Node.js精進(12)——ElasticSearch
ElasticSearch(簡稱 ES)是一款基於 Lucene 的分散式、可延伸、RESTful 風格的全文檢索和資料分析引擎,擅長實時處理 PB 級別的資料。
一、基本概念
1)Lucene
Lucene 是一款開源免費、成熟權威、高效能的全文檢索庫,是 ES 實現全文檢索的核心基礎,而檢索的關鍵正是倒排索引。
2)倒排索引
索引的目的是加快查詢速度,儘快查出符合條件的資料。
正排索引就像翻書一樣,先查目錄,然後鎖定頁碼,再去看內容。而倒排索引正好與其相反,通過對內容的分詞,建立內容到檔案 ID 之間的對映關係,如下圖所示(來源於elasticsearch原理及入門)。
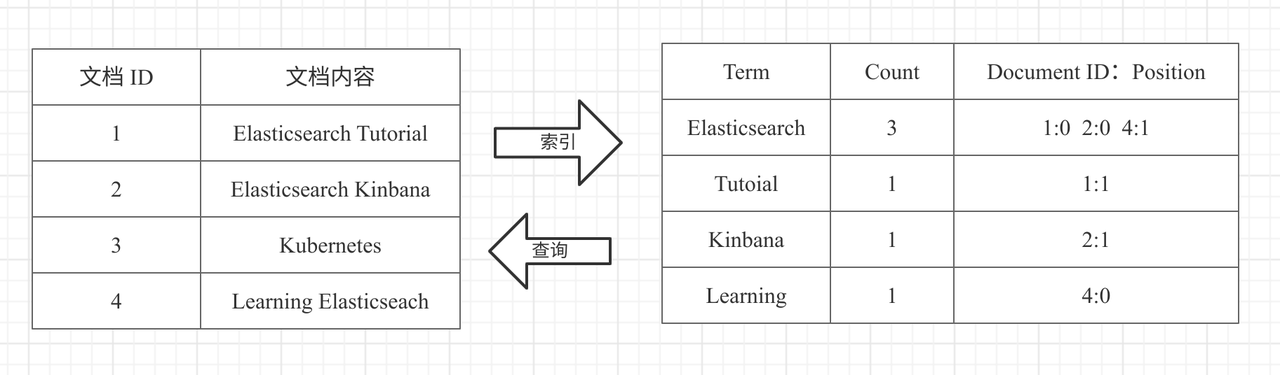
倒排索引包括兩部分: Term Dictionary(單詞詞典)和 Posting List(倒排列表)。
Term Dictionary 記錄了檔案單詞,以及單詞和倒排列表的關係。Posting List 則是記錄了 Term 在檔案中的位置以及其他資訊,主要包括檔案 ID、詞頻(Term 在檔案中出現的次數,用來計算相關性評分),位置以及偏移(實現搜尋高亮)。
3)壓縮演演算法
為了搜尋能高效能,需要將倒排列表放入記憶體中,但是海量的檔案必然會增加表的尺寸,為了節約空間,Lucene 使用了兩種壓縮演演算法:FOR(Frame Of Reference)和 RBM(RoaringBitmap)。
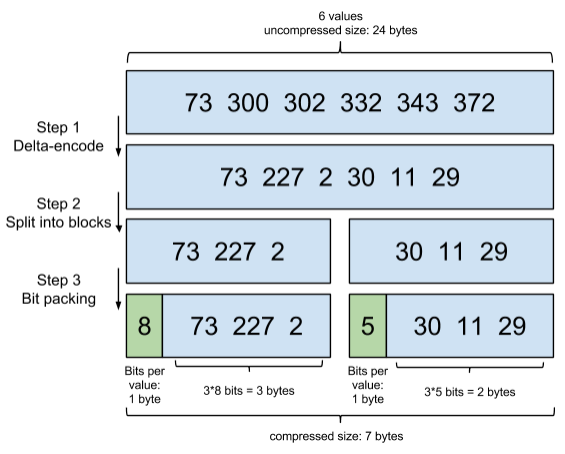
FOR 演演算法的原理就是通過增量,將原來的大數變成小數,僅儲存增量值,最後通過位元組儲存,具體分為 3 步:
- 將排序的整數列表轉換成 Delta 列表,第二排的 227 是增量值(300 - 73),其餘值依次計算。
- 切分成 blocks,每個 block 是 256 個 Delta,這裡為了簡化一下,搞成 3 個 Delta。
- 看下每個 block 最大的 Delta 是多少。下圖的第一個,最大是 227,最接近的 2 次冪是 256(8bits),於是規定這個 block 裡都用 8bits 來編碼(綠色的 header 就是 8);第二個最大的是 30,最接近的 2 次冪是 32(5bits),於是規定這個 block 裡都用 5bits 來編碼。
FOR 壓縮演演算法適用於間隔比較小稠密的檔案 ID 列表,如1、2、3、5、8.......。假如遇到間隔較大稀疏的檔案 ID 列表,如 1000、62101、131385、132052、191173、196658,就更適合通過 RBM 演演算法來壓縮。
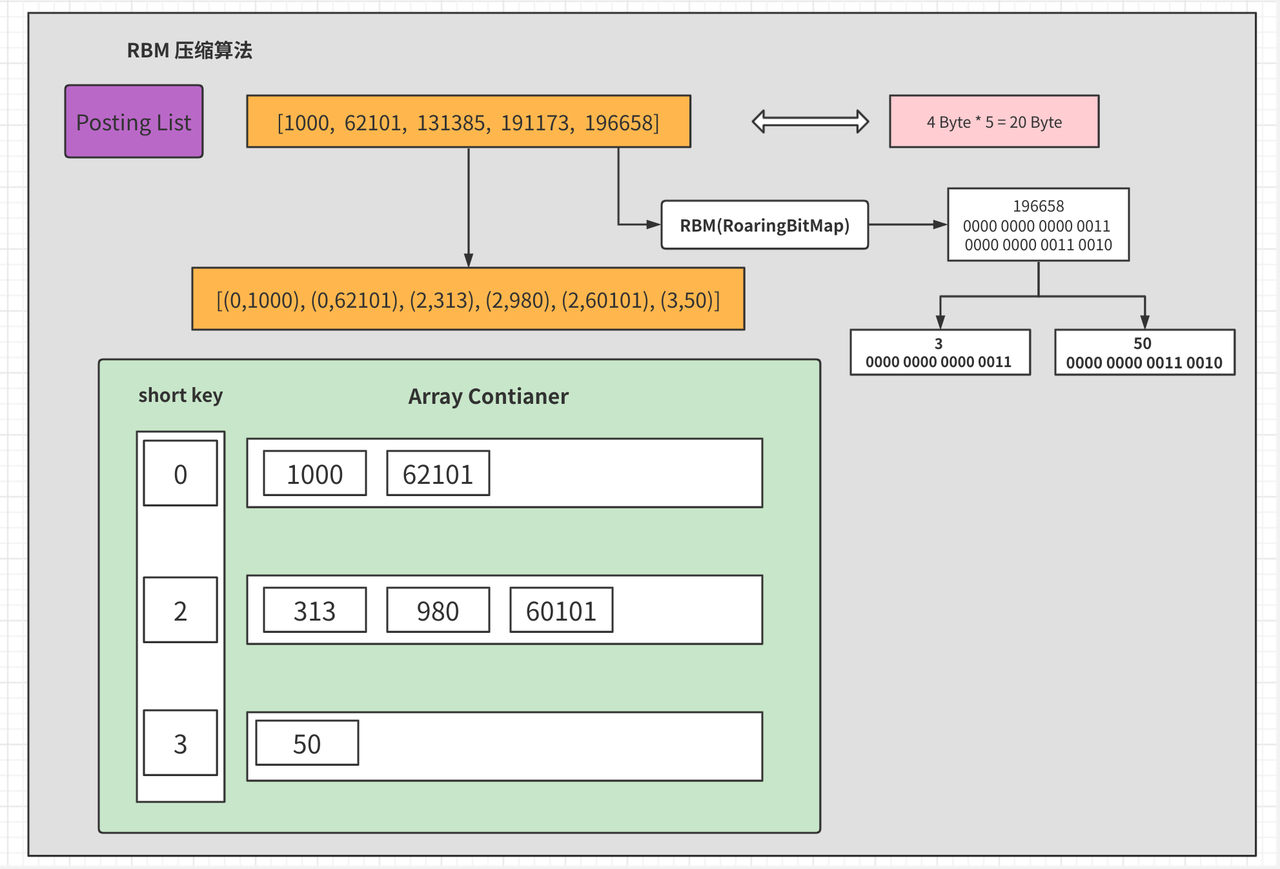
RBM 演演算法的核心就是把資料表示成 32 位的二進位制,分為高 16 和低 16 進行分別儲存,最大值就是 2 的 16 次方(即 65536)。下圖描述了具體的壓縮步驟(來源於elasticsearch原理及入門):
- 每個數位除以 65536 會得到一個商和餘數。
- 用(商,餘數)的組合表示每一組 ID,範圍都在 0 ~ 65535 之內。
- 其中商為該數位(以 196658 為例)的二進位制的前 16 位,餘數為該數位的二進位制的後 16 位。
- 再將商提取出來作為 short key,將關聯的餘數整合在一起,例如商是 0,則 1000 和 62101 重新組合。
4)FST
在資料寫入的時候,Lucene 會為原始資料中的每個 Term 生成對應的倒排索引,這就會讓倒排索引的資料量變得很大。而倒排索引對應的倒排列表檔案又是儲存在硬碟上的,如果每次查詢都直接去磁碟中讀取,那就會嚴重影響全文檢索的效率。
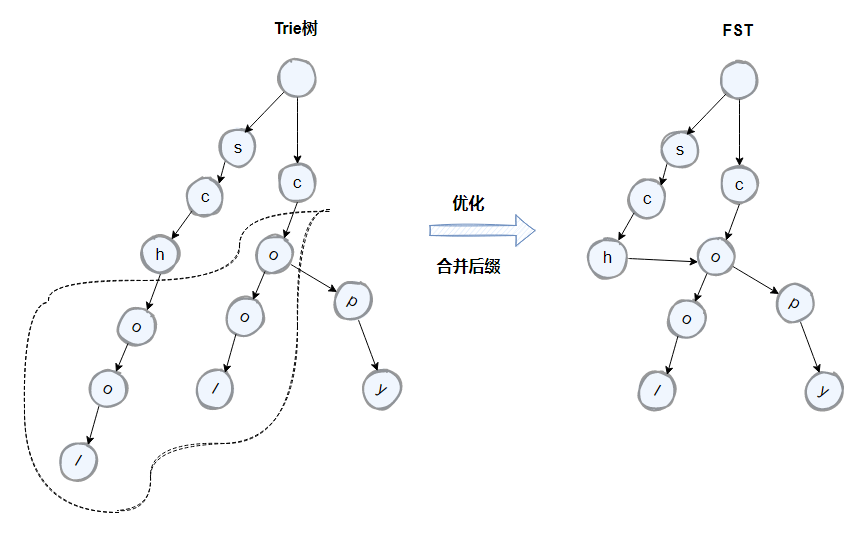
因此需要一種方式可以快速定位到倒排索引中的 Term,Lucene 使用了 FST(Finite State Transducer)有限狀態轉換器來實現二級索引的設計,這是一種類似 Trie 樹的演演算法。
Trie 樹是一種樹形結構,雜湊樹的變種,經常被搜尋引擎系統用於文字詞頻統計。可利用字串的公共字首來減少查詢時間,最大限度地減少無謂的字串比較,查詢效率比雜湊樹高。它有 3 個基本性質:
- 根節點不包含字元,除根節點外每一個節點都只包含一個字元。
- 從根節點到某一節點,路徑上經過的字元連線起來,為該節點對應的字串。
- 每個節點的所有子節點包含的字元都不相同。
假設有兩個 Term:school 和 cool,它們後面的字元一致,可以通過將原先的 Trie 樹中的字尾字元進行合併來進一步的壓縮空間。優化後的 trie 樹就是 FST,如下圖所示(來源於Elasticsearch核心概念):
5)術語
ES 是分散式資料庫,允許多臺伺服器協同工作,每臺伺服器可以執行多個範例。單個範例稱為一個節點(node),一組節點構成一個叢集(cluster)。
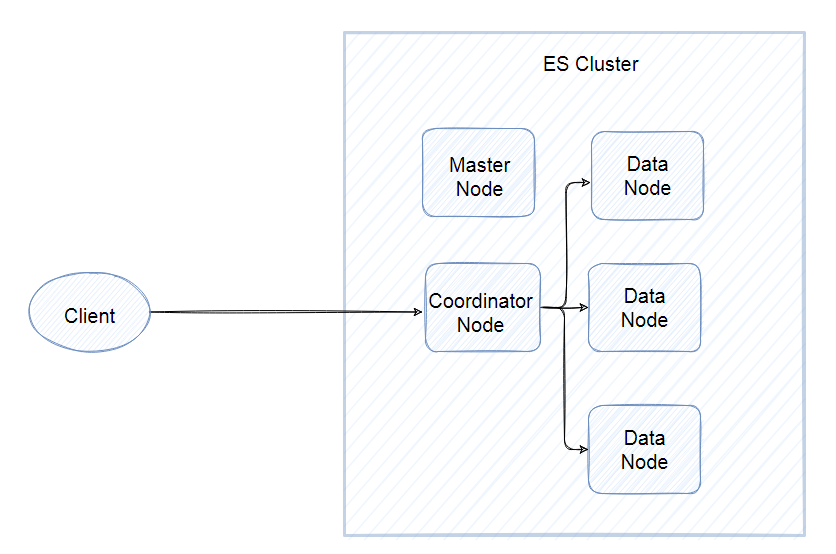
在上圖中,包含三類節點:
- 主節點(Master Node),為確保一個叢集的穩定,分離主節點和資料節點,主要職責是和叢集操作相關的內容,如建立或刪除索引,跟蹤哪些節點是叢集的一部分,並決定哪些分片分配給相關的節點。
- 資料節點(Data Node),儲存索引資料的節點,主要對檔案進行增刪改查、聚合等操作。
- 協調節點(Coordinator Node),該節點只處理路由請求、分發索引等操作,相當於一個智慧負載平衡器,協調節點將請求轉發給儲存資料的 Data Node。每個 Data Node 會將結果返回協調節點,協調節點收集完資料後,將每個 Data Node 的結果合併為單個全域性結果。
分片(shared)是底層的工作單元,檔案(document)儲存在分片內,分片又被分配到叢集內的各個節點裡,每個分片僅儲存全部資料的一部分。注意,分片不是隨意進行設定的,而是需要根據實際的生產環境提前進行資料儲存的容量規劃,若設定的過大或過小都會影響 ES 叢集的整體效能。
索引(index)是一類檔案的集合,而檔案是具體的一條資料,注意,從 ElasticSearch 8 開始,徹底移除了 Type 的概念。
為了便於理解,相關概念與關係型資料庫(MySQL)的對比如下:
| MySQL | ElasticSearch |
| Table | Index |
| Row | Doucment |
| Column | Field |
| Schema | Mapping |
| SQL | DSL |
二、實戰應用
1)安裝
在官網可以下載各種作業系統版本的 ES,當進入下載頁面時會自動切換成當前電腦的系統。
下載完成後,就可以執行第二步,執行 bin 目錄中 elasticsearch 可執行檔案,簡單點就是將其拖到命令列視窗中。
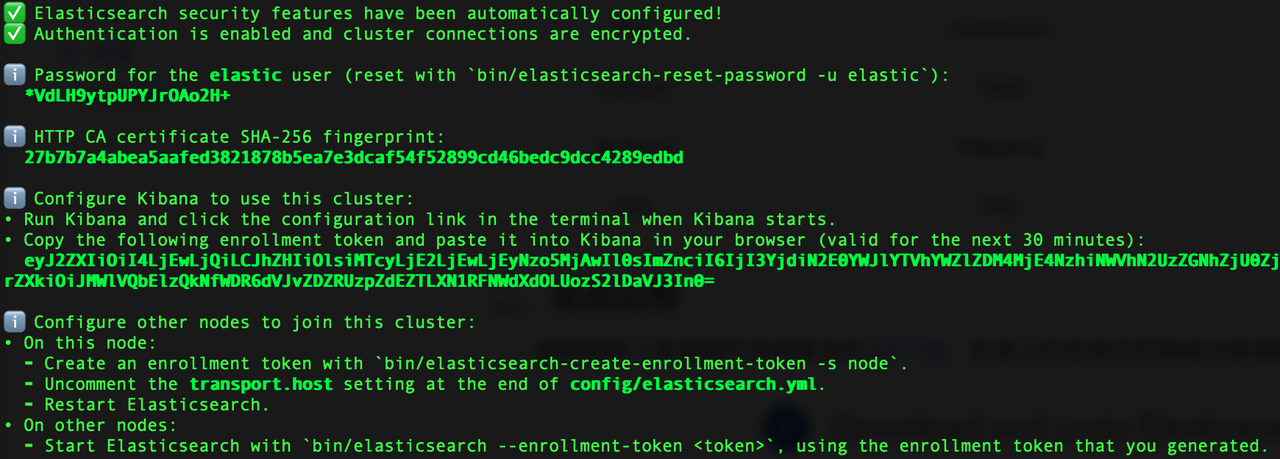
在安裝成功後,儲存給出的密碼和 token。
2)Kibana
官方提供了一套視覺化操作 ES 的系統:Kibana,在下載完成後,執行 bin 目錄中的 kibana 檔案。
耐心等待,安裝成功後,在命令視窗會給出一條地址。
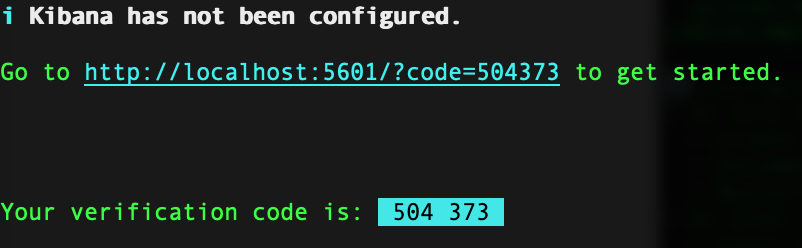
在初始化時會要求填入之前儲存的 token,點選 Configure 按鈕,若彈出驗證碼,則將上圖中的 code 引數複製過來,設定完成後進入登入頁面。
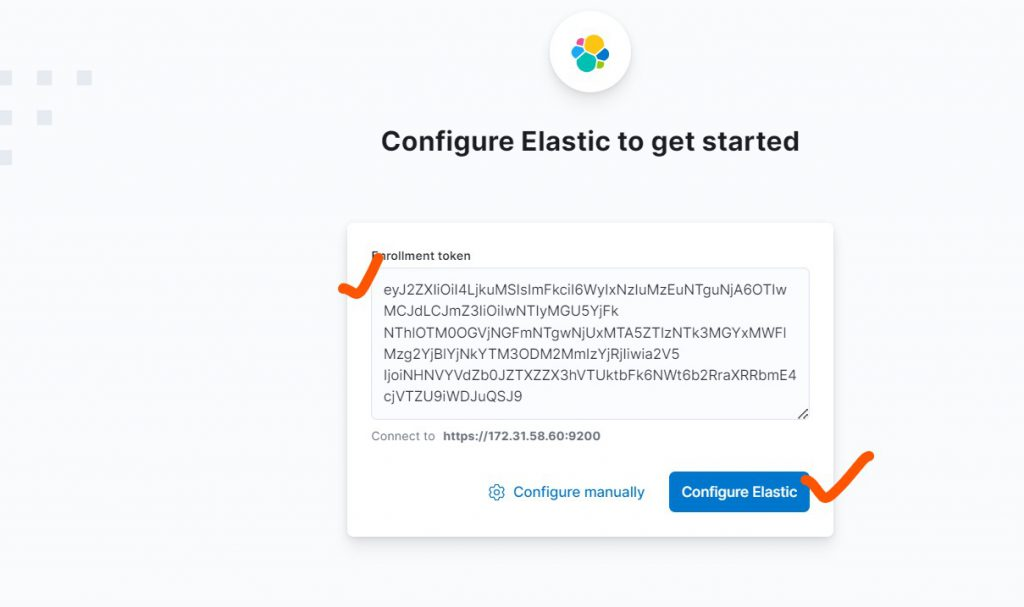
在登入時會用到預設賬號 elastic,上一節儲存的密碼,點選確定進入主頁,在左側選單中找到 Dev Tools。
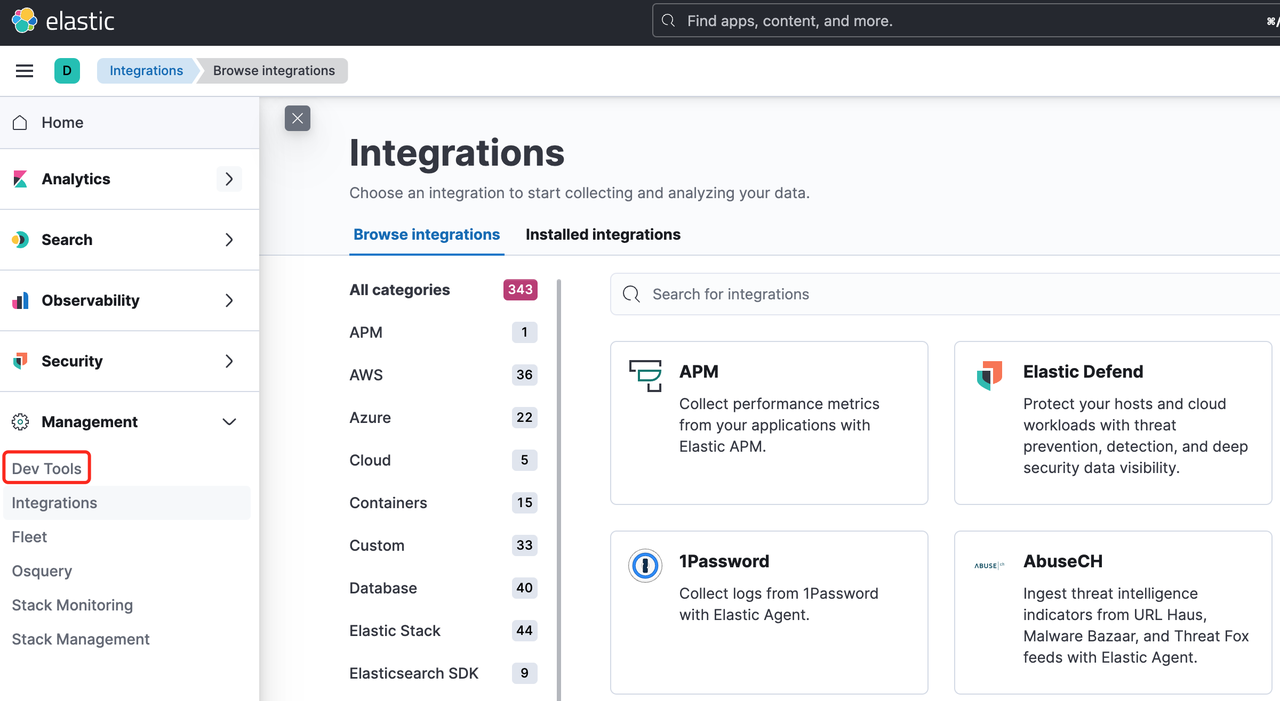
點選後就能進入可執行 ES RESTful API 的操作介面。
若 Kibana 啟動不了,報錯如下:
Kibana server is not ready yet.
此時可以開啟 config/kibana.yml 中的組態檔,翻到最後,很可能是 hosts 中的 IP 地址有問題,因為電腦重新聯網時,IP 地址很有可能變換了,將其改成 localhost 問題就能迎刃而解。
elasticsearch.hosts: ['https://172.21.10.10:9200'] elasticsearch.serviceAccountToken: AAEAAWVsYXN0aWMva2liYW5 elasticsearch.ssl.certificateAuthorities: [/Users/pwstrick/code/kibana/data/ca_1699243503862.crt] xpack.fleet.outputs: [{id: fleet-default-output, name: default, is_default: true,
is_default_monitoring: true, type: elasticsearch, hosts: ['https://172.21.10.10:9200'],
ca_trusted_fingerprint: 1b6c0b97e18f22efdd4925a95a4a0dc898de5072e3d6c45938b8d2f0a7f920fb}]
3)RESTful API
ES 提供了對 Document 進行增刪改查的常規介面,例如使用 Bulk 介面插入一條資料,_index 就相當於資料庫表,第三行就是具體的欄位名稱和值。
POST _bulk {"index": {"_id": 862024079,"_index": "web_monitor_2023.11"}} {"id":862024079,"project":"game","project_subdir":"chat","category":"ajax",
"message":"{\"type\":\"GET\",\"url\":\"https://static.xxx.me/xxx.json\",\"status\":200,\"endBytes\":\"80.43KB\",\"interval\":\"9ms\"}",
"key":"80c89d32b27f8f7d43fa8470aeba3f3a","source":"","identity":"xe990bhs4j","referer":"https://www.xxx.me/chat.html",
"message_type":"get","message_status":200,"message_path":"xxx.json","day":"20231103","hour":15,"minute":29,"ctime":1698996585,
"ip":"0.0.0.0","os_name":"iOS","os_version":"15.4.1","app_version":"5.36.1","author":"張三",
"fingerprint":"38eab40b373220bea1bab2933649c","country":"中國","province":"廣東省","city":"佛山市","isp":"電信","digit":1}
若要更新或刪除一條記錄,也可以在 Bulk 介面完成,格式參考如下,更新語句需要包含待更新的資料。
POST _bulk { "delete" : {"_id" : "2", "_index" : "web_monitor_2023.11" } } { "update" : {"_id" : "1", "_index" : "web_monitor_2023.11"} } { "doc" : {"field" : "value"} }
使用 Search 介面做查詢,格式參考 GET /<target>/_search,其中 target 可以理解為 Index(相當於資料庫表的名稱)。
GET web_monitor_2023.11/_search
響應的 JSON 結構欄位包含眾多(如下所示),took 是搜尋耗費的毫秒數;_shards 中的 total 代表本次搜尋一共使用的分片數量;hits 中的 total 代表本次搜尋得到的結果數,預設最大值為 1W,max_score 指搜尋結果中相關度得分的最大值,預設搜尋結果會按照相關度得分降序排列,hits 就是命中的資料列表,而其中的 _score 是單個檔案的相關度得分,_source 就是原始資料的 JSON 內容。
{ "took": 6, // 搜尋耗費的毫秒數 "timed_out": false, "_shards": { "total": 1, // 本次搜尋一共使用的分片數量 "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1, // 本次搜尋得到的結果數,預設最大值為 1W "relation": "eq" }, "max_score": 1, // 搜尋結果中相關度得分的最大值 "hits": [ { "_index": "web_monitor_2023.11", "_id": "862024079", "_score": 1, // 單個檔案的相關度得分 "_source": { // 原始資料的 JSON 內容 "id": 862024079, "project": "game", "project_subdir": "chat", "category": "ajax", "fingerprint": "38eab40b373220bea1baee7b2933649c", "country": "中國", "province": "廣東省", "city": "佛山市", "isp": "電信", "digit": 1 } } ] } }
如果要計算搜尋結果真實的資料量,可以參考 Count 介面,格式為 GET /<target>/_count。
4)索引模板
索引模板(Index Template)允許使用者在建立索引時,參照已儲存的模板來減少設定項,在 MySQL 中就相當於建立表結構。
Elasticsearch 的索引模板功能以 7.8 版本為界,兩個版本的主要區別是模板之間複用方式。
- 老版本:使用優先順序(order)關鍵字實現,當建立索引匹配到多個索引模板時,高優先順序會繼承並覆蓋低優先順序的模板設定,最終多個模板共同起作用。
- 新版本:刪除了 order 關鍵字,引入了元件模板(Component Template)的概念。在宣告索引模板時可以參照多個元件模板,當建立索引匹配到多個索引模板時,選最高權重的那個。
老版本會造成使用者在建立索引時,不能明確知道自己到底用了多少模板,索引設定在繼承覆蓋的過程中容易出錯。
建立或更新一個老版索引模板,需要向 /_template 傳送 PUT 請求,設定包括 aliases、settings、mappings、order 等欄位。
PUT _template/web_monitor { order: 0, index_patterns: ["web_monitor_*"], settings: { index: { number_of_shards: 1 } }, mappings: { dynamic: "strict", properties: { app_version: { type: "keyword" }, ctime: { format: "strict_date_optional_time||epoch_second", type: "date" }, digit: { type: "keyword", fields: { num: { type: "integer" } } }, author: { type: "keyword" }, ip: { type: "ip" } } }, aliases: { web_monitor: {} } }
新版本索引自動設定功能,需要通過元件模板和索引模板來完成。
在元件模板中可設定的欄位包括:aliases、settings 和 mappings,元件模板只有在被索引模板參照時,才會發揮作用。當需要建立或更新一個元件模板時,向 /_component_template 傳送 PUT 請求即可。
PUT /_component_template/ct1 { "template": { "settings": { "index.number_of_shards": 2 } } } PUT /_component_template/ct2 { "template": { "settings": { "index.number_of_replicas": 0 }, "mappings": { "properties": { "@timestamp": { "type": "date" } } } } }
建立或更新一個索引模板的方式都是向 /_index_template 傳送 1 個 POST 請求。
POST /_index_template/_simulate { "index_patterns": ["my*"], "template": { "settings" : { "index.number_of_shards" : 3 } }, "composed_of": ["ct1", "ct2"] }
5)搜尋
下面是一組查詢條件,query、from、size 和 sort 平級,分別表示查詢條件、頁碼、頁數和排序規則。
{ query: { bool: { // 布林查詢 must: [ [ { multi_match: { query: "精確", fields: ["message", "title"], type: "best_fields" } } ] ], filter: [ { term: { category: "error" } }, { term: { project: "backend-app" } }, { term: { message_type: "runtime" } }, { range: { ctime: { gte: 1699286400, lt: 1699372800 } } } ] } }, from: 0, size: 10, sort: [ { id: { order: "DESC" } } ] }
布林查詢(bool),只有符合整個布林條件的檔案才會被搜尋出來,支援 4 種組合型別:
- must:可包含多個查詢條件,每個條件都被滿足才能命中,每次查詢需要計算相關度得分。
- should:可包含多個查詢條件,只要滿足一個條件就能命中,匹配到結果越多,相關度得分也越高。
- filter:與 must 作用類似,但是不計算相關度得分,結果在一定條件下會被快取。
- must_not:與 must 作用相反,並且也不計算相關度得分,結果在一定條件下會被快取。
多欄位匹配(multi_match)允許用同一段文字檢索多個欄位,其中 best_fields 是預設的搜尋方式,搜尋文字與哪個欄位相關度最高,就使用最佳欄位中的 _score。
ES 內建了 8 種文字分析器,但對於中文的支援並不友好,無法準確的反映中文文字的語意,所以對於中文需要安裝另一款分析器:ik。
除了常規的全文檢索和精準查詢之外,ES 還支援經緯度搜尋,包括圓形、矩形和多邊形範圍內的搜尋。
6)聚合
當需要對資料做分析時,就需要對資料進行聚合。在 MySQL 中常用的就是 sum()、group by 等語法。
ES 提供的聚合分為 3 大類:
- 度量聚合:計算搜尋結果在某個欄位上的數量統計指標,包括平均值、最大值、最小值、求和、基數(唯一值)、百分比、頭部命中等。
- 桶聚合:在某個欄位上劃定一些區間,每個區間是一個桶,統計結果能明確每個桶中的檔案數量。桶聚合還能巢狀其他的桶聚合或度量聚合來進行更為複雜的指標計算,例如詞條、直方圖、缺失等聚合。
- 管道聚合:把桶聚合統計的結果作為輸入來繼續做聚合統計,在結果中追加一些額外的統計資料。
下面是一個桶聚合的例子,在查詢條件中使用了 ES 特有的時間範圍語法糖(now-7d/d)。
聚合部分要使用 aggs 屬性包裹,其子屬性 date 自定義的聚合名稱(在搜尋結果中也會包含這個自定義的名稱),date_histogram 是聚合型別,以天為間隔,計算每天符合條件的數量。
{ query: { bool: { filter: [ { term: { category: "error" } }, { range: { ctime: { gt: "now-7d/d", // 當前時間減去 7 天 lte: "now/d" } } } ] } }, aggs: { date: { date_histogram: { field: "ctime", // 欄位名稱 interval: "day", // 以天為間隔 time_zone: "+08:00" } } } }
聚合結果與查詢結果類似,也會包含符合查詢條件的檔案列表,但是還會多一個 aggregations 屬性。
其 date 屬性就是之前自定義的聚合名稱,buckets 中就是聚合結果,key 是聚合的欄位值,doc_count 是計算的結果值,key_as_string 是格式化後的日期值,可在查詢時指定格式。
{ took: 245, timed_out: false, _shards: { total: 2, successful: 2, skipped: 0, failed: 0 }, hits: { total: { value: 3799, relation: "eq" }, max_score: 0, hits: [{}, {}] }, aggregations: { date: { buckets: [ { key_as_string: "2023-11-02T00:00:00.000+08:00", key: 1698854400000, doc_count: 451 }, { key_as_string: "2023-11-03T00:00:00.000+08:00", key: 1698940800000, doc_count: 594 }, { key_as_string: "2023-11-04T00:00:00.000+08:00", key: 1699027200000, doc_count: 612 } ] } } }
參考資料:
Frame of Reference 和 Roaring Bitmaps
elasticsearch-Index template 索引模板