增長實驗室-ab分流的流量保護功能介紹
介紹ab分流的流量保護功能之前,先普及一下ab分流的一些概念和術語
名詞解釋:
- 實驗:用來驗證某個決定請求處理方式的功能或策略的一部分流量,通常用來驗證某個功能或策略對系統指標(如PV/UV,CRT,下單轉化率等)的影響。
- 流量 :指所有存取使用者的請求
- Hash因子:可以理解為存取實驗使用者的uuid,即一個可以識別某個流量使用者的唯一標識。
- Hash演演算法:是把任意長度的輸入通過雜湊演演算法變換成固定長度的輸出,是一種從任意檔案中創造小的數位「指紋」的方法。與指紋一樣,雜湊演演算法就是一種以較短的資訊來保證檔案唯一性的標誌
- 桶位:ab測試又稱為分桶測試。當用戶的請求打到某個實驗進行分流時,分流引擎會根據請求的uuid + 強一致性hash演演算法(保證分每個桶分到的越隨機越平均越好)生成一個全域性固定不變的值 ,然後 值取模100 得到一個0-100區間的具體桶位編號,一個百分點對應一個桶位編號。
- 實驗版本:實驗版本即實驗分組,A/B實驗通常是為了驗證一個新策略的效果。在實驗進行中,所抽取的使用者被隨機地分配到A組和B組中,A組使用者體驗到新策略,B組使用者體驗的仍舊是舊策略。在這一實驗過程中,A組便為實驗組,B組則為對照組。也有多個實驗組和一個對照組構成的實驗,他們共同承載了100%的流量請求。
使用者桶位編號如何生成
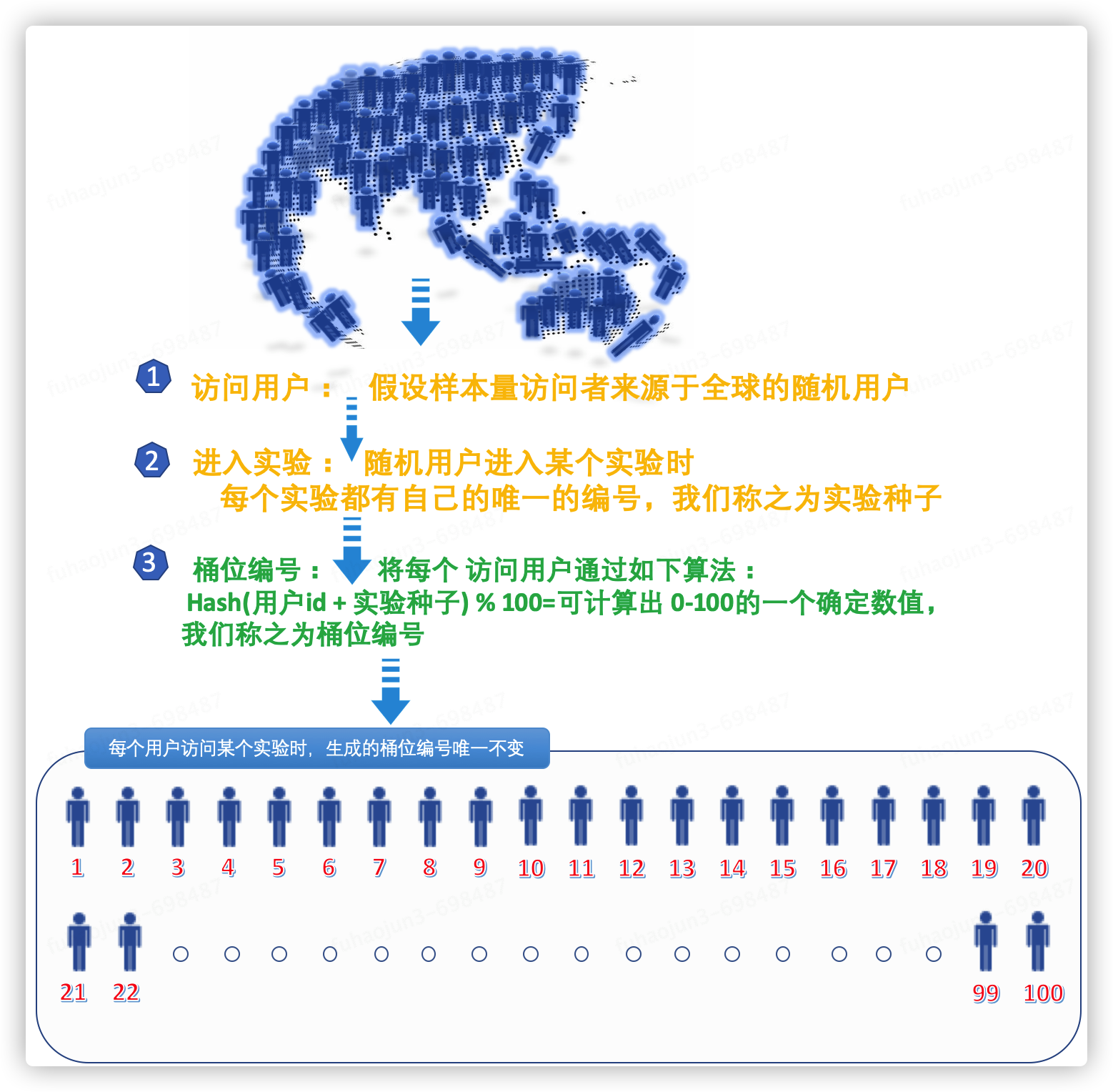
如上圖說明,現在大家知道一個使用者存取某個實驗時都會有一個唯一固定的編號。
為了更好闡述其意,假設我們有這樣26位流量使用者,分別是A-Z的這樣26位使用者:
{****A , B , C , D , E , F , G , H , I , J , K , L , M , N , O , P , Q , R , S , T , U , V , W , X , Y , Z }
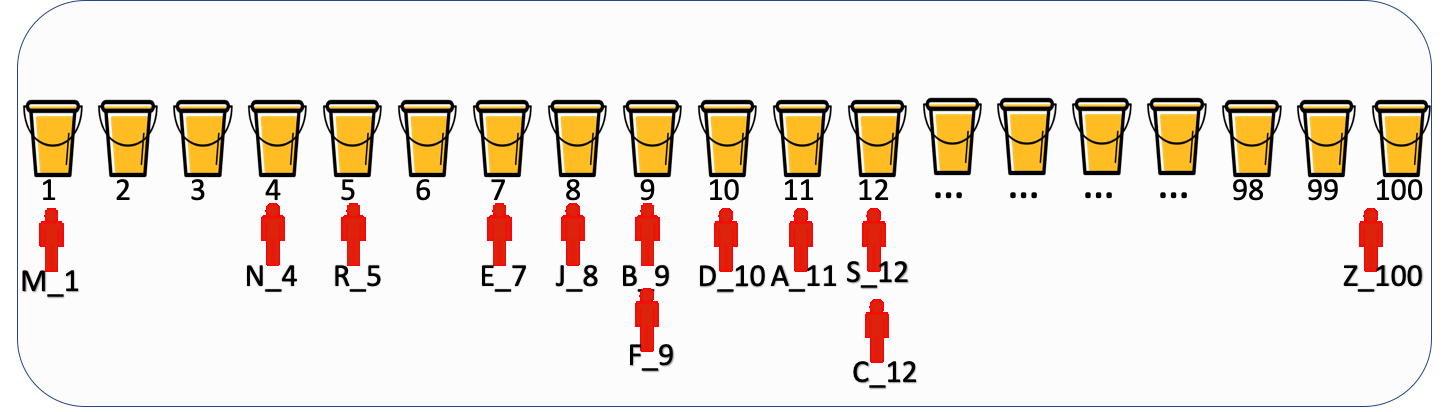
他們存取實驗X時,通過 Hash(uid+實驗X種子) 生成了如下的實驗編號(命名規則為:使用者x_桶位編號):
A_11,B_9,C_12,D_10,E_7,F_9,G_24,H_22,I_18,J_8,K_21,L_15,M_1,N_4,O_76,P_33,Q_40,
R_5,S_12,T_80,U_67,V_25,W_33,X_49,Y_87,Z_100
他們存取實驗Y時,通過 Hash(uid+實驗X種子) 生成了如下的實驗編號(命名規則為:使用者x_桶位編號):
A_25,B_17,C_19,D_2,E_1,F_18,G_19,H_22,I_12,J_2,K_22,L_14,M_4,N_16,O_28,P_30,
Q_92,R_93,S_8,T_55,U_18,V_100,W_1,X_100,Y_50,Z_36
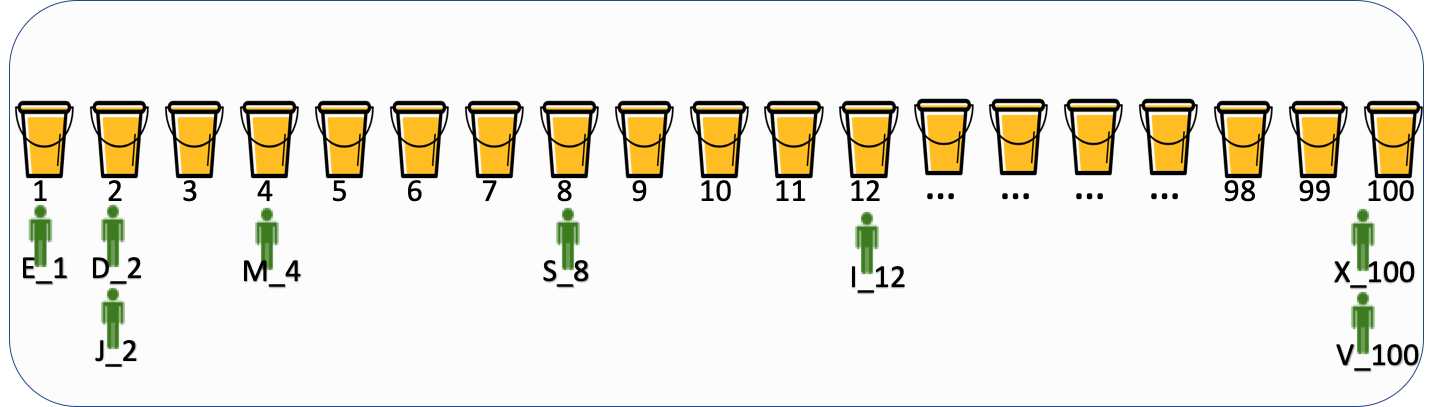
通過上面的案例說明,隨機的流量使用者存取實驗時,某些使用者生成的桶位編號會一樣,那他們就會進入實驗的同一個分組裡。
實驗版本與桶位的關係
一個桶位編號代表全部流量(100%)的一個百分點的流量(1%)
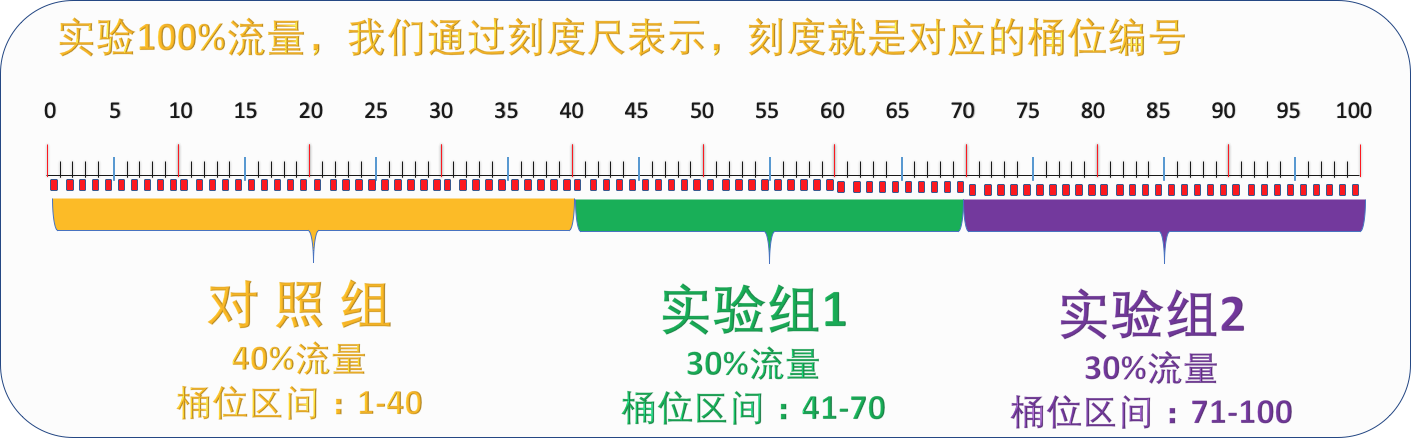
實驗分流演示
假設我們一個實驗有三個版本即三個分組,分別是 實驗組1=VA,實驗組2=VB,對照組=VC
初始分組比例為:VA=10%,VB=10%,VC=80%
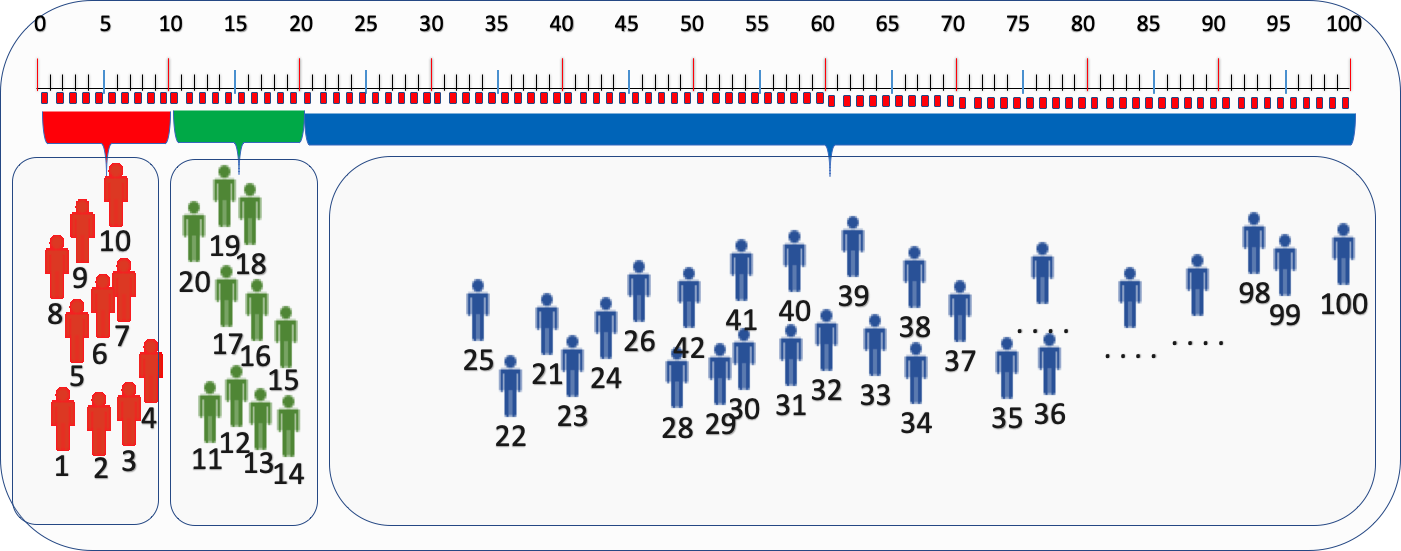
下一步,我們要將實驗組流量擴量,流量分別為:VA=20%,VB=20%,VC=60%
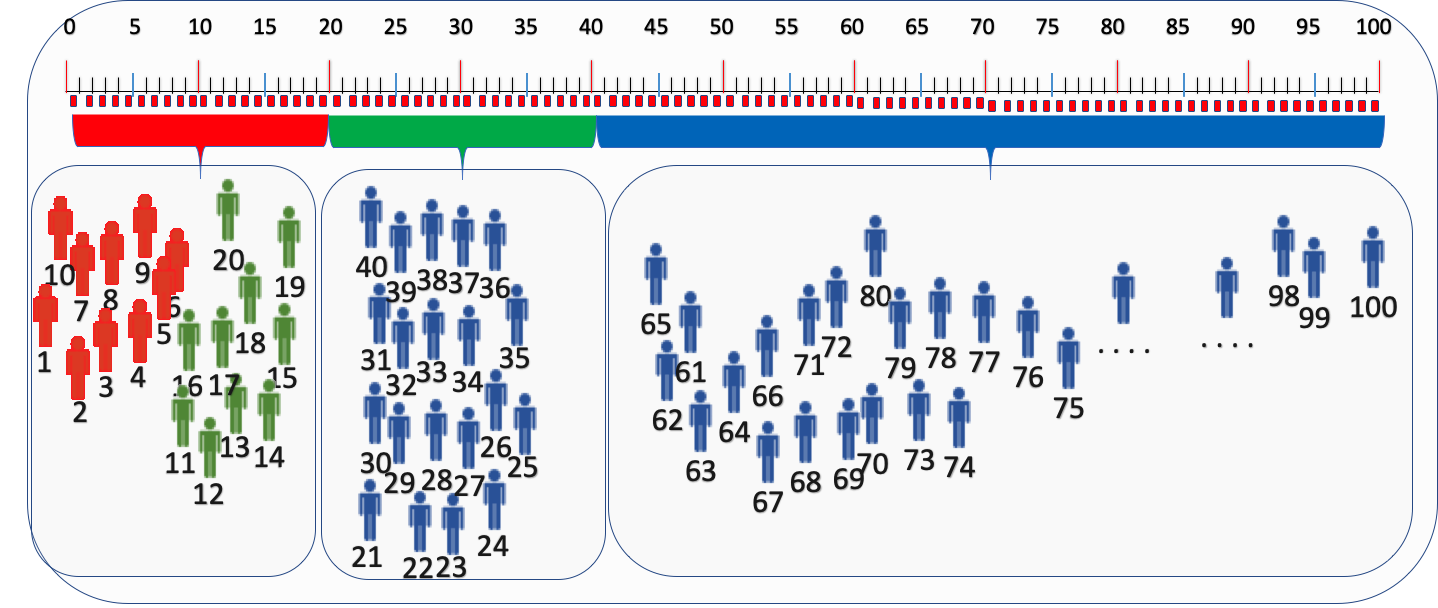
這種擴量後的分流,從分流角度看是ok的,But細心的同學可能會發現之前進入實驗組2的使用者11-20桶位編號的在進行實驗組擴量後,居然...居然...被分配到實驗組1。這樣就發生了使用者跳組的情況,如果接下來繼續擴量,一直會存在此類問題:就是進入過實驗組2的使用者擴量後又被分配到實驗組1。
每次都有實驗組使用者汙染的問題,但是運營同事每次調整比例時並不知道後端分配邏輯,他們會想當然認為流量分配是ok的,這種分配方式會造成資料分析問題和使用者體驗問題,可能比例調整後對其他組的使用者進行了汙染,這樣的結果在業務上是不可接受的
那麼... 針對這種情況實際怎麼分配會最佳呢,繼續往下看。
正確的分流效果圖
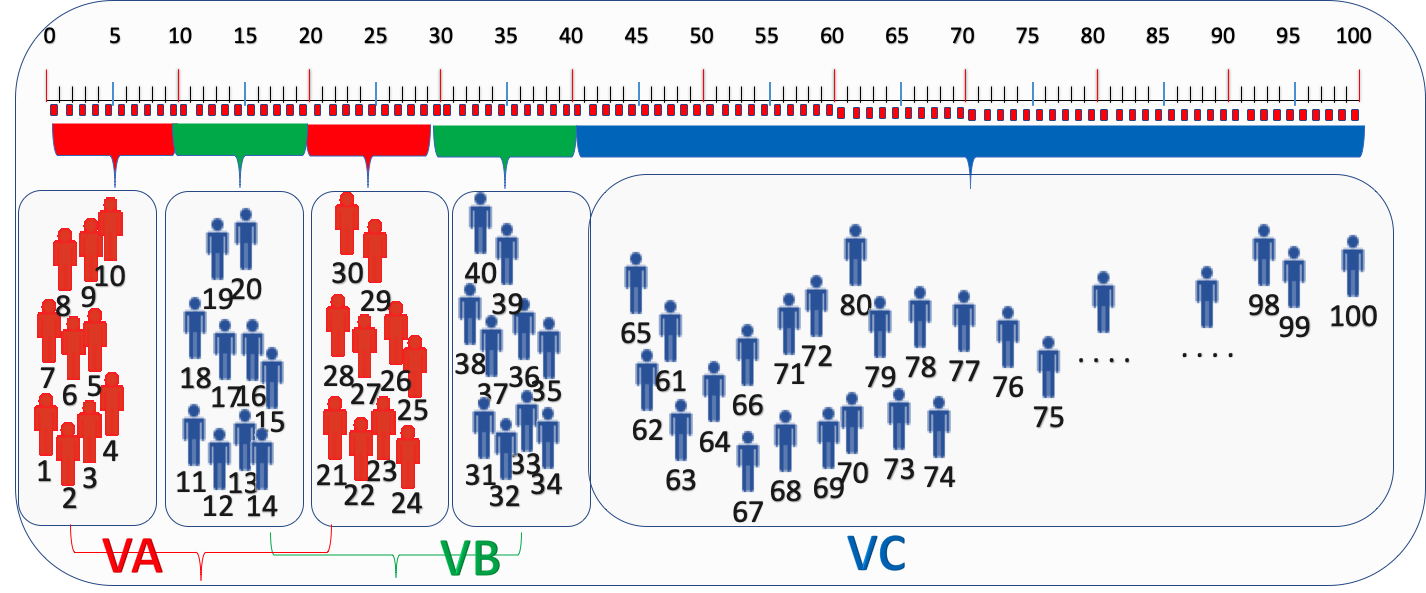
如上效果圖:
VA 版本由原來的10%擴量到20%,正確的分流是:
新增的10%流量來自對照組VC的流量使用者即桶位區間是21-30。
擴量後VA的20%流量是由:1-10,21-30的兩個桶位區間。
VB版本由原來的10%擴量到20%,正確的分流是:
新增的10%流量來自對照組VC的流量使用者即桶位區間是31-40。
擴量後VB的20%流量是由:11-20,31-40的兩個桶位區間。
這樣的擴量之後不會出現之前那樣的流量使用者發生跳組,即保證原來的使用者進入的哪個版本擴量之後還是之前的版本。
這種的分流優化我們稱之為:流量保護,就是我們本篇文章重點介紹的功能。
為什麼做流量保護:
答:實驗迭代時,增減版本、調整比例是最高頻的操作,此時平臺採用了【流量保護】功能,即每次修改先識別減少比例的版本,從減少比例的版本的流量拆分給增加比例的版本。最大限度隔離流量,減少實驗組之間相互汙染;
引入流量保護功能
ab分流亟需解決這種不科學的流量調整問題,升級【流量保護】功能後,再看一組如下實驗的版本流量迭代的推演過程(紅色代表A組、藍色代表B組、綠色代表C組)

這樣經過多次調整後,每個實驗都儘可能的減少了自己區間的變動,保證自己使用者的留存性,減少對實驗指標的影響
流量保護動畫推演
大家可以直接欣賞:四個版本比例調整的推演(可以關注每個版本色塊的變化)

從上面的例子可以看出,經過多次的流量調整後,各個實驗的區間分佈會變得比較複雜,但是從使用者的角度看,他只需要關心每個實驗所佔的流量配比,不需要關心底層實驗流量的區間分佈情況(這塊對他是黑匣子),因此不會增加使用者操作的難度。
流量保護分配規則
- 對版本比例調整進行分組:比對版本修改前、後的資料。按序識別比例新增、減少、不變的三個變化組
- 將版本減少組的桶位拆分:對減少組版本桶位區間從最右側拆分、匹配直到滿足減少的浮動比例的桶位區間段
- 對拆分的桶位區間排序、移動:對減少組被拆分的桶位區間按從左到右的排序,依次次分配給新增版本
- 對版本變化後的桶位排序、合併: 分配後的所有版本進行桶位區間排序,相鄰的桶位區間進行合併操作
作者:京東科技 付浩軍
來源:京東雲開發者社群 轉載請註明來源