樸素貝葉斯深度解碼:從原理到深度學習應用
本文深入探討了樸素貝葉斯演演算法,從基礎的貝葉斯定理到演演算法的各種變體,以及在深度學習和文字分類中的應用。通過實戰演示和詳細的程式碼範例,展示了樸素貝葉斯在自然語言處理等任務中的實用性和高效性。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。

一、簡介
樸素貝葉斯(Naive Bayes)是一種基於貝葉斯定理的分類技術,具有實現簡單、易於理解、且在多種應用場景中表現優秀的特點。本節旨在介紹貝葉斯定理的基本歷史和重要性,以及樸素貝葉斯分類器的應用場景。
貝葉斯定理的歷史和重要性
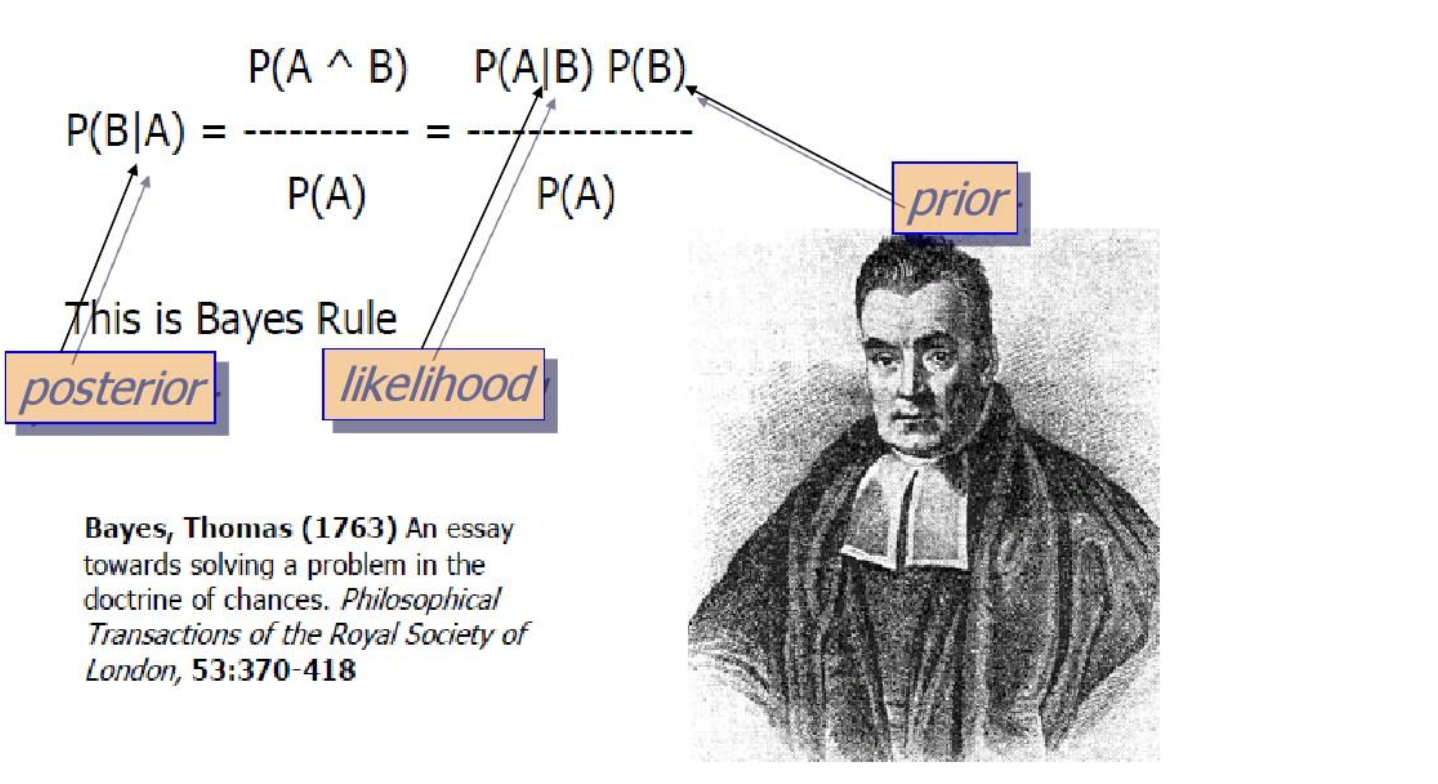
定義
貝葉斯定理(Bayes' Theorem)是一種在已知某個條件下,預測另一個條件概率的方法。數學表示式為:
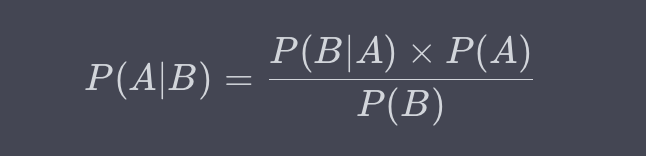
例子
比如,在醫學檢測中,已知某種疾病在總體中的發病率P(A),以及某項檢測的準確率P(B|A),貝葉斯定理就能用於預測某個檢測結果陽性的人實際患病的概率P(A|B)。
樸素貝葉斯分類器的應用場景
定義
樸素貝葉斯分類器(Naive Bayes Classifier)是一種應用貝葉斯定理,以及一個「樸素」的假設,即特徵間相互獨立,來進行分類的演演算法。
例子
垃圾郵件過濾就是樸素貝葉斯分類器的一個經典應用。通過學習垃圾郵件和非垃圾郵件中詞彙的出現頻率,樸素貝葉斯分類器能夠預測一個新郵件是否為垃圾郵件。
常見應用場景
- 文字分類:除了垃圾郵件過濾,還廣泛應用於新聞分類、情感分析等。
- 推薦系統:例如,根據使用者以往的購買歷史和瀏覽記錄,預測使用者可能感興趣的其他產品。
- 醫學診斷:如基於病人的一系列檢測結果,預測病人是否患有某種疾病。
二、貝葉斯定理基礎
貝葉斯定理是一種數學工具,用於在給定某些觀察或資料的情況下,計算不同事件的條件概率。本節將詳細介紹與貝葉斯定理相關的幾個基本概念:條件概率、貝葉斯公式,以及它們在現實世界中的應用範例。
條件概率
定義
條件概率(Conditional Probability)是在給定某一事件B發生的條件下,另一事件A發生的概率。數學上,條件概率用P(A|B)表示,計算公式為:

例子
假設一個課堂裡有60%的男生和40%的女生。其中,50%的男生和20%的女生喜歡數學。現在,如果隨機選一個喜歡數學的學生,那麼這個學生是男生的條件概率是多少?
解:這裡,A是學生是男生,B是學生喜歡數學。需要找的是P(A|B),即給定一個學生喜歡數學,在這個條件下,這個學生是男生的概率。
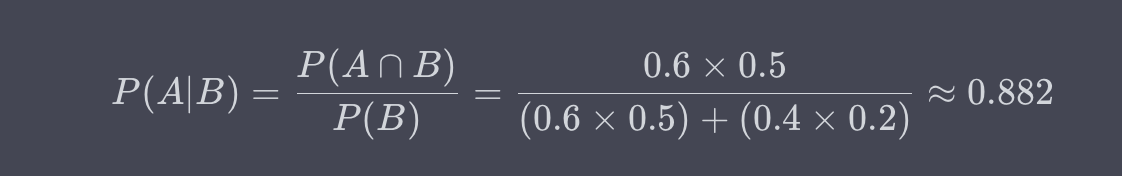
因此,給定一個喜歡數學的學生,這個學生是男生的條件概率約為0.882或88.2%。
貝葉斯公式
定義
貝葉斯公式(Bayes' Formula)是一個用於更新隨機事件概率估計的公式。基礎形式為:

例子
在醫學檢測中,假設某疾病在總人口中的患病率P(A) 為1%。某項檢測對這種疾病的診斷準確率P(B|A) 為99%。現在,這項檢測的結果對一個人是陽性,求這個人實際上患有這種疾病的概率P(A|B) 。

三、樸素貝葉斯演演算法原理
樸素貝葉斯(Naive Bayes)演演算法是一種基於貝葉斯定理的分類演演算法,其「樸素」之處在於假設所有特徵都是互相獨立的。本節將深入探討該演演算法的基本構成、分類過程、以及不同變體。
基本構成
定義
樸素貝葉斯分類器用以下公式描述分類過程:

例子
假設我們有一個天氣預測模型,用於預測明天是晴天(Sunny)還是多雲(Cloudy)。我們的特徵有兩個:溫度(高、低)和溼度(高、低)。假設先驗概率P(Sunny)=0.6,P(Cloudy)=0.4,以及一些已知的條件概率(例如,P(高溫 | Sunny) = 0.7等)。
現在,給定一個具有「高溫」和「低溼度」的天氣情況,我們可以使用樸素貝葉斯公式來計算明天是晴天還是多雲的概率。
分類過程
定義
樸素貝葉斯演演算法通常包含以下步驟:
- 計算先驗概率:基於訓練資料集,計算每個類別Ck的先驗概率P(Ck)。
- 計算條件概率:對於每個特徵xi和每個類別Ck,計算P(xi | Ck)。
- 應用貝葉斯公式:對於一個新的樣本,應用貝葉斯公式來計算所有可能類別的後驗概率。
- 分類決策:選擇具有最高後驗概率的類別作為樣本的預測分類。
例子
繼續上面的天氣預測模型,假設我們已經從歷史資料中計算出了各種先驗概率和條件概率。現在,對於一個具有「高溫」和「低溼度」的新樣本,我們將:
- 計算該樣本屬於「晴天」和「多雲」的後驗概率。
- 比較兩個後驗概率,並選擇概率更高的類別作為預測結果。
不同變體
定義
根據特徵的不同型別(連續或離散)和分佈(高斯、多項式等),樸素貝葉斯演演算法有幾個不同的變體:
- 高斯樸素貝葉斯(Gaussian Naive Bayes):用於連續特徵,假設特徵服從高斯分佈。
- 多項式樸素貝葉斯(Multinomial Naive Bayes):常用於文字分類,特徵表示詞頻。
- 伯努利樸素貝葉斯(Bernoulli Naive Bayes):用於二值特徵。
例子
- 高斯樸素貝葉斯:在垃圾郵件分類中,如果特徵是每封郵件的長度和使用某些關鍵詞的頻率,我們可能會使用高斯樸素貝葉斯。
- 多項式樸素貝葉斯:在文字分類中,比如新聞文章分為政治、體育、娛樂等,通常使用多項式樸素貝葉斯。
- 伯努利樸素貝葉斯:在情感分析中,如果我們只關心某個詞是否出現(而不是出現的次數),則可能會使用伯努利樸素貝葉斯。
四、樸素貝葉斯的種類
樸素貝葉斯演演算法有多種變體,每種都有其特定的應用場景和假設。本節將詳細探討這些不同型別的樸素貝葉斯分類器。
高斯樸素貝葉斯(Gaussian Naive Bayes)
定義
高斯樸素貝葉斯是最常用於連續特徵的樸素貝葉斯分類器。該模型假設每個類別中每個特徵的值都服從高斯(正態)分佈。

例子
考慮一個簡單的腫瘤分類問題,特徵是腫瘤的大小和年齡。我們可以通過高斯樸素貝葉斯模型來預測一個新樣本(例如,大小為2.5cm、年齡45歲)是良性或惡性的。
多項式樸素貝葉斯(Multinomial Naive Bayes)
定義
多項式樸素貝葉斯通常用於離散特徵,特別是在文字分類問題中。該模型假設特徵是由一個簡單多項式分佈生成的。

例子
在新聞分類中,假設我們有三個類別:政治、科技和娛樂。特徵則是每篇文章中單詞的頻數。多項式樸素貝葉斯可以有效地預測一個新文章的類別。
伯努利樸素貝葉斯(Bernoulli Naive Bayes)
定義
伯努利樸素貝葉斯適用於二值特徵模型。與多項式樸素貝葉斯不同,這種模型只考慮特徵是否出現。

例子
在情感分析中,特徵可能是某些情感詞(如「好」或「壞」)是否出現在文字中。伯努利樸素貝葉斯可以用於預測文字(例如,產品評論)是正面還是負面。
五、樸素貝葉斯在深度學習中的應用
樸素貝葉斯(Naive Bayes)和深度學習都是機器學習的重要分支,但它們在許多方面都有根本的不同。然而,這並不意味著兩者不能結合使用。本節將探討樸素貝葉斯在深度學習領域中的具體應用。
資料預處理和特徵選擇
定義
在深度學習模型訓練之前,樸素貝葉斯演演算法可以用於資料預處理和特徵選擇。它能快速地評估特徵與標籤之間的相關性,為複雜的深度學習模型提供有用的資訊。
例子
例如,在影象分類任務中,我們可以先用樸素貝葉斯對畫素級特徵進行預篩選,識別哪些特徵與目標類別最相關,然後只用這些特徵去訓練折積神經網路(CNN)模型。
生成對抗網路(GANs)中的生成模型
定義
在生成對抗網路(GANs)中,樸素貝葉斯可以作為一個簡單的生成模型與判別模型配合使用。儘管它沒有深度生成模型那麼強大,但在一些場景下,它足夠生成合理的資料分佈。
例子
假設我們正在嘗試生成文字資料。一般來說,LSTM或Transformer更常用於這類問題,但在某些特定應用中,樸素貝葉斯足夠生成簡單的文字資料,例如垃圾郵件生成等。
作為基線模型
定義
樸素貝葉斯由於其簡單和計算高效的特點,經常被用作深度學習任務的基線模型。這能提供一個基準,讓研究人員更容易評估深度學習模型的效能是否有顯著提升。
例子
在自然語言處理(NLP)任務,比如情感分類上,樸素貝葉斯往往是一個很好的起點。如果一個複雜的深度學習模型(如BERT)與樸素貝葉斯有相似的效能,這通常意味著深度學習模型需要進一步優化。
異常檢測與解釋性
定義
深度學習模型通常作為黑箱操作,而樸素貝葉斯由於其概率基礎,可以用於解釋深度學習模型的決策過程,特別是在異常檢測場景下。
例子
在信用卡欺詐檢測系統中,一個深度學習模型可能很好地識別出異常行為,但樸素貝葉斯可以進一步提供哪些特徵最可能導致該行為被標記為異常,從而提供更多的解釋性。
六、實戰:文字分類
在這一節中,我們將通過一個具體的例子來實戰演示如何使用樸素貝葉斯進行文字分類。文字分類是NLP(自然語言處理)中一個非常基礎和廣泛應用的任務,通常用於垃圾郵件檢測、情感分析、主題分類等。
任務定義
定義
文字分類的目標是自動將文字內容分到預定義的類別。例如,在情感分析中,預定義的類別可能是積極、消極和中性。
例子
一個典型的應用場景是電影評論的情感分析。給定一段電影評論文字,目標是判斷這段評論是正面的、負面的,還是中性的。
資料預處理
定義
資料預處理通常包括去除停用詞、詞幹提取、分詞等。
例子
例如,句子 "This movie is not good" 經過預處理後可能變為 ['movie', 'not', 'good']。
樸素貝葉斯分類器訓練
下面的程式碼段是用Python和scikit-learn庫進行樸素貝葉斯分類器訓練的完整範例。
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 範例資料集
X = ["I love this movie", "I hate this movie", "Not bad", "Not good"]
y = ["Positive", "Negative", "Neutral", "Neutral"]
# 資料預處理(向量化)
vectorizer = CountVectorizer()
X_vec = vectorizer.fit_transform(X)
# 劃分資料集
X_train, X_test, y_train, y_test = train_test_split(X_vec, y, test_size=0.25, random_state=42)
# 訓練樸素貝葉斯分類器
clf = MultinomialNB()
clf.fit(X_train, y_train)
# 測試模型
y_pred = clf.predict(X_test)
# 輸出準確度
print("Accuracy:", accuracy_score(y_test, y_pred))
輸入和輸出
- 輸入:一組標記(Positive, Negative, Neutral)的文字資料。
- 輸出:模型對測試集的分類準確度。
處理過程
- 使用
CountVectorizer將文字資料轉換為向量。 - 使用
train_test_split將資料集劃分為訓練集和測試集。 - 使用
MultinomialNB(多項式樸素貝葉斯)進行模型訓練。 - 使用訓練好的模型對測試集進行預測。
- 使用
accuracy_score計算模型準確度。
七、總結
樸素貝葉斯演演算法是一個簡單但強大的工具,不僅在傳統機器學習領域有廣泛應用,還能與深度學習演演算法相輔相成。從基礎的貝葉斯定理到演演算法的多種變體,再到深度學習中的具體應用場景,樸素貝葉斯展示了其獨特的優點和潛力。
獨特洞見
-
互補性與簡單性:樸素貝葉斯和深度學習在許多方面都是互補的。當深度學習模型因其複雜性而難以解釋時,樸素貝葉斯能夠提供更多的可解釋性。
-
速度與效率:樸素貝葉斯因其演演算法簡單和計算高效,非常適用於資料預處理和特徵選擇,這在深度學習任務中尤為重要。
-
自然語言處理中的廣泛應用:通過實戰演示,我們瞭解到樸素貝葉斯在文字分類方面具有不小的潛力,尤其是當資料稀疏或標籤非常不平衡時。
-
模型解釋與信任度:在現實世界的應用場景,比如醫療診斷或金融風險評估中,模型的解釋性往往與準確性同等重要。樸素貝葉斯能夠提供這一點,而深度學習則往往缺乏這方面的能力。
-
模型融合與整合學習:樸素貝葉斯由於其計算簡單和預測速度快,常常作為整合學習方法中的一部分,與其他更復雜的模型組合,以達到更高的準確度。
綜上所述,樸素貝葉斯是一個不容忽視的演演算法。在當前由深度學習主導的人工智慧領域裡,樸素貝葉斯仍然佔有一席之地。正因為其簡單、高效和易於解釋,這使得它成為了各種機器學習任務,尤其是自然語言處理和資料預處理中的重要工具。通過深入地掌握和理解這一演演算法,我們可以更全面地認識到機器學習的多樣性和靈活性,這對於任何希望深入瞭解這一領域的人來說,都是極其寶貴的。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。