C++ LibCurl實現Web指紋識別
Web指紋識別是一種通過分析Web應用程式的特徵和後設資料,以確定應用程式所使用的技術棧和設定的技術。這項技術旨在識別Web伺服器、Web應用框架、後端資料庫、JavaScript庫等元件的版本和設定資訊。通過分析HTTP響應頭、HTML原始碼、JavaScript程式碼、CSS檔案等,可以獲取關於Web應用程式的資訊。指紋識別在資訊蒐集、滲透測試、安全審計等方面具有重要作用。有許多開源和商業工具可以用於執行Web指紋識別,例如Wappalyzer、WebScarab、Nmap等。
Web指紋識別的主要目的包括:
- 技術識別: 瞭解Web應用程式所使用的伺服器軟體、框架、資料庫等技術。
- 版本檢測: 確定這些技術的具體版本,有助於判斷應用程式是否存在已知的漏洞。
- 設定檢測: 獲取Web應用程式的設定資訊,包括安裝路徑、預設檔案、目錄結構等。
- 漏洞分析: 通過已知漏洞與特定版本相關聯,評估Web應用程式的安全性。
指紋識別是滲透測試中常用的一項技術,用於識別目標Web應用程式所使用的框架、技術和設定。其中,通過計算特定頁面的雜湊值進行指紋識別是一種常見的方法,主要通過以下步驟實現:
- 1.利用CURL庫獲取頁面內容: 使用LibCURL庫可以方便地獲取目標網站的頁面內容,將其讀入到
std::string字串中,以便後續處理。 - 2.MD5演演算法計算雜湊值: 對獲取的頁面內容進行MD5雜湊計算,得到一個唯一的雜湊值。MD5是一種常用的雜湊演演算法,將任意長度的資料對映成128位元的雜湊值,通常以16進位製表示。
- 3.比對預先計算的框架頁面雜湊值: 預先計算一些特定頁面的雜湊值,這些頁面通常是目標框架中相對獨立且不經常變動的頁面。將獲取到的頁面的雜湊值與預先計算的雜湊值進行比對。
- 4.框架識別: 如果雜湊值匹配,則說明目標頁面的框架很可能是預先定義的框架,從而實現對框架的識別。比對的過程可以使用簡單的相等比對,也可以設定一定的相似度閾值。
通過計算頁面雜湊值進行指紋識別是一種有效的方式,特別是針對那些相對穩定的頁面。首先我們利用LibCURL庫將目標頁面讀入到std::string字串中,然後呼叫MD5演演算法計算出該頁面的HASH值並比對,由於特定框架中總是有些頁面不會變動,我們則去校驗這些頁面的HASH值,即可實現對框架的識別。
LibCURL讀入頁面
當我們需要獲取遠端伺服器上的網頁內容時,使用C++編寫一個簡單的程式來實現這個目標是非常有用的。在這個例子中,我們使用了libcurl庫,在程式中引入libcurl庫的標頭檔案,並使用#pragma comment指令引入相關的庫檔案。接下來,我們定義了一個回撥函數WriteCallback,該函數將獲取的資料追加到一個std::string物件中。
主要的功能實現在GetUrlPageOfString函數中。該函數接受一個URL作為引數,並使用libcurl庫來執行HTTP GET請求。我們通過設定CURLOPT_URL選項來指定URL路徑,同時關閉了SSL證書驗證以及啟用了重定向。我們還設定了一些超時選項,以確保在連線或接收資料時不會花費太長時間。通過呼叫curl_easy_perform執行請求,並通過回撥函數將獲取到的資料儲存在read_buffer中。最後,我們輸出接收到的資料的長度。
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include <string>
#include "curl/curl.h"
#pragma comment (lib,"libcurl_a.lib")
#pragma comment (lib,"wldap32.lib")
#pragma comment (lib,"ws2_32.lib")
#pragma comment (lib,"Crypt32.lib")
using namespace std;
// 儲存回撥函數
size_t WriteCallback(char *contents, size_t size, size_t nmemb, void *userp)
{
((std::string*)userp)->append((char*)contents, size * nmemb);
return size * nmemb;
}
// 獲取資料並放入string中.
std::string GetUrlPageOfString(std::string url)
{
std::string read_buffer;
CURL *curl;
curl_global_init(CURL_GLOBAL_ALL);
curl = curl_easy_init();
if (curl)
{
curl_easy_setopt(curl, CURLOPT_SSL_VERIFYPEER, 0L); // 忽略證書檢查
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1); // 重定向
curl_easy_setopt(curl, CURLOPT_URL, url); // URL路徑
curl_easy_setopt(curl, CURLOPT_MAXREDIRS, 1); // 查詢次數,防止查詢太深
curl_easy_setopt(curl, CURLOPT_CONNECTTIMEOUT, 3); // 連線超時
curl_easy_setopt(curl, CURLOPT_TIMEOUT, 3); // 接收資料時超時設定
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &read_buffer);
curl_easy_perform(curl);
curl_easy_cleanup(curl);
return read_buffer;
}
return "None";
}
int main(int argc, char *argv[])
{
std::string urls = GetUrlPageOfString("https://www.baidu.com");
std::cout << "接收長度: " << urls.length() << " bytes" << std::endl;
system("pause");
return 0;
}
執行上述程式碼將會輸出存取特定主機所接收到的流量位元組數,如下圖所示;

LibCURL獲取狀態碼
在這個C++程式中,我們使用了libcurl庫來獲取指定URL的HTTP狀態碼。首先,我們引入libcurl庫的標頭檔案,並通過#pragma comment指令引入相關的庫檔案。然後,我們定義了一個靜態的回撥函數not_output,該函數用於遮蔽libcurl的輸出。
接著,我們定義了GetStatus函數,該函數接受一個URL作為引數,並返回該URL對應的HTTP狀態碼。在函數中,我們使用curl_easy_setopt設定了一些選項,包括URL、寫資料的回撥函數(這裡我們使用not_output遮蔽輸出),以及通過curl_easy_getinfo獲取狀態碼。
在main函數中,我們呼叫GetStatus函數並輸出獲取到的狀態碼。這個例子非常簡單,但展示了使用libcurl庫獲取HTTP狀態碼的基本方法。
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include <string>
#include "curl/curl.h"
#pragma comment (lib,"libcurl_a.lib")
#pragma comment (lib,"wldap32.lib")
#pragma comment (lib,"ws2_32.lib")
#pragma comment (lib,"Crypt32.lib")
using namespace std;
// 遮蔽輸出
static size_t not_output(char *d, size_t n, size_t l, void *p){ return 0; }
// 獲取狀態碼
long GetStatus(std::string url)
{
CURLcode return_code;
long retcode = 0;
return_code = curl_global_init(CURL_GLOBAL_WIN32);
if (CURLE_OK != return_code)
return 0;
CURL *easy_handle = curl_easy_init();
if (NULL != easy_handle)
{
curl_easy_setopt(easy_handle, CURLOPT_URL, url); // 請求的網站
curl_easy_setopt(easy_handle, CURLOPT_WRITEFUNCTION, not_output); // 設定回撥函數,遮蔽輸出
return_code = curl_easy_perform(easy_handle); // 執行CURL
return_code = curl_easy_getinfo(easy_handle, CURLINFO_RESPONSE_CODE, &retcode);
if ((CURLE_OK == return_code) && retcode)
{
return retcode;
}
}
curl_easy_cleanup(easy_handle);
curl_global_cleanup();
return retcode;
}
int main(int argc, char *argv[])
{
long ref = GetStatus("https://www.baidu.com/");
std::cout << "返回狀態碼: " << ref << std::endl;
system("pause");
return 0;
}
執行上述程式碼可得到特定網址的狀態碼資訊,圖中200表示存取正常;

計算字串Hash值
我們使用Boost庫中的boost/crc.hpp和boost/uuid/detail/md5.hpp來計算CRC32和MD5值。首先,定義GetCrc32函數,該函數接受一個字串作為輸入,使用Boost庫中的crc_32_type計算字串的CRC32值。
接著,我們定義了GetMd5函數,該函數接受一個字元陣列和其大小作為輸入,使用Boost庫中的boost::uuids::detail::md5計算字串的MD5值。在這個例子中,我們使用了Boost的md5實現。
在main函數中,我們建立了一個測試字串"hello lyshark",並分別呼叫GetMd5和GetCrc32函數來計算其MD5和CRC32值。最後,我們輸出計算得到的MD5和CRC32值。
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include <string>
#include <boost/crc.hpp>
#include <boost/uuid/detail/md5.hpp>
#include <boost/algorithm/hex.hpp>
using namespace std;
using namespace boost;
// 應用於crc32
long GetCrc32(std::string sz_string)
{
long ref;
crc_32_type crc32;
cout << hex;
crc32.process_bytes(sz_string.c_str(), sz_string.length());
return crc32.checksum();
}
// 應用於md5
std::string GetMd5(const char * const buffer, size_t buffer_size)
{
if (buffer == nullptr)
return false;
std::string str_md5;
boost::uuids::detail::md5 boost_md5;
boost_md5.process_bytes(buffer, buffer_size);
boost::uuids::detail::md5::digest_type digest;
boost_md5.get_digest(digest);
const auto char_digest = reinterpret_cast<const char*>(&digest);
str_md5.clear();
boost::algorithm::hex(char_digest, char_digest + sizeof(boost::uuids::detail::md5::digest_type), std::back_inserter(str_md5));
return str_md5;
}
int main(int argc, char *argv[])
{
std::string urls = "hello lyshark";
std::cout << "計算Hash: " << urls << std::endl;
// 計算MD5
std::string str = GetMd5(urls.c_str(), urls.length());
std::cout << "計算 MD5: " << str << std::endl;
// 計算CRC32
long crc = GetCrc32(urls.c_str());
std::cout << "計算 CRC32: " << crc << std::endl;
system("pause");
return 0;
}
通過計算可得到hello lyshark字串的CRC32與MD5特徵碼,如下圖;

當具備了hash值的計算後,我們只需要將上述兩個功能組合起來就可以實現提取特定頁面的特徵碼,首先通過libcurl庫完成對頁面的存取,接著就是計算特徵碼即可。
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include <string>
#include "curl/curl.h"
#include <boost/crc.hpp>
#include <boost/uuid/detail/md5.hpp>
#include <boost/algorithm/hex.hpp>
#pragma comment (lib,"libcurl_a.lib")
#pragma comment (lib,"wldap32.lib")
#pragma comment (lib,"ws2_32.lib")
#pragma comment (lib,"Crypt32.lib")
using namespace std;
// 儲存回撥函數
size_t WriteCallback(char *contents, size_t size, size_t nmemb, void *userp)
{
((std::string*)userp)->append((char*)contents, size * nmemb);
return size * nmemb;
}
// 獲取資料並放入string中.
std::string GetUrlPageOfString(std::string url)
{
std::string read_buffer;
CURL *curl;
curl_global_init(CURL_GLOBAL_ALL);
curl = curl_easy_init();
if (curl)
{
curl_easy_setopt(curl, CURLOPT_SSL_VERIFYPEER, 0L); // 忽略證書檢查
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1); // 重定向
curl_easy_setopt(curl, CURLOPT_URL, url); // URL路徑
curl_easy_setopt(curl, CURLOPT_MAXREDIRS, 1); // 查詢次數,防止查詢太深
curl_easy_setopt(curl, CURLOPT_CONNECTTIMEOUT, 3); // 連線超時
curl_easy_setopt(curl, CURLOPT_TIMEOUT, 3); // 接收資料時超時設定
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &read_buffer);
curl_easy_perform(curl);
curl_easy_cleanup(curl);
return read_buffer;
}
return "None";
}
// 應用於md5
std::string GetMd5(const char * const buffer, size_t buffer_size)
{
if (buffer == nullptr)
return false;
std::string str_md5;
boost::uuids::detail::md5 boost_md5;
boost_md5.process_bytes(buffer, buffer_size);
boost::uuids::detail::md5::digest_type digest;
boost_md5.get_digest(digest);
const auto char_digest = reinterpret_cast<const char*>(&digest);
str_md5.clear();
boost::algorithm::hex(char_digest, char_digest + sizeof(boost::uuids::detail::md5::digest_type), std::back_inserter(str_md5));
return str_md5;
}
// 計算特定頁面MD5
std::string CalculationMD5(std::string url)
{
std::string page_string = GetUrlPageOfString(url);
if (page_string != "None")
{
std::string page_md5 = GetMd5(page_string.c_str(), page_string.length());
std::cout << "[+] 計算頁面: " << url << std::endl;
std::cout << "[+] 壓縮資料: " << page_md5 << std::endl;
return page_md5;
}
return "None";
}
int main(int argc, char *argv[])
{
std::string md5 = CalculationMD5("https://www.baidu.com");
system("pause");
return 0;
}
上述程式碼執行後,則可以計算出特定網站的MD5值,如下圖;

解析對比Hash值
指紋識別依賴於特徵庫,如果需要實現自己的指紋識別工具則需要我麼能自行去收集各類框架的特徵庫,有了這些特徵庫就可以定義一個如下所示的JSON文字,該文字中container用於儲存框架型別,其次hash則用於存放特徵碼,最後的sub_url則是識別路徑。
{
"data_base":
[
{ "container": "typecho", "hash": "04A40072CDB70B1BF54C96C6438678CB" ,"sub_url":"/index.php/about.html" },
{ "container": "wordpress", "hash": "04A40072CBB70B1BF54C96C6438678CB" ,"sub_url":"/admin.php" },
{ "container": "baidu", "hash": "EF3F1F8FBB7D1F545A75A83640FF0E9F" ,"sub_url":"/index.php" }
]
}
接著就是解析這段JSON文字,我們利用BOOST提供的JSON解析庫,首先解析出所有的鍵值對,將其全部讀入到定義的結構體對映中,然後嘗試輸出看看,注意壓縮和解包格式必須對應。
#include <iostream>
#include <string>
#include <boost/property_tree/ptree.hpp>
#include <boost/property_tree/json_parser.hpp>
using namespace std;
using namespace boost;
using namespace boost::property_tree;
// 定義對映欄位
typedef struct
{
std::vector<std::string> container;
std::vector<std::string> hash;
std::vector<std::string> sub_url;
}database_map;
// 獲取文字中的JSON,放入自定義database_map
std::vector<database_map> GetDataBase()
{
std::vector<database_map> ref;
boost::property_tree::ptree ptr;
boost::property_tree::read_json("database.json", ptr);
if (ptr.count("data_base") == 1)
{
boost::property_tree::ptree p1, p2;
p1 = ptr.get_child("data_base");
// 定義對映型別
std::vector<std::string> x, y, z;
database_map maps;
for (ptree::iterator it = p1.begin(); it != p1.end(); ++it)
{
// 讀取出json中的資料
p2 = it->second;
std::string container = p2.get<std::string>("container");
std::string hash = p2.get<std::string>("hash");
std::string sub_url = p2.get<std::string>("sub_url");
// 臨時儲存資料
x.push_back(container);
y.push_back(hash);
z.push_back(sub_url);
}
// 打包結構壓入ref中
maps.container = x;
maps.hash = y;
maps.sub_url = z;
ref.push_back(maps);
}
return ref;
}
int main(int argc, char *argv[])
{
std::vector<database_map> db_map = GetDataBase();
for (int x = 0; x < db_map.size(); x++)
{
// 依次將字典讀入記憶體容器.
database_map maps = db_map[x];
std::vector<std::string> container = maps.container;
std::vector<std::string> hash = maps.hash;
std::vector<std::string> sub_url = maps.sub_url;
// 必須保證記錄數完全一致
if (container.size() != 0 && hash.size() != 0 && sub_url.size() != 0)
{
for (int x = 0; x < container.size(); x++)
{
std::cout << "容器型別: " << container[x] << std::endl;
std::cout << "指紋: " << hash[x] << std::endl;
std::cout << "根路徑: " << sub_url[x] << std::endl;
std::cout << std::endl;
}
}
}
std::system("pause");
return 0;
}
執行後則可以實現正常的json檔案解析,如下圖;
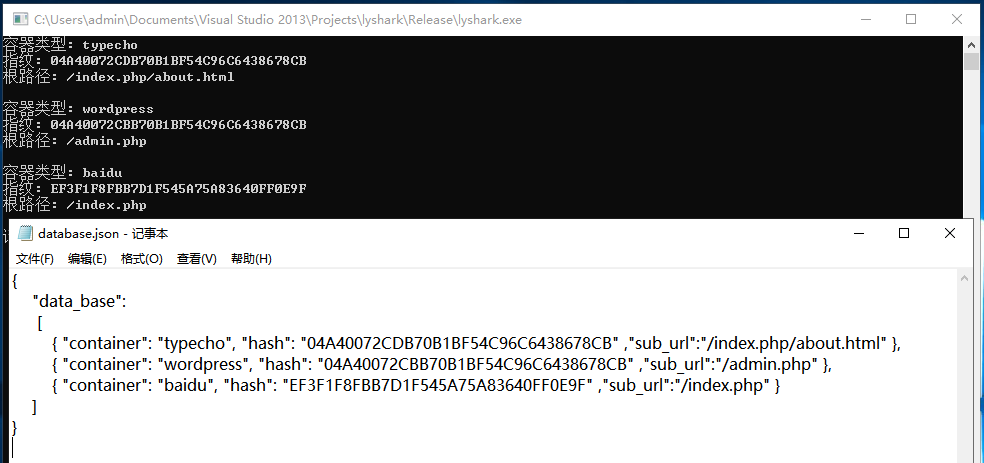
最後增加回圈對比流程,這裡我們以百度為例測試一下提取欄位是否可以被解析。
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include <string>
#include "curl/curl.h"
#include <boost/format.hpp>
#include <boost/property_tree/ptree.hpp>
#include <boost/property_tree/json_parser.hpp>
#include <boost/crc.hpp>
#include <boost/uuid/detail/md5.hpp>
#include <boost/algorithm/hex.hpp>
#pragma comment (lib,"libcurl_a.lib")
#pragma comment (lib,"wldap32.lib")
#pragma comment (lib,"ws2_32.lib")
#pragma comment (lib,"Crypt32.lib")
using namespace std;
using namespace boost;
using namespace boost::property_tree;
// 定義對映欄位
typedef struct
{
std::vector<std::string> container;
std::vector<std::string> hash;
std::vector<std::string> sub_url;
}database_map;
// 儲存回撥函數
size_t WriteCallback(char *contents, size_t size, size_t nmemb, void *userp)
{
((std::string*)userp)->append((char*)contents, size * nmemb);
return size * nmemb;
}
// 遮蔽輸出
static size_t not_output(char *d, size_t n, size_t l, void *p){ return 0; }
// 獲取資料並放入string中.
std::string GetUrlPageOfString(std::string url)
{
std::string read_buffer;
CURL *curl;
curl_global_init(CURL_GLOBAL_ALL);
curl = curl_easy_init();
if (curl)
{
curl_easy_setopt(curl, CURLOPT_SSL_VERIFYPEER, 0L); // 忽略證書檢查
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1); // 重定向
curl_easy_setopt(curl, CURLOPT_URL, url); // URL路徑
curl_easy_setopt(curl, CURLOPT_MAXREDIRS, 1); // 查詢次數,防止查詢太深
curl_easy_setopt(curl, CURLOPT_CONNECTTIMEOUT, 3); // 連線超時
curl_easy_setopt(curl, CURLOPT_TIMEOUT, 3); // 接收資料時超時設定
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &read_buffer);
curl_easy_perform(curl);
curl_easy_cleanup(curl);
return read_buffer;
}
return "None";
}
// 獲取狀態碼
long GetStatus(std::string url)
{
CURLcode return_code;
long retcode = 0;
return_code = curl_global_init(CURL_GLOBAL_WIN32);
if (CURLE_OK != return_code)
return 0;
CURL *easy_handle = curl_easy_init();
if (NULL != easy_handle)
{
curl_easy_setopt(easy_handle, CURLOPT_URL, url); // 請求的網站
curl_easy_setopt(easy_handle, CURLOPT_WRITEFUNCTION, not_output); // 設定回撥函數,遮蔽輸出
return_code = curl_easy_perform(easy_handle); // 執行CURL
return_code = curl_easy_getinfo(easy_handle, CURLINFO_RESPONSE_CODE, &retcode);
if ((CURLE_OK == return_code) && retcode)
{
return retcode;
}
}
curl_easy_cleanup(easy_handle);
curl_global_cleanup();
return retcode;
}
// 應用於md5
std::string GetMd5(const char * const buffer, size_t buffer_size)
{
if (buffer == nullptr)
return false;
std::string str_md5;
boost::uuids::detail::md5 boost_md5;
boost_md5.process_bytes(buffer, buffer_size);
boost::uuids::detail::md5::digest_type digest;
boost_md5.get_digest(digest);
const auto char_digest = reinterpret_cast<const char*>(&digest);
str_md5.clear();
boost::algorithm::hex(char_digest, char_digest + sizeof(boost::uuids::detail::md5::digest_type), std::back_inserter(str_md5));
return str_md5;
}
// 獲取文字中的JSON,放入自定義database_map
std::vector<database_map> GetDataBase()
{
std::vector<database_map> ref;
boost::property_tree::ptree ptr;
boost::property_tree::read_json("database.json", ptr);
if (ptr.count("data_base") == 1)
{
boost::property_tree::ptree p1, p2;
p1 = ptr.get_child("data_base");
// 定義對映型別
std::vector<std::string> x, y, z;
database_map maps;
for (ptree::iterator it = p1.begin(); it != p1.end(); ++it)
{
// 讀取出json中的資料
p2 = it->second;
std::string container = p2.get<std::string>("container");
std::string hash = p2.get<std::string>("hash");
std::string sub_url = p2.get<std::string>("sub_url");
// 臨時儲存資料
x.push_back(container);
y.push_back(hash);
z.push_back(sub_url);
}
// 打包結構壓入ref中
maps.container = x;
maps.hash = y;
maps.sub_url = z;
ref.push_back(maps);
}
return ref;
}
int main(int argc, char *argv[])
{
std::vector<database_map> db_map = GetDataBase();
for (int x = 0; x < db_map.size(); x++)
{
// 依次將字典讀入記憶體容器.
database_map maps = db_map[x];
std::vector<std::string> container = maps.container;
std::vector<std::string> hash = maps.hash;
std::vector<std::string> sub_url = maps.sub_url;
// 必須保證記錄數完全一致
if (container.size() != 0 && hash.size() != 0 && sub_url.size() != 0)
{
for (int x = 0; x < container.size(); x++)
{
// 開始編寫掃描函數
// 1.拼接字串
std::string ur = "https://www.baidu.com";
std::string this_url = boost::str(boost::format("%s%s") %ur %sub_url[x]);
// 2.判斷頁面是否存在
long ref_status = GetStatus(this_url);
if (ref_status != 0 && ref_status == 200)
{
// 3.讀入頁面字串,判斷是否成功
std::string read_page = GetUrlPageOfString(this_url);
if (read_page != "None")
{
std::string check_md5 = GetMd5(read_page.c_str(),read_page.length());
std::cout << "[+] 頁面MD5: " << check_md5 << std::endl;
std::cout << "[+] 資料庫: " << hash[x] << std::endl;
// 4.比對MD5值是否相同
if (check_md5 == std::string(hash[x]))
{
std::cout << "[*] 診斷框架為: " << container[x] << std::endl;
break;
}
}
}
}
}
}
std::system("pause");
return 0;
}
如下圖所示,說明對比通過,接著就可以增加命令列引數並使用了。

完整程式碼總結
C++指紋識別助手程式,它使用了libcurl庫進行HTTP請求,通過比對頁面的MD5值與預先儲存在資料庫中的MD5值,從而識別目標網站所使用的容器框架。
通過引數-u用於識別一個網站是什麼框架,使用-g則是獲取當前頁面指紋特徵,如下圖;
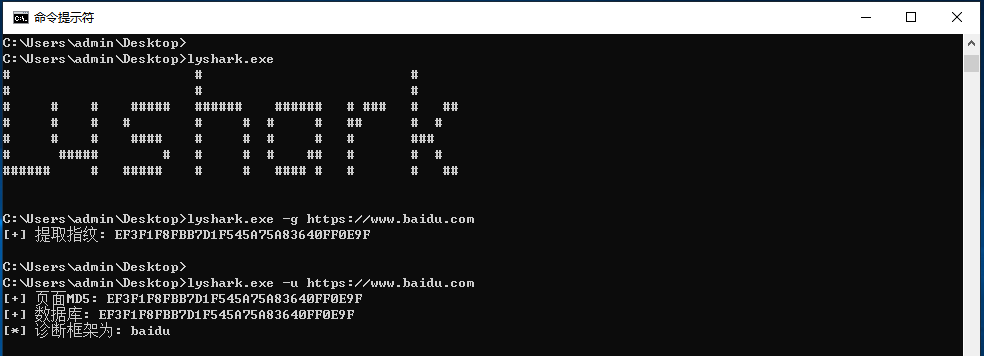
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include <string>
#include "curl/curl.h"
#include <boost/format.hpp>
#include <boost/property_tree/ptree.hpp>
#include <boost/property_tree/json_parser.hpp>
#include <boost/crc.hpp>
#include <boost/uuid/detail/md5.hpp>
#include <boost/algorithm/hex.hpp>
#include <boost/program_options.hpp>
#pragma comment (lib,"libcurl_a.lib")
#pragma comment (lib,"wldap32.lib")
#pragma comment (lib,"ws2_32.lib")
#pragma comment (lib,"Crypt32.lib")
using namespace std;
using namespace boost;
using namespace boost::property_tree;
namespace opt = boost::program_options;
// 定義對映欄位
typedef struct
{
std::vector<std::string> container;
std::vector<std::string> hash;
std::vector<std::string> sub_url;
}database_map;
void ShowOpt()
{
fprintf(stderr,
"# # # \n"
"# # # \n"
"# # # ##### ###### ###### # ### # ## \n"
"# # # # # # # # ## # # \n"
"# # # #### # # # # # ### \n"
"# ##### # # # # ## # # # \n"
"###### # ##### # # #### # # # ## \n\n"
);
}
// 儲存回撥函數
size_t WriteCallback(char *contents, size_t size, size_t nmemb, void *userp)
{
((std::string*)userp)->append((char*)contents, size * nmemb);
return size * nmemb;
}
// 遮蔽輸出
static size_t not_output(char *d, size_t n, size_t l, void *p){ return 0; }
// 獲取資料並放入string中.
std::string GetUrlPageOfString(std::string url)
{
std::string read_buffer;
CURL *curl;
curl_global_init(CURL_GLOBAL_ALL);
curl = curl_easy_init();
if (curl)
{
curl_easy_setopt(curl, CURLOPT_SSL_VERIFYPEER, 0L); // 忽略證書檢查
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1); // 重定向
curl_easy_setopt(curl, CURLOPT_URL, url); // URL路徑
curl_easy_setopt(curl, CURLOPT_MAXREDIRS, 1); // 查詢次數,防止查詢太深
curl_easy_setopt(curl, CURLOPT_CONNECTTIMEOUT, 3); // 連線超時
curl_easy_setopt(curl, CURLOPT_TIMEOUT, 3); // 接收資料時超時設定
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &read_buffer);
curl_easy_perform(curl);
curl_easy_cleanup(curl);
return read_buffer;
}
return "None";
}
// 獲取狀態碼
long GetStatus(std::string url)
{
CURLcode return_code;
long retcode = 0;
return_code = curl_global_init(CURL_GLOBAL_WIN32);
if (CURLE_OK != return_code)
return 0;
CURL *easy_handle = curl_easy_init();
if (NULL != easy_handle)
{
curl_easy_setopt(easy_handle, CURLOPT_URL, url); // 請求的網站
curl_easy_setopt(easy_handle, CURLOPT_WRITEFUNCTION, not_output); // 設定回撥函數,遮蔽輸出
return_code = curl_easy_perform(easy_handle); // 執行CURL
return_code = curl_easy_getinfo(easy_handle, CURLINFO_RESPONSE_CODE, &retcode);
if ((CURLE_OK == return_code) && retcode)
{
return retcode;
}
}
curl_easy_cleanup(easy_handle);
curl_global_cleanup();
return retcode;
}
// 應用於md5
std::string GetMd5(const char * const buffer, size_t buffer_size)
{
if (buffer == nullptr)
return false;
std::string str_md5;
boost::uuids::detail::md5 boost_md5;
boost_md5.process_bytes(buffer, buffer_size);
boost::uuids::detail::md5::digest_type digest;
boost_md5.get_digest(digest);
const auto char_digest = reinterpret_cast<const char*>(&digest);
str_md5.clear();
boost::algorithm::hex(char_digest, char_digest + sizeof(boost::uuids::detail::md5::digest_type), std::back_inserter(str_md5));
return str_md5;
}
// 獲取文字中的JSON,放入自定義database_map
std::vector<database_map> GetDataBase()
{
std::vector<database_map> ref;
boost::property_tree::ptree ptr;
boost::property_tree::read_json("database.json", ptr);
if (ptr.count("data_base") == 1)
{
boost::property_tree::ptree p1, p2;
p1 = ptr.get_child("data_base");
// 定義對映型別
std::vector<std::string> x, y, z;
database_map maps;
for (ptree::iterator it = p1.begin(); it != p1.end(); ++it)
{
// 讀取出json中的資料
p2 = it->second;
std::string container = p2.get<std::string>("container");
std::string hash = p2.get<std::string>("hash");
std::string sub_url = p2.get<std::string>("sub_url");
// 臨時儲存資料
x.push_back(container);
y.push_back(hash);
z.push_back(sub_url);
}
// 打包結構壓入ref中
maps.container = x;
maps.hash = y;
maps.sub_url = z;
ref.push_back(maps);
}
return ref;
}
// 掃描判斷容器型別
void ScanPage(std::string urls)
{
std::vector<database_map> db_map = GetDataBase();
for (int x = 0; x < db_map.size(); x++)
{
// 依次將字典讀入記憶體容器.
database_map maps = db_map[x];
std::vector<std::string> container = maps.container;
std::vector<std::string> hash = maps.hash;
std::vector<std::string> sub_url = maps.sub_url;
// 必須保證記錄數完全一致
if (container.size() != 0 && hash.size() != 0 && sub_url.size() != 0)
{
for (int x = 0; x < container.size(); x++)
{
// 1.拼接字串
std::string this_url = boost::str(boost::format("%s%s") % urls %sub_url[x]);
// 2.判斷頁面是否存在
long ref_status = GetStatus(this_url);
if (ref_status != 0 && ref_status == 200)
{
// 3.讀入頁面字串,判斷是否成功
std::string read_page = GetUrlPageOfString(this_url);
if (read_page != "None")
{
std::string check_md5 = GetMd5(read_page.c_str(), read_page.length());
std::cout << "[+] 頁面MD5: " << check_md5 << std::endl;
std::cout << "[+] 資料庫: " << hash[x] << std::endl;
// 4.比對MD5值是否相同
if (check_md5 == std::string(hash[x]))
{
std::cout << "[*] 診斷框架為: " << container[x] << std::endl;
break;
}
}
}
}
}
}
}
int main(int argc, char *argv[])
{
opt::options_description des_cmd("\n Usage: 容器識別助手 \n\n Options");
des_cmd.add_options()
("url,u", opt::value<std::string>(), "指定目標URL地址")
("get,g", opt::value<std::string>(), "提取頁面指紋")
("help,h", "幫助選單");
opt::variables_map virtual_map;
try
{
opt::store(opt::parse_command_line(argc, argv, des_cmd), virtual_map);
}
catch (...){ return 0; }
// 定義訊息
opt::notify(virtual_map);
// 無引數直接返回
if (virtual_map.empty())
{
ShowOpt();
return 0;
}
// 幫助選單
else if (virtual_map.count("help") || virtual_map.count("h"))
{
ShowOpt();
std::cout << des_cmd << std::endl;
return 0;
}
else if (virtual_map.count("url"))
{
std::string address = virtual_map["url"].as<std::string>();
ScanPage(address);
}
else if (virtual_map.count("get"))
{
std::string address = virtual_map["get"].as<std::string>();
std::string read_page = GetUrlPageOfString(address);
std::cout << "[+] 提取指紋: " << GetMd5(read_page.c_str(), read_page.length()) << std::endl;
}
else
{
std::cout << "引數錯誤" << std::endl;
}
return 0;
std::system("pause");
return 0;
}