【scipy 基礎】--最佳化
SciPy庫的optimize模組主要用於執行各種優化任務。
優化是尋找特定函數的最小值或最大值的過程,通常用於機器學習、資料分析、工程和其他領域。
scipy.optimize提供了多種優化演演算法,包括梯度下降法、牛頓法、最小二乘法等,可以解決各種複雜的優化問題。
該模組還包含一些特定的函數,用於解決某些特定型別的優化問題,如多維非線性優化、約束優化、最小二乘問題等。
此外,scipy.optimize還提供了一些工具,如多執行緒支援、邊界條件處理、數值穩定性措施等,以提高優化的效率和準確性。
1. 主要功能
最佳化是數學學科中的一個重要研究領域,optimize模組包含的各類函數能夠幫助我們節省大量的計算時間和精力。
| 類別 | 說明 |
|---|---|
| 優化 | 包含標量函數優化,區域性優化,全域性優化等各類方法 |
| 最小二乘法和曲線擬合 | 包含求解最小二乘法問題,各種擬合曲線的方法 |
| 求根 | 包含多種求根的方法,比如布倫特方法,牛頓-拉夫森方法等10來種求根方法 |
| 線性規劃 | 內建多種線性規劃演演算法以及混合整數線性規劃計算等 |
| 分配問題 | 解決線性和分配問題,包括二次分配和圖匹配問題的近似解等 |
| 工具函數 | 包含一些通用的計算方法,比如有限差分近似,海森近似,線搜尋等計算函數 |
| 遺留函數 | 即將被淘汰的一些函數,不建議再繼續使用 |
下面通過曲線擬合和非線性方程組求解兩個範例演示optimize模組的使用。
2. 曲線擬合範例
所謂曲線擬合,其實就是找到一個函數,能夠儘可能的經過或接近一系列離散的點。
然後就可以用這個函數來預測離散點的變化趨勢。
2.1. 最小二乘法
optimize模組的最小二乘法擬合曲線需要定義一個目標函數和一個殘差函數。
最小二乘法通過迭代尋找目標函數中引數的最優值,
而殘差函數是用來計算目標函數的返回值和實際值之間的誤差的。
首先,載入需要擬合的離散資料。
import pandas as pd
data = pd.read_csv("d:/share/data/A0A01.csv")
data = data[data["zb"] == "A0A0101"]
data = data.sort_values("sj")
data.head()
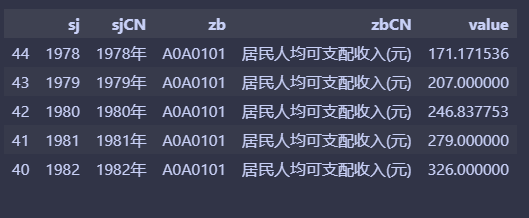
資料來源:https://databook.top/nation/A0A (其中的A0A01.csv)
然後,依據其中1978年~2022年的居民人均可支配收入繪製散點圖。
from matplotlib.ticker import MultipleLocator
import matplotlib.pyplot as plt
ax = plt.subplot()
ax.scatter(data["sjCN"], data["value"], marker='*', color='r')
ax.xaxis.set_major_locator(MultipleLocator(4))
ax.set_title("居民人均可支配收入(元)")
plt.xticks(rotation=45)
plt.show()
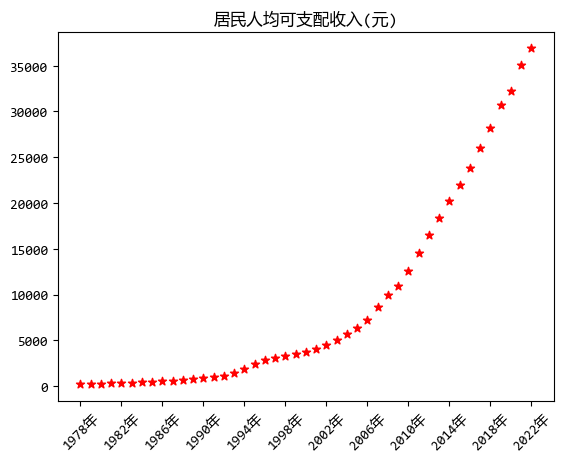
最後,用optimize模組提供的最小二乘法擬合居民人均可支配收入的變化曲線。
from scipy.optimize import least_squares
# 目標函數
def target_func(p, x):
return p[0]*np.exp(p[1]*x) + p[2]
# 殘差函數
def residual(p, x, dy):
return target_func(p, x) - dy
p0 = [1, 1, 0]
x = range(len(data))
y = data["value"]
# 最小二乘法迭代目標函數的引數
result = least_squares(residual, p0, args=(x, y))
ax = plt.subplot()
ax.xaxis.set_major_locator(MultipleLocator(4))
ax.set_title("居民人均可支配收入(元)")
ax.scatter(data["sjCN"], data["value"], marker='*', color='r')
# 這裡的result.x就是迭代後的最優引數
ax.plot(x, target_func(result.x, x), color='g')
plt.xticks(rotation=45)
plt.show()
圖中綠色的曲線就是擬合的曲線,根據擬合出的曲線和目標函數,
就可以預測以後的居民人均可支配收入的變化情況。
2.2. curve_fit方法
最小二乘法需要定義目標函數和殘差函數,使用起來有些繁瑣,optimize模組中還提供了一個curve_fit函數。
可以簡化曲線擬合的過程。
from scipy.optimize import curve_fit
# 目標函數
def curve_fit_func(x, p0, p1, p2):
return p0*np.exp(p1*x) + p2
# fitp 就是計算出的目標函數的最優引數
fitp, _ = curve_fit(curve_fit_func, x, y, [1, 1, 0])
ax = plt.subplot()
ax.xaxis.set_major_locator(MultipleLocator(4))
ax.set_title("居民人均可支配收入(元)")
ax.scatter(data["sjCN"], data["value"], marker='*', color='r')
ax.plot(x, curve_fit_func(x, *fitp), color='b')
plt.xticks(rotation=45)
plt.show()
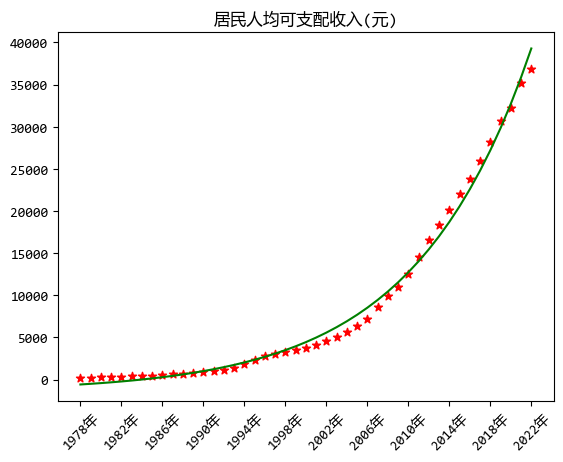
藍色的線就是擬合曲線,擬合結果和使用最小二乘法擬合出的是一樣的,只是程式碼可以簡化一些。
3. 非線性方程組求解範例
眾所周知,手工求解非線性方程是非常困難的,如果經常遇到求解非線性方程的情況,optimize模組絕對能成為你的一個稱手工具。
3.1. 非線性方程
使用optimize模組求解非線性方程非常簡單。
比如方程:\(2^x+sin(x)-x^3=0\)
from scipy.optimize import root
f = lambda x: 2**x + np.sin(x) - x**3
result = root(f, [1, 1], method='hybr')
# result.x 是方程的解
result.x
# 執行結果:
array([1.58829918, 1.58829918])
實際使用時,將變數f對應的方程換成你的方程即可。
注意,求解方程的 root 方法的引數method,這個引數支援多種求解方程的方法,可以根據方程的特點選擇不同的method。
支援的method列表可參考官方檔案:https://docs.scipy.org/doc/scipy/reference/optimize.html
3.2. 非線性方程組
對於方程組,求解的方法如下:
比如方程組:\(\begin{cases}
\begin{align*}
x^2 +y-3 & =0 \\
(x-2)^2+y-1 & =0
\end{align*}
\end{cases}\)
fs = lambda x: np.array(
[
x[0] ** 2 + x[1] - 3,
(x[0] - 2) ** 2 + x[1] - 1,
]
)
result = root(fs, [1, 1], method="hybr")
result.x
# 執行結果:
array([1.5 , 0.75])
方程組中方程個數多的話,直接新增到變數fs的陣列中即可。
4. 總結
總的來說,scipy.optimize是一個強大且易用的優化工具箱,用於解決各種複雜的優化問題。
它對於需要優化演演算法的許多科學和工程領域都具有重要價值。
通過使用這個模組,使用者可以節省大量時間和精力,同時還能保證優化的質量和準確性。