決策樹C4.5演演算法的技術深度剖析、實戰解讀
在本篇深入探討的文章中,我們全面分析了C4.5決策樹演演算法,包括其核心原理、實現流程、實戰案例,以及與其他流行決策樹演演算法(如ID3、CART和Random Forests)的比較。文章不僅涵蓋了豐富的理論細節和實際應用,還提出了獨特的洞見,旨在幫助讀者全面瞭解C4.5演演算法的優缺點和應用場景。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。

一、簡介
C4.5演演算法是一種廣泛應用於機器學習和資料探勘的決策樹演演算法。它是由Ross Quinlan教授在1993年提出的,作為其早期ID3(Iterative Dichotomiser 3)演演算法的一種擴充套件和改進。這個演演算法被設計用來將一個複雜的決策問題分解成一系列簡單的決策,然後構建一個決策樹模型來解決這個問題。
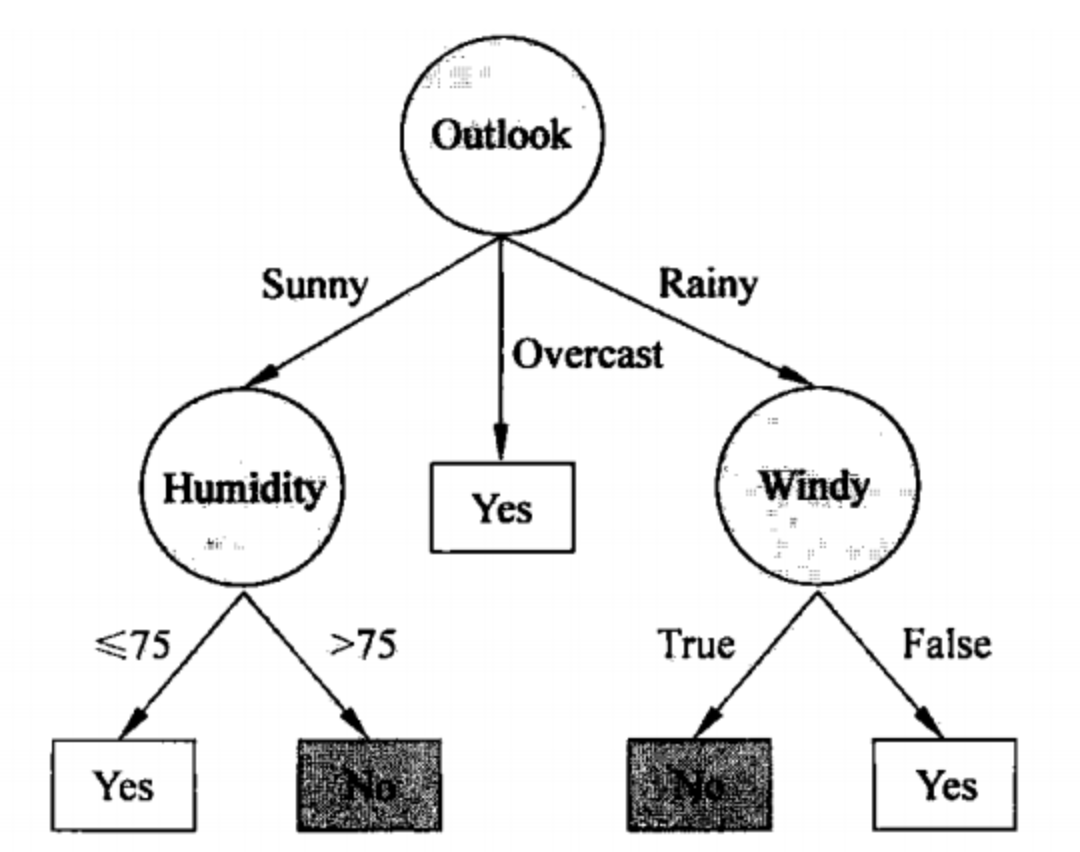
決策樹(Decision Tree)
決策樹是一種樹形結構模型,用於在給定一組特徵的情況下進行決策或分類。在這個模型中,每一個內部節點代表一個特徵測試,每一個分支代表一個測試結果,而每一個葉子節點代表一個決策結果。
例子:
假設我們有一個資料集,其中包括天氣、溫度和是否進行戶外活動。一個決策樹可能會首先根據「天氣」進行分支:如果是晴天,則推薦進行戶外活動;如果是雨天,則進一步根據「溫度」進行分支。
資訊熵(Information Entropy)與資訊增益(Information Gain)
資訊熵是用於度量資料不確定性的一個指標,而資訊增益則表示通過某個特徵進行分裂後,能夠為我們帶來多少「資訊」以減少這種不確定性。
例子:
考慮一個資料集,其中有兩個類別A和B。如果所有範例都屬於類別A,那麼資訊熵就是0,因為我們完全確定了任何範例都屬於類別A。但如果一半屬於類別A,另一半屬於類別B,資訊熵就是最高的,因為資料最不確定。
資訊增益比(Gain Ratio)
與資訊增益類似,資訊增益比也是用於評估特徵的重要性,但它還考慮了特徵可能帶來的分裂數(即特徵值的數量)。
例子:
假設有一個特徵「顏色」,它有很多可能的值(紅、藍、綠等)。即使「顏色」能提供很高的資訊增益,由於它導致樹分裂過多,因此資訊增益比可能會相對較低。
通過這些核心概念和改進,C4.5演演算法不僅在計算效率上有所提升,而且在處理連續屬性、缺失值以及減枝優化等方面都有顯著的優勢。
二、演演算法原理
在深入瞭解C4.5演演算法之前,有必要明確幾個核心概念和度量指標。本節將重點介紹資訊熵、資訊增益、以及資訊增益比,這些都是C4.5演演算法決策樹構建中的關鍵因素。
資訊熵(Information Entropy)
資訊熵是用來度量一組資料的不確定性或混亂程度的。它是基於概率論的一個概念,通常用以下數學公式來定義:
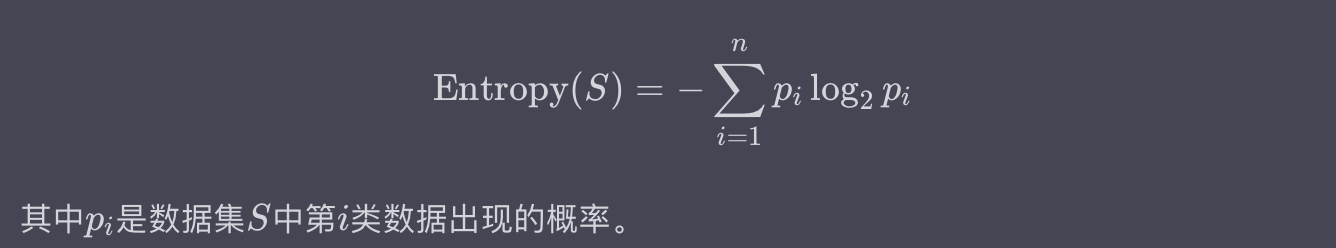
例子:
假設我們有一個資料集,包含10個樣本,其中5個樣本為正類(Yes),5個樣本為負類(No)。資訊熵可以計算為:

資訊增益(Information Gain)
資訊增益表示通過某個特徵進行分裂後,資料集不確定性(即資訊熵)下降的程度。資訊增益通常用以下數學公式來定義:

例子:
考慮一個簡單資料集,其中有一個特徵「天氣」,它有兩個可能的值:「晴天」和「雨天」。通過計算,我們發現通過「天氣」這個特徵進行分裂後,資訊增益是0.2。這意味著使用這個特徵進行分裂能讓資料集的不確定性下降0.2。
資訊增益比(Gain Ratio)
資訊增益比是資訊增益與該特徵導致的資料集分裂複雜度(Split Information)的比值。用數學公式表示為:

例子:
如果在前面的「天氣」特徵例子中,我們計算出Split Information是0.5,那麼資訊增益比就是0.2 / 0.5 = 0.4。
通過資訊熵、資訊增益和資訊增益比這三個關鍵概念,C4.5演演算法能有效地選擇最優特徵,進行資料集的分裂,從而構建出高效且準確的決策樹。這不僅解決了ID3演演算法在某些方面的不足,也使得決策樹模型更加適用於實際問題。
三、演演算法流程
在這一部分中,我們將深入探討C4.5演演算法的核心流程。流程通常可以分為幾個主要步驟,從資料預處理到決策樹的生成,以及後續的決策樹剪枝。下面是更詳細的解釋:
步驟1:資料準備
概念:
在決策樹的構建過程中,首先需要準備一個訓練資料集。這個資料集應該包含多個特徵(或屬性)和一個目標變數(或標籤)。資料準備階段也可能包括資料淨化和轉換。
例子:
比如,在醫療診斷中,特徵可能包括病人的年齡、性別和症狀等,而目標變數可能是病人是否患有某種疾病。
步驟2:計算資訊熵
概念:
資訊熵是一個用於衡量資料不確定性的度量。在C4.5演演算法中,使用資訊熵來評估如何分割資料。
例子:
假如有一個資料集,其中有兩個分類:「是」和「否」,每個分類包含50%的資料。在這種情況下,資訊熵是最高的,因為資料具有最高程度的不確定性。
步驟3:選擇最優特徵
概念:
在決策樹的每一個節點,演演算法需要選擇一個特徵來分割資料。選擇哪個特徵取決於哪個特徵會導致資訊熵最大的下降(或資訊增益最大)。
例子:
在預測是否會下雨的任務中,可能有多個特徵如氣溫、溼度等。如果發現通過「溼度」這一特徵分割資料會得到資訊增益最大,那麼該節點就應該基於「溼度」來分割。
步驟4:遞迴構建決策樹
概念:
一旦選擇了最優特徵並根據該特徵分割了資料,演演算法將在每個分割後的子集上遞迴地執行同樣的過程,直到滿足某個停止條件(如,所有資料都屬於同一類別或達到預設的最大深度等)。
例子:
考慮一個用於分類動物的決策樹。首先,根據「是否有脊椎」這一特徵來分割資料,然後,在「有脊椎」的子集中進一步基於「是否能飛」來分割,以此類推。
步驟5:決策樹剪枝(可選)
概念:
決策樹剪枝是一種優化手段,用於去除決策樹中不必要的節點,以防止過擬合。
例子:
如果一個節點的所有子節點都對應著同一個類別標籤,那麼這個節點可能是不必要的,因為它的父節點已經能準確分類。
四、案例實戰
在本節中,我們將使用一個實際的資料集來展示如何應用C4.5演演算法。通過這個案例,您將更清楚地瞭解如何將理論應用到實際問題中。我們將使用Python和Scikit-learn庫來實現這一演演算法(注意,Scikit-learn的DecisionTreeClassifier提供了一個引數criterion='entropy',用於實現C4.5的資訊增益準則)。
資料集選擇
概念:
在機器學習專案中,選擇合適的資料集是非常關鍵的一步。資料集應該是問題相關、豐富而且乾淨的。
例子:
為了本例,我們將使用經典的Iris資料集,該資料集用於分類三種不同的鳶尾花。
資料預處理
概念:
資料預處理是準備資料用於機器學習模型的過程。這可能包括標準化、缺失值處理等。
例子:
在Iris資料集中,所有的特徵都是數值型的,不需要進一步的轉換或標準化。
Python實現程式碼
下面是使用Python和Scikit-learn實現C4.5演演算法的程式碼。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# 載入資料集
iris = load_iris()
X = iris.data
y = iris.target
# 資料劃分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化決策樹分類器
clf = DecisionTreeClassifier(criterion='entropy')
# 訓練模型
clf.fit(X_train, y_train)
# 測試模型
score = clf.score(X_test, y_test)
print(f'Accuracy: {score * 100:.2f}%')
輸入和輸出:
- 輸入:Iris資料集的特徵和標籤
- 輸出:模型的準確率
處理過程:
- 載入Iris資料集。
- 將資料集劃分為訓練集和測試集。
- 初始化一個使用資訊熵作為分裂準則的決策樹分類器。
- 使用訓練集訓練分類器。
- 使用測試集評估分類器。
五、演演算法優缺點
C4.5演演算法作為決策樹家族中的一員,廣泛應用於分類問題。然而,和所有演演算法一樣,C4.5也有其優缺點。這一節將詳細地探討這些方面。
優點
易於理解和解釋
概念:
決策樹是白盒模型,這意味著與黑盒模型(如神經網路)相比,決策樹更容易理解和解釋。
例子:
假設你有一個決策樹模型用於信用評分。每個節點都清晰地描述了哪個特徵被用於分割,比如年收入或債務比率。這使得銀行能輕易地解釋給客戶為什麼他們的貸款申請被拒絕。
能夠處理非線性關係
概念:
C4.5能很好地處理特徵與目標變數之間的非線性關係。
例子:
考慮一個電子商務網站,其中使用者年齡和購買意願之間可能存在非線性關係。年輕人和老年人可能更傾向於購買,而中年人可能相對較少。C4.5演演算法能捕捉到這種非線性關係。
對缺失值有較好的容忍性
概念:
C4.5演演算法可以容忍輸入資料的缺失值。
例子:
在醫療診斷場景中,患者的某些檢查結果可能不完整或缺失,C4.5演演算法仍然可以進行有效的分類。
缺點
容易過擬合
概念:
C4.5演演算法非常容易產生過擬合,尤其是當決策樹很深的時候。
例子:
如果一個決策樹模型在股票市場預測問題上表現得異常好,那很可能是該模型已經過擬合了,因為股票價格受到多種不可預測因素的影響。
對噪聲和異常值敏感
概念:
由於決策樹模型在構建時對資料分佈的微小變化非常敏感,因此噪聲和異常值可能會極大地影響模型效能。
例子:
在識別垃圾郵件的應用中,如果訓練資料包含由於標註錯誤而導致的噪聲,C4.5演演算法可能會誤將合法郵件分類為垃圾郵件。
計算複雜度可能較高
概念:
由於需要計算所有特徵的資訊增益或增益率,C4.5演演算法在特徵維度非常高時可能會有較高的計算成本。
例子:
在基因表達資料集上,由於特徵數可能達到數千或更多,使用C4.5演演算法可能會導致計算成本增加。
六、與其他類似演演算法比較
決策樹演演算法有多個不同的實現,如ID3、CART(分類與迴歸樹)和Random Forests。在這一節中,我們將重點比較C4.5與這些演演算法的主要區別和適用場景。
C4.5 vs ID3
特徵選擇準則
概念:
ID3演演算法使用資訊增益作為特徵選擇的準則,而C4.5使用的是資訊增益率。
例子:
假設你正在對文字資料進行分類,其中一個特徵是文字長度。ID3可能會傾向於使用這個特徵,因為它可能具有高資訊增益。然而,C4.5通過使用增益率,可能會減少這種偏向,從而選出更有區分度的特徵。
對連續屬性的處理
概念:
C4.5能夠直接處理連續屬性,而ID3不能。
例子:
在房價預測模型中,房屋面積是一個連續屬性。C4.5能夠自然地處理這種型別的資料,而ID3需要先將其離散化。
C4.5 vs CART
輸出型別
概念:
CART支援分類和迴歸兩種輸出,而C4.5主要用於分類。
例子:
如果你的目標是預測一個連續的輸出變數(如房價),那麼CART可能是一個更好的選擇。
特徵選擇準則
概念:
CART使用「基尼不純度」或「均方誤差」作為特徵選擇準則,而C4.5使用資訊增益率。
例子:
在一個醫療診斷應用中,假設某個特徵在兩個類別中的分佈相差非常大,C4.5可能會優先選擇這個特徵,而CART則可能不會。
C4.5 vs Random Forests
模型複雜性
概念:
Random Forests是一個整合方法,通常包括多個決策樹,因此模型更為複雜。
例子:
在一個高維資料集(例如影象分類)上,Random Forests可能會比C4.5表現得更好,但需要更多的計算資源。
魯棒性
概念:
由於Random Forests是一個整合方法,它通常更不容易過擬合,並且對噪聲和異常值有更好的魯棒性。
例子:
在金融欺詐檢測的應用中,由於資料通常非常不平衡並且包含許多噪聲,使用Random Forests通常會獲得比C4.5更好的結果。
七、總結
決策樹演演算法,尤其是C4.5演演算法,因其直觀、易於理解和實施而得到了廣泛的應用。在本篇文章中,我們從演演算法原理、流程、案例實戰、優缺點,以及與其他類似演演算法的比較多個角度對C4.5演演算法進行了深入的探討。
-
特徵選擇的多樣性:C4.5演演算法通過使用資訊增益率來優化特徵選擇,提供了一個在某些情況下比ID3更合適的選擇。這一點在處理高維資料或特徵間存在依賴的情況下尤為重要。
-
適用性與侷限性:雖然C4.5在處理分類問題時非常強大,但它也有自己的侷限,比如容易過擬合和對噪聲敏感。理解這些侷限不僅有助於我們在具體應用中做出更明智的決策,還促使我們去探索如何通過整合方法或引數調優來改進演演算法。
-
與其他演演算法的相對位置:當我們將C4.5與CART、Random Forests等其他決策樹演演算法比較時,可以看出每種演演算法都有其獨特的應用場景和侷限性。例如,在需要模型解釋性的場合,C4.5和CART可能更為合適;而在高維複雜資料集上,Random Forests可能更具優勢。
-
複雜性和計算成本:C4.5雖然是一個相對簡單的演演算法,但在處理大規模或高維資料時,其計算成本也不容忽視。這提醒我們,在實際應用中需要綜合考慮演演算法效能和計算成本。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。