快速生成一組環形資料
2023-11-23 18:00:33
sklearn是一個開源的機器學習庫,支援不同種類的機器學習演演算法,並且提供了許多質量良好的資料集。假如我們想要得到一組環形資料集,藉助sklearn的包很輕易就可以實現,不過換個角度思考,我們自己動手是否也可以生成一組資料,使之在散點圖上環狀分佈;藉助C++的random標頭檔案以及一點高中數學知識,我們很快也可以打造屬於自己的資料集。
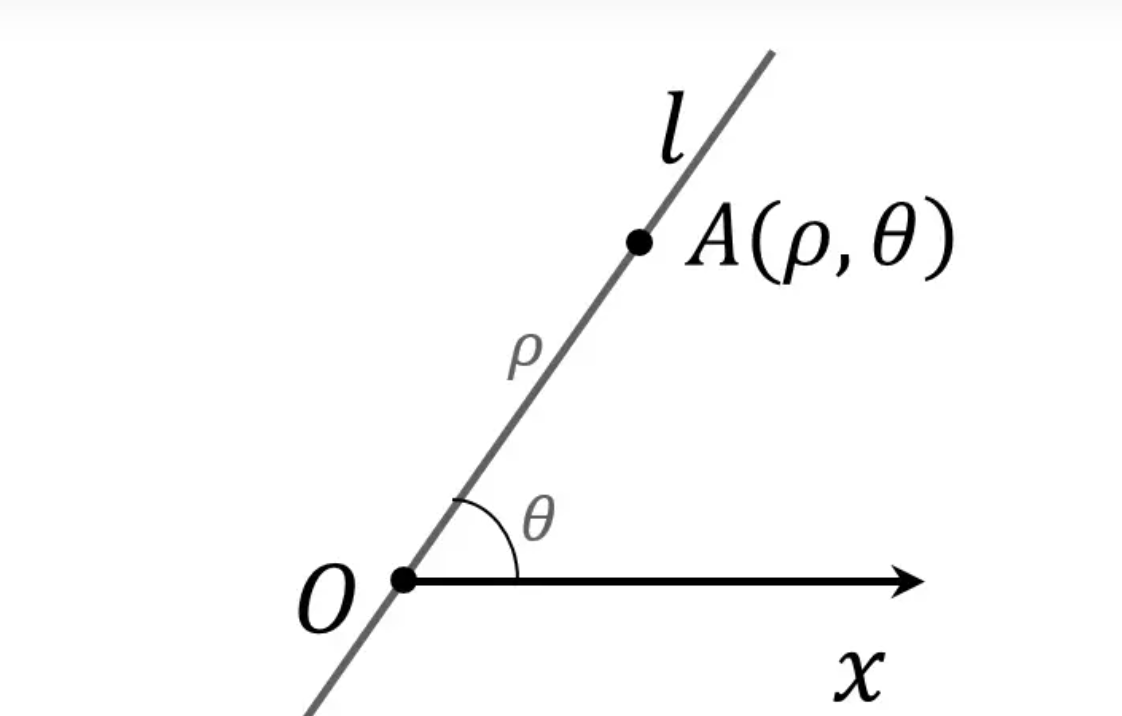
簡單回顧一下,ρ與x和y之間的關係,y=ρsin(θ),x=ρcos(θ)。這是第一象限的情況,對於其它象限,只需要注意角度和符號的關係便可。
#include <iostream>
#include <fstream>
#include <random>
#include <string>
#include <utility>
#include <cmath>
std::random_device rd;
std::mt19937 g(rd());
std::uniform_real_distribution dis(0.0, M_PI * 2);
std::pair<double, double> circleData(double radius) {
double tolerance = radius / (30.0 + dis(g));
int n;
double d = dis(g);
if (d < M_PI)
n = 1;
else
n = -1;
double r = radius + n * tolerance * dis(g);
double x, y;
double sita = dis(g);
double mapping = sita / (M_PI / 2);
if (mapping < 1.0) {
x = r * cos(sita);
y = r * sin(sita);
} else if (mapping < 2.0) {
x = -r * cos(M_PI - sita);
y = r * sin(M_PI - sita);
} else if (mapping < 3.0) {
x = -r * cos(sita - M_PI);
y = -r * sin(sita - M_PI);
} else {
x = r * cos(2 * M_PI - sita);
y = -r * sin(2 * M_PI - sita);
}
return std::pair<double, double>{x, y};
}
void generateData(const std::string& path, std::size_t n = 1000, double radius = 1000.0) {
std::ofstream out{path};
out << "X,Y\n";
for (std::size_t i{}; i < n; ++i) {
std::pair<double, double> pii = circleData(radius);
std::string str = std::to_string(pii.first) + ',' + std::to_string(pii.second) + '\n';
out << str;
}
}
int main() {
std::string str{};
std::cin >> str;
generateData(str);
}需要額外補充幾點:1.生成的資料並不必完全呈環狀,有稍微的偏差更加符合隨機性,所以這裡定義了tolerance變數,允許在半徑範圍內有一定的誤差。2.生成的資料會寫入csv格式的檔案當中,而csv格式下的資料說白了就是一堆以逗號作為分割界限的字串,後面用藉助Python的pandas庫便能很容易地對csv格式檔案進行解析。3.為了確定隨機生成的角度屬於哪一象限,只需要除以(pi/2)即可判斷,浮點數比較帶來的精度丟失可接受。
接下來開啟Python的編輯器,只需要寫入下列程式碼:
import pandas as pd
import matplotlib.pyplot as plt
def f():
file = 'data.csv'
data = pd.read_csv(file)
x = data['X']
y = data['Y']
plt.scatter(x, y)
plt.title('Circle Data')
plt.xlabel('X')
plt.ylabel('Y')
plt.show()
if __name__ == '__main__':
f() 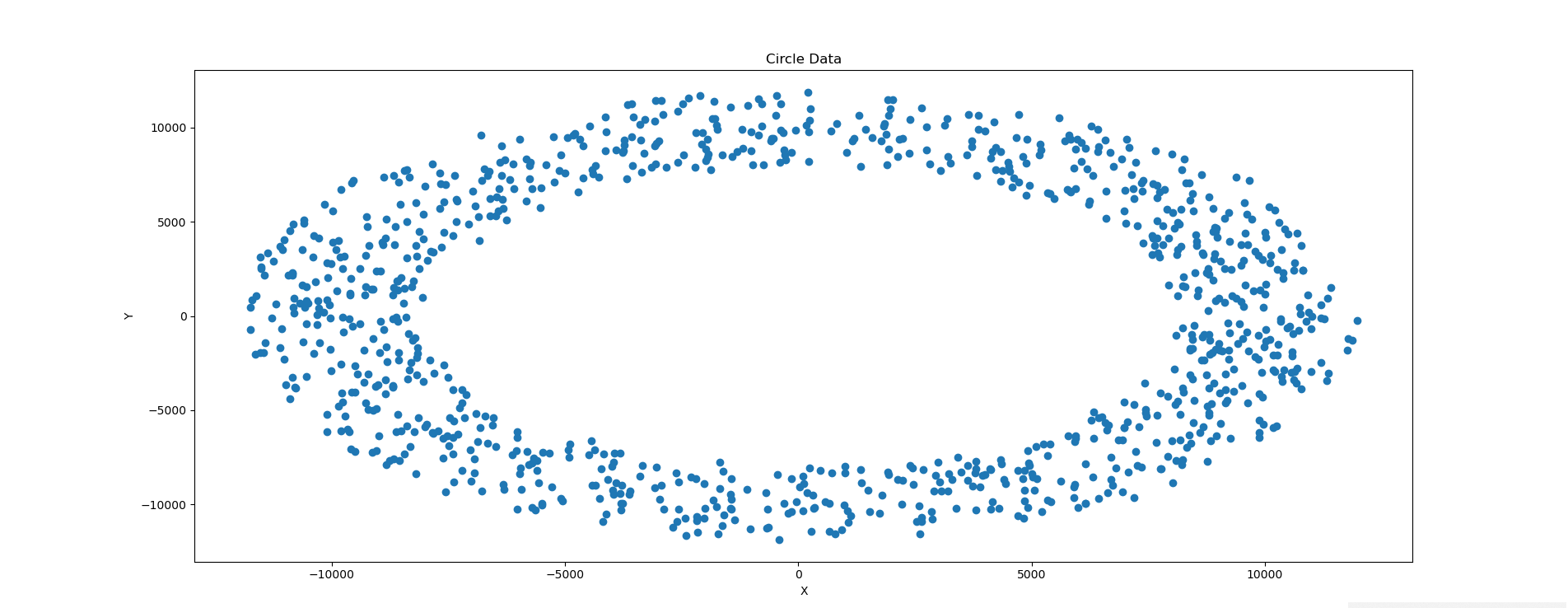
這是在半徑為10000時的效果,為了多作幾組對比,我們分別選取半徑為100,1000的圖片進行測試。
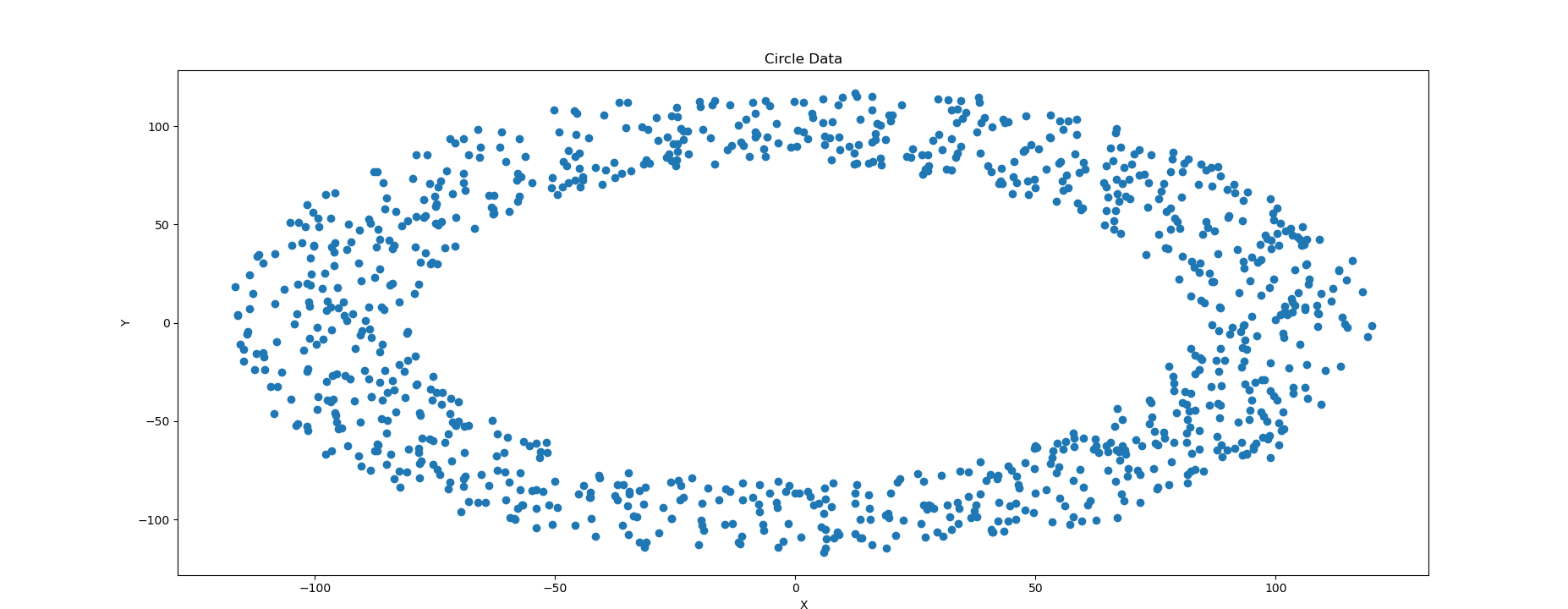
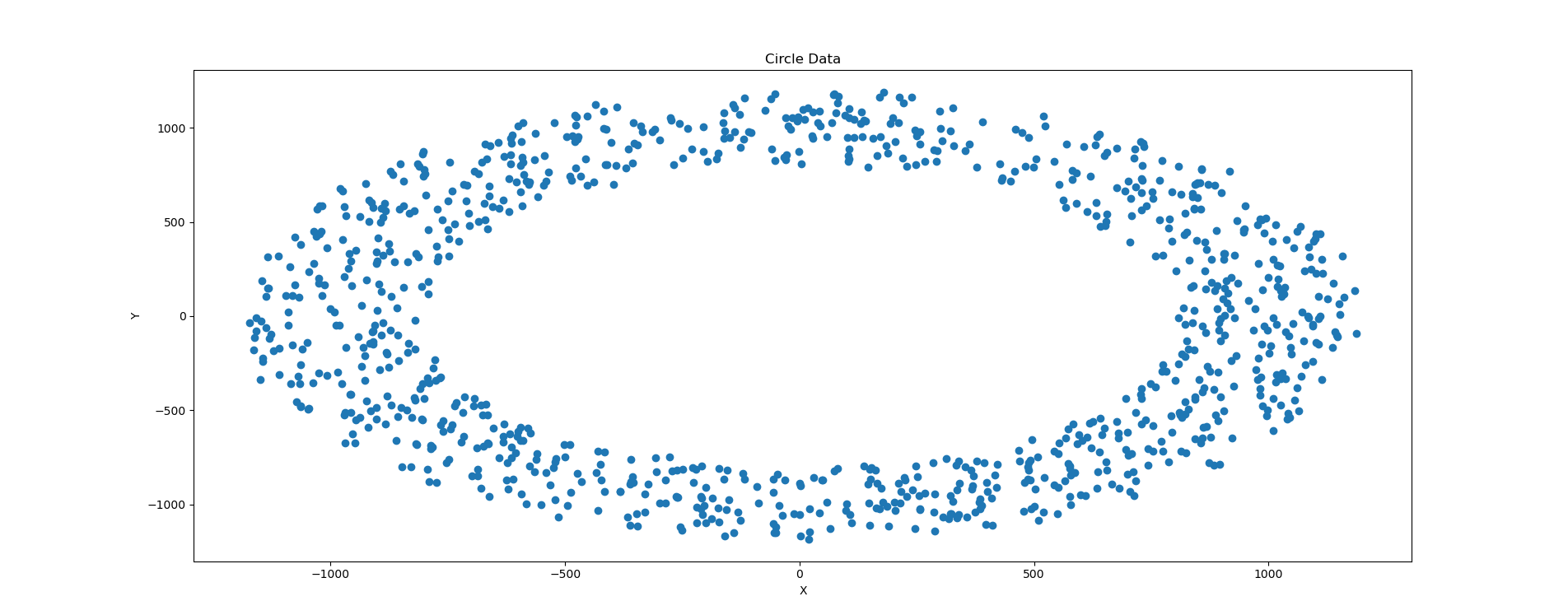
總結:效果看上去都還不錯,不過並不一定任何時候都能滿足需求,可以對程式碼當中的引數進行一定的調整,生成更符合預期的資料集。