python 資料視覺化:直方圖、核密度估計圖、箱線圖、累積分佈函數圖
本文使用資料來源自2023年數學建模國賽C題,以附件1、附件2資料為基礎,通過excel的資料透視表等功能重新彙總了一份新的資料表,從中擷取了一部分資料為例用於繪製圖表。繪製的圖表包括一維直方圖、一維核密度估計圖、二維直方圖、二維核密度估計圖、箱線圖、累計分佈函數圖。
目錄
1.一維直方圖、一維核密度估計圖
2.二維直方圖、二維核密度估計圖
3.箱線圖、累計分佈函數圖
4.附錄:資料
1.一維直方圖和核密度估計圖
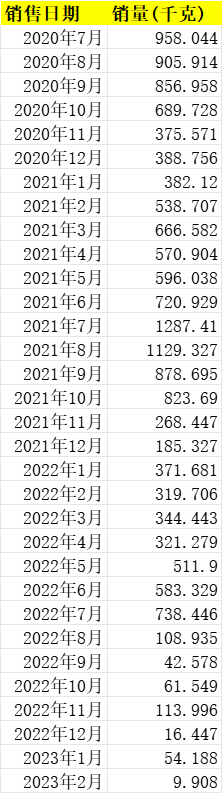
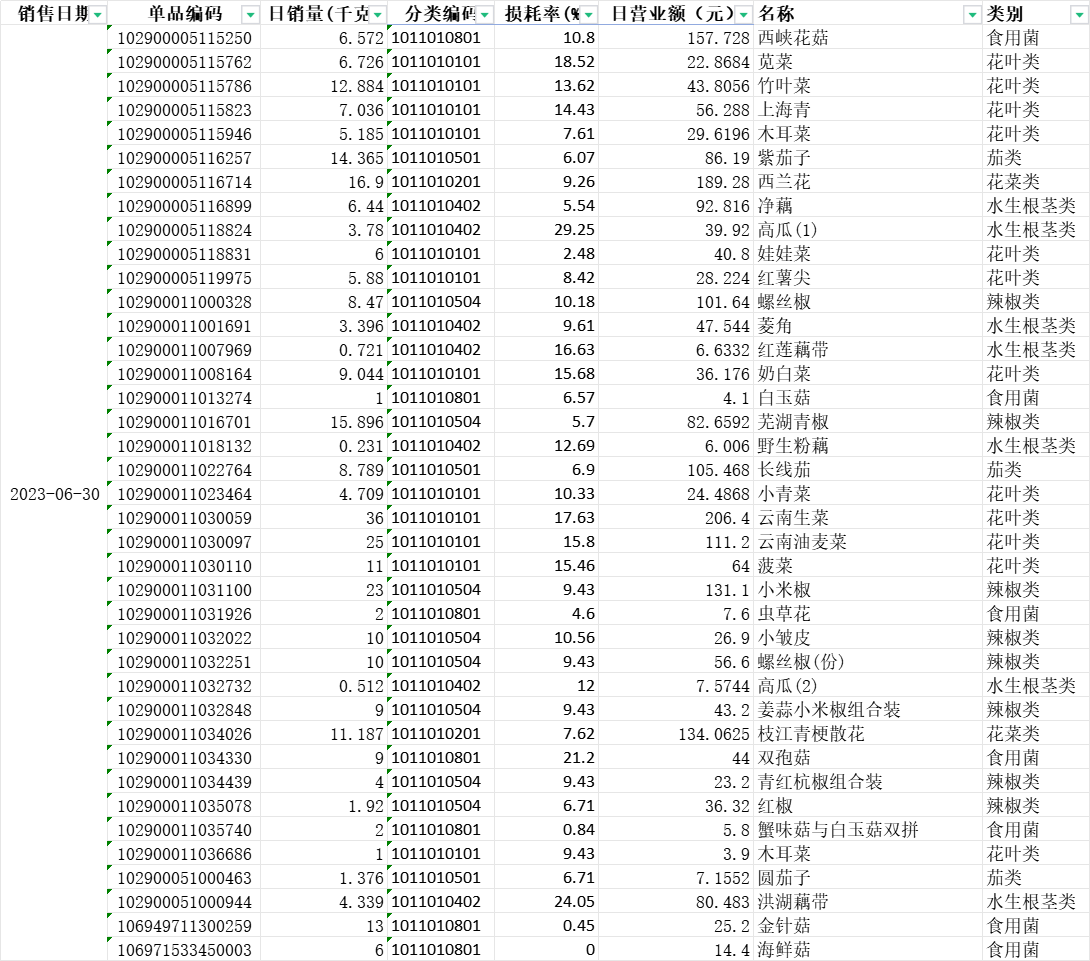
以某生鮮超市2023年6月30日銷售流水資料為基礎,整理出當日的各類商品銷售情況表(如4.附件:資料的圖所示),繪製了蔬菜類別的一維直方圖、日銷量的一維核密度估計圖。核密度估計圖可以反映了銷售量較為集中的範圍。
程式碼步驟如下:
①從Excel檔案中讀取名為"2023-6-30日銷售情況"的工作表資料
②從表中提取損耗率、日銷量和類別等關鍵列的資料
③利用seaborn和matplotlib繪製了一個包含兩個子圖的圖形,分別是:
蔬菜類別的一維直方圖,顯示每個類別的銷售頻數
日銷量的一維核密度估計圖,顯示銷售額的分佈情況
⑥設定了圖形的標籤、標題和佈局,確保圖形的可讀性和美觀性,通過plt.show()顯示生成的圖形
關鍵函數:
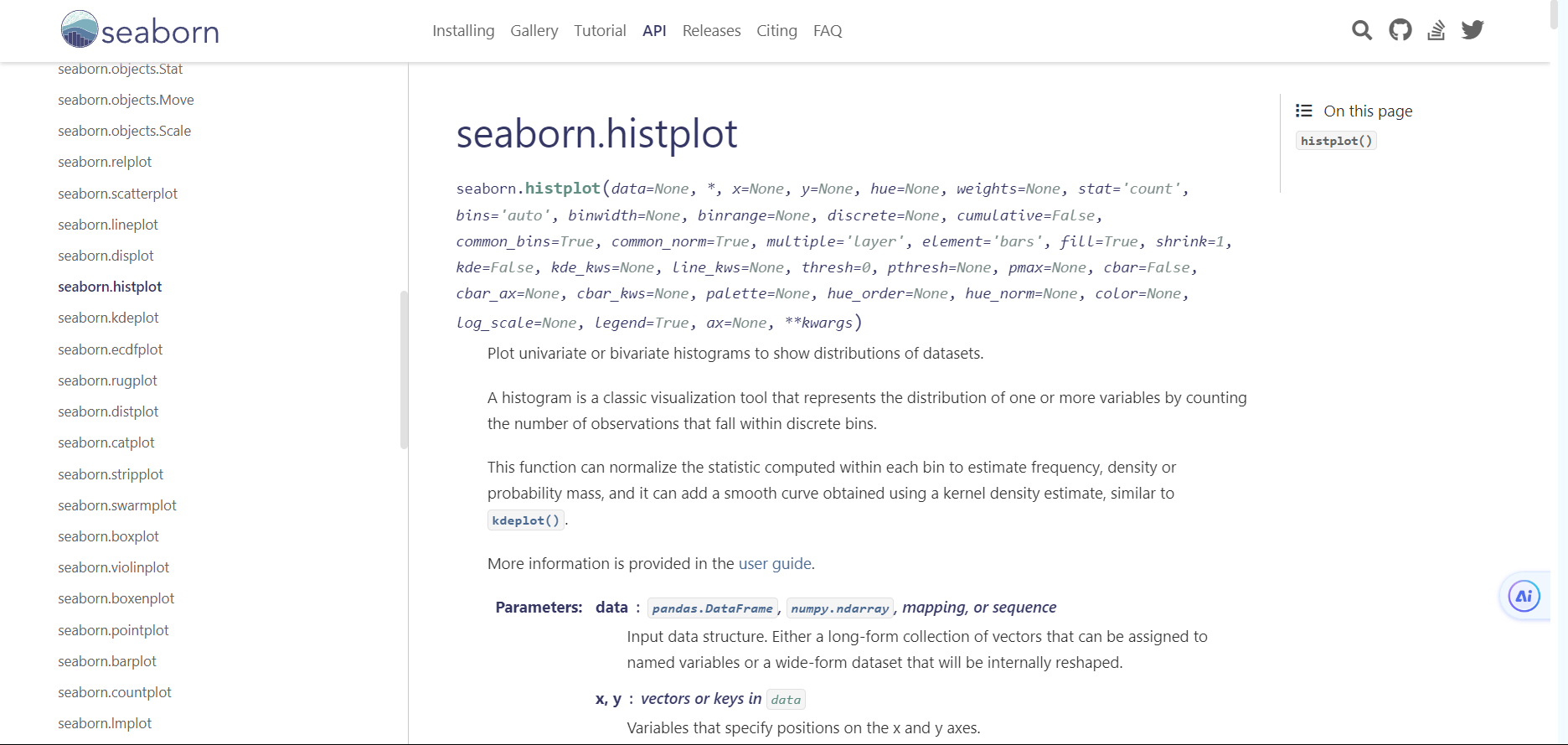
①seaborn.histplot(data, bins=20, kde=False, color='steelblue') # 繪製一維直方圖
seaborn.histplot() 用於繪製一維直方圖,直方圖是一種對資料分佈進行粗略估計的圖形表示。它將資料範圍劃分為一系列連續的區間,然後統計每個區間內資料點的數量,並將這些數量用柱狀圖表示。通過直方圖,可以直觀地看到資料的分佈情況,瞭解資料集中的集中趨勢、離散程度等資訊
data:要繪製的資料,可以是 Pandas DataFrame、NumPy 陣列或其他類似的資料結構。
bins:指定直方圖的箱子數量,或者是箱子的邊緣位置。可以是一個整數,表示箱子的數量,也可以是一個表示箱子邊緣位置的序列。預設值為 auto,由 Seaborn 根據資料自動選擇
False。
color:指定直方圖的顏色。可以是字串(表示顏色的名稱)、元組(表示 RGB 值)或其他有效的顏色表示方式。
詳細引數可見官方檔案:seaborn.histplot — seaborn 0.13.0 documentation (pydata.org)
②seaborn.kdeplot(data, fill=True, color='steelblue')#繪製一維核密度圖
seaborn.kdeplot()用於繪製一維核密度圖,核密度圖是通過對資料進行平滑處理,估計概率密度函數的圖形表示。核密度圖可以提供更加平滑的資料分佈估計,相比直方圖,它對資料的分佈進行了更加連續的建模。
data:要繪製的資料,可以是 Pandas DataFrame、NumPy 陣列或其他類似的資料結構
fill:一個布林值,表示是否填充核密度圖下方的區域。如果為True,則填充;如果為 False,則只繪製輪廓線。預設為 True
color:指定核密度圖的顏色。可以是字串(表示顏色的名稱)、元組(表示 RGB 值)或其他有效的顏色表示方式。
程式碼:
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 import seaborn as sns # matplotlib的補充 4 5 # 讀取Excel檔案 6 file_path = "單日銷售情況.xlsx" 7 sheet_name = "2023-6-30日銷售情況" 8 df = pd.read_excel(file_path, sheet_name) 9 10 # 提取所需的列 11 selected_columns = ['損耗率(%)', '日銷量(千克)', '類別'] 12 selected_data = df[selected_columns] 13 14 # 設定顯示中文 15 plt.rcParams['font.sans-serif'] = ['KaiTi'] # 'SimHei'也可以 16 plt.rcParams['axes.unicode_minus'] = False 17 18 # 繪製一維直方圖 19 plt.figure(figsize=(12, 6)) 20 plt.subplot(1, 2, 1) 21 sns.histplot(selected_data['類別'], bins=20, kde=False, color='steelblue') 22 plt.xlabel('類別') 23 plt.ylabel('頻數') 24 plt.title('某生鮮超市2023年6月30日銷售蔬菜類別一維直方圖') 25 26 # 繪製一維核密度估計圖 27 plt.subplot(1, 2, 2) 28 sns.kdeplot(x=selected_data['日銷量(千克)'], fill=True, color='steelblue') 29 plt.xlabel('日銷量(千克)') 30 plt.ylabel('核密度估計') 31 plt.title('某生鮮超市2023年6月30日銷售額一維核密度估計圖') 32 33 # 顯示圖形 34 plt.tight_layout() 35 plt.show()
2.二維統計直方圖和核密度估計圖
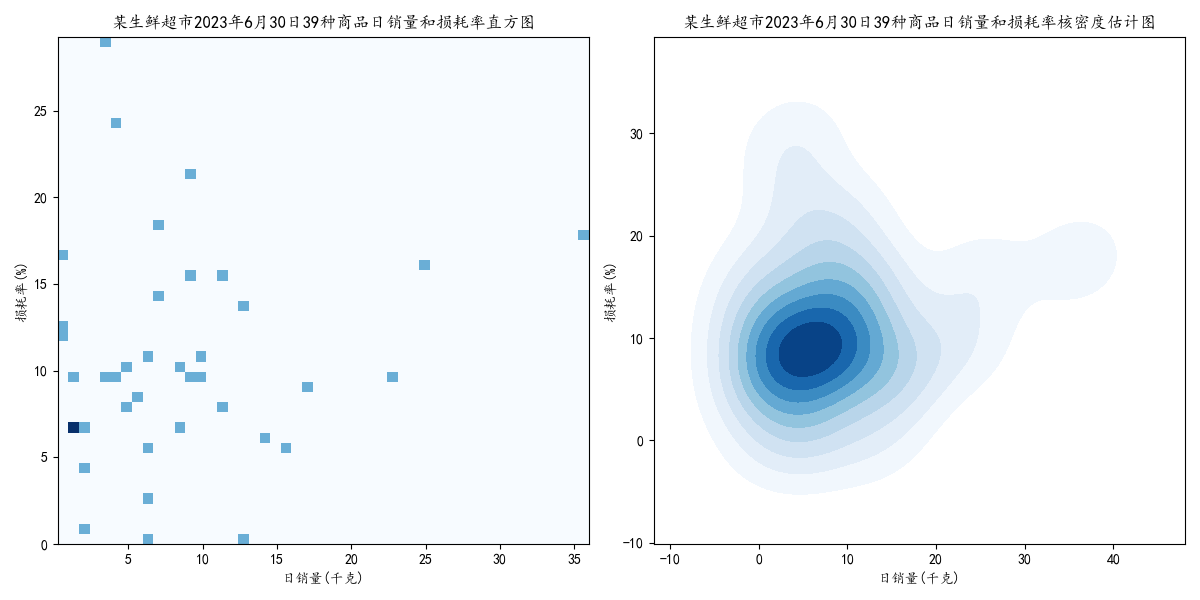
以某生鮮超市2023年6月30日銷售流水資料為基礎,整理出當日的各類商品銷售情況表,繪製了某生鮮超市2023年6月30日39種商品的日銷量和損耗率的二維統計直方圖和二維核密度估計圖。
關鍵步驟:
①讀取資料:從Excel檔案中讀取了名為"2023-6-30日銷售情況"的工作表的資料。
②提取所需列:從資料中提取了'損耗率(%)'和'日銷量(千克)'兩列資料。
③設定圖形引數:設定了中文顯示和防止負號顯示問題的引數。
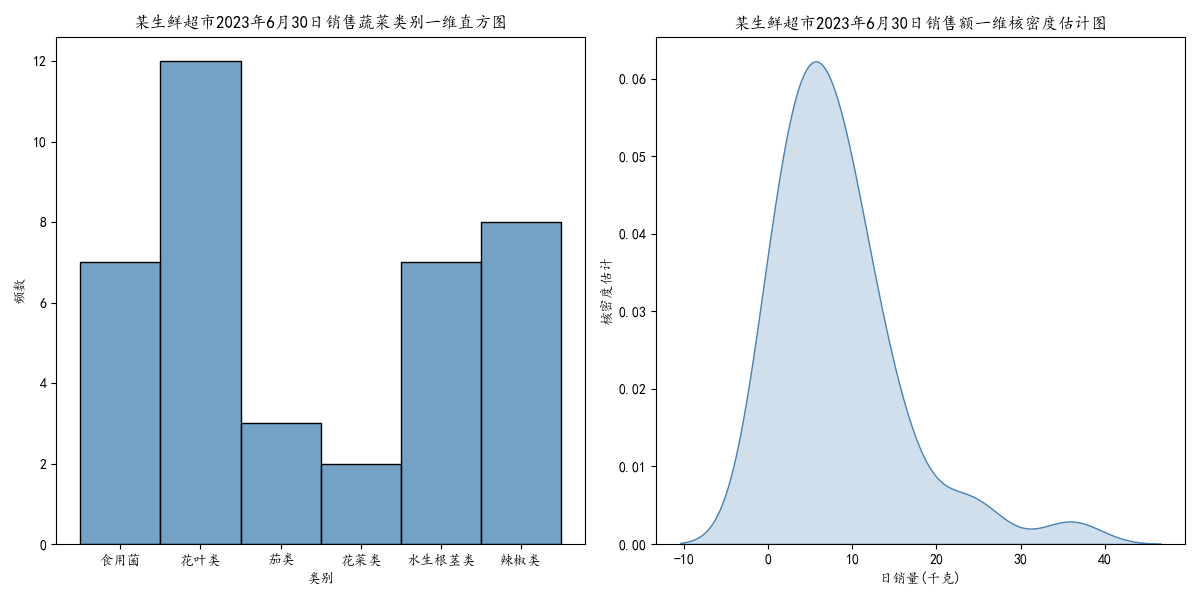
④繪製統計直方圖和核密度估計圖:利用matplotlib和seaborn繪製了一個包含兩個子圖的圖形。左側子圖是二維直方圖,表示了日銷量和損耗率之間的關係;右側子圖是核密度估計圖,展示了這兩個變數的分佈情況。
⑤顯示圖形:利用plt.show()將圖形顯示出來。
關鍵函數:
①plt.hist2d(x=selected_data['日銷量(千克)'],y=selected_data['損耗率(%)'],bins=(50,50),cmap='Blues'):
該函數用於繪製二維直方圖,其中x和y分別為資料的兩個維度橫軸和縱軸,bins引數指定了直方圖的箱體數量,cmap引數指定了顏色對映。
②sns.kdeplot(x=selected_data['日銷量(千克)'],y=selected_data['損耗率(%)'],cmap='Blues',fill=True):
該函數用於繪製核密度估計圖,其中x和y分別為資料的兩個維度,cmap引數指定了顏色對映,fill=True表示使用顏色填充密度曲線下面的區域。
程式碼:
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 import seaborn as sns # matplotlib的補充 4 5 # 讀取Excel檔案 6 file_path = "單日銷售情況.xlsx" 7 sheet_name = "2023-6-30日銷售情況" 8 df = pd.read_excel(file_path, sheet_name) 9 10 # 提取所需的列 11 selected_columns = ['損耗率(%)', '日銷量(千克)'] 12 selected_data = df[selected_columns] 13 14 # 設定顯示中文 15 plt.rcParams['font.sans-serif'] = ['KaiTi'] # 'SimHei'也可以 16 plt.rcParams['axes.unicode_minus'] = False 17 18 # 繪製統計直方圖和核密度估計圖 19 plt.figure(figsize=(12, 6)) 20 21 # 繪製二維直方圖 22 plt.subplot(1, 2, 1) 23 plt.hist2d(x=selected_data['日銷量(千克)'], y=selected_data['損耗率(%)'], bins=(50, 50), cmap='Blues') 24 plt.xlabel('日銷量(千克)') 25 plt.ylabel('損耗率(%)') 26 plt.title('某生鮮超市2023年6月30日39種商品日銷量和損耗率直方圖') 27 28 29 # 繪製核密度估計圖 30 plt.subplot(1, 2, 2) 31 sns.kdeplot(x=selected_data['日銷量(千克)'], y=selected_data['損耗率(%)'], cmap='Blues', fill=True) 32 plt.xlabel('日銷量(千克)') 33 plt.ylabel('損耗率(%)') 34 plt.title('某生鮮超市2023年6月30日39種商品日銷量和損耗率核密度估計圖') 35 36 # 顯示圖形 37 plt.tight_layout() 38 plt.show()
3.箱線圖、累積分佈函數圖
常見的資料分佈圖表有直方圖、核密度估計圖、箱線圖、散點圖、累積分佈函數圖等,本部分以某生鮮超市2020年7月-2023年2月銷售流水資料為基礎,整理出小白菜和雲南生菜的月銷量,繪製箱線圖、累積分佈函數圖,通過箱線圖和累積分佈函數圖分別展示了不同蔬菜銷售量的總體分佈和累積概率分佈情況。
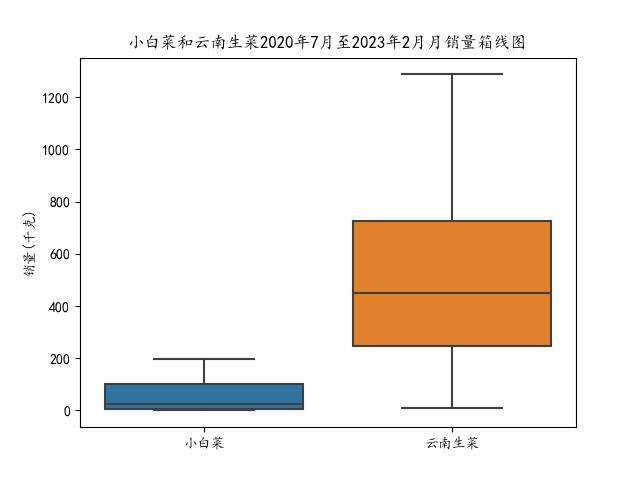
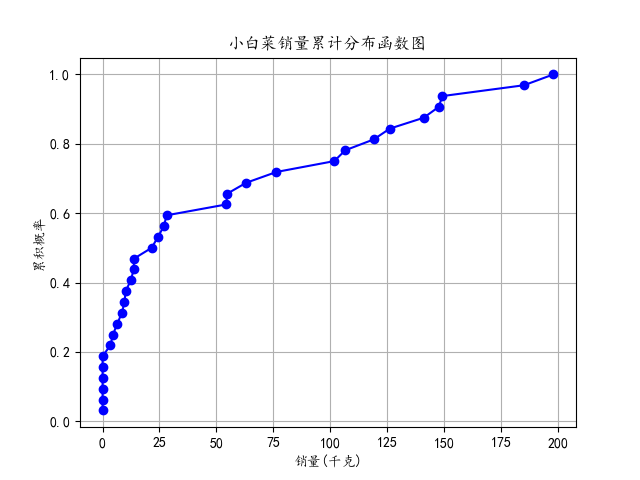
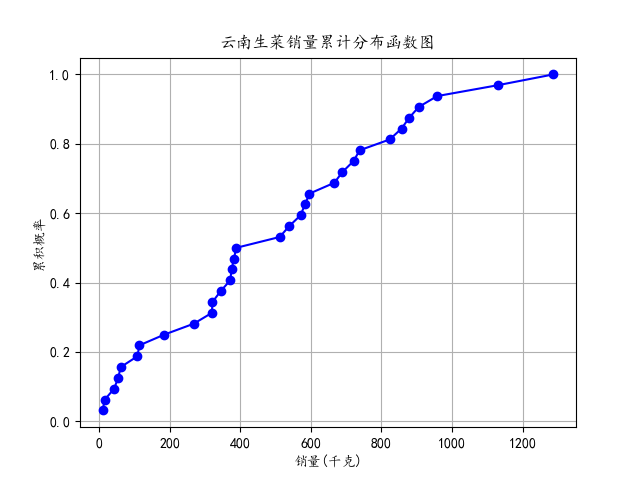
箱線圖,又稱為盒須圖、箱型圖,是一種用於顯示資料分佈情況的統計圖表。它能夠展示一組或多組資料的中位數、四分位數、最小值、最大值以及可能的異常值
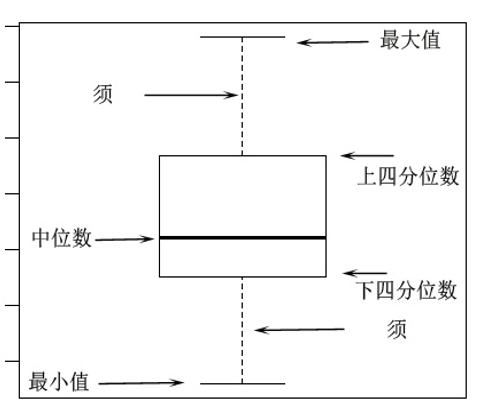
箱體:表示資料的中間50%範圍,即上四分位數到下四分位數之間的資料。箱體的長度代表資料的離散度。
中位數:位於箱體中間的線條,表示資料的中間值。
須:由箱體向外延伸的直線,表示資料的最大值和最小值。有時,須的長度可能被限制,以確定是否存在異常值。
異常值:超過須的特定範圍的資料點,通常被認為是異常值。在箱線圖中,異常值通常用圓點或叉號表示。
箱線圖的繪製過程包括計算資料的四分位數和中位數,然後根據這些值繪製箱體和須。箱線圖對於檢測資料的中心趨勢、分散程度以及異常值非常有用,特別適用於比較不同組或類別之間的資料分佈。
累積分佈函數:累計分佈函數圖是用來表示隨機變數的分佈情況的圖形,顯示的是隨機變數小於或等於某個特定值的概率,是概率分佈函數的積分。通過觀察累積分佈函數圖,可以瞭解隨機變數在不同取值上的累積概率。
關鍵步驟:
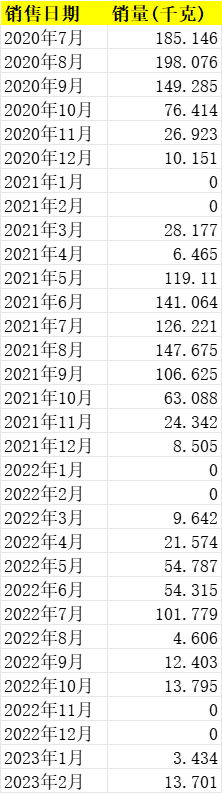
①從Excel檔案中讀取兩個不同蔬菜(小白菜和雲南生菜)每月銷售資訊的資料。
②為每個資料框新增了一個名為"來源"的標籤,以便識別不同蔬菜的來源。
③將兩個資料框合併為一個名為combined_data的新資料框。
④利用seaborn繪製了一個箱線圖,展示了小白菜和雲南生菜在2020年7月至2023年2月期間每月銷量的分佈情況。箱線圖顯示了銷量的中位數、上下四分位數和異常值。
⑤針對小白菜和雲南生菜分別提取銷量列,計算了它們的累積分佈函數,並繪製了兩個累積分佈函數圖。這些圖展示了銷量在累積概率上的分佈情況,幫助瞭解銷量的累積趨勢。
關鍵函數:
①sns.boxplot(x='來源',y='銷量(千克)',data=combined_data):使用seaborn繪製箱線圖,展示不同蔬菜來源的銷量分佈情況。
②累積分佈函數
np.sort(sales_data):對銷量資料進行排序。
np.arange(1,len(sorted_data)+1)/len(sorted_data):計算累積分佈函數的概率值。
注:np.arange(1,len(sorted_data)+1)生成一個從 1 到資料集長度的陣列,表示每個資料點的累積順序。然後,除以資料集的長度 len(sorted_data),將排名歸一化到範圍 [0, 1],從而得到了每個資料點對應的累積概率。
plt.plot(sorted_data,cumulative_prob,marker='o',linestyle='-',color='b'):使用matplotlib繪製累積分佈函數圖。
程式碼:
1 import numpy as np 2 import pandas as pd 3 import matplotlib.pyplot as plt 4 import seaborn as sns 5 6 # 讀取Excel檔案 7 file_path = "某件商品資訊.xlsx" 8 sheet_name1 = "小白菜每月銷售資訊" 9 sheet_name2 = "雲南生菜每月銷售資訊" 10 df1 = pd.read_excel(file_path, sheet_name1) 11 df2 = pd.read_excel(file_path, sheet_name2) 12 13 # 給資料新增標籤,以便識別來源 14 df1['來源'] = '小白菜' 15 df2['來源'] = '雲南生菜' 16 17 # 合併兩個資料框 18 combined_data = pd.concat([df1, df2]) 19 20 # 設定顯示中文 21 plt.rcParams['font.sans-serif'] = ['KaiTi'] # 'SimHei'也可以 22 plt.rcParams['axes.unicode_minus'] = False 23 24 # 繪製箱線圖 25 sns.boxplot(x='來源', y='銷量(千克)', data=combined_data) 26 plt.xlabel('') 27 plt.ylabel('銷量(千克)') 28 plt.title('小白菜和雲南生菜2020年7月至2023年2月月銷量箱線圖') 29 plt.show() 30 31 # 提取小白菜的銷量列 32 sales_data = df1['銷量(千克)'] 33 34 # 計算累積分佈函數 35 sorted_data = np.sort(sales_data) 36 cumulative_prob = np.arange(1, len(sorted_data) + 1) / len(sorted_data) 37 38 # 繪製累積分佈函數圖 39 plt.plot(sorted_data, cumulative_prob, marker='o', linestyle='-', color='b') 40 plt.xlabel('銷量(千克)') 41 plt.ylabel('累積概率') 42 plt.title('小白菜銷量累計分佈函數圖') 43 plt.grid(True) 44 plt.show() 45 46 47 # 提取雲南生菜的銷量列 48 sales_data = df2['銷量(千克)'] 49 50 # 計算累積分佈函數 51 sorted_data = np.sort(sales_data) 52 cumulative_prob = np.arange(1, len(sorted_data) + 1) / len(sorted_data) 53 54 # 繪製累積分佈函數圖 55 plt.plot(sorted_data, cumulative_prob, marker='o', linestyle='-', color='b') 56 plt.xlabel('銷量(千克)') 57 plt.ylabel('累積概率') 58 plt.title('雲南生菜銷量累計分佈函數圖') 59 plt.grid(True) 60 plt.show()
4.附錄:資料
單日銷售情況.xlsx
某件商品資訊.xlsx 小白菜每月銷售資訊
某件商品資訊.xlsx 雲南生菜每月銷售資訊