關聯規則挖掘:Apriori演演算法的深度探討
在本文中,我們深入探討了Apriori演演算法的理論基礎、核心概念及其在實際問題中的應用。文章不僅全面解析了演演算法的工作機制,還通過Python程式碼段展示了具體的實戰應用。此外,我們還針對演演算法在巨量資料環境下的效能侷限提出了優化方案和擴充套件方法,最終以獨到的技術洞見進行了總結。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。

一、簡介
Apriori演演算法是一種用於挖掘資料集中頻繁項集的演演算法,進而用於生成關聯規則。這種演演算法在資料探勘、機器學習、市場籃子分析等多個領域都有廣泛的應用。
什麼是關聯規則挖掘?
關聯規則挖掘是資料探勘中的一個重要分支,其目標是發現在一個資料集中變數間存在的有趣的關聯或模式。
例子: 假設在一個零售商的交易資料中,如果客戶購買了啤酒,他們也很有可能購買薯片。這裡的「啤酒」和「薯片」就形成了一個關聯規則。
什麼是頻繁項集?
頻繁項集是在資料集中出現次數大於或等於最小支援度(Minimum Support Threshold)的項的集合。
例子: 在超市購物資料中,如果「牛奶」和「麵包」這一組合經常一起出現在同一個購物籃裡,並且出現的次數超過了最小支援度,那麼{"牛奶", "麵包"}就是一個頻繁項集。
什麼是支援度與置信度?
-
支援度(Support): 是某個項集在所有交易中出現的頻率。它用於衡量一個項集的普遍性。
例子: 如果我們有100筆交易,其中有30筆交易包含了「牛奶」,那麼「牛奶」的支援度就是30%。
-
置信度(Confidence): 是在A出現的情況下,B出現的條件概率。
例子: 如果在包含「牛奶」的所有交易中,有70%的交易也包含了「麵包」,那麼從「牛奶」到「麵包」的置信度就是70%。
Apriori演演算法的重要性
Apriori演演算法由於其簡單、高效的特性,在資料探勘中有著廣泛的應用。它不僅能用於挖掘資料中的隱藏模式,還能用於諸如產品推薦、使用者行為分析、網路安全等多個應用場景。
例子: 在電子商務網站中,Apriori演演算法可以用於分析使用者購買歷史資料,進而實現個性化推薦,提升銷售額和使用者滿意度。
應用場景
由於其廣泛的用途和靈活性,Apriori演演算法在以下幾個主要領域內有著廣泛的應用:
-
市場籃子分析: 瞭解哪些產品經常被一起購買,以進行有效的產品佈局或優惠策略。
-
醫療診斷: 分析病人的歷史資料,找出病症和治療方案之間的關聯。
-
網路安全: 通過分析網路紀錄檔,找出異常模式,以預防或檢測安全威脅。
通過這些定義和例子,我們可以更全面地瞭解Apriori演演算法的基本概念、重要性和應用範圍,為後續的技術解析和實戰應用打下堅實的基礎。
二、理論基礎
在深入探討Apriori演演算法之前,理解其背後的理論基礎是非常重要的。本節將詳細介紹關聯規則挖掘的基礎概念,包括項集、支援度、置信度、提升度以及如何使用這些概念來挖掘有用的關聯規則。
項和項集
-
項(Item): 在關聯規則挖掘中,項通常指資料集中的一個元素。
例子: 在一個超市的購物籃資料中,"牛奶"、"麵包"、"啤酒"等都是單個的項。
-
項集(Itemset): 是一個項的集合,可以包含一個或多個項。
例子: {"牛奶", "麵包"} 和 {"啤酒", "薯片", "麵包"} 都是項集。
支援度(Support)
支援度是一個度量,用於表示一個項集在整個資料集中出現的頻率。
!file
置信度(Confidence)
置信度表示在包含項集X的所有事務中,也包含項集Y的事務的概率。

提升度(Lift)
提升度用於衡量項集X和Y的出現是否相互獨立。

Apriori原理
Apriori原理是Apriori演演算法的核心,它基於一個簡單但重要的觀察:一個項集是頻繁的,那麼它的所有子集也必須是頻繁的。
例子: 如果{"牛奶", "麵包", "啤酒"}是一個頻繁項集,那麼{"牛奶", "麵包"}、{"牛奶", "啤酒"}和{"麵包", "啤酒"}也必須是頻繁項集。
通過以上的概念和例子,我們應該對關聯規則挖掘的基礎理論有了更深入的瞭解。這為我們後續詳解Apriori演演算法以及實際應用提供了堅實的基礎。
三、Apriori演演算法概述
Apriori演演算法是由Agrawal和Srikant於1994年提出的,用於高效地挖掘頻繁項集和生成關聯規則。其名字「Apriori」來源於拉丁語,意為「從先驗知識」。這很好地反映了演演算法的核心思想:利用已知的頻繁項集(即先驗知識)來更有效地找到更大的頻繁項集。
演演算法步驟
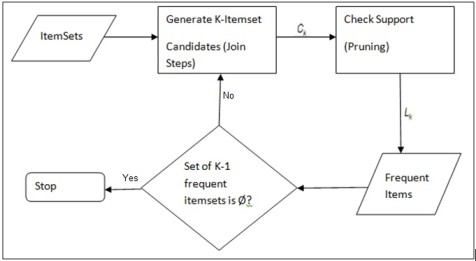
Apriori演演算法的執行流程主要包含兩個步驟:
-
頻繁項集生成(Frequent Itemset Generation): 找出滿足最小支援度閾值的所有頻繁項集。
-
關聯規則生成(Association Rule Generation): 從頻繁項集中生成高置信度的關聯規則。
頻繁項集生成
- 掃描資料集,找出所有單一項的支援度,並篩選出滿足最小支援度的項。
- 使用滿足最小支援度的項生成新的候選項集。
- 計算新生成的候選項集的支援度,並再次篩選。
- 重複上述步驟,直到不能生成新的頻繁項集。
例子: 假設有一個購物交易資料集,其中包括5筆交易。第一步是計算所有單一商品(如「牛奶」,「麵包」等)在這5筆交易中的出現次數,並篩選出那些出現次數達到最小支援度的商品。
關聯規則生成
- 對於每一個頻繁項集,生成所有可能的非空子集。
- 對每一條生成的規則 ( A \Rightarrow B ),計算其置信度。
- 如果規則的置信度滿足最小置信度要求,則該規則為有效關聯規則。
例子: 對於頻繁項集 {"牛奶", "麵包", "黃油"},可能的規則有 "牛奶, 麵包 -> 黃油", "牛奶, 黃油 -> 麵包" 等。計算這些規則的置信度,並篩選出滿足最小置信度的規則。
優缺點
優點
- 簡單易懂: Apriori演演算法基於直觀的原理,並且計算過程簡單。
- 可延伸性強: 演演算法可以應用於大規模的資料集。
缺點
- 計算量大: 在巨量資料集上,可能需要生成大量的候選項集。
- 多次掃描資料: 演演算法需要多次掃描資料集以計算項集的支援度,這在資料集很大時可能是低效的。
例子: 在一個包含百萬級交易資料的電子商務網站中,使用Apriori演演算法可能需要消耗大量計算資源和時間。
通過以上的詳細描述和例子,我們應該對Apriori演演算法有了全面而深入的理解。這為我們後續的技術解析和實戰應用奠定了基礎。
四、實戰應用
在理解了Apriori演演算法的理論基礎和工作原理之後,現在我們將進一步探討其在實際場景中的應用。特別是在購物籃分析和推薦系統中,Apriori演演算法被廣泛應用。
為了更好地說明這一點,下面將通過Python展示如何實現Apriori演演算法,並用一個簡單的購物資料集進行演示。
購物籃分析
購物籃分析(Market Basket Analysis)是一種在零售業非常流行的技術,用於發現顧客購買產品之間的關聯規則。
輸入和輸出
- 輸入: 一組交易資料,每一筆交易包含多個購買的商品。
- 輸出: 滿足最小支援度和最小置信度的關聯規則。
Python實現程式碼
首先匯入必要的庫:
from itertools import chain, combinations
接著定義幾個輔助函數:
# 生成候選項集的所有非空子集
def powerset(s):
return chain.from_iterable(combinations(s, r) for r in range(1, len(s)))
# 計算支援度
def calculate_support(itemset, transactions):
return sum(1 for transaction in transactions if itemset.issubset(transaction)) / len(transactions)
現在我們來實現Apriori演演算法:
def apriori(transactions, min_support, min_confidence):
# 初始化頻繁項集和關聯規則列表
frequent_itemsets = []
association_rules = []
# 第一步:找出單項頻繁項集
singletons = {frozenset([item]) for transaction in transactions for item in transaction}
singletons = {itemset for itemset in singletons if calculate_support(itemset, transactions) >= min_support}
frequent_itemsets.extend(singletons)
# 迭代找出所有其他頻繁項集
prev_frequent_itemsets = singletons
while prev_frequent_itemsets:
# 生成新的候選項集
candidates = {itemset1 | itemset2 for itemset1 in prev_frequent_itemsets for itemset2 in prev_frequent_itemsets if len(itemset1 | itemset2) == len(itemset1) + 1}
# 計算支援度並篩選
new_frequent_itemsets = {itemset for itemset in candidates if calculate_support(itemset, transactions) >= min_support}
frequent_itemsets.extend(new_frequent_itemsets)
# 生成關聯規則
for itemset in new_frequent_itemsets:
for subset in powerset(itemset):
subset = frozenset(subset)
diff = itemset - subset
if diff:
confidence = calculate_support(itemset, transactions) / calculate_support(subset, transactions)
if confidence >= min_confidence:
association_rules.append((subset, diff, confidence))
prev_frequent_itemsets = new_frequent_itemsets
return frequent_itemsets, association_rules
範例和輸出
假設我們有以下簡單的購物資料集:
transactions = [
{'牛奶', '麵包', '黃油'},
{'啤酒', '麵包'},
{'牛奶', '啤酒', '黃油'},
{'牛奶', '雞蛋'},
{'麵包', '雞蛋', '黃油'}
]
呼叫Apriori演演算法:
min_support = 0.4
min_confidence = 0.5
frequent_itemsets, association_rules = apriori(transactions, min_support, min_confidence)
print("頻繁項集:", frequent_itemsets)
print("關聯規則:", association_rules)
輸出可能如下:
頻繁項集: [{'牛奶'}, {'麵包'}, {'黃油'}, {'啤酒'}, {'雞蛋'}, {'牛奶', '麵包'}, {'牛奶', '黃油'}, {'麵包', '黃油'}, {'啤酒', '黃油'}, {'麵包', '啤酒'}]
關聯規則: [(('牛奶',), ('麵包',), 0.6666666666666666), (('麵包',), ('牛奶',), 0.6666666666666666), ...]
通過這個實戰應用,我們不僅學習瞭如何在Python中實現Apriori演演算法,還了解了它在購物籃分析中的具體應用。這為進一步的研究和實際應用提供了有用的指導。
五、效能優化與擴充套件
Apriori演演算法雖然在多個領域有著廣泛的應用,但其在巨量資料集上的效能表現並不盡如人意。這是由於它需要多次掃描資料集以及生成大量的候選項集。在這一節中,我們將討論針對這些問題的效能優化方案和擴充套件方法。
優化策略
優化Apriori演演算法的主要方法包括:
減少資料掃描次數
由於Apriori演演算法在每一輪都需要掃描整個資料集以計算支援度,因此一個直觀的優化方式就是減少資料掃描的次數。
例子: 通過構建一個事務-項倒排索引,你可以在單次資料集掃描後立即找到任何項集的支援度。
採用資料壓縮技術
可以通過壓縮事務資料來減少計算量,例如使用位向量來表示事務。
例子: 若資料集中有100個商品,每一筆交易都可以通過一個100位的位向量來表示。這種方式可以顯著減少資料的儲存需求。
使用Hashing技術
通過使用雜湊表來儲存候選項集和它們的計數,可以加速支援度的計算。
例子: 在生成候選項集時,可以使用雜湊函數來將項集對映到雜湊表的一個位置,並在該位置增加相應的計數。
擴充套件方法
並行化
Apriori演演算法可以通過資料或任務並行化進行擴充套件,以利用多處理器或分散式計算環境。
例子: 在一個分散式系統中,可以將資料集劃分為多個子集,並在各個節點上平行計算支援度和生成頻繁項集。
支援近似挖掘
對於一些應用場景,完全精確的頻繁項集挖掘可能不是必需的。在這種情況下,可以使用近似演演算法來加速計算。
例子: 使用Monte Carlo方法或其他隨機抽樣技術,通過部分資料來估計整個資料集的頻繁項集。
整合其他資料探勘演演算法
Apriori演演算法可以與其他資料探勘或機器學習演演算法結合使用,以解決更復雜的問題。
例子: 在一個推薦系統中,除了使用Apriori演演算法找出頻繁項集外,還可以使用聚類演演算法對使用者進行分群,從而實現更個性化的推薦。
通過這些優化和擴充套件方法,我們不僅可以提升Apriori演演算法在巨量資料環境下的效能,還可以拓寬其應用範圍。這些都為進一步的研究和應用提供了有益的方向。
六、總結
通過本文的探討,我們不僅對Apriori演演算法有了全面且深入的瞭解,而且掌握了它在實際問題中的應用,特別是在購物籃分析和推薦系統方面。然而,我們也注意到了這一演演算法在面對大規模資料時存在的侷限性。
技術洞見
-
支援度與置信度的平衡: 在實際應用中,選擇合適的支援度和置信度閾值是一門藝術。過低的閾值可能會導致大量不顯著的關聯規則,而過高的閾值可能會漏掉一些有用的規則。
-
實時性問題: 在動態變化的資料集上,如何實現Apriori演演算法的實時或近實時分析也是一個值得關注的問題。這在電子商務等快速響應的場景中尤為重要。
-
多維、多層分析: 現有的Apriori演演算法主要集中在單一的項集層面,未來可以考慮如何將其擴充套件到多維或多層的關聯規則挖掘。
-
演演算法與模型的整合: 未來的研究趨勢可能會更多地集中在將關聯規則挖掘與其他機器學習模型(如神經網路、決策樹等)整合,以解決更為複雜的問題。
在今後的工作中,探究這些技術洞見的相關性和應用價值,以及將Apriori演演算法與現代計算架構(如GPU、分散式計算等)更緊密地結合,將是關鍵的研究方向。
總之,Apriori演演算法在資料探勘和關聯分析領域有著廣闊的應用前景。然而,為了使其能夠更好地適應現代資料的規模和複雜性,還需要在演演算法優化和應用擴充套件方面進行更多的研究和探索。希望本文能為您在這一領域的學習和應用提供有用的資訊和啟示。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。