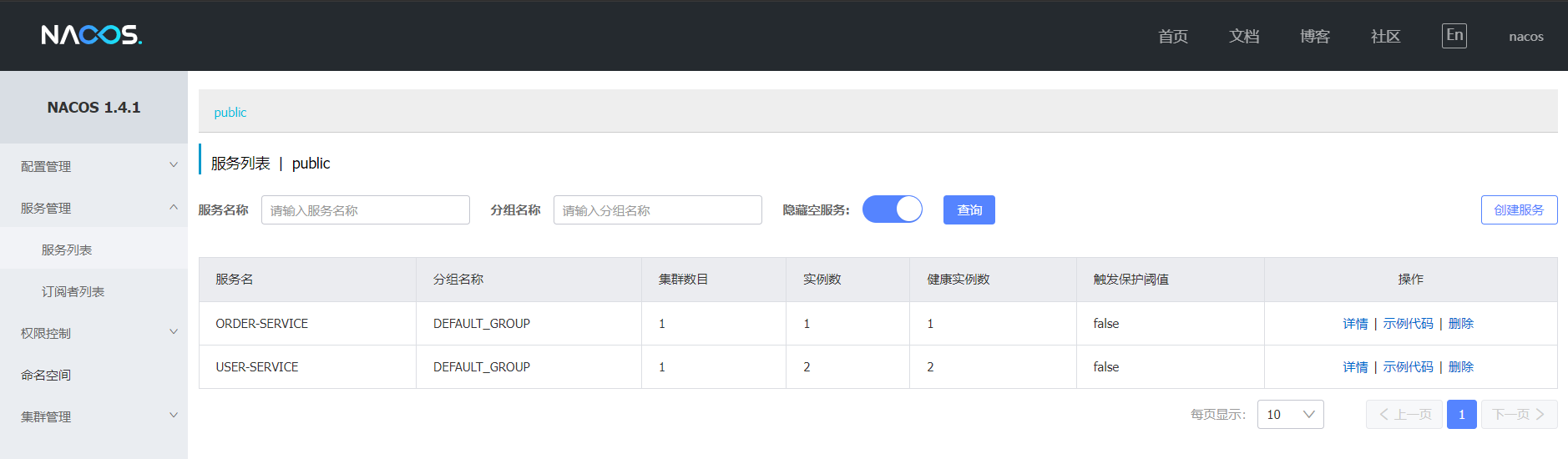
Nacos叢集設定與負載均衡策略調整
1、叢集設定:Nacos的服務多級儲存模型和其他的不一樣
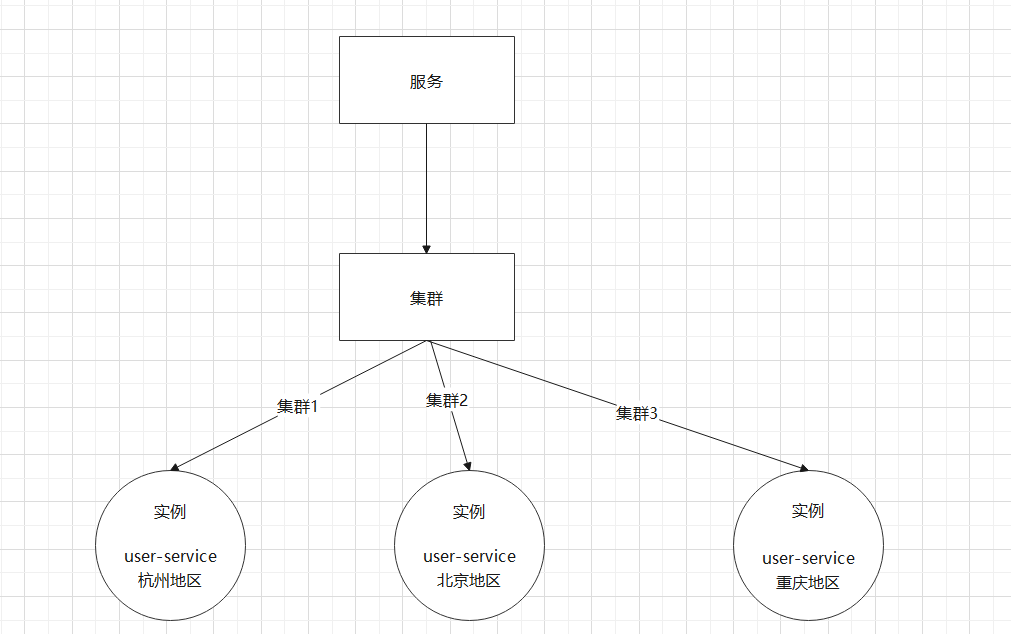
就多了一個叢集,不像其他的是 服務-----> 範例
好處:微服務互相存取時,應該儘可能存取同叢集範例,因為本地存取速度更快。當本叢集內不可用時,才存取其它叢集
設定服務叢集:想要對哪個服務設定叢集則在其yml組態檔中加入即可
server:
port: 8081
application:
name: USER-SERVICE
cloud:
nacos:
# Nacos伺服器地址
server-addr: localhost:8848
# 設定叢集名稱,如:HZ,杭州
cluster-name: HZ
測試則直接將「服務提供者」復刻多份,共用同一叢集名啟動,然後再復刻修改叢集名啟動即可,如下面的:
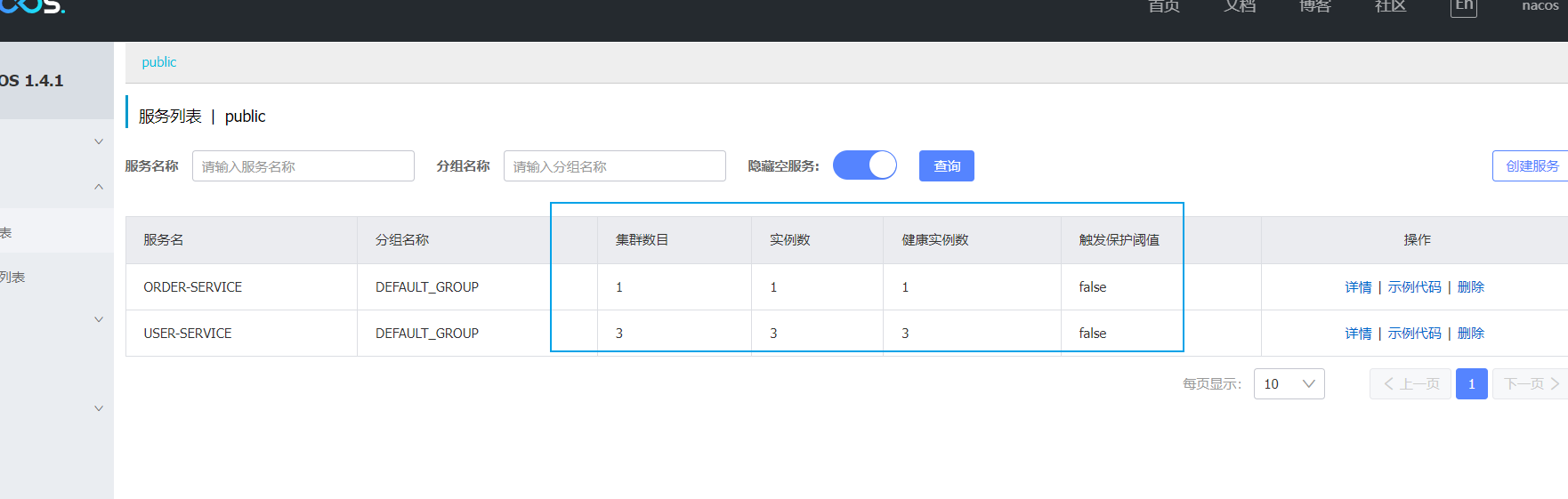
2、負載均衡策略調整:前面玩Ribbon時已經知道了預設是輪詢策略,而想要達到Nacos的 儘可能存取同叢集範例,因為本地存取速度更快。當本叢集內不可用時,才存取其它叢集 的功能,則就需要調整負載均衡策略,設定如下:
USER-SERVICE:
ribbon:
# 單獨對某個服務設定負載均衡策略
# NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule
# 改為Naocs的負載均衡策略
NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule
注: 再次說明前面提到的 ------> 負載均衡策略調整放在「服務消費方」
經過上面的設定之後,服務消費方去呼叫服務提供方的服務時,會優先選擇和服務消費方同叢集下的服務提供方的服務,若無法存取才跨叢集存取其他叢集下的服務提供方得到服務
- 小細節: 服務消費方存取同叢集下服務提供方的服務時(提供方是叢集,多範例),選擇這些範例中的哪一個服務時並不是採用輪詢了,而是隨機
另外的負載均衡策略就是Ribbon中的:
3、加權策略 :伺服器權重值越高,越容易被選擇,所以能者多勞,效能好的伺服器被存取的次數應該越多
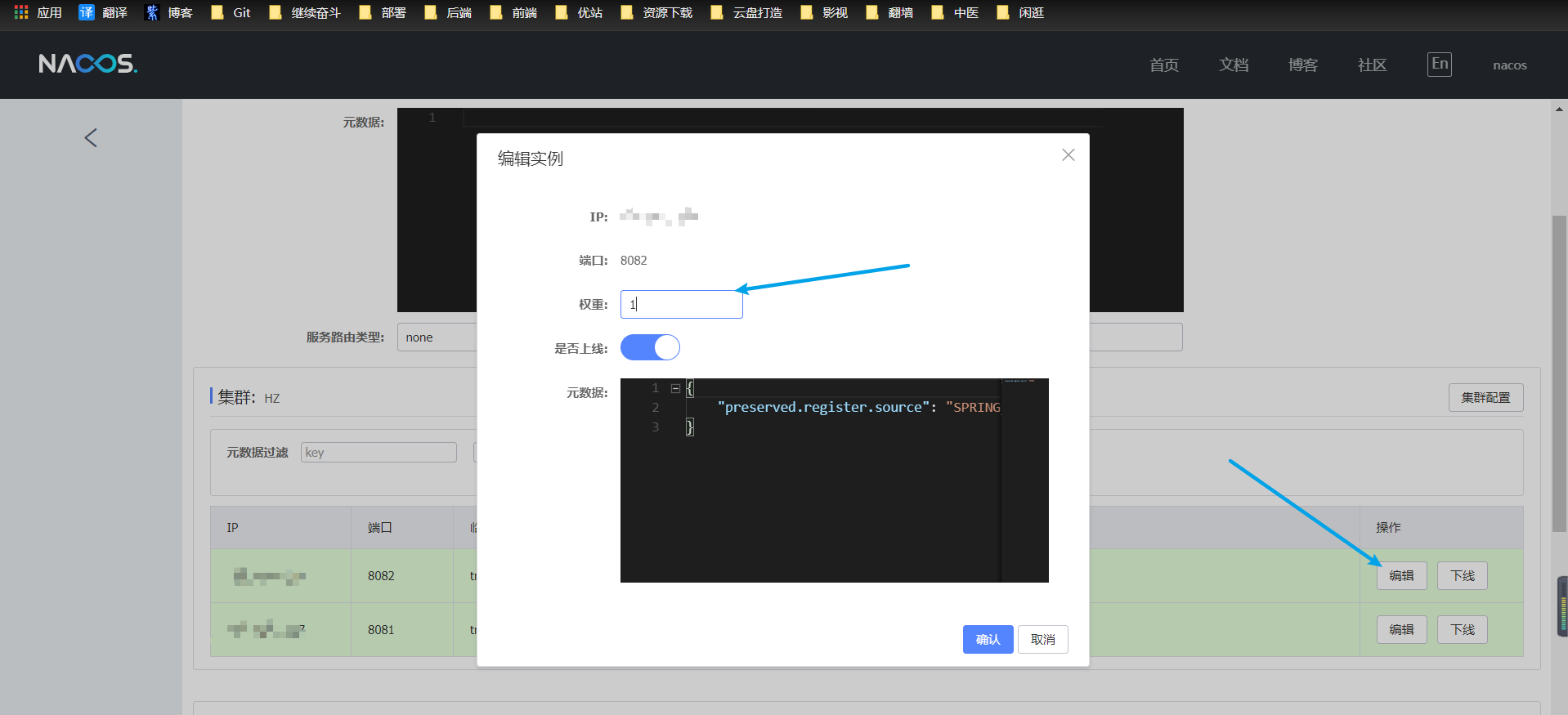
權重值一般在 [0,10000] 之間。直接去Nacos的控制檯中選擇想要修改權重值的服務,點選「詳情」即可修改
注: 當權重值為0時,代表此服務範例不會再被存取,類似於停機迭代
Nacos環境隔離
前面一節見到了Nacos的叢集結構,但那只是較內的一層,Nacos不止是註冊中心,也可以是資料中心
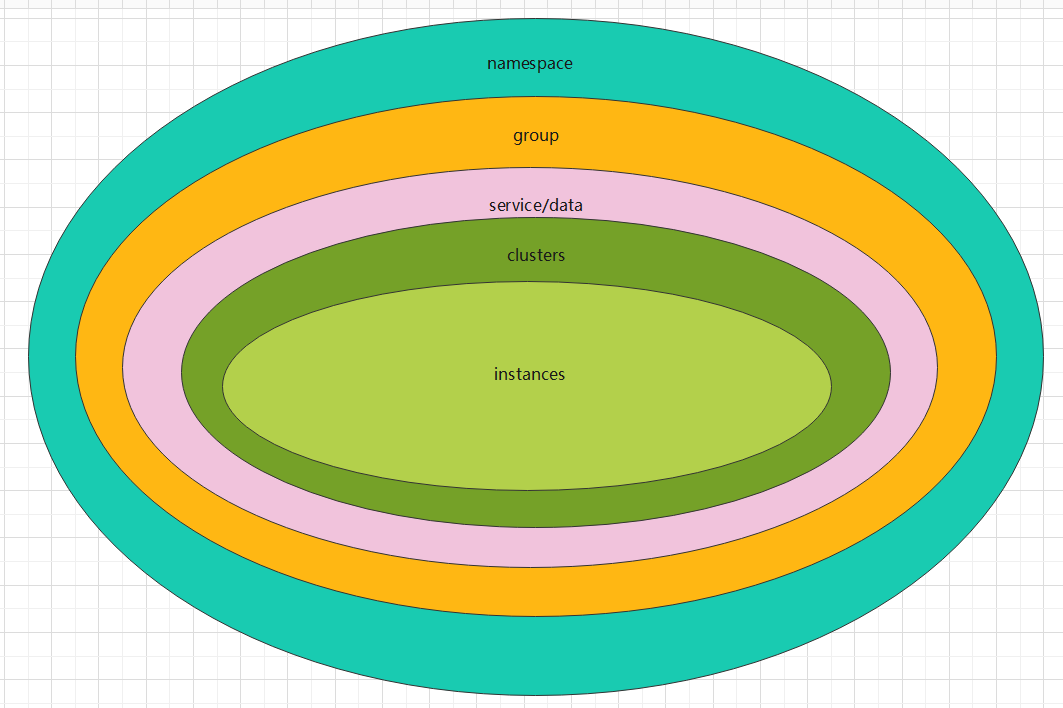
- namespace :就是環境隔離,如 dev開發環境、test測試環境、prod生產環境。若沒設定,則預設是public,在沒有指定名稱空間時都會預設從
public這個名稱空間拉取設定以及註冊到該名稱空間下的登入檔中。什麼是登入檔在後續看原始碼時會說明 - group :就是在namespace的基礎上,再進行分組,就是平時理解的分組,如 將服務相關性強的分在一個組
- service ----> clusters -----> instances :就是前面說的叢集,服務 ----> 叢集 ------> 範例
設定namespace: 注意事項如下
- 同名的名稱空間只能建立一個
- 微服務間如果沒有註冊到一個名稱空間下,無法使用OpenFeign指定服務名負載通訊(服務拉取的組態檔不同名稱空間不影響)。Feign是後面要玩的
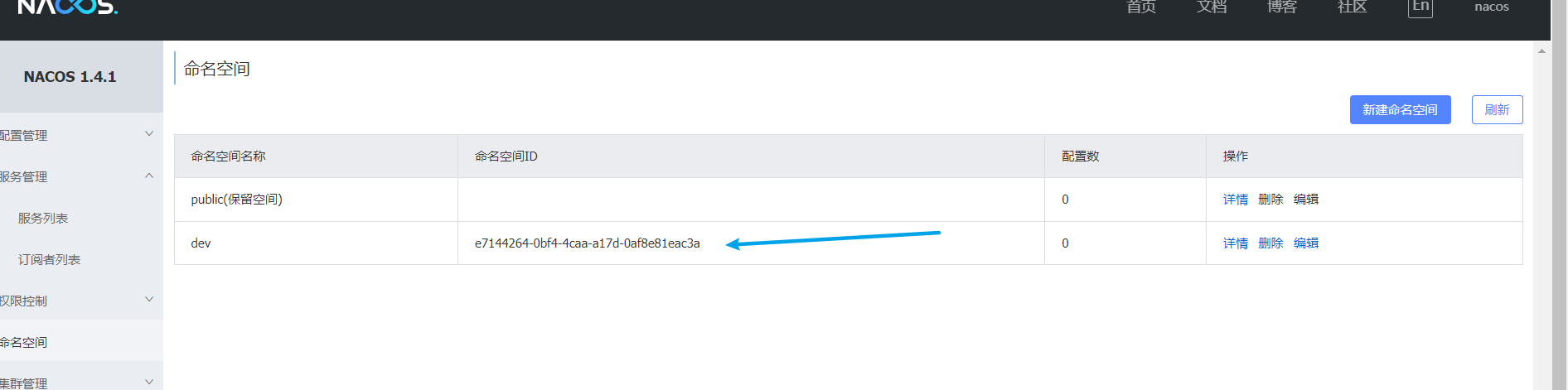
在yml組態檔中進行環境隔離設定
spring:
cloud:
nacos:
server-addr: localhost:8848
cluster-name: HZ
# 環境隔離:即當前這個服務要註冊到哪個名稱空間環境去
# 值為在Nacos控制檯建立名稱空間時的id值,如下面的dev環境
namespace: e7144264-0bf4-4caa-a17d-0af8e81eac3a
Nacos臨時與非臨時範例
1、Nacos和Eureka的不同:不同在下圖字型加粗的部分,加粗是Nacos具備而Eureka不具備的
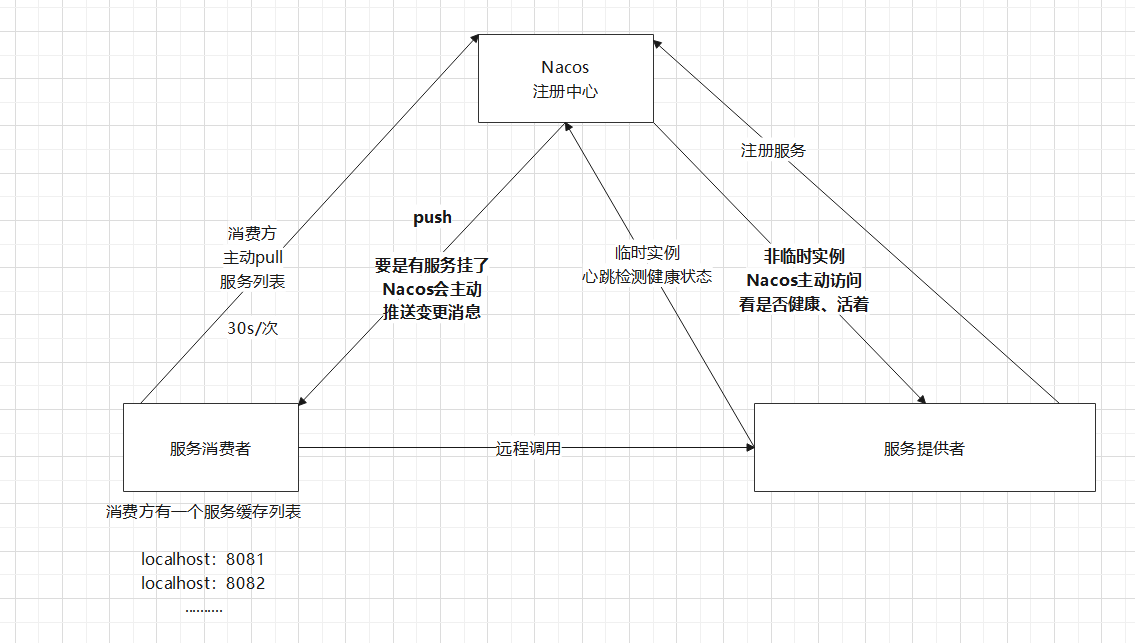
臨時範例: 由服務提供者主動給Nacos傳送心跳情況,在規定時間內要是沒有傳送,則Nacos認為此服務掛了,就會從服務列表中踢掉(非親兒子)
非臨時範例/永久範例:由Nacos主動來詢問服務是否還健康、活著(此種範例會讓伺服器壓力變大),若非臨時範例掛了,Naocs並不會將其踢掉(親兒子)
-
臨時範例:Nacos官網https://nacos.io/zh-cn/docs/open-api.html中的「服務發現」的「傳送範例心跳」中可以看到原始碼是在什麼地方找
-
適合:流量激增時使用(高並行故增加更多範例),後續流量下降了這些範例就可以不要了
-
採用使用者端心跳檢測模式,心跳週期5秒
-
心跳間隔超過15秒則標記為不健康
-
心跳間隔超過30秒則從服務列表刪除
-
-
永久範例:
-
適合:常備範例
-
採用伺服器端主動健康檢測方式
-
週期為2000 + 5000,即[2000, 7000]毫秒內的亂數
-
檢測異常只會標記為不健康,不會刪除
-
push:若是Nacos檢測到有服務提供者掛了,就會主動給消費者傳送服務變更的訊息,然後服務消費者更新自己的服務快取列表。這一步就會讓服務列表更新很及時
- 此方式是Nacos具備而Eureka不具備的,Eureka只有pull操作,因此Eureka的缺點就是服務更新可能會不及時(在30s內,服務提供者變動了,個別掛了,而消費者中的服務快取列表還是舊的,只能等到30s到了才去重新pull)
Nacos的服務發現分為兩種模式:
- 模式一:主動拉取模式(push模式),消費者定期主動從Nacos拉取服務列表並快取起來,再服務呼叫時優先讀取本地快取中的服務列表
- 模式二:訂閱模式(pull模式),消費者訂閱Nacos中的服務列表,並基於UDP協定來接收服務變更通知。當Nacos中的服務列表更新時,會傳送UDP廣播給所有訂閱者
檢視服務發現原始碼的地方:後續也會介紹

Nacos叢集預設採用AP方式,當叢集中存在非臨時範例時,採用CP模式;Eureka採用AP方式
補充:CAP定理 這是分散式事務中的一個方法論
- C 即:Consistency 資料一致性。指的是:使用者存取分散式系統中的任意節點,得到的資料必須一致
- A 即:Availability 可用性。指的是:使用者存取叢集中的任意健康節點,必須能得到響應,而不是超時或拒絕
- P 即:Partition Tolerance 分割區容錯性。指的是:由於某種原因導致系統中任意資訊的丟失或失敗都不能不會影響系統的繼續獨立運作
注: 分割區容錯性是必須滿足的,資料一致性( C )和 可用性( A )只滿足其一即可,一般的搭配是如下的(即:取捨策略):
- CP 保證資料的準確性
- AP 保證資料的及時性
既然CAP定理都整了,那就再加一個Base理論吧,這個理論是對CAP中C和A這兩個矛盾點的調和和選擇
- BA 即:Basically Available 基本可用性。指的是:在發生故障的時候,可以允許損失「非核心部分」的可用性,保證系統正常執行,即保證核心部分可用
- S 即:Soft State 軟狀態。指的是:允許系統的資料存在中間狀態,只要不影響整個系統的執行就行
- E 即:Eventual Consistency 最終一致性。指的是:無論以何種方式寫入資料庫 / 顯示出來,都要保證系統最終的資料是一致的
2、設定臨時範例與非臨時範例:在需要的一方的yml組態檔中設定如下開關即可
spring:
cloud:
nacos:
server-addr: localhost:8848
cluster-name: HZ
# 預設為true,即臨時範例
ephemeral: false
改完之後可以在Nacos控制檯看到服務是否為臨時範例
Nacos統一設定管理
統一設定管理: 將容易發生改變的設定單獨弄出來,然後在後續需要變更時,直接去統一設定管理處進行更改,這樣凡是依賴於這些設定的服務就可以統一被更新,而不用挨個服務更改設定,同時更改設定之後不用重啟服務,直接實現熱更新
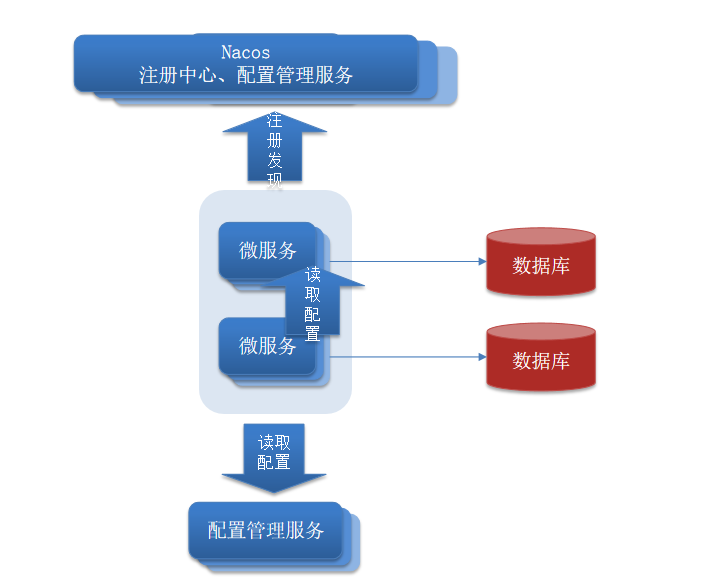
Nacos和SpringCloud原生的config不一樣,Nacos是將 註冊中心+config 結合在一起了,而SpringCloud原生的是Eureka+config
1、設定Nacos設定管理
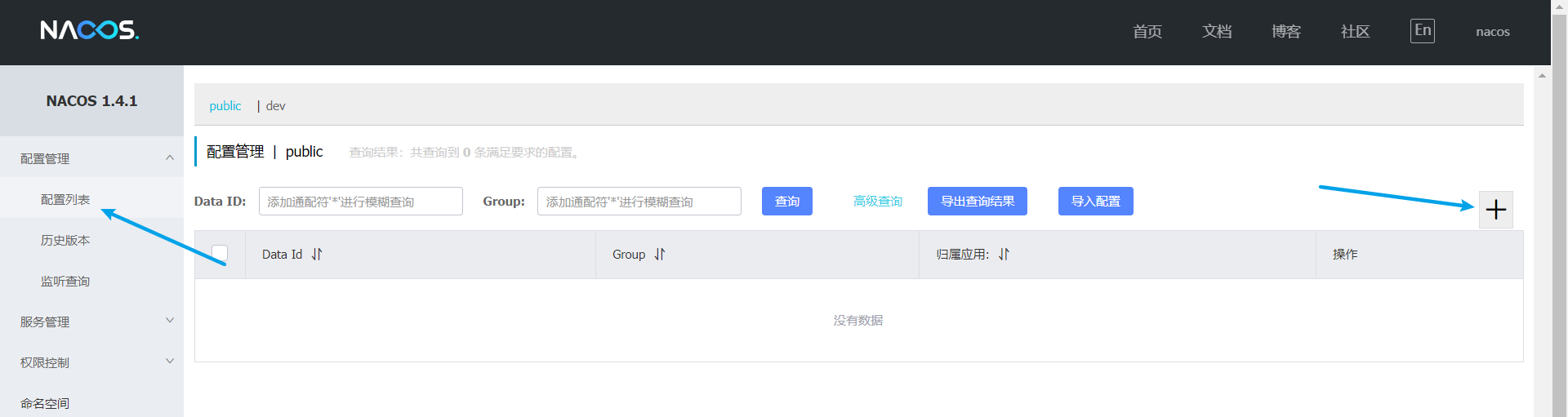
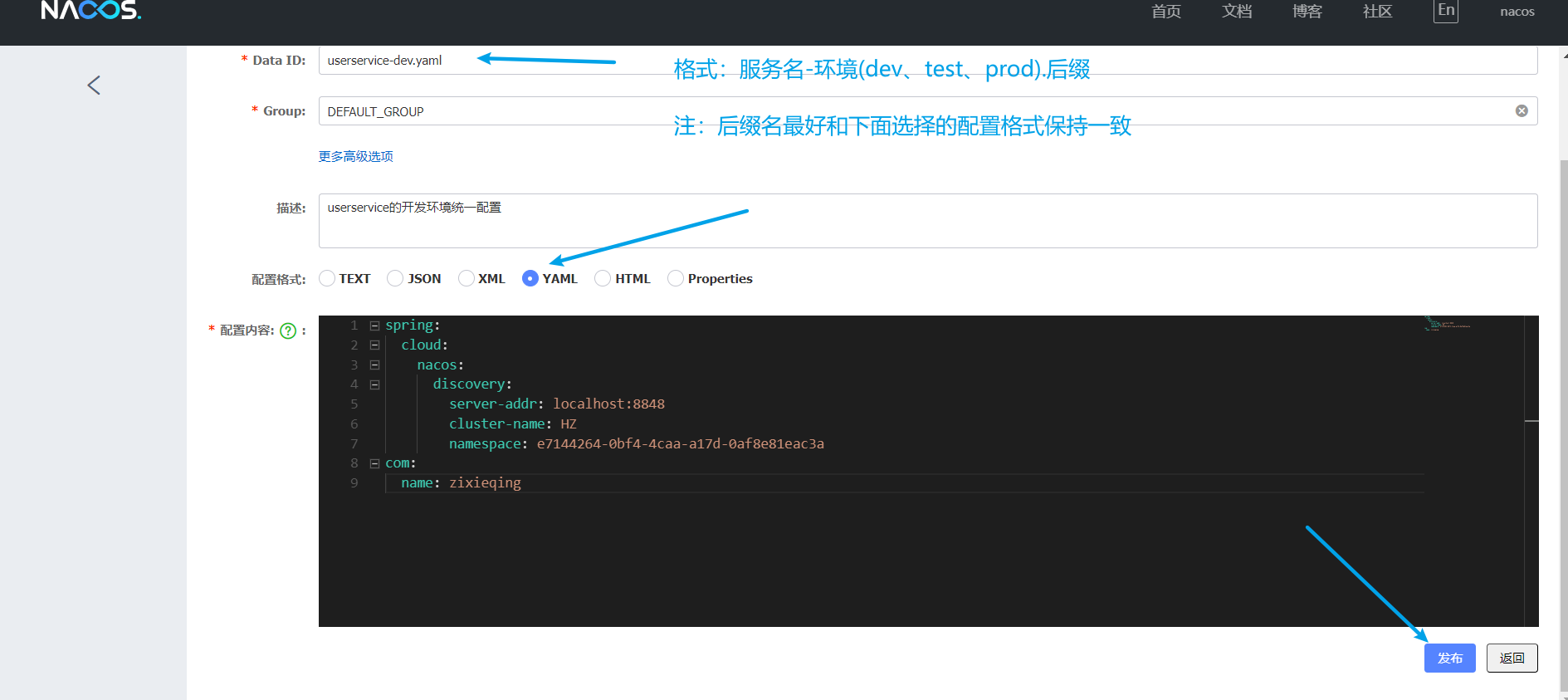
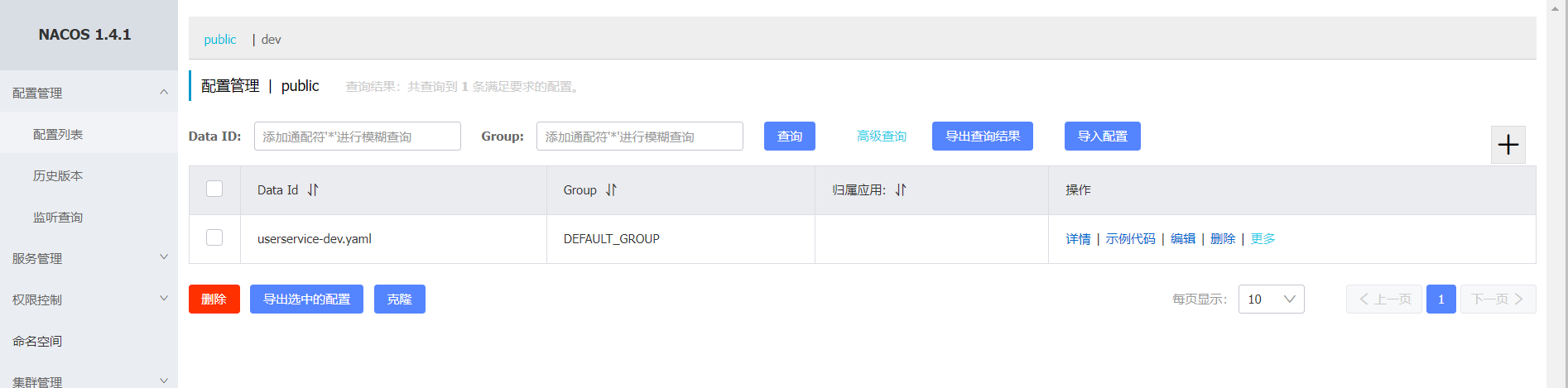
以上便是在Nacos中設定了統一設定。但是:專案/服務想要得到這些設定,那就得獲取到這些設定,怎麼辦?
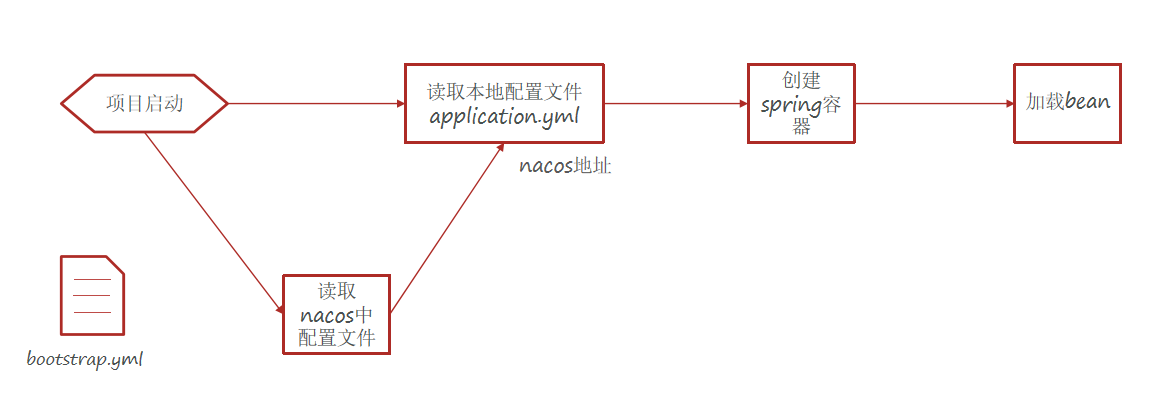
在前面說過SpringCloud中有兩種yml的設定方式,一種是 application.yml ,一種是 bootstrap.yml ,這裡就需要藉助後者了,它是引導檔案,優先順序比前者高,會優先被載入,這樣就可以先使用它載入到Nacos中的組態檔,然後再讀取 application.yml ,從而完成Spring的那一套註冊範例的事情
2、在需要讀取Nacos統一設定的服務中引入如下依賴:
<!--nacos設定管理依賴-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
3、resources下新建 bootstrap.yml,裡面的設定內容如下
spring:
application:
# 服務名,對應在nacos中進行設定管理的data id的服務名
name: userservice
profiles:
# 環境,對應在nacos中進行設定管理的data id的環境
active: dev
cloud:
nacos:
# nacos伺服器地址,需要知道去哪裡拉取設定資訊
server-addr: localhost:8848
config:
# 檔案字尾,對應在nacos中進行設定管理的data id的字尾名
file-extension: yaml
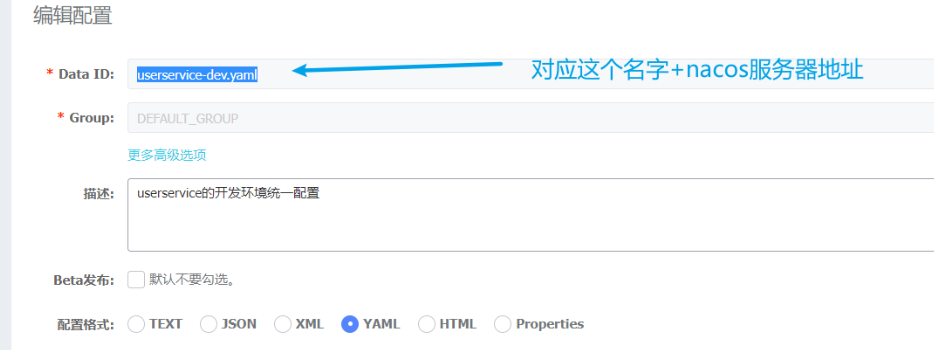
經過上面的操作之後,以前需要單獨在 application.yml 改的事情就不需要了,bootstrap.yml 設定的東西會去拉取nacos中的設定
4、設定熱更新: 假如業務程式碼中有需要用到nacos中的設定資訊,那nacos中的設定改變之後,不需要重啟服務,自動更新。一共有兩種方式
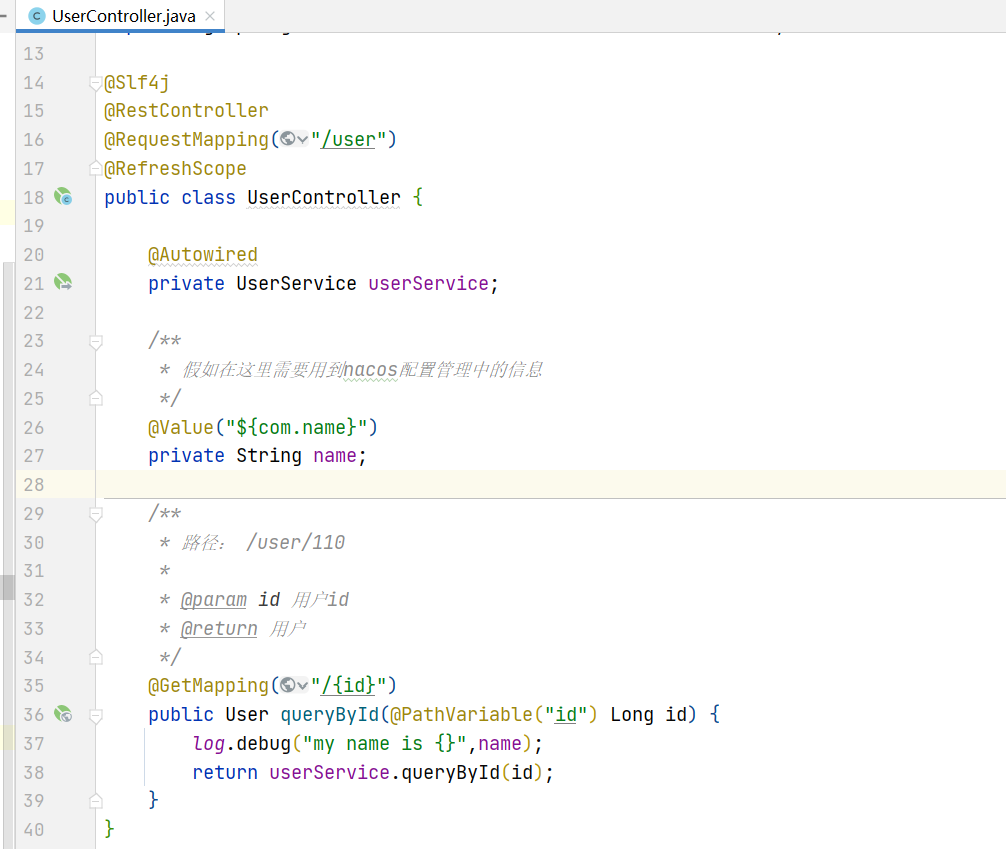
@RefreshScope+@Value註解: 在 @Value 注入的變數所在類上新增註解 @RefreshScope
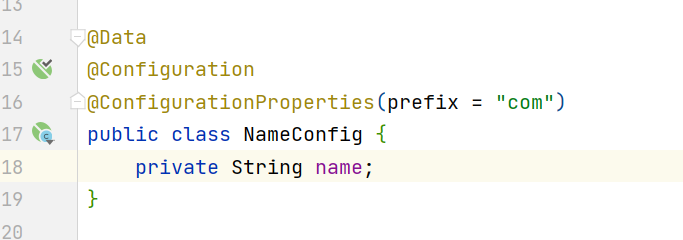
@ConfigurationProperties註解
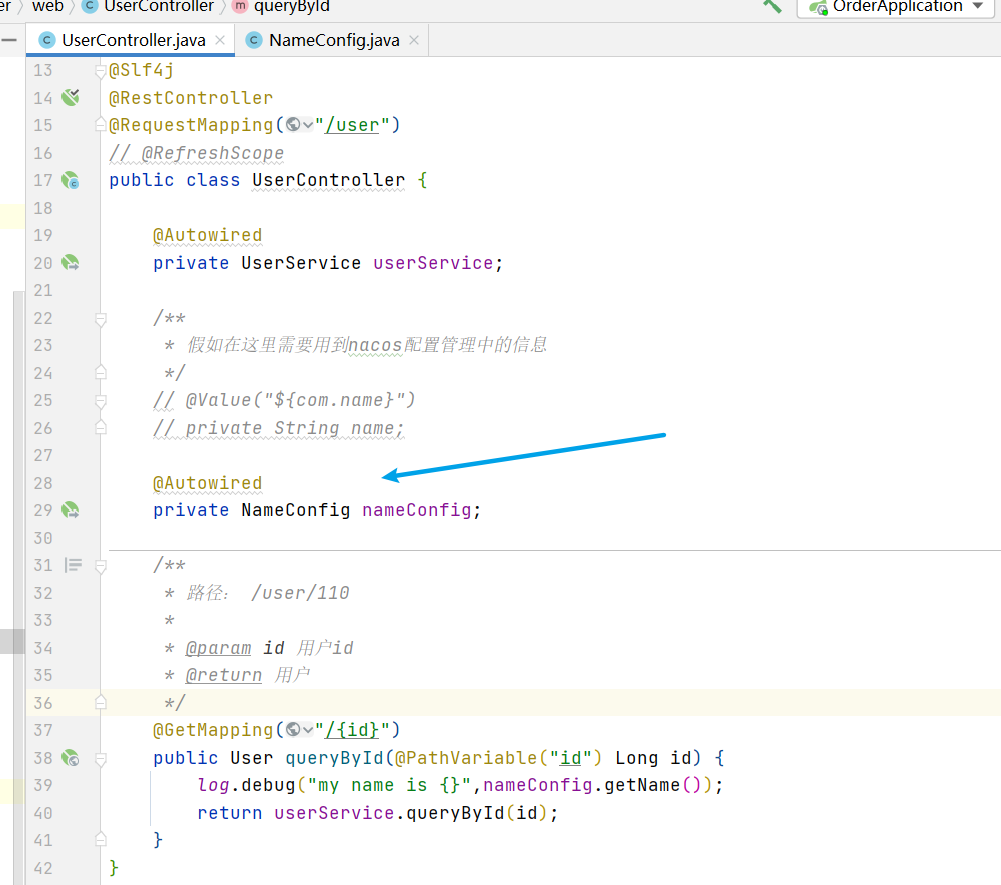
然後在需要的地方直接注入物件即可
Nacos多環境共用設定
有時會遇到這樣的情況:生產環境、開發環境、測試環境有些設定是相同的,這種應該不需要在每個環境中都設定,因此需要讓這些相同的設定單獨弄出來,然後實行共用
在前面一節中已經說到了一種Nacos的組態檔格式 即 服務名-環境.字尾,除了這種還有一種格式 即 服務名.字尾
因此:想要讓環境設定共用,那麼直接在Nacos控制檯的設定中再加一個以 服務名.字尾名 格式命名的設定即可,如下:
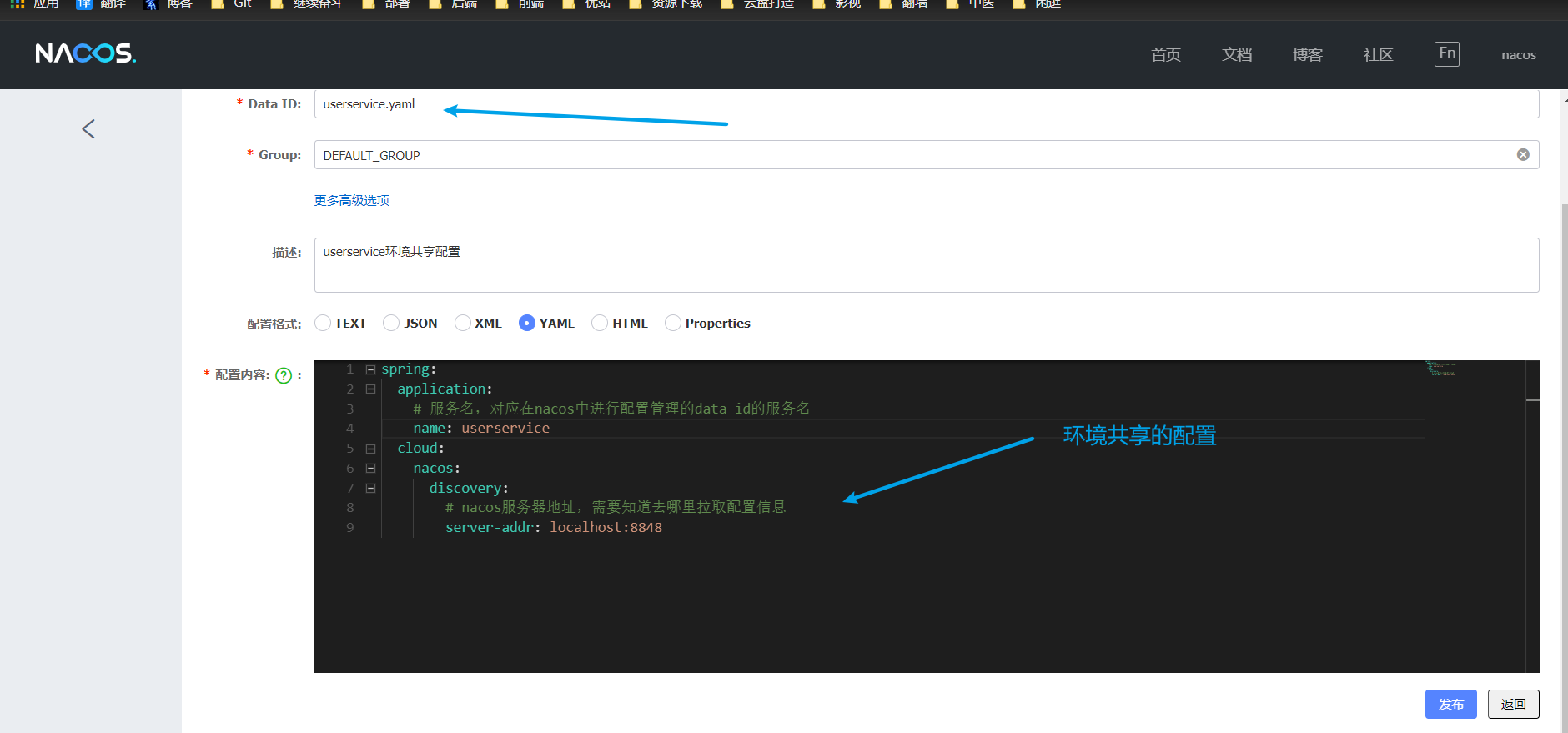
其他的都不用動,要只是針對於專案中的yml,如 appilication.yml,那前面已經說了,會先讀取Nacos中設定,然後和 application.yml 進行合併
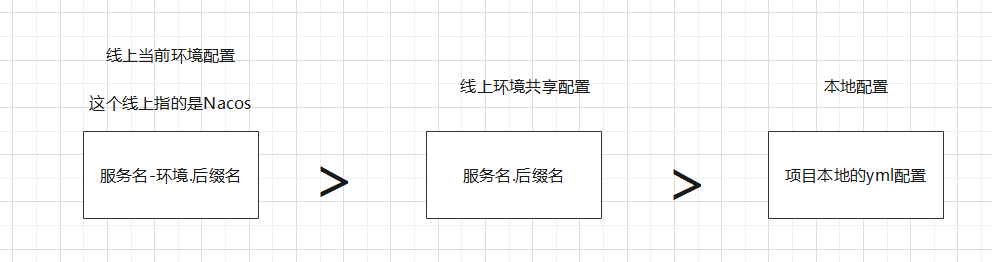
但是:若專案原生的yml中、服務名.字尾、服務名-環境.字尾 中有相同的屬性/設定時,優先順序不一樣,如下:
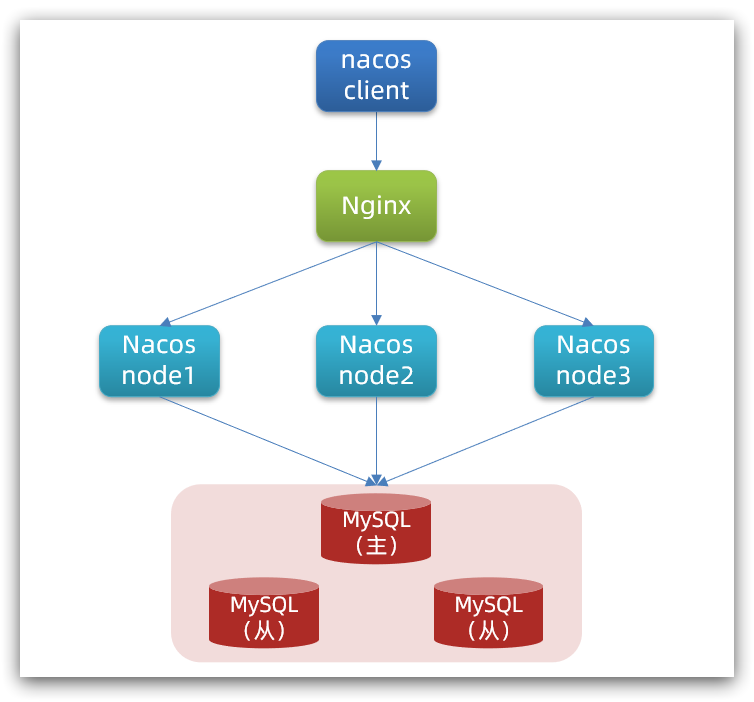
Nacos叢集部署
windows和Linux都是一樣的思路,叢集部署的邏輯如下:
1、解壓壓縮包
2、進入nacos的conf目錄,修改組態檔cluster.conf.example,重新命名為cluster.conf,並新增要部署的叢集ip+port,如下:
ip1:port1
ip2:port2
ip3:port3
3、然後修改conf/application.properties檔案,新增資料庫設定
# 告訴nacos資料庫叢集是MySQL,根據需要自定義
spring.datasource.platform=mysql
# 資料庫的數量
db.num=1
# 資料庫url
db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
# 資料庫使用者名稱
db.user.0=root
# 資料庫密碼
db.password.0=88888
4、複製解壓包,部署到不同伺服器,然後改變每個解壓包的埠,路徑:conf/application.properties檔案,例如:
# 第一個nacos節點
server.port=8845
# 第二個nacos節點
server.port=8846
# 第三個nacos節點
server.port=8847
5、挨個啟動nacos即可,進入到解壓的nacos的bin目錄中,執行如下命令即可
startup.cmd
此命令告知:nacos預設就是叢集啟動,前面玩時加了 -m standalone 就是單機啟動
5、使用Nginx做反向代理 :修改conf/nginx.conf檔案,設定如下:
upstream nacos-cluster {
server ip1:port1;
server ip2:port2;
server ip3:port3;
}
server {
listen 80;
server_name localhost;
location /nacos {
proxy_pass http://nacos-cluster;
}
}
6、程式碼中application.yml檔案設定如下:
spring:
cloud:
nacos:
# Nacos地址,上一步Nginx中的 server_name+listen監聽的埠
server-addr: localhost:80
7、存取 http://localhost/nacos 即可
- 注:瀏覽器預設就是80埠,而上面Nginx中監聽的就是80,所以根據情況自行修改這裡的存取路徑
Nacos服務登入檔結構是怎樣的?
分析原始碼就在nacos官網下載的source.code:nacos-naming/controller/InstanceController#register(HttpServletRequest request)
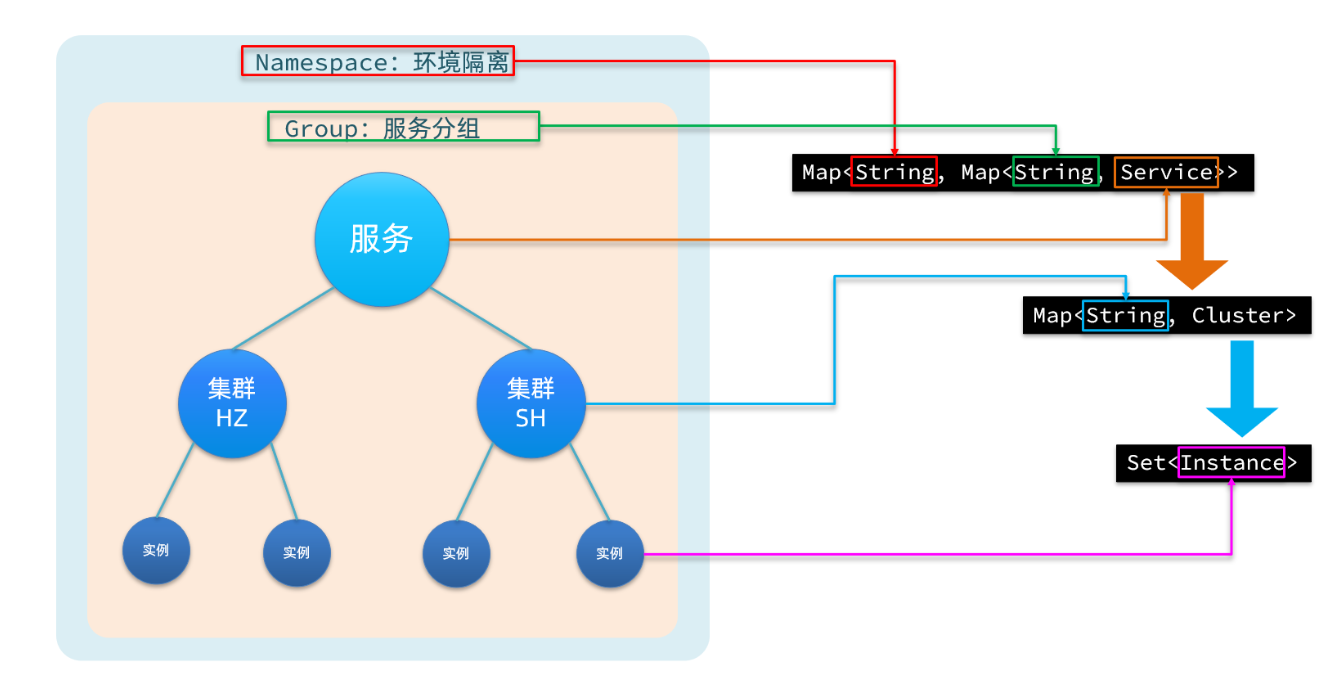
Java程式碼中是使用了Map<String, Map<String, Service>>:每一個服務去註冊到Nacos時,就會把資訊組織並存入這個Map中
- key:是namespace_id,用於環境隔離
- value:是Map<String, Service>
- key:是group,但是是使用group+serviceName組成的key
- value:表示Service服務,這個Service又套了一個Map<String, Cluster>
- key:就是叢集名
- value:就是Cluster物件,這裡面又套了一個Set
,這裡面就是範例了
Nacos如何為何能抗住數十萬服務註冊壓力?
原始碼在:nacos-naming/controller/InstanceController#register(HttpServletRequest request)中的serviceManager.registerInstance(namespaceId, serviceName, instance)裡面
先看抗住壓力的原因的結論:
- 在Nacos叢集下,對於臨時範例,服務註冊時是將其丟給了一個ArrayBlockingQueue阻塞佇列,然後就返回使用者端,最後通過一個死迴圈利用執行緒池去執行阻塞佇列中的任務(註冊服務),這就做到了非同步操作
- 將服務更新情況同步給叢集中的其他節點也是同樣的原理,底層還是用了阻塞佇列+執行緒池
具體的邏輯在 DistroConsistencyServiceImpl.put()中
public class DistroConsistencyServiceImpl {
@Override
public void put(String key, Record value) throws NacosException {
// 非同步服務註冊 key是服務唯一id,value就是instances
onPut(key, value);
// 服務更強情況非同步更新給叢集下的另外節點
distroProtocol.sync(new DistroKey(key, KeyBuilder.INSTANCE_LIST_KEY_PREFIX), DataOperation.CHANGE,
globalConfig.getTaskDispatchPeriod() / 2);
}
/**
* Put a new record.
*
* @param key key of record
* @param value record
*/
public void onPut(String key, Record value) {
// 判斷是否是臨時範例
if (KeyBuilder.matchEphemeralInstanceListKey(key)) {
// 封裝 Instances 資訊到 資料集:Datum
Datum<Instances> datum = new Datum<>();
// value就是instances
datum.value = (Instances) value;
// key是服務的唯一id
datum.key = key;
// 加入當前修改時間
datum.timestamp.incrementAndGet();
// 資料儲存 放入dataStore中
dataStore.put(key, datum);
}
if (!listeners.containsKey(key)) {
return;
}
// notifier這玩意兒 implements Runnable
notifier.addTask(key, DataOperation.CHANGE);
}
public class Notifier implements Runnable {
private ConcurrentHashMap<String, String> services = new ConcurrentHashMap<>(10 * 1024);
/**
* 維護了一個阻塞佇列
*/
private BlockingQueue<Pair<String, DataOperation>> tasks = new ArrayBlockingQueue<>(1024 * 1024);
/**
* Add new notify task to queue.
*
* @param datumKey data key
* @param action action for data
*/
public void addTask(String datumKey, DataOperation action) {
if (services.containsKey(datumKey) && action == DataOperation.CHANGE) {
return;
}
if (action == DataOperation.CHANGE) {
services.put(datumKey, StringUtils.EMPTY);
}
// 將服務唯一id + 事件型別(CHANGE)放入了阻塞佇列
tasks.offer(Pair.with(datumKey, action));
}
@Override
public void run() {
Loggers.DISTRO.info("distro notifier started");
for (; ; ) { // 死迴圈
try {
// 去阻塞佇列中獲取任務
Pair<String, DataOperation> pair = tasks.take();
// 有任務就處理任務,更新服務列表;無任務就進入wait,所以此死迴圈不會導致CPU負載過高
handle(pair);
} catch (Throwable e) {
Loggers.DISTRO.error("[NACOS-DISTRO] Error while handling notifying task", e);
}
}
}
/**
* DistroConsistencyServiceImpl.Notifier類的 handle 方法:即 handle(pair) 中的邏輯
*/
private void handle(Pair<String, DataOperation> pair) {
try {
String datumKey = pair.getValue0();
DataOperation action = pair.getValue1();
services.remove(datumKey);
int count = 0;
if (!listeners.containsKey(datumKey)) {
return;
}
// 遍歷,找到變化的service,這裡的 RecordListener 就是 Service
for (RecordListener listener : listeners.get(datumKey)) {
count++;
try {
// 如果是 CHANGE 事件
if (action == DataOperation.CHANGE) {
// 就更新服務列表
listener.onChange(datumKey, dataStore.get(datumKey).value);
continue;
}
// 如果是 DELETE 事件
if (action == DataOperation.DELETE) {
// 就根據服務ID刪除從服務列表中刪除服務
listener.onDelete(datumKey);
continue;
}
} catch (Throwable e) {
Loggers.DISTRO.error("[NACOS-DISTRO] error while notifying listener of key: {}", datumKey, e);
}
}
if (Loggers.DISTRO.isDebugEnabled()) {
Loggers.DISTRO
.debug("[NACOS-DISTRO] datum change notified, key: {}, listener count: {}, action: {}",
datumKey, count, action.name());
}
} catch (Throwable e) {
Loggers.DISTRO.error("[NACOS-DISTRO] Error while handling notifying task", e);
}
}
}
}
因此能抗住壓力的原因:
- 在Nacos叢集下,對於臨時範例,服務註冊時是將其丟給了一個ArrayBlockingQueue阻塞佇列,然後就返回使用者端,最後通過一個死迴圈利用執行緒池去執行阻塞佇列中的任務(註冊服務),這就做到了非同步操作
- 將服務更新情況同步給叢集中的其他節點也是同樣的原理,底層還是用了阻塞佇列+執行緒池
Nacos範例的並行讀寫問題
原始碼還是在:nacos-naming/controller/InstanceController#register(HttpServletRequest request)中的serviceManager.registerInstance(namespaceId, serviceName, instance)裡面
具體思路:採用了同步鎖+CopyOnWrite思想
- 並行讀的解決方式 - CopyOnWrite思想:將原來的範例列表Map拷貝給了一個新的Map,然後對新的範例列表Map進行增刪,最後將新的範例列表Map的參照給舊的範例列表Map
- 並行寫的解決方式:
- 在註冊範例時,會使用synchronized同步鎖對service進行加鎖,不同service不影響,相同service通過鎖排斥
- 另外還有一個原因是:更新範例列表時,底層使用了執行緒池非同步更新範例列表,但是執行緒池的執行緒數量為「1」
@Component
public class ServiceManager {
public void addInstance(String namespaceId, String serviceName, boolean ephemeral, Instance... ips)
throws NacosException {
// 監聽服務列表用到的key,服務唯一標識
// 如:com.alibaba.nacos.naming.iplist.ephemeral.public##DEFAULT_GROUP@@order-service
String key = KeyBuilder.buildInstanceListKey(namespaceId, serviceName, ephemeral);
// 獲取服務
Service service = getService(namespaceId, serviceName);
// 同步鎖:解決並行寫的問題
synchronized (service) {
// 1、獲取要更新的範例列表
// addIPAddress中,會拷貝舊的範例列表,新增新範例到列表中 即:COPY
List<Instance> instanceList = addIpAddresses(service, ephemeral, ips);
// 2、將更新後的資料封裝到Instances物件
Instances instances = new Instances();
instances.setInstanceList(instanceList);
// 3、完成 登入檔更新 以及 Nacos叢集的資料同步(保證叢集一致性)
// 在這裡面 完成對範例狀態更新後,會用新列表直接覆蓋舊範例列表。而在更新過程中,舊範例列表不受影響,使用者依然可以讀取
consistencyService.put(key, instances);
}
}
private List<Instance> addIpAddresses(Service service, boolean ephemeral, Instance... ips) throws NacosException {
return updateIpAddresses(service, UtilsAndCommons.UPDATE_INSTANCE_ACTION_ADD, ephemeral, ips);
}
/**
* 拷貝舊的範例列表,新增新範例到列表中
*/
public List<Instance> updateIpAddresses(Service service, String action, boolean ephemeral, Instance... ips)
throws NacosException {
// 根據namespaceId、serviceName獲取當前服務的範例列表,返回值是Datum
// 第一次來,肯定是null
Datum datum = consistencyService
.get(KeyBuilder.buildInstanceListKey(service.getNamespaceId(), service.getName(), ephemeral));
// 得到服務中舊的範例列表
List<Instance> currentIPs = service.allIPs(ephemeral);
// 儲存範例列表,key為ip地址,value是Instance物件
Map<String, Instance> currentInstances = new HashMap<>(currentIPs.size());
// 建立Set集合,儲存範例的instanceId
Set<String> currentInstanceIds = Sets.newHashSet();
// 遍歷舊範例列表
for (Instance instance : currentIPs) {
// 儲存範例列表
currentInstances.put(instance.toIpAddr(), instance);
// 新增instanceId到set中
currentInstanceIds.add(instance.getInstanceId());
}
// 用來儲存更新後的範例列表
Map<String, Instance> instanceMap;
// 如果服務中已經有舊的資料
if (datum != null && null != datum.value) {
// 將舊範例列表與新範例列表進行比對、合併
instanceMap = setValid(((Instances) datum.value).getInstanceList(), currentInstances);
} else {
// 若服務中沒有資料,則直接建立新的map
instanceMap = new HashMap<>(ips.length);
}
// 遍歷新範例列表ips
for (Instance instance : ips) {
// 判斷服務中是否包含要註冊的範例的cluster資訊
if (!service.getClusterMap().containsKey(instance.getClusterName())) {
// 如果不包含,建立新的cluster
Cluster cluster = new Cluster(instance.getClusterName(), service);
cluster.init();
// 將叢集放入service的登入檔
service.getClusterMap().put(instance.getClusterName(), cluster);
// ......記錄紀錄檔
}
// 刪除範例 or 新增範例
// 若是Remove刪除事件型別
if (UtilsAndCommons.UPDATE_INSTANCE_ACTION_REMOVE.equals(action)) {
// 則通過範例ID刪除範例
instanceMap.remove(instance.getDatumKey());
} else {
// 通過範例ID從舊範例列表中獲取範例
Instance oldInstance = instanceMap.get(instance.getDatumKey());
if (oldInstance != null) {
// 若舊範例列表中有這個範例 則將舊範例ID賦值給新範例ID
instance.setInstanceId(oldInstance.getInstanceId());
} else {
// 若舊範例列表中沒有這個範例 則給新範例生成一個範例ID
instance.setInstanceId(instance.generateInstanceId(currentInstanceIds));
}
// 範例ID為key、範例為value存入新範例列表
instanceMap.put(instance.getDatumKey(), instance);
}
}
if (instanceMap.size() <= 0 && UtilsAndCommons.UPDATE_INSTANCE_ACTION_ADD.equals(action)) {
throw new IllegalArgumentException(
"ip list can not be empty, service: " + service.getName() + ", ip list: " + JacksonUtils
.toJson(instanceMap.values()));
}
// 將instanceMap中的所有範例轉為List返回
return new ArrayList<>(instanceMap.values());
}
}
服務註冊原始碼
Nacos的登入檔結構是什麼樣的?
-
Nacos是多級儲存模型,最外層通過namespace來實現環境隔離,然後是group分組,分組下就是service服務,一個服務又可以分為不同的cluster叢集,叢集中包含多個instance範例。因此其登入檔結構為一個Map,型別是:
Map<String, Map<String, Service>>,外層key是
namespace_id,內層key是group+serviceName.Service內部維護一個Map,結構是:
Map<String,Cluster>,key是clusterName,值是叢集資訊Cluster內部維護一個Set集合,元素是Instance型別,代表叢集中的多個範例。
Nacos如何保證並行寫的安全性?
- 在註冊範例時,會對service加鎖,不同service之間本身就不存在並行寫問題,互不影響。相同service時通過鎖來互斥。並且,在更新範例列表時,是基於非同步的執行緒池來完成,而執行緒池的執行緒數量為1.
問題延伸:Nacos是如何應對數十萬服務的並行寫請求?
- Nacos內部會將服務註冊的任務放入阻塞佇列,採用執行緒池非同步來完成範例更新,從而提高並行寫能力
Nacos如何避免並行讀寫的衝突?
- Nacos在更新範例列表時,會採用CopyOnWrite技術,首先將Old範例列表拷貝一份,然後更新拷貝的範例列表,再用更新後的範例列表來覆蓋舊的範例列表。
使用者端
流程如下:
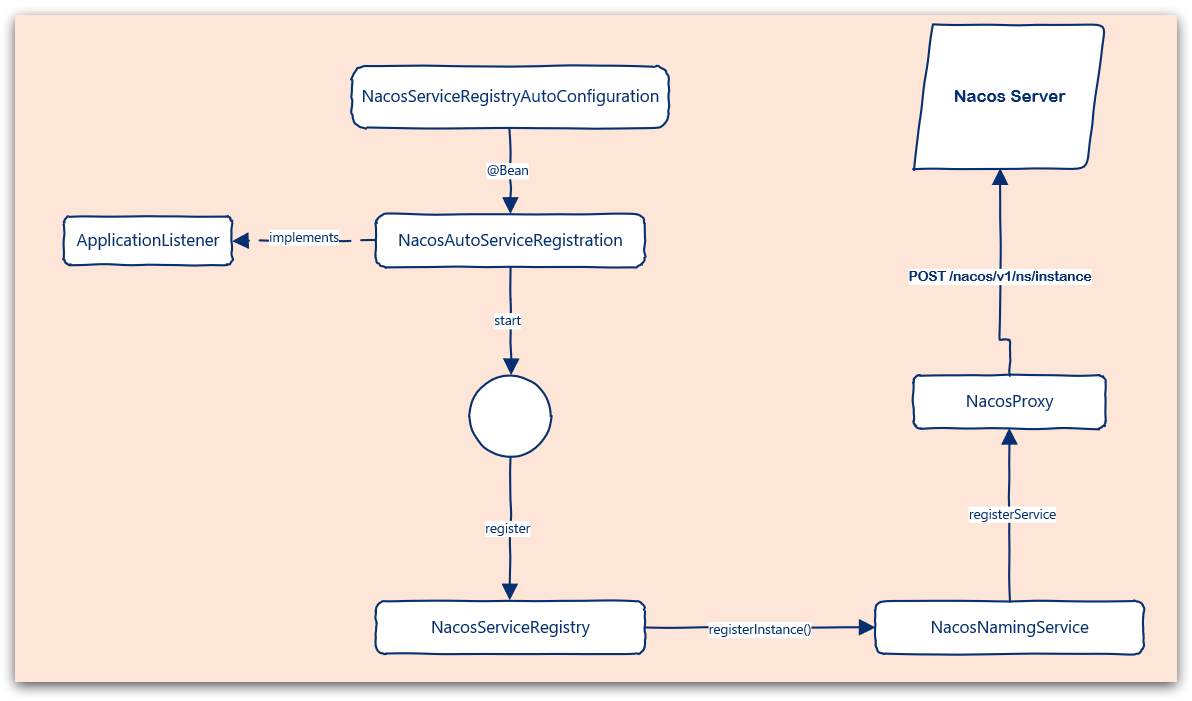
NacosServiceRegistryAutoConfiguration
Nacos的使用者端是基於SpringBoot的自動裝配實現的,我們可以在nacos-discovery依賴:
spring-cloud-starter-alibaba-nacos-discovery-2.2.6.RELEASE.jar
這個包中找到Nacos自動裝配資訊:

可以看到,在NacosServiceRegistryAutoConfiguration這個類中,包含一個跟自動註冊有關的Bean:
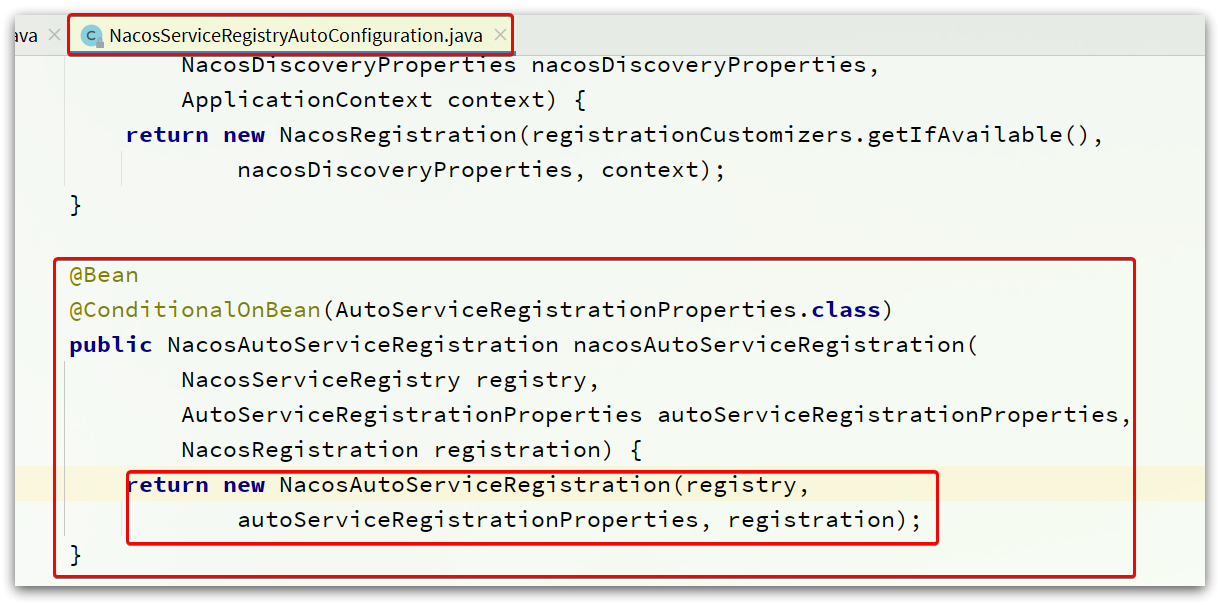
NacosAutoServiceRegistration
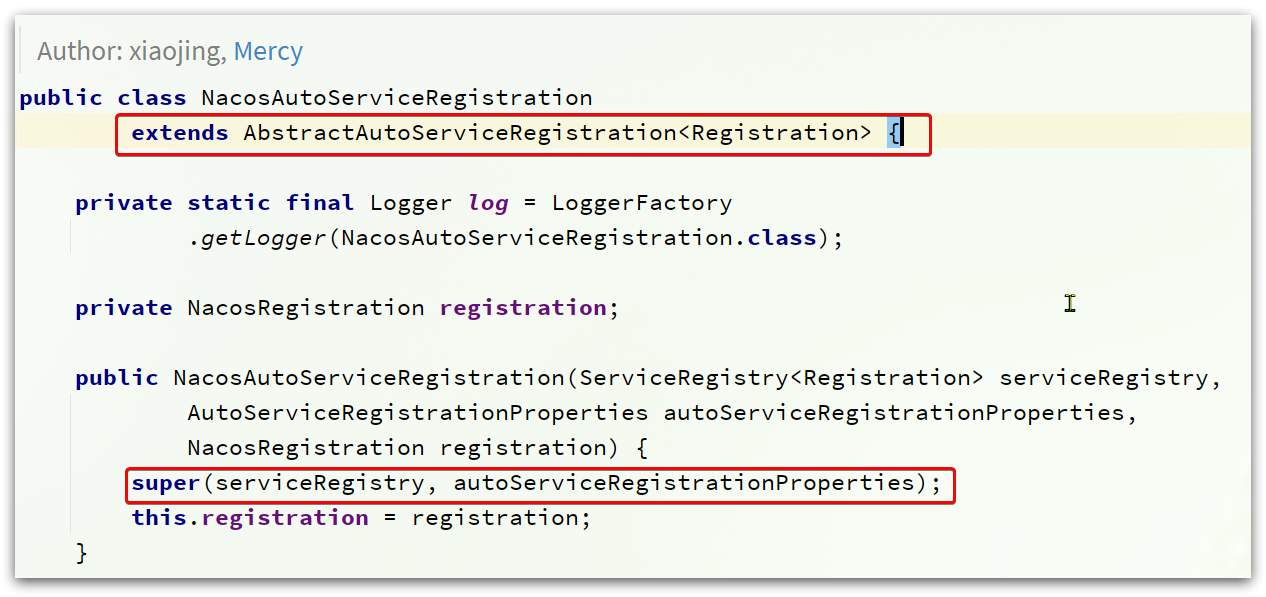
可以看到在初始化時,其父類別AbstractAutoServiceRegistration也被初始化了
AbstractAutoServiceRegistration如圖:
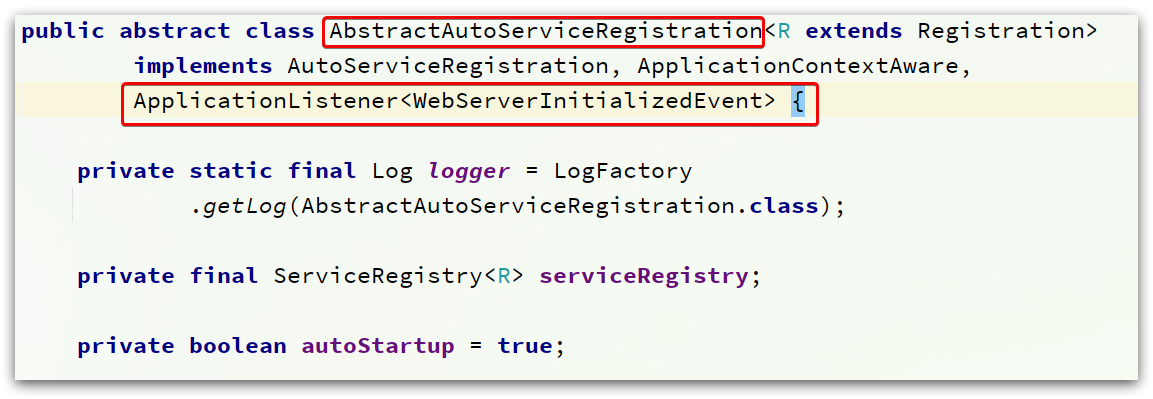
可以看到它實現了ApplicationListener介面,監聽Spring容器啟動過程中的事件
在監聽到WebServerInitializedEvent(web服務初始化完成)的事件後,執行了bind 方法。
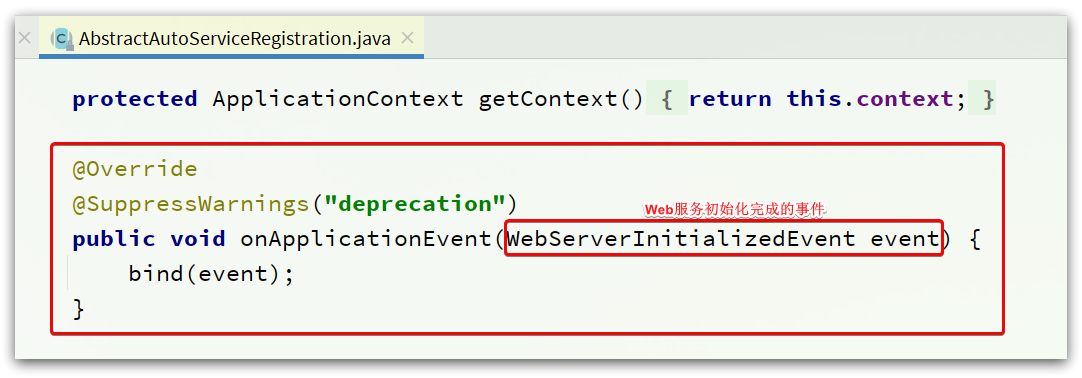
其中的bind方法如下:
public void bind(WebServerInitializedEvent event) {
// 獲取 ApplicationContext
ApplicationContext context = event.getApplicationContext();
// 判斷服務的 namespace,一般都是null
if (context instanceof ConfigurableWebServerApplicationContext) {
if ("management".equals(((ConfigurableWebServerApplicationContext) context)
.getServerNamespace())) {
return;
}
}
// 記錄當前 web 服務的埠
this.port.compareAndSet(0, event.getWebServer().getPort());
// 啟動當前服務註冊流程
this.start();
}
其中的start方法流程:
public void start() {
if (!isEnabled()) {
if (logger.isDebugEnabled()) {
logger.debug("Discovery Lifecycle disabled. Not starting");
}
return;
}
// 當前服務處於未執行狀態時,才進行初始化
if (!this.running.get()) {
// 釋出服務開始註冊的事件
this.context.publishEvent(
new InstancePreRegisteredEvent(this, getRegistration()));
// ☆☆☆☆開始註冊☆☆☆☆
register();
if (shouldRegisterManagement()) {
registerManagement();
}
// 釋出註冊完成事件
this.context.publishEvent(
new InstanceRegisteredEvent<>(this, getConfiguration()));
// 服務狀態設定為執行狀態,基於AtomicBoolean
this.running.compareAndSet(false, true);
}
}
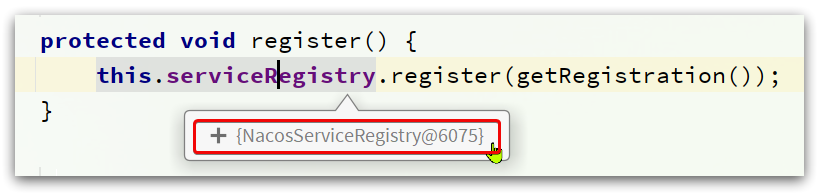
其中最關鍵的register()方法就是完成服務註冊的關鍵,程式碼如下:
protected void register() {
this.serviceRegistry.register(getRegistration());
}
此處的this.serviceRegistry就是NacosServiceRegistry:
NacosServiceRegistry
NacosServiceRegistry是Spring的ServiceRegistry介面的實現類,而ServiceRegistry介面是服務註冊、發現的規約介面,定義了register、deregister等方法的宣告。
而NacosServiceRegistry對register的實現如下:
@Override
public void register(Registration registration) {
// 判斷serviceId是否為空,也就是spring.application.name不能為空
if (StringUtils.isEmpty(registration.getServiceId())) {
log.warn("No service to register for nacos client...");
return;
}
// 獲取Nacos的命名服務,其實就是註冊中心服務
NamingService namingService = namingService();
// 獲取 serviceId 和 Group
String serviceId = registration.getServiceId();
String group = nacosDiscoveryProperties.getGroup();
// 封裝服務範例的基本資訊,如 cluster-name、是否為臨時範例、權重、IP、埠等
Instance instance = getNacosInstanceFromRegistration(registration);
try {
// 開始註冊服務
namingService.registerInstance(serviceId, group, instance);
log.info("nacos registry, {} {} {}:{} register finished", group, serviceId,
instance.getIp(), instance.getPort());
}
catch (Exception e) {
if (nacosDiscoveryProperties.isFailFast()) {
log.error("nacos registry, {} register failed...{},", serviceId,
registration.toString(), e);
rethrowRuntimeException(e);
}
else {
log.warn("Failfast is false. {} register failed...{},", serviceId,
registration.toString(), e);
}
}
}
可以看到方法中最終是呼叫NamingService的registerInstance方法實現註冊的
而NamingService介面的預設實現就是NacosNamingService
NacosNamingService
NacosNamingService提供了服務註冊、訂閱等功能
其中registerInstance就是註冊服務範例,原始碼如下:
@Override
public void registerInstance(String serviceName, String groupName, Instance instance) throws NacosException {
// 檢查超時引數是否異常。心跳超時時間(預設15秒)必須大於心跳週期(預設5秒)
NamingUtils.checkInstanceIsLegal(instance);
// 拼接得到新的服務名,格式為:groupName@@serviceId
String groupedServiceName = NamingUtils.getGroupedName(serviceName, groupName);
// 判斷是否為臨時範例,預設為 true。
if (instance.isEphemeral()) { // 這裡面的兩行程式碼很關鍵
// 如果是臨時範例,需要定時向 Nacos 服務傳送心跳 ---------- 涉及臨時範例的心跳檢測
BeatInfo beatInfo = beatReactor.buildBeatInfo(groupedServiceName, instance);
// 新增心跳任務
beatReactor.addBeatInfo(groupedServiceName, beatInfo);
}
// 傳送註冊服務範例的請求
serverProxy.registerService(groupedServiceName, groupName, instance);
}
最終,由NacosProxy的registerService方法,完成服務註冊
public void registerService(String serviceName, String groupName, Instance instance) throws NacosException {
// 組織請求引數
final Map<String, String> params = new HashMap<String, String>(16);
params.put(CommonParams.NAMESPACE_ID, namespaceId);
params.put(CommonParams.SERVICE_NAME, serviceName);
params.put(CommonParams.GROUP_NAME, groupName);
params.put(CommonParams.CLUSTER_NAME, instance.getClusterName());
params.put("ip", instance.getIp());
params.put("port", String.valueOf(instance.getPort()));
params.put("weight", String.valueOf(instance.getWeight()));
params.put("enable", String.valueOf(instance.isEnabled()));
params.put("healthy", String.valueOf(instance.isHealthy()));
params.put("ephemeral", String.valueOf(instance.isEphemeral()));
params.put("metadata", JacksonUtils.toJson(instance.getMetadata()));
// 通過POST請求將上述引數,傳送到 /nacos/v1/ns/instance
reqApi(UtilAndComs.nacosUrlInstance, params, HttpMethod.POST);
}
這裡提交的資訊就是Nacos服務註冊介面需要的完整引數,核心引數有:
- namespace_id:環境
- service_name:服務名稱
- group_name:組名稱
- cluster_name:叢集名稱
- ip: 當前範例的ip地址
- port: 當前範例的埠
伺服器端
伺服器端流程圖:
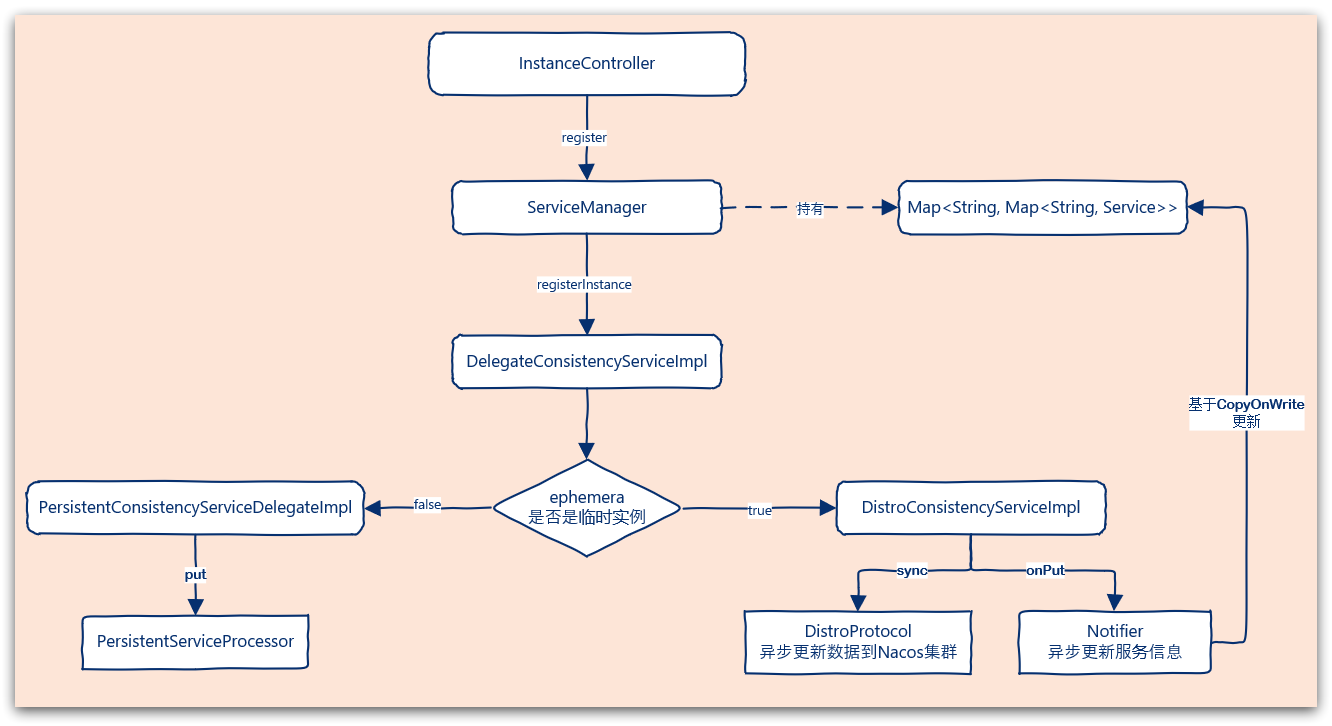
官網下載原始碼:進入 naming-nacos/com/alibaba/nacos/naming/controllers/InstanceController#register(HttpServletRequest request)
@CanDistro
@PostMapping
@Secured(parser = NamingResourceParser.class, action = ActionTypes.WRITE)
public String register(HttpServletRequest request) throws Exception {
// 嘗試獲取namespaceId
final String namespaceId = WebUtils
.optional(request, CommonParams.NAMESPACE_ID, Constants.DEFAULT_NAMESPACE_ID);
// 嘗試獲取serviceName,其格式為 group_name@@service_name
final String serviceName = WebUtils.required(request, CommonParams.SERVICE_NAME);
NamingUtils.checkServiceNameFormat(serviceName);
// 解析出範例資訊,封裝為Instance物件
final Instance instance = parseInstance(request);
// 註冊範例
serviceManager.registerInstance(namespaceId, serviceName, instance);
return "ok";
}
進入serviceManager.registerInstance(namespaceId, serviceName, instance)
ServiceManager
這裡面的東西在前面並行讀寫的解決方式中見過了
這裡面的流程一句話來說就是:先獲取舊的範例列表,然後把新的範例資訊與舊的做對比、合併,新的範例就新增,老的範例同步ID。然後返回最新的範例列表
registerInstance方法就是註冊服務範例的方法:
/**
* 註冊服務範例
*
* Register an instance to a service in AP mode.
*
* <p>This method creates service or cluster silently if they don't exist.
*
* @param namespaceId id of namespace
* @param serviceName service name
* @param instance instance to register
* @throws Exception any error occurred in the process
*/
public void registerInstance(String namespaceId, String serviceName, Instance instance) throws NacosException {
// 建立一個空的service(如果是第一次來註冊範例,要先建立一個空service出來,放入登入檔)
// 此時不包含範例資訊
createEmptyService(namespaceId, serviceName, instance.isEphemeral());
// 拿到建立好的service
Service service = getService(namespaceId, serviceName);
// 拿不到則拋異常
if (service == null) {
throw new NacosException(NacosException.INVALID_PARAM,
"service not found, namespace: " + namespaceId + ", service: " + serviceName);
}
// 新增要註冊的範例到service中
addInstance(namespaceId, serviceName, instance.isEphemeral(), instance);
}
建立好了服務,接下來就要新增範例到服務中:
/**
* 新增範例到服務中
*
* Add instance to service.
*
* @param namespaceId namespace
* @param serviceName service name
* @param ephemeral whether instance is ephemeral
* @param ips instances
* @throws NacosException nacos exception
*/
public void addInstance(String namespaceId, String serviceName, boolean ephemeral, Instance... ips)
throws NacosException {
// 監聽服務列表用到的key
// 服務唯一標識,例如:com.alibaba.nacos.naming.iplist.ephemeral.public##DEFAULT_GROUP@@order-service
String key = KeyBuilder.buildInstanceListKey(namespaceId, serviceName, ephemeral);
// 獲取服務
Service service = getService(namespaceId, serviceName);
// 同步鎖,避免並行修改的安全問題
synchronized (service) {
// 1、獲取要更新的範例列表
// addIPAddress中,會拷貝舊的範例列表,新增新範例到列表中 即:COPY
List<Instance> instanceList = addIpAddresses(service, ephemeral, ips);
// 2、將更新後的資料封裝到Instances物件
Instances instances = new Instances();
instances.setInstanceList(instanceList);
// 3、完成 登入檔更新 以及 Nacos叢集的資料同步(保證叢集一致性)
// 在這裡面 完成對範例狀態更新後,會用新列表直接覆蓋舊範例列表。而在更新過程中,舊範例列表不受影響,使用者依然可以讀取
consistencyService.put(key, instances);
}
}
最後就要更新服務的範例 列表了
private List<Instance> addIpAddresses(Service service, boolean ephemeral, Instance... ips) throws NacosException {
return updateIpAddresses(service, UtilsAndCommons.UPDATE_INSTANCE_ACTION_ADD, ephemeral, ips);
}
/**
* 拷貝舊的範例列表,新增新範例到列表中
*/
public List<Instance> updateIpAddresses(Service service, String action, boolean ephemeral, Instance... ips)
throws NacosException {
// 根據namespaceId、serviceName獲取當前服務的範例列表,返回值是Datum
// 第一次來,肯定是null
Datum datum = consistencyService
.get(KeyBuilder.buildInstanceListKey(service.getNamespaceId(), service.getName(), ephemeral));
// 得到服務中舊的範例列表
List<Instance> currentIPs = service.allIPs(ephemeral);
// 儲存範例列表,key為ip地址,value是Instance物件
Map<String, Instance> currentInstances = new HashMap<>(currentIPs.size());
// 建立Set集合,儲存範例的instanceId
Set<String> currentInstanceIds = Sets.newHashSet();
// 遍歷舊的範例列表
for (Instance instance : currentIPs) {
// 儲存範例列表
currentInstances.put(instance.toIpAddr(), instance);
// 新增instanceId到set中
currentInstanceIds.add(instance.getInstanceId());
}
// 用來儲存更新後的範例列表
Map<String, Instance> instanceMap;
// 如果服務中已經有舊的資料
if (datum != null && null != datum.value) {
// 將舊的範例列表與新的範例列表進行比對
instanceMap = setValid(((Instances) datum.value).getInstanceList(), currentInstances);
} else {
// 若服務中沒有資料,則直接建立新的map
instanceMap = new HashMap<>(ips.length);
}
// 遍歷新的範例列表ips
for (Instance instance : ips) {
// 判斷服務中是否包含要註冊的範例的cluster資訊
if (!service.getClusterMap().containsKey(instance.getClusterName())) {
// 如果不包含,建立新的cluster
Cluster cluster = new Cluster(instance.getClusterName(), service);
cluster.init();
// 將叢集放入service的登入檔
service.getClusterMap().put(instance.getClusterName(), cluster);
Loggers.SRV_LOG
.warn("cluster: {} not found, ip: {}, will create new cluster with default configuration.",
instance.getClusterName(), instance.toJson());
}
// 刪除範例 or 新增範例
// 若是Remove刪除事件型別
if (UtilsAndCommons.UPDATE_INSTANCE_ACTION_REMOVE.equals(action)) {
// 則通過範例ID刪除範例
instanceMap.remove(instance.getDatumKey());
} else {
// 通過範例ID從舊範例列表中獲取範例
Instance oldInstance = instanceMap.get(instance.getDatumKey());
if (oldInstance != null) {
// 若舊範例列表中有這個範例 則將舊範例ID賦值給新範例ID
instance.setInstanceId(oldInstance.getInstanceId());
} else {
// 若舊範例列表中沒有這個範例 則給新範例生成一個範例ID
instance.setInstanceId(instance.generateInstanceId(currentInstanceIds));
}
// 範例ID為key、範例為value存入新範例列表
instanceMap.put(instance.getDatumKey(), instance);
}
}
if (instanceMap.size() <= 0 && UtilsAndCommons.UPDATE_INSTANCE_ACTION_ADD.equals(action)) {
throw new IllegalArgumentException(
"ip list can not be empty, service: " + service.getName() + ", ip list: " + JacksonUtils
.toJson(instanceMap.values()));
}
// 將instanceMap中的所有範例轉為List返回
return new ArrayList<>(instanceMap.values());
}
Nacos叢集一致性
在上一節中,在完成本地服務列表更新後,Nacos又實現了叢集一致性更新,呼叫的是:
consistencyService.put(key, instances);
/**
* 新增範例到服務中
*
* Add instance to service.
*
* @param namespaceId namespace
* @param serviceName service name
* @param ephemeral whether instance is ephemeral
* @param ips instances
* @throws NacosException nacos exception
*/
public void addInstance(String namespaceId, String serviceName, boolean ephemeral, Instance... ips)
throws NacosException {
// 監聽服務列表用到的key
// 服務唯一標識,例如:com.alibaba.nacos.naming.iplist.ephemeral.public##DEFAULT_GROUP@@order-service
String key = KeyBuilder.buildInstanceListKey(namespaceId, serviceName, ephemeral);
// 獲取服務
Service service = getService(namespaceId, serviceName);
// 同步鎖,避免並行修改的安全問題
synchronized (service) {
// 1、獲取要更新的範例列表
// addIPAddress中,會拷貝舊的範例列表,新增新範例到列表中 即:COPY
List<Instance> instanceList = addIpAddresses(service, ephemeral, ips);
// 2、將更新後的資料封裝到Instances物件
Instances instances = new Instances();
instances.setInstanceList(instanceList);
// 3、完成 登入檔更新 以及 Nacos叢集的資料同步(保證叢集一致性)
// 在這裡面 完成對範例狀態更新後,會用新列表直接覆蓋舊範例列表。而在更新過程中,舊範例列表不受影響,使用者依然可以讀取
consistencyService.put(key, instances);
}
}
這裡的ConsistencyService介面,代表叢集一致性的介面,有很多中不同實現:

進入DelegateConsistencyServiceImpl來看:
@Override
public void put(String key, Record value) throws NacosException {
// 根據範例是否是臨時範例,判斷委託物件
mapConsistencyService(key).put(key, value);
}
其中的mapConsistencyService(key)方法就是選擇委託方式:
private ConsistencyService mapConsistencyService(String key) {
// 判斷是否是臨時範例:
// 是,選擇 ephemeralConsistencyService,也就是 DistroConsistencyServiceImpl
// 否,選擇 persistentConsistencyService,也就是 PersistentConsistencyServiceDelegateImpl
return KeyBuilder.matchEphemeralKey(key) ? ephemeralConsistencyService : persistentConsistencyService;
}
預設情況下,所有範例都是臨時範例,因此關注DistroConsistencyServiceImpl即可
DistroConsistencyServiceImpl
這裡面的邏輯在前面「Nacos如何抗住數十萬服務註冊壓力」中見過了的,但是沒弄全
@Override
public void put(String key, Record value) throws NacosException {
// 非同步服務註冊 key是服務的唯一id,value就是instances
onPut(key, value);
// 服務更強情況非同步更新給叢集下的另外節點
distroProtocol.sync(new DistroKey(key, KeyBuilder.INSTANCE_LIST_KEY_PREFIX), DataOperation.CHANGE,
globalConfig.getTaskDispatchPeriod() / 2);
}
onPut 更新本地範例列表
@DependsOn("ProtocolManager")
@org.springframework.stereotype.Service("distroConsistencyService")
public class DistroConsistencyServiceImpl implements EphemeralConsistencyService, DistroDataProcessor {
public void onPut(String key, Record value) {
// 判斷是否是臨時範例
if (KeyBuilder.matchEphemeralInstanceListKey(key)) {
// 封裝 Instances 資訊到 資料集:Datum
Datum<Instances> datum = new Datum<>();
// value就是instances
datum.value = (Instances) value;
// key是服務的唯一id
datum.key = key;
// 加入當前修改時間
datum.timestamp.incrementAndGet();
// 資料儲存 放入dataStore中
dataStore.put(key, datum);
}
if (!listeners.containsKey(key)) {
return;
}
// notifier這玩意兒 implements Runnable
notifier.addTask(key, DataOperation.CHANGE);
}
public class Notifier implements Runnable {
private ConcurrentHashMap<String, String> services = new ConcurrentHashMap<>(10 * 1024);
/**
* 維護了一個阻塞佇列
*/
private BlockingQueue<Pair<String, DataOperation>> tasks = new ArrayBlockingQueue<>(1024 * 1024);
/**
* Add new notify task to queue.
*
* @param datumKey data key
* @param action action for data
*/
public void addTask(String datumKey, DataOperation action) {
if (services.containsKey(datumKey) && action == DataOperation.CHANGE) {
return;
}
if (action == DataOperation.CHANGE) {
services.put(datumKey, StringUtils.EMPTY);
}
// 將服務唯一id + 事件型別(CHANGE)放入了阻塞佇列
tasks.offer(Pair.with(datumKey, action));
}
}
}
Notifier非同步更新
Notifier是一個Runnable,通過一個單執行緒的執行緒池來不斷從阻塞佇列中獲取任務,執行服務列表的更新
@DependsOn("ProtocolManager")
@org.springframework.stereotype.Service("distroConsistencyService")
public class DistroConsistencyServiceImpl implements EphemeralConsistencyService, DistroDataProcessor {
public class Notifier implements Runnable {
private ConcurrentHashMap<String, String> services = new ConcurrentHashMap<>(10 * 1024);
/**
* 維護了一個阻塞佇列
*/
private BlockingQueue<Pair<String, DataOperation>> tasks = new ArrayBlockingQueue<>(1024 * 1024);
@Override
public void run() {
Loggers.DISTRO.info("distro notifier started");
for (; ; ) { // 死迴圈
try {
// 去阻塞佇列中獲取任務
Pair<String, DataOperation> pair = tasks.take();
// 有任務就處理任務,更新服務列表;無任務就進入wait,所以此死迴圈不會導致CPU負載過高
handle(pair);
} catch (Throwable e) {
Loggers.DISTRO.error("[NACOS-DISTRO] Error while handling notifying task", e);
}
}
}
private void handle(Pair<String, DataOperation> pair) {
try {
String datumKey = pair.getValue0();
DataOperation action = pair.getValue1();
services.remove(datumKey);
int count = 0;
if (!listeners.containsKey(datumKey)) {
return;
}
// 遍歷,找到變化的service,這裡的 RecordListener就是 Service
for (RecordListener listener : listeners.get(datumKey)) {
count++;
try {
// 如果是 CHANGE 事件
if (action == DataOperation.CHANGE) {
// 就更新服務列表
listener.onChange(datumKey, dataStore.get(datumKey).value);
continue;
}
// 如果是 DELETE 事件
if (action == DataOperation.DELETE) {
// 就根據服務ID刪除從服務列表中刪除服務
listener.onDelete(datumKey);
continue;
}
} catch (Throwable e) {
Loggers.DISTRO.error("[NACOS-DISTRO] error while notifying listener of key: {}", datumKey, e);
}
}
if (Loggers.DISTRO.isDebugEnabled()) {
Loggers.DISTRO
.debug("[NACOS-DISTRO] datum change notified, key: {}, listener count: {}, action: {}",
datumKey, count, action.name());
}
} catch (Throwable e) {
Loggers.DISTRO.error("[NACOS-DISTRO] Error while handling notifying task", e);
}
}
}
}
onChange 覆蓋範例列表
上一節中 listener.onChange(datumKey, dataStore.get(datumKey).value); 進去,選擇Service的onChange()
@JsonInclude(Include.NON_NULL)
public class Service extends com.alibaba.nacos.api.naming.pojo.Service implements Record, RecordListener<Instances> {
@Override
public void onChange(String key, Instances value) throws Exception {
Loggers.SRV_LOG.info("[NACOS-RAFT] datum is changed, key: {}, value: {}", key, value);
for (Instance instance : value.getInstanceList()) {
if (instance == null) {
// Reject this abnormal instance list:
throw new RuntimeException("got null instance " + key);
}
if (instance.getWeight() > 10000.0D) {
instance.setWeight(10000.0D);
}
if (instance.getWeight() < 0.01D && instance.getWeight() > 0.0D) {
instance.setWeight(0.01D);
}
}
// 更新範例列表
updateIPs(value.getInstanceList(), KeyBuilder.matchEphemeralInstanceListKey(key));
recalculateChecksum();
}
}
updateIPs 的邏輯如下:
@JsonInclude(Include.NON_NULL)
public class Service extends com.alibaba.nacos.api.naming.pojo.Service implements Record, RecordListener<Instances> {
/**
* 更新範例列表
*
* Update instances.
*
* @param instances instances
* @param ephemeral whether is ephemeral instance
*/
public void updateIPs(Collection<Instance> instances, boolean ephemeral) {
// key是cluster,值是叢集下的Instance集合
Map<String, List<Instance>> ipMap = new HashMap<>(clusterMap.size());
// 獲取服務的所有cluster名稱
for (String clusterName : clusterMap.keySet()) {
ipMap.put(clusterName, new ArrayList<>());
}
// 遍歷要更新的範例
for (Instance instance : instances) {
try {
if (instance == null) {
Loggers.SRV_LOG.error("[NACOS-DOM] received malformed ip: null");
continue;
}
// 判斷範例是否包含clusterName,沒有的話用預設cluster
if (StringUtils.isEmpty(instance.getClusterName())) {
// DEFAULT_CLUSTER_NAME = "DEFAULT"
instance.setClusterName(UtilsAndCommons.DEFAULT_CLUSTER_NAME);
}
// 判斷cluster是否存在,不存在則建立新的cluster
if (!clusterMap.containsKey(instance.getClusterName())) {
Loggers.SRV_LOG
.warn("cluster: {} not found, ip: {}, will create new cluster with default configuration.",
instance.getClusterName(), instance.toJson());
Cluster cluster = new Cluster(instance.getClusterName(), this);
cluster.init();
getClusterMap().put(instance.getClusterName(), cluster);
}
// 獲取當前cluster範例的集合,不存在則建立新的
List<Instance> clusterIPs = ipMap.get(instance.getClusterName());
if (clusterIPs == null) {
clusterIPs = new LinkedList<>();
ipMap.put(instance.getClusterName(), clusterIPs);
}
// 新增新的範例到 Instance 集合
clusterIPs.add(instance);
} catch (Exception e) {
Loggers.SRV_LOG.error("[NACOS-DOM] failed to process ip: " + instance, e);
}
}
for (Map.Entry<String, List<Instance>> entry : ipMap.entrySet()) {
//make every ip mine
List<Instance> entryIPs = entry.getValue();
// 將範例集合更新到 clusterMap(登入檔)
clusterMap.get(entry.getKey()).updateIps(entryIPs, ephemeral);
}
setLastModifiedMillis(System.currentTimeMillis());
// 釋出服務變更的通知訊息
getPushService().serviceChanged(this);
StringBuilder stringBuilder = new StringBuilder();
for (Instance instance : allIPs()) {
stringBuilder.append(instance.toIpAddr()).append("_").append(instance.isHealthy()).append(",");
}
Loggers.EVT_LOG.info("[IP-UPDATED] namespace: {}, service: {}, ips: {}", getNamespaceId(), getName(),
stringBuilder.toString());
}
}
上面的 clusterMap.get(entry.getKey()).updateIps(entryIPs, ephemeral); 就是在更新範例列表,進入 updateIps(entryIPs, ephemeral) 即可看到邏輯
public class Cluster extends com.alibaba.nacos.api.naming.pojo.Cluster implements Cloneable {
/**
* 更新範例列表
*
* Update instance list.
*
* @param ips instance list
* @param ephemeral whether these instances are ephemeral
*/
public void updateIps(List<Instance> ips, boolean ephemeral) {
// 獲取舊範例列表
Set<Instance> toUpdateInstances = ephemeral ? ephemeralInstances : persistentInstances;
HashMap<String, Instance> oldIpMap = new HashMap<>(toUpdateInstances.size());
for (Instance ip : toUpdateInstances) {
oldIpMap.put(ip.getDatumKey(), ip);
}
// 更新範例列表
List<Instance> updatedIPs = updatedIps(ips, oldIpMap.values());
if (updatedIPs.size() > 0) {
for (Instance ip : updatedIPs) {
Instance oldIP = oldIpMap.get(ip.getDatumKey());
// do not update the ip validation status of updated ips
// because the checker has the most precise result
// Only when ip is not marked, don't we update the health status of IP:
if (!ip.isMarked()) {
ip.setHealthy(oldIP.isHealthy());
}
if (ip.isHealthy() != oldIP.isHealthy()) {
// ip validation status updated
Loggers.EVT_LOG.info("{} {SYNC} IP-{} {}:{}@{}", getService().getName(),
(ip.isHealthy() ? "ENABLED" : "DISABLED"), ip.getIp(), ip.getPort(), getName());
}
if (ip.getWeight() != oldIP.getWeight()) {
// ip validation status updated
Loggers.EVT_LOG.info("{} {SYNC} {IP-UPDATED} {}->{}", getService().getName(), oldIP.toString(),
ip.toString());
}
}
}
// 檢查新加入範例的狀態
List<Instance> newIPs = subtract(ips, oldIpMap.values());
if (newIPs.size() > 0) {
Loggers.EVT_LOG
.info("{} {SYNC} {IP-NEW} cluster: {}, new ips size: {}, content: {}", getService().getName(),
getName(), newIPs.size(), newIPs.toString());
for (Instance ip : newIPs) {
HealthCheckStatus.reset(ip);
}
}
// 移除要刪除的範例
List<Instance> deadIPs = subtract(oldIpMap.values(), ips);
if (deadIPs.size() > 0) {
Loggers.EVT_LOG
.info("{} {SYNC} {IP-DEAD} cluster: {}, dead ips size: {}, content: {}", getService().getName(),
getName(), deadIPs.size(), deadIPs.toString());
for (Instance ip : deadIPs) {
HealthCheckStatus.remv(ip);
}
}
toUpdateInstances = new HashSet<>(ips);
// 直接覆蓋舊範例列表
if (ephemeral) {
ephemeralInstances = toUpdateInstances;
} else {
persistentInstances = toUpdateInstances;
}
}
}
Nacos叢集一致性

@Component
public class DistroProtocol {
/**
* 同步資料到其他遠端伺服器
*
* Start to sync data to all remote server.
*
* @param distroKey distro key of sync data
* @param action the action of data operation
*/
public void sync(DistroKey distroKey, DataOperation action, long delay) {
// 遍歷 Nacos 叢集中除自己以外的其它節點
for (Member each : memberManager.allMembersWithoutSelf()) {
DistroKey distroKeyWithTarget = new DistroKey(distroKey.getResourceKey(), distroKey.getResourceType(),
each.getAddress());
// Distro同步任務
DistroDelayTask distroDelayTask = new DistroDelayTask(distroKeyWithTarget, action, delay);
// 交給執行緒池去執行
distroTaskEngineHolder.getDelayTaskExecuteEngine().addTask(distroKeyWithTarget, distroDelayTask);
if (Loggers.DISTRO.isDebugEnabled()) {
Loggers.DISTRO.debug("[DISTRO-SCHEDULE] {} to {}", distroKey, each.getAddress());
}
}
}
}
distroTaskEngineHolder.getDelayTaskExecuteEngine() 的返回值是 NacosDelayTaskExecuteEngine,它維護了一個執行緒池,並且接收任務,執行任務。執行任務的方法為processTasks()方法
public class NacosDelayTaskExecuteEngine extends AbstractNacosTaskExecuteEngine<AbstractDelayTask> {
protected void processTasks() {
Collection<Object> keys = getAllTaskKeys();
for (Object taskKey : keys) {
AbstractDelayTask task = removeTask(taskKey);
if (null == task) {
continue;
}
NacosTaskProcessor processor = getProcessor(taskKey);
if (null == processor) {
getEngineLog().error("processor not found for task, so discarded. " + task);
continue;
}
try {
// ReAdd task if process failed
// 嘗試執行同步任務,如果失敗會將任務重新入隊重試
if (!processor.process(task)) {
retryFailedTask(taskKey, task);
}
} catch (Throwable e) {
getEngineLog().error("Nacos task execute error : " + e.toString(), e);
retryFailedTask(taskKey, task);
}
}
}
}
Distro模式的同步是非同步進行的,並且失敗時會將任務重新入隊並重試,因此不保證同步結果的強一致性,屬於AP模式的一致性策略
心跳檢測原始碼
Nacos的健康檢測有兩種模式:
- 臨時範例:適合增加更多範例來應對高並行
- 採用使用者端心跳檢測模式,心跳週期5秒
- 心跳間隔超過15秒則標記為不健康
- 心跳間隔超過30秒則從服務列表刪除
- 永久範例:適合常備範例
- 採用伺服器端主動健康檢測方式
- 週期為2000 + 5000毫秒內的亂數
- 檢測異常只會標記為不健康,不會刪除
使用者端
在前面看nacos服務註冊的使用者端原始碼時,看到過一段程式碼:
@Override
public void registerInstance(String serviceName, String groupName, Instance instance) throws NacosException {
// 檢查超時引數是否異常。心跳超時時間(預設15秒)必須大於心跳週期(預設5秒)
NamingUtils.checkInstanceIsLegal(instance);
// 拼接得到新的服務名,格式為:groupName@@serviceId
String groupedServiceName = NamingUtils.getGroupedName(serviceName, groupName);
// 判斷是否為臨時範例,預設為 true。
if (instance.isEphemeral()) { // 這裡面的兩行程式碼很關鍵
// 如果是臨時範例,需要定時向 Nacos 服務傳送心跳 ---------- 涉及臨時範例的心跳檢測
BeatInfo beatInfo = beatReactor.buildBeatInfo(groupedServiceName, instance);
// 新增心跳任務
beatReactor.addBeatInfo(groupedServiceName, beatInfo);
}
// 傳送註冊服務範例的請求
serverProxy.registerService(groupedServiceName, groupName, instance);
}
這個IF中就涉及的是心跳檢測
BeatInfo
就包含心跳需要的各種資訊
BeatReactor
維護了一個執行緒池
public class BeatReactor implements Closeable {
public BeatReactor(NamingProxy serverProxy, int threadCount) {
this.lightBeatEnabled = false;
this.dom2Beat = new ConcurrentHashMap();
this.serverProxy = serverProxy;
this.executorService = new ScheduledThreadPoolExecutor(threadCount, new ThreadFactory() {
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setDaemon(true);
thread.setName("com.alibaba.nacos.naming.beat.sender");
return thread;
}
});
}
}
當呼叫BeatReactor的addBeatInfo(groupedServiceName, beatInfo)方法時,就會執行心跳
public class BeatReactor implements Closeable {
public void addBeatInfo(String serviceName, BeatInfo beatInfo) {
LogUtils.NAMING_LOGGER.info("[BEAT] adding beat: {} to beat map.", beatInfo);
String key = this.buildKey(serviceName, beatInfo.getIp(), beatInfo.getPort());
BeatInfo existBeat = null;
if ((existBeat = (BeatInfo)this.dom2Beat.remove(key)) != null) {
existBeat.setStopped(true);
}
this.dom2Beat.put(key, beatInfo);
// 利用執行緒池,定期執行心跳任務,週期為 beatInfo.getPeriod()
this.executorService.schedule(new BeatReactor.BeatTask(beatInfo), beatInfo.getPeriod(), TimeUnit.MILLISECONDS);
MetricsMonitor.getDom2BeatSizeMonitor().set((double)this.dom2Beat.size());
}
}
心跳週期的預設值在com.alibaba.nacos.api.common.Constants類中:

預設5秒一次心跳
BeatTask
上一節中 this.executorService.schedule(new BeatReactor.BeatTask(beatInfo), beatInfo.getPeriod(), TimeUnit.MILLISECONDS)
心跳的任務封裝就在BeatTask這個類中,是一個Runnable
@Override
public void run() {
if (beatInfo.isStopped()) {
return;
}
// 獲取心跳週期
long nextTime = beatInfo.getPeriod();
try {
// 傳送心跳
JsonNode result = serverProxy.sendBeat(beatInfo, BeatReactor.this.lightBeatEnabled);
long interval = result.get("clientBeatInterval").asLong();
boolean lightBeatEnabled = false;
if (result.has(CommonParams.LIGHT_BEAT_ENABLED)) {
lightBeatEnabled = result.get(CommonParams.LIGHT_BEAT_ENABLED).asBoolean();
}
BeatReactor.this.lightBeatEnabled = lightBeatEnabled;
if (interval > 0) {
nextTime = interval;
}
// 判斷心跳結果
int code = NamingResponseCode.OK;
if (result.has(CommonParams.CODE)) {
code = result.get(CommonParams.CODE).asInt();
}
if (code == NamingResponseCode.RESOURCE_NOT_FOUND) {
// 如果失敗,則需要 重新註冊範例
Instance instance = new Instance();
instance.setPort(beatInfo.getPort());
instance.setIp(beatInfo.getIp());
instance.setWeight(beatInfo.getWeight());
instance.setMetadata(beatInfo.getMetadata());
instance.setClusterName(beatInfo.getCluster());
instance.setServiceName(beatInfo.getServiceName());
instance.setInstanceId(instance.getInstanceId());
instance.setEphemeral(true);
try {
serverProxy.registerService(beatInfo.getServiceName(),
NamingUtils.getGroupName(beatInfo.getServiceName()), instance);
} catch (Exception ignore) {
}
}
} catch (NacosException ex) {
// ...... 記錄紀錄檔
} catch (Exception unknownEx) {
// ...... 記錄紀錄檔
} finally {
executorService.schedule(new BeatTask(beatInfo), nextTime, TimeUnit.MILLISECONDS);
}
}
傳送心跳
JsonNode result = serverProxy.sendBeat(beatInfo, BeatReactor.this.lightBeatEnabled) ,最終心跳的傳送還是通過NamingProxy的sendBeat方法來實現
public JsonNode sendBeat(BeatInfo beatInfo, boolean lightBeatEnabled) throws NacosException {
if (NAMING_LOGGER.isDebugEnabled()) {
NAMING_LOGGER.debug("[BEAT] {} sending beat to server: {}", namespaceId, beatInfo.toString());
}
// 組織請求引數
Map<String, String> params = new HashMap<String, String>(8);
Map<String, String> bodyMap = new HashMap<String, String>(2);
if (!lightBeatEnabled) {
bodyMap.put("beat", JacksonUtils.toJson(beatInfo));
}
params.put(CommonParams.NAMESPACE_ID, namespaceId);
params.put(CommonParams.SERVICE_NAME, beatInfo.getServiceName());
params.put(CommonParams.CLUSTER_NAME, beatInfo.getCluster());
params.put("ip", beatInfo.getIp());
params.put("port", String.valueOf(beatInfo.getPort()));
// 傳送請求,這個地址就是:/v1/ns/instance/beat
String result = reqApi(UtilAndComs.nacosUrlBase + "/instance/beat", params, bodyMap, HttpMethod.PUT);
return JacksonUtils.toObj(result);
}
伺服器端
對於臨時範例,伺服器端程式碼分兩部分:
- InstanceController提供了一個介面,處理使用者端的心跳請求
- 時檢測範例心跳是否按期執行
InstanceController
在nacos-naming模組中的InstanceController類中,定義了一個方法用來處理心跳請求
@RestController
@RequestMapping(UtilsAndCommons.NACOS_NAMING_CONTEXT + "/instance")
public class InstanceController {
/**
* 為範例建立心跳
*
* Create a beat for instance.
*
* @param request http request
* @return detail information of instance
* @throws Exception any error during handle
*/
@CanDistro
@PutMapping("/beat")
@Secured(parser = NamingResourceParser.class, action = ActionTypes.WRITE)
public ObjectNode beat(HttpServletRequest request) throws Exception {
// 解析心跳的請求引數
ObjectNode result = JacksonUtils.createEmptyJsonNode();
result.put(SwitchEntry.CLIENT_BEAT_INTERVAL, switchDomain.getClientBeatInterval());
String beat = WebUtils.optional(request, "beat", StringUtils.EMPTY);
RsInfo clientBeat = null;
if (StringUtils.isNotBlank(beat)) {
clientBeat = JacksonUtils.toObj(beat, RsInfo.class);
}
String clusterName = WebUtils
.optional(request, CommonParams.CLUSTER_NAME, UtilsAndCommons.DEFAULT_CLUSTER_NAME);
String ip = WebUtils.optional(request, "ip", StringUtils.EMPTY);
int port = Integer.parseInt(WebUtils.optional(request, "port", "0"));
if (clientBeat != null) {
if (StringUtils.isNotBlank(clientBeat.getCluster())) {
clusterName = clientBeat.getCluster();
} else {
// fix #2533
clientBeat.setCluster(clusterName);
}
ip = clientBeat.getIp();
port = clientBeat.getPort();
}
String namespaceId = WebUtils.optional(request, CommonParams.NAMESPACE_ID, Constants.DEFAULT_NAMESPACE_ID);
String serviceName = WebUtils.required(request, CommonParams.SERVICE_NAME);
NamingUtils.checkServiceNameFormat(serviceName);
Loggers.SRV_LOG.debug("[CLIENT-BEAT] full arguments: beat: {}, serviceName: {}", clientBeat, serviceName);
// 嘗試根據引數中的namespaceId、serviceName、clusterName、ip、port等資訊從Nacos的登入檔中 獲取範例
Instance instance = serviceManager.getInstance(namespaceId, serviceName, clusterName, ip, port);
// 如果獲取失敗,說明心跳失敗,範例尚未註冊
if (instance == null) {
if (clientBeat == null) {
result.put(CommonParams.CODE, NamingResponseCode.RESOURCE_NOT_FOUND);
return result;
}
// ...... 記錄紀錄檔
// 重新註冊一個範例
instance = new Instance();
instance.setPort(clientBeat.getPort());
instance.setIp(clientBeat.getIp());
instance.setWeight(clientBeat.getWeight());
instance.setMetadata(clientBeat.getMetadata());
instance.setClusterName(clusterName);
instance.setServiceName(serviceName);
instance.setInstanceId(instance.getInstanceId());
instance.setEphemeral(clientBeat.isEphemeral());
serviceManager.registerInstance(namespaceId, serviceName, instance);
}
// 嘗試基於 namespaceId + serviceName 從 登入檔 中獲取Service服務
Service service = serviceManager.getService(namespaceId, serviceName);
// 如果不存在,說明服務不存在,返回SERVER_ERROR = 500
if (service == null) {
throw new NacosException(NacosException.SERVER_ERROR,
"service not found: " + serviceName + "@" + namespaceId);
}
if (clientBeat == null) {
clientBeat = new RsInfo();
clientBeat.setIp(ip);
clientBeat.setPort(port);
clientBeat.setCluster(clusterName);
}
// 如果心跳沒問題(在確認心跳請求對應的服務、範例都在的情況下),開始處理心跳結果
service.processClientBeat(clientBeat);
result.put(CommonParams.CODE, NamingResponseCode.OK);
if (instance.containsMetadata(PreservedMetadataKeys.HEART_BEAT_INTERVAL)) {
result.put(SwitchEntry.CLIENT_BEAT_INTERVAL, instance.getInstanceHeartBeatInterval());
}
result.put(SwitchEntry.LIGHT_BEAT_ENABLED, switchDomain.isLightBeatEnabled());
return result;
}
}
processClientBeat() 處理心跳請求
在上一節中有如下方法
// 如果心跳沒問題(在確認心跳請求對應的服務、範例都在的情況下),開始處理心跳結果
service.processClientBeat(clientBeat);
這個方法的邏輯如下:
@JsonInclude(Include.NON_NULL)
public class Service extends com.alibaba.nacos.api.naming.pojo.Service
implements Record, RecordListener<Instances> {
/**
* Process client beat.
*
* @param rsInfo metrics info of server
*/
public void processClientBeat(final RsInfo rsInfo) {
// 建立執行緒:ClientBeatProcessor implements Runnable
ClientBeatProcessor clientBeatProcessor = new ClientBeatProcessor();
clientBeatProcessor.setService(this);
clientBeatProcessor.setRsInfo(rsInfo);
// HealthCheckReactor:執行緒池的封裝
HealthCheckReactor.scheduleNow(clientBeatProcessor);
}
}
所以關鍵業務邏輯就在ClientBeatProcessor的run()方法中
public class ClientBeatProcessor implements Runnable {
@Override
public void run() {
// 獲取service、ip、clusterName、port、Cluster物件
Service service = this.service;
if (Loggers.EVT_LOG.isDebugEnabled()) {
Loggers.EVT_LOG.debug("[CLIENT-BEAT] processing beat: {}", rsInfo.toString());
}
String ip = rsInfo.getIp();
String clusterName = rsInfo.getCluster();
int port = rsInfo.getPort();
// 獲取Cluster物件
Cluster cluster = service.getClusterMap().get(clusterName);
// 獲取叢集中的所有範例資訊
List<Instance> instances = cluster.allIPs(true);
for (Instance instance : instances) {
// 找到心跳的這個範例
if (instance.getIp().equals(ip) && instance.getPort() == port) {
if (Loggers.EVT_LOG.isDebugEnabled()) {
Loggers.EVT_LOG.debug("[CLIENT-BEAT] refresh beat: {}", rsInfo.toString());
}
// 更新最新的範例心跳時間,LastBeat就是用來判斷心跳是否過期的
instance.setLastBeat(System.currentTimeMillis());
if (!instance.isMarked()) {
// 若範例已被標記為:不健康
if (!instance.isHealthy()) {
// 則將範例狀態改為健康狀態
instance.setHealthy(true);
Loggers.EVT_LOG
.info("service: {} {POS} {IP-ENABLED} valid: {}:{}@{}, region: {}, msg: client beat ok",
cluster.getService().getName(), ip, port, cluster.getName(),
UtilsAndCommons.LOCALHOST_SITE);
// 進行服務變更推播,即:push操作
getPushService().serviceChanged(service);
}
}
}
}
}
}
Service#init() 開啟心跳檢測任務
@JsonInclude(Include.NON_NULL)
public class Service extends com.alibaba.nacos.api.naming.pojo.Service
implements Record, RecordListener<Instances> {
/**
* Init service.
*/
public void init() {
// 開啟心跳檢測任務
HealthCheckReactor.scheduleCheck(clientBeatCheckTask);
// 遍歷登入檔中的叢集
for (Map.Entry<String, Cluster> entry : clusterMap.entrySet()) {
entry.getValue().setService(this);
// 完成叢集初始化:非臨時範例的主動健康檢測的邏輯就可以在這裡面找到
entry.getValue().init();
}
}
}
心跳檢測任務的邏輯如下:
public class HealthCheckReactor {
/**
* Schedule client beat check task with a delay.
*
* @param task client beat check task
*/
public static void scheduleCheck(ClientBeatCheckTask task) {
// ClientBeatCheckTask task 還是一個 Runnable
// computeIfAbsent(key, mappingFunction) 與指定key關聯的當前(現有的或function計算的)值,
// 若計算的(mappingFunction)為null則為null
// key:服務唯一ID,即 com.alibaba.nacos.naming.domains.meta. + NamespaceId + ## + serviceName
// value:mappingFunction 計算值的函數
futureMap.computeIfAbsent(task.taskKey(),
// scheduleNamingHealth() 第3個引數 delay 就是心跳檢測任務執行時間,即:5s執行一次心跳檢測任務
k -> GlobalExecutor.scheduleNamingHealth(task, 5000, 5000, TimeUnit.MILLISECONDS));
}
}
ClientBeatCheckTask的run()方法邏輯如下:
public class ClientBeatCheckTask implements Runnable {
public void run() {
try {
// 找到所有臨時範例的列表
List<Instance> instances = service.allIPs(true);
// first set health status of instances:
// 給臨時範例設定健康狀態
for (Instance instance : instances) {
// 判斷 心跳間隔(當前時間 - 最後一次心跳時間) 是否大於 心跳超時時間,預設15s
if (System.currentTimeMillis() - instance.getLastBeat() > instance.getInstanceHeartBeatTimeOut()) {
if (!instance.isMarked()) {
if (instance.isHealthy()) {
// 如果超時,標記範例為不健康 healthy = false
instance.setHealthy(false);
Loggers.EVT_LOG
.info("{POS} {IP-DISABLED} valid: {}:{}@{}@{}, region: {}, msg: client timeout after {}, last beat: {}",
instance.getIp(), instance.getPort(), instance.getClusterName(),
service.getName(), UtilsAndCommons.LOCALHOST_SITE,
instance.getInstanceHeartBeatTimeOut(), instance.getLastBeat());
// 釋出範例狀態變更的事件
getPushService().serviceChanged(service);
ApplicationUtils.publishEvent(new InstanceHeartbeatTimeoutEvent(this, instance));
}
}
}
}
if (!getGlobalConfig().isExpireInstance()) {
return;
}
// then remove obsolete instances:
for (Instance instance : instances) {
if (instance.isMarked()) {
continue;
}
// 判斷心跳間隔(當前時間 - 最後一次心跳時間)是否大於 範例被刪除的最長超時時間,預設30s
if (System.currentTimeMillis() - instance.getLastBeat() > instance.getIpDeleteTimeout()) {
// delete instance
Loggers.SRV_LOG.info("[AUTO-DELETE-IP] service: {}, ip: {}", service.getName(),
JacksonUtils.toJson(instance));
// 若超過超時時間,則刪除該範例
deleteIp(instance);
}
}
} catch (Exception e) {
Loggers.SRV_LOG.warn("Exception while processing client beat time out.", e);
}
}
}
非臨時範例:主動健康檢測
對於非臨時範例(ephemeral=false),Nacos會採用主動的健康檢測,定時向範例傳送請求,根據響應來判斷範例健康狀態
在前面看服務註冊的程式碼:InstanceController/re/register(HttpServletRequest request)#serviceManager.registerInstance(namespaceId, serviceName, instance)中有如下的程式碼
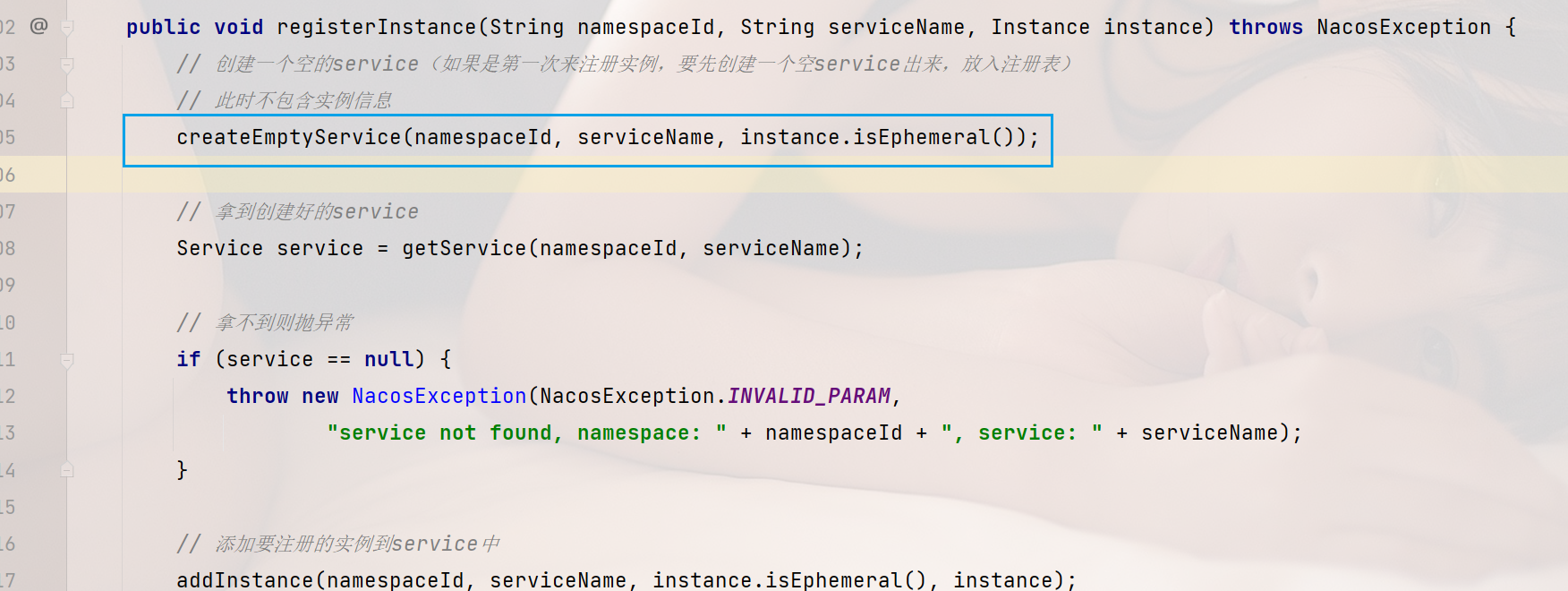
建立空服務時:
@Component
public class ServiceManager implements RecordListener<Service> {
public void createEmptyService(String namespaceId, String serviceName, boolean local) throws NacosException {
// 若服務不存在,則建立新服務
createServiceIfAbsent(namespaceId, serviceName, local, null);
}
/**
* 若服務不存在,則建立新服務
*/
public void createServiceIfAbsent(String namespaceId, String serviceName, boolean local, Cluster cluster)
throws NacosException {
// 通過 namespaceId + serviceName 獲取服務
Service service = getService(namespaceId, serviceName);
if (service == null) {
Loggers.SRV_LOG.info("creating empty service {}:{}", namespaceId, serviceName);
// 若服務不存在則建立新服務
service = new Service();
service.setName(serviceName);
service.setNamespaceId(namespaceId);
service.setGroupName(NamingUtils.getGroupName(serviceName));
// now validate the service. if failed, exception will be thrown
service.setLastModifiedMillis(System.currentTimeMillis());
service.recalculateChecksum();
if (cluster != null) {
cluster.setService(service);
service.getClusterMap().put(cluster.getName(), cluster);
}
service.validate();
// 寫入登入檔 並 初始化
putServiceAndInit(service);
if (!local) {
addOrReplaceService(service);
}
}
}
/**
* 將服務寫入登入檔 並 初始化服務
*/
private void putServiceAndInit(Service service) throws NacosException {
// 將服務新增到登入檔
putService(service);
// 通過 NamespaceId + serviceName 嘗試獲取服務
service = getService(service.getNamespaceId(), service.getName());
// 初始化服務 這裡就是進入Servicec,init()方法,即:開啟心跳檢測任務
service.init();
consistencyService
.listen(KeyBuilder.buildInstanceListKey(service.getNamespaceId(), service.getName(), true), service);
consistencyService
.listen(KeyBuilder.buildInstanceListKey(service.getNamespaceId(), service.getName(), false), service);
Loggers.SRV_LOG.info("[NEW-SERVICE] {}", service.toJson());
}
}
service.init();的邏輯如下:
@JsonInclude(Include.NON_NULL)
public class Service extends com.alibaba.nacos.api.naming.pojo.Service implements Record, RecordListener<Instances> {
/**
* Init service.
*/
public void init() {
// 開啟心跳檢測任務
HealthCheckReactor.scheduleCheck(clientBeatCheckTask);
// 遍歷登入檔中的叢集
for (Map.Entry<String, Cluster> entry : clusterMap.entrySet()) {
entry.getValue().setService(this);
// 完成叢集初始化
entry.getValue().init();
}
}
}
entry.getValue().init();的邏輯如下:
public class Cluster extends com.alibaba.nacos.api.naming.pojo.Cluster implements Cloneable {
/**
* Init cluster.
*/
public void init() {
if (inited) {
return;
}
checkTask = new HealthCheckTask(this);
// 這裡會開啟對 非臨時範例的 定時健康檢測
HealthCheckReactor.scheduleCheck(checkTask);
inited = true;
}
}
HealthCheckTask還是一個Runnable,其run()方法邏輯如下:
public class HealthCheckTask implements Runnable {
public void run() {
try {
if (distroMapper.responsible(cluster.getService().getName()) &&
switchDomain.isHealthCheckEnabled(cluster.getService().getName())) {
// 進行健康檢測
healthCheckProcessor.process(this);
// ......記錄紀錄檔
}
} catch (Throwable e) {
// ......記錄紀錄檔
} finally {
if (!cancelled) {
// 結束後,再次進行任務排程,一定延遲後執行
HealthCheckReactor.scheduleCheck(this);
// ..........
}
}
}
健康檢測邏輯定義在healthCheckProcessor.process(this);方法中,在HealthCheckProcessor介面中,這個介面也有很多實現,預設是TcpSuperSenseProcessor:
@Component
@SuppressWarnings("PMD.ThreadPoolCreationRule")
public class TcpSuperSenseProcessor implements HealthCheckProcessor, Runnable {
public void process(HealthCheckTask task) {
// 從登入檔中獲取所有的 非臨時範例
List<Instance> ips = task.getCluster().allIPs(false);
if (CollectionUtils.isEmpty(ips)) {
return;
}
// 遍歷非臨時範例
for (Instance ip : ips) {
// 若沒被標記為 不健康 則找下一個非臨時範例
if (ip.isMarked()) {
if (SRV_LOG.isDebugEnabled()) {
SRV_LOG.debug("tcp check, ip is marked as to skip health check, ip:" + ip.getIp());
}
continue;
}
// 若此非臨時範例不是正在被標記
if (!ip.markChecking()) {
// ......記錄紀錄檔
// 重新計算響應時間 並 找下一個範例
healthCheckCommon
// 預設CheckRtNormalized = -1
// 預設TcpHealthParams:max=5000、min=1000、factor=0.75F
.reEvaluateCheckRT(task.getCheckRtNormalized() * 2, task, switchDomain.getTcpHealthParams());
continue;
}
// 封裝健康檢測資訊到 Beat
Beat beat = new Beat(ip, task);
// 非同步執行:放入一個阻塞佇列中
taskQueue.add(beat);
MetricsMonitor.getTcpHealthCheckMonitor().incrementAndGet();
}
}
}
可以看到,所有的健康檢測任務都被放入一個阻塞佇列,而不是立即執行了。這裡又採用了非同步執行的策略
而TcpSuperSenseProcessor本身就是一個Runnable,在它的建構函式中會把自己放入執行緒池中去執行,其run方法如下
@Component
@SuppressWarnings("PMD.ThreadPoolCreationRule")
public class TcpSuperSenseProcessor implements HealthCheckProcessor, Runnable {
/**
* 構造
*/
public TcpSuperSenseProcessor() {
try {
selector = Selector.open();
// 將自己放入執行緒池
GlobalExecutor.submitTcpCheck(this);
} catch (Exception e) {
throw new IllegalStateException("Error while initializing SuperSense(TM).");
}
}
public void run() {
while (true) {
try {
// 處理任務
processTask();
// ......
} catch (Throwable e) {
SRV_LOG.error("[HEALTH-CHECK] error while processing NIO task", e);
}
}
}
private void processTask() throws Exception {
// 將任務封裝為一個 TaskProcessor,並放入集合
Collection<Callable<Void>> tasks = new LinkedList<>();
do {
Beat beat = taskQueue.poll(CONNECT_TIMEOUT_MS / 2, TimeUnit.MILLISECONDS);
if (beat == null) {
return;
}
// 將任務丟給 TaskProcessor 去執行,TaskProcessor implements Callable<Void>
tasks.add(new TaskProcessor(beat));
} while (taskQueue.size() > 0 && tasks.size() < NIO_THREAD_COUNT * 64);
// 批次處理集合中的任務
for (Future<?> f : GlobalExecutor.invokeAllTcpSuperSenseTask(tasks)) {
f.get();
}
}
}
TaskProcessor的cail()方法邏輯如下:
@Component
@SuppressWarnings("PMD.ThreadPoolCreationRule")
public class TcpSuperSenseProcessor implements HealthCheckProcessor, Runnable {
private class TaskProcessor implements Callable<Void> {
@Override
public Void call() {
// 獲取檢測任務已經等待的時長
long waited = System.currentTimeMillis() - beat.getStartTime();
if (waited > MAX_WAIT_TIME_MILLISECONDS) {
Loggers.SRV_LOG.warn("beat task waited too long: " + waited + "ms");
}
SocketChannel channel = null;
try {
// 獲取範例資訊
Instance instance = beat.getIp();
BeatKey beatKey = keyMap.get(beat.toString());
if (beatKey != null && beatKey.key.isValid()) {
if (System.currentTimeMillis() - beatKey.birthTime < TCP_KEEP_ALIVE_MILLIS) {
instance.setBeingChecked(false);
return null;
}
beatKey.key.cancel();
beatKey.key.channel().close();
}
// 通過NIO建立TCP連線
channel = SocketChannel.open();
channel.configureBlocking(false);
// only by setting this can we make the socket close event asynchronous
channel.socket().setSoLinger(false, -1);
channel.socket().setReuseAddress(true);
channel.socket().setKeepAlive(true);
channel.socket().setTcpNoDelay(true);
Cluster cluster = beat.getTask().getCluster();
int port = cluster.isUseIPPort4Check() ? instance.getPort() : cluster.getDefCkport();
channel.connect(new InetSocketAddress(instance.getIp(), port));
// 註冊連線、讀取事件
SelectionKey key = channel.register(selector, SelectionKey.OP_CONNECT | SelectionKey.OP_READ);
key.attach(beat);
keyMap.put(beat.toString(), new BeatKey(key));
beat.setStartTime(System.currentTimeMillis());
GlobalExecutor
.scheduleTcpSuperSenseTask(new TimeOutTask(key), CONNECT_TIMEOUT_MS, TimeUnit.MILLISECONDS);
} catch (Exception e) {
beat.finishCheck(false, false, switchDomain.getTcpHealthParams().getMax(),
"tcp:error:" + e.getMessage());
if (channel != null) {
try {
channel.close();
} catch (Exception ignore) {
}
}
}
return null;
}
}
}
服務發現原始碼
Nacos的服務發現分為兩種模式:
- 主動拉取模式(push模式):消費者定期主動從Nacos拉取服務列表並快取起來,再服務呼叫時優先讀取本地快取中的服務列表
- 訂閱模式(pull模式):消費者訂閱Nacos中的服務列表,並基於UDP協定來接收服務變更通知。當Nacos中的服務列表更新時,會傳送UDP廣播給所有訂閱者
使用者端
定時更新服務列表
在前面看服務註冊的原始碼時有一個類NacosNamingService,這個類不僅僅提供了服務註冊功能,同樣提供了服務發現的功能
通過下面的思路去找也行

所有的getAllInstances過載方法都進入了下面的方法:
public class NacosNamingService implements NamingService {
@Override
public List<Instance> getAllInstances(String serviceName, String groupName, List<String> clusters,
boolean subscribe) throws NacosException {
ServiceInfo serviceInfo;
// 是否需要訂閱服務資訊 預設true
if (subscribe) {
// 訂閱服務資訊
serviceInfo = hostReactor.getServiceInfo(NamingUtils.getGroupedName(serviceName, groupName),
StringUtils.join(clusters, ","));
} else {
// 直接去Nacos中拉取服務資訊
serviceInfo = hostReactor
.getServiceInfoDirectlyFromServer(NamingUtils.getGroupedName(serviceName, groupName),
StringUtils.join(clusters, ","));
}
List<Instance> list;
// 從服務資訊中獲取範例列表並返回
if (serviceInfo == null || CollectionUtils.isEmpty(list = serviceInfo.getHosts())) {
return new ArrayList<Instance>();
}
return list;
}
}
HostReactor#getServiceInfo() 訂閱服務資訊
進入上一節的hostReactor.getServiceInfo()
public class HostReactor implements Closeable {
public ServiceInfo getServiceInfo(final String serviceName, final String clusters) {
// key = name + "@@" + clusters
String key = ServiceInfo.getKey(serviceName, clusters);
// 讀取本地服務列表的快取,快取是一個Map,格式:Map<String, ServiceInfo>
ServiceInfo serviceObj = getServiceInfo0(serviceName, clusters);
// 判斷本地快取是否存在
if (null == serviceObj) {
// 不存在,直接建立新的ServiceInfo 放入快取
serviceObj = new ServiceInfo(serviceName, clusters);
serviceInfoMap.put(serviceObj.getKey(), serviceObj);
// 放入待更新的服務列表(updatingMap)中
updatingMap.put(serviceName, new Object());
// 立即更新服務列表:此方法中的邏輯就是立刻從Nacos中獲取
updateServiceNow(serviceName, clusters);
// 從待更新服務列表中刪除已更新的服務
updatingMap.remove(serviceName);
} else if (updatingMap.containsKey(serviceName)) { // 快取中有,但是需要更新
if (UPDATE_HOLD_INTERVAL > 0) {
// hold a moment waiting for update finish 等待5秒,待更新完成
synchronized (serviceObj) {
try {
serviceObj.wait(UPDATE_HOLD_INTERVAL);
} catch (InterruptedException e) {
NAMING_LOGGER
.error("[getServiceInfo] serviceName:" + serviceName + ", clusters:" + clusters, e);
}
}
}
}
// 本地快取中有,則開啟定時更新服務列表的功能
scheduleUpdateIfAbsent(serviceName, clusters);
// 返回快取中的服務資訊
return serviceInfoMap.get(serviceObj.getKey());
}
}
基本邏輯就是先從本地快取讀,根據結果來選擇:
- 如果本地快取沒有,立即去nacos讀取,
updateServiceNow(serviceName, clusters)
- 如果本地快取有,則開啟定時更新功能,並返回快取結果:
scheduleUpdateIfAbsent(serviceName, clusters)
在UpdateTask中,最終還是呼叫updateService方法:
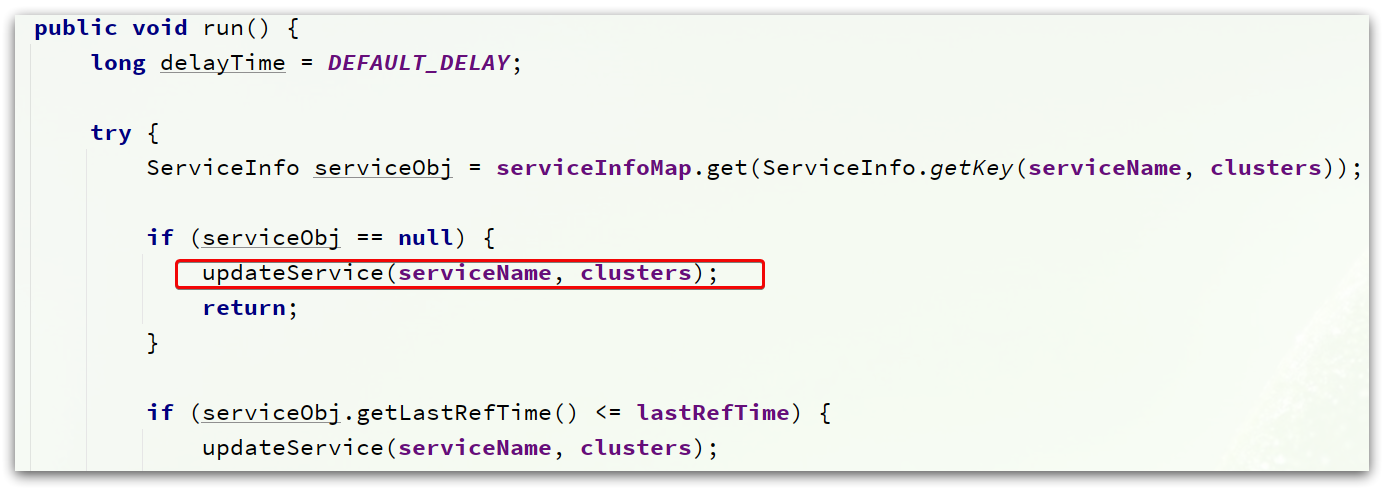
不管是立即更新服務列表,還是定時更新服務列表,最終都會執行HostReactor中的updateService()方法:
public class HostReactor implements Closeable {
public void updateService(String serviceName, String clusters) throws NacosException {
ServiceInfo oldService = getServiceInfo0(serviceName, clusters);
try {
// 基於ServerProxy發起遠端呼叫,查詢服務列表
String result = serverProxy.queryList(serviceName, clusters, pushReceiver.getUdpPort(), false);
if (StringUtils.isNotEmpty(result)) {
// 處理查詢結果
processServiceJson(result);
}
} finally {
if (oldService != null) {
synchronized (oldService) {
oldService.notifyAll();
}
}
}
}
NamingProxy#queryList() 發起查詢服務下的範例列表的請求
進入上一節的serverProxy.queryList()
public class NamingProxy implements Closeable {
public String queryList(String serviceName, String clusters, int udpPort, boolean healthyOnly)
throws NacosException {
// 準備請求引數
final Map<String, String> params = new HashMap<String, String>(8);
params.put(CommonParams.NAMESPACE_ID, namespaceId);
params.put(CommonParams.SERVICE_NAME, serviceName);
params.put("clusters", clusters);
params.put("udpPort", String.valueOf(udpPort));
params.put("clientIP", NetUtils.localIP());
params.put("healthyOnly", String.valueOf(healthyOnly));
// 給伺服器端發起請求,介面地址就是:/nacos/v1/ns/instance/list
return reqApi(UtilAndComs.nacosUrlBase + "/instance/list", params, HttpMethod.GET);
}
處理服務變更通知
除了定時更新服務列表的功能外,Nacos還支援服務列表變更時的主動推播功能
基本思路是:
- 通過PushReceiver監聽伺服器端推播的變更資料
- 解析資料後,通過NotifyCenter釋出服務變更的事件
- InstanceChangeNotifier監聽變更事件,完成對服務列表的更新
在HostReactor類別建構函式中,有非常重要的幾個步驟:
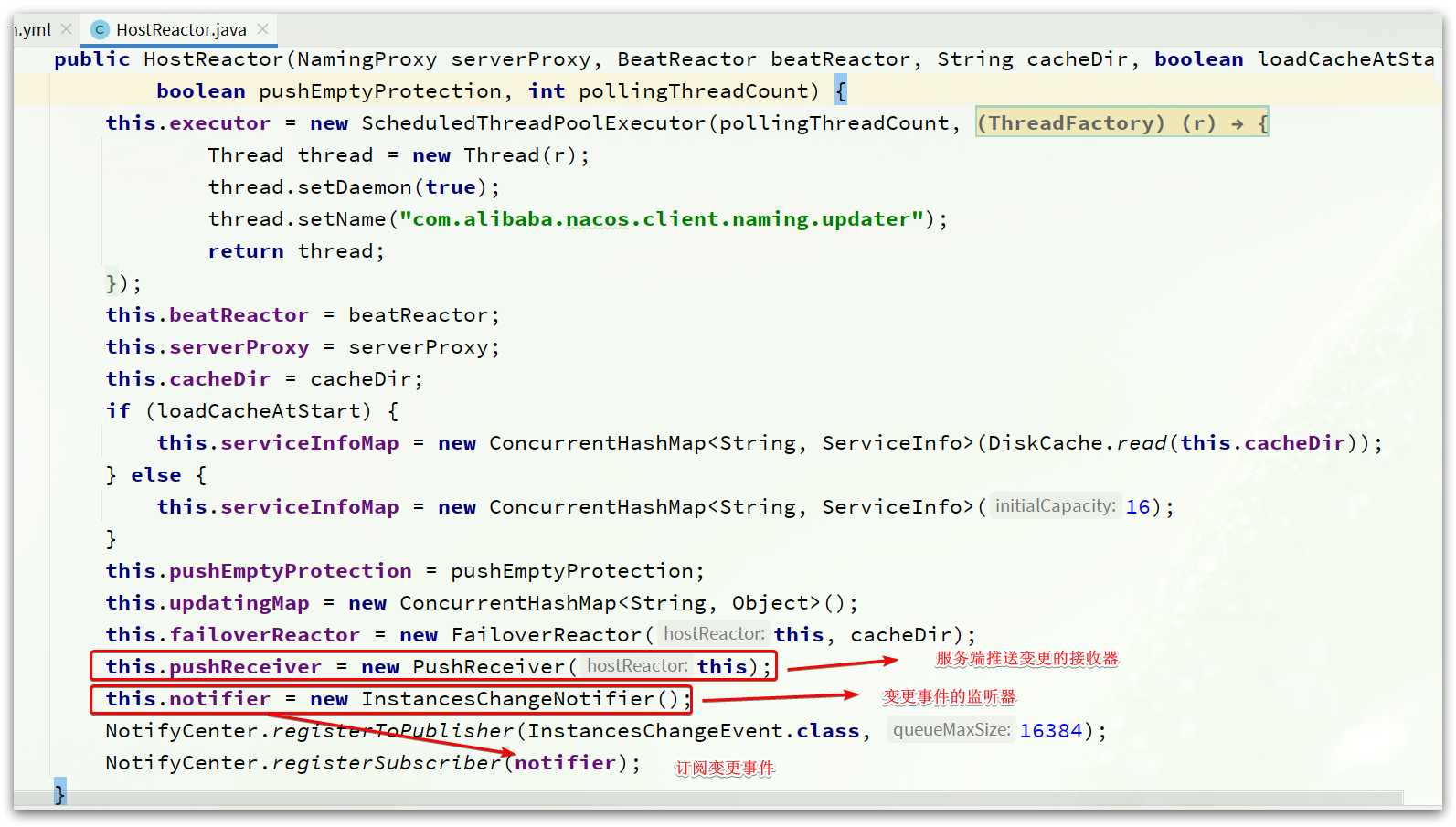
PushReceiver 伺服器端推播變更的接收器
這個類會以UDP方式接收Nacos伺服器端推播的服務變更資料
先看建構函式:
public PushReceiver(HostReactor hostReactor) {
try {
this.hostReactor = hostReactor;
// 建立 UDP使用者端
String udpPort = getPushReceiverUdpPort();
if (StringUtils.isEmpty(udpPort)) {
this.udpSocket = new DatagramSocket();
} else {
this.udpSocket = new DatagramSocket(new InetSocketAddress(Integer.parseInt(udpPort)));
}
// 準備執行緒池
this.executorService = new ScheduledThreadPoolExecutor(1, new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setDaemon(true);
thread.setName("com.alibaba.nacos.naming.push.receiver");
return thread;
}
});
// 開啟執行緒任務,準備接收變更資料
this.executorService.execute(this);
} catch (Exception e) {
NAMING_LOGGER.error("[NA] init udp socket failed", e);
}
}
PushReceiver建構函式中基於執行緒池來執行任務。這是因為PushReceiver本身也是一個Runnable,其中的run方法業務邏輯如下:
@Override
public void run() {
while (!closed) {
try {
// byte[] is initialized with 0 full filled by default
byte[] buffer = new byte[UDP_MSS];
DatagramPacket packet = new DatagramPacket(buffer, buffer.length);
// 接收推播資料
udpSocket.receive(packet);
// 解析為json字串
String json = new String(IoUtils.tryDecompress(packet.getData()), UTF_8).trim();
NAMING_LOGGER.info("received push data: " + json + " from " + packet.getAddress().toString());
// 反序列化為物件
PushPacket pushPacket = JacksonUtils.toObj(json, PushPacket.class);
String ack;
if ("dom".equals(pushPacket.type) || "service".equals(pushPacket.type)) {
// 交給 HostReactor去處理
hostReactor.processServiceJson(pushPacket.data);
// send ack to server 傳送ACK回執,略。。
} catch (Exception e) {
if (closed) {
return;
}
NAMING_LOGGER.error("[NA] error while receiving push data", e);
}
}
}
HostReactor#processServiceJson() 通知資料的處理
通知資料的處理交給了HostReactor的processServiceJson方法:
public class HostReactor implements Closeable {
public ServiceInfo processServiceJson(String json) {
// 解析出ServiceInfo資訊
ServiceInfo serviceInfo = JacksonUtils.toObj(json, ServiceInfo.class);
String serviceKey = serviceInfo.getKey();
if (serviceKey == null) {
return null;
}
// 查詢快取中的 ServiceInfo
ServiceInfo oldService = serviceInfoMap.get(serviceKey);
// 如果快取存在,則需要校驗哪些資料要更新
boolean changed = false;
if (oldService != null) {
// 拉取的資料是否已經過期
if (oldService.getLastRefTime() > serviceInfo.getLastRefTime()) {
NAMING_LOGGER.warn("out of date data received, old-t: " + oldService.getLastRefTime() + ", new-t: "
+ serviceInfo.getLastRefTime());
}
// 放入快取
serviceInfoMap.put(serviceInfo.getKey(), serviceInfo);
// 中間是快取與新資料的對比,得到newHosts:新增的範例;remvHosts:待移除的範例;
// modHosts:需要修改的範例
if (newHosts.size() > 0 || remvHosts.size() > 0 || modHosts.size() > 0) {
// 釋出範例變更的事件
NotifyCenter.publishEvent(new InstancesChangeEvent(
serviceInfo.getName(), serviceInfo.getGroupName(),
serviceInfo.getClusters(), serviceInfo.getHosts()));
DiskCache.write(serviceInfo, cacheDir);
}
} else {
// 本地快取不存在
changed = true;
// 放入快取
serviceInfoMap.put(serviceInfo.getKey(), serviceInfo);
// 直接釋出範例變更的事件
NotifyCenter.publishEvent(new InstancesChangeEvent(
serviceInfo.getName(), serviceInfo.getGroupName(),
serviceInfo.getClusters(), serviceInfo.getHosts()));
serviceInfo.setJsonFromServer(json);
DiskCache.write(serviceInfo, cacheDir);
}
// 。。。
return serviceInfo;
}
}
伺服器端
拉取服務列表
進入前面說的 /nacos/v1/ns/instance/list 介面中,也就是naming-nacos/controller/InstanceController#list(HttpServletRequest request)
@RestController
@RequestMapping(UtilsAndCommons.NACOS_NAMING_CONTEXT + "/instance")
public class InstanceController {
@GetMapping("/list")
@Secured(parser = NamingResourceParser.class, action = ActionTypes.READ)
public ObjectNode list(HttpServletRequest request) throws Exception {
// 從request中獲取 namespaceId、serviceName
String namespaceId = WebUtils.optional(request, CommonParams.NAMESPACE_ID, Constants.DEFAULT_NAMESPACE_ID);
String serviceName = WebUtils.required(request, CommonParams.SERVICE_NAME);
NamingUtils.checkServiceNameFormat(serviceName);
String agent = WebUtils.getUserAgent(request);
String clusters = WebUtils.optional(request, "clusters", StringUtils.EMPTY);
String clientIP = WebUtils.optional(request, "clientIP", StringUtils.EMPTY);
// 獲取使用者端的UDP埠
int udpPort = Integer.parseInt(WebUtils.optional(request, "udpPort", "0"));
String env = WebUtils.optional(request, "env", StringUtils.EMPTY);
boolean isCheck = Boolean.parseBoolean(WebUtils.optional(request, "isCheck", "false"));
String app = WebUtils.optional(request, "app", StringUtils.EMPTY);
String tenant = WebUtils.optional(request, "tid", StringUtils.EMPTY);
boolean healthyOnly = Boolean.parseBoolean(WebUtils.optional(request, "healthyOnly", "false"));
// 獲取服務列表
return doSrvIpxt(namespaceId, serviceName, agent, clusters, clientIP, udpPort, env, isCheck, app, tenant,
healthyOnly);
}
}
doSrvIpxt()的邏輯如下:
@RestController
@RequestMapping(UtilsAndCommons.NACOS_NAMING_CONTEXT + "/instance")
public class InstanceController {
/**
* 獲取服務列表
*/
public ObjectNode doSrvIpxt(String namespaceId, String serviceName, String agent,
String clusters, String clientIP,
int udpPort, String env, boolean isCheck,
String app, String tid, boolean healthyOnly) throws Exception {
ClientInfo clientInfo = new ClientInfo(agent);
ObjectNode result = JacksonUtils.createEmptyJsonNode();
// 獲取服務列表資訊
Service service = serviceManager.getService(namespaceId, serviceName);
long cacheMillis = switchDomain.getDefaultCacheMillis();
// now try to enable the push
try {
if (udpPort > 0 && pushService.canEnablePush(agent)) {
// 新增當前使用者端 IP、UDP埠到 PushService 中
pushService
.addClient(namespaceId, serviceName, clusters, agent, new InetSocketAddress(clientIP, udpPort),
pushDataSource, tid, app);
cacheMillis = switchDomain.getPushCacheMillis(serviceName);
}
} catch (Exception e) {
Loggers.SRV_LOG
.error("[NACOS-API] failed to added push client {}, {}:{}", clientInfo, clientIP, udpPort, e);
cacheMillis = switchDomain.getDefaultCacheMillis();
}
if (service == null) {
// 如果沒找到,返回空
if (Loggers.SRV_LOG.isDebugEnabled()) {
Loggers.SRV_LOG.debug("no instance to serve for service: {}", serviceName);
}
result.put("name", serviceName);
result.put("clusters", clusters);
result.put("cacheMillis", cacheMillis);
result.replace("hosts", JacksonUtils.createEmptyArrayNode());
return result;
}
// 結果的檢測,異常範例的剔除等邏輯省略
// 最終封裝結果並返回 。。。
result.replace("hosts", hosts);
if (clientInfo.type == ClientInfo.ClientType.JAVA
&& clientInfo.version.compareTo(VersionUtil.parseVersion("1.0.0")) >= 0) {
result.put("dom", serviceName);
} else {
result.put("dom", NamingUtils.getServiceName(serviceName));
}
result.put("name", serviceName);
result.put("cacheMillis", cacheMillis);
result.put("lastRefTime", System.currentTimeMillis());
result.put("checksum", service.getChecksum());
result.put("useSpecifiedURL", false);
result.put("clusters", clusters);
result.put("env", env);
result.replace("metadata", JacksonUtils.transferToJsonNode(service.getMetadata()));
return result;
}
釋出服務變更的UDP通知
在上一節中,InstanceController中的doSrvIpxt()方法中,有這樣一行程式碼:
// 新增當前使用者端 IP、UDP埠到 PushService 中
pushService.addClient(namespaceId, serviceName, clusters, agent,
new InetSocketAddress(clientIP, udpPort),
pushDataSource, tid, app);
就是把消費者的UDP埠、IP等資訊封裝為一個PushClient物件,儲存PushService中。方便以後服務變更後推播訊息
PushService類本身實現了ApplicationListener介面:這個是事件監聽器介面,監聽的是ServiceChangeEvent(服務變更事件)
當服務列表變化時,就會通知我們:
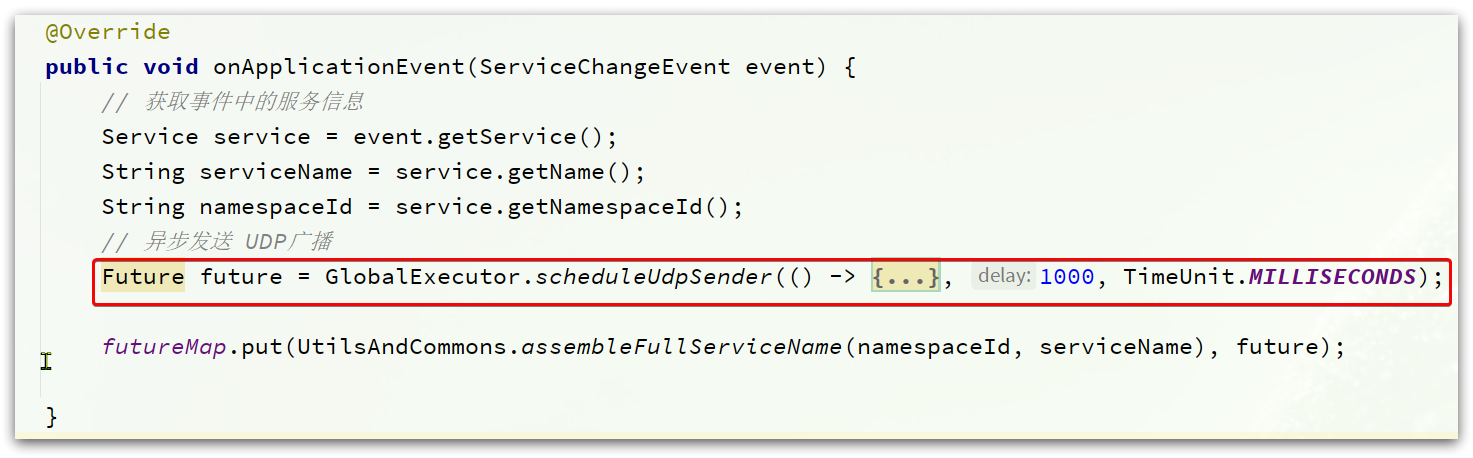
Feign遠端呼叫
Feign與OpenFeign是什麼?
Feign是Netflix開發的宣告式、模板化的HTTP使用者端, 在 RestTemplate 的基礎上做了進一步的封裝,Feign可以幫助我們更快捷、優雅地呼叫HTTP API。具有可插入註解支援,包括Feign註解和JAX-RS註解,通過 Feign,我們只需要宣告一個介面並通過註解進行簡單的設定(類似於 Dao 介面上面的 Mapper 註解一樣)即可實現對 HTTP 介面的繫結;通過 Feign,我們可以像呼叫本地方法一樣來呼叫遠端服務,而完全感覺不到這是在進行遠端呼叫
OpenFeign全稱Spring Cloud OpenFeign,2019 年 Netflix 公司宣佈 Feign 元件正式進入停更維護狀態,於是 Spring 官方便推出了一個名為 OpenFeign 的元件作為 Feign 的替代方案。基於Netflix feign實現,是一個宣告式的http使用者端,整合了Spring Cloud Ribbon,除了支援netflix的feign註解之外,增加了對Spring MVC註釋的支援,OpenFeign 的 @FeignClient 可以解析SpringMVC的 @RequestMapping 註解下的介面,並通過動態代理的方式產生實現類,實現類中做負載均衡並呼叫其他服務
- 宣告式·: 即只需要將呼叫服務需要的東西宣告出來,剩下就不用管了,交給feign即可
Spring Cloud Finchley 及以上版本一般使用 OpenFeign 作為其服務呼叫元件。由於 OpenFeign 是在 2019 年 Feign 停更進入維護後推出的,因此大多數 2019 年及以後的新專案使用的都是 OpenFeign,而 2018 年以前的專案一般使用 Feign
OpenFeign 常用註解
使用 OpenFegin 進行遠端服務呼叫時,常用註解如下表:
| 註解 | 說明 |
|---|---|
| @FeignClient | 該註解用於通知 OpenFeign 元件對 @RequestMapping 註解下的介面進行解析,並通過動態代理的方式產生實現類,實現負載均衡和服務呼叫。 |
| @EnableFeignClients | 該註解用於開啟 OpenFeign 功能,當 Spring Cloud 應用啟動時,OpenFeign 會掃描標有 @FeignClient 註解的介面,生成代理並註冊到 Spring 容器中。 |
| @RequestMapping | Spring MVC 註解,在 Spring MVC 中使用該註解對映請求,通過它來指定控制器(Controller)可以處理哪些 URL 請求,相當於 Servlet 中 web.xml 的設定。 |
| @GetMapping | Spring MVC 註解,用來對映 GET 請求,它是一個組合註解,相當於 @RequestMapping(method = RequestMethod.GET) 。 |
| @PostMapping | Spring MVC 註解,用來對映 POST 請求,它是一個組合註解,相當於 @RequestMapping(method = RequestMethod.POST) 。 |
Feign VS OpenFeign
相同點
Feign 和 OpenFegin 具有以下相同點:
- Feign 和 OpenFeign 都是 Spring Cloud 下的遠端呼叫和負載均衡元件
- Feign 和 OpenFeign 作用一樣,都可以實現服務的遠端呼叫和負載均衡
- Feign 和 OpenFeign 都對 Ribbon 進行了整合,都利用 Ribbon 維護了可用服務清單,並通過 Ribbon 實現了使用者端的負載均衡
- Feign 和 OpenFeign 都是在服務消費者(使用者端)定義服務繫結介面並通過註解的方式進行設定,以實現遠端服務的呼叫
不同點
Feign 和 OpenFeign 具有以下不同:
- Feign 和 OpenFeign 的依賴項不同,Feign 的依賴為 spring-cloud-starter-feign,而 OpenFeign 的依賴為 spring-cloud-starter-openfeign
- Feign 和 OpenFeign 支援的註解不同,Feign 支援 Feign 註解和 JAX-RS 註解,但不支援 Spring MVC 註解;OpenFeign 除了支援 Feign 註解和 JAX-RS 註解外,還支援 Spring MVC 註解
入手OpenFeign
OpenFeign是Feign的增強版,使用時將依賴換一下,然後注意一下二者能支援的註解的區別即可
1、依賴:在「服務消費方」新增如下依賴
<!--openfeign的依賴-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<!--Feign的依賴-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-feign</artifactId>
</dependency>
2、啟動類假如如下註解:在「服務消費方」啟動類新增
@EnableFeignClients /*開啟feign使用者端功能*/
3、建立介面,並使用 @@org.springframework.cloud.openfeign.FeignClient 註解:這種方式相當於 DAO
/**
* @FeignClient("USER-SERVICE")
*
* Spring Cloud 應用在啟動時,OpenFeign 會掃描標有 @FeignClient 註解的介面生成代理,並注人到 Spring 容器中
*
* 引數為要呼叫的服務名,這裡的服務名區分大小寫
*/
@FeignClient("USER-SERVICE")
public interface FeignClient {
/**
* 支援SpringMVC的所有註解
*/
@GetMapping("/user/{id}")
User findById(@PathVariable("id") long id);
}
在編寫服務繫結介面時,需要注意以下 2 點:
- 在 @FeignClient 註解中,value 屬性的取值為:服務提供者的服務名,即服務提供者組態檔(application.yml)中 spring.application.name 的值
- 介面中定義的每個方法都與 服務提供者 中 Controller 定義的服務方法對應
4、在需要呼叫3中服務與方法的地方進行呼叫
import com.zixieqing.order.client.FeignClient;
import com.zixieqing.order.entity.Order;
import com.zixieqing.order.entity.User;
import com.zixieqing.order.mapper.OrderMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
/**
* <p>@description : order服務
* </p>
* <p>@author : ZiXieqing</p>
*/
@Service
public class OrderService {
/* @Autowired
private RestTemplate restTemplate;*/
@Autowired
private FeignClient feignClient;
@Autowired
private OrderMapper orderMapper;
public Order queryOrderById(Long orderId) {
// 1.查詢訂單
Order order = orderMapper.findById(orderId);
/* // 2、遠端呼叫服務的url 此處直接使用服務名,不用ip+port
// 原因是底層有一個LoadBalancerInterceptor,裡面有一個intercept(),後續玩負載均衡Ribbon會看到
String url = "http://USER-SERVICE/user/" + order.getUserId();
// 2.1、利用restTemplate呼叫遠端服務,封裝成user物件
User user = restTemplate.getForObject(url, User.class); */
// 2、使用feign來進行遠端調研
User user = feignClient.findById(order.getUserId());
// 3、給oder設定user物件值
order.setUser(user);
// 4.返回
return order;
}
}
OpenFeign自定義設定
Feign可以支援很多的自定義設定,如下表所示:
| 型別 | 作用 | 說明 |
|---|---|---|
| feign.Logger.Level | 修改紀錄檔級別 | 包含四種不同的級別:NONE、BASIC、HEADERS、FULL 1、NONE:預設的,不顯示任何紀錄檔 2、BACK:僅記錄請求方法、URL、響應狀態碼及執行時間 3、HEADERS:除了BASIC中定義的資訊之外,還有請求和響應的頭資訊 4、FULL:除了HEADERS中定義的資訊之外,還有請求和響應的正文及後設資料 |
| feign.codec.Decoder | 響應結果的解析器 | http遠端呼叫的結果做解析,例如解析json字串為Java物件 |
| feign.codec.Encoder | 請求引數編碼 | 將請求引數編碼,便於通過http請求傳送 |
| feign. Contract | 支援的註解格式 | 預設是SpringMVC的註解 |
| feign. Retryer | 失敗重試機制 | 請求失敗的重試機制,預設是沒有,不過會使用Ribbon的重試 |
一般情況下,預設值就能滿足我們使用,如果要自定義時,只需要建立自定義的 @Bean 覆蓋預設Bean即可
設定紀錄檔增強
這個有4種設定方式,區域性設定(2種=YAML+程式碼實現)、全域性設定(2種=YAML+程式碼實現)
1、YAML實現
- 基於YAML檔案修改Feign的紀錄檔級別可以針對單個服務:即區域性設定
feign:
client:
config:
userservice: # 針對某個微服務的設定
loggerLevel: FULL # 紀錄檔級別
- 也可以針對所有服務:即全域性設定
feign:
client:
config:
default: # 這裡用default就是全域性設定,如果是寫服務名稱,則是針對某個微服務的設定
loggerLevel: FULL # 紀錄檔級別
2、程式碼實現
也可以基於Java程式碼來修改紀錄檔級別,先宣告一個類,然後宣告一個Logger.Level的物件:
/**
* 注:這裡可以不用加 @Configuration 註解
* 因為要麼在啟動類 @EnableFeignClients 註解中進行宣告這個設定類
* 要麼在遠端服務呼叫的介面的 @FeignClient 註解中宣告該設定
*/
public class DefaultFeignConfiguration {
@Bean
public Logger.Level feignLogLevel(){
return Logger.Level.BASIC; // 紀錄檔級別為BASIC
}
}
- 如果要全域性生效,將其放到啟動類的
@EnableFeignClients這個註解中:
@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration .class)
- 如果是區域性生效,則把它放到對應的
@FeignClient這個註解中:
@FeignClient(value = "userservice", configuration = DefaultFeignConfiguration .class)
設定使用者端
Feign底層發起http請求,依賴於其它的框架。其底層使用者端實現包括:
- URLConnection:預設實現,不支援連線池
- Apache HttpClient :支援連線池
- OKHttp:支援連線池
替換為Apache HttpClient
1、在服務消費方新增依賴
<!--httpClient的依賴 -->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
</dependency>
2、在YAML中開啟使用者端和設定連線池
feign:
httpclient:
# 開啟feign對HttpClient的支援 預設值就是true,即 匯入對應使用者端依賴之後就開啟了,但為了提高程式碼可讀性,還是顯示宣告比較好
enabled: true
# 最大的連線數
max-connections: 200
# 每個路徑最大連線數
max-connections-per-route: 50
# 連結超時時間
connection-timeout: 2000
# 存活時間
time-to-live: 900
驗證:在FeignClientFactoryBean中的loadBalance方法中打斷點:
Debug方式啟動服務消費者,可以看到這裡的client底層就是Apache HttpClient:
Feign的失敗處理
業務失敗後,不能直接報錯,而應該返回使用者一個友好提示或者預設結果,這個就是失敗降級邏輯
給FeignClient編寫失敗後的降級邏輯
- 方式一:FallbackClass,無法對遠端呼叫的異常做處理
- 方式二:FallbackFactory,可以對遠端呼叫的異常做處理。一般選擇這種
使用FallbackFactory進行失敗降級
-
在定義Feign-Client的地方建立失敗邏輯處理
package com.zixieqing.feign.fallback; import com.zixieqing.feign.clients.UserClient; import com.zixieqing.feign.pojo.User; import feign.hystrix.FallbackFactory; import lombok.extern.slf4j.Slf4j; /** * userClient失敗時的降級處理 * * <p>@author : ZiXieqing</p> */ @Slf4j public class UserClientFallBackFactory implements FallbackFactory<UserClient> { @Override public UserClient create(Throwable throwable) { return new UserClient() { /** * 重寫userClient中的方法,編寫失敗時的降級邏輯 */ @Override public User findById(Long id) { log.info("userClient的findById()在進行 id = {} 時失敗", id); return new User(); } }; } } -
將定義的失敗邏輯類丟給Spring容器託管
@Bean public UserClientFallBackFactory userClientFallBackFactory() { return new UserClientFallBackFactory(); } -
在對應的Feign-Client中使用fallbackFactory回撥函數
package com.zixieqing.feign.clients; import com.zixieqing.feign.fallback.UserClientFallBackFactory; import com.zixieqing.feign.pojo.User; import org.springframework.cloud.openfeign.FeignClient; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PathVariable; @FeignClient(value = "userservice",fallbackFactory = UserClientFallBackFactory.class) public interface UserClient { @GetMapping("/user/{id}") User findById(@PathVariable("id") Long id); } -
呼叫,失敗時就會進入自定義的失敗邏輯中
package com.zixieqing.order.service; import com.zixieqing.feign.clients.UserClient; import com.zixieqing.feign.pojo.User; import com.zixieqing.order.mapper.OrderMapper; import com.zixieqing.order.pojo.Order; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; @Service public class OrderService { @Autowired private OrderMapper orderMapper; @Autowired private UserClient userClient; public Order queryOrderById(Long orderId) { // 1.查詢訂單 Order order = orderMapper.findById(orderId); // 2.用Feign遠端呼叫 User user = userClient.findById(14321432143L); // 傳入錯誤 id=14321432143L 模擬錯誤 // 3.封裝user到Order order.setUser(user); // 4.返回 return order; } }
Gateway 閘道器
在微服務架構中,一個系統往往由多個微服務組成,而這些服務可能部署在不同機房、不同地區、不同域名下。這種情況下,使用者端(例如瀏覽器、手機、軟體工具等)想要直接請求這些服務,就需要知道它們具體的地址資訊,如 IP 地址、埠號等
這種使用者端直接請求服務的方式存在以下問題:
- 當服務數量眾多時,使用者端需要維護大量的服務地址,這對於使用者端來說,是非常繁瑣複雜的
- 在某些場景下可能會存在跨域請求的問題
- 身份認證的難度大,每個微服務需要獨立認證
我們可以通過 API 閘道器來解決這些問題,下面就讓我們來看看什麼是 API 閘道器
API 閘道器
API 閘道器是一個搭建在使用者端和微服務之間的服務,我們可以在 API 閘道器中處理一些非業務功能的邏輯,例如許可權驗證、監控、快取、請求路由等
API 閘道器就像整個微服務系統的門面一樣,是系統對外的唯一入口。有了它,使用者端會先將請求傳送到 API 閘道器,然後由 API 閘道器根據請求的標識資訊將請求轉發到微服務範例
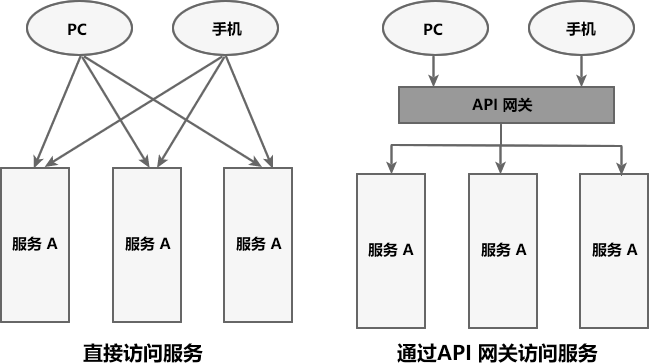
對於服務數量眾多、複雜度較高、規模比較大的系統來說,使用 API 閘道器具有以下好處:
- 使用者端通過 API 閘道器與微服務互動時,使用者端只需要知道 API 閘道器地址即可,而不需要維護大量的服務地址,簡化了使用者端的開發
- 使用者端直接與 API 閘道器通訊,能夠減少使用者端與各個服務的互動次數
- 使用者端與後端的服務耦合度降低
- 節省流量,提高效能,提升使用者體驗
- API 閘道器還提供了安全、流控、過濾、快取、計費以及監控等 API 管理功能
常見的 API 閘道器實現方案主要有以下 5 種:
- Spring Cloud Gateway
- Spring Cloud Netflix Zuul
- Kong
- Nginx+Lua
- Traefik
認識Sprin gCloud Gateway
Spring Cloud Gateway 是 Spring Cloud 團隊基於 Spring 5.0、Spring Boot 2.0 和 Project Reactor 等技術開發的高效能 API 閘道器元件
Spring Cloud Gateway 旨在提供一種簡單而有效的途徑來傳送 API,併為它們提供橫切關注點,例如:安全性,監控/指標和彈性
Spring Cloud Gateway 是基於 WebFlux 框架實現的,而 WebFlux 框架底層則使用了高效能的 Reactor 模式通訊框架 Netty
Spring Cloud Gateway 核心概念
Spring Cloud Gateway 最主要的功能就是路由轉發,而在定義轉發規則時主要涉及了以下三個核心概念,如下表:
| 核心概念 | 描述 |
|---|---|
| Route 路由 | 閘道器最基本的模組。它由一個 ID、一個目標 URI、一組斷言(Predicate)和一組過濾器(Filter)組成 |
| Predicate 斷言 | 路由轉發的判斷條件,我們可以通過 Predicate 對 HTTP 請求進行匹配,如請求方式、請求路徑、請求頭、引數等,如果請求與斷言匹配成功,則將請求轉發到相應的服務 |
| Filter 過濾器 | 過濾器,我們可以使用它對請求進行攔截和修改,還可以使用它對上文的響應進行再處理 |
注意:其中 Route 和 Predicate 必須同時宣告
閘道器的核心功能特性:
- 請求路由
- 許可權控制
- 限流
架構圖:
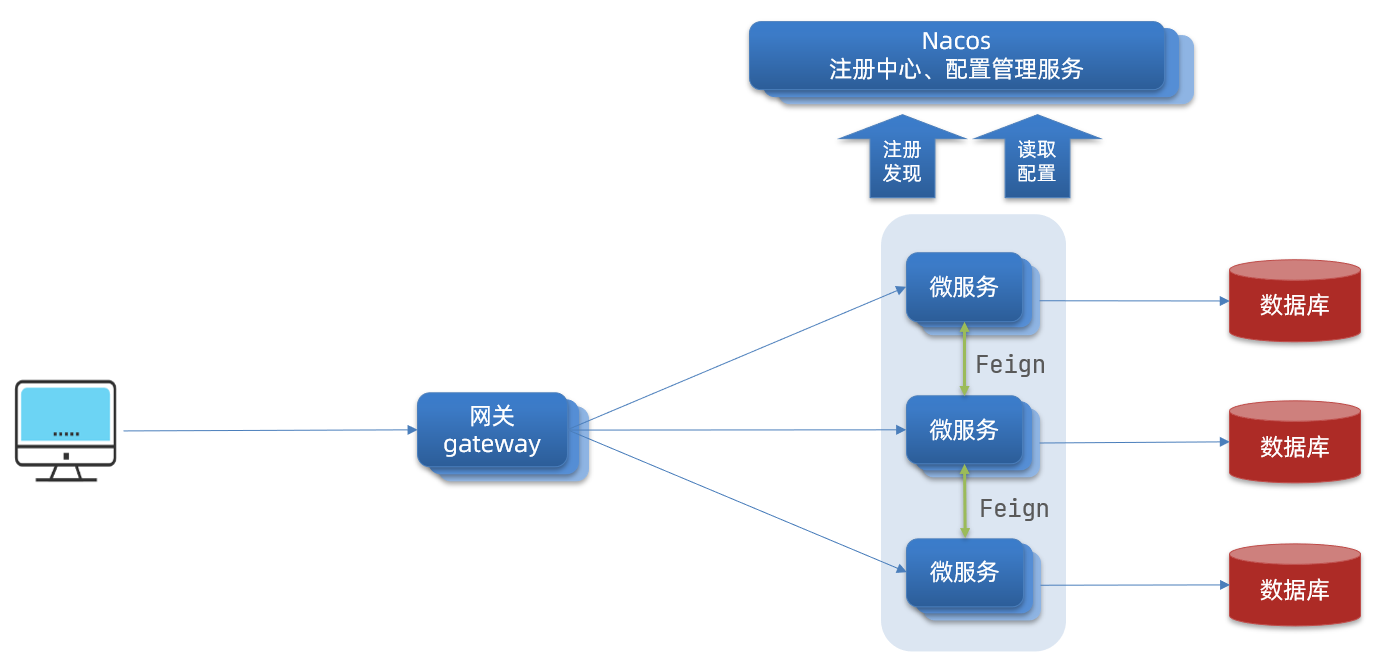
許可權控制:閘道器作為微服務入口,需要校驗使用者是否有請求資格,如果沒有則進行攔截
路由和負載均衡:一切請求都必須先經過gateway,但閘道器不處理業務,而是根據指定規則,把請求轉發到某個微服務,這個過程叫做路由。當然路由的目標服務有多個時,還需要做負載均衡
限流:當請求流量過高時,在閘道器中按照下游的微服務能夠接受的速度來放行請求,避免服務壓力過大
Gateway 的工作流程
Spring Cloud Gateway 工作流程如下圖:
Spring Cloud Gateway 工作流程說明如下:
- 使用者端將請求傳送到 Spring Cloud Gateway 上
- Spring Cloud Gateway 通過 Gateway Handler Mapping 找到與請求相匹配的路由,將其傳送給 Gateway Web Handler
- Gateway Web Handler 通過指定的過濾器鏈(Filter Chain),將請求轉發到實際的服務節點中,執行業務邏輯返回響應結果
- 過濾器之間用虛線分開是因為過濾器可能會在轉發請求之前(pre)或之後(post)執行業務邏輯
- 過濾器(Filter)可以在請求被轉發到伺服器端前,對請求進行攔截和修改,例如引數校驗、許可權校驗、流量監控、紀錄檔輸出以及協定轉換等
- 過濾器可以在響應返回使用者端之前,對響應進行攔截和再處理,例如修改響應內容或響應頭、紀錄檔輸出、流量監控等
- 響應原路返回給使用者端
總而言之,使用者端傳送到 Spring Cloud Gateway 的請求需要通過一定的匹配條件,才能到達真正的服務節點。在將請求轉發到服務進行處理的過程前後(pre 和 post),我們還可以對請求和響應進行一些精細化控制。
Predicate 就是路由的匹配條件,而 Filter 就是對請求和響應進行精細化控制的工具。有了這兩個元素,再加上目標 URI,就可以實現一個具體的路由了
當然,要是再加上前面已經玩過的東西的流程就變成下面的樣子了:
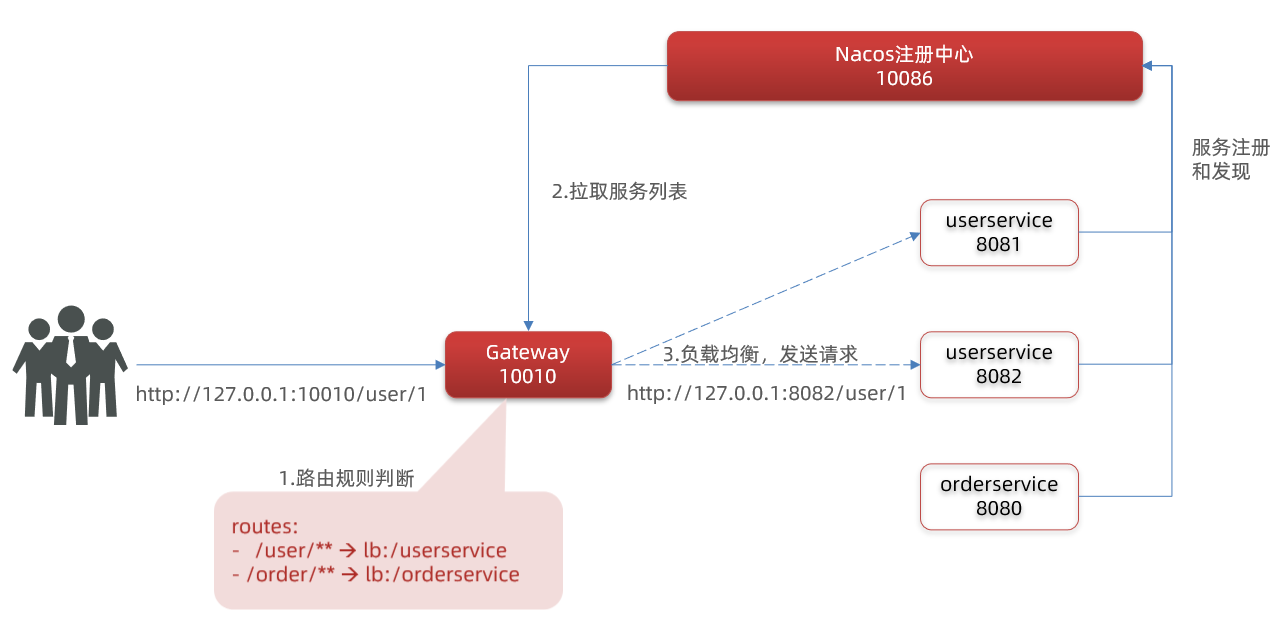
Predicate 斷言
Spring Cloud Gateway 通過 Predicate 斷言來實現 Route 路由的匹配規則。簡單點說,Predicate 是路由轉發的判斷條件,請求只有滿足了 Predicate 的條件,才會被轉發到指定的服務上進行處理。
使用 Predicate 斷言需要注意以下 3 點:
- Route 路由與 Predicate 斷言的對應關係為「一對多」,一個路由可以包含多個不同斷言條件
- 一個請求想要轉發到指定的路由上,就必須同時匹配路由上的所有斷言
- 當一個請求同時滿足多個路由的斷言條件時,請求只會被首個成功匹配的路由轉發
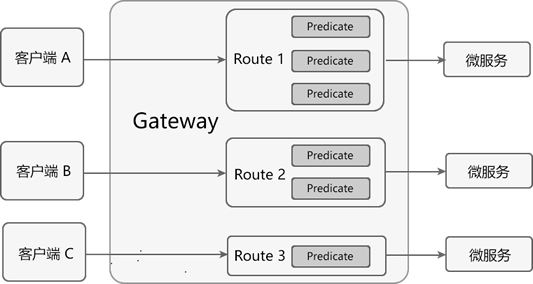
常見的 Predicate 斷言如下表:假設轉發的 URI 為 http://localhost:8001
| 斷言 | 範例 | 說明 |
|---|---|---|
| Path | - Path=/dept/list/** | 當請求路徑與 /dept/list/ 匹配時,該請求才能被轉發到 http://localhost:8001 上 |
| Before | - Before=2021-10-20T11:47:34.255+08:00[Asia/Shanghai] | 在 2021 年 10 月 20 日 11 時 47 分 34.255 秒之前的請求,才會被轉發到 http://localhost:8001 上 |
| After | - After=2021-10-20T11:47:34.255+08:00[Asia/Shanghai] | 在 2021 年 10 月 20 日 11 時 47 分 34.255 秒之後的請求,才會被轉發到 http://localhost:8001 上 |
| Between | - Between=2021-10-20T15:18:33.226+08:00[Asia/Shanghai],2021-10-20T15:23:33.226+08:00[Asia/Shanghai] | 在 2021 年 10 月 20 日 15 時 18 分 33.226 秒 到 2021 年 10 月 20 日 15 時 23 分 33.226 秒之間的請求,才會被轉發到 http://localhost:8001 伺服器上 |
| Cookie | - Cookie=name,www.cnblogs.com/xiegongzi | 攜帶 Cookie 且 Cookie 的內容為 name=www.cnblogs.com/xiegongzi 的請求,才會被轉發到 http://localhost:8001 上 |
| Header | - Header=X-Request-Id,\d+ | 請求頭上攜帶屬性 X-Request-Id 且屬性值為整數的請求,才會被轉發到 http://localhost:8001 上 |
| Method | - Method=GET | 只有 GET 請求才會被轉發到 http://localhost:8001 上 |
| Host | - Host=.somehost.org,.anotherhost.org | 請求必須是存取.somehost.org和.anotherhost.org這兩個host(域名)才會被轉發到 http://localhost:8001 上 |
| Query | - Query=name | 請求引數必須包含指定引數(name),才會被轉發到 http://localhost:8001 上 |
| RemoteAddr | - RemoteAddr=192.168.1.1/24 | 請求者的ip必須是指定範圍(192.168.1.1 到 192.168.1.24) |
| Weight |  |
權重處理weight,有兩個引數:group和weight(一個整數) 如範例中表示:分80%的流量給weihthigh.org |
上表中這些也叫「Predicate斷言工廠」,我們在組態檔中寫的斷言規則只是字串,這些字串會被Predicate Factory讀取並處理,轉變為路由判斷的條件
例如 Path=/user/** 是按照路徑匹配,這個規則是由
org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactory類來
處理的
入手Gateway
新建一個Maven專案,依賴如下:
<!--Nacos服務發現-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--閘道器-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
YAML組態檔內容如下:
server:
port: 10010 # 閘道器埠
spring:
application:
name: gateway # 服務名稱
cloud:
nacos:
server-addr: localhost:8848 # nacos地址
gateway:
routes: # 閘道器路由設定
- id: userservice # 路由id,自定義,只要唯一即可
# uri: http://127.0.0.1:8081 # 路由的目標地址,這是一種寫法,常用的是下面這種
uri: lb://userservice # 路由的目標地址 lb就是負載均衡,後面跟服務名稱
predicates: # 路由斷言,也就是判斷請求是否符合路由規則的條件
- Path=/user/** # 按路徑匹配,只要以 /user/ 開頭就符合要求
- id: orderservice
uri: lb://orderservice
predicates:
- Path=/order/**
經過如上方式,就簡單搭建了Gateway閘道器,啟動、存取 localhost:10010/user/id 或 localhost:10010/order/id 即可
filter 過濾器
通常情況下,出於安全方面的考慮,伺服器端提供的服務往往都會有一定的校驗邏輯,例如使用者登陸狀態校驗、簽名校驗等
在微服務架構中,系統由多個微服務組成,所以這些服務都需要這些校驗邏輯,此時我們就可以將這些校驗邏輯寫到 Spring Cloud Gateway 的 Filter 過濾器中
Filter是閘道器中提供的一種過濾器,可以對進入閘道器的請求和微服務返回的響應做處理:
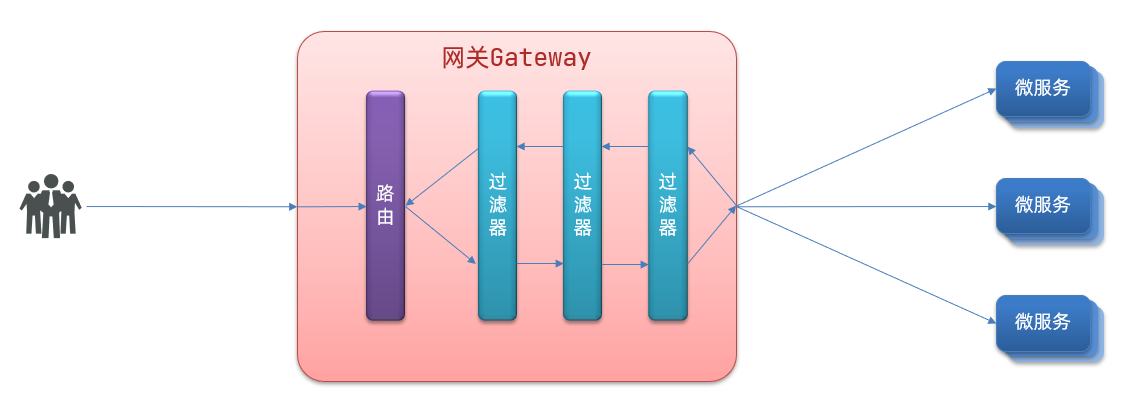
pring Cloud Gateway 提供了以下兩種型別的過濾器,可以對請求和響應進行精細化控制
| 過濾器型別 | 說明 |
|---|---|
| Pre 型別 | 這種過濾器在請求被轉發到微服務「之前」可以對請求進行攔截和修改,如引數校驗、許可權校驗、流量監控、紀錄檔輸出以及協定轉換等操作 |
| Post 型別 | 這種過濾器在微服務對請求做出響應「之後」可以對響應進行攔截和再處理,如修改響應內容或響應頭、紀錄檔輸出、流量監控等 |
按照作用範圍劃分,Spring Cloud gateway 的 Filter 可以分為 2 類:
- GatewayFilter:應用在「單個路由」或者「一組路由」上的過濾器
- GlobalFilter:應用在「所有的路由」上的過濾器
GatewayFilter 閘道器過濾器
GatewayFilter 是 Spring Cloud Gateway 閘道器中提供的一種應用在「單個路由」或「一組路由」上的過濾器
它可以對單個路由或者一組路由上傳入的請求和傳出響應進行攔截,並實現一些與業務無關的功能,如登陸狀態校驗、簽名校驗、許可權校驗、紀錄檔輸出、流量監控等
GatewayFilter 在組態檔(如 application.yml)中的寫法與 Predicate 類似,格式如下:
server:
port: 10010 # 閘道器埠
spring:
application:
name: gateway # 服務名稱
cloud:
nacos:
server-addr: localhost:8848 # nacos地址
gateway:
routes: # 閘道器路由設定
- id: userservice # 路由id,自定義,只要唯一即可
# uri: http://127.0.0.1:8081 # 路由的目標地址,常用寫法是下面這種
uri: lb://userservice # 路由的目標地址 lb就是負載均衡,後面跟服務名稱
predicates: # 路由斷言,也就是判斷請求是否符合路由規則的條件
- Path=/user/** # 按路徑匹配,只要以/user/開頭就符合要求
filters: # gateway過濾器
- AddRequestHeader=name, zixieqing # 新增請求頭name=zixieqing
- id: orderservice
uri: lb://orderservice
predicates:
- Path=/order/**
想要驗證的話,可以在新增路由的服務中進行獲取,如上面加在了userservice中,那麼驗證方式如下:
package com.zixieqing.user.web;
import com.zixieqing.user.entity.User;
import com.zixieqing.user.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
/**
* <p>@description : 該類功能 user控制層
* </p>
* <p>@author : ZiXieqing</p>
*/
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
/**
* 路徑: /user/110
*
* @param id 使用者id
* @return 使用者
*/
@GetMapping("/{id}")
public User queryById(@PathVariable("id") Long id,
@RequestHeader(value = "name",required = false) String name) {
System.out.println("name = " + name);
return userService.queryById(id);
}
}
此種路由一共有37種,它們的用法和上面的差不多,可以多個過濾器共同使用
詳細去看連結:https://docs.spring.io/spring-cloud-gateway/docs/current/reference/html/
下表中列舉了幾種比較常用的閘道器過濾器:
| 路由過濾器 | 描述 | 引數 | 使用範例 |
|---|---|---|---|
| AddRequestHeader | 攔截傳入的請求,並在請求上新增一個指定的請求頭引數 | name:需要新增的請求頭引數的 key value:需要新增的請求頭引數的 value |
- AddRequestHeader=my-request-header,1024 |
| AddRequestParameter | 攔截傳入的請求,並在請求上新增一個指定的請求引數 | name:需要新增的請求引數的 key value:需要新增的請求引數的 value |
- AddRequestParameter=my-request-param,c.biancheng.net |
| AddResponseHeader | 攔截響應,並在響應上新增一個指定的響應頭引數 | name:需要新增的響應頭的 key value:需要新增的響應頭的 value |
- AddResponseHeader=my-response-header,c.biancheng.net |
| PrefixPath | 攔截傳入的請求,並在請求路徑增加一個指定的字首 | prefix:需要增加的路徑字首 | - PrefixPath=/consumer |
| PreserveHostHeader | 轉發請求時,保持使用者端的 Host 資訊不變,然後將它傳遞到提供具體服務的微服務中 | 無 | - PreserveHostHeader |
| RemoveRequestHeader | 移除請求頭中指定的引數 | name:需要移除的請求頭的 key | - RemoveRequestHeader=my-request-header |
| RemoveResponseHeader | 移除響應頭中指定的引數 | name:需要移除的響應頭 | - RemoveResponseHeader=my-response-header |
| RemoveRequestParameter | 移除指定的請求引數 | name:需要移除的請求引數 | - RemoveRequestParameter=my-request-param |
| RequestSize | 設定請求體的大小,當請求體過大時,將會返回 413 Payload Too Large | maxSize:請求體的大小 | - name: RequestSize args: maxSize: 5000000 |
GlobalFilter 全域性過濾器
全域性過濾器的作用也是處理一切進入閘道器的請求和微服務響應
- 像上面一樣直接在YAML檔案中設定
缺點:要是需要編寫複雜的業務邏輯時會非常不方便,但是:這種過濾器的優先順序比下面一種要高
server:
port: 10010 # 閘道器埠
spring:
application:
name: gateway # 服務名稱
cloud:
nacos:
server-addr: localhost:8848 # nacos地址
gateway:
routes: # 閘道器路由設定
- id: userservice # 路由id,自定義,只要唯一即可
# uri: http://127.0.0.1:8081 # 路由的目標地址
uri: lb://userservice # 路由的目標地址 lb就是負載均衡,後面跟服務名稱
predicates: # 路由斷言,也就是判斷請求是否符合路由規則的條件
- Path=/user/** # 按路徑匹配,只要以 /user/ 開頭就符合要求
# filters:
# - AddRequestHeader=name, zixieqing
- id: orderservice
uri: lb://orderservice
predicates:
- Path=/order/**
default-filters:
# 全域性過濾器
- AddRequestHeader=name, zixieqing
- 使用程式碼實現,定義方式是實現GlobalFilter介面:
public interface GlobalFilter {
/**
* 處理當前請求,有必要的話通過 GatewayFilterChain 將請求交給下一個過濾器處理
*
* @param exchange 請求上下文,裡面可以獲取Request、Response等資訊
* @param chain 用來把請求委託給下一個過濾器
* @return Mono<Void> 返回標示當前過濾器業務結束
*/
Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain);
}
在filter中編寫自定義邏輯,可以實現下列功能:
- 登入狀態判斷
- 許可權校驗
- 請求限流等
舉例如下:獲取和比較的就是剛剛前面在YAML中使用的 - AddRequestHeader=name, zixieqing
package com.zixieqing.gateway.filter;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.annotation.Order;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
import java.util.List;
/**
* <p>@description : 自定義gateway全域性路由器:請求頭中有 name=zixieqing 才放行
* </p>
* <p>@author : ZiXieqing</p>
*/
@Order(-1) // 這個註解和本類實現 Ordered 是一樣的效果,都是返回一個整數
// 這個整數表示當前過濾器的執行優先順序,值越小優先順序越高,取值範圍就是 int的範圍
@Component
public class MyGlobalFilter implements GlobalFilter /* , Ordered */ {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 獲取請求頭中的name
List<String> name = exchange.getRequest().getHeaders().get("name");
for (String value : name) {
if ("zixieqing".equals(value))
// 放行
return chain.filter(exchange);
}
// 設定狀態碼
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
// 不再執行下去,到此結束 setComplete即設定完成的意思
return exchange.getResponse().setComplete();
}
}
過濾器執行順序
請求進入閘道器會碰到三類過濾器:當前路由的過濾器、DefaultFilter、GlobalFilter
請求路由後,會將當前路由過濾器和DefaultFilter、GlobalFilter,合併到一個過濾器鏈(集合)中,排序後依次執行每個過濾器:
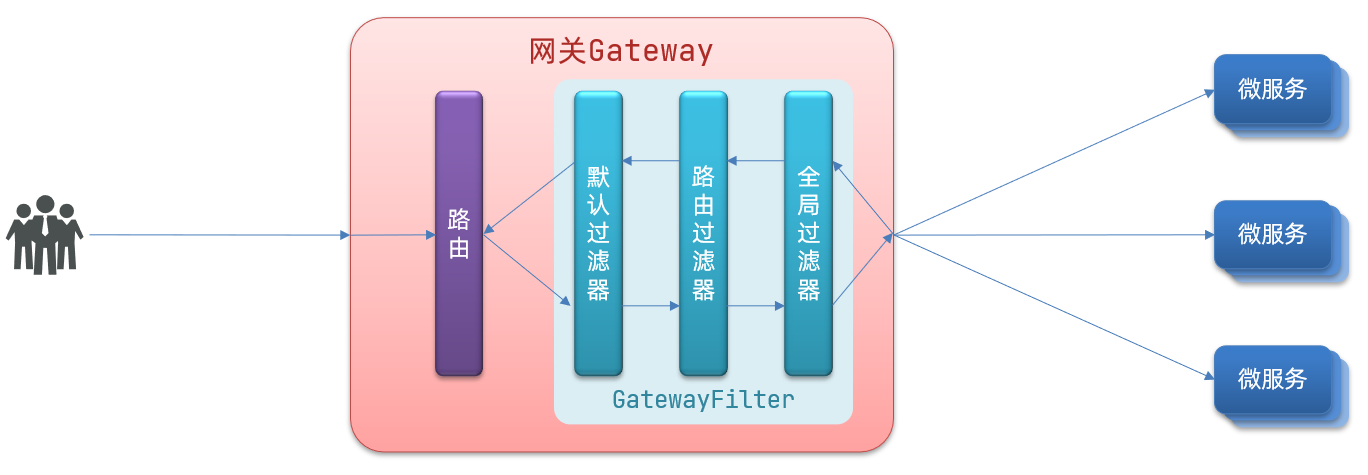
排序的規則是什麼呢?
- 每一個過濾器都必須指定一個int型別的order值,order值越小,優先順序越高,執行順序越靠前
- GlobalFilter通過實現Ordered介面,或者新增 @Order 註解來指定order值,由我們自己指定
- 路由過濾器和defaultFilter的order值由Spring指定,預設是按照宣告順序從1遞增
- 當過濾器的order值一樣時,會按照 defaultFilter > 路由過濾器 > GlobalFilter 的順序執行
詳細內容,可以檢視原始碼:
org.springframework.cloud.gateway.route.RouteDefinitionRouteLocator#getFilters()方法是先載入defaultFilters,然後再載入某個route的filters,最後合併org.springframework.cloud.gateway.handler.FilteringWebHandler#handle()方法會載入全域性過濾器,與前面的過濾器合併後根據order排序,組織過濾器鏈
閘道器跨域問題
跨域:域名不一致就是跨域,主要包括:
-
域名不同: www.taobao.com 和 www.taobao.org 和 www.jd.com 和 miaosha.jd.com
-
域名相同,埠不同:localhost:8080 和 localhost8081
跨域問題:瀏覽器禁止請求的發起者與伺服器端發生跨域ajax請求,請求被瀏覽器攔截的問題
解決方案:CORS,瞭解CORS可以去這裡 https://www.ruanyifeng.com/blog/2016/04/cors.html
全域性跨域
解決方式:在gateway服務的 application.yml 檔案中,新增下面的設定:
spring:
cloud:
gateway:
globalcors: # 全域性的跨域處理
# 解決options請求被攔截問題。CORS跨域瀏覽器會問伺服器可不可以跨域,而這種請求是options,閘道器預設會攔截這種請求
add-to-simple-url-handler-mapping: true
corsConfigurations:
'[/**]': # 攔截哪些請求,此處為攔截所有請求
allowedOrigins: # 允許哪些網站的跨域請求
- "http://localhost:8090"
allowedMethods: # 允許的跨域ajax的請求方式
- "GET"
- "POST"
- "DELETE"
- "PUT"
- "OPTIONS"
allowedHeaders: "*" # 允許在請求中攜帶的頭資訊
allowCredentials: true # 是否允許攜帶cookie
maxAge: 360000 # 這次跨域檢測的有效期是多少秒。每次跨域都要詢問一次伺服器,這會浪費一定效能,因此加入有效期
區域性跨域
route設定允許將 CORS 作為後設資料直接應用於路由,例如下面的設定:
spring:
cloud:
gateway:
routes:
- id: cors_route
uri: https://example.org
predicates:
- Path=/service/**
metadata:
cors
allowedOrigins: '*'
allowedMethods:
- GET
- POST
allowedHeaders: '*'
maxAge: 30
注意:若是
predicates中的Path沒有的話,那麼預設使用/**
Docker
安裝docker
1、安裝yum工具
yum install -y yum-utils device-mapper-persistent-data lvm2 --skip-broken
2、更新本地映象源為阿里映象源
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
sed -i 's/download.docker.com/mirrors.aliyun.com\/docker-ce/g' /etc/yum.repos.d/docker-ce.repo
yum makecache fast
3、安裝docker
yum install -y docker-ce
4、關閉防火牆
Docker應用需要用到各種埠,逐一去修改防火牆設定。非常麻煩,因此可以選擇直接關閉防火牆,也可以開放需要的埠號,這裡採用直接關閉防火牆
# 關閉
systemctl stop firewalld
# 禁止開機啟動防火牆
systemctl disable firewalld
5、啟動docker服務
systemctl start docker
6、開啟開機自啟
systemctl enable docker
7、測試是否成功
docker ps

出現這個頁面,則:說明安裝成功
或者是:
docker -v
出現docker版本號也表示成功
8、設定映象加速
docker官方映象倉庫網速較差,我們需要設定國內映象服務:
參考阿里雲的映象加速檔案:https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors
映象名稱
首先來看下映象的名稱組成:
- 鏡名稱一般分兩部分組成:[repository]:[tag]。
- 在沒有指定tag時,預設是latest,代表最新版本的映象
如圖:
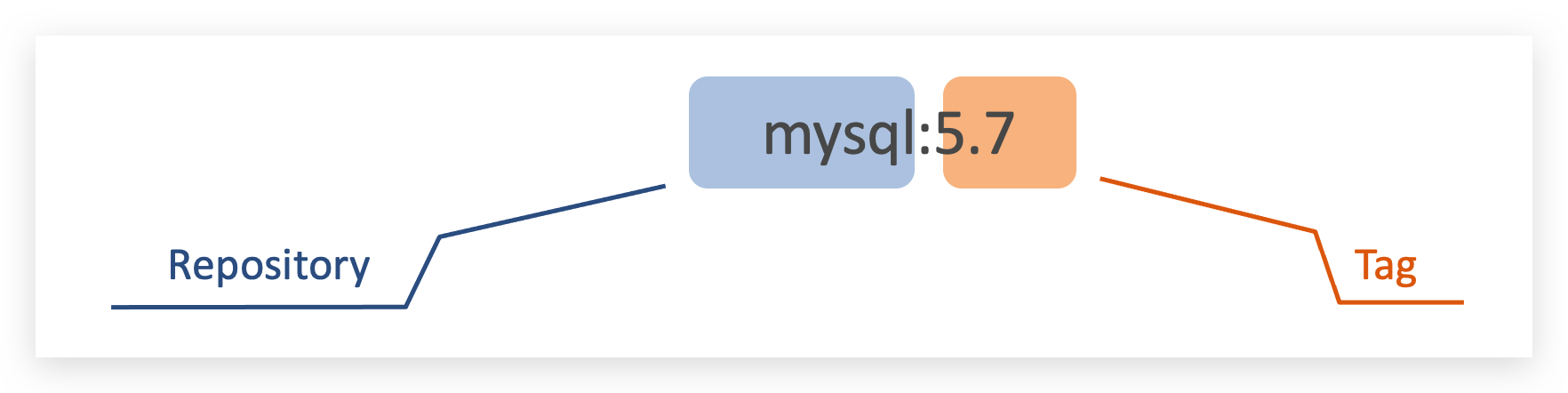
這裡的mysql就是repository,5.7就是tag,合一起就是映象名稱,代表5.7版本的MySQL映象。
Docker命令
Docker倉庫地址(即dockerHub):https://hub.docker.com
常見的映象操作命令如圖:
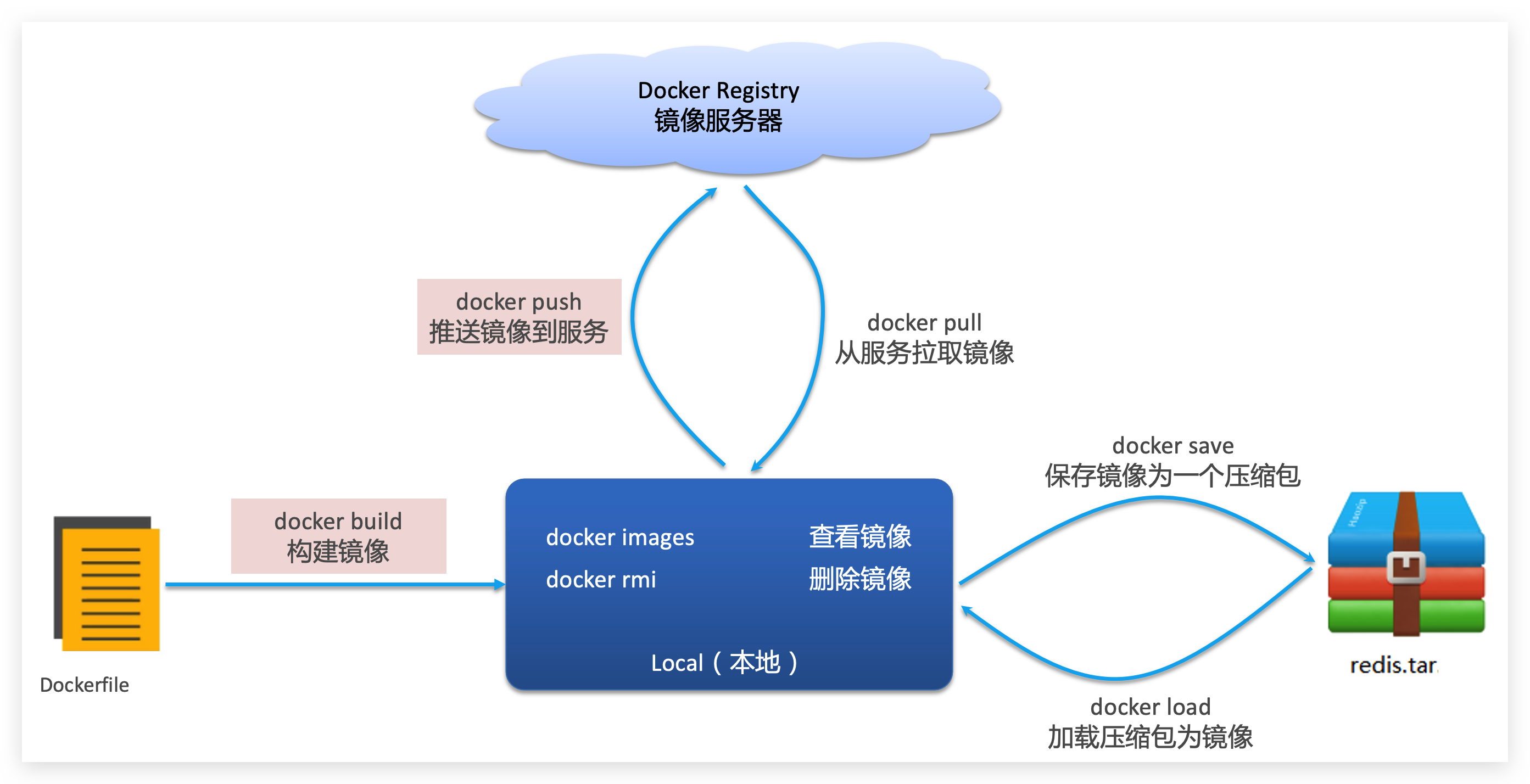
# 拉取映象
docker pull 映象名稱
# 檢視全部映象
docker images
# 刪除映象
docker rmi 映象ID
# 將原生的映象匯出
docker save -o 匯出的路徑 映象id
# 載入原生的映象檔案
docker load -i 映象檔案
# 修改映象名稱
docker tag 映象id 新映象名稱:版本
# 簡單執行操作
docker run 映象ID | 映象名稱
# docker run 指的是建立一個容器並執行
# 跟引數的執行
docker run -d -p 宿主機埠:容器埠 --name 容器名稱 映象ID | 映象名稱
# 如:docker run -d -p 8081:8080 --name tomcat b8
# -d:代表後臺執行容器
# -p 宿主機埠:容器埠 為了對映當前Linux的埠和容器的埠
# --name 容器名稱:指定容器的名稱
# 檢視執行的容器
docker ps [-qa]
# -a:檢視全部的容器,包括沒有執行
# -q:只檢視容器的標識
# 檢視紀錄檔
docker logs -f 容器id
# -f:可以捲動檢視紀錄檔的最後幾行
# 進入容器內部
docker exec -it 容器id bash
# docker exec 進入容器內部,執行一個命令
# -it 給當前進入的容器建立一個標準輸入、輸出終端,允許我們與容器互動
# bash 進入容器後執行的命令,bash是一個Linux終端互動命令
# 退出容器:exit
# 將宿主機的檔案複製到容器內部的指定目錄
docker cp 檔名稱 容器id:容器內部路徑
docker cp index.html 982:/usr/local/tomcat/webapps/ROOT
# 重新啟動容器
docker restart 容器id
# 啟動停止執行的容器
docker start 容器id
# 停止指定的容器(刪除容器前,需要先停止容器)
docker stop 容器id
# 停止全部容器
docker stop $(docker ps -qa)
# 刪除指定容器
docker rm 容器id
# 刪除全部容器
docker rm $(docker ps -qa)
# ==================資料卷volume========================
# 建立資料卷
docker volume create 資料卷名稱
# 建立資料卷之後,預設會存放在一個目錄下 /var/lib/docker/volumes/資料卷名稱/_data
# 檢視資料卷詳情
docker volume inspect 資料卷名稱
# 檢視全部資料卷
docker volume ls
# 刪除指定資料卷
docker volume rm 資料卷名稱
# Docker容器對映資料卷==========>有兩種方式:
# 1、通過資料卷名稱對映,如果資料卷不存在。Docker會幫你自動建立,會將容器內部自帶的檔案,儲存在預設的存放路徑中
# 通過資料卷名稱對映
docker run -v 資料卷名稱:容器內部的路徑 映象id
# 2、通過路徑對映資料卷,直接指定一個路徑作為資料卷的存放位置。但是這個路徑不能是空的 - 重點掌握的一種
# 通過路徑對映資料卷
docker run -v 宿主機中自己建立的路徑:容器內部的路徑 映象id
# 如:docker run -d -p 8081:8080 --name tomcat -v[volume] /opt/tocmat/usr/local/tocmat/webapps b8
資料卷掛載和目錄直接掛載的區別:
- 資料卷掛載耦合度低,由docker來管理目錄且目錄較深,所以不好找
- 目錄掛載耦合度高,需要我們自己管理目錄,不過很容易檢視
更多命令通過
docker -help或docker 某指令 --help來學習
虛懸映象
指的是:倉庫名、標籤都是 <none> ,即俗稱dangling image
出現的原因:在構建映象或刪除映象時出現了某些錯誤,從而導致倉庫名和標籤都是 <none>
事故重現:
# 1、建立Dockerfile檔案,注:必須是大寫的D
vim Dockerfile
# 2、編寫如下內容,下面這兩條指令看不懂沒關係,下一節會解釋
FROM ubuntu
CMD echo "執行完成"
# 3、構建映象
docker build .
# 4、檢視映象
docker images

這種東西就是「虛懸映象」,就是個殘次品,不是一定會出事,也不是一定不會出事,但一旦有,就很可能會導致專案出問題,因此絕不可以出現這種映象,一旦有就最好刪掉
# 檢視虛懸映象有哪些
docker image ls -f dangling=true
# 刪除所有的虛懸映象
docker image prune
Dockerfile 自定義映象
玩這個玩的就是三步驟,重現虛懸映象時已經見了一下:
- 編輯Dockerfile檔案 注:必須是大寫D
- docker build構建成Docker映象
- 啟動構建的Docker映象
Dockerfile檔案中的關鍵字
官網: https://docs.docker.com/engine/reference/builder/
| 指令 | 含義 | 解讀 | 範例 |
|---|---|---|---|
| # | 註釋 | 字面意思 | # 註釋內容 |
| FROM | 指定當前新映象是基於哪個基礎映象,即:基於哪個映象繼續升級 「必須放在第一行」 |
類似於對「某系統」進行升級,新增新功能 這裡的「某系統」就是基礎映象 |
FROM centos:7 |
| MAINTAINER | 映象的作者和郵箱 | 和IDEA中寫一個類或方法時留下自己姓名和郵箱類似 | MAINTAINER zixq[email protected] |
| RUN | 容器「執行時」需要執行的命令 RUN是在進行docker build時執行 |
在進行docker build時會安裝一些命令或外掛,亦或輸出一句話用來提示進行到哪一步了/當前這一步是否成功了 | 有兩種格式: 1、shell格式:RUN <命令列命令> 如:RUN echo 「Successfully built xxxx」 或者是 RUN yum -y imstall vim 這種等價於在終端中執行shell命令 2、exec格式:RUN {「可執行檔案」,」引數1」,」引數2」} 如:RUN {「./startup.cmd」,」-m」,」standalone」} 等價於 startup.cmd -m standalone |
| EXPOSE | 當前容器對外暴露出的埠 | 字面意思。容器自己想設定的埠,docker要做宿主機和容器內埠對映咯 | EXPOSE 80 |
| WORKDIR | 指定在容器建立後,終端預設登入進來時的工作目錄 | 虛擬機器器進入時預設不就是 ~ 或者 Redis中使用Redis -cli登入進去之後不是也有預設路徑嗎 |
WORKDIR /usr/local 或 WORKDIR / |
| USER | 指定該映象以什麼樣的使用者去執行,若不進行指定,則預設用 root 使用者 這玩意兒一般都不會特意去設定 |
時空見慣了,略過 | USER root |
| ENV | 是environment的縮寫,即:用來在映象構建過程中設定環境變數 | 可以粗略理解為定義了一個 key=value 形式的常數,這個常數方便後續某些地方直接進行參照 | ENV MY_NAME="John Doe" 或形象點 ENV JAVA_HOME=/usr/local/java |
| VOLUME | 資料卷,進行資料儲存和持久化 | 和前面docker中使用 -v 資料卷是一樣的 |
VOLUME /myvol |
| COPY | 複製,拷貝目錄和檔案到映象中 | COPY test.txt relativeDir/ 注:這裡的目標路徑或目標檔案relativeDir 不用事先建立,會自動建立 |
|
| ADD | 將宿主機目錄下的檔案拷貝進映象 且 會自動處理URL和解壓tar壓縮包 | 和COPY類似,就是COPY+tar檔案解壓這兩個功能組合 | ADD test.txt /mydir/ 或形象點 ADD target/tomcat-stuffed-1.0.jar /deployments/app.jar |
| CMD | 指定容器「啟動後」要乾的事情 Dockerfile中可以有多個CMD指令,「但是:只有最後一個有效」 「但可是:若Dockerfile檔案中有CMD,而在執行docker run時後面跟了引數,那麼就會替換掉Dockerfile中CMD的指令」,如: docker run -d -p 80:80 —name tomcat 容器ID /bin/bash 這裡用了/bin/bash引數,那就會替換掉自定義的Dockerfile中的CMD指令 |
和RUN一樣也是支援兩種格式 1、shell格式:CMD <命令> 如 CMD echo "wc,This is a test" 2、exec格式:CMD {「可執行檔案」,」引數1」,」引數2」} 和RUN的區別: CMD是docker run時執行 RUN是docker build時執行 |
|
| ENTRYPOINT | 也是用來指定一個容器「啟動時」要執行的命令 | 類似於CMD指令,但:ENRTYPOINT不會被docker run後面的命令覆蓋,且這些命令列會被當做引數送給ENTRYPOINT指令指定的程式 |
和CMD一樣,支援兩種格式 1、shell格式:ENTRYPOINT<命令> 2、exec格式:ENTRYPOINT |
注意: 上表中指令必須是大寫
再理解Dockerfile語法,直接參考Tomcat:https://github.com/apache/tomcat/blob/main/modules/stuffed/Dockerfile
將微服務構建為映象部署
這個玩意兒屬於雲原生技術裡面的,因為前面都玩了Dockerfile,所以就順便弄一下這個
思路:
-
建立一個微服務專案,編寫自己的邏輯,通過Maven的package工具打成jar包
-
將打成的jar包上傳到自己的虛擬機器器中,目錄自己隨意
-
建立Dockerfile檔案,並編寫內容,參考如下:
# 基礎映象 FROM java:8 # 作者 MAINTAINER zixq # 資料卷 在宿主機/var/lib/docker目錄下建立了一個臨時檔案並對映到容器的/tmp VOLUME /tmp # 將jar包新增到容器中 並 更名為 zixq_dokcer.jar ADD docker_boot-0.0.1.jar zixq_docker.jar # 執行jar包 RUN bash -c "touch /zixq_docker.jar" ENTRYPOINT {"java","-jar","/zixq_docker.jar"} # 暴露埠 EXPOSE 8888注:Dockerfile檔案和jar包最好在同一目錄
-
構建成docker映象
# docker build -t 倉庫名字(REPOSITORY):標籤(TAG) docker build -t zixq_docker:0.1 . # 最後有一個 點. 表示:當前目錄,jar包和Dockerfile不都在當前目錄嗎 -
執行映象
docker run -d -p 8888:8888 映象ID # 注意防火牆的問題,埠是否開放或防火牆是否關閉,否則關閉/開放,然後重啟docker,重現執行映象......... -
瀏覽器存取
自己虛擬機器器ip + 5中暴露的port + 自己微服務中的controller路徑
Docker-Compose
Docker Compose可以基於Compose檔案幫我們快速的部署分散式應用,而無需手動一個個建立和執行容器!
安裝Docker-Compose
1、下載Docker-Compose
# 1、安裝
# 1.1、選擇線上,直接官網拉取
curl -L https://github.com/docker/compose/releases/download/1.23.1/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
# 要是嫌慢的話,也可以去這個網址
curl -L https://get.daocloud.io/docker/compose/releases/download/1.26.2/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
# 1.2、也可以選擇離線安裝,直接下載到本地後,上傳到虛擬機器器 /usr/local/bin/ 路徑中即可
# 2、修改檔案許可權,因為 /usr/local/bin/docker-compose 檔案還沒有執行權
chmod +x /usr/local/bin/docker-compose
# 3、檢測是否成功,出現命令檔案說明就表示成功了
docker-compose
可以再加上一個東西:Base自動補全命令
# 補全命令
curl -L https://raw.githubusercontent.com/docker/compose/1.29.1/contrib/completion/bash/docker-compose > /etc/bash_completion.d/docker-compose
# 若是出現錯誤,這是因為上面這個網址域名的問題,這需要修改hosts檔案
# 可以先修改hosts,然後再拉取Base自動補全命令
echo "199.232.68.133 raw.githubusercontent.com" >> /etc/hosts
Docker-Compose語法
DockerCompose的詳細語法參考官網:https://docs.docker.com/compose/compose-file/
其實DockerCompose檔案可以看做是將多個docker run命令寫到一個檔案,只是語法稍有差異
Compose檔案是一個文字檔案(YAML格式),通過指令定義叢集中的每個容器如何執行。格式如下:
注: 這YAML裡面的格式要求很嚴格
- 每行末尾別有空格
- 別用tab縮排(在IDEA中編輯好除外,這種會自動進行轉換,但偶爾會例外),容易導致啟動不起來
- 註釋最好像下面這樣寫在上面,不要像在IDEA中寫在行尾,這樣容易解析出錯成為空格(偶爾會莫名其妙啟動不起來,把註釋位置改為上面又可以了)
# docker-compose的版本,目前的版本有1.x、2.x、3.x
version: "3.2"
services:
# 就是docker run中 --name 後面的名字
nacos:
image: nacos/nacos-server
environment:
# 前面玩nacos的單例模式啟動
MODE: standalone
ports:
- "8848:8848"
mysql:
image: mysql:5.7.25
environment:
MYSQL_ROOT_PASSWORD: 123
volumes:
- "$PWD/mysql/data:/var/lib/mysql"
- "$PWD/mysql/conf:/etc/mysql/conf.d/"
# 對某微服務的設定,一般不要暴露埠,閘道器會協調,微服務之間是內部存取,對於使用者只需暴露一個入口就行,即:閘道器
xxxservice:
build: ./xxx-service
yyyservice:
build: ./yyy-service
# 閘道器微服務設定
gateway:
build: ./gateway
ports:
- "10010:10010"
上面的Compose檔案就描述一個專案,其中包含兩個容器(對照使用 docker run -d -p 對映出來的宿主機埠:容器內暴露的埠 –name 某名字……… 命令跑某個映象,這檔案內容就是多個容器設定都在一起,最後一起跑起來而已):
- mysql:一個基於
mysql:5.7.25映象構建的容器,並且掛載了兩個目錄 - web:一個基於
docker build臨時構建的映象容器,對映埠時8090
Docker-Compose的基本命令
在使用docker-compose的命令時,預設會在當前目錄下找 docker-compose.yml 檔案(這個檔案裡面的內容就是上一節中YAML格式的內容寫法),所以:需要讓自己在建立的 docker-compose.yml 檔案的當前目錄中,從而來執行docker-compose相關的命令
# 1. 基於docker-compose.yml啟動管理的容器
docker-compose up -d
# 2. 關閉並刪除容器
docker-compose down
# 3. 開啟|關閉|重啟已經存在的由docker-compose維護的容器
docker-compose start|stop|restart
# 4. 檢視由docker-compose管理的容器
docker-compose ps
# 5. 檢視紀錄檔
docker-compose logs -f [服務名1] [服務名2]
更多命令使用
docker-compose -help或docker-compose 某指令 --help檢視即可
Docker私有倉庫搭建
公共倉庫:像什麼前面的DockerHub、DaoCloud、阿里雲映象倉庫…………..
簡化版倉庫
Docker官方的Docker Registry是一個基礎版本的Docker映象倉庫,具備倉庫管理的完整功能,但是沒有圖形化介面。
搭建方式如下:
# 直接在虛擬機器器中執行命令即可
docker run -d \
--restart=always \
--name registry \
-p 5000:5000 \
-v registry-data:/var/lib/registry \
registry
命令中掛載了一個資料卷registry-data到容器內的 /var/lib/registry 目錄,這是私有映象庫存放資料的目錄
存取http://YourIp:5000/v2/_catalog 可以檢視當前私有映象服務中包含的映象
圖形化倉庫
1、在自己的目錄中建立 docker-compose.yml 檔案
vim docker-compose.yml
2、設定Docker信任地址:Docker私服採用的是http協定,預設不被Docker信任,所以需要做一個配
# 開啟要修改的檔案
vim /etc/docker/daemon.json
# 新增內容:registry-mirrors 是前面已經設定過的阿里雲加速,放在這裡是為了注意整個json怎麼設定的,以及注意多個是用 逗號 隔開的
# 真正要加的內容是 "insecure-registries":["http://192.168.150.101:8080"]
{
"registry-mirrors": ["https://838ztoaf.mirror.aliyuncs.com"],
"insecure-registries":["http://192.168.150.101:8080"]
}
# 過載入
systemctl daemon-reload
# 重啟docker
systemctl restart docker
3、在docekr-compose.yml檔案中編寫如下內容
version: '3.0'
services:
registry:
image: registry
volumes:
- ./registry-data:/var/lib/registry
# ui介面搭建,用的是別人的
ui:
image: joxit/docker-registry-ui:static
ports:
- 8080:80
environment:
- REGISTRY_TITLE=悠忽有限公司私有倉庫
- REGISTRY_URL=http://registry:5000
depends_on:
- registry
4、使用docker-compose啟動容器
docekr-compsoe up -d
5、瀏覽器存取
虛擬機器器IP:上面ui中設定的ports
推播和拉取映象
推播映象到私有映象服務必須先tag,步驟如下:
- 重新tag本地映象,名稱字首為私有倉庫的地址:192.168.xxx.yyy:8080/
# docker tag 倉庫名(REPOSITORY):標籤(TAG) YourIp:ui中設定的port/新倉庫名:標籤
docker tag nginx:latest 192.168.xxx.yyy:8080/nginx:1.0
- 推播映象
docker push 192.168.xxx.yyy:8080/nginx:1.0
- 拉取映象
docker pull 192.168.xxx.yyy:8080/nginx:1.0
RabbitMQ 訊息佇列
這裡只說明一部分,當然針對開發也夠了。全系列的RabbitMQ理論與實操知識去這個旮旯地方:https://www.cnblogs.com/xiegongzi/p/16242291.html
幾種常見MQ的對比
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社群 | Rabbit | Apache | 阿里 | Apache |
| 開發語言 | Erlang | Java | Java | Scala&Java |
| 協定支援 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定義協定 | 自定義協定 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 單機吞吐量 | 一般 | 差 | 高 | 非常高 |
| 訊息延遲 | 微秒級 | 毫秒級 | 毫秒級 | 毫秒以內 |
| 訊息可靠性 | 高 | 一般 | 高 | 一般 |
追求可用性:Kafka、 RocketMQ 、RabbitMQ
追求可靠性:RabbitMQ、RocketMQ
追求吞吐能力:RocketMQ、Kafka
追求訊息低延遲:RabbitMQ、Kafka
5種常用訊息模型
當然只需要記住Topic Exchange型別就可以轉成其他任何一種模型,無非就是少這裡少那裡、適用不同場景的區別
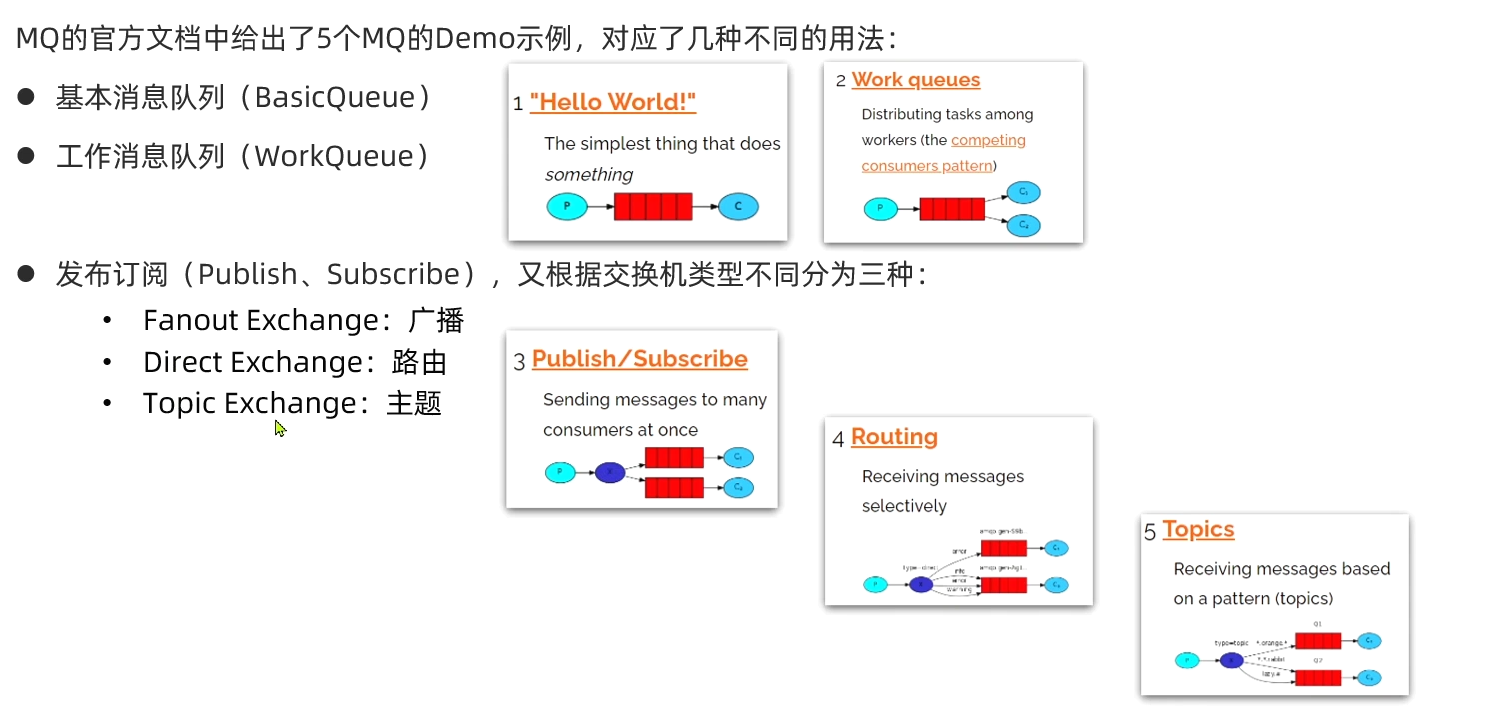
Spring AMQP
Spring AMQP是基於RabbitMQ封裝的一套模板,並且還利用SpringBoot對其實現了自動裝配,使用起來非常方便
Spring AMQP官網:https://spring.io/projects/spring-amqp


Spring AMQP提供了三個功能:
- 自動宣告佇列、交換機及其繫結關係
- 基於註解的監聽器模式,非同步接收訊息
- 封裝了RabbitTemplate工具,用於傳送訊息
依賴:
<!--AMQP依賴,包含RabbitMQ-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
Hello word 基本訊息佇列模型
官網中的結構圖:
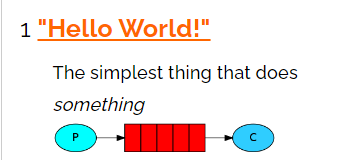
即:1個publisher生產者、1個預設交換機、1個佇列、1個consumer消費者
此種模型:做最簡單的事情,一個生產者對應一個消費者,RabbitMQ相當於一個訊息代理,負責將A的訊息轉發給B
應用場景:將傳送的電子郵件放到訊息佇列,然後郵件服務在佇列中獲取郵件並行送給收件人
生產者
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.ConnectionFactory;
import org.junit.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
/**
* <p>@description : 該類功能 hello word 基本訊息佇列模型 生產者測試
* </p>
* <p>@author : ZiXieqing</p>
*/
@SpringBootTest
public class o1HelloWordTest {
private String host = "自己部署rabbitmq的虛擬機器器ip";
private int port = 5672;
private String username = "zixieqing";
private String password = "072413";
private String queueName = "hello-word";
@Test
public void helloWordTest() throws IOException, TimeoutException {
// 1、設定連結資訊
ConnectionFactory conFactory = new ConnectionFactory();
conFactory.setHost(host);
conFactory.setPort(port);
conFactory.setUsername(username);
conFactory.setPassword(password);
// 當然:這裡還可以設定vhost虛擬機器器
// factory.setVirtualHost();
// 2、獲取管道
Channel channel = conFactory.newConnection().createChannel();
/*
* 3、佇列宣告
* queueDeclare(String queue, boolean durable, boolean exclusive, boolean autoDelete, Map<String, Object> arguments);
* 引數1、佇列名字
* 引數2、是否持久化,預設是在記憶體中
* 引數3、是否共用,即:是否讓多個消費者共用這個佇列中的資訊
* 引數4、是否自動刪除,即:最後一個消費者獲取資訊之後,這個佇列是否自動刪除
* 引數5、其他設定項,這涉及到後面的知識,目前選擇null
* */
channel.queueDeclare(queueName, false, false, false, null);
// 4、訊息推播
String msg = "this is hello word";
/*
* basicPublish(String exchange, String routingKey, BasicProperties props, byte[] body)
* 引數1 交換機名
* 引數2 路由鍵,是hello word 基礎訊息佇列模型,所以此處使用佇列名即可
* 引數3 訊息其他設定項
* 引數4 要傳送的訊息內容
* */
channel.basicPublish("", queueName, null, msg.getBytes());
// 5、釋放資源
channel.close();
conFactory.clone();
}
}
使用Spring AMQP就是如下的方式:
- 設定application.yml
spring:
rabbitmq:
host: 自己的ip
port: 5672
# 叢集的連結方式
# addresses: ip:5672,ip:5673,ip:5674...................
username: "zixieqing"
password: "072413"
# 要是mq設定得有獨立的虛擬機器器空間,則在此處設定虛擬機器器
# virtual-host: /
- 傳送訊息的程式碼:
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
/**
* <p>@description : 該類功能 SpringAMQP測試
* </p>
* <p>@author : ZiXieqing</p>
*/
@RunWith(SpringRunner.class)
@SpringBootTest
public class WorkModeTest {
@Autowired
private RabbitTemplate rabbitTemplate;
/**
* 使用Spring AMQP實現 hello word 簡單佇列模式
*/
@Test
public void springAMQP2HelloWordTest() {
// 1、引入spring-boot-starter-springamqp依賴
// 2、編寫application.uml檔案
// 3、傳送訊息
String queueName = "hello-word";
String message = "hello,this is springAMQP";
rabbitTemplate.convertAndSend(queueName, message);
}
}
消費者
import com.rabbitmq.client.*;
import org.junit.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
/**
* <p>@description : 該類功能 hello word 簡單工作佇列模型 消費者測試
* </p>
* <p>@author : ZiXieqing</p>
*/
@SpringBootTest
public class HelloWordTest {
private String host = "自己部署rabbitmq的虛擬機器器ip";
private int port = 5672;
private String username = "zixieqing";
private String password = "072413";
private String queueName = "hello-word";
@Test
public void consumerTest() throws IOException, TimeoutException {
// 1、設定連結資訊
ConnectionFactory conFactory = new ConnectionFactory();
conFactory.setHost(host);
conFactory.setPort(port);
conFactory.setUsername(username);
conFactory.setPassword(password);
// 2、獲取管道
Channel channel = conFactory.newConnection().createChannel();
/*
* 3、佇列宣告
* queueDeclare(String queue, boolean durable, boolean exclusive, boolean autoDelete, Map<String, Object> arguments);
* 引數1 佇列名
* 引數2 此佇列是否持久化
* 引數3 此佇列是否共用,即:是否讓多個消費者共用這個佇列中的資訊
* 引數4 此佇列是否自動刪除,即:最後一個消費者獲取資訊之後,這個佇列是否自動刪除
* 引數5 其他設定項
*
* */
channel.queueDeclare(queueName, false, false, false, null);
/*
* 4、訂閱訊息
* basicConsume(String queue, boolean autoAck, Consumer callback)
* 引數1 佇列名
* 引數2 是否自動應答
* 引數3 回撥函數
* */
channel.basicConsume(queueName, true, new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("consumerTag = " + consumerTag);
/*
* 可以獲取到交換機、routingkey、deliveryTag
* */
System.out.println("envelope = " + envelope);
System.out.println("properties = " + properties);
System.out.println("處理了訊息:" + new String(body));
}
});
// 這是另外一種接收訊息的方式
/*DeliverCallback deliverCallback = (consumerTag, message) -> {
System.out.println("接收到了訊息:" + new String(message.getBody(), StandardCharsets.UTF_8));
};
CancelCallback cancelCallback = consumerTag -> System.out.println("消費者取消了消費資訊行為");
channel.basicConsume(queueName, true, deliverCallback, cancelCallback);*/
}
}
使用Spring AMQP就是如下的方式:
- 設定application.yml
spring:
rabbitmq:
host: 自己的ip
port: 5672
username: "zixieqing"
password: "072413"
# 要是mq設定的有獨立的虛擬機器器空間,則在此處設定虛擬機器器
# virtual-host: /
- 接收訊息的程式碼:
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
import java.time.LocalTime;
/**
* <p>@description : 該類功能 rabbitmq監聽
* </p>
* <p>@author : ZiXieqing</p>
*/
@Component
public class RabbitmqListener {
// 1、匯入spring-boot-starter-springamqp依賴
// 2、設定application.yml
// 3、編寫接受訊息邏輯
/**
* <p>@description : 該方法功能 監聽 hello-word 佇列
* </p>
* <p>@methodName : listenQueue2HelloWord</p>
* <p>@author: ZiXieqing</p>
*
* @param msg 接收到的訊息
*/
@RabbitListener(queues = "hello-word")
public void listenQueue2HelloWord(String msg) {
System.out.println("收到的訊息 msg = " + msg);
}
}
Work Queue 工作訊息佇列模型
官網中的結構圖:
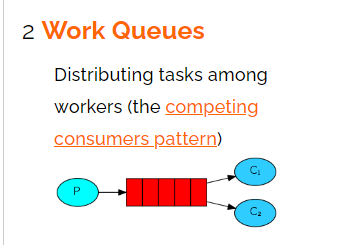
即:1個publisher生產者、1個預設交換機、1個queue佇列、多個consumer消費者
在多個消費者之間分配任務(競爭的消費者模式),一個生產者對應多個消費者,一般適用於執行資源密集型任務,單個消費者處理不過來,需要多個消費者進行處理
應用場景: 一個訂單的處理需要10s,有多個訂單可以同時放到訊息佇列,然後讓多個消費者同時處理
生產者
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
/**
* <p>@description : 該類功能 SpringAMQP測試
* </p>
* <p>@author : ZiXieqing</p>
*/
@RunWith(SpringRunner.class)
@SpringBootTest
public class WorkModeTest {
@Autowired
private RabbitTemplate rabbitTemplate;
/**
* 使用SpringAMQP實現 work queue 工作佇列模式
*/
@Test
public void springAMQP2WorkQueueTest() {
// 1、引入spring-boot-starter-springamqp依賴
// 2、編寫application.uml檔案
// 3、傳送訊息
String queueName = "hello-word";
String message = "hello,this is springAMQP + ";
for (int i = 1; i <= 50; i++) {
rabbitTemplate.convertAndSend(queueName, message + i);
}
}
}
消費者
application.yml設定:
spring:
rabbitmq:
host: 自己的ip
port: 5672
username: "zixieqing"
password: "072413"
# 要是mq設定的有獨立的虛擬機器器空間,則在此處設定虛擬機器器
# virtual-host: /
listener:
simple:
# 不公平分發,預取值 消費者每次從佇列獲取的訊息數量 預設一次250個 通過檢視後臺管理器中queue的unacked數量
prefetch: 1
接收訊息
package com.zixieqing.consumer.listener;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
import java.time.LocalTime;
/**
* <p>@description : 該類功能 rabbitmq監聽
* </p>
* <p>@author : ZiXieqing</p>
*/
@Component
public class RabbitmqListener {
// 1、匯入spring-boot-starter-springamqp依賴
// 2、設定application.yml
// 3、編寫接受訊息邏輯
/**
* <p>@description : 該方法功能 監聽 hello-word 佇列
* </p>
* <p>@author: ZiXieqing</p>
*
* @param msg 接收到的訊息
*/
@RabbitListener(queues = "hello-word")
public void listenQueue2WorkQueue1(String msg) throws InterruptedException {
System.out.println("消費者1收到的訊息 msg = " + msg + " + " + LocalTime.now());
// 模擬效能,假設此消費者效能好
Thread.sleep(20);
}
/**
* <p>@description : 該方法功能 監聽 hello-word 佇列
* </p>
* <p>@author: ZiXieqing</p>
*
* @param msg 接收到的訊息
*/
@RabbitListener(queues = "hello-word")
public void listenQueue2WorkQueue2(String msg) throws InterruptedException {
System.err.println("消費者2.............收到的訊息 msg = " + msg + " + " + LocalTime.now());
// 模擬效能,假設此消費者性差點
Thread.sleep(200);
}
}
交換機
交換機的作用就是為了接收生產者傳送的訊息 並 將訊息傳送到佇列中去
注意:前面玩的那些模式,雖然沒有寫交換機,但並不是說RabbitMQ就沒用交換機
ps:使用的是""空串,也就是使用了RabbitMQ的預設交換機,生產者傳送的訊息只能發到交換機中,從而由交換機來把訊息發給佇列
交換機的分類
- 直接(direct) / routing 模式
- 主題(topic)
- 標題 (heanders)- 這個已經很少用了
- 扇出(fancut) / 廣播
Fanout Exchange 廣播模型 / 釋出訂閱模式
官網結構圖:
即:1個生產者、1個交換機、多個佇列、多個消費者
廣播訊息到所有佇列,沒有任何處理,速度最快。類似群發,一人發,很多人收到訊息
一次向許多消費者傳送訊息,一個生產者傳送的訊息會被多個消費者獲取,也就是將訊息廣播到所有的消費者中
應用場景: 更新商品庫存後需要通知多個快取和多個資料庫,這裡的結構應該是:
- 一個fanout型別交換機扇出兩個訊息佇列,分別為快取訊息佇列、資料庫訊息佇列
- 一個快取訊息佇列對應著多個快取消費者
- 一個資料庫訊息佇列對應著多個資料庫消費者
生產者
package com.zixieqing.publisher;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
/**
* <p> fanout exchange 扇形/廣播模型測試
* </p>
* <p>@author : ZiXieqing</p>
*/
@RunWith(SpringRunner.class)
@SpringBootTest
public class o3FanoutExchangeTest {
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void fanoutExchange4SendMsgTest() {
String exchangeName = "fanout.exchange";
String message = "this is fanout exchange";
rabbitTemplate.convertAndSend(exchangeName,"",message);
}
}
消費者
建立交換機和佇列 並 進行繫結
package com.zixieqing.consumer.config;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.FanoutExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* <p> rabbitMQ設定
* </p>
* <p>@author : ZiXieqing</p>
*/
@Configuration
public class RabbitmqConfig {
/**
* 定義交換機型別 fanout.exchange
*/
@Bean
public FanoutExchange fanoutExchange() {
return new FanoutExchange("fanout.exchange");
}
/**
* 定義佇列 fanout.queue1
*/
@Bean
public Queue fanoutExchange4Queue1() {
return new Queue("fanout.queue1");
}
/**
* 將 fanout.exchange 和 fanout.queue1 兩個進行繫結
*/
@Bean
public Binding fanoutExchangeBindQueue1(Queue fanoutExchange4Queue1, FanoutExchange fanoutExchange) {
return BindingBuilder
.bind(fanoutExchange4Queue1)
.to(fanoutExchange);
}
/**
* 定義佇列 fanout.queue2
*/
@Bean
public Queue fanoutExchange4Queue2() {
return new Queue("fanout.queue2");
}
/**
* 將 fanout.exchange 和 fanout.queue2 兩個進行繫結
*/
@Bean
public Binding fanoutExchangeBindQueue2(Queue fanoutExchange4Queue2, FanoutExchange fanoutExchange) {
return BindingBuilder
.bind(fanoutExchange4Queue2)
.to(fanoutExchange);
}
}
監聽佇列中的訊息:
package com.zixieqing.consumer.listener;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
import java.time.LocalTime;
/**
* <p>@description : 該類功能 rabbitmq監聽
* </p>
* <p>@author : ZiXieqing</p>
*/
@Component
public class RabbitmqListener {
// 1、匯入spring-boot-starter-springamqp依賴
// 2、設定application.yml
// 3、編寫接受訊息邏輯
/**
* fanoutExchange模型 監聽fanout.queue1 佇列的訊息
* @param msg 收到的訊息
*/
@RabbitListener(queues = "fanout.queue1")
public void listenQueue14FanoutExchange(String msg) {
System.out.println("消費者1收到 fanout.queue1 的訊息 msg = " + msg );
}
/**
* fanoutExchange模型 監聽fanout.queue1 佇列的訊息
* @param msg 收到的訊息
*/
@RabbitListener(queues = "fanout.queue2")
public void listenQueue24FanoutExchange(String msg) {
System.err.println("消費者2收到 fanout.queue2 的訊息 msg = " + msg );
}
}
Direct Exchange 路由訊息佇列模型
官網中的結構圖:
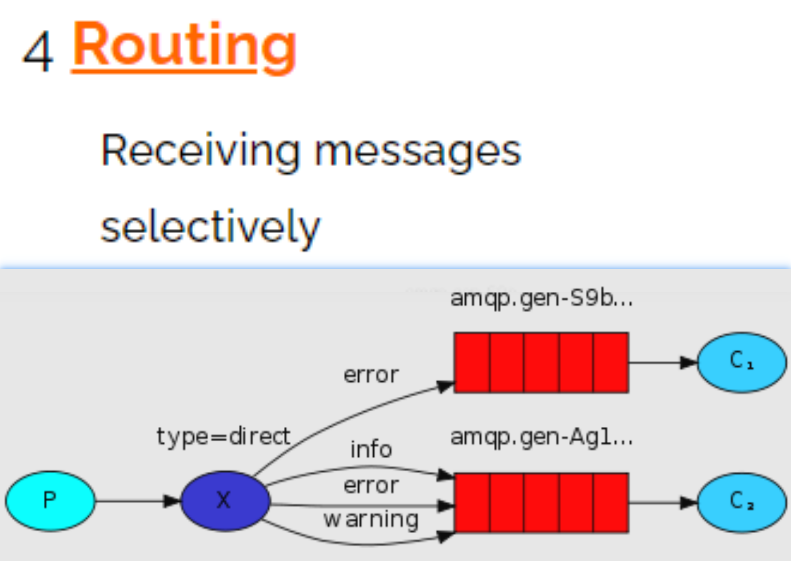
即:1個訊息傳送者、1個交換機、routing key路由鍵、多個佇列、多個訊息消費者
這個玩意兒吧,才是真正的釋出訂閱模式,fanout型別交換機的變樣板,即:多了一個routing key的設定而已,也就是說:生產者和消費者傳輸訊息就通過routing key進行關聯起來,因此:現在就變成了生產者想把訊息發給誰就發給誰
有選擇地(Routing key)接收訊息,傳送訊息到交換機並指定路由key ,消費者將佇列繫結到交換機時需要指定路由key,僅消費指定路由key的訊息
應用場景: 如在商品庫存中增加了1臺iphone12,iphone12促銷活動消費者指定routing key為iphone12,只有此促銷活動會接收到訊息,其它促銷活動不關心也不會消費此routing key的訊息
生產者
package com.zixieqing.publisher;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
/**
* <p> DirectEXchange 路由模式測試
* </p>
* <p>@author : ZiXieqing</p>
*/
@RunWith(SpringRunner.class)
@SpringBootTest
public class o4DirectExchangeTest {
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void sendMsg4DirectExchangeTest() {
String exchangeNmae = "direct.exchange";
String message = "this is direct exchange";
// 把訊息發給 routingkey 為 zixieqing 的佇列中
rabbitTemplate.convertAndSend(exchangeNmae, "zixieqing", message);
}
}
消費者
package com.zixieqing.consumer.listener;
import org.springframework.amqp.core.ExchangeTypes;
import org.springframework.amqp.rabbit.annotation.Exchange;
import org.springframework.amqp.rabbit.annotation.Queue;
import org.springframework.amqp.rabbit.annotation.QueueBinding;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
import java.time.LocalTime;
/**
* <p>@description : 該類功能 rabbitmq監聽
* </p>
* <p>@author : ZiXieqing</p>
*/
@Component
public class RabbitmqListener {
// 1、匯入spring-boot-starter-springamqp依賴
// 2、設定application.yml
// 3、編寫接受訊息邏輯
/**
* 使用純註解的方式宣告佇列、交換機及二者繫結、以及監聽此佇列的訊息
*
* @param msg 監聽到的訊息
*/
@RabbitListener(bindings = @QueueBinding(
// 佇列宣告
value = @Queue(name = "direct.queue1"),
// 交換機宣告
exchange = @Exchange(name = "direct.exchange", type = ExchangeTypes.DIRECT),
// 佇列和交換機的繫結鍵值,是一個陣列
key = {"zixieqing"}
))
public void listenQueue14DirectExchange(String msg) {
System.err.println("消費者1收到 direct.queue1 的訊息 msg = " + msg);
}
/**
* 使用純註解的方式宣告佇列、交換機及二者繫結、以及監聽此佇列的訊息
*
* @param msg 監聽到的訊息
*/
@RabbitListener(bindings = @QueueBinding(
// 佇列宣告
value = @Queue(name = "direct.queue2"),
// 交換機宣告
exchange = @Exchange(name = "direct.exchange", type = ExchangeTypes.DIRECT),
// 佇列和交換機的繫結鍵值,是一個陣列
key = {"zimingxuan"}
))
public void listenQueue24DirectExchange(String msg) {
System.err.println("消費者2收到 direct.queue2 的訊息 msg = " + msg);
}
}
從此處程式碼可以得知:將每個佇列與交換機的routing key改為一樣的值,則變成Fanout Exchange了
Fanout Exchange與Direct Exchange的區別:
- Fanout交換機將訊息路由給每一個與之繫結的佇列
- Direct交換機根據Routing Key判斷路由給哪個佇列
Topic Exchange 主題模型
官網結構圖:
![]()
前面玩的fanout扇出型別的交換機是一個生產者釋出,多個消費者共用訊息,和qq群類似;而direct 路由模式是消費者只能消費和消費者相同routing key的訊息
而上述這兩種還有侷限性,如:現在生產者的routing key為zi.xie.qing,而一個消費者只消費含xie的訊息,一個消費者只消費含qing的訊息,另一個消費者只消費第一個為zi的零個或無數個單詞的訊息,甚至還有一個消費者只消費最後一個單詞為qing,前面有三個單詞的routing key的訊息呢?
這樣一看,釋出訂閱模式和路由模式都不能友好地解決,更別說前面玩的簡單模式、工作佇列模式了,因此:就來了這個topic主題模式
應用場景: iphone促銷活動可以接收主題為iphone的訊息,如iphone12、iphone13等
topic中routing key的要求:只要交換機型別是topic型別的,那麼其routing key就不能亂寫
- routing key只能是一個「單詞列表」,多個單詞之間採用 點 隔開,如:com.zixieqing.rabbit
- 單詞列表的長度不能超過255個位元組
在routing key的規則列表中有兩個替換符可以用
*代表一個單詞#代表零或無數個單詞
生產者
package com.zixieqing.publisher;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
/**
* <p> Topic Exchange 話題模式測試
* </p>
* <p>@author : ZiXieqing</p>
*/
@RunWith(SpringRunner.class)
@SpringBootTest
public class o5TopicExchangeTest {
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void sendMSg2TopicExchangeTest() {
String exchangeNmae = "topic.exchange";
String msg = "貧道又升遷了,離目標越來越近了";
// routing key變為 話題模式 com.zixieqing.blog
rabbitTemplate.convertAndSend(exchangeNmae, "com.zixieqing.blog", msg);
}
}
消費者
package com.zixieqing.consumer.listener;
import org.springframework.amqp.core.ExchangeTypes;
import org.springframework.amqp.rabbit.annotation.Exchange;
import org.springframework.amqp.rabbit.annotation.Queue;
import org.springframework.amqp.rabbit.annotation.QueueBinding;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
import java.time.LocalTime;
/**
* <p>@description : 該類功能 rabbitmq監聽
* </p>
* <p>@author : ZiXieqing</p>
*/
@Component
public class RabbitmqListener {
// 1、匯入spring-boot-starter-springamqp依賴
// 2、設定application.yml
// 3、編寫接受訊息邏輯
/**
* 使用純註解的方式宣告佇列、交換機及二者繫結、以及監聽此佇列的訊息
*/
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "topic.queue1"),
exchange = @Exchange(name = "topic.exchange", type = ExchangeTypes.TOPIC),
// 只接收routing key 前面是一個詞 且 含有 zixieiqng 釋出的訊息
key = {"*.zixieqing.#"}
))
public void listenQueue14TopicExchange(String msg) {
System.out.println("消費者1收到 topic.queue1 的訊息 msg = " + msg);
}
/**
* 使用純註解的方式宣告佇列、交換機及二者繫結、以及監聽此佇列的訊息
*/
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "topic.queue2"),
exchange = @Exchange(name = "topic.exchange", type = ExchangeTypes.TOPIC),
// 只接收routing key含有 blog 釋出的訊息
key = {"#.blog"}
))
public void listenQueue24TopicExchange(String msg) {
System.err.println("消費者1收到 topic.queue1 的訊息 msg = " + msg);
}
}
訊息轉換器
檢視Spring中預設的MessageConverter訊息轉換器
生產者:
package com.zixieqing.publisher;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.HashMap;
import java.util.Map;
/**
* mq訊息轉換器測試
*
* <p>@author : ZiXieqing</p>
*/
@RunWith(SpringRunner.class)
@SpringBootTest
public class o7MessageConverterTest {
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void mqMSgConverterTest() {
// 準備訊息
Map<String,Object> msgMap = new HashMap<>();
msgMap.put("name", "紫邪情");
msgMap.put("age", 18);
msgMap.put("profession", "java");
// 傳送訊息
rabbitTemplate.convertAndSend("msg.converter.queue",msgMap);
}
}
package com.zixieqing.publisher.config;
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 註冊bean
*
* <p>@author : ZiXieqing</p>
*/
@Configuration
public class BeanConfig {
@Bean
public Queue msgConverterQueue() {
return new Queue("msg.converter.queue");
}
}
檢視mq後臺管理介面:
可知:spring中使用的訊息轉換器是 JDK序列化方式,即:ObjectOutputStream
設定Jackson序列化
生產者:
package com.zixieqing.publisher.config;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.amqp.support.converter.MessageConverter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 註冊bean
*
* <p>@author : ZiXieqing</p>
*/
@Configuration
public class BeanConfig {
/**
* 將訊息轉換器改為jackson序列化方式
*/
@Bean
public MessageConverter jacksonMsgConverter() {
return new Jackson2JsonMessageConverter();
}
}
訊息傳送:
package com.zixieqing.publisher;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.HashMap;
import java.util.Map;
/**
* mq訊息轉換器測試
*
* <p>@author : ZiXieqing</p>
*/
@RunWith(SpringRunner.class)
@SpringBootTest
public class o7MessageConverterTest {
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void mqMSgConverterTest() {
// 準備訊息
Map<String,Object> msgMap = new HashMap<>();
msgMap.put("name", "紫邪情");
msgMap.put("age", 18);
msgMap.put("profession", "java");
// 傳送訊息 注意:這裡的msg訊息型別是map
rabbitTemplate.convertAndSend("msg.converter.queue",msgMap);
}
}
消費者:
package com.zixieqing.consumer.config;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.amqp.support.converter.MessageConverter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* bean註冊
*
* <p>@author : ZiXieqing</p>
*/
@Configuration
public class BeanConfig {
/**
* 將訊息轉換器改為jackson序列化方式
*/
@Bean
public MessageConverter jacksonMsgConverter() {
return new Jackson2JsonMessageConverter();
}
}
package com.zixieqing.consumer.listener;
import org.springframework.amqp.core.ExchangeTypes;
import org.springframework.amqp.rabbit.annotation.Exchange;
import org.springframework.amqp.rabbit.annotation.Queue;
import org.springframework.amqp.rabbit.annotation.QueueBinding;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
import java.time.LocalTime;
import java.util.Map;
/**
* <p>@description : 該類功能 rabbitmq監聽
* </p>
* <p>@author : ZiXieqing</p>
*/
@Component
public class RabbitmqListener {
// 1、匯入spring-boot-starter-springamqp依賴
// 2、設定application.yml
// 3、編寫接受訊息邏輯
/**
* 使用jackson的方式對訊息進行接收
* @param msg 接收到的訊息 注:這裡的型別需要和生產者傳送訊息時的型別保持一致
*/
@RabbitListener(queues = "msg.converter.queue")
public void listenQueue4Jackson(Map<String,Object> msg) {
System.out.println("消費者收到訊息 msg = " + msg);
}
}
publisher-confirms 釋出確認模型
如何確保RabbitMQ訊息的可靠性?
- 生產者方:
- 開啟生產者確認機制,確保生產者的訊息能到達佇列
- 開啟持久化功能,確保訊息未消費前在佇列中不會丟失
- 消費者方:
- 開啟消費者確認機制為auto,由spring確認訊息處理成功後完成ack
- 開啟消費者失敗重試機制,並設定MessageRecoverer,多次重試失敗後將訊息投遞到異常交換機,交由人工處理
正常的流程應該是下面的樣子
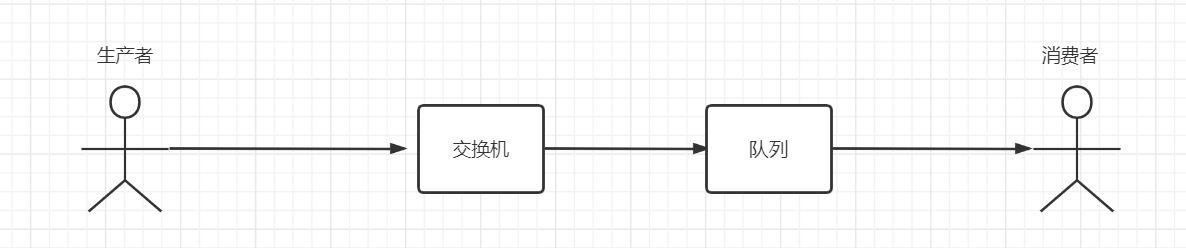
但是:如果交換機出問題了呢,總之就是交換機沒有接收到生產者釋出的訊息(如:發訊息時,交換機名字搞錯了),那訊息就直接丟了嗎?
同理:要是佇列出問題了呢,總之也就是交換機沒有成功地把訊息推到佇列中(如:routing key搞錯了),咋辦?
那就需要第一個條件 傳送訊息確認:用來確認訊息從 producer傳送到 exchange, exchange 到 queue過程中,訊息是否成功投遞
應用場景: 對於訊息可靠性要求較高,比如錢包扣款
流程
- 若訊息未到達exchange,則confirm回撥,ack=false
- 若訊息到達exchange,則confirm回撥,ack=true
- exchange到queue成功,則不回撥return
- exchange到queue失敗,則回撥return(需設定mandatory=true,否則不會回撥,這樣訊息就丟了)
生產者方需要開啟兩個設定:
spring:
rabbitmq:
# 釋出確認型別 生產者開啟 confirm 確認機制 等價於舊版本的publisher-confirms=true
# 有3種屬性設定 correlated none simple
# none 禁用釋出確認模式,是預設值
# correlated 非同步回撥 釋出訊息成功到exchange後會觸發 rabbitTemplate.setConfirmCallback 回撥方法
# simple 同步等待confirm結果,直到超時
publisher-confirm-type: correlated
# 生產者開啟 return 確認機制 如果訊息未能投遞到目標queue中,觸發returnCallback
publisher-returns: true
ConfirmCallback 回撥
在前面 publisher-confirm-type: correlated 設定開啟的前提下,釋出訊息成功到exchange後會進行 ConfirmCallback#confirm 非同步回撥,範例如下:
@Component
public class ConfirmCallbackService implements RabbitTemplate.ConfirmCallback {
/**
* correlationData:物件內部有id (訊息的唯一性)和 Message
* 若ack為false,則Message不為null,可將Message資料 重新投遞;
* 若ack是true,則correlationData為nul
*
* ack:訊息投遞到exchange 的狀態,true表示成功
*
* cause:表示投遞失敗的原因
* 若ack為false,則cause不為null
* 若ack是true,則cause為null
*/
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
if(ack){
System.out.println("訊息送達到Exchange");
}else{
System.out.println("訊息未送達到Exchange");
}
}
}
在生產者傳送訊息時,可以給每一條資訊新增一個dataId,放在CorrelationData,這樣在RabbitConfirmCallback返回失敗時可以知道哪條訊息失敗
public void send(String dataId, String exchangeName, String rountingKey, String message){
CorrelationData correlationData = new CorrelationData();
// 可以給每條訊息設定唯一id 在RabbitConfirmCallback返回失敗時可以知道哪個訊息失敗
correlationData.setId(dataId);
rabbitTemplate.convertAndSend(exchangeName, rountingKey, message, correlationData);
}
public String receive(String queueName){
return String.valueOf(rabbitTemplate.receiveAndConvert(queueName));
}
2.1版本之後,CorrelationData物件具有getFuture,可用於獲取結果,而不用在rabbitTemplate上使用ConfirmCallback
CorrelationData correlationData = new CorrelationData();
// 可以給每條訊息設定唯一id 在RabbitConfirmCallback返回失敗時可以知道哪個訊息失敗
correlationData.setId(dataId);
// 在新版中correlationData具有getFuture,可獲取結果,而不用在rabbitTemplate上使用ConfirmCallback
correlationData.getFuture().addCallback( // 對照Ajax
// 成功:收到MQ發的回執
result -> {
// 成功傳送到exchange
if (result.isAck()) {
// 訊息傳送成功 ack回執
System.out.println(correlationData.getId() + " 訊息傳送成功");
} else { // 未成功傳送到exchange
// 訊息傳送失敗 nack回執
System.out.println(correlationData.getId() + " 訊息傳送失敗,原因:" + result.getReason());
}
}, ex -> { // ex 即 exception 不知道什麼原因,拋了異常,沒收到MQ的回執
System.out.println(correlationData.getId() + " 訊息傳送失敗,原因:" + ex.getMessage());
}
);
rabbitTemplate.convertAndSend(exchangeName, rountingKey, message, correlationData);
ReturnCallback 回撥
如果訊息未能投遞到目標queue中,觸發returnCallback#returnedMessage
注意點:每個RabbitTemplate只能設定一個ReturnCallback。 即Spring全域性只有這一個Return回撥,不能說想寫多少個就寫多少個
若向 queue 投遞訊息未成功,可記錄下當前訊息的詳細投遞資料,方便後續做重發或者補償等操作
但是這玩意兒又要涉及到另外一個設定:訊息路由失敗策略
spring:
rabbitmq:
template:
# 生產者方訊息路由失敗策略
# true:呼叫ReturnCallback
# false:直接丟棄訊息
mandatory: true
ReturnCallBack回撥的玩法:
@Component
public class ReturnCallbackService implements RabbitTemplate.ReturnCallback {
/**
* 保證 spring.rabbitmq.template.mandatory = true 和 publisher-returns: true 的前提下
* 如果訊息未能投遞到目標queue中,觸發本方法
*
* 引數1、訊息 new String(message.getBody())
* 引數2、訊息退回的狀態碼
* 引數3、訊息退回的原因
* 引數4、交換機名字
* 引數5、路由鍵
*/
@Override
public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
System.out.println("訊息沒有送達到Queue");
}
}
ConfirmCallback 和 ReturnCallback 整合的寫法
訊息傳送者編寫程式碼:
package com.zixieqing.publisher.config;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.connection.CorrelationData;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import javax.annotation.PostConstruct;
/**
* <p> mq的confirmCallback和ReturnCallback
* </p>
* <p>@author : ZiXieqing</p>
*/
@Configuration
public class PublisherConfirmAndReturnConfig implements RabbitTemplate.ConfirmCallback,
RabbitTemplate.ReturnCallback {
@Autowired
private RabbitTemplate rabbitTemplate;
/**
* 初始化方法
* 目的:因為ConfirmCallback 和 ReturnCallback這兩個介面是RabbitTemplate的內部類
* 因此:想要讓當前編寫的PublisherConfirmAndReturnConfig能夠存取到這兩個介面
* 那麼:就需要把當前類PublisherConfirmAndReturnConfig的confirmCallback 和 returnCallback
* 注入到RabbitTemplate中去 即:init的作用
*/
@PostConstruct
public void init(){
rabbitTemplate.setConfirmCallback(this);
rabbitTemplate.setReturnCallback(this);
}
/**
* 在前面 publisher-confirm-type: correlated 設定開啟的前提下,釋出訊息成功到exchange後
* 會進行 ConfirmCallback#confirm 非同步回撥
* 引數1、傳送訊息的ID - correlationData.getID() 和 訊息的相關資訊
* 引數2、是否成功傳送訊息給exchange true成功;false失敗
* 引數3、失敗原因
*/
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
if(ack){
System.out.println("訊息送達到Exchange");
}else{
System.out.println("訊息未送達到Exchange");
}
}
/**
* 保證 spring.rabbitmq.template.mandatory = true 和 publisher-returns: true 的前提下
* 如果訊息未能投遞到目標queue中,觸發returnCallback#returnedMessage
*
* 引數1、訊息 new String(message.getBody())
* 引數2、訊息退回的狀態碼
* 引數3、訊息退回的原因
* 引數4、交換機名字
* 引數5、路由鍵
*/
@Override
public void returnedMessage(Message message, int replyCode,
String replyText, String exchange, String routingKey) {
System.out.println("訊息沒有送達到Queue");
}
}
生產者呼叫的方法是:
// 可以給每條訊息設定唯一id
CorrelationData correlationData = new CorrelationData();
correlationData.setId(dataId);
// 傳送訊息
rabbitTemplate.convertAndSend(String exchange, String routingKey, Object message, correlationData);
訊息持久化
生產者確認可以確保訊息投遞到RabbitMQ的佇列中,但是訊息傳送到RabbitMQ以後,如果突然宕機,也可能導致訊息丟失
要想確保訊息在RabbitMQ中安全儲存,必須開啟訊息持久化機制:
- 交換機持久化:RabbitMQ中交換機預設是非持久化的,mq重啟後就丟失。Spring AMQP中可以通過程式碼指定交換機持久化。預設情況下,由Spring AMQP宣告的交換機都是持久化的
@Bean
public DirectExchange simpleExchange(){
// 三個引數:交換機名稱、是否持久化、當沒有queue與其繫結時是否自動刪除
return new DirectExchange(exchangeName, true, false);
}
- 佇列持久化:RabbitMQ中佇列預設是非持久化的,mq重啟後就丟失。SpringAMQP中可以通過程式碼指定交換機持久化。預設情況下,由Spring AMQP宣告的佇列都是持久化的
@Bean
public Queue simpleQueue(){
// 使用QueueBuilder構建佇列,durable就是持久化的
return QueueBuilder.durable(queueName).build();
}
- 訊息持久化:利用Spring AMQP傳送訊息時,可以設定訊息的屬性(MessageProperties),指定delivery-mode:非持久化 / 持久化。預設情況下,Spring AMQP發出的任何訊息都是持久化的
// 構建訊息
Message msg = MessageBuilder.
// 訊息體
withBody(message.getBytes(StandardCharsets.UTF_8))
// 持久化
.setDeliveryMode(MessageDeliveryMode.PERSISTENT)
.build();
消費者訊息確認
RabbitMQ是閱後即焚機制,RabbitMQ確認訊息被消費者消費後會立刻刪除
而RabbitMQ是通過消費者回執來確認消費者是否成功處理了訊息:消費者獲取訊息後,應該向RabbitMQ傳送ACK回執,表明自己已經處理訊息
設想這樣的場景:
- RabbitMQ投遞訊息給消費者
- 消費者獲取訊息後,返回ACK給RabbitMQ
- RabbitMQ刪除訊息
- 消費者宕機,訊息尚未處理
這樣,訊息就丟失了。因此消費者返回ACK的時機非常重要
而Spring AMQP則允許設定三種確認模式:
- manual:手動ack,需要在業務程式碼結束後,呼叫api傳送ack,所以要自己根據業務情況,判斷什麼時候該ack
- auto:自動ack,由spring監測Listener程式碼是否出現異常,沒有異常則返回ack;丟擲異常則返回nack。一般要用就用此種方式即可
- none:關閉ack,MQ假定消費者獲取訊息後會成功處理,因此訊息投遞後立即被刪除。不可靠,訊息可能丟失
使用確認模式:在消費者方的YAML檔案中設定如下內容:
spring:
rabbitmq:
listener:
simple:
acknowledge-mode: auto # 自動應答模式
失敗重試機制
經過前面的 釋出確認模式+訊息持久化+消費者訊息確認 之後,還會有問題,如下面的程式碼:
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueue(String msg) {
log.info("消費者接收到simple.queue的訊息:【{}】", msg);
// 模擬異常
System.out.println(1 / 0);
log.debug("訊息處理完成!");
}
會死迴圈:當消費者出現異常後,訊息會不斷requeue(重入隊)到佇列,再重新傳送給消費者,然後再次異常,再次requeue,無限迴圈,導致mq的訊息處理飆升,帶來不必要的壓力

要解決就就得引入下一節的內容
本地重試機制
可以利用Spring的retry機制,在消費者出現異常時利用本地重試,而不是無限制的requeue到mq佇列
在消費者方的YAML檔案中新增如下內容即可:
spring:
rabbitmq:
listener:
simple:
retry:
enabled: true # 開啟消費者失敗重試
interval-interval: 1000 # 初始的失敗等待時長為1秒
multiplier: 1 # 失敗的等待時長倍數,下次等待時長 = multiplier * interval-interval
max-attempts: 3 # 最大重試次數
stateless: true # true無狀態;false有狀態。如果業務中包含事務,這裡改為false
開啟本地重試時,訊息處理過程中丟擲異常,不會requeue到佇列,而是在消費者本地重試
重試達到最大次數後,Spring會返回ack,訊息會被丟棄。這不可取,對於不重要的訊息可以採用這種方式,但是有時的開發場景中有些訊息很重要,達到重試上限後,不能丟棄,得使用另外的方式:失敗策略
失敗策略
達到最大重試次數後,訊息會被丟棄,這是由Spring內部機制決定的
在開啟重試模式後,重試次數耗盡,如果訊息依然失敗,則需要有MessageRecovery介面來處理,它包含三種不同的實現:
- RejectAndDontRequeueRecoverer:重試耗盡後,直接reject,丟棄訊息。預設就是這種方式
- ImmediateRequeueMessageRecoverer:重試耗盡後,返回nack,訊息重新入隊
- RepublishMessageRecoverer:重試耗盡後,將失敗訊息投遞到指定的交換機
使用RepublisherMessageRecoverer失敗策略:在消費者方定義失敗之後要丟去的exchange+queue
package com.zixieqing.mq.config;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.DirectExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.amqp.rabbit.retry.MessageRecoverer;
import org.springframework.amqp.rabbit.retry.RepublishMessageRecoverer;
import org.springframework.context.annotation.Bean;
@Configuration
public class ErrorMessageConfig {
@Bean
public DirectExchange errorMessageExchange(){
return new DirectExchange("error.direct.exchange");
}
@Bean
public Queue errorQueue(){
return new Queue("error.queue", true);
}
@Bean
public Binding errorBinding(Queue errorQueue, DirectExchange errorMessageExchange){
return BindingBuilder
.bind(errorQueue)
.to(errorMessageExchange)
.with("error");
}
/**
* 定義RepublishMessageRecoverer,關聯佇列和交換機
*/
@Bean
public MessageRecoverer republishMessageRecoverer(RabbitTemplate rabbitTemplate){
return new RepublishMessageRecoverer(rabbitTemplate, "error.direct.exchange", "error");
}
}
死信佇列
死信佇列:指的是「死了」的訊息。 換言之就是:生產者把訊息傳送到交換機中,再由交換機推到佇列中,但由於某些原因,佇列中的訊息沒有被正常消費,從而就讓這些訊息變成了死信,而專門用來放這種訊息的佇列就是死信佇列,同理接收這種訊息的交換機就是死信交換機
讓訊息成為死信的三大因素:
- 訊息過期 即:TTL(time to live)過期
- 超過佇列長度
- 訊息被消費者絕收了
TTL訊息過期
超時分為兩種情況:若下面兩個都設定了,那麼先觸發時間短的那個
- 訊息本身設定了超時時間
- 訊息所在佇列設定了超時時間
實現下圖邏輯:
- 生產者:給訊息設定超時間是
package com.zixieqing.publisher;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.core.MessageBuilder;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.nio.charset.StandardCharsets;
/**
* 死信佇列測試
*
* <p>@author : ZiXieqing</p>
*/
@Slf4j
@SpringBootTest(classes = PublisherApp.class)
public class o8DelayedQueueTest {
@Autowired
private RabbitTemplate rabbitTemplate;
/**
* 發訊息給TTL正常交換機
*/
@Test
void TTLMessageTest() {
Message message = MessageBuilder
.withBody("hello,dead-letter-exchange".getBytes(StandardCharsets.UTF_8))
// 給訊息設定失效時間,單位ms
.setExpiration("5000")
.build();
rabbitTemplate.convertAndSend("ttl.direct", "ttl", message);
log.info("訊息傳送成功");
}
}
- 消費者:宣告死信交換機+死信佇列+二者的繫結+接收訊息並處理
/**
* TTL正常佇列,同時繫結死信交換機
*/
@Bean
public Queue ttlQueue() {
return QueueBuilder
.durable("ttl.queue")
// 設定佇列的超時時間
.ttl(10000)
// 繫結死信交換機
.deadLetterExchange("dl.direct")
// 死信交換機與死信佇列的routing key
.deadLetterRoutingKey("dl")
.build();
}
/**
* 將正常交換機和正常佇列進行繫結
*/
@Bean
public Binding ttlBinding() {
return BindingBuilder
.bind(ttlQueue())
.to(ttlExchange())
.with("ttl");
}
/**
* 監聽死信佇列:死信交換機+死信佇列進行繫結
*/
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "dl.queue", durable = "true"),
exchange = @Exchange(name = "dl.direct"),
key = "dl"
))
public void listenDlQueue(String msg) {
log.info("消費者收到了dl.queue的訊息:{}", msg);
}
超過佇列最大長度
分為兩種情況:
- 佇列中只能放多少條訊息
- 佇列中只能放多少位元組的訊息
@Bean
public Queue queueLength() {
return QueueBuilder
.durable("length.queue")
// 佇列只能放多少條訊息
.maxLength(100)
// 佇列中只能放多少位元組的訊息
.maxLengthBytes(10240)
.build();
// 或下面的方式宣告
Map<String, Object> params = new HashMap<>();
// 佇列最大長度,即佇列中只能放這麼多個訊息
params.put("x-max-length", 100);
// 佇列中最大的位元組數
params.put("x-max-length=bytes", 10240);
return new Queue("length.queue", false, false, false, params);
}
另外一種被消費者拒收就是nack了,早已熟悉
惰性佇列
解決的問題: 訊息堆積問題。當生產者傳送訊息的速度超過了消費者處理訊息的速度,就會導致佇列中的訊息堆積,直到佇列儲存訊息達到上限。之後傳送的訊息就會成為死信,可能會被丟棄,這就是訊息堆積問題
惰性佇列: RabbitMQ 3.6加入的,名為lazy queue
- 接收到訊息後直接存入磁碟而非記憶體
- 消費者要消費訊息時才會從磁碟中讀取並載入到記憶體
- 支援數百萬條的訊息儲存
解決訊息堆積有兩種思路:
-
增加更多消費者,提高消費速度。也就是之前說的work queue模式
-
擴大佇列容積,提高堆積上限(惰性佇列要採用的方式)
-
Linux中宣告
rabbitmqctl set_policy Lazy "^lazy-queue$" '{"queue-mode":"lazy"}' --apply-to queues
rabbitmqctl RabbitMQ的命令列工具
set_policy 新增一個策略
Lazy 策略名稱,可以自定義
"^lazy-queue$" 用正規表示式匹配佇列的名字
'{"queue-mode":"lazy"}' 設定佇列模式為lazy模式
--apply-to queues 策略的作用物件,是所有的佇列
- Java程式碼宣告:消費者方定義即可
/**
* 惰性佇列宣告:Bean註解的方式
*/
@Bean
public Queue lazyQueue() {
Map<String, Object> params = new HashMap();
params.put("x-queue-mode", "lazy");
return new Queue("lazy.queue", true, true, false, params);
// 或使用下面更方便的方式
return QueueBuilder
.durable("lazy.queue")
// 宣告為惰性佇列
.lazy()
.build();
}
/**
* 惰性佇列:RabbitListener註解的方式 這種就是new一個Map裡面放引數的方式
* @param msg 接收到的訊息
*/
@RabbitListener(queuesToDeclare = @org.springframework.amqp.rabbit.annotation.Queue(
name = "lazy.queue",
durable = "true",
arguments = @Argument(name = "x-queue-mode", value = "lazy")
))
public void lazyQueue(String msg) {
System.out.println("消費者接收到了訊息:" + msg);
}
RabbitMQ如何保證訊息的有序性?
RabbitMQ是佇列儲存,天然具備先進先出的特點,只要訊息的傳送是有序的,那麼理論上接收也是有序的
不過當一個佇列繫結了多個消費者時,可能出現訊息輪詢投遞給消費者的情況,而消費者的處理順序就無法保證了
因此,要保證訊息的有序性,需要做到下面幾點:
- 保證訊息傳送的有序性
- 保證一組有序的訊息都傳送到同一個佇列
- 保證一個佇列只包含一個消費者
如何防止MQ訊息被重複消費?
訊息重複消費的原因多種多樣,不可避免。所以只能從消費者端入手,只要能保證訊息處理的冪等性就可以確保訊息不被重複消費
而冪等性的保證又有很多方案:
-
給每一條訊息都新增一個唯一id,在本地記錄訊息表及訊息狀態,處理訊息時基於資料庫表的id唯一性做判斷
-
同樣是記錄訊息表,利用訊息狀態列位實現基於樂觀鎖的判斷,保證冪等
-
基於業務本身的冪等性。比如根據id的刪除、查詢業務天生冪等;新增、修改等業務可以考慮基於資料庫id唯一性、或者樂觀鎖機制確保冪等。本質與訊息表方案類似
如何保證RabbitMQ的高可用?
要實現RabbitMQ的高可用無外乎下面兩點:
- 做好交換機、佇列、訊息的持久化
- 搭建RabbitMQ的映象叢集,做好主從備份。當然也可以使用仲裁佇列代替映象叢集
ElasticSearch 分散式搜尋引擎
此處只是濃縮內容,沒基礎的可能看不懂,全系列知識去下列連結:
- 基礎理論和DSL語法(可看可不看):https://www.cnblogs.com/xiegongzi/p/15684307.html
- Java操作:https://www.cnblogs.com/xiegongzi/p/15690534.html
- 續篇:https://www.cnblogs.com/xiegongzi/p/15770665.html
關係型資料庫與ES的對應關係
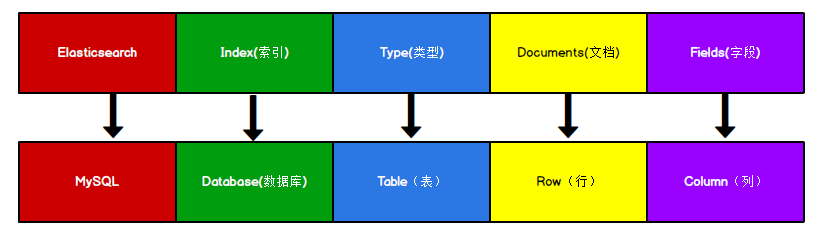
注:ES 7.x之後,type已經被淘汰了,其他的沒變
基礎理論
正向索引和倒排索引
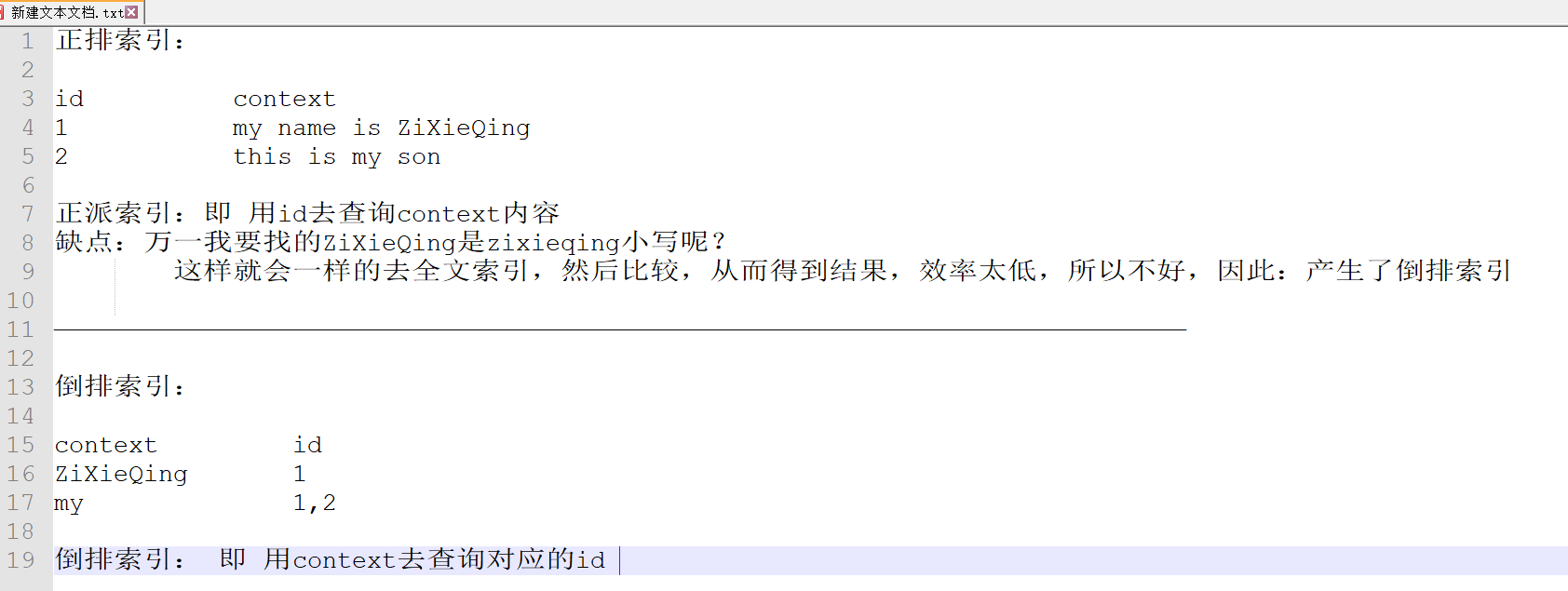
elasticsearch使用的就是倒排索引
倒排索引中又有3個小東西:
- 詞條:是指索引中的最小儲存或查詢單元。這個其實很好理解,白話文來講就是:字或者片語,英文就是一個單詞,中文就是字或片語嘛,比如:你要查詢的內容中具備含義的某一個字或片語,這就是詞條唄,如:我是中國人,就可以分為:我、是、中國人、中國、國人這樣的幾個詞條
- 詞典:就是詞條的集合嘛。字或者片語組成的內容唄
- 倒排表:就是指 關鍵字 / 關鍵詞 在索引中的位置。 有點類似於陣列,你查詢陣列中某個元素的位置,但是區別很大啊,我只是為了好理解,所以才這麼舉例子的
type 型別
這玩意兒就相當於關係型資料庫中的表,注意啊:關係型中表是在資料庫下,那麼ES中也相應的 型別是在索引之下建立的
表是個什麼玩意呢?行和列嘛,這行和列有多少?N多行和N多列嘛,所以:ES中的型別也一樣,可以定義N種型別。
同時:每張表要儲存的資料都不一樣吧,所以表是用來幹嘛的?分類 / 分割區嘛,所以ES中的型別的作用也來了:就是為了分類嘛。
另外:關係型中可以定義N張表,那麼在ES中,也可以定義N種型別
因此:ES中的型別類似於關係型中的表,作用:為了分類 / 分割區,同時:可以定義N種型別,但是:型別必須是在索引之下建立的( 是索引的邏輯體現嘛 )
但是:不同版本的ES,型別也發生了變化,上面的解讀不是全通用的

field 欄位
這也就類似於關係型中的列。 對檔案資料根據不同屬性(列欄位)進行的分類標識
欄位常見的簡單型別:注意:id的型別在ES中id是字串,這點需要注意
- 字串:text(可分詞的文字)、keyword(精確值,例如:品牌、國家、ip地址)
- 數值:long、integer、short、byte、double、float、
- 布林:boolean
- 日期:date
- 物件:object
- 地圖型別:geo_point 和 geo_shape
- geo_point:有緯度(latitude) 和經度(longitude)確定的一個點,如:「32.54325453, 120.453254」
- geo_shape:有多個geo_point組成的複雜集合圖形,如一條直線 「LINESTRING (-77.03653 38.897676, -77.009051 38.889939)」
- 自動補全型別:completion
注意:沒有陣列型別,但是可以實現出陣列,因為每種型別可以有「多個值」,即可實現出類似於陣列型別,例如下面的格式:
{
"age": 21, // Integer型別
"weight": 52.1, // float型別
"isMarried": false, // boolean型別
"info": "這就是一個屌絲女", // 字串型別 可能為test,也可能為keyword 需要看mapping定義時對檔案的約束時什麼
"email": "[email protected]", // 字串型別 可能為test,也可能為keyword 需要看mapping定義時對檔案的約束時什麼
"score": [99.1, 99.5, 98.9], // 類似陣列 就是利用了一個型別可以有多個值
"name": { // object物件型別
"firstName": "紫",
"lastName": "邪情"
}
}
還有一個欄位的拷貝: 可以使用copy_to屬性將當前欄位拷貝到指定欄位
使用場景: 多個欄位放在一起搜尋的時候
注意: 定義的要拷貝的那個欄位在ES中看不到,但是確實是存在的,就像個虛擬的一樣
// 定義了一個欄位
"all": {
"type": "text",
"analyzer": "ik_max_word"
}
"name": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all" // 將當前欄位 name 拷貝到 all欄位中去
}
document 檔案
這玩意兒類似於關係型中的行。 一個檔案是一個可被索引的基礎資訊單元,也就是一條資料嘛
即:用來搜尋的資料,其中的每一條資料就是一個檔案。例如一個網頁、一個商品資訊
新增檔案:
// 這是kibana中進行的操作,要是使用如postman風格的東西發請求,則在 /索引庫名/_doc/檔案id 前加上es主機地址即可
POST /索引庫名/_doc/檔案id // 指定了檔案id,若不指定則es自動建立
{
"欄位1": "值1",
"欄位2": "值2",
"欄位3": {
"子屬性1": "值3",
"子屬性2": "值4"
},
// ...
}
檢視指定檔案id的檔案:
GET /{索引庫名稱}/_doc/{id}
刪除指定檔案id的檔案:
DELETE /{索引庫名}/_doc/id值
修改檔案:有兩種方式
- 全量修改:直接覆蓋原來的檔案。其本質是:
- 根據指定的id刪除檔案
- 新增一個相同id的檔案
- 注意:如果根據id刪除時,id不存在,第二步的新增也會執行,也就從修改變成了新增操作了
// 語法格式
PUT /{索引庫名}/_doc/檔案id
{
"欄位1": "值1",
"欄位2": "值2",
// ... 略
}
- 增量/區域性修改:是隻修改指定id匹配的檔案中的部分欄位
// 語法格式
POST /{索引庫名}/_update/檔案id
{
"doc": {
"欄位名": "新的值",
}
}
檔案分析
試想:我們在瀏覽器中,輸入一條資訊,如:搜尋「部落格園紫邪情」,為什麼連「部落格園也搜尋出來了?我要的是不是這個結果澀」
這就是全文檢索,就是ES乾的事情( 過濾資料、檢索嘛 ),但是:它做了哪些操作呢?
在ES中有一個檔案分析的過程,檔案分析的過程也很簡單:
-
將文字拆成適合於倒排索引的獨立的詞條,然後把這些詞條統一變為一個標準格式,從而使文字具有「可搜尋性」。
而這個檔案分析的過程在ES是由一個叫做「分析器 analyzer」的東西來做的,這個分析器裡面做了三個步驟
- 字元過濾器:就是用來處理一些字元的嘛,像什麼將 & 變為 and 啊、去掉HTML元素啊之類的。它是文字字串在經過分詞之前的一個步驟,文字字串是按文字順序經過每個字串過濾器從而處理字串
- 分詞器:見名知意,就是用來分詞的,也就是將字串拆分成詞條( 字 / 片語 ),這一步和Java中String的split()一樣的,通過指定的要求,把內容進行拆分,如:空格、標點符號
- Token過濾器:這個玩意兒的作用就是 詞條經過每個Token過濾器,從而對資料再次進行篩選,如:字母大寫變小寫、去掉一些不重要的詞條內容、新增一些詞條(如:同義詞)
內建分析器
standard 標準分析器
這是根據Unicode定義的單詞邊界來劃分文字,將字母轉成小寫,去掉大部分的標點符號,從而得到的各種語言的最常用文字選擇,另外:這是ES的預設分析器
simple 簡單分析器
按非字母的字元分詞,例如:數位、標點符號、特殊字元等,會去掉非字母的詞,大寫字母統一轉換成小寫
whitespace 空格分析器
是簡單按照空格進行分詞,相當於按照空格split了一下,大寫字母不會轉換成小寫
stop 去詞分析器
會去掉無意義的詞
此無意義是指語氣助詞等修飾性詞,補語文:語氣詞是疑問語氣、祈使語氣、感嘆語氣、肯定語氣和停頓語氣。例如:the、a、an 、this等,大寫字母統一轉換成小寫
keyword 不拆分分析器
就是將整個文字當作一個詞
檔案搜尋
不可變的倒排索引
以前的全文檢索是將整個檔案集合弄成一個倒排索引,然後存入磁碟中,當要建立新的索引時,只要新的索引準備就緒之後,舊的索引就會被替換掉,這樣最近的檔案資料變化就可以被檢索到
而索引一旦被存入到磁碟就是不可變的( 永遠都可以修改 ),而這樣做有如下的好處:
- 只要索引被讀入到記憶體中了,由於其不變性,所以就會一直留在記憶體中( 只要空間足夠 ),從而當我們做「讀操作」時,請求就會進入記憶體中去,而不會去磁碟中,這樣就減小開銷,提高效率了
- 索引放到記憶體中之後,是可以進行壓縮的,這樣做之後,也就可以節約空間了
- 放到記憶體中後,是不需要鎖的,如果自己的索引是長期不用更新的,那麼就不用怕多程序同時修改它的情況了
當然:這種不可變的倒排索引有好處,那就肯定有壞處了
- 不可變,不可修改嘛,這就是最大的壞處,當要重定一個索引能夠被檢索時,就需要重新把整個索引構建一下,這樣的話,就會導致索引的資料量很大( 資料量大小有限制了 ),同時要更新索引,那麼這頻率就會降低了
- 這就好比是什麼呢?關係型中的表,一張大表檢索資料、更新資料效率高不高?肯定不高,所以延伸出了:可變索引
可變的倒排索引
又想保留不可變性,又想能夠實現倒排索引的更新,咋辦?
- 就搞出了
補充索引,所謂的補充索引:有點類似於紀錄檔這個玩意兒,就是重建一個索引,然後用來記錄最近指定一段時間內的索引中檔案資料的更新。這樣更新的索引資料就記錄在補充索引中了,然後檢索資料時,直接找補充索引即可,這樣檢索時不再重寫整個倒排索引了,這有點類似於關係型中的拆表,大表拆小表嘛,但是啊:每一份補充索引都是一份單獨的索引啊,這又和分片很像,可是:查詢時是對這些補充索引進行輪詢,然後再對結果進行合併,從而得到最終的結果,這和前面說過的讀流程中說明的協調節點掛上鉤了
這裡還需要了解一個配套的按段搜尋,玩過 Lucene 的可能聽過。按段,每段也就可以理解為:補充索引,它的流程其實也很簡單:
- 新檔案被收集到記憶體索引快取
- 不時地提交快取
- 一個新的段,一個追加的倒排索引,被寫入磁碟
- 一個新的包含新段名字的提交點被寫入磁碟
- 磁碟進行同步,所有在檔案系統快取中等待的寫入都重新整理到磁碟,以確保它們被寫入物理檔案
- 記憶體快取被清空,等待接收新的檔案
- 新的段被開啟,讓它包含的檔案可見,以被搜尋
一樣的,段在查詢的時候,也是輪詢的啊,然後把查詢結果合併從而得到的最終結果
另外就是涉及到刪除的事情,段本身也是不可變的, 既不能把檔案從舊的段中移除,也不能修改舊的段來進行檔案的更新,而刪除是因為:是段在每個提交點時有一個.del檔案,這個檔案就是一個刪除的標誌檔案,要刪除哪些資料,就對該資料做了一個標記,從而下一次查詢的時候就過濾掉被標記的這些段,從而就無法查到了,這叫邏輯刪除(當然:這就會導致倒排索引越積越多,再查詢時。輪詢來查資料也會影響效率),所以也有物理刪除,它是把段進行合併,這樣就捨棄掉被刪除標記的段了,從而最後重新整理到磁碟中去的就是最新的資料(就是去掉刪除之後的 ,別忘了前面整的段的流程啊,不是白寫的)
mapping 對映
指的就是:結構資訊 / 限制條件
還是對照關係型來看,在關係型中表有哪些欄位、該欄位是否為null、預設值是什麼........諸如此的限制條件,所以ES中的對映就是:資料的使用規則設定
mapping是對索引庫中檔案的約束,常見的mapping屬性包括:
- index:是否建立索引,預設為true
- analyzer:使用哪種分詞器
- properties:該欄位的子欄位
更多型別去官網檢視:https://www.elastic.co/guide/en/elasticsearch/reference/8.8/mapping-params.html
建立索引庫,最關鍵的是mapping對映,而mapping對映要考慮的資訊包括:
- 欄位名
- 欄位資料型別
- 是否參與搜尋
- 是否需要分詞
- 如果分詞,分詞器是什麼?
其中:
- 欄位名、欄位資料型別,可以參考資料表結構的名稱和型別
- 是否參與搜尋要分析業務來判斷,例如圖片地址,就無需參與搜尋
- 是否分詞呢要看內容,內容如果是一個整體就無需分詞,反之則要分詞
- 分詞器,我們可以統一使用ik_max_word
{
"mappings": {
"properties": { // 子欄位
"欄位名1":{ // 定義欄位名
"type": "text", // 該欄位的型別
"analyzer": "ik_smart" // 該欄位採用的分詞器型別 這是ik分詞器中的,一種為ik_smart 一種為ik_max_word,具體看一開始給的系列知識連結
},
"欄位名2":{
"type": "keyword",
"index": "false" // 該欄位是否可以被索引,預設值為trus,即:不想被搜尋的欄位就可以顯示宣告為false
},
"欄位名3":{
"properties": {
"子欄位": {
"type": "keyword"
}
}
},
// ...略
}
}
}
建立索引庫的同時,建立資料結構約束:
// 格式
PUT /索引庫名稱 // 建立索引庫
{ // 同時建立資料結構約束資訊
"mappings": {
"properties": {
"欄位名":{
"type": "text",
"analyzer": "ik_smart"
},
"欄位名2":{
"type": "keyword",
"index": "false"
},
"欄位名3":{
"properties": {
"子欄位": {
"type": "keyword"
}
}
},
// ...略
}
}
}
// 範例
PUT /user
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": "falsae"
},
"name":{
"properties": {
"firstName": {
"type": "keyword"
},
"lastName": {
"type": "keyword"
}
}
},
// ... 略
}
}
}
index 索引庫
所謂索引:類似於關係型資料庫中的資料庫
但是索引這個東西在ES中又有點東西,它的作用和關係型資料庫中的索引是一樣的,相當於門牌號,一個標識,旨在:提高查詢效率,當然,不是說只針對查詢,CRUD都可以弄索引,所以這麼一說ES中的索引和關係型資料庫中的索引是一樣的,就不太類似於關係型中的資料庫了,此言差矣!在關係型中有了資料庫,才有表結構( 行、列、型別...... )
而在ES中就是有了索引,才有doc、field.....,因此:這就類似於關係型中的資料庫,只是作用和關係型中的索引一樣罷了
因此:ES中索引類似於關係型中的資料庫,作用:類似於關係型中的索引,旨在:提高查詢效率,當然:在一個叢集中可以定義N多個索引,同時:索引名字必須採用全小寫字母
當然:也別忘了有一個倒排索引
- 關係型資料庫通過增加一個B+樹索引到指定的列上,以便提升資料檢索速度。而ElasticSearch 使用了一個叫做
倒排索引的結構來達到相同的目的
建立索引: 相當於在建立資料庫
# 在kibana中進行的操作
PUT /索引庫名稱
# 在postman之類的地方建立
http://ip:port/indexName 如:http://127.0.0.1:9200/createIndex 請求方式:put
注:put請求具有冪等性,冪等性指的是: 不管進行多少次重複操作,都是實現相同的結果。可以採用把下面的請求多執行幾次,然後:觀察返回的結果
具有冪等性的有:put、delete、get
檢視索引庫:
# 檢視指定的索引庫
GET /索引庫名
# 檢視所有的索引庫
GET /_cat/indices?v
修改索引庫:
- 倒排索引結構雖然不復雜,但是一旦資料結構改變(比如改變了分詞器),就需要重新建立倒排索引,這簡直是災難。因此索引庫一旦建立,無法修改mapping。
雖然無法修改mapping中已有的欄位,但是卻允許新增新的欄位到mapping中,因為不會對倒排索引產生影響。
語法說明:
PUT /索引庫名/_mapping
{
"properties": {
"新欄位名":{
"type": "integer"
// ............
}
}
}
刪除索引庫:
DELETE /索引庫名
分詞器
內建分詞器
1、標準分析器 standard: 根據Unicode定義的單詞邊界來劃分文字,將字母轉成小寫,去掉大部分的標點符號,從而得到的各種語言的最常用文字選擇,另外:這是ES的預設分析器
2、簡單分析器 simple: 按非字母的字元分詞,例如:數位、標點符號、特殊字元等,會去掉非字母的詞,大寫字母統一轉換成小寫
3、空格分析器 whitespace: 簡單按照空格進行分詞,相當於按照空格split了一下,大寫字母不會轉換成小寫
4、去詞分析器 stop:會去掉無意義的詞(此無意義是指語氣助詞等修飾性詞,補語文:語氣詞是疑問語氣、祈使語氣、感嘆語氣、肯定語氣和停頓語氣),例如:the、a、an 、this等,大寫字母統一轉換成小寫
5、不拆分分析器 keyword: 就是將整個文字當作一個詞
IK分詞器
官網:https://github.com/medcl/elasticsearch-analysis-ik/releases
步驟:
- 下載ik分詞器。注意:版本對應問題,版本關係在這裡檢視 https://github.com/medcl/elasticsearch-analysis-ik
- 上傳解壓,放到es的plugins外掛目錄
- 重啟es
此種分詞器的分詞器型別:
- ik_max_word 是細粒度的分詞,就是:窮盡詞彙的各種組成。如4個字是一個詞,繼續看3個字是不是一個詞,再看2個字又是不是一個詞,以此窮盡..........
- ik_smart 是粗粒度的分詞。如:那個叼毛也是一個程式設計師,就先看整句話是不是一個詞(length = 11),不是的話,就看length-1是不是一個詞.....,如果某個長度是一個詞了,那麼這長度內的內容就不看了,繼續看其他的是不是一個詞,如「那個"是一個詞,那就看後面的內容,繼續length、length-1、length-2........
在ik分詞器的 config/IKAnalyzer.cfg.xml 中可以設定擴充套件詞典和停用詞典(即:敏感詞)
拼音分詞器
官網:https://github.com/medcl/elasticsearch-analysis-pinyin
安裝和IK分詞器一樣
- 下載
- 上傳解壓
- 重啟es
測試拼音分詞器
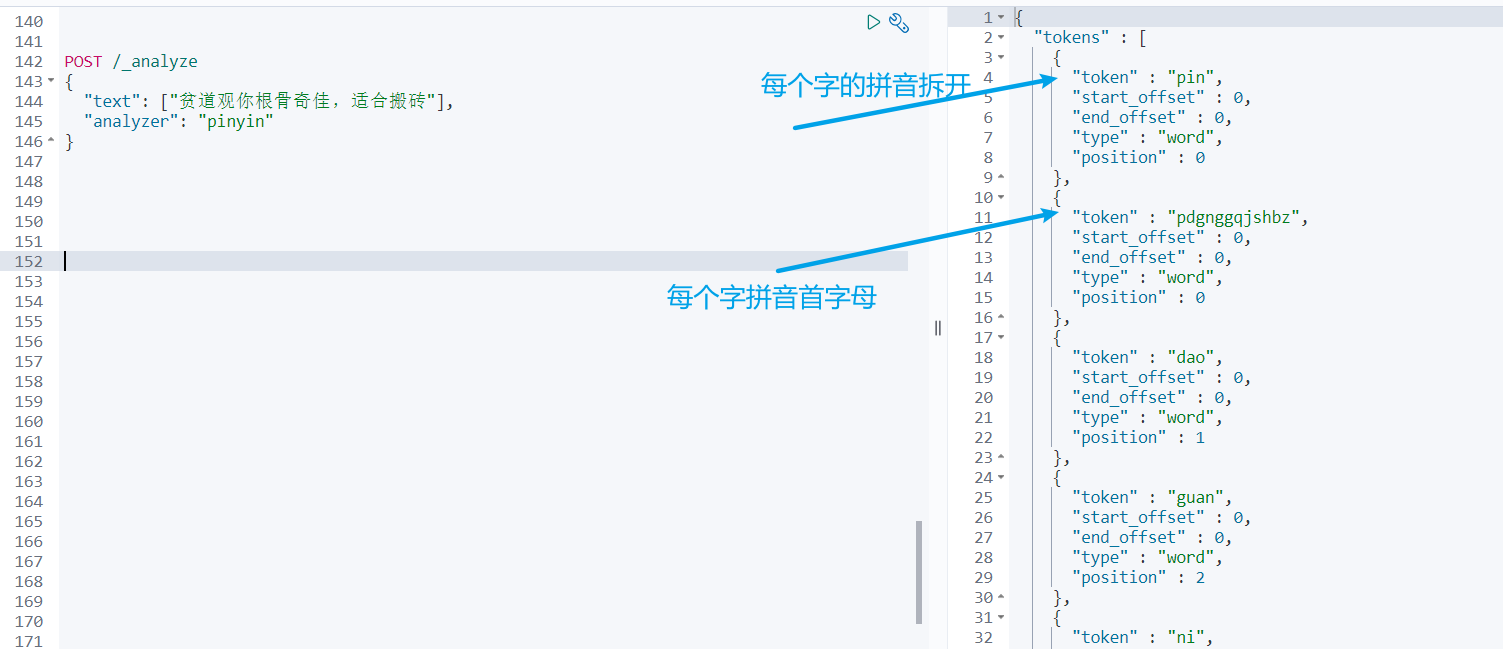
由上可知,伴隨2個問題:
- 只進行了拼音分詞,漢字分詞不見了
- 只採用拼音分詞會出現一種情況:同音字,如「獅子」,「蝨子」,這樣的話明明想搜尋的是「獅子」,結果「蝨子」也出來了,所以這種搜尋效果不好
因此:需要客製化,讓漢字分詞出現,同時搜尋時使用的漢字是什麼就是什麼,別弄同音字
要完成上面的需求,就需要結合檔案分析的過程
在ES中有一個檔案分析的過程,檔案分析的過程也很簡單:
- 將文字拆成適合於倒排索引的獨立的詞條,然後把這些詞條統一變為一個標準格式,從而使文字具有「可搜尋性」。 而這個檔案分析的過程在ES是由一個叫做「分析器 analyzer」的東西來做的,這個分析器裡面做了三個步驟
- 字元過濾器(character filters):就是用來處理一些字元的嘛,像什麼將 & 變為 and 啊、去掉HTML元素啊之類的。它是文字字串在經過分詞之前的一個步驟,文字字串是按文字順序經過每個字串過濾器從而處理字串
- 分詞器(tokenizer):見名知意,就是用來分詞的,也就是將字串拆分成詞條( 字 / 片語 ),這一步和Java中String的split()一樣的,通過指定的要求,把內容進行拆分,如:空格、標點符號
- Token過濾器(tokenizer filter):這個玩意兒的作用就是 詞條經過每個Token過濾器,從而對資料再次進行篩選,如:字母大寫變小寫、去掉一些不重要的詞條內容、新增一些詞條( 如:同義詞 )
舉例理解:character filters、tokenizer、tokenizer filter)
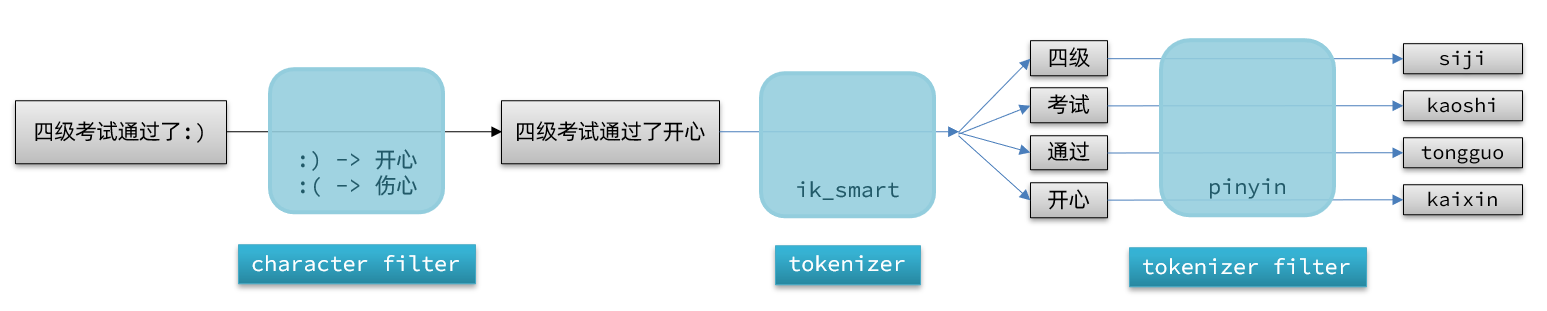
因此現在自定義分詞器就變成如下的樣子:
注: 是建立索引時自定義分詞器,即自定義的分詞器只對當前索引庫有效
PUT /test
{
"settings": {
"analysis": {
"analyzer": { // 自定義分詞器
"my_analyzer": { // 分詞器名稱
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": { // 自定義tokenizer filter
"py": { // 過濾器名稱
"type": "pinyin", // 過濾器型別,這裡是pinyin,這些引數都在 拼音分詞器官網有
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer", // 指明在索引時使用的分詞器
"search_analyzer": "ik_smart" // 指明搜尋時使用的分詞器
}
}
}
}
使用自定義分詞器:
shards 分片
這玩意兒就類似於關係型中的分表
在關係型中如果一個表的資料太大了,查詢效率很低、響應很慢,所以就會採用大表拆小表,如:使用者表,不可能和使用者相關的啥子東西都放在一張表吧,這不是找事嗎?因此:需要分表
相應的在ES中,也需要像上面這麼幹,如:儲存100億檔案資料的索引,在單節點中沒辦法儲存這麼多的檔案資料,所以需要進行切割,就是將這整個100億檔案資料切幾刀,然後每一刀切分出來的每份資料就是一個分片 ( 索引 ),然後將切開的每份資料單獨放在一個節點中,這樣切開的所有檔案資料合在一起就是一份完整的100億資料,因此:這個的作用也是為了提高效率
建立一個索引的時候,可以指定想要的分片的數量。每個分片本身也是一個功能完善並且獨立的「索引」,這個「索引」可以被放置到叢集中的任何節點上
分片有兩方面的原因:
- 允許水平分割 / 擴充套件內容容量,水平擴充,負載均衡嘛
- 允許在分片之上進行分散式的、並行的操作,進而提高效能 / 吞吐量
注意: 當 Elasticsearch 在索引中搜尋的時候, 它傳送查詢到每一個屬於索引的分片,然後合併每個分片的結果到一個全域性的結果集中
replicas 副本
這不是遊戲中的刷副本的那個副本啊。是指:分片的複製品
失敗是常有的事嘛,所以:在ES中也會失敗呀,可能因為網路、也可能因此其他鬼原因就導致失敗了,此時不就需要一種故障轉移機制嗎,也就是 建立分片的一份或多份拷貝,這些拷貝就叫做複製分片( 副本 )
副本( 複製分片 )之所以重要,有兩個原因:
- 在分片 / 節點失敗的情況下,提供了高可用性。因為這個原因,複製分片不與原 / 主( original / primary )分片置於同一節點上是非常重要的
- 擴充套件搜尋量 / 吞吐量,因為搜尋可以在所有的副本上並行執行
多說一嘴,分片和副本這兩個不就是配套了嗎,分片是切割資料,放在不同的節點中( 服務中 );副本是以防服務宕掉了,從而丟失資料,進而把分片拷貝了任意份。這個像什麼?不就是主備嗎( 我說的是主備,不是主從啊 ,這兩個有區別的,主從是主機具有寫操作,從機具有讀操作;而主備是主機具有讀寫操作,而備機只有讀操作,不一樣的啊 )
有個細節需要注意,在ES中,分片和副本不是在同一臺伺服器中,是分開的,如:分片P1在節點1中,那麼副本R1就不能在節點1中,而是其他服務中,不然服務宕掉了,那資料不就全丟了嗎
allocation 分配
前面講到了分片和副本,對照Redis中的主備來看了,那麼對照Redis的主從來看呢?主機宕掉了怎麼重新選一個主機?Redis中是加了一個哨兵模式,從而達到的。那麼在ES中哪個是主節點、哪個是從節點、分片怎麼去分的?就是利用了分配
所謂的分配是指: 將分片分配給某個節點的過程,包括分配主分片或者副本。如果是副本,還包含從主分片複製資料的過程。注意:這個過程是由 master 節點完成的,和Redis還是有點不一樣的啊
既然都說了這麼多,那就再來一個ES的系統架構吧
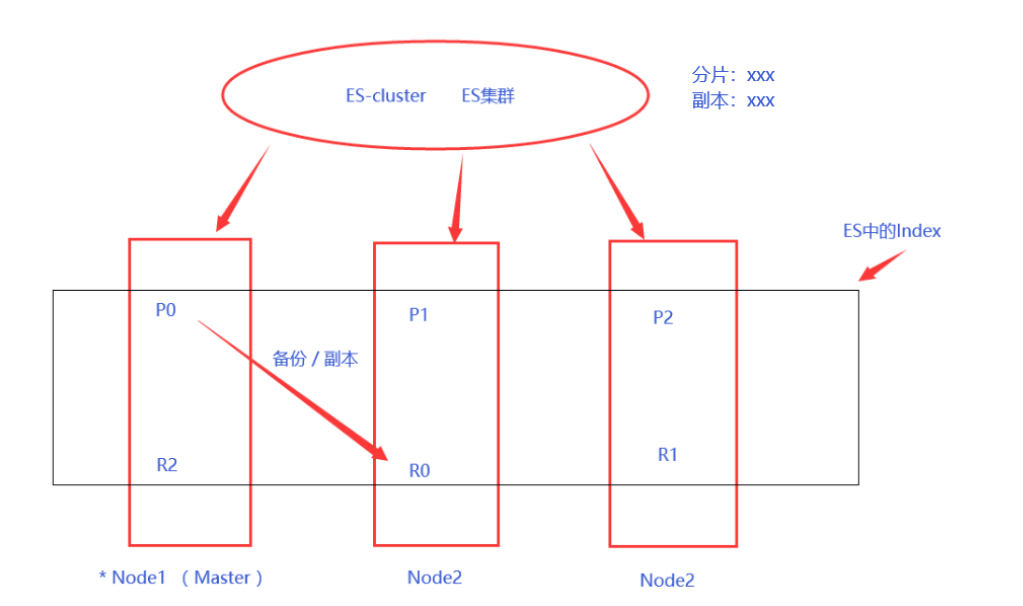
其中,P表示分片、R表示副本
預設情況下,分片和副本都是1,根據需要可以改變
Java操作ES
操作索引
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.admin.indices.flush.FlushRequest;
import org.elasticsearch.action.admin.indices.flush.FlushResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.GetIndexResponse;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import static com.zixieqing.hotel.constant.MappingConstant.mappingContext;
/**
* elasticsearch的索引庫測試
* 規律:esClient.indices().xxx(xxxIndexRequest(IndexName), RequestOptions.DEFAULT)
* 其中 xxx 表示要對索引進行得的操作,如:create、delete、get、flush、exists.............
*
* <p>@author : ZiXieqing</p>
*/
@SpringBootTest
public class o1IndexTest {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://ip:9200")));
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
/**
* 建立索引 並 建立欄位的mapping對映關係
*/
@Test
void createIndexAndMapping() throws IOException {
// 1、建立索引
CreateIndexRequest request = new CreateIndexRequest("indexName");
// 2、建立欄位的mapping對映關係 引數1:編寫的mapping json字串 引數2:採用的文字型別
request.source(mappingContext, XContentType.JSON);
// 3、傳送請求 正式建立索引庫與mapping對映關係
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
// 檢視是否建立成功
System.out.println("response.isAcknowledged() = " + response.isAcknowledged());
// 判斷指定索引庫是否存在
boolean result = client.indices().exists(new GetIndexRequest("indexName"), RequestOptions.DEFAULT);
System.out.println(result ? "hotel索引庫存在" : "hotel索引庫不存在");
}
/**
* 刪除指定索引庫
*/
@Test
void deleteIndexTest() throws IOException {
// 刪除指定的索引庫
AcknowledgedResponse response = client.indices()
.delete(new DeleteIndexRequest("indexName"), RequestOptions.DEFAULT);
// 檢視是否成功
System.out.println("response.isAcknowledged() = " + response.isAcknowledged());
}
// 索引庫一旦建立,則不可修改,但可以新增mapping對映
/**
* 獲取指定索引庫
*/
@Test
void getIndexTest() throws IOException {
// 獲取指定索引
GetIndexResponse response = client.indices()
.get(new GetIndexRequest("indexName"), RequestOptions.DEFAULT);
}
/**
* 重新整理索引庫
*/
@Test
void flushIndexTest() throws IOException {
// 重新整理索引庫
FlushResponse response = client.indices().flush(new FlushRequest("indexName"), RequestOptions.DEFAULT);
// 檢查是否成功
System.out.println("response.getStatus() = " + response.getStatus());
}
}
操作檔案
基本的CRUD操作
import com.alibaba.fastjson.JSON;
import com.zixieqing.hotel.pojo.Hotel;
import com.zixieqing.hotel.pojo.HotelDoc;
import com.zixieqing.hotel.service.IHotelService;
import org.apache.http.HttpHost;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
/**
* elasticsearch的檔案測試
* 規律:esClient.xxx(xxxRequest(IndexName, docId), RequestOptions.DEFAULT)
* 其中 xxx 表示要進行的檔案操作,如:
* index 新增檔案
* delete 刪除指定id檔案
* get 獲取指定id檔案
* update 修改指定id檔案的區域性資料
*
* <p>@author : ZiXieqing</p>
*/
@SpringBootTest
public class o2DocumentTest {
@Autowired
private IHotelService service;
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(
RestClient.builder(HttpHost.create("http://ip:9200"))
);
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
/**
* 新增檔案
*/
@Test
void addDocumentTest() throws IOException {
// 1、準備要新增的檔案json資料
// 通過id去資料庫獲取資料
Hotel hotel = service.getById(36934L);
// 當資料庫中定義的表結構和es中定義的欄位mapping對映不一致時:將從資料庫中獲取的資料轉成 es 中定義的mapping對映關係物件
HotelDoc hotelDoc = new HotelDoc(hotel);
// 2、準備request物件 指定 indexName+檔案id
IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());
// 3、把資料轉成json
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
// 4、發起請求,正式在ES中新增檔案 就是根據資料建立倒排索引,所以這裡呼叫了index()
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
// 5、檢查是否成功 使用下列任何一個API均可 若成功二者返回的結果均是 CREATED
System.out.println("response.getResult() = " + response.getResult());
System.out.println("response.status() = " + response.status());
}
/**
* 根據id刪除指定檔案
*/
@Test
void deleteDocumentTest() throws IOException {
// 1、準備request物件
DeleteRequest request = new DeleteRequest("indexName", "docId");
// 2、發起請求
DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);
// 檢視是否成功 成功則返回 OK
System.out.println("response.status() = " + response.status());
}
/**
* 獲取指定id的檔案
*/
@Test
void getDocumentTest() throws IOException {
// 1、獲取request
GetRequest request = new GetRequest"indexName", "docId");
// 2、發起請求,獲取響應物件
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 3、解析結果
HotelDoc hotelDoc = JSON.parseObject(response.getSourceAsString(), HotelDoc.class);
System.out.println("hotelDoc = " + hotelDoc);
}
/**
* 修改指定索引庫 和 檔案id的區域性欄位資料
* 全量修改是直接刪除指定索引庫下的指定id檔案,然後重新新增相同檔案id的檔案即可
*/
@Test
void updateDocumentTest() throws IOException {
// 1、準備request物件
UpdateRequest request = new UpdateRequest("indexName", "docId");
// 2、要修改那個欄位和值 注:引數是 key, value 形式 中間是 逗號
request.doc(
"price",500
);
// 3、發起請求
UpdateResponse response = client.update(request, RequestOptions.DEFAULT);
// 檢視結果 成功則返回 OK
System.out.println("response.status() = " + response.status());
}
}
批次操作
本質:把請求封裝了而已,從而讓這個請求可以傳遞各種型別引數,如:刪除的、修改的、新增的,這樣就可以搭配for迴圈
package com.zixieqing.hotel;
import com.alibaba.fastjson.JSON;
import com.zixieqing.hotel.pojo.Hotel;
import com.zixieqing.hotel.pojo.HotelDoc;
import com.zixieqing.hotel.service.IHotelService;
import org.apache.http.HttpHost;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.get.MultiGetItemResponse;
import org.elasticsearch.action.get.MultiGetRequest;
import org.elasticsearch.action.get.MultiGetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.List;
/**
* elasticsearch 批次操作檔案測試
* 規律:EsClient.bulk(new BulkRequest()
* .add(xxxRequest("indexName").id().source())
* , RequestOptions.DEFAULT)
* 其中:xxx 表示要進行的操作,如
* index 新增
* delete 刪除
* get 查詢
* update 修改
*
* <p>@author : ZiXieqing</p>
*/
@SpringBootTest(classes = HotelApp.class)
public class o3BulkDocumentTest {
@Autowired
private IHotelService service;
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(
RestClient.builder(HttpHost.create("http://ip:9200"))
);
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
/**
* 批次新增檔案資料到es中
*/
@Test
void bulkAddDocumentTest() throws IOException {
// 1、去資料庫批次查詢資料
List<Hotel> hotels = service.list();
// 2、將資料庫中查詢的資料轉成 es 的mapping需要的物件
BulkRequest request = new BulkRequest();
for (Hotel hotel : hotels) {
HotelDoc hotelDoc = new HotelDoc(hotel);
// 批次新增檔案資料到es中
request.add(new IndexRequest("hotel")
.id(hotelDoc.getId().toString())
.source(JSON.toJSONString(hotelDoc), XContentType.JSON));
}
// 3、發起請求
BulkResponse response = client.bulk(request, RequestOptions.DEFAULT);
// 檢查是否成功 成功則返回OK
System.out.println("response.status() = " + response.status());
}
/**
* 批次刪除es中的檔案資料
*/
@Test
void bulkDeleteDocumentTest() throws IOException {
// 1、準備要刪除資料的id
List<Hotel> hotels = service.list();
// 2、準備request物件
BulkRequest request = new BulkRequest();
for (Hotel hotel : hotels) {
// 根據批次資料id 批次刪除es中的檔案
request.add(new DeleteRequest("hotel").id(hotel.getId().toString()));
}
// 3、發起請求
BulkResponse response = client.bulk(request, RequestOptions.DEFAULT);
// 檢查是否成功 成功則返回 OK
System.out.println("response.status() = " + response.status());
}
// 批次獲取和批次修改是同樣的套路 批次獲取還可以使用 mget 這個API
/**
* mget批次獲取
*/
@Test
void mgetTest() throws IOException {
List<Hotel> hotels = service.list();
// 1、準備request物件
MultiGetRequest request = new MultiGetRequest();
for (Hotel hotel : hotels) {
// 新增get資料 必須指定index 和 檔案id,可以根據不同index查詢
request.add("hotel", hotel.getId().toString());
}
// 2、發起請求,獲取響應
MultiGetResponse responses = client.mget(request, RequestOptions.DEFAULT);
for (MultiGetItemResponse response : responses) {
GetResponse resp = response.getResponse();
// 如果存在則列印響應資訊
if (resp.isExists()) {
System.out.println("獲取到的資料= " +
JSON.toJSONString(resp.getSourceAsString()));
}
}
}
}
近實時搜尋、檔案重新整理、檔案刷寫、檔案合併
ES的最大好處就是實時資料全文檢索
但是:ES這個玩意兒並不是真的實時的,而是近實時 / 準實時
原因就是:ES的資料搜尋是分段搜尋,最新的資料在最新的段中(每一個段又是一個倒排索引),只有最新的段重新整理到磁碟中之後,ES才可以進行資料檢索,這樣的話,磁碟的IO效能就會極大的影響ES的查詢效率,而ES的目的就是為了:快速的、準確的獲取到我們想要的資料,因此:降低資料查詢處理的延遲就very 重要了,而ES對這方面做了什麼操作?
- 就是搞的一主多副的方式(一個主分片,多個副本分片),這雖然就是一句話概括了,但是:裡面的門道卻不是那麼簡單的
首先來看一下主副操作
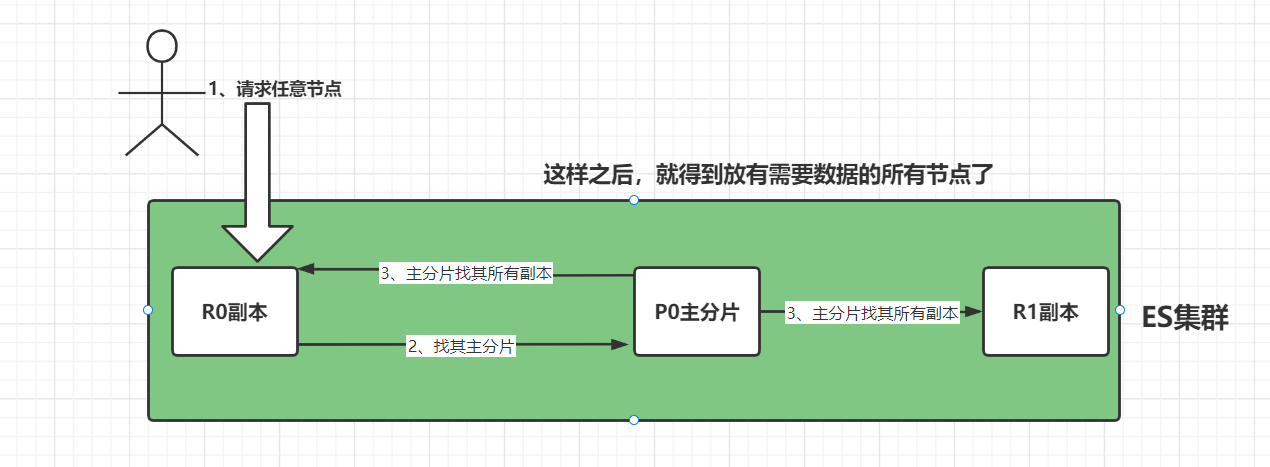
但是:這種去找尋節點的過程想都想得到會造成延時,而延時 = 主分片延時 + 主分片拷貝資料給副本的延時
而且並不是這樣就算完了,前面提到的分段、重新整理到磁碟還沒上堂呢,所以接著看
但是:在flush到磁碟中的時候,萬一斷電了呢?或者其他原因導致出問題了,那最後資料不就沒有flush到磁碟嗎
因此:其實還有一步操作,把資料儲存到另外一個檔案中去

資料放到磁碟中之後,translog中的資料就會清空
同時更新到磁碟之後,使用者就可以進行搜尋資料了
注意:這裡要區分一下,資料庫中是先更新到log中,然後再更新到記憶體中,而ES是反著的,是先更新到Segment(可以直接認為是記憶體,因它本身就在記憶體中),再更新到log中
可是啊,還是有問題,flush刷寫到磁碟是很耗效能的,假如:不斷進行更新呢?這樣不斷進行IO操作,效能好嗎?也不行,因此:繼續改造(沒有什麼是加一層解決不了的,一層不夠,那就再來一層)
加入了快取之後,這快取裡面的資料是可以直接用來搜尋的,這樣就不用等到flush到磁碟之後,才可以搜尋了,這大大的提高了效能,而flush到磁碟,只要時間到了,讓它自個兒慢慢flush就可以了,上面這個流程也叫:持久化 / 持久化變更
寫入和開啟一個新段的輕量的過程叫做refresh。預設情況下每個分片會每秒自動重新整理一次。這就是為什麼我們說 ES是近實時搜尋:檔案的變化並不是立即對搜尋可見,但會在一秒之內變為可見
重新整理是1s以內完成的,這是有時間間隙的,所以會造成:搜尋一個檔案時,可能並沒有搜尋到,因此:解決辦法就是使用refresh API重新整理一下即可
但是這樣也伴隨一個問題:雖然這種從記憶體重新整理到快取中看起來不錯,但是還是有效能開銷的。並不是所有的情況都需要refresh的, 假如:是在索引紀錄檔檔案呢?去refresh幹嘛,浪費效能而已,所以此時:你要的是查詢速度,而不是近實時搜尋,因此:可以通過一個設定來進行改動,從而降低每個索引的重新整理頻率
http://ip:port/index_name/_settings // 請求方式:put
// 請求體內容
{
"settings": {
"refresh_interval": "60s"
}
}
refresh_interval 可以在既存索引上進行動態更新。在生產環境中,當你正在建立一個大的新索引時,可以先關閉自動重新整理,待開始使用該索引時,再把它們調回來。雖然有點麻煩,但是按照ES這個玩意兒來說,確實需要這麼做比較好
// 關閉自動重新整理
http://ip:port/users/_settings // 請求方式:put
// 請求體內容
{
"refresh_interval": -1
}
// 每一秒重新整理
http://ip:port/users/_settings // 請求方式:put
// 請求體內容
{
"refresh_interval": "1s"
}
另外:不斷進行更新就會導致很多的段出現(在記憶體刷寫到磁碟那裡,會造成很多的磁碟檔案 ),因此:在哪裡利用了檔案合併的功能(也就是段的能力,合併檔案,從而讓刷寫到磁碟中的檔案變成一份)
路由計算
路由、路由,這個東西太熟悉了,在Vue中就見過路由router了(用來轉發和重定向的嘛)
那在ES中的路由計算又是怎麼回事?這個主要針對的是ES叢集中的存資料,試想:你知道你存的資料是在哪個節點 / 哪個主分片中嗎( 副本是拷貝的主分片,所以主分片才是核心 )?
當然知道啊,就是那幾個節點中的任意一個嘛。娘希匹~這樣的騷回答好嗎?其實這是由一個公式來決定的
shard = hash(routing) % number_of_primary_shards
routing 是一個任意值,預設是檔案的_id,也可以自定義
number_of_primary_shards 表示主分片的數量
hash() 是一個hash函數
這就解釋了為什麼我們要在建立索引的時候就確定好主分片的數量並且永遠不會改變這個數量:因為如果數量變化了,那麼之前所有路由的值都會無效,檔案也再也找不到了
分片是將索引切分成任意份,然後得到的每一份資料都是一個單獨的索引
分片完成後,我們存資料時,存到哪個節點上,就是通過shard = hash(routing) % number_of_primary_shards得到的
而我們查詢資料時,ES怎麼知道我們要找的資料在哪個節點上,就是通過協調節點做到的,它會去找到和資料相關的所有節點,從而輪詢。所以最後的結果可能是從主分片上得到的,也可能是從副本上得到的,就看最後輪詢到的是哪個節點罷了
分片控制
既然有了存資料的問題,那當然就有取資料的問題了。
請問:在ES叢集中,取資料時,ES怎麼知道去哪個節點中取資料(假如在3節點中,你去1節點中,可以取到嗎?),因此:來了分片控制
其實ES不知道資料在哪個節點中,但是:你自己卻可以取到資料,為什麼?
負載均衡,輪詢嘛。所以這裡有個小知識點,就是:協調節點 coordinating node,我們可以傳送請求到叢集中的任一節點,每個節點都有能力處理任意請求,每個節點都知道叢集中任一檔案位置,這就是分片控制,而我們傳送請求的那個節點就是:協調節點,它會去幫我們找到我們要的資料在哪裡
因此:當傳送請求的時候, 為了擴充套件負載,更好的做法是輪詢叢集中所有的節點
叢集下的資料寫流程
新建、刪除請求都是寫操作, 必須在主分片上面完成之後才能被複制到相關的副本分片
整個流程也很簡單
- 使用者端請求任意節點(協調節點)
- 通過路由計算,協調節點把請求轉向指定的節點
- 轉向的節點的主分片儲存資料
- 主節點再將資料轉發給副本儲存
- 副本給主節點反饋儲存結果
- 主節點給使用者端反饋儲存結果
- 使用者端收到反饋結果

但是:從圖中就可以看出來,這套流程完了,才可以做其他事( 如:才可以去查詢資料 ),那我為什麼不可以非同步呢?就是我只要保證到了哪一個步驟之後,就可以進行資料查詢,所以:這裡有兩個小東西需要了解
在進行寫資料時,我們做個小小的設定,這就是接下來的兩個小節內容
consistency 一致性
這玩意就是為了和讀資料搭配起來,寫入和讀取保證資料的一致性唄
這玩意兒可以設定的值如下:
- one :只要主分片狀態 ok 就允許執行讀操作,這種寫入速度快,但不能保證讀到最新的更改
- all:這是強一致性,必須要主分片和所有副本分片的狀態沒問題才允許執行寫操作
- quorum:這是ES的預設值。即大多數的分片副本狀態沒問題就允許執行寫操作。這是折中的方法,write的時候,W>N/2,即參與寫入操作的節點數W,必須超過副本節點數N的一半,在這個預設情況下,ES是怎麼判定你的分片數量的,就一個公式:
int((primary + number_of_replicas) / 2) + 1
primary 指的是建立的索引數量
number_of_replicas 是指的在索引設定中設定的副本分片數
如果你的索引設定中指定了當前索引擁有3個副本分片
那規定數量的計算結果為:int(1 primary + 3 replicas) / 2) + 1 = 3,
如果此時你只啟動兩個節點,那麼處於活躍狀態的分片副本數量就達不到規定數量,
也因此你將無法索引和刪除任何檔案
- realtime request:就是從translog裡頭讀,可以保證是最新的。但是注意:get是最新的,但是檢索等其他方法不是( 如果需要搜尋出來也是最新的,需要refresh,這個會重新整理該shard但不是整個index,因此如果read請求分發到repliac shard,那麼可能讀到的不是最新的資料,這個時候就需要指定preference=_primary)
timeout 超時
如果沒有足夠的副本分片會發生什麼?Elasticsearch 會等待,希望更多的分片出現。預設情況下,它最多等待 1 分鐘。 如果你需要,你可以使用timeout引數使它更早終止,單位是毫秒,如:100就是100毫秒
新索引預設有1個副本分片,這意味著為滿足規定數量應該需要兩個活動的分片副本。 但是,這些預設的設定會阻止我們在單一節點上做任何事情。為了避免這個問題,要求只有當number_of_replicas 大於1的時候,規定數量才會執行
叢集下的資料讀流程
有寫流程,那肯定也要說一下讀流程嘛,其實和寫流程很像,只是變了那麼一丟丟而已
流程如下:
- 使用者端傳送請求到任意節點(協調節點)
- 這裡不同,此時協調節點會做兩件事:1、通過路由計算得到分片位置,2、還會把當前查詢的資料所在的另外節點也找到(如:副本)
- 為了負載均衡(可能某個節點中的存取量很大嘛,減少一下壓力咯),所以就會對查出來的所有節點做輪詢操作,從而找到想要的資料. 因此:你想要的資料在主節點中有、副本中也有,但是:給你的資料可能是主節點中的,也可能是副本中的 ,看輪詢到的是哪個節點中的
- 節點反饋結果
- 使用者端收到反饋結果
這裡有個注意點: 在檔案( 資料 )被檢索時,已經被索引的檔案可能已經存在於主分片上但是還沒有複製到副本分片。 在這種情況下,副本分片可能會報檔案不存在,但是主分片可能成功返回檔案。 一旦索引請求成功返回給使用者,檔案在主分片和副本分片都是可用的
叢集下的更新操作流程
- 使用者端向node 1傳送更新請求
- 它將請求轉發到主分片所在的node 3
- node 3從主分片檢索檔案,修改_source欄位中的JSON,並且嘗試重新索引主分片的檔案。如果檔案已經被另一個程序修改,它會重試步驟3 ,超過retry_on_conflict次後放棄
- 如果 node 3成功地更新檔案,它將新版本的檔案並行轉發到node 1和 node 2上的副本分片,重新建立索引。一旦所有副本分片都返回成功,node 3向協調節點也返回成功,協調節點向用戶端返回成功
當然:上面有個漏洞,就是萬一在另一個程序修改之後,當前修改程序又去修改了,那要是把原有的資料修改了呢?這不就成關係型資料庫中的「不可重複讀」了嗎?
- 不會的。因為當主分片把更改轉發到副本分片時, 它不會轉發更新請求。 相反,它轉發完整檔案的新版本。注意點:這些更改將會「非同步轉發」到副本分片,並且不能保證它們以相同的順序到達。 如果 ES 僅轉發更改請求,則可能以錯誤的順序應用更改,導致得到的是損壞的檔案
叢集下的批次更新操作流程
這個其實更容易理解,單檔案更新懂了,那多檔案更新就懂了嘛,多檔案就請求拆分唄
所謂的多檔案更新就是:將整個多檔案請求分解成每個分片的檔案請求,並且將這些請求並行轉發到每個參與節點。協調節點一旦收到來自每個節點的應答,就將每個節點的響應收集整理成單個響應,返回給使用者端
原理圖的話:我就在網上偷一張了
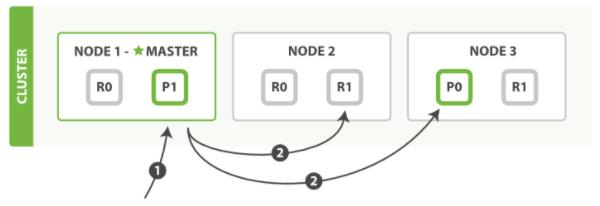
其實mget 和 bulk API的模式就類似於單檔案模式。區別在於協調節點知道每個檔案存在於哪個分片中
用單個 mget 請求取回多個檔案所需的步驟順序:
- 使用者端向 Node 1 傳送 mget 請求
- Node 1為每個分片構建多檔案獲取請求,然後並行轉發這些請求到託管在每個所需的主分片或者副本分片的節點上。一旦收到所有答覆,Node 1 構建響應並將其返回給使用者端。可以對docs陣列中每個檔案設定routing引數
- bulk API, 允許在單個批次請求中執行多個建立、索引、刪除和更新請求
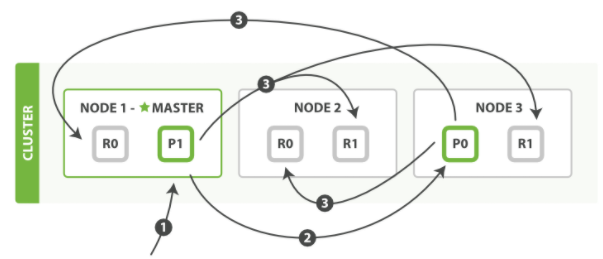
bulk API 按如下步驟順序執行:
- 使用者端向Node 1 傳送 bulk請求
- Node 1為每個節點建立一個批次請求,並將這些請求並行轉發到每個包含主分片的節點主機
- 主分片一個接一個按順序執行每個操作。當每個操作成功時,主分片並行轉發新檔案(或刪除)到副本分片,然後執行下一個操作。一旦所有的副本分片報告所有操作成功,該節點將向協調節點報告成功,協調節點將這些響應收集整理並返回給使用者端
Java進行DSL檔案查詢
其實這種查詢都是套路而已,一看前面玩的DSL查詢的json形式是怎麼寫的,二看你要做的是什麼查詢,然後就是用 queryBuilds 將對應的查詢構建出來,其他都是相同套路了
查詢所有 match all
match all:查詢出所有資料
package com.zixieqing.hotel.dsl_query_document;
import com.zixieqing.hotel.HotelApp;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
/**
* es的dsl檔案查詢之match all查詢所有,也可以稱之為 全量查詢
*
* <p>@author : ZiXieqing</p>
*/
@SpringBootTest
public class o1MatchAll {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(
RestClient.builder(HttpHost.create("http://ip:9200"))
);
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
/**
* 全量查詢:查詢所有資料
*/
@Test
void matchAllTest() throws IOException {
// 1、準備request
SearchRequest request = new SearchRequest("indexName");
// 2、指定哪種查詢/構建DSL語句
request.source().query(QueryBuilders.matchAllQuery());
// 3、發起請求 獲取響應物件
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4、處理響應結果
// 4.1、獲取結果中的Hits
SearchHits searchHits = response.getHits();
// 4.2、獲取Hits中的total
long total = searchHits.getTotalHits().value;
System.out.println("總共獲取了 " + total + " 條資料");
// 4.3、獲取Hits中的hits
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
// 4.3.1、獲取hits中的source 也就是真正的資料,獲取到之後就可以用來處理自己要的邏輯了
String source = hit.getSourceAsString();
System.out.println("source = " + source);
}
}
}
Java程式碼和前面玩的DSL語法的對應情況:
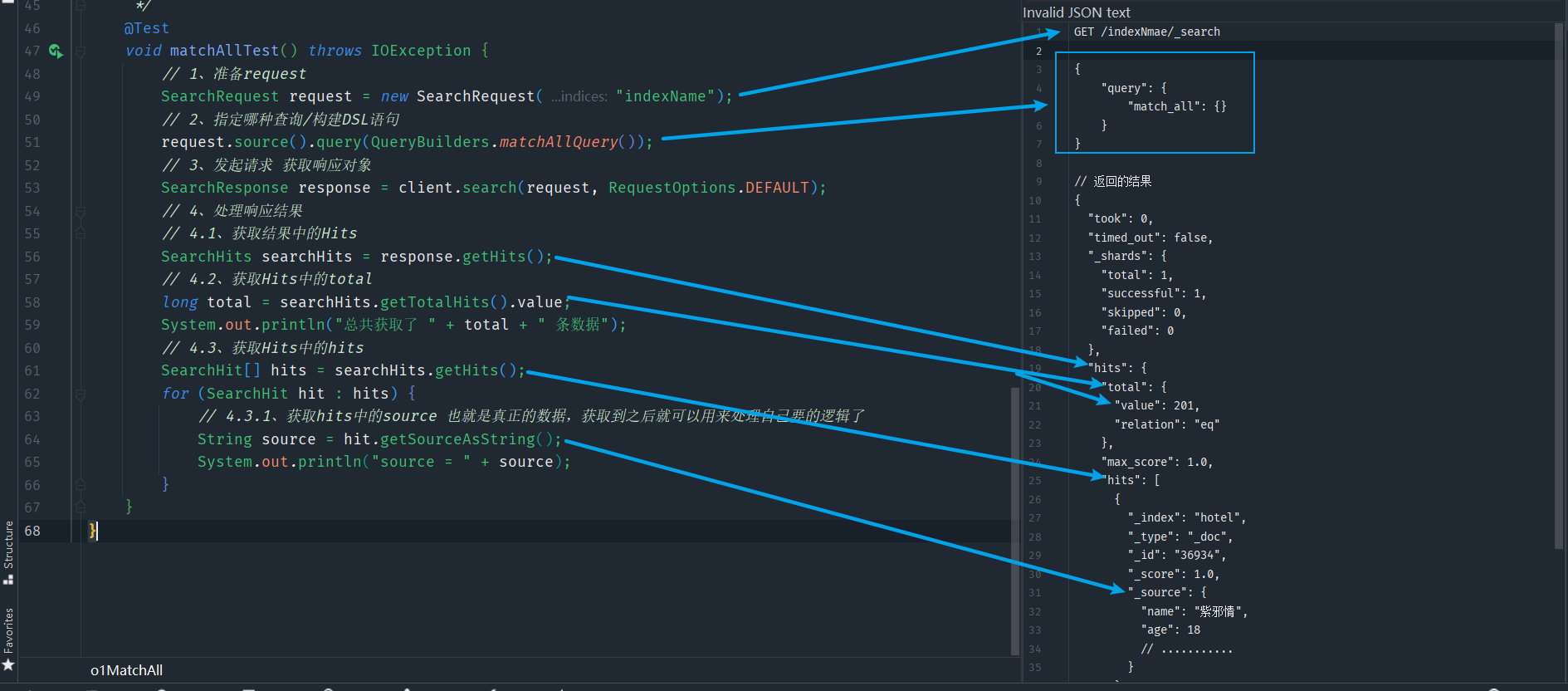
全文檢索查詢
match 單欄位查詢 與 multi match多欄位查詢
下面的程式碼根據情境需要,可自行將響應結果處理進行抽取
package com.zixieqing.hotel.dsl_query_document;
import com.zixieqing.hotel.HotelApp;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
/**
* DLS之全文檢索查詢:利用分詞器對使用者輸入內容分詞,然後去倒排索引庫中匹配
* match_query 單欄位查詢 和 multi_match_query 多欄位查詢
*
* <p>@author : ZiXieqing</p>
*/
@SpringBootTest
public class o2FullTextTest {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(
RestClient.builder(HttpHost.create("http://ip:9200"))
);
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
/**
* match_query 單欄位查詢
*/
@Test
void matchQueryTest() throws IOException {
// 1、準備request
SearchRequest request = new SearchRequest("indexName");
// 2、準備DSL
request.source().query(QueryBuilders.matchQuery("city", "上海"));
// 3、傳送請求,獲取響應物件
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 處理響應結果,後面都是一樣的流程 都是解析json結果而已
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("獲取了 " + total + " 條資料");
for (SearchHit hit : searchHits.getHits()) {
String dataJson = hit.getSourceAsString();
System.out.println("dataJson = " + dataJson);
}
}
/**
* multi match 多欄位查詢 任意一個欄位符合條件就算符合查詢條件
*/
@Test
void multiMatchTest() throws IOException {
SearchRequest request = new SearchRequest("indexName");
request.source().query(QueryBuilders.multiMatchQuery("成人用品", "name", "business"));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 處理響應結果,後面都是一樣的流程 都是解析json結果而已
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("獲取了 " + total + " 條資料");
for (SearchHit hit : searchHits.getHits()) {
String dataJson = hit.getSourceAsString();
System.out.println("dataJson = " + dataJson);
}
}
}
精確查詢
精確查詢:根據精確詞條值查詢資料,一般是查詢keyword、數值、日期、boolean等型別欄位,所以不會對搜尋條件分詞
range 範圍查詢 和 term精準查詢
term:根據詞條精確值查詢
range:根據值的範圍查詢
package com.zixieqing.hotel.dsl_query_document;
import com.zixieqing.hotel.HotelApp;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
/**
* DSL之精確查詢:根據精確詞條值查詢資料,一般是查詢keyword、數值、日期、boolean等型別欄位,所以 不會 對搜尋條件分詞
* range 範圍查詢 和 term 精準查詢
*
* <p>@author : ZiXieqing</p>
*/
@SpringBootTest
public class o3ExactTest {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(
RestClient.builder(HttpHost.create("http://ip:9200"))
);
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
/**
* term 精準查詢 根據詞條精確值查詢
* 和 match 單欄位查詢有區別,term要求內容完全匹配
*/
@Test
void termTest() throws IOException {
SearchRequest request = new SearchRequest("indexName");
request.source().query(QueryBuilders.termQuery("city", "深圳"));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 處理響應結果,後面都是一樣的流程 都是解析json結果而已
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("獲取了 " + total + " 條資料");
for (SearchHit hit : searchHits.getHits()) {
String dataJson = hit.getSourceAsString();
System.out.println("dataJson = " + dataJson);
}
}
/**
* range 範圍查詢
*/
@Test
void rangeTest() throws IOException {
SearchRequest request = new SearchRequest("indexName");
request.source().query(QueryBuilders.rangeQuery("price").lte(250));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 處理響應結果,後面都是一樣的流程 都是解析json結果而已
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("獲取了 " + total + " 條資料");
for (SearchHit hit : searchHits.getHits()) {
String dataJson = hit.getSourceAsString();
System.out.println("dataJson = " + dataJson);
}
}
}
地理座標查詢
geo_distance 附近查詢
package com.zixieqing.hotel.dsl_query_document;
import com.zixieqing.hotel.HotelApp;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
/**
* DSL之地理位置查詢
* geo_bounding_box 矩形範圍查詢 和 geo_distance 附近查詢
*
* <p>@author : ZiXieqing</p>
*/
@SpringBootTest
public class o4GeoTest {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(
RestClient.builder(HttpHost.create("http://ip:9200"))
);
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
/**
* geo_distance 附近查詢
*/
@Test
void geoDistanceTest() throws IOException {
SearchRequest request = new SearchRequest("indexName");
request.source()
.query(QueryBuilders
.geoDistanceQuery("location")
// 方圓多少距離
.distance("15km")
// 圓中心點座標
.point(31.21,121.5)
);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 處理響應結果,後面都是一樣的流程 都是解析json結果而已
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("獲取了 " + total + " 條資料");
for (SearchHit hit : searchHits.getHits()) {
String dataJson = hit.getSourceAsString();
System.out.println("dataJson = " + dataJson);
}
}
}
複合查詢
function_score 算分函數查詢 是差不多的道理
bool 布林查詢之must、should、must not、filter查詢
布林查詢是一個或多個查詢子句的組合,每一個子句就是一個子查詢。子查詢的組合方式有:
- must:必須匹配每個子查詢,類似「與」
- should:選擇性匹配子查詢,類似「或」
- must_not:必須不匹配,不參與算分,類似「非」
- filter:必須匹配,不參與算分
注意: 搜尋時,參與打分的欄位越多,查詢的效能也越差。因此這種多條件查詢時,建議這樣做:
- 搜尋方塊的關鍵字搜尋,是全文檢索查詢,使用must查詢,參與算分
- 其它過濾條件,採用filter查詢。不參與算分
package com.zixieqing.hotel.dsl_query_document;
import com.zixieqing.hotel.HotelApp;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
/**
* DSL之複合查詢:基礎DSL查詢進行組合,從而得到實現更復雜邏輯的複合查詢
* function_score 算分函數查詢
*
* bool 布林查詢
* must 必須匹配每個子查詢 即:and 「與」 參與score算分
* should 選擇性匹配子查詢 即:or 「或」 參與score算分
* must not 必須不匹配 即:「非" 不參與score算分
* filter 必須匹配 即:過濾 不參與score算分
*
* <p>@author : ZiXieqing</p>
*/
@SpringBootTest
public class o5Compound {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(
RestClient.builder(HttpHost.create("http://ip:9200"))
);
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
/**
* bool布林查詢
* must 必須匹配每個子查詢 即:and 「與」 參與score算分
* should 選擇性匹配子查詢 即:or 「或」 參與score算分
* must not 必須不匹配 即:「非" 不參與score算分
* filter 必須匹配 即:過濾 不參與score算分
*/
@Test
void boolTest() throws IOException {
SearchRequest request = new SearchRequest("indexName");
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 構建must 即:and 與
boolQueryBuilder.must(QueryBuilders.termQuery("city", "北京"));
// 構建should 即:or 或
boolQueryBuilder.should(QueryBuilders.multiMatchQuery("速8", "brand", "name"));
// 構建must not 即:非
boolQueryBuilder.mustNot(QueryBuilders.rangeQuery("price").gte(250));
// 構建filter 即:過濾
boolQueryBuilder.filter(QueryBuilders.termQuery("starName", "二鑽"));
request.source().query(boolQueryBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 處理響應結果,後面都是一樣的流程 都是解析json結果而已
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("獲取了 " + total + " 條資料");
for (SearchHit hit : searchHits.getHits()) {
String dataJson = hit.getSourceAsString();
System.out.println("dataJson = " + dataJson);
}
}
}
Java程式碼和前面玩的DSL語法對應關係:
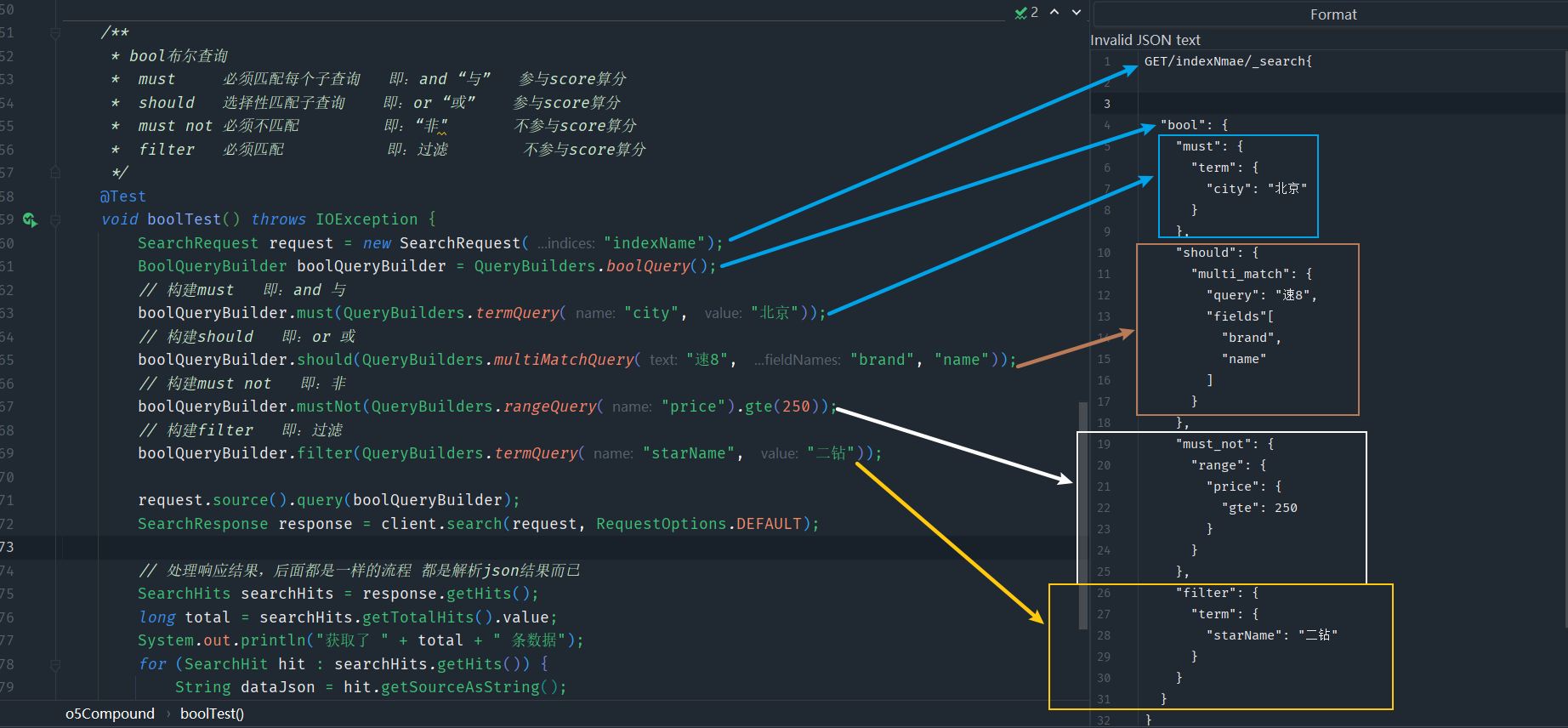
fuzzy 模糊查詢
package com.zixieqing.hotel.dsl_query_document;
import com.zixieqing.hotel.HotelApp;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.unit.Fuzziness;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
/**
* DSL之模糊查詢
*
* <p>@author : ZiXieqing</p>
*/
@SpringBootTest
public class o6FuzzyTest {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(
RestClient.builder(HttpHost.create("http://ip:9200"))
);
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
/**
* 模糊查詢
*/
@Test
void fuzzyTest() throws IOException {
SearchRequest request = new SearchRequest("indexName");
// fuzziness(Fuzziness.ONE) 表示的是:字元誤差數 取值有:zero、one、two、auto
// 誤差數 指的是:fuzzyQuery("name","深圳")這裡面匹配的字元的誤差 可以有幾個字元不一樣,多/少幾個字元?
request.source().query(QueryBuilders
.fuzzyQuery("name", "深圳")
.fuzziness(Fuzziness.ONE)
);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 處理響應結果,後面都是一樣的流程 都是解析json結果而已
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("獲取了 " + total + " 條資料");
for (SearchHit hit : searchHits.getHits()) {
String dataJson = hit.getSourceAsString();
System.out.println("dataJson = " + dataJson);
}
}
}
排序和分頁查詢
package com.zixieqing.hotel.dsl_query_document;
import com.zixieqing.hotel.HotelApp;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.sort.SortOrder;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
/**
* DSL之排序和分頁
*
* <p>@author : ZiXieqing</p>
*/
@SpringBootTest
public class o7SortAndPageTest {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(
RestClient.builder(HttpHost.create("http://ip:9200"))
);
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
/**
* sort 排序查詢
*/
@Test
void sortTest() throws IOException {
SearchRequest request = new SearchRequest("indexName");
request.source()
.query(QueryBuilders.matchAllQuery())
.sort("price", SortOrder.ASC);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 處理響應結果,後面都是一樣的流程 都是解析json結果而已
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("獲取了 " + total + " 條資料");
for (SearchHit hit : searchHits.getHits()) {
String dataJson = hit.getSourceAsString();
System.out.println("dataJson = " + dataJson);
}
}
/**
* page 分頁查詢
*/
@Test
void pageTest() throws IOException {
int page = 2, size = 20;
SearchRequest request = new SearchRequest("indexName");
request.source()
.query(QueryBuilders.matchAllQuery())
.from((page - 1) * size)
.size(size);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 處理響應結果,後面都是一樣的流程 都是解析json結果而已
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("獲取了 " + total + " 條資料");
for (SearchHit hit : searchHits.getHits()) {
String dataJson = hit.getSourceAsString();
System.out.println("dataJson = " + dataJson);
}
}
}
高亮查詢
返回結果處理的邏輯有點區別,但思路都是一樣的
package com.zixieqing.hotel.dsl_query_document;
import com.alibaba.fastjson.JSON;
import com.zixieqing.hotel.HotelApp;
import com.zixieqing.hotel.pojo.HotelDoc;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.util.CollectionUtils;
import java.io.IOException;
import java.util.Map;
/**
* DSL之高亮查詢
*
* <p>@author : ZiXieqing</p>
*/
@SpringBootTest(classes = HotelApp.class)
public class o8HighLightTest {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(
RestClient.builder(HttpHost.create("http://ip:9200"))
);
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
/**
* 高亮查詢
* 返回結果處理不太一樣
*/
@Test
void highLightTest() throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source()
.query(QueryBuilders.matchQuery("city", "北京"))
.highlighter(SearchSourceBuilder
.highlight()
.field("name") // 要高亮的欄位
.preTags("<em>") // 前置HTML標籤 預設就是em
.postTags("</em>") // 後置標籤
.requireFieldMatch(false) // 是否進行查詢欄位和高亮欄位匹配
);
// 發起請求,獲取響應物件
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 處理響應結果
for (SearchHit hit : response.getHits()) {
String originalData = hit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(originalData, HotelDoc.class);
System.out.println("原始資料為:" + originalData);
// 獲取高亮之後的結果
// key 為要進行高亮的欄位,如上為field("name") value 為新增了標籤之後的高亮內容
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (!CollectionUtils.isEmpty(highlightFields)) {
// 根據高亮欄位,獲取對應的高亮內容
HighlightField name = highlightFields.get("name");
if (name != null) {
// 獲取高亮內容 是一個陣列
String highLightStr = name.getFragments()[0].string();
hotelDoc.setName(highLightStr);
}
}
System.out.println("hotelDoc = " + hotelDoc);
}
}
}
程式碼和DSL語法對應關係: request.source() 獲取到的就是返回結果的整個json檔案
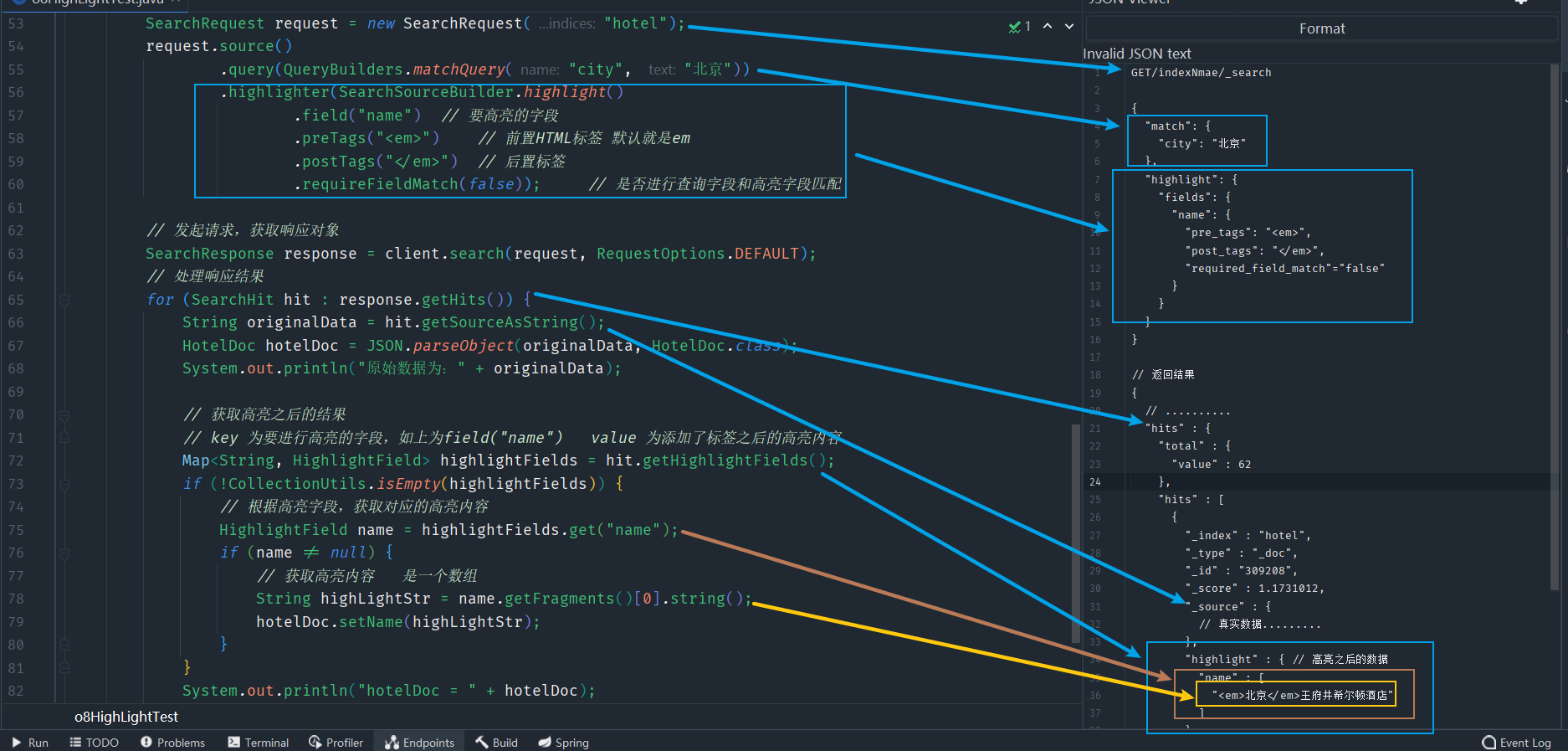
聚合查詢
聚合(aggregations)可以讓我們極其方便地實現對資料的統計、分析、運算
聚合常見的有三類:
-
桶(Bucket)聚合:用來對檔案做分組
- TermAggregation:按照檔案欄位值分組,例如按照品牌值分組、按照國家分組
- Date Histogram:按照日期階梯分組,例如一週為一組,或者一月為一組
-
度量(Metric)聚合:用以計算一些值,比如:最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同時求max、min、avg、sum等
-
管道(pipeline)聚合:其它聚合的結果為基礎做聚合
注意:參加聚合的欄位必須是keyword、日期、數值、布林型別,即:可以說只要不是 text 型別即可,因為text型別會進行分詞,而聚合不能進行分詞
package com.zixieqing.hotel.dsl_query_document;
import com.zixieqing.hotel.HotelApp;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.BucketOrder;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.List;
/**
* 資料聚合 aggregation 可以讓我們極其方便的實現對資料的統計、分析、運算
* 桶(Bucket)聚合:用來對檔案做分組
* TermAggregation:按照檔案欄位值分組,例如按照品牌值分組、按照國家分組
* Date Histogram:按照日期階梯分組,例如一週為一組,或者一月為一組
*
* 度量(Metric)聚合:用以計算一些值,比如:最大值、最小值、平均值等
* Avg:求平均值
* Max:求最大值
* Min:求最小值
* Stats:同時求max、min、avg、sum等
*
* 管道(pipeline)聚合:其它聚合的結果為基礎做聚合
*
* <p>@author : ZiXieqing</p>
*/
@SpringBootTest(classes = HotelApp.class)
public class o9AggregationTest {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(
RestClient.builder(HttpHost.create("http://ip:9200"))
);
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
@Test
void aggregationTest() throws IOException {
// 獲取request
SearchRequest request = new SearchRequest("indexName");
// 組裝DSL
request.source()
.size(0)
.query(QueryBuilders
.rangeQuery("price")
.lte(250)
)
.aggregation(AggregationBuilders
.terms("brandAgg")
.field("brand")
.order(BucketOrder.aggregation("scoreAgg.avg",true))
.subAggregation(AggregationBuilders
.stats("scoreAgg")
.field("score")
)
);
// 傳送請求,獲取響應
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 處理響應結果
System.out.println("response = " + response);
// 獲取全部聚合結果物件 getAggregations
Aggregations aggregations = response.getAggregations();
// 根據聚合名 獲取其聚合物件
Terms brandAgg = aggregations.get("brandAgg");
// 根據聚合型別 獲取對應聚合物件
List<? extends Terms.Bucket> buckets = brandAgg.getBuckets();
for (Terms.Bucket bucket : buckets) {
// 根據key獲取其value
String value = bucket.getKeyAsString();
// 將value根據需求做處理
System.out.println("value = " + value);
}
}
}
請求組裝對應關係:
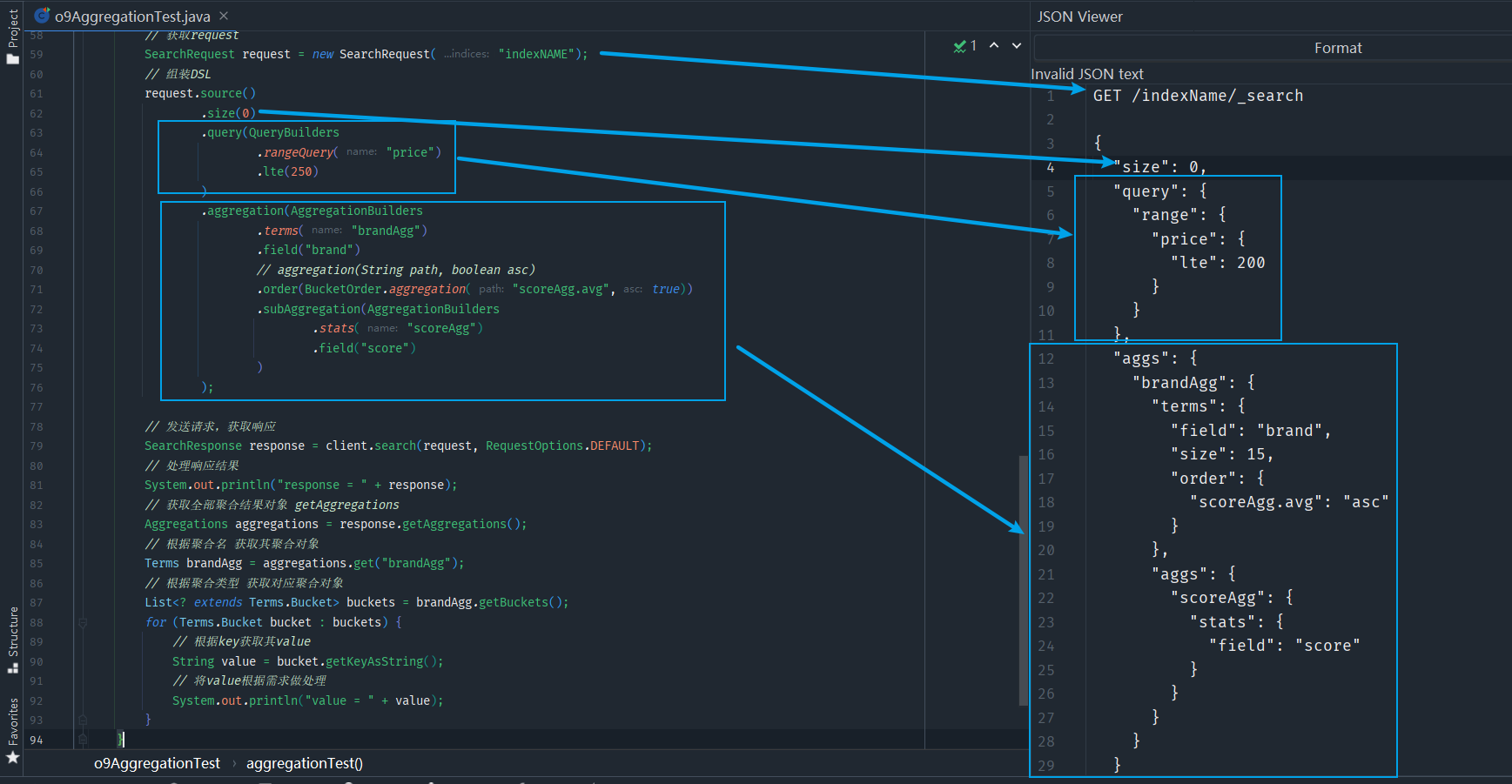
響應結果對應關係:
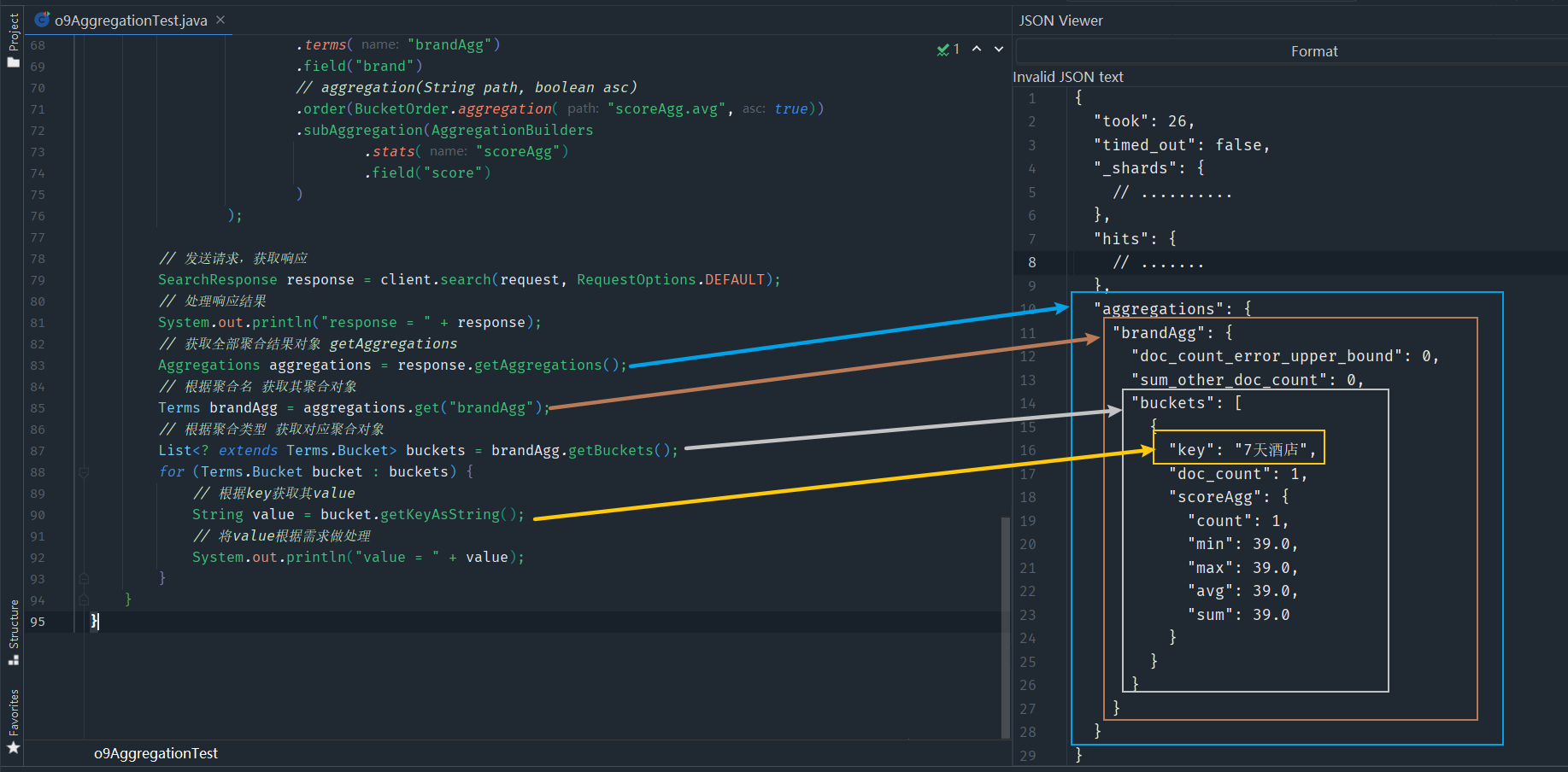
自動補全查詢
package com.zixieqing.hotel.dsl_query_document;
import com.zixieqing.hotel.HotelApp;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.search.suggest.Suggest;
import org.elasticsearch.search.suggest.SuggestBuilder;
import org.elasticsearch.search.suggest.SuggestBuilders;
import org.elasticsearch.search.suggest.completion.CompletionSuggestion;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
/**
* 自動補全 completion型別: 這個查詢會匹配以使用者輸入內容開頭的詞條並返回
* 參與補全查詢的欄位 必須 是completion型別
* 欄位的內容一般是用來補全的多個詞條形成的陣列
*
* <p>@author : ZiXieqing</p>
*/
@SpringBootTest(classes = HotelApp.class)
public class o10Suggest {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(
RestClient.builder(HttpHost.create("http://ip:9200"))
);
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
@Test
void completionTest() throws IOException {
// 準備request
SearchRequest request = new SearchRequest("hotel");
// 構建DSL
request.source()
.suggest(new SuggestBuilder().addSuggestion(
"title_suggest",
SuggestBuilders
.completionSuggestion("title")
.prefix("s")
.skipDuplicates(true)
.size(10)
));
// 發起請求,獲取響應物件
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 解析響應結果
// 獲取整個suggest物件
Suggest suggest = response.getSuggest();
// 通過指定的suggest名字,獲取其物件
CompletionSuggestion titleSuggest = suggest.getSuggestion("title_suggest");
for (CompletionSuggestion.Entry options : titleSuggest) {
// 獲取每一個options中的test內容
String context = options.getText().string();
// 按需求對內容進行處理
System.out.println("context = " + context);
}
}
}
程式碼與DSL、響應結果對應關係:
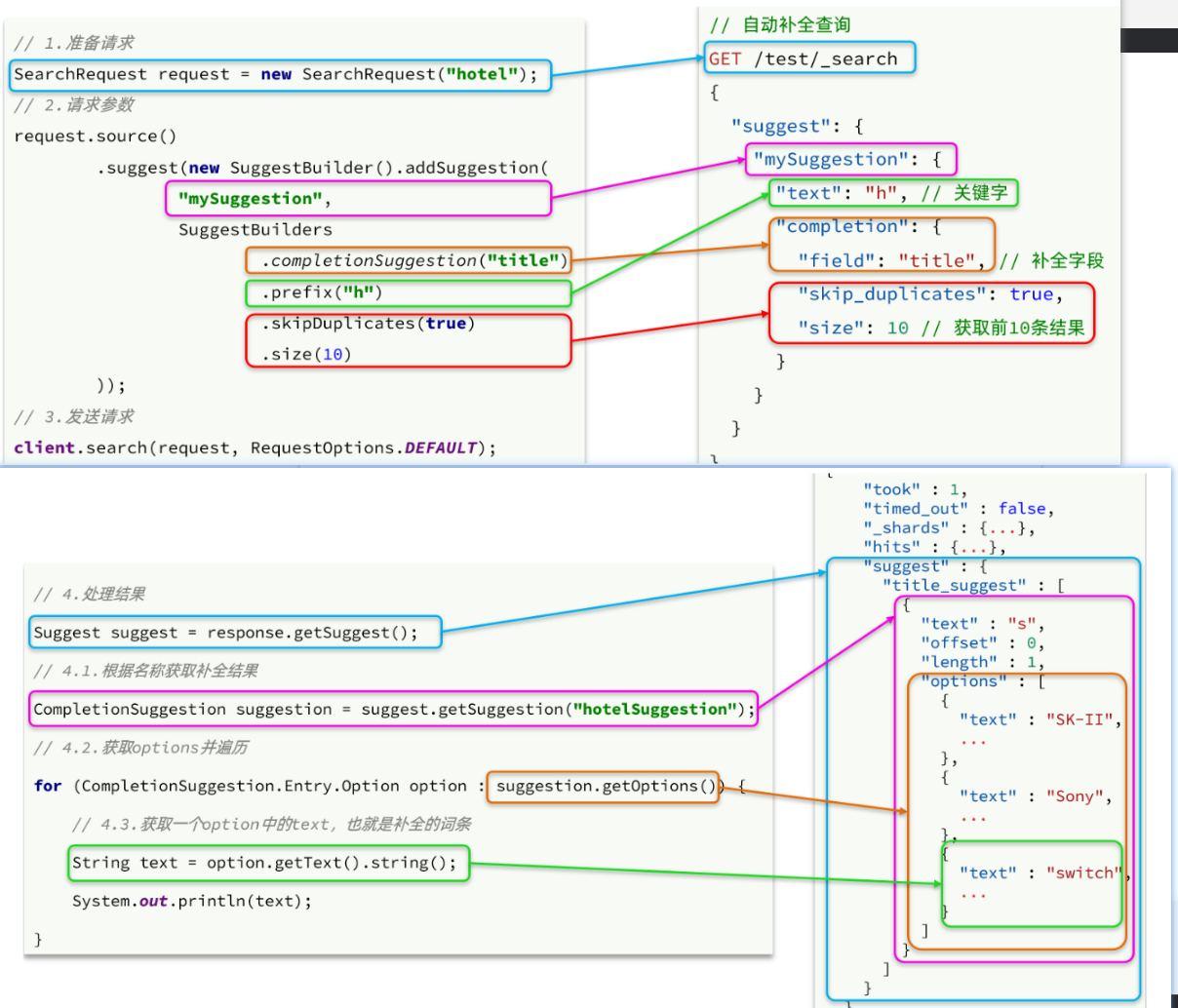
ES與MySQL資料同步
這裡的同步指的是:MySQL發生變化,則elasticsearch索引庫也需要跟著發生變化
資料同步一般有三種方式:同步呼叫方式、非同步通知方式、監聽MySQL的binlog方式
- 同步呼叫:
- 優點:實現簡單,粗暴
- 缺點:業務耦合度高
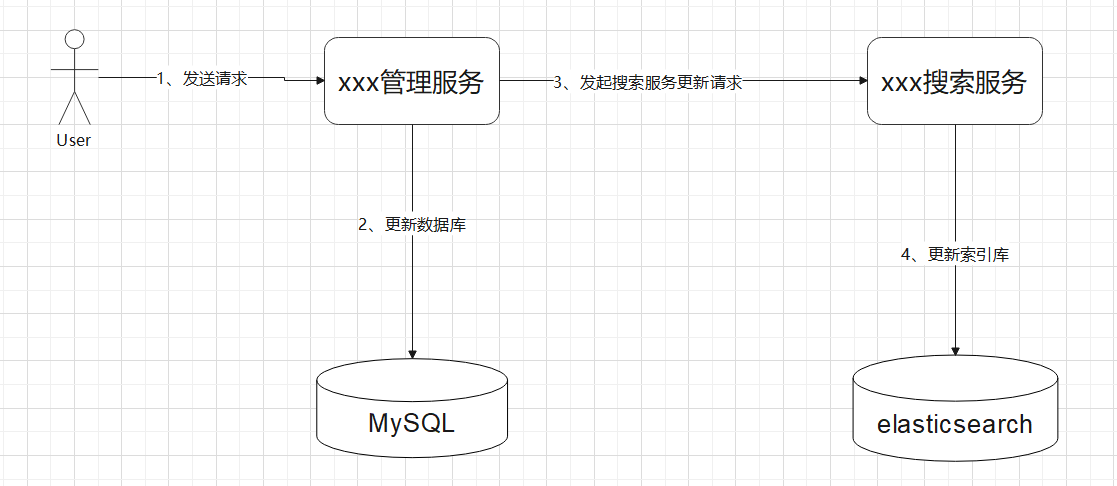
- 非同步通知:
- 優點:低耦合,實現難度一般
- 缺點:依賴mq的可靠性
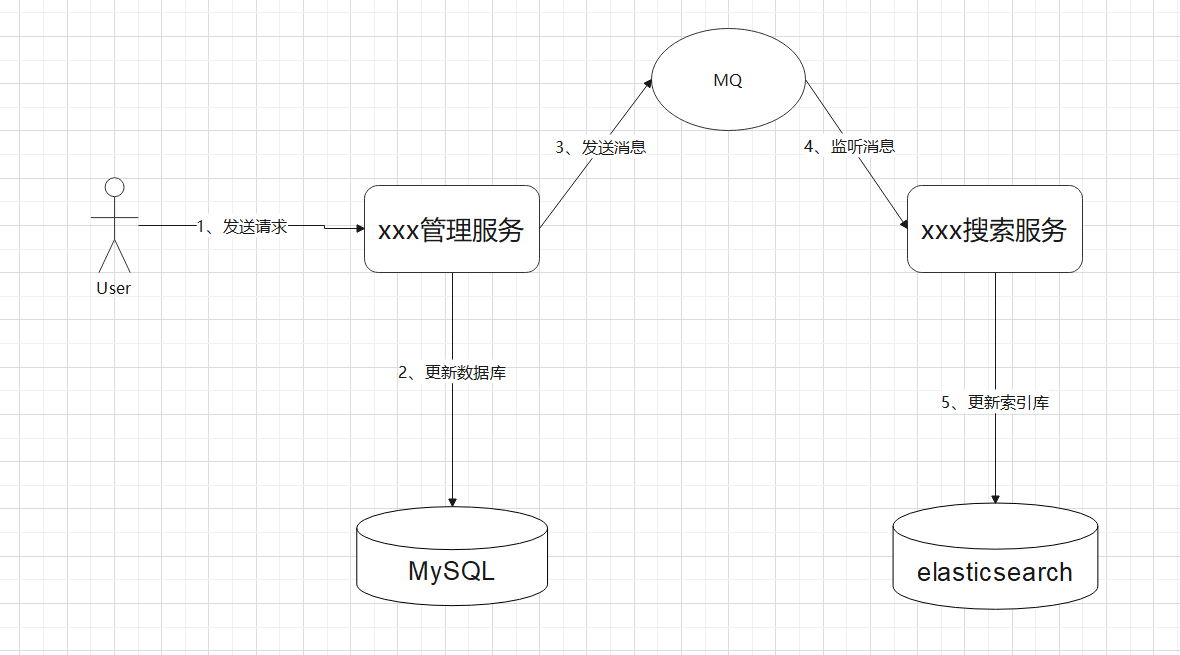
- 監聽MySQL的binlog檔案:canel是阿里巴巴的,它是將自己偽裝成MySQL的slave((即:canel要基於MySQL主從實現)。canel監聽MySQL的binlog檔案,此檔案發生改變canel就會讓另外儲存地也發生改變(如:MQ、ES、Redis......)
- 優點:完全解除服務間耦合
- 缺點:開啟binlog增加資料庫負擔、實現複雜度高
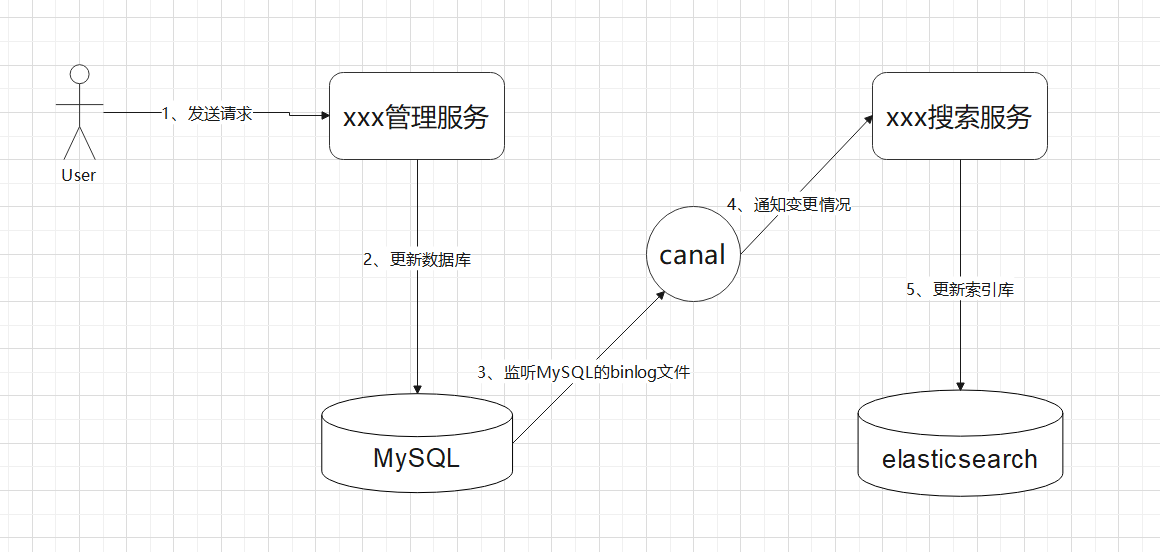
MySQL主從同步:
Sentinel 微服務保護
Sentinel是阿里巴巴開源的一款微服務流量控制元件。官網地址:https://sentinelguard.io/zh-cn/index.html
雪崩問題與解決方式
所謂的雪崩指的是:微服務之間相互呼叫,呼叫鏈中某個微服務出現問題了,導致整個服務鏈的所有服務也跟著出問題,從而造成所有服務都不可用
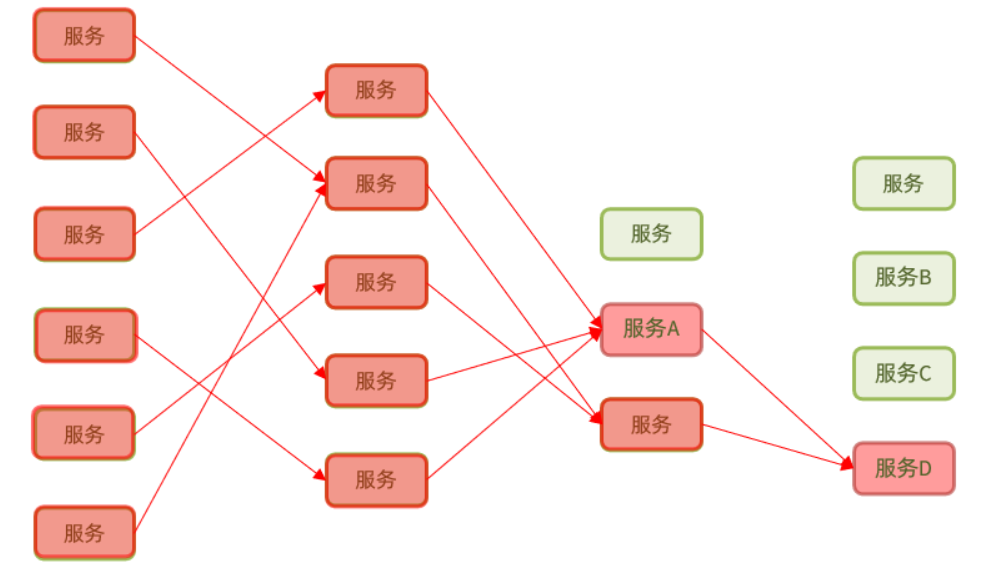
解決方式:
-
超時處理:是一種臨時方針,即設定定時器,請求超過規定的時間就返回錯誤資訊,不會無休止等待
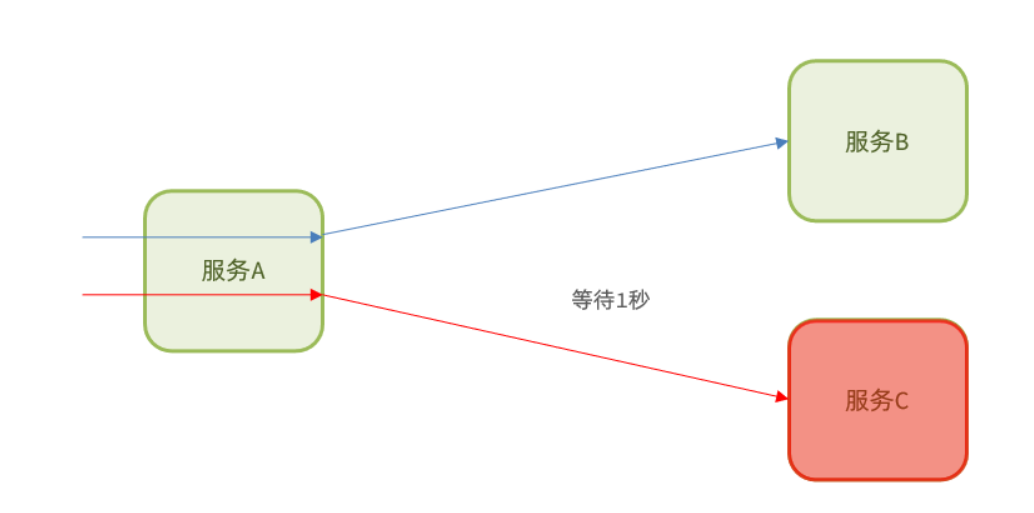
缺點:在超時時間內,還未返回錯誤資訊內,服務未處理完,請求激增,一樣會導致後面的請求阻塞
-
執行緒隔離:也叫艙壁模式,即限定每個業務能使用的執行緒數,避免耗盡整個tomcat的資源
缺點:會造成一定資源的浪費。明明服務已經不可用了,還佔用固定數量的執行緒
-
熔斷降級:
- 熔斷: 由「斷路器」統計業務執行的異常比例,如果超出「閾值」則會熔斷/暫停該業務,攔截存取該業務的一切請求,後續搞好了再開啟。從而做到在流量過大時(或下游服務出現問題時),可以自動斷開與下游服務的互動,並可以通過自我診斷下游系統的錯誤是否已經修正,或上游流量是否減少至正常水平來恢復自我恢復。熔斷更像是自動化補救手段,可能發生在服務無法支撐大量請求或服務發生其他故障時,對請求進行限制處理,同時還可嘗試性的進行恢復
- 降級: 丟車保帥。針對非核心業務功能,核心業務超出預估峰值需要進行限流;所謂降級指的就是在預計流量峰值前提下,整體資源快不夠了,忍痛將某些非核心服務先關掉,待渡過難關,再開啟回來
-
限流: 也叫流量控制。指的是限制業務存取的QPS,避免服務因流量的突增而故障。是防禦保護手段,從流量源頭開始控制流量規避問題

限流是對服務的保護,避免因瞬間高並行流量而導致服務故障,進而避免雪崩。是一種預防措施
超時處理、執行緒隔離、降級熔斷是在部分服務故障時,將故障控制在一定範圍,避免雪崩。是一種補救措施
服務保護技術對比
在SpringCloud當中支援多種服務保護技術:
早期比較流行的是Hystrix框架(後面這叼毛不維護、不更新了),所以目前國內實用最廣泛的是阿里巴巴的Sentinel框架
| Sentinel | Hystrix | |
|---|---|---|
| 隔離策略 | 號誌隔離 | 執行緒池隔離/號誌隔離 |
| 熔斷降級策略 | 基於慢呼叫比例或異常比例 | 基於失敗比率 |
| 實時指標實現 | 滑動視窗 | 滑動視窗(基於 RxJava) |
| 規則設定 | 支援多種資料來源 | 支援多種資料來源 |
| 擴充套件性 | 多個擴充套件點 | 外掛的形式 |
| 基於註解的支援 | 支援 | 支援 |
| 限流 | 基於 QPS,支援基於呼叫關係的限流 | 有限的支援 |
| 流量整形 | 支援慢啟動、勻速排隊模式 | 不支援 |
| 系統自適應保護 | 支援 | 不支援 |
| 控制檯 | 開箱即用,可設定規則、檢視秒級監控、機器發現等 | 不完善 |
| 常見框架的適配 | Servlet、Spring Cloud、Dubbo、gRPC 等 | Servlet、Spring Cloud Netflix |
安裝sentinel
-
下載:https://github.com/alibaba/Sentinel/releases 是一個jar包,這是sentinel的ui控制檯,下載了放到「非中文」目錄中
-
執行
java -jar sentinel-dashboard-1.8.1.jar
如果要修改Sentinel的預設埠、賬戶、密碼,可以通過下列設定:
| 設定項 | 預設值 | 說明 |
|---|---|---|
| server.port | 8080 | 伺服器埠 |
| sentinel.dashboard.auth.username | sentinel | 預設使用者名稱 |
| sentinel.dashboard.auth.password | sentinel | 預設密碼 |
例如,修改埠:
java -Dserver.port=8090 -jar sentinel-dashboard-1.8.1.jar
- 存取。如http://localhost:8080,使用者名稱和密碼都是sentinel
入手sentinel
-
依賴
<!--sentinel--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency> -
YAML設定
server: port: 8088 spring: cloud: sentinel: transport: # sentinel的ui控制檯地址 dashboard: localhost:8080 -
然後將服務提供者、服務消費者、閘道器、Feign……啟動,傳送請求即可在前面sentinel的ui控制檯看到資訊了
限流 / 流量控制
雪崩問題雖然有四種方案,但是限流是避免服務因突發的流量而發生故障,是對微服務雪崩問題的預防,因此先來了解這種模式,但在瞭解這個之前先了解一下限流演演算法
限流演演算法
固定視窗計數器演演算法
- 將時間劃分為多個視窗,視窗時間跨度稱為Interval
- 每個視窗維護一個計數器,每有一次請求就將計數器 +1,限流就是設定計數器閾值
- 如果計數器超過了限流閾值,則超出閾值的請求都被丟棄
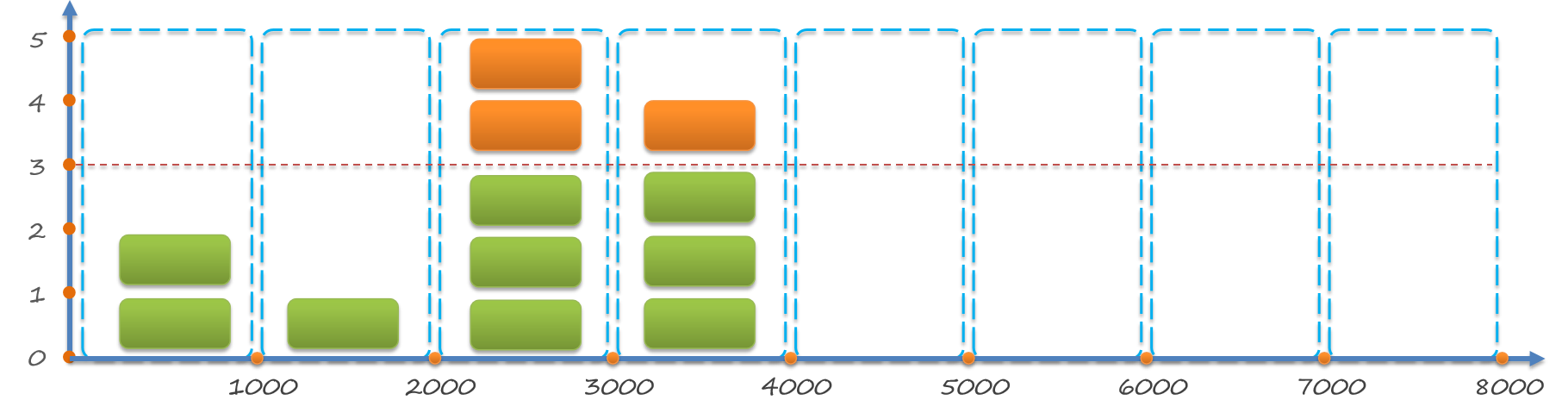
但是有個缺點:時間是不固定的。如0 - 1000ms是QPS(1秒內的請求數),這樣來看沒有超過閾值,可是:4500 - 5500ms也是1s啊,這是不是也是QPS啊,像下面這樣就超出閾值了,服務不得幹爬了
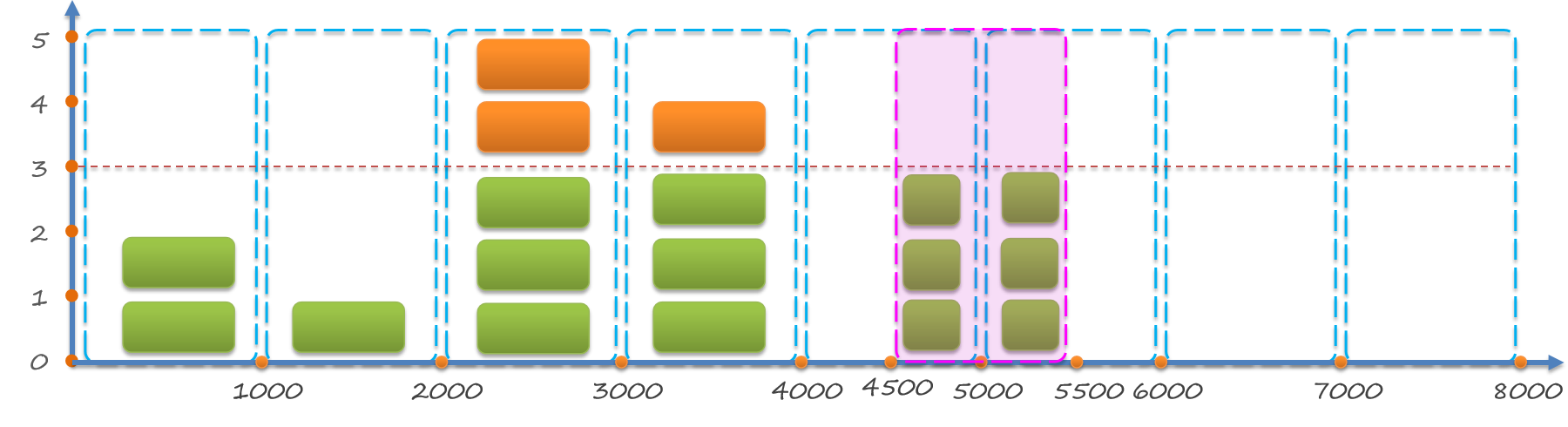
滑動視窗計數器演演算法
在固定視窗計數器演演算法的基礎上,滑動視窗計數器演演算法會將一個視窗劃分為n個更小的區間,如:
- 視窗時間跨度Interval為1秒;區間數量 n = 2 ,則每個小區間時間跨度為500ms
- 限流閾值依然為3,時間視窗(1秒)內請求超過閾值時,超出的請求被限流
- 視窗會根據當前請求所在時間(currentTime)移動,視窗範圍是從(currentTime-Interval)之後的第一個時區開始,到currentTime所在時區結束
令牌桶演演算法
- 以固定的速率生成令牌,存入令牌桶中,如果令牌桶滿了以後,多餘令牌丟棄
- 請求進入後,必須先嚐試從桶中獲取令牌,獲取到令牌後才可以被處理
- 如果令牌桶中沒有令牌,則請求等待或丟棄
也有個缺點:
- 假如限流閾值是1000個請求
- 假設捅中只能放1000個令牌,前一秒內沒有請求,但是令牌已經生成了,放入了捅中
- 之後下一秒來了2000個請求,可捅中前一秒生成了1000令牌,所以可以有1000個請求拿到令牌,從而放行,捅中沒令牌了
- 然後當前這一秒就要生成令牌,這樣另外1000個請求也可以拿到令牌
- 最後2000個請求都放行了,服務又幹爬了
漏桶演演算法
是對令牌桶演演算法做了改進:可以理解成請求在桶內排隊等待
- 將每個請求視作"水滴"放入"漏桶"進行儲存
- "漏桶"以固定速率向外"漏"出請求來執行,如果"漏桶"空了則停止"漏水」
- 如果"漏桶"滿了則多餘的"水滴"會被直接丟棄
限流演演算法對比
因為計數器演演算法一般都會採用滑動視窗計數器,所以這裡只對比三種演演算法
| 對比項 | 滑動時間視窗 | 令牌桶 | 漏桶 |
|---|---|---|---|
| 能否保證流量曲線平滑 | 不能,但視窗內區間越小,流量控制越平滑 | 基本能,在請求量持續高於令牌生成速度時,流量平滑。但請求量在令牌生成速率上下波動時,無法保證曲線平滑 | 能,所有請求進入桶內,以恆定速率放行,絕對平滑 |
| 能否應對突增流量 | 不能,徒增流量,只要高出限流閾值都會被拒絕。 | 能,桶內積累的令牌可以應對突增流量 | 能,請求可以暫存在桶內 |
| 流量控制精確度 | 低,視窗區間越小,精度越高 | 高 | 高 |
簇點鏈路
簇點鏈路: 就是專案內的呼叫鏈路,鏈路中被監控的每個介面就是一個「資源」
當請求進入微服務時,首先會存取DispatcherServlet,然後進入Controller、Service、Mapper,這樣的一個呼叫鏈就叫做簇點鏈路。簇點鏈路中被監控的每一個介面就是一個資源
預設情況下sentinel會監控SpringMVC的每一個端點(Endpoint,也就是controller中的方法),因此SpringMVC的每一個端點就是呼叫鏈路中的一個資源
例如下圖中的端點:/order/{orderId}

流控、熔斷等都是針對簇點鏈路中的資源來設定的,因此我們可以點選對應資源後面的按鈕來設定規則:
- 流控:流量控制
- 降級:降級熔斷
- 熱點:熱點引數限流
- 授權:請求的許可權控制
入門流控
-
點選下圖按鈕

-
設定基本流控資訊
上圖的含義:限制 /order/{orderId} 這個資源的單機QPS為1,即:每秒只允許1次請求,超出的請求會被攔截並報錯
流控模式的分類
在新增限流規則時,點選高階選項,可以選擇三種流控模式:
-
直接模式:一句話來說就是「對當前資源限流」。統計當前資源的請求,當其觸發閾值時,對當前資源直接限流。上面這張圖就是此種模式。這也是預設的模式。採用的演演算法就是滑動視窗演演算法
-
關聯模式:一句話來說就是「高優先順序觸發閾值,對低優先順序限流」。統計與當前資源A「相關」的另一個資源B,A資源觸發閾值時,對B資源限流
如:在一個Controller中,一個高流量的方法和一個低流量的方法都呼叫了這個Controller中的另一個方法,為了預防雪崩問題,就對低流量的方法進行限流設定
適用場景:兩個有競爭關係的資源,一個優先順序高,一個優先順序低,優先順序高的觸發閾值時,就對優先順序低的進行限流
-
鏈路模式:一句話來說就是「對請求來源做限流」。統計從「指定鏈路」存取到本資源的請求,觸發閾值時,對指定鏈路限流
如:兩個不同鏈路的請求,如需要讀庫和寫庫,這兩個請求都呼叫了同一個服務/資源/介面,所以為了需求考慮,可以設定讀庫達到了閾值就進行限流
範例:
-
關聯模式: 對誰進行限流,就點選誰的流控按鈕進行設定
上圖含義:當 /order/update 請求單機達到 每秒1000 請求量的閾值時,就會對 /order/query 進行限流,從而避免影響 /order/update 資源
-
鏈路模式: 請求鏈路存取的是哪個資源,就點選哪個資源的流控按鈕進行設定
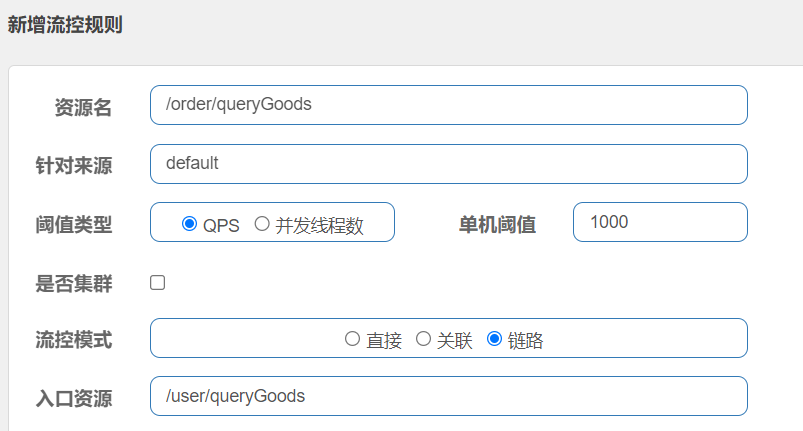
上圖含義:只有來自 /user/queryGoods 鏈路的請求來存取 /order/queryGoods 資源時,每秒請求量達到1000,就會對 /user/queryGoods 進行限流
鏈路模式的注意事項:
預設情況下,Service中的方法是不被Sentinel監控的,想要Service中的方法也被Sentinel監控的話,則需要我們自己通過 @SentinelResource("起個名字 或 像controllerz中請求路徑寫法") 註解來標記要監控的方法
鏈路模式中,是對不同來源的兩個鏈路做監控。但是sentinel預設會給進入SpringMVC的所有請求設定同一個root資源,進行了context整合,所以會導致鏈路模式失效。因此需要關閉一個context整合設定:
spring: cloud: sentinel: web-context-unify: false # 關閉context整合同一個root資源指的是:

流控效果及其分類
流控效果:指請求達到流控閾值時應該採取的措施
分類
- 快速失敗:達到閾值後,新的請求會被立即拒絕並丟擲 FlowException異常。是預設的處理方式
- warm up:預熱模式,對超出閾值的請求同樣是拒絕並丟擲異常。但這種模式閾值會動態變化,從一個較小值逐漸增加到最大閾值
- 排隊等待:讓所有的請求按照先後次序排隊執行,兩個請求的間隔不能小於指定時長
warn up 預熱模式
warm up:預熱模式,對超出閾值的請求同樣是拒絕並丟擲異常。但這種模式閾值會動態變化,從一個較小值逐漸增加到最大閾值
閾值一般是一個微服務能承擔的最大QPS,但是一個服務剛剛啟動時,一切資源尚未初始化(冷啟動),如果直接將QPS跑到最大值,可能導致服務瞬間宕機
warm up也叫預熱模式,是應對服務冷啟動的一種方案
請求閾值初始值 = maxThreshold / coldFactor
- maxThreshold 就是設定的QPS數量。持續指定時長後,逐漸提高到maxThreshold值。
- coldFactor 預熱因子,預設值是3
排隊等待
排隊等待:讓所有的請求按照先後次序排隊執行,兩個請求的間隔不能小於指定時長
採用的演演算法:基於漏桶演演算法
當請求超過QPS閾值時,快速失敗和warm up 會拒絕新的請求並丟擲異常
而排隊等待則是讓所有請求進入一個佇列中,然後按照閾值允許的時間間隔依次執行。後來的請求必須等待前面執行完成,如果請求預期的等待時間超出最大時長,則會被拒絕
QPS = 5,那麼 1/5(個/ms) = 200(個/ms),意味著每200ms處理1個佇列中的請求;timeout = 2000,意味著預期等待時長超過2000ms的請求會被拒絕並丟擲異常
那什麼叫做預期等待時長呢?
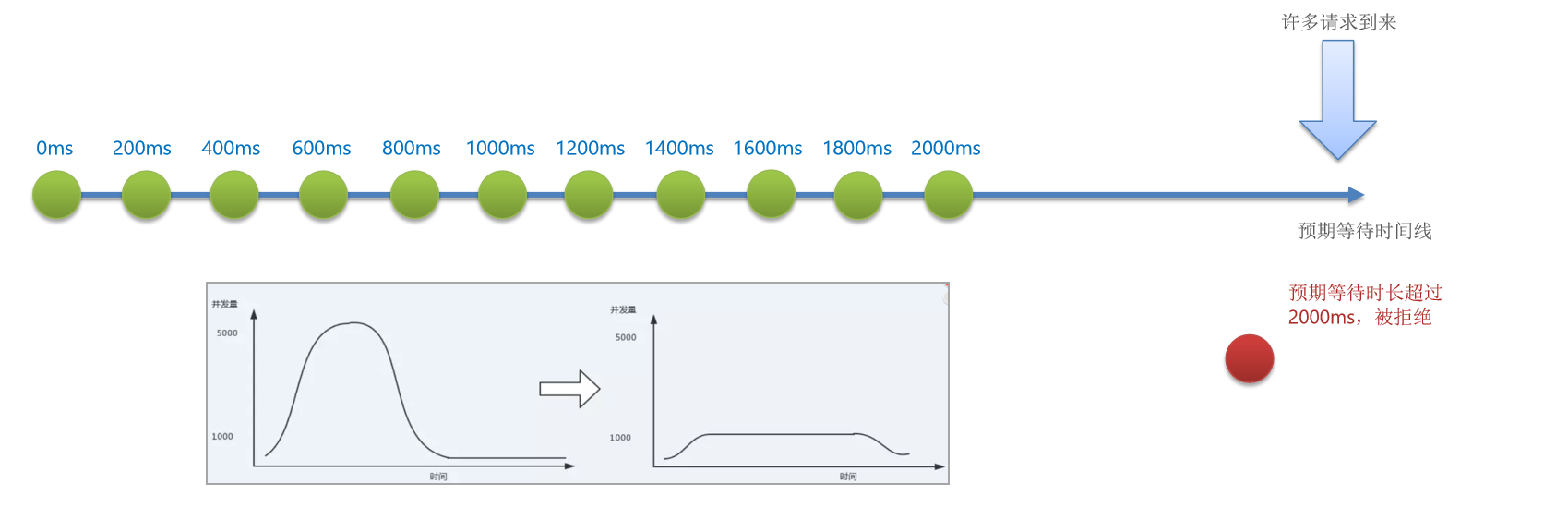
如果使用佇列模式做流控,所有進入的請求都要排隊,以固定的200ms的間隔執行,QPS會變的很平滑
平滑的QPS曲線,對於伺服器來說是更友好的
熱點引數限流
之前的限流是統計存取某個資源的所有請求,判斷是否超過QPS閾值
熱點引數限流是分別統計引數值相同的請求,判斷是否超過QPS閾值
採用的演演算法: 令牌桶演演算法
注意事項:熱點引數限流對預設的SpringMVC資源無效,需要利用@SentinelResource註解標記資源,例如:
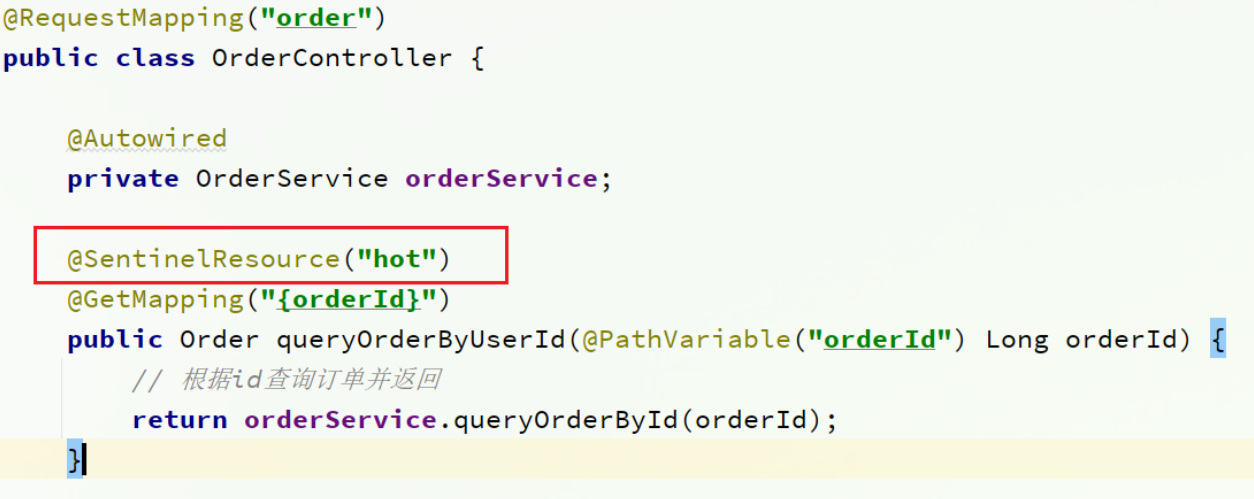

但是設定時不要通過上面按鈕點選設定,會有BUG,而是通過下圖中的方式:
所謂的引數值指的是:

id引數值會有變化,熱點引數限流會根據引數值分別統計QPS
當id=1的請求觸發閾值被限流時,id值不為1的請求不受影響
全域性引數限流
就是基礎設定,沒有加入高階設定的情況
上圖含義:對於來存取hot資源的請求,每1秒相同引數值的請求數不能超過10000
熱點引數限流
剛才的設定中,對查詢商品這個介面的所有商品一視同仁,QPS都限定為10000
而在實際開發中,可能部分商品是熱點商品,例如秒殺商品,我們希望這部分商品的QPS限制與其它商品不一樣,高一些。那就需要設定熱點引數限流的高階選項了
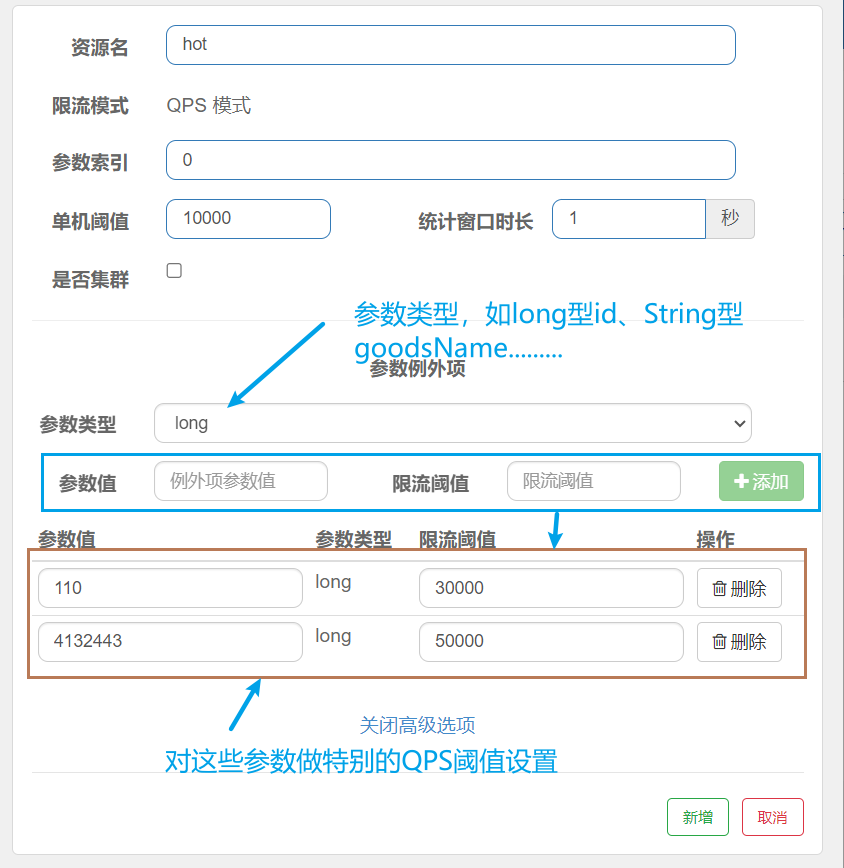
上圖含義:對於來存取hot資源的請求,id=110時的QPS閾值為30000,id=4132443時的QPS閾值為50000,id為其他的則QPS閾值為10000
Seatinel限流與Gateway限流的差異
Gateway則採用了基於Redis實現的令牌桶演演算法。而Sentinel內部所有演演算法都有::
- 預設限流模式是基於滑動時間視窗演演算法
- 排隊等待的限流模式則基於漏桶演演算法
- 而熱點引數限流則是基於令牌桶演演算法
Sentinel整合Feign
Sentinel是做服務保護的,而在微服務中調來調去是常有的事,要遠端呼叫就離不開Feign
- 修改設定,開啟sentinel功能: 在服務「消費方」的feign設定新增如下設定內容
feign:
sentinel:
enabled: true # 開啟feign對sentinel的支援
- feign-client中編寫失敗降級邏輯: 後面的流程就是前面玩Fengn時失敗降級的流程
package com.zixieqing.feign.fallback;
import com.zixieqing.feign.clients.UserClient;
import com.zixieqing.feign.pojo.User;
import feign.hystrix.FallbackFactory;
import lombok.extern.slf4j.Slf4j;
/**
* userClient失敗時的降級處理
*
* <p>@author : ZiXieqing</p>
*/
@Slf4j
public class UserClientFallBackFactory implements FallbackFactory<UserClient> {
@Override
public UserClient create(Throwable throwable) {
return new UserClient() {
/**
* 重寫userClient中的方法,編寫失敗時的降級邏輯
*/
@Override
public User findById(Long id) {
log.info("userClient的findById()在進行 id = {} 時失敗", id);
return new User();
}
};
}
}
- 將失敗降級邏輯的類丟給Spring容器
@Bean
public UserClientFallBackFactory userClientFallBackFactory() {
return new UserClientFallBackFactory();
}
- 在相關feign-client定義處使用fallbackFactory回撥函數即可
package com.zixieqing.feign.clients;
import com.zixieqing.feign.fallback.UserClientFallBackFactory;
import com.zixieqing.feign.pojo.User;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
@FeignClient(value = "userservice",fallbackFactory = UserClientFallBackFactory.class)
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}
- 呼叫,失敗時就會進入自定義的失敗邏輯中
package com.zixieqing.order.service;
import com.zixieqing.feign.clients.UserClient;
import com.zixieqing.feign.pojo.User;
import com.zixieqing.order.mapper.OrderMapper;
import com.zixieqing.order.pojo.Order;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private UserClient userClient;
public Order queryOrderById(Long orderId) {
// 1.查詢訂單
Order order = orderMapper.findById(orderId);
// 2.用Feign遠端呼叫
User user = userClient.findById(order.getId());
// 3.封裝user到Order
order.setUser(user);
// 4.返回
return order;
}
}
隔離與降級
執行緒隔離
執行緒隔離有兩種方式實現:
-
執行緒池隔離:給每個服務呼叫業務分配一個執行緒池,利用執行緒池本身實現隔離效果
優點:
- 支援主動超時:也就是呼叫進行邏輯處理時超過了規定時間,直接噶了,不再讓其繼續處理
- 支援非同步呼叫:執行緒池隔離了嘛,彼此不干擾,因此可以非同步了
缺點:造成資源浪費。明明被呼叫的服務都出問題了,還佔用固定的執行緒池數量
適用場景:低扇出。MQ中扇出交換機的那個扇出,也就是較少的請求量,扇出/廣播到很多服務上
-
號誌隔離(Sentinel預設採用):不建立執行緒池,而是計數器模式,記錄業務使用的執行緒數量,達到號誌上限時,禁止新的請求
優點:輕量級、無額外開銷
缺點:不支援主動超時、不支援非同步呼叫
適用場景:高頻呼叫、高扇出
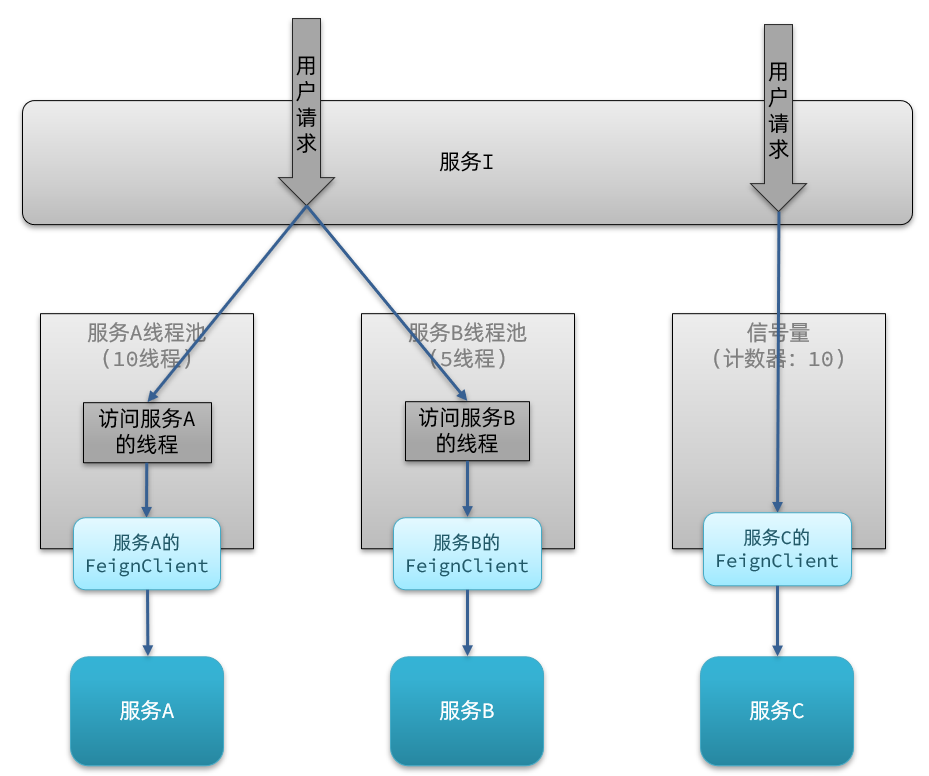
設定Sentinel的執行緒隔離-號誌隔離
在新增限流規則時,可以選擇兩種閾值型別:
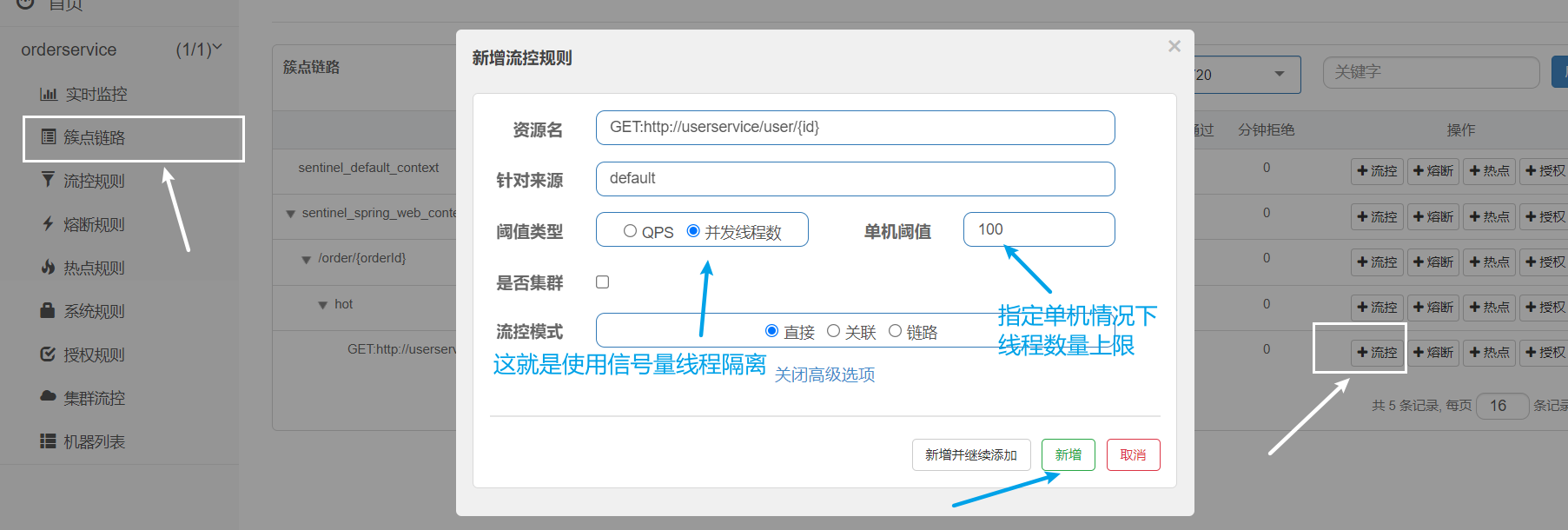
熔斷降級
熔斷降級是解決雪崩問題的重要手段。其思路是由斷路器統計服務呼叫的異常比例、慢請求比例,如果超出閾值則會熔斷該服務。即攔截存取該服務的一切請求;而當服務恢復時,斷路器會放行存取該服務的請求
斷路器控制熔斷和放行是通過狀態機來完成的:
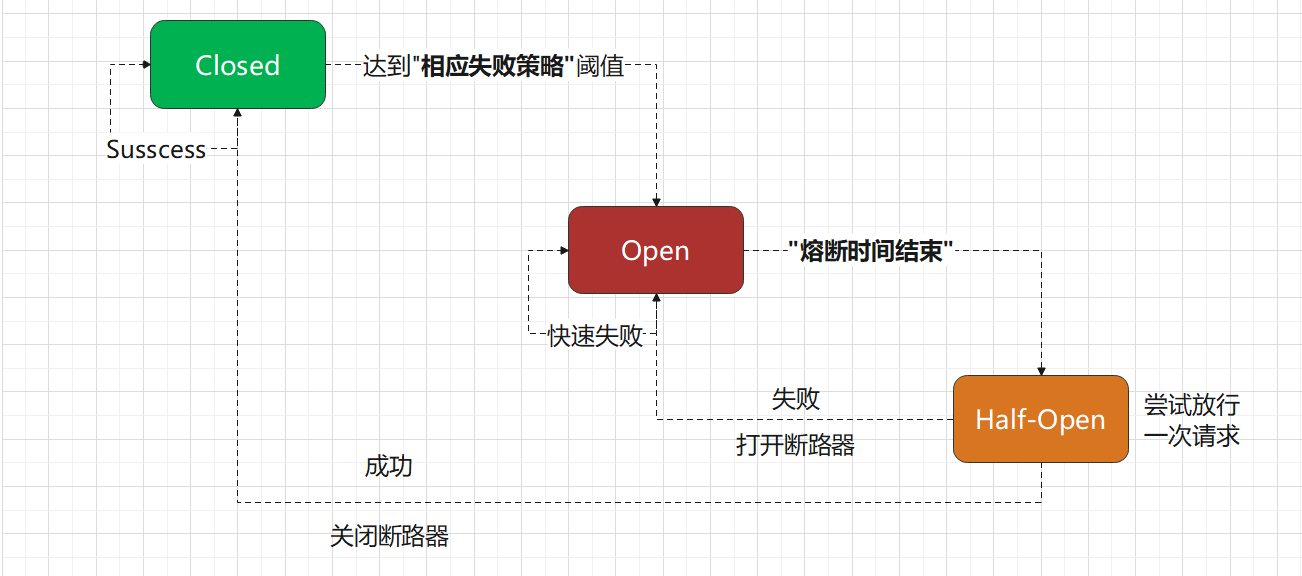
斷路器熔斷策略有三種:慢呼叫、異常比例、異常數
狀態機包括三個狀態:
- Closed:關閉狀態,斷路器放行所有請求,並開始統計異常比例、慢請求比例。超過閾值則切換到open狀態
- Open:開啟狀態,服務呼叫被熔斷,存取被熔斷服務的請求會被拒絕,快速失敗,直接走降級邏輯。Open狀態預設5秒後會進入half-open狀態
- Half-Open:半開狀態,放行一次請求,根據執行結果來判斷接下來的操作。
- 請求成功:則切換到closed狀態
- 請求失敗:則切換到open狀態
斷路器熔斷策略:慢呼叫
慢呼叫:業務的響應時長(RT)大於指定時長的請求認定為慢呼叫請求
在指定時間內,如果請求數量超過設定的最小數量,慢呼叫比例大於設定的閾值,則觸發熔斷
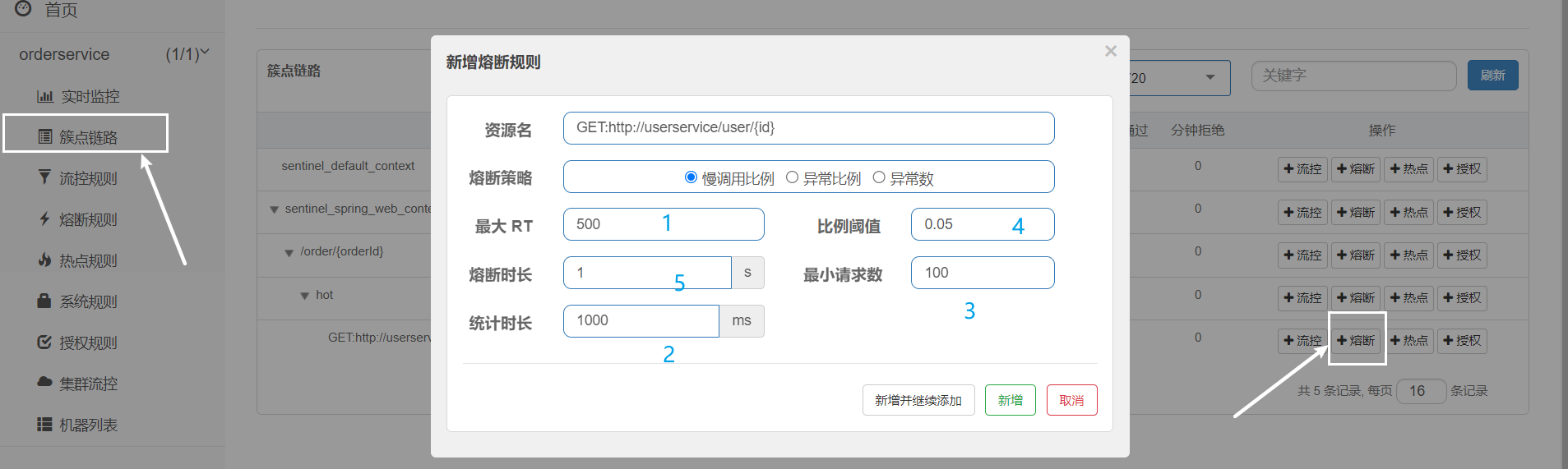
上圖含義:
- 響應時間為500ms的即為慢呼叫
- 如果1000ms內有100次請求,且慢呼叫比例不低於0.05(即:100*0.05=5個慢呼叫),則觸發熔斷(暫停該服務)
- 熔斷時間達到1s進入half-open狀態,然後放行一次請求測試
- 成功則進入Closed狀態關閉斷路器
- 失敗則進入Open狀態開啟斷路器,繼續像前面一樣開始統計RT=500ms,1s內有100次請求……………..
斷路器熔斷策略:異常比例 與 異常數
- 異常比例:
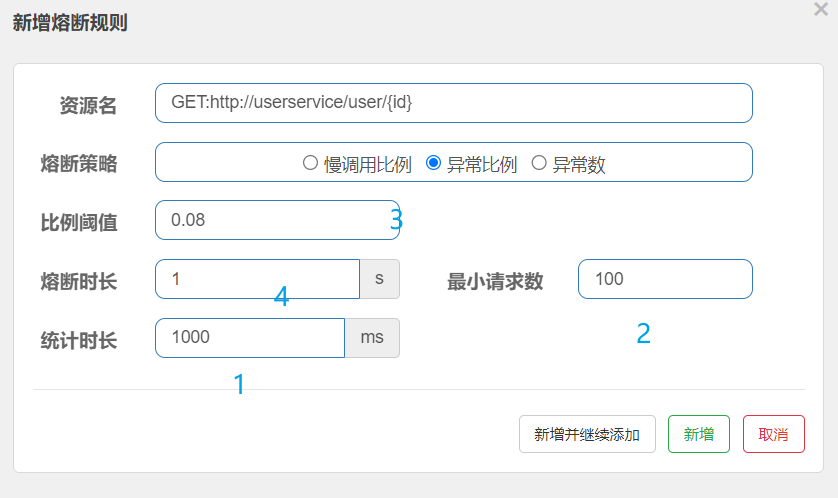
上圖含義:在1s內,若是請求數量不低於100個,且異常比例不低於0.08(即:100*0.08=8個有異常),則觸發熔斷,熔斷時長達到1s就進入half-open狀態
- 異常數:直接敲定有多少個異常數量就觸發熔斷
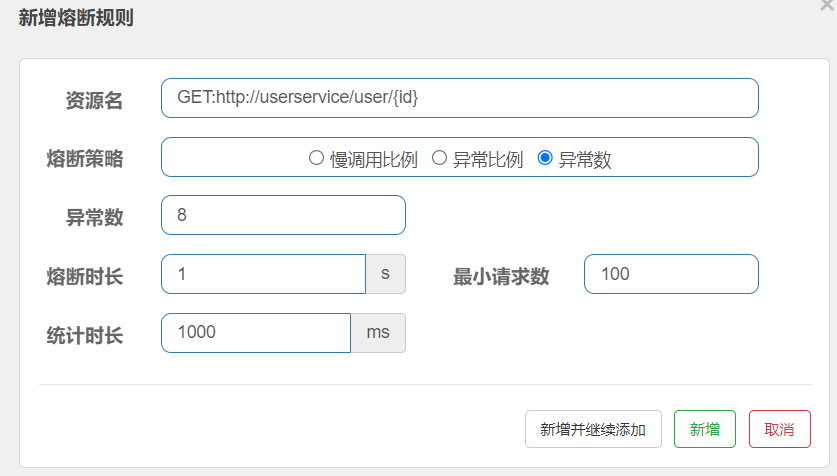
授權規則
授權規則可以對請求方來源做判斷和控制
授權規則可以對呼叫方的來源做控制,有白名單和黑名單兩種方式:
- 白名單:來源(origin)在白名單內的呼叫者允許存取
- 黑名單:來源(origin)在黑名單內的呼叫者不允許存取
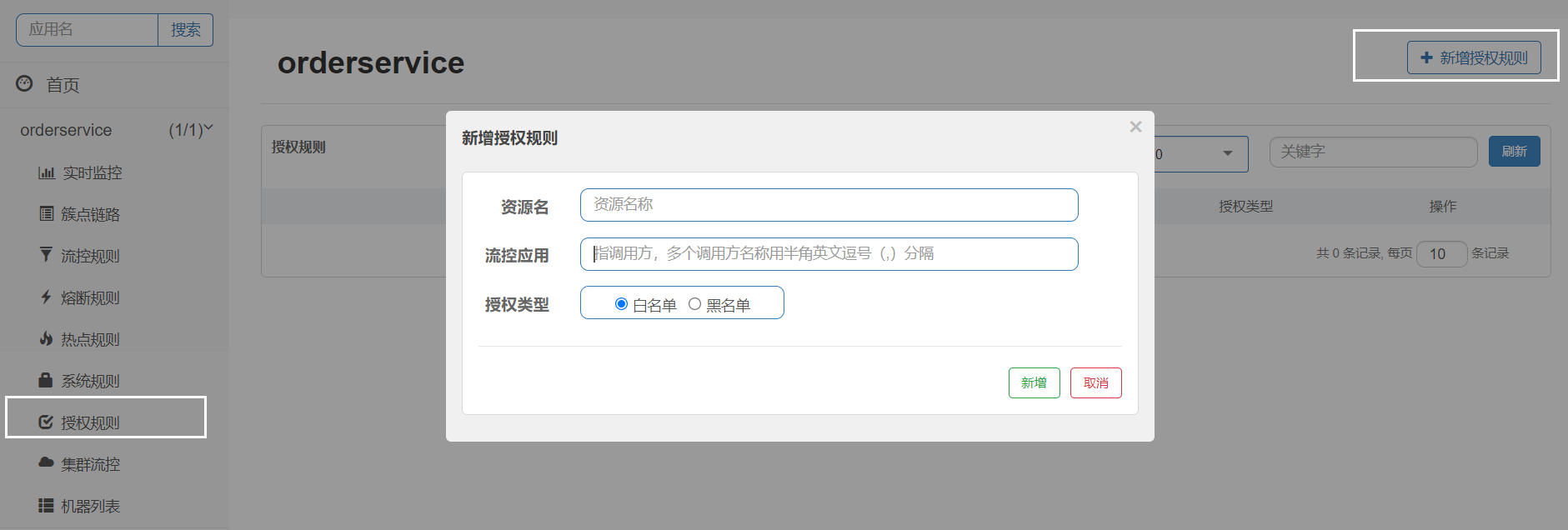
-
資源名:就是受保護的資源,例如 /order/
-
流控應用:是來源者的名單
- 如果是勾選白名單,則名單中的來源被許可存取
- 如果是勾選黑名單,則名單中的來源被禁止存取
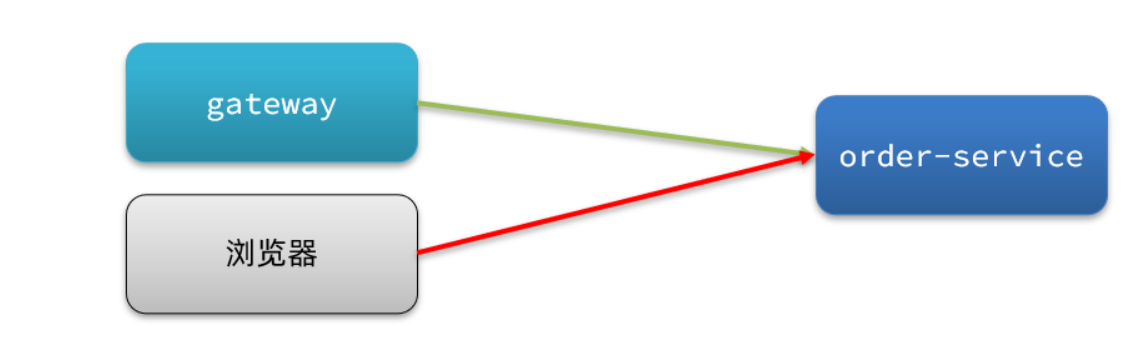
我們允許請求從gateway到order-service,不允許瀏覽器存取order-service,那麼白名單中就要填寫閘道器的來源名稱(origin)
但是上圖中怎麼區分請求是從閘道器來的還是瀏覽器來的?在微服務中的想法是所有請求只能走閘道器,然後由閘道器路由到具體的服務,直接存取服務應該阻止才對,像下面直接跳過閘道器去存取服務,應該不行才對
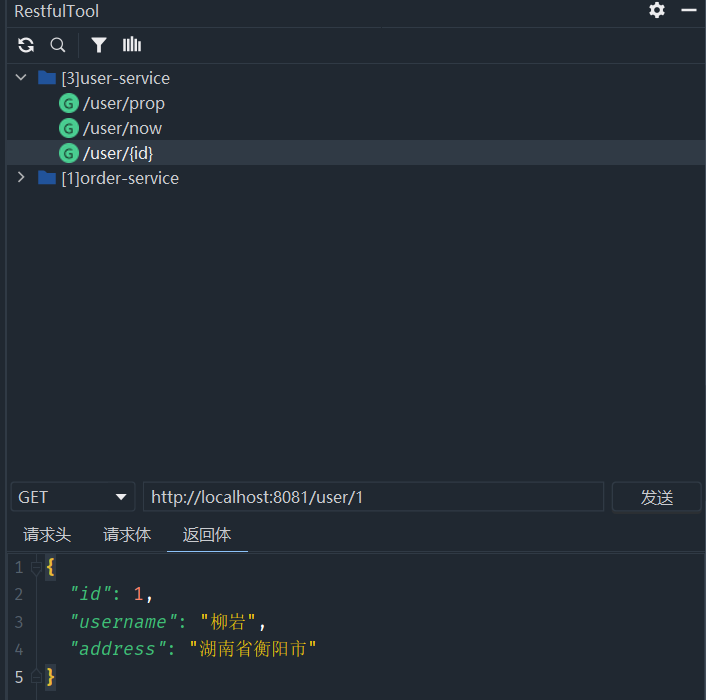
要做到就需要使用授權規則了:
- 閘道器授權攔截:針對於別人不知道內部服務介面的情況可以攔截成功
- 服務授權控制/流控應用控制:針對「內鬼「 或者 別人知道了內部服務介面,我們限定只能從哪裡來的請求才能存取該服務,否則直接拒絕
流控應用怎麼控制的?
下圖中的名字怎麼定義?
需要實現 RequestOriginParser 這個介面的 parseOrigin() 來獲取請求的來源從而做到
public interface RequestOriginParser {
/**
* 從請求request物件中獲取origin,獲取方式自定義
*/
String parseOrigin(HttpServletRequest request);
}
範例:
- 在需要進行保護的服務中編寫請求來源解析邏輯
package com.zixieqing.order.intercepter;
import com.alibaba.csp.sentinel.adapter.spring.webmvc.callback.RequestOriginParser;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;
import javax.servlet.http.HttpServletRequest;
/**
* 攔截請求,允許從什麼地方來的請求才能存取此微服務
*
* <p>@author : ZiXieqing</p>
*/
@Component
public class RequestInterceptor implements RequestOriginParser {
@Override
public String parseOrigin(HttpServletRequest request) {
// 獲取請求中的請求頭 可自定義
String origin = request.getHeader("origin");
if (StringUtils.isEmpty(origin))
origin = "black";
return origin;
}
}
- 在閘道器中根據2中 parseOrigin() 的邏輯新增相應的東西

- 新增流控規則:不要在簇點鏈路中選擇相應服務來設定授權,會有BUG
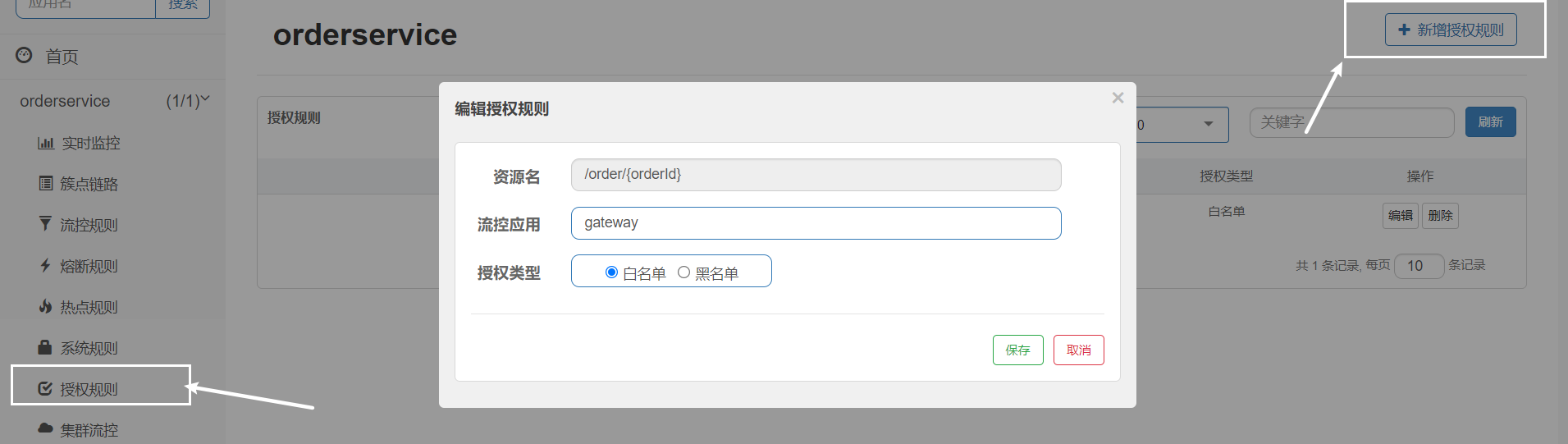
經過上面的操作之後,要進入服務就只能通過閘道器路由過來了,不是從閘道器過來的就無法存取服務
自定義異常
預設情況下,發生限流、降級、授權攔截時,都會丟擲異常到呼叫方。異常結果都是flow limmiting(限流)。這樣不夠友好,無法得知是限流還是降級還是授權攔截
而如果要自定義異常時的返回結果,需要實現 BlockExceptionHandler 介面:
public interface BlockExceptionHandler {
/**
* 處理請求被限流、降級、授權攔截時丟擲的異常:BlockException
*
* @param e 被sentinel攔截時丟擲的異常
*/
void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception;
}
這裡的BlockException包含多個不同的子類:
| 異常 | 說明 |
|---|---|
| FlowException | 限流異常 |
| ParamFlowException | 熱點引數限流的異常 |
| DegradeException | 降級異常 |
| AuthorityException | 授權規則異常 |
| SystemBlockException | 系統規則異常 |
範例:
- 在需要的服務中實現 BlockExceptionHandler 介面
package com.zixieqing.order.exception;
import com.alibaba.csp.sentinel.adapter.spring.webmvc.callback.BlockExceptionHandler;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import com.alibaba.csp.sentinel.slots.block.authority.AuthorityException;
import com.alibaba.csp.sentinel.slots.block.degrade.DegradeException;
import com.alibaba.csp.sentinel.slots.block.flow.FlowException;
import com.alibaba.csp.sentinel.slots.block.flow.param.ParamFlowException;
import org.springframework.stereotype.Component;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* 自定義sentinel的各種例外處理
*
* <p>@author : ZiXieqing</p>
*/
@Component
public class SentinelExceptionHandler implements BlockExceptionHandler {
@Override
public void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception {
String msg = "未知異常";
int status = 429;
if (e instanceof FlowException) {
msg = "請求被限流了";
} else if (e instanceof ParamFlowException) {
msg = "請求被熱點引數限流";
} else if (e instanceof DegradeException) {
msg = "請求被降級了";
} else if (e instanceof AuthorityException) {
msg = "沒有許可權存取";
status = 401;
}
response.setContentType("application/json;charset=utf-8");
response.setStatus(status);
response.getWriter().println("{\"msg\": " + msg + ", \"status\": " + status + "}");
}
}
- 重啟服務,不同異常就會出現不同結果了
規則持久化
在預設情況下,sentinel的所有規則都是記憶體儲存,重啟後所有規則都會丟失。在生產環境下,我們必須確保這些規則的持久化,避免丟失
規則是否能持久化,取決於規則管理模式,sentinel支援三種規則管理模式:
- 原始模式:Sentinel的預設模式,將規則儲存在記憶體,重啟服務會丟失
- pull模式
- push模式
pull模式
pull模式:控制檯將設定的規則推播到Sentinel使用者端,而使用者端會將設定規則儲存在本地檔案或資料庫中。以後會定時去本地檔案或資料庫中查詢,更新本地規則
缺點:服務之間的規則更新不及時。因為是定時去讀取,在時間還未到時,可能規則發生了變化
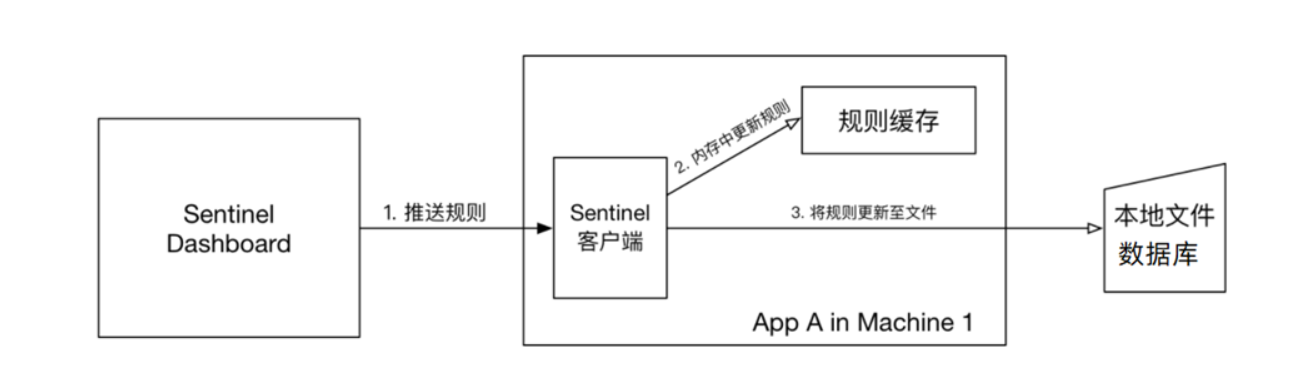
push模式
push模式:控制檯將設定規則推播到遠端設定中心(如Nacos)。Sentinel使用者端監聽Nacos,獲取設定變更的推播訊息,完成本地設定更新
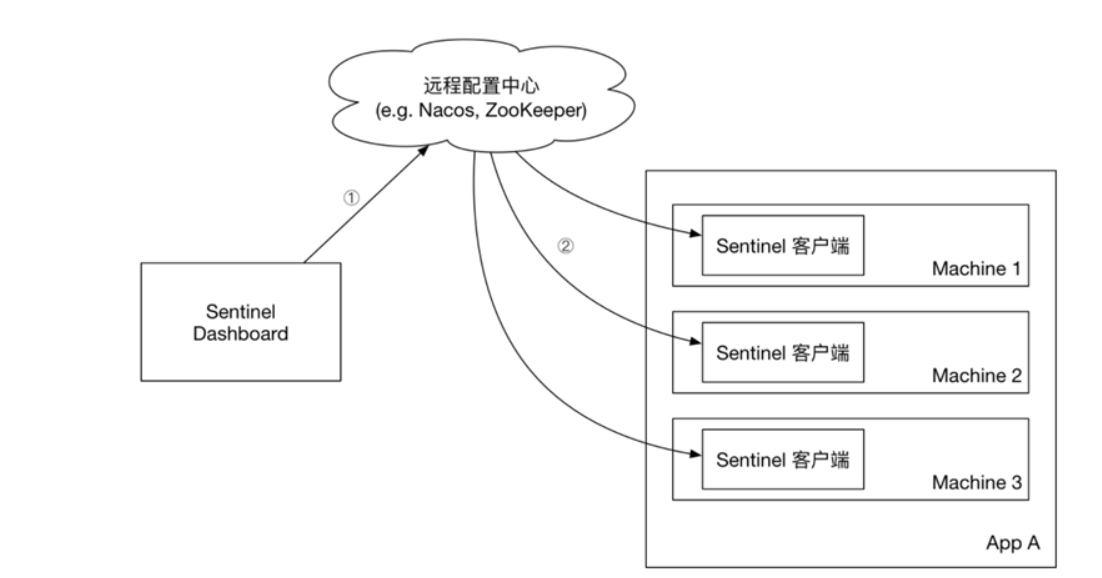
使用push模式實現規則持久化
在想要進行規則持久化的服務中引入如下依賴:
<!--sentinel規則持久化到Nacos的依賴-->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
設定此服務的YAML檔案,內容如下:
spring:
cloud:
sentinel:
datasource:
flow: # 流控規則持久化
nacos:
server-addr: localhost:8848 # nacos地址
dataId: orderservice-flow-rules
groupId: SENTINEL_GROUP
rule-type: flow # 還可以是:degrade 降級、authority 授權、param-flow 熱點引數限流
# degrade: # 降級規則持久化
# nacos:
# server-addr: localhost:8848 # nacos地址
# dataId: orderservice-degrade-rules
# groupId: SENTINEL_GROUP
# rule-type: degrade
# authority: # 授權規則持久化
# nacos:
# server-addr: localhost:8848 # nacos地址
# dataId: orderservice-authority-rules
# groupId: SENTINEL_GROUP
# rule-type: authority
# param-flow: # 熱電引數限流持久化
# nacos:
# server-addr: localhost:8848 # nacos地址
# dataId: orderservice-param-flow-rules
# groupId: SENTINEL_GROUP
# rule-type: param-flow
修改sentinel的原始碼
因為阿里的sentinel預設採用的是將規則內容存到記憶體中的,因此需要改原始碼
- 使用git克隆sentinel的原始碼,之後IDEA等工具開啟
git clone https://github.com/alibaba/Sentinel.git
- 修改nacos依賴。在sentinel-dashboard模組的pom檔案中,nacos的依賴預設的scope如果是test,那它只能在測試時使用,所以要去除 scope 標籤
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
- 新增nacos支援。在sentinel-dashboard的test包下,已經編寫了對nacos的支援,我們需要將其拷貝到src/main/java/com/alibaba/csp/sentinel/dashboard/rule 下
- 修改nacos地址,讓其讀取application.properties中的設定
- 在sentinel-dashboard的application.properties中新增nacos地址設定
nacos.addr=127.0.0.1:8848 # ip和port改為自己想要的即可
- 設定nacos資料來源
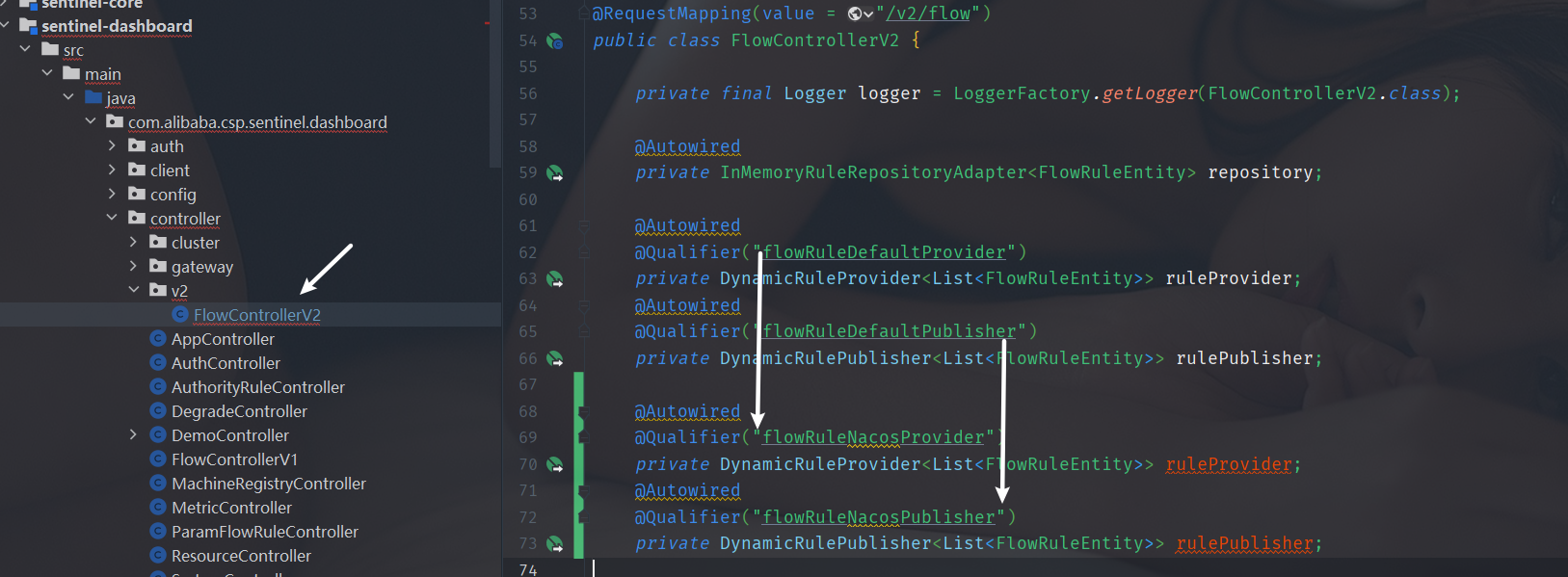
- 修改前端
- 重現編譯打包Sentinel-Dashboard模組
- 重現啟動sentinel即可
java -jar -Dnacos.addr=127.0.0.1:8848 sentinel-dashboard.jar
補充:Sentinel基礎知識
Sentinel實現限流、隔離、降級、熔斷等功能,本質要做的就是兩件事情:
- 統計資料:統計某個資源的存取資料(QPS、RT等資訊)
- 規則判斷:判斷限流規則、隔離規則、降級規則、熔斷規則是否滿足
這裡的資源就是希望被Sentinel保護的業務,例如專案中定義的controller方法就是預設被Sentinel保護的資源
ProcessorSlotChain
實現上述功能的核心骨架是一個叫做ProcessorSlotChain的類。這個類基於責任鏈模式來設計,將不同的功能(限流、降級、系統保護)封裝為一個個的Slot,請求進入後逐個執行即可
責任鏈中的Slot也分為兩大類:
- 統計資料構建部分(statistic)
- NodeSelectorSlot:負責構建簇點鏈路中的節點(DefaultNode),將這些節點形成鏈路樹
- ClusterBuilderSlot:負責構建某個資源的ClusterNode,ClusterNode可以儲存資源的執行資訊(響應時間、QPS、block 數目、執行緒數、異常數等)以及來源資訊(origin名稱)
- StatisticSlot:負責統計實時呼叫資料,包括執行資訊、來源資訊等
- 規則判斷部分(rule checking)
- AuthoritySlot:負責授權規則(來源控制)
- SystemSlot:負責系統保護規則
- ParamFlowSlot:負責熱點引數限流規則
- FlowSlot:負責限流規則
- DegradeSlot:負責降級規則
Node
Sentinel中的簇點鏈路是由一個個的Node組成的,Node是一個介面,包括下面的實現:
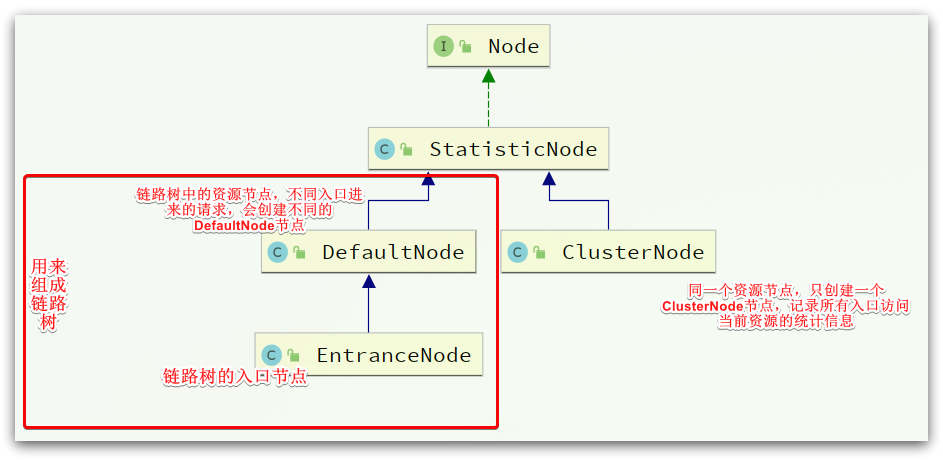
所有的節點都可以記錄對資源的存取統計資料,所以都是StatisticNode的子類
按照作用分為兩類Node:
- DefaultNode:代表鏈路樹中的每一個資源,一個資源出現在不同鏈路中時,會建立不同的DefaultNode節點。而樹的入口節點叫EntranceNode,是一種特殊的DefaultNode
- ClusterNode:代表資源,一個資源不管出現在多少鏈路中,只會有一個ClusterNode。記錄的是當前資源被存取的所有統計資料之和。
DefaultNode記錄的是資源在當前鏈路中的存取資料,用來實現基於鏈路模式的限流規則。ClusterNode記錄的是資源在所有鏈路中的存取資料,實現預設模式、關聯模式的限流規則。
例如:我們在一個SpringMVC專案中,有兩個業務:
- 業務1:controller中的資源
/order/query存取了service中的資源/goods - 業務2:controller中的資源
/order/save存取了service中的資源/goods
建立的鏈路圖如下:
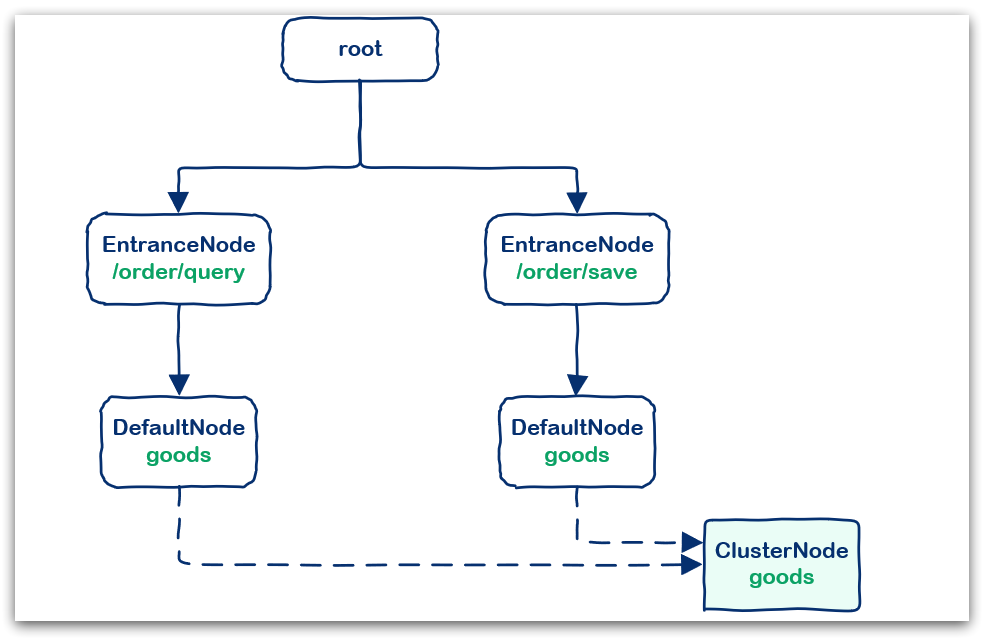
Entry
預設情況下,Sentinel會將controller中的方法作為被保護資源,那麼問題來了,我們該如何將自己的一段程式碼標記為一個Sentinel的資源呢?前面是用了 @SentinelResoutce 註解來實現的,那麼這個註解的原理是什麼?要搞清這玩意兒,那就得先來了解Entry這個吊毛玩意兒了
Sentinel中的資源用Entry來表示。宣告Entry的API範例:
// 資源名可使用任意有業務語意的字串,比如方法名、介面名或其它可唯一標識的字串。
try (Entry entry = SphU.entry("resourceName")) {
// 被保護的業務邏輯
// do something here...
} catch (BlockException ex) {
// 資源存取阻止,被限流或被降級
// 在此處進行相應的處理操作
}
原生方式自定義資源
- 在需要自定義資源的服務中引入依賴
<!--sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
- 設定Sentinel
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8089
- 對自定義資源的地方進行邏輯編寫
public Order queryOrderById(Long orderId) {
// 建立Entry,標記資源,資源名為resource1
try (Entry entry = SphU.entry("resource1")) {
// 1.查詢訂單,這裡是假資料
Order order = Order.build(101L, 4999L, "小米 MIX4", 1, 1L, null);
// 2.查詢使用者,基於Feign的遠端呼叫
User user = userClient.findById(order.getUserId());
// 3.設定
order.setUser(user);
// 4.返回
return order;
}catch (BlockException e){
log.error("被限流或降級", e);
return null;
}
}
開啟sentinel控制檯,檢視簇點鏈路:
@SentinelResoutce 註解標記資源
通過給方法新增@SentinelResource註解的形式來標記資源:
這是怎麼實現的?
Sentinel依賴中有自動裝配相關的東西,spring.factories宣告需要就是自動裝配的設定類,內容如下:
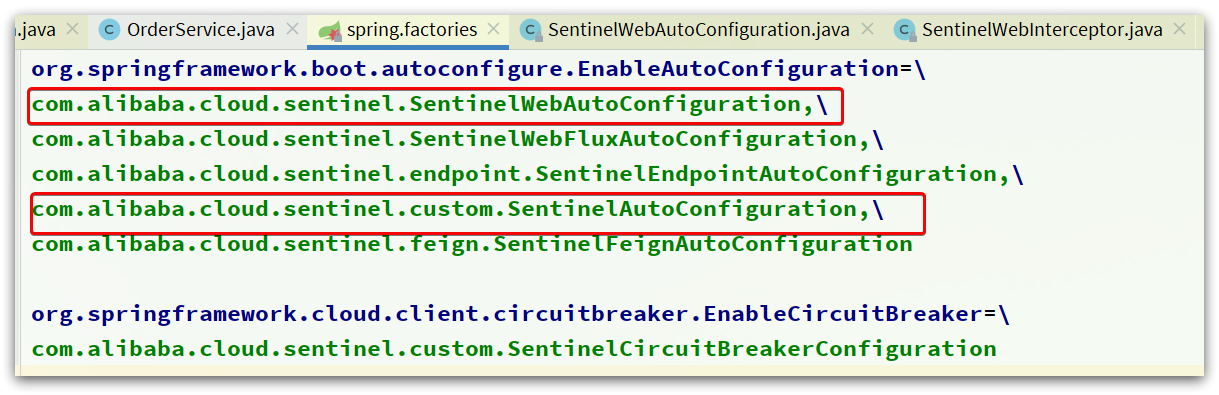
我們來看下SentinelAutoConfiguration這個類:
可以看到,在這裡宣告了一個Bean,SentinelResourceAspect:
/**
* Aspect for methods with {@link SentinelResource} annotation.
*
* @author Eric Zhao
*/
@Aspect
public class SentinelResourceAspect extends AbstractSentinelAspectSupport {
// 切點是新增了 @SentinelResource 註解的類
@Pointcut("@annotation(com.alibaba.csp.sentinel.annotation.SentinelResource)")
public void sentinelResourceAnnotationPointcut() {
}
// 環繞增強
@Around("sentinelResourceAnnotationPointcut()")
public Object invokeResourceWithSentinel(ProceedingJoinPoint pjp) throws Throwable {
// 獲取受保護的方法
Method originMethod = resolveMethod(pjp);
// 獲取 @SentinelResource 註解
SentinelResource annotation = originMethod.getAnnotation(SentinelResource.class);
if (annotation == null) {
// Should not go through here.
throw new IllegalStateException("Wrong state for SentinelResource annotation");
}
// 獲取註解上的資源名稱
String resourceName = getResourceName(annotation.value(), originMethod);
EntryType entryType = annotation.entryType();
int resourceType = annotation.resourceType();
Entry entry = null;
try {
// 建立資源 Entry
entry = SphU.entry(resourceName, resourceType, entryType, pjp.getArgs());
// 執行受保護的方法
Object result = pjp.proceed();
return result;
} catch (BlockException ex) {
return handleBlockException(pjp, annotation, ex);
} catch (Throwable ex) {
Class<? extends Throwable>[] exceptionsToIgnore = annotation.exceptionsToIgnore();
// The ignore list will be checked first.
if (exceptionsToIgnore.length > 0 && exceptionBelongsTo(ex, exceptionsToIgnore)) {
throw ex;
}
if (exceptionBelongsTo(ex, annotation.exceptionsToTrace())) {
traceException(ex);
return handleFallback(pjp, annotation, ex);
}
// No fallback function can handle the exception, so throw it out.
throw ex;
} finally {
if (entry != null) {
entry.exit(1, pjp.getArgs());
}
}
}
}
簡單來說,@SentinelResource註解就是一個標記,而Sentinel基於AOP思想,對被標記的方法做環繞增強,完成資源(Entry)的建立。
Context
上一節,我們發現簇點鏈路中除了controller方法、service方法兩個資源外,還多了一個預設的入口節點:
sentinel_spring_web_context,是一個EntranceNode型別的節點
這個節點是在初始化Context的時候由Sentinel幫我們建立的
什麼是Context?
- Context 代表呼叫鏈路上下文,貫穿一次呼叫鏈路中的所有資源(
Entry),基於ThreadLocal - Context 維持著入口節點(
entranceNode)、本次呼叫鏈路的 curNode(當前資源節點)、呼叫來源(origin)等資訊 - 後續的Slot都可以通過Context拿到DefaultNode或者ClusterNode,從而獲取統計資料,完成規則判斷
- Context初始化的過程中,會建立EntranceNode,contextName就是EntranceNode的名稱
對應的API如下:
// 建立context,包含兩個引數:context名稱、 來源名稱
ContextUtil.enter("contextName", "originName");
Context的初始化
Context又是在何時完成初始化的?
進入SentinelWebAutoConfiguration這個類:可以直接搜,可以去Sentinel依賴的Spring.factories中找
WebMvcConfigurer是SpringMVC自定義設定用到的類,可以設定HandlerInterceptor
SentinelWebInterceptor的宣告如下:
發繼承了AbstractSentinelInterceptor這個類。
AbstractSentinelInterceptor
HandlerInterceptor攔截器會攔截一切進入controller的方法,執行preHandle前置攔截方法,而Context的初始化就是在這裡完成的。
我們來看看這個類的preHandle實現:
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
throws Exception {
try {
// 獲取資源名稱,一般是controller方法的 @RequestMapping 路徑,例如/order/{orderId}
String resourceName = getResourceName(request);
if (StringUtil.isEmpty(resourceName)) {
return true;
}
// 從request中獲取請求來源,將來做 授權規則 判斷時會用
String origin = parseOrigin(request);
// 獲取 contextName,預設是sentinel_spring_web_context
String contextName = getContextName(request);
// 建立 Context
ContextUtil.enter(contextName, origin);
// 建立資源,名稱就是當前請求的controller方法的對映路徑
Entry entry = SphU.entry(resourceName, ResourceTypeConstants.COMMON_WEB, EntryType.IN);
request.setAttribute(baseWebMvcConfig.getRequestAttributeName(), entry);
return true;
} catch (BlockException e) {
try {
handleBlockException(request, response, e);
} finally {
ContextUtil.exit();
}
return false;
}
}
ContextUtil
建立Context的方法就是 ContextUtil.enter(contextName, origin);
進入該方法:
public static Context enter(String name, String origin) {
if (Constants.CONTEXT_DEFAULT_NAME.equals(name)) {
throw new ContextNameDefineException(
"The " + Constants.CONTEXT_DEFAULT_NAME + " can't be permit to defined!");
}
return trueEnter(name, origin);
}
進入trueEnter方法:
protected static Context trueEnter(String name, String origin) {
// 嘗試獲取context
Context context = contextHolder.get();
// 判空
if (context == null) {
// 如果為空,開始初始化
Map<String, DefaultNode> localCacheNameMap = contextNameNodeMap;
// 嘗試獲取入口節點
DefaultNode node = localCacheNameMap.get(name);
if (node == null) {
LOCK.lock();
try {
node = contextNameNodeMap.get(name);
if (node == null) {
// 入口節點為空,初始化入口節點 EntranceNode
node = new EntranceNode(new StringResourceWrapper(name, EntryType.IN), null);
// 新增入口節點到 ROOT
Constants.ROOT.addChild(node);
// 將入口節點放入快取
Map<String, DefaultNode> newMap = new HashMap<>(contextNameNodeMap.size() + 1);
newMap.putAll(contextNameNodeMap);
newMap.put(name, node);
contextNameNodeMap = newMap;
}
} finally {
LOCK.unlock();
}
}
// 建立Context,引數為:入口節點 和 contextName
context = new Context(node, name);
// 設定請求來源 origin
context.setOrigin(origin);
// 放入ThreadLocal
contextHolder.set(context);
}
// 返回
return context;
}
綜合流程
Seata 分散式事務
Seata是 2019 年 1 月份螞蟻金服和阿里巴巴共同開源的分散式事務解決方案。致力於提供高效能和簡單易用的分散式事務服務,為使用者打造一站式的分散式解決方案。
官網地址:http://seata.io/
CAP定理和Base理論
這兩個在前面弄Nacos的時候已經說過了
CAP定理 這是分散式事務中的一個方法論
- C 即:Consistency 資料一致性。指的是:使用者存取分散式系統中的任意節點,得到的資料必須一致
- A 即:Availability 可用性。指的是:使用者存取叢集中的任意健康節點,必須能得到響應,而不是超時或拒絕
- P 即:Partition Tolerance 分割區容錯性。指的是:由於某種原因導致系統中任意資訊的丟失或失敗都不能不會影響系統的繼續獨立運作
注: 分割區容錯性是必須滿足的,資料一致性( C )和 可用性( A )只滿足其一即可,一般的搭配是如下的(即:取捨策略):
- CP 保證資料的準確性
- AP 保證資料的及時性
既然CAP定理都整了,那就再加一個Base理論吧,這個理論是對CAP中C和A這兩個矛盾點的調和和選擇
- BA 即:Basically Available 基本可用性。指的是:在發生故障的時候,可以允許損失「非核心部分」的可用性,保證系統正常執行,即保證核心部分可用
- S 即:Soft State 軟狀態。指的是:允許系統的資料存在中間狀態,只要不影響整個系統的執行就行
- E 即:Eventual Consistency 最終一致性。指的是:無論以何種方式寫入資料庫 / 顯示出來,都要保證系統最終的資料是一致的
分散式事務最大問題就是各個子事務的資料一致性問題,由CAP定理和Base理論進行綜合之後,得出的分散式事務中的兩個模式:
- AP模式 ——–> 最終一致性:各個分支事務各自執行和提交,允許出現短暫的結果不一致,採用彌補措施將資料進行同步,從而恢復資料,達到最終資料一致
- CP模式 ——–> 強一致性:各個分支事務執行後互相等待,同時提交或回滾,達成資料的強一致性
Seata 的架構
Seata事務管理中有三個重要的角色:
- TC (Transaction Coordinator) - 事務協調者:維護全域性和分支事務的狀態,協調全域性事務提交或回滾
- TM (Transaction Manager) - 事務管理器:定義全域性事務的範圍、開始全域性事務、提交或回滾全域性事務
- RM (Resource Manager) - 資源管理器:管理分支事務處理的資源,與TC交談以註冊分支事務和報告分支事務的狀態,並驅動分支事務提交或回滾
Seata基於上述架構提供了四種不同的分散式事務解決方案:
- XA模式:強一致性分階段事務模式,犧牲了一定的可用性。無業務侵入
- AT模式:最終一致的分階段事務模式,也是Seata的預設模式。無業務侵入
- TCC模式:最終一致的分階段事務模式。有業務侵入
- SAGA模式:長事務模式。有業務侵入
無論哪種方案,都離不開TC,也就是事務的協調者
部署TC服務
- 下載Seata-Server 並 解壓。連結:https://github.com/seata/seata/releases 或 http://seata.io/zh-cn/blog/download.html
- 修改 conf/registry.conf 檔案
registry {
# TC服務的註冊中心 file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos"
# 設定Nacos註冊中心資訊
nacos {
application = "seata-tc-server"
serverAddr = "127.0.0.1:8848"
group = "DEFAULT_GROUP"
namespace = ""
cluster = "HZ"
username = "nacos"
password = "nacos"
}
}
config {
# 設定中心:讀取TC伺服器端的組態檔的方式,這裡是從nacos設定中心讀取,這樣如果tc是叢集,可以共用設定
# file、nacos 、apollo、zk、consul、etcd3
type = "nacos"
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "DEFAULT_GROUP"
username = "nacos"
password = "nacos"
dataId = "seataServer.properties"
}
}
- 在Nacos的控制檯設定管理中設定2中的 seataServer.properties,內容如下:
# 資料儲存方式,db代表資料庫
store.mode=db
store.db.datasource=druid
store.db.dbType=mysql
store.db.driverClassName=com.mysql.jdbc.Driver
store.db.url=jdbc:mysql://127.0.0.1:3306/seata?useUnicode=true&rewriteBatchedStatements=true
store.db.user=root
store.db.password=zixieqing072413
store.db.minConn=5
store.db.maxConn=30
store.db.globalTable=global_table
store.db.branchTable=branch_table
store.db.queryLimit=100
store.db.lockTable=lock_table
store.db.maxWait=5000
# 事務、紀錄檔等設定
server.recovery.committingRetryPeriod=1000
server.recovery.asynCommittingRetryPeriod=1000
server.recovery.rollbackingRetryPeriod=1000
server.recovery.timeoutRetryPeriod=1000
server.maxCommitRetryTimeout=-1
server.maxRollbackRetryTimeout=-1
server.rollbackRetryTimeoutUnlockEnable=false
server.undo.logSaveDays=7
server.undo.logDeletePeriod=86400000
# 使用者端與伺服器端傳輸方式
transport.serialization=seata
transport.compressor=none
# 關閉metrics功能,提高效能
metrics.enabled=false
metrics.registryType=compact
metrics.exporterList=prometheus
metrics.exporterPrometheusPort=9898
- 建立資料庫表:tc服務在管理分散式事務時,需要記錄事務相關資料到資料庫中(3中設定了的)
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- 分支事務表
-- ----------------------------
DROP TABLE IF EXISTS `branch_table`;
CREATE TABLE `branch_table` (
`branch_id` bigint(20) NOT NULL,
`xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`resource_group_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`branch_type` varchar(8) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`status` tinyint(4) NULL DEFAULT NULL,
`client_id` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime(6) NULL DEFAULT NULL,
`gmt_modified` datetime(6) NULL DEFAULT NULL,
PRIMARY KEY (`branch_id`) USING BTREE,
INDEX `idx_xid`(`xid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
-- ----------------------------
-- 全域性事務表
-- ----------------------------
DROP TABLE IF EXISTS `global_table`;
CREATE TABLE `global_table` (
`xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`status` tinyint(4) NOT NULL,
`application_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_service_group` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`timeout` int(11) NULL DEFAULT NULL,
`begin_time` bigint(20) NULL DEFAULT NULL,
`application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime NULL DEFAULT NULL,
`gmt_modified` datetime NULL DEFAULT NULL,
PRIMARY KEY (`xid`) USING BTREE,
INDEX `idx_gmt_modified_status`(`gmt_modified`, `status`) USING BTREE,
INDEX `idx_transaction_id`(`transaction_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
SET FOREIGN_KEY_CHECKS = 1;
- 啟動seat-server
- 驗證是否成功
Spring Cloud整合Seata
- 依賴
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<exclusions>
<!--版本較低,1.3.0,因此排除-->
<exclusion>
<artifactId>seata-spring-boot-starter</artifactId>
<groupId>io.seata</groupId>
</exclusion>
</exclusions>
</dependency>
<!--seata starter 採用1.4.2版本-->
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>${seata.version}</version>
</dependency>
- 給需要註冊到TC的微服務的YAML檔案設定如下內容:
seata:
registry: # TC服務註冊中心的設定,微服務根據這些資訊去註冊中心獲取tc服務地址 參考tc服務自己的registry.conf中的設定
type: nacos
nacos: # tc
server-addr: 127.0.0.1:8848
namespace: ""
group: DEFAULT_GROUP
application: seata-tc-server # tc服務在nacos中的服務名稱
tx-service-group: seata-demo # 事務組,根據這個獲取tc服務的cluster名稱
service:
vgroup-mapping: # 事務組與TC服務cluster的對映關係
seata-demo: HZ
經過如上操作就整合成功了
分散式事務之XA模式
XA 規範 是 X/Open 組織定義的分散式事務處理(DTP,Distributed Transaction Processing)標準,XA 規範 描述了全域性的TM與區域性的RM之間的介面,幾乎所有主流的資料庫都對 XA 規範 提供了支援。實現的原理都是基於兩階段提交
- 正常情況:
- 異常情況:
一階段:
- 事務協調者通知每個事務參與者執行本地事務
- 本地事務執行完成後報告事務執行狀態給事務協調者,此時事務不提交,繼續持有資料庫鎖
二階段:
- 事務協調者基於一階段的報告來判斷下一步操作
- 如果一階段都成功,則通知所有事務參與者,提交事務
- 如果一階段任意一個參與者失敗,則通知所有事務參與者回滾事務
Seata之XA模式 - 強一致性
應用場景: 並行量不大,但資料很重要的專案
Seata對原始的XA模式做了簡單的封裝和改造,以適應自己的事務模型
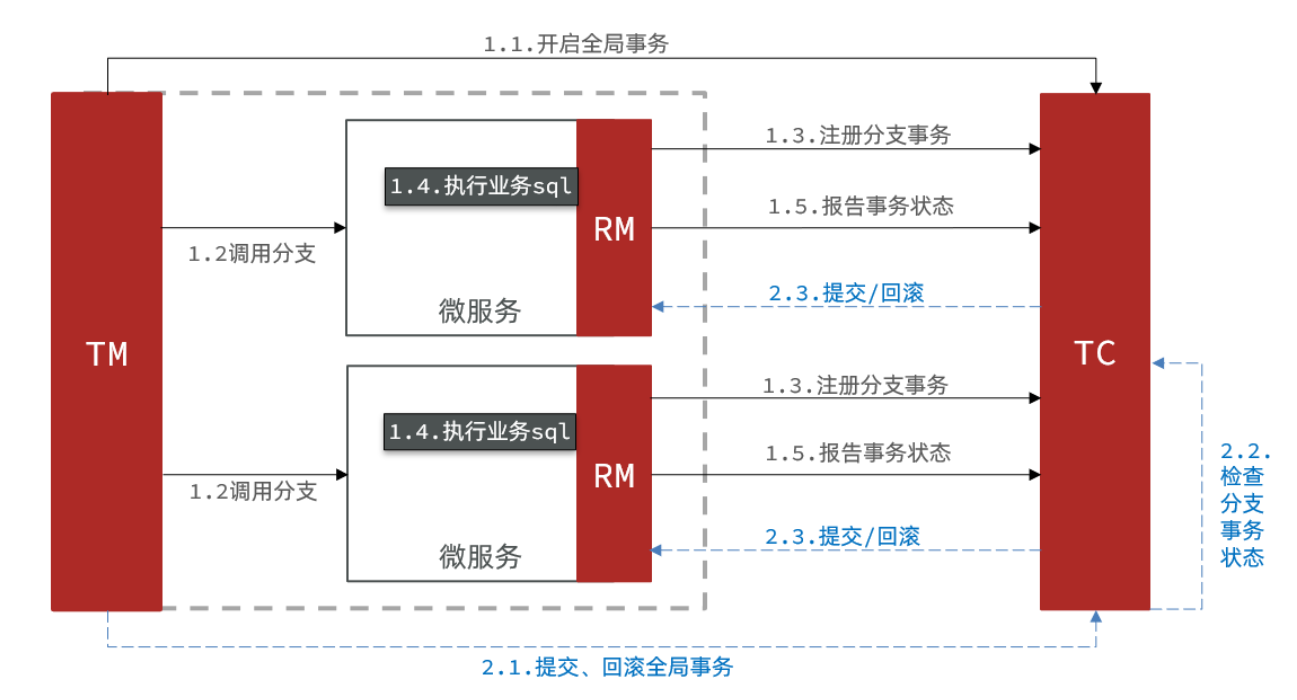
RM一階段的工作:
- 註冊分支事務到TC
- 執行分支業務sql但不提交
- 報告執行狀態到TC
TC二階段的工作:TC檢測各分支事務執行狀態
- 如果都成功,通知所有RM提交事務
- 如果有失敗,通知所有RM回滾事務
RM二階段的工作:
- 接收TC指令,提交或回滾事務
XA模式的優點:
- 事務的強一致性,滿足ACID原則
- 常用資料庫都支援,實現簡單,並且沒有程式碼侵入
XA模式的缺點:
- 因為一階段需要鎖定資料庫資源,等待二階段結束才釋放,效能較差
- 依賴關係型資料庫實現事務
Java實現Seata的XA模式
- 修改註冊到TC的微服務的YAML設定
seata:
data-source-proxy-mode: XA # 開啟XA模式
- 給發起全域性事務的入口方法新增 @GlobalTransactional 註解。就是要開啟事務的方法,如下:
- 重啟服務即可成功實現XA模式了
Seata之AT模式 - 最終一致性
AT模式同樣是分階段提交的事務模型,不過卻彌補了XA模型中資源鎖定週期過長的缺陷
應用場景: 高並行網際網路應用,允許資料出現短時不一致
基本架構圖:
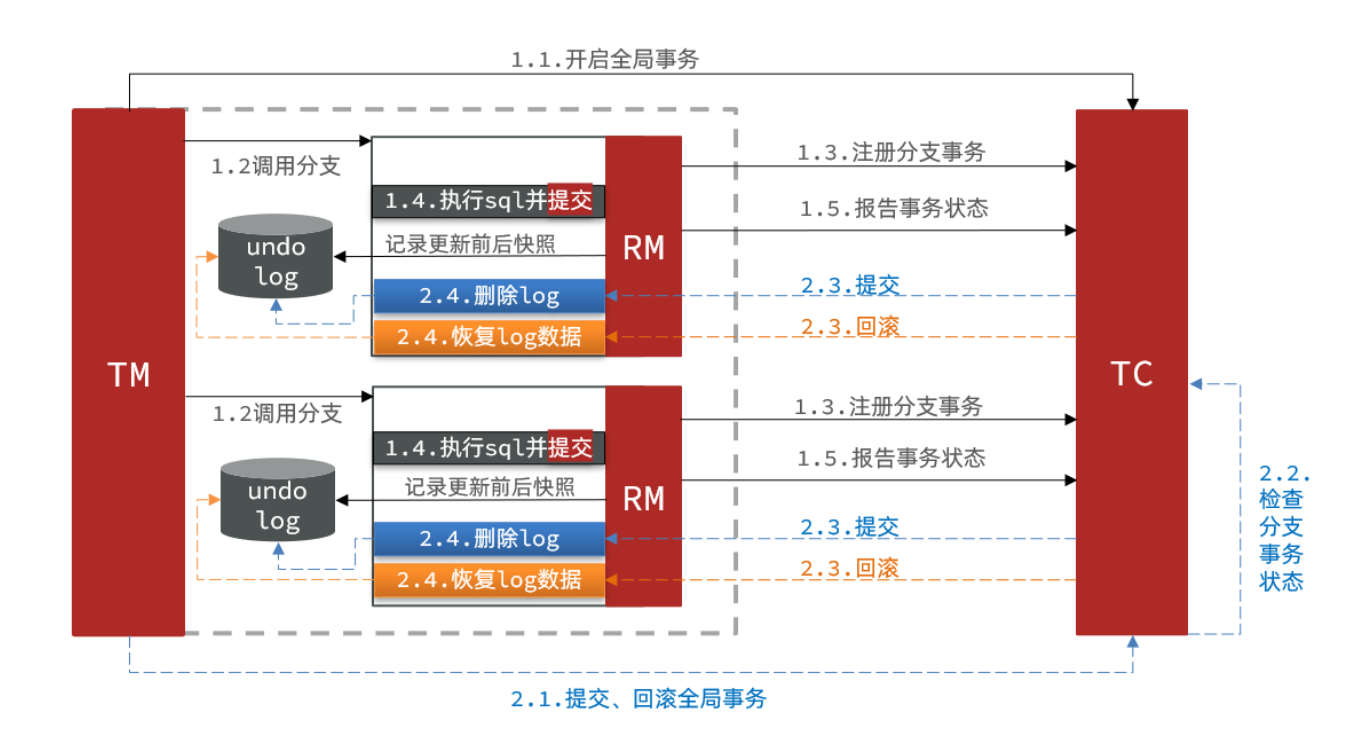
RM階段一的工作:
- 註冊分支事務
- 記錄undo-log(資料快照)
- 執行業務sql並提交
- 報告事務狀態
階段二提交時RM的工作:刪除undo-log即可
階段二回滾時RM的工作:根據undo-log恢復資料到更新前。恢復資料之後也會把undo-log中的資料刪掉
流程圖如下:
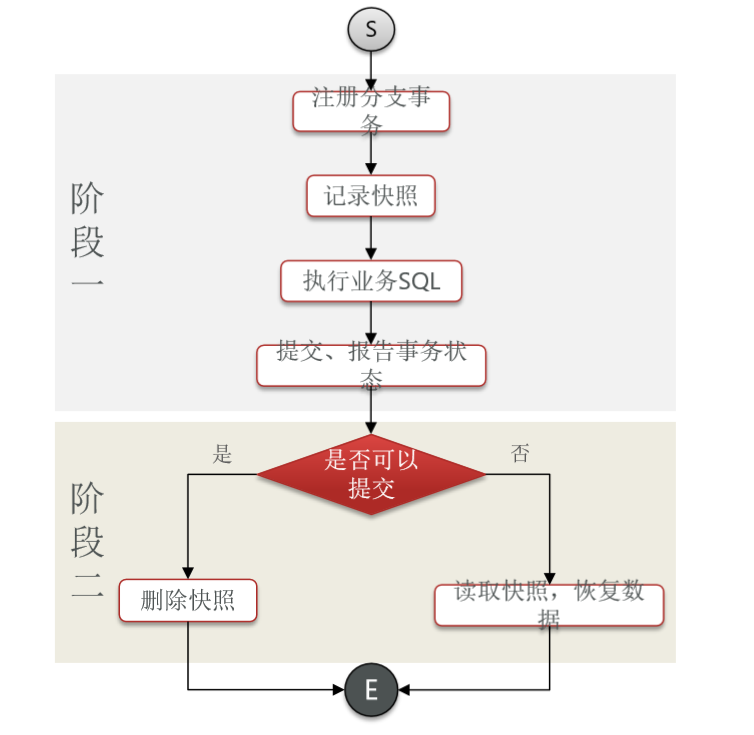
AT模式與XA模式的區別是什麼?
- XA模式一階段不提交事務,鎖定資源;AT模式一階段直接提交,不鎖定資源。
- XA模式依賴資料庫機制實現回滾;AT模式利用資料快照實現資料回滾。
- XA模式強一致;AT模式最終一致
AT模式的髒寫問題
解決思路就是引入了全域性鎖的概念。在釋放DB鎖之前,先拿到全域性鎖。避免同一時刻有另外一個事務來操作當前資料,從而來做到寫隔離
- 全域性鎖: 由TC記錄當前正在執行資料的事務,該事務持有全域性鎖,具備執行權

但就算引入了全域性鎖,也還會有BUG,因為上面兩個事務都是Seata管理,若事務1是Seata管理,而事務2是非Seata管理,同時這兩個事務都在修改同一條資料,那麼就還會造成髒寫問題
為了防止這個問題,Seata在儲存快照時實際上會記錄2份快照,一份是修改之前的快照,一份是修改之後的快照
-
在恢復快照資料時,會將更新後的快照值和當前資料庫的實際值進行比對(類似CAS過程)
如果數值不匹配則說明在此期間有另外的事務修改了資料,此時直接釋放全域性鎖,事務1記錄異常,傳送告警資訊讓人工介入
如果一致則恢復資料,釋放全域性鎖即可
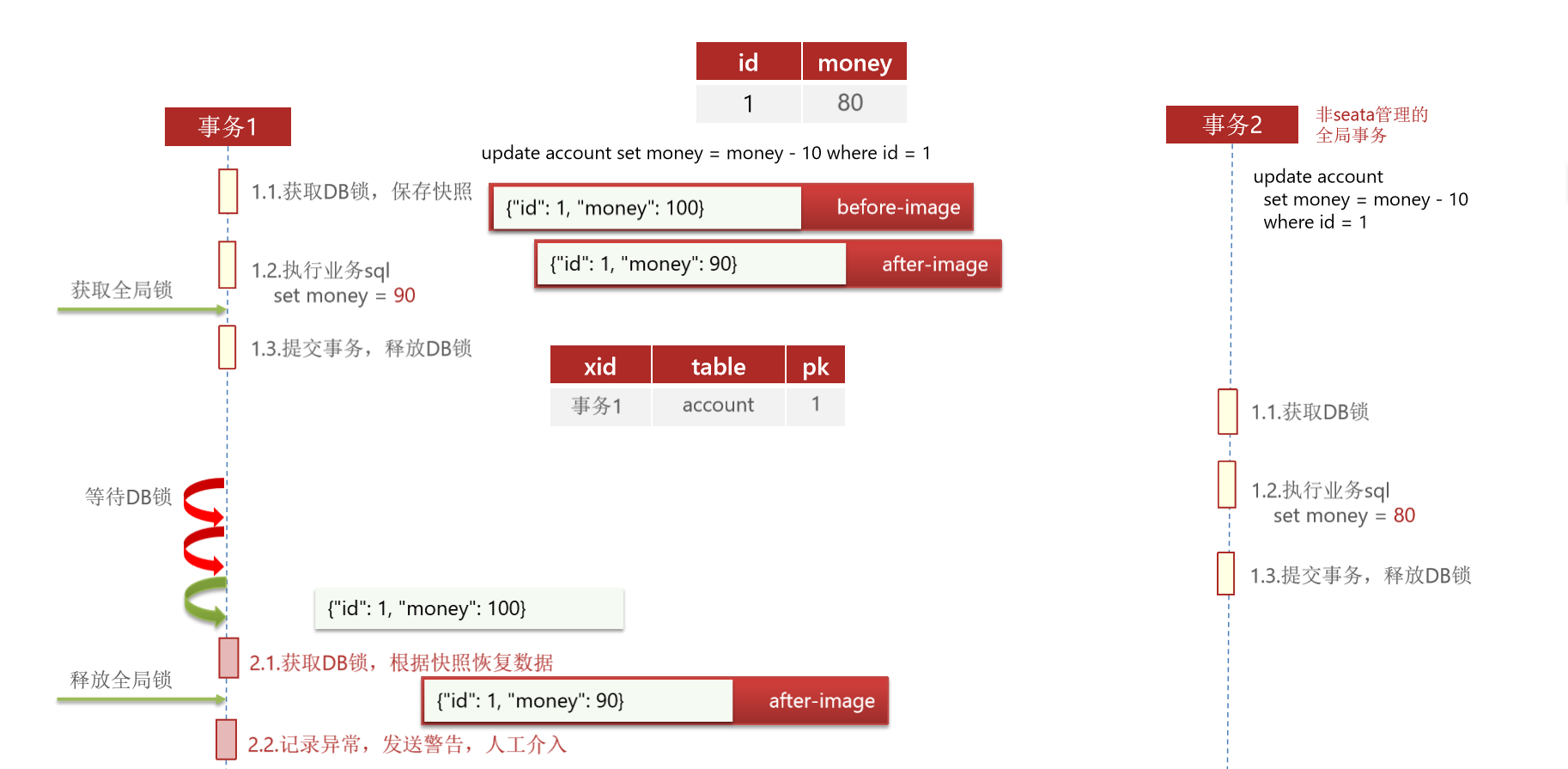
AT模式的優點:
- 一階段完成直接提交事務,釋放資料庫資源,效能比較好
- 利用全域性鎖實現讀寫隔離
- 沒有程式碼侵入,框架自動完成回滾和提交
AT模式的缺點:
- 兩階段之間屬於軟狀態,屬於最終一致
- 框架的快照功能會影響效能,但比XA模式要好很多
Java實現AT模式
AT模式中的快照生成、回滾等動作都是由框架自動完成,沒有任何程式碼侵入
只不過,AT模式需要一個表來記錄全域性鎖、另一張表來記錄資料快照undo_log。其中:
- lock_table表:需要放在「TC服務關聯」的資料庫中。例如表結構如下:
DROP TABLE IF EXISTS `lock_table`;
CREATE TABLE `lock_table` (
`row_key` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`xid` varchar(96) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`branch_id` bigint(20) NOT NULL,
`resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`table_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`pk` varchar(36) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime NULL DEFAULT NULL,
`gmt_modified` datetime NULL DEFAULT NULL,
PRIMARY KEY (`row_key`) USING BTREE,
INDEX `idx_branch_id`(`branch_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
- undo_log表 :需要放在「微服務關聯」的資料庫中。例如表結構如下:
DROP TABLE IF EXISTS `undo_log`;
CREATE TABLE `undo_log` (
`branch_id` bigint(20) NOT NULL COMMENT 'branch transaction id',
`xid` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT 'global transaction id',
`context` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` longblob NOT NULL COMMENT 'rollback info',
`log_status` int(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` datetime(6) NOT NULL COMMENT 'create datetime',
`log_modified` datetime(6) NOT NULL COMMENT 'modify datetime',
UNIQUE INDEX `ux_undo_log`(`xid`, `branch_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = 'AT transaction mode undo table' ROW_FORMAT = Compact;
然後修改註冊到TC中的微服務的YAML設定,最後重啟服務,模式就變為AT模式了
seata:
data-source-proxy-mode: AT # 預設就是AT
Seata之TCC模式 - 最終一致性
應用場景: 高並行網際網路應用,允許資料出現短時不一致,可通過對賬程式或補錄來保證最終一致性
TCC模式與AT模式非常相似,每階段都是獨立事務,不同的是TCC通過人工編碼來實現資料恢復。需要實現三個方法:
- Try:資源的檢測和預留
- Confirm:完成資源操作業務;要求 Try 成功 Confirm 一定要能成功
- Cancel:預留資源釋放,可以理解為try的反向操作。
舉例說明三個方法:一個扣減使用者餘額的業務。假設賬戶A原來餘額是100,需要餘額扣減30元

TCC模式的架構
TCC模式的每個階段是做什麼的?
- Try:資源檢查和預留
- Confirm:業務執行和提交
- Cancel:預留資源的釋放
TCC的優點是什麼?
- 一階段完成直接提交事務,釋放資料庫資源,效能好
- 相比AT模型,無需生成快照,無需使用全域性鎖,效能最強
- 不依賴資料庫事務,而是依賴補償操作,可以用於非事務型資料庫(如:Redis)
TCC的缺點是什麼?
- 有程式碼侵入,需要人為編寫try、Confirm和Cancel介面,太麻煩
- 軟狀態,事務是最終一致
- 需要考慮Confirm和Cancel的失敗情況,做好冪等處理
空回滾和業務懸掛
空補償 / 空回滾: 未執行try(原服務)就執行了cancel(補償服務)。即當某分支事務的try階段阻塞時,可能導致全域性事務超時而觸發二階段的cancel操作。在未執行try操作時先執行了cancel操作,這時cancel不能做回滾,就是「空回滾」
因此:執行cancel操作時,應當判斷try是否已經執行,如果尚未執行,則應該空回滾
業務懸掛: 已經空回滾的業務,之前阻塞的try恢復了,然後繼續執行try,之後就永不可能執行confirm或cancel,從而變成「業務懸掛」
因此:執行try操作時,應當判斷cancel是否已經執行過了,如果已經執行,應當阻止空回滾後的try操作,避免懸掛
Java實現TCC模式範例
Try業務:
- 根據xid查詢account_freeze ,如果已經存在則證明Cancel已經執行,拒絕執行try業務
- 記錄凍結金額和事務狀態到account_freeze表
- 扣減account表可用金額
Confirm業務
- 需判斷此方法的冪等性問題
- 根據xid刪除account_freeze表的凍結記錄
Cancel業務
- 需判斷此方法的冪等性問題
- 根據xid查詢account_freeze,如果為null則說明try還沒做,需要空回滾
- 修改account_freeze表,凍結金額為0,state為2
- 修改account表,恢復可用金額
- 在業務管理的庫中建表:是為了實現空回滾、防止業務懸掛,以及冪等性要求。所以在資料庫記錄凍結金額的同時,記錄當前事務id和執行狀態
CREATE TABLE `account_freeze_tbl` (
`xid` varchar(128) NOT NULL COMMENT '全域性事務id',
`user_id` varchar(255) DEFAULT NULL COMMENT '使用者id',
`freeze_money` int(11) unsigned DEFAULT '0' COMMENT '凍結金額',
`state` int(1) DEFAULT NULL COMMENT '事務狀態,0:try,1:confirm,2:cancel',
PRIMARY KEY (`xid`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT
- 業務介面定義try+confirm+cancel三個方法
package com.zixieqing.account.service;
import io.seata.rm.tcc.api.BusinessActionContext;
import io.seata.rm.tcc.api.BusinessActionContextParameter;
import io.seata.rm.tcc.api.LocalTCC;
import io.seata.rm.tcc.api.TwoPhaseBusinessAction;
import org.springframework.stereotype.Service;
/**
* Seata之TCC模式實現業務的account介面
*
* "@LocalTCC" SpringCloud + Feign,Feign的呼叫基於http
* 此註解所在的介面需要實現TCC的兩階段提交對應方法才行
*
* <p>@author : ZiXieqing</p>
*/
@Service
@LocalTCC
public interface AccountTccService {
/**
* 扣款
*
* Try邏輯 資源檢查和預留,同時需要判斷Cancel是否已經執行,是則拒絕執行本次業務
*
* "@TwoPhaseBusinessAction" 中
* name屬性要與當前方法名一致,用於指定Try邏輯對應的方法
* commitMethod屬性值就是confirm邏輯的方法
* rollbackMethod屬性值就是cancel邏輯的方法
*
* "@BusinessActionContextParameter" 將指定的引數傳遞給confirm和cancel
*
* @param userId 使用者id
* @param money 要扣的錢
*/
@TwoPhaseBusinessAction(
name = "deduct",
commitMethod = "confirm",
rollbackMethod = "cancel"
)
void deduct(@BusinessActionContextParameter(paramName = "userId") String userId,
@BusinessActionContextParameter(paramName = "money") int money);
/**
* 二階段confirm確認方法 業務執行和提交 另外需考慮冪等性問題
* 方法名可以另命名,但需保證與commitMethod一致
*
* @param context 上下文,可以傳遞try方法的引數
* @return boolean 執行是否成功
*/
boolean confirm(BusinessActionContext context);
/**
* 二階段回滾方法 預留資源釋放 另外需考慮冪等性問題 需要判斷try是否已經執行,否就需要空回滾
* 方法名須保證與rollbackMethod一致
*
* @param context 上下文,可以傳遞try方法的引數
* @return boolean 執行是否成功
*/
boolean cancel(BusinessActionContext context);
}
- 實現類邏輯編寫
package com.zixieqing.account.service.impl;
import com.zixieqing.account.entity.AccountFreeze;
import com.zixieqing.account.mapper.AccountFreezeMapper;
import com.zixieqing.account.mapper.AccountMapper;
import com.zixieqing.account.service.AccountTccService;
import io.seata.core.context.RootContext;
import io.seata.rm.tcc.api.BusinessActionContext;
import org.springframework.beans.factory.annotation.Autowired;
/**
* 扣款業務
*
* <p>@author : ZiXieqing</p>
*/
public class AccountTccServiceImpl implements AccountTccService {
@Autowired
private AccountMapper accountMapper;
@Autowired
private AccountFreezeMapper accountFreezeMapper;
/**
* 扣款
*
* Try邏輯 資源檢查和預留,同時需要判斷Cancel是否已經執行,是則拒絕執行本次業務
*
* "@TwoPhaseBusinessAction" 中
* name屬性要與當前方法名一致,用於指定Try邏輯對應的方法
* commitMethod屬性值就是confirm邏輯的方法
* rollbackMethod屬性值就是cancel邏輯的方法
*
* "@BusinessActionContextParameter" 將指定的引數傳遞給confirm和cancel
*
* @param userId 使用者id
* @param money 要扣的錢
*/
@Override
public void deduct(String userId, int money) {
// 獲取事務ID,RootContext 是seata中的
String xid = RootContext.getXID();
AccountFreeze accountFreeze = accountFreezeMapper.selectById(xid);
// 業務懸掛處理:判斷cancel是否已經執行,若執行過則free表中肯定有資料
if (accountFreeze == null) {
// 進行扣款
accountMapper.deduct(userId, money);
// 記錄本次狀態
AccountFreeze freeze = new AccountFreeze();
freeze.setXid(xid)
.setUserId(userId)
.setFreezeMoney(money)
.setState(AccountFreeze.State.TRY);
accountFreezeMapper.insert(freeze);
}
}
/**
* 二階段confirm確認方法 業務執行和提交 另外需考慮冪等性問題
* 方法名可以另命名,但需保證與commitMethod一致
*
* @param context 上下文,可以傳遞try方法的引數
* @return boolean 執行是否成功
*/
@Override
public boolean confirm(BusinessActionContext context) {
// 刪掉freeze表中的記錄即可 delete方法本身就具有冪等性
return accountFreezeMapper.deleteById(context.getXid()) == 1;
}
/**
* 二階段回滾方法 預留資源釋放 另外需考慮冪等性問題 需要判斷try是否已經執行,否 就需要空回滾
* 方法名須保證與rollbackMethod一致
*
* @param context 上下文,可以傳遞try方法的引數
* @return boolean 執行是否成功
*/
@Override
public boolean cancel(BusinessActionContext context) {
// 空回滾處理:判斷try是否已經執行
AccountFreeze freeze = accountFreezeMapper.selectById(context.getXid());
// 若為null,則try肯定沒執行
if (freeze == null) {
// 需要進行空回滾
freeze = new AccountFreeze();
freeze.setXid(context.getXid())
// getActionContext("userId") 的key就是@BusinessActionContextParameter(paramName = "userId")的pramName值
.setUserId(context.getActionContext("userId").toString())
.setFreezeMoney(0)
.setState(AccountFreeze.State.CANCEL);
return accountFreezeMapper.updateById(freeze) == 1;
}
// 冪等性處理
if (freeze.getState() == AccountFreeze.State.CANCEL) {
// 說明已經執行過一次cancel了,直接拒絕執行本次業務
return true;
}
// 不為null,則回滾資料
accountMapper.refund(freeze.getUserId(), freeze.getFreezeMoney());
// 將凍結金額歸0,並修改本次狀態
freeze.setFreezeMoney(0)
.setState(AccountFreeze.State.CANCEL);
return accountFreezeMapper.updateById(freeze) == 1;
}
}
最後正常使用service呼叫使用3中的實現類即可
Seata之Saga模式 - 最終一致性
Saga 模式是 Seata 的長事務解決方案,由螞蟻金服主要貢獻
其理論基礎是Hector & Kenneth 在1987年發表的論文Sagas
Seata官網對於Saga的指南:https://seata.io/zh-cn/docs/user/saga.html
適用場景:
- 業務流程長、,業務流程多且需要保證事務最終一致性的業務系統
- 銀行業金融機構
- 需要與第三方互動,如:呼叫支付寶支付介面->出庫失敗->呼叫支付寶退款介面
優點:
- 事務參與者可以基於事件驅動實現非同步呼叫,吞吐高
- 一階段直接提交事務,無鎖,效能好
- 不用編寫TCC中的三個階段,實現簡單
缺點:
- 軟狀態持續時間不確定,時效性差
- 由於一階段已經提交本地資料庫事務,且沒有進行「預留」動作,所以不能保證隔離性,同時也沒有鎖,所以會有髒寫
Saga模式是SEATA提供的長事務解決方案。也分為兩個階段:
- 一階段:直接提交本地事務
- 二階段:成功則什麼都不做;失敗則通過編寫補償業務來回滾
Saga 是一種補償協定,Saga 正向服務與補償服務也需要業務開發者實現。在 Saga 模式下,分散式事務內有多個參與者,每一個參與者都是一個衝正補償服務,需要使用者根據業務場景實現其正向操作和逆向回滾操作。
分散式事務執行過程中,依次執行各參與者的正向操作,如果所有正向操作均執行成功,那麼分散式事務提交;如果任何一個正向操作執行失敗,那麼分散式事務會退回去執行前面各參與者的逆向回滾操作,回滾已提交的參與者,使分散式事務回到初始狀態
Seata四種模式對比
| XA | AT | TCC | SAGA | |
|---|---|---|---|---|
| 一致性 | 強一致 | 弱一致 | 弱一致 | 最終一致 |
| 隔離性 | 完全隔離 | 基於全域性鎖隔離 | 基於資源預留隔離 | 無隔離 |
| 程式碼侵入 | 無 | 無 | 有,要編寫三個介面 | 有,要編寫狀態機和補償業務 |
| 效能 | 差 | 好 | 非常好 | 非常好 |
| 場景 | 對一致性、隔離性有高要求的業務 | 基於關係型資料庫的大多數分散式事務場景都可以 | 對效能要求較高的事務。有非關係型資料庫要參與的事務 | 業務流程長、業務流程多參與者包含其它公司或遺留系統服務,無法提供 TCC 模式要求的三個介面 |