解密Prompt系列19. LLM Agent之資料分析領域的應用:Data-Copilot & InsightPilot
在之前的 LLM Agent+DB 的章節我們已經談論過如何使用大模型接入資料庫並獲取資料,這一章我們聊聊大模型代理在資料分析領域的應用。資料分析主要是指在獲取資料之後的資料淨化,資料處理,資料建模,資料洞察和資料視覺化的步驟。可以為經常和資料打交道,但是並不需要太過艱深的資料分析能力的同學提供日常工作的支援,已看到很多 BI 平臺在嘗試類似的方案。這裡我們聊兩篇論文:Data-Copilot 和 InsightPilot, 主要參考一些有意思的思路~
資料分析:Data-Copilot
- paper: Data-Copilot: Bridging Billions of Data and Humans with Autonomous Workflow
- github: https://github.com/zwq2018/Data-Copilot
先介紹下浙大提出的已擴充套件的資料分析框架,支援多種金融資料型別的查詢,資料處理,簡單建模,和資料視覺化。Data-copilot 以金融領域的資料分析為例,提供了一套可以簡單基於已有資料進行擴充套件生成的資料分析框架。
整個框架分成兩個部分,基於大模型的 API 生成和基於生成 API 的 llm 任務規劃和執行。其實說複雜也不復雜,資料分析任務裡面幾個核心的要素就是
- 分析啥:提問的實體,股票?債券?基金經理?
- 分析哪段時間:資料的覆蓋範圍,一季度?今年?
- 用什麼指標:股票的收益率?債券利率?基金淨值?
- 如何分析:收益對比?價格漲跌?排名?
- 如何輸出:繪圖?表格?文字?
API生成
設計部分其實是使用大模型來構建更符合上下文語意的 API 呼叫語句,以及 API 的輸入輸出。這部分程式碼並未開源......所以我們只依據論文和腦補做簡單介紹。主要分成以下四個步驟
1. 生成更多的使用者請求
API 的生成需要基於使用者會問什麼樣的問題。而使用者的提問又是基於你有什麼樣的資料。因此這裡使用資料描述和人工編寫的種子提問作為上文,讓 LLM 生成更多的使用者提問。
2. 生成 API 呼叫語句
把以上生成的所有使用者提問,一個個輸入模型,使用以下 prompt 指令引導 llm 生成完成一個資料分析任務,所需的多個步驟,以及每個步驟對應的API 描述和虛擬碼"Interface1={Interface Name: %s, Function description:%s, Input and Output:%s}"
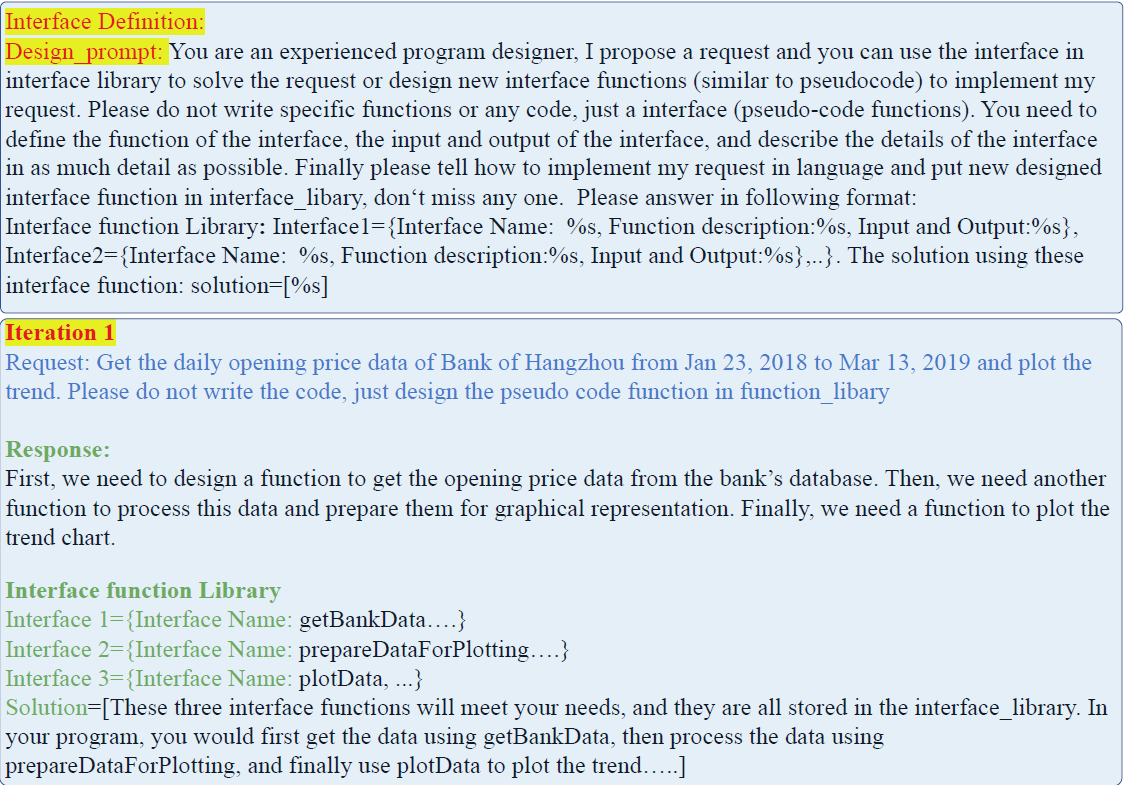
3. 合併相似的 API 呼叫
每得到一個新的 API function,都會和已生成的 API function 配對後輸入模型,並使用以下指令讓大模型判斷兩個 function 是否功能相似可以合併為一個新的 API。例如把查詢 GDP 的 API 和查詢 CPI 的 API 合併為查詢 GDP_CPI 的 API。不過個人感覺這個方案時間和 token 開銷頗大,可能比較適合 online API 的線上構建,在離線構建時先基於 API 的描述進行聚類,然後每個 cluster 進行合併可能更經濟實惠?

4. 為每個 API 生成對應程式碼
最後針對合併後的 API,使用大模型進行程式碼生成。這裡使用了 pandas DataFrame 作為資料處理,資料繪圖的資料互動格式。這裡論文把工具呼叫分成了 5 個大類:資料獲取,資料處理,合併切片,建模和視覺化。

看完以上整個 API 構建流程,不難發現使用 llm 來自動生成 API 有以下幾個好處(不過估計完全自動化難度不小......)
- 節省人力
- 和 APE 的思路類似,大模型生成的指令更符合模型生成偏好,API 同理
- 當前是離線批次生成,如果可以優化為 online 的 API 生成的話,可以使得 API 具有動態可延伸性
API呼叫
獲得 API 之後,就是如何排列組合規劃 API 的執行來回答使用者的提問/完成使用者的任務。這裡的任務流同樣拆成了多個步驟:
意圖識別
第一步是意圖識別,這裡其實融合了搜尋中 query 預處理的幾個功能:
- 意圖識別用於縮小問題範圍提高後面 API 呼叫的準確率
- 時效性模組基於今天的日期和使用者提問,生成問題對應的具體時間範圍(包括時間範圍標準化)
- 實體模組用於定位問題的核心實體
- 輸出形式的判別是繪圖、表格還是文字輸出
論文把以上多個模組融合成了基於 few-shot 的大模型改寫任務,會把使用者的提問改寫成一個新的具有明確時間區間,任務型別更加明確的文字,與其說是意圖識別,其實更像 query 改寫。如下
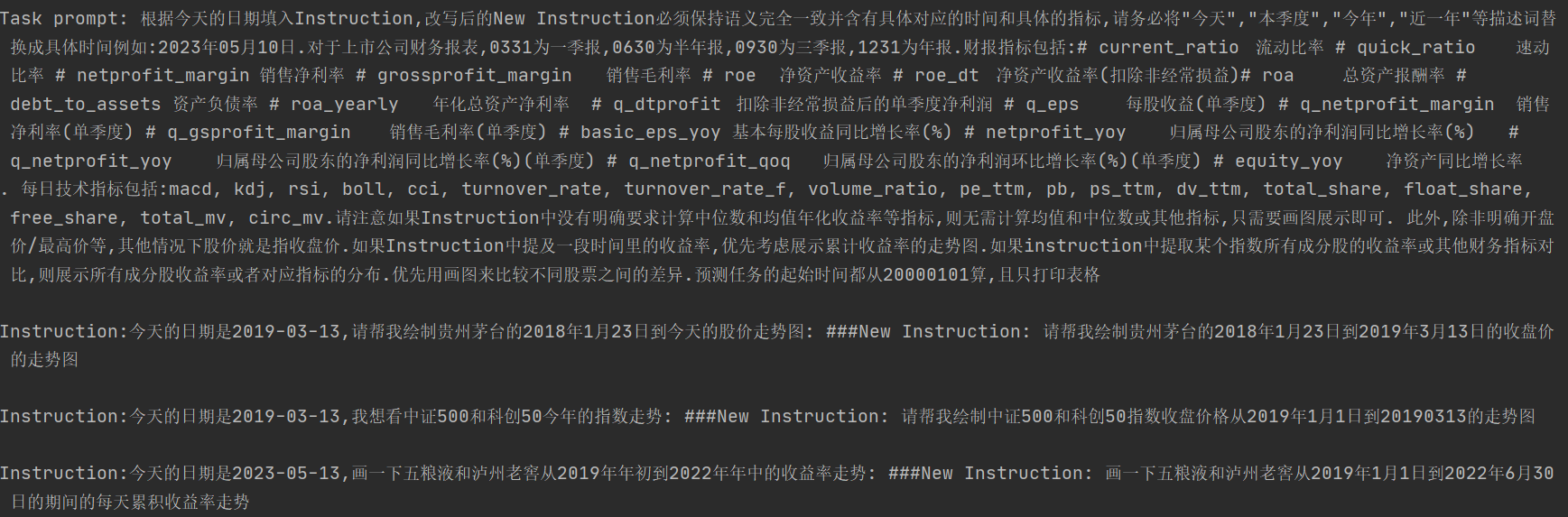
個人感覺意圖這裡完全可以不基於大模型,或者可以用大模型造樣本再蒸餾到小模型上。以及整個意圖識別的模組可以拆分成多個獨立且粒度更細的模組,在金融領域至少可以拆分成大類資產實體的抽取對齊,針對不同資產型別的不同問題意圖的識別,以及獨立的時效性生成/判別模組。意圖模組直接影響後面的行為規劃,需要準確率和執行成功率都足夠高。
行為規劃
行為規劃模組包含兩個步驟,第一步是任務拆解,以上改寫後的 query 會作為輸入,輸入任務拆解模組。同樣是基於 few-shot 的大模型指令任務,把任務拆分成多個執行步驟,每個步驟包括任務型別。
這裡作者定義了 stock_task、fund_task、economic_task, visualization_task、financial_task 這 5 種任務,任務拆解類似 COT 把一個任務拆分成多個執行步驟,但本質上還是為了縮小 API的呼叫範圍。指令如下

基於以上任務選擇模組每個步驟的任務型別,例如 stock_task,會有不同的 few-shot prompt 來指導模型針對該任務型別,生成多步的 API 呼叫,包括每一步呼叫的 API,輸入,輸出和返回值。行為規劃部分通用指令如下
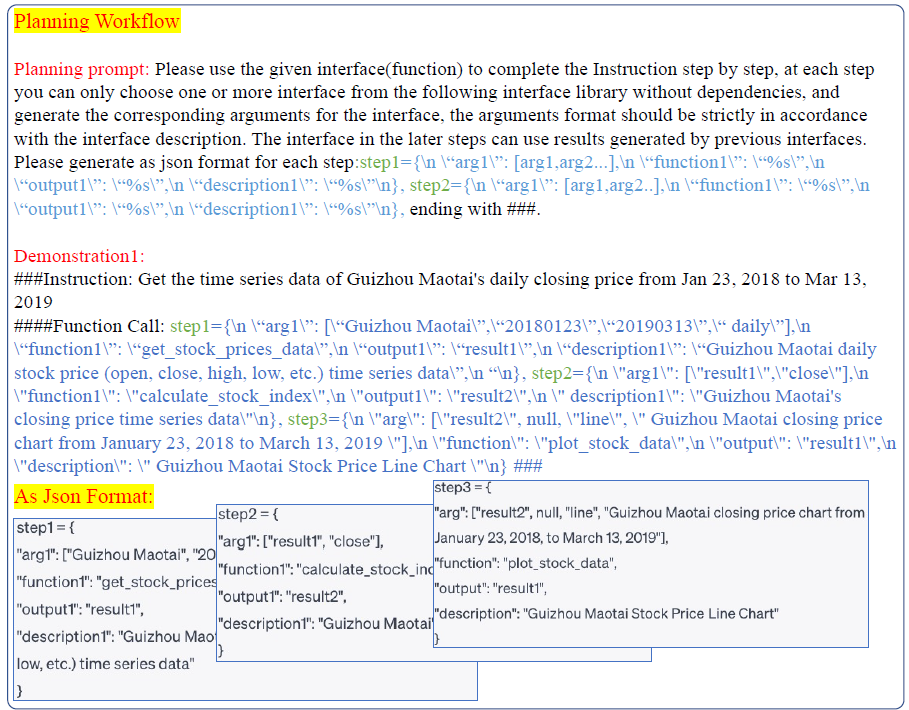
行為規劃中一個有意思的點,是論文構建的API中包含三種不同的執行方式,序列操作常規單個輸入單個輸出,並行操作獲取一個證券的多個指標資料,以及迴圈操作,類似 map 對多個輸入執行相同的操作。以下是Data-Copilot的Demo
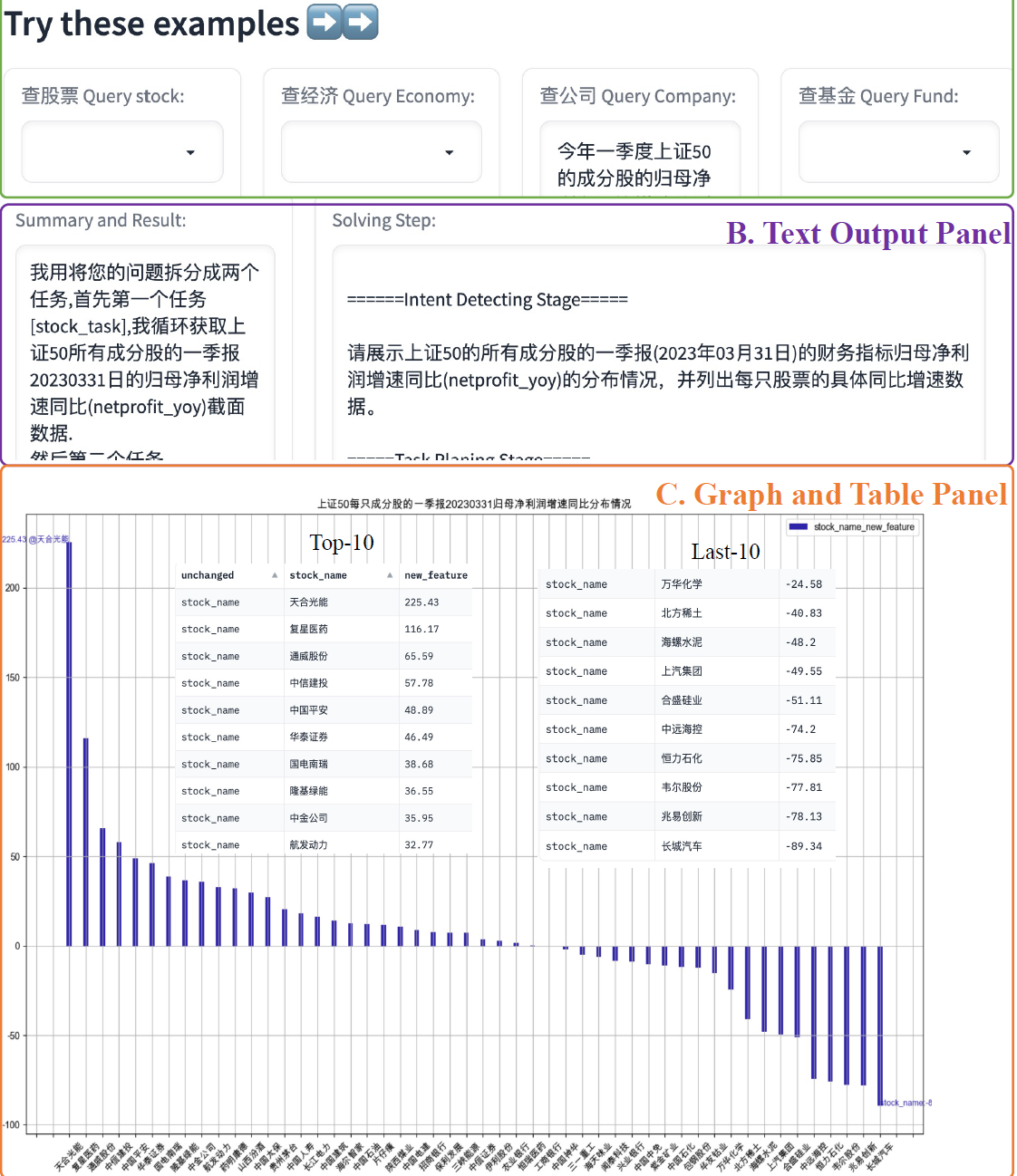
資料洞察:InsightPilot
- paper:Demonstration of InsightPilot: An LLM-EmpoweredAutomated Data Exploration System
- 相關 paper:QuickInsights: Quick and Automatic Discovery of Insights fromMulti-Dimensional Data
- 相關 paper:MetaInsight: Automatic Discovery of Structured Knowledge forExploratory Data Analysis
- 相關 paper:XInsight: eXplainable Data Analysis Through The Lens ofCausality
- https://www.msra.cn/zh-cn/news/features/exploratory-data-analysis
InsightPilot與其說是一篇 paper,更像是一份微軟 BI 的產品白皮書。主打 EDA 資料洞察,和上面的 Data-copilot 拼在一起,也算是把資料分析最基礎工作涵蓋了。舉個資料洞察的栗子,最早在 UG 使用者增長部門工作時,每次 APP 活躍使用者下降了,資料分析組收到的任務就是趕緊去分析活躍使用者資料,看看到底使用者為啥流失了,是被競品搶走了,是最近上了什麼新功能使用者不喜歡,還是之前活動拉來的使用者質量不高留存較少,基於這些資料洞察,好制定下一步挽留流式使用者,啟用沉默使用者的具體方案。
那如何發現資料中的異常點?一個基礎的操作就是對資料進行不同維度的拆分對比。例如把活躍使用者分成男女,老幼,不同城市,不同機型,渠道來源,不同閱讀偏好等等維度,觀察不同 subgroup 的使用者他們的活躍是否發生下降,下降比例是否相同,是否有某個維度的使用者組流失最顯著。這個維度拆分可以是平行維度,也可以是下鑽維度,對比方式可以是一階變化趨勢對比,也可以是波動率等二階趨勢的對比等等
微軟的實現方案其實是使用 LLM 把之前微軟已經開發應用到 BI 的三款資料洞察工具進行了組合串聯,這三款資料洞察工具分別是 QuickInsight,MetaInsight和XInsight。我們先簡單介紹下這三款工具,再看大模型要如何對資料分析工具進行組合串聯。
Insights 們
QuickInsight
QuickInisght 是最早也是功能最基礎的資料分析工具,它能快速發現多維資料中的 pattern。它的洞察資料單元由三個要素組成subject ≔ {