TiDB binlog故障處理之drainer週期性罷工
背景
前段時間使用者反饋某生產環境 TiDB 叢集 drainer 頻繁發生故障,要麼服務崩潰無法啟動,要麼資料跑著跑著就丟失了,很是折磨人。該叢集跑的是離線分析業務,資料量20T ,v4版本,有多個 drainer 往下游同步資料,目標端包括kafka、file、tidb多種形態。
兩天前剛恢復過一次,這會又故障重現,不得不來一次根因排查。
故障現象
接業務端反饋,某下游kafka幾個小時沒收到 TiDB 資料了,但是 pump 和 drainer 節點狀態都顯示正常,同樣在幾天前也收到類似的反饋,當時是因為 binlog 發生未知異常導致 TiDB server 停止寫入,需要通過以下 API 驗證 binlog 狀態:
curl http://{tidb-server ip}:{status_port}/info/all
該 API 會返回所有 TiDB server 的元資訊,其中就包括每個範例 binlog 的寫入狀態(binlog_status欄位),如果 TiDB server設定了ignore-error,那麼在 binlog 故障時通常是 skipping,正常情況下是 on。
經確認7個 TiDB server 的 binlog_status 均為 skipping狀態,和此前是一樣的問題。
處理方法比較簡單,重啟 TiDB server 即可,但是避免後續重複出現需要搞清楚原因後再重啟。
分析過程
資料不同步了相信大家都會第一時間懷疑是 drainer 的問題, 最常見的原因就是大事務導致 drainer 崩潰panic,但是登入到 drainer 所在的機器上分析紀錄檔,並沒有發現異常現象,紀錄檔顯示 savepoint 正常寫入,checkpoint 正常推進,範例狀態up,說明並不是 drainer的問題。
根據 binlog skip 狀態,轉頭去分析 TiDB server監控,在 TiDB->Server->Skip Binlog Count面板可以看到被跳過的 binlog 數量:
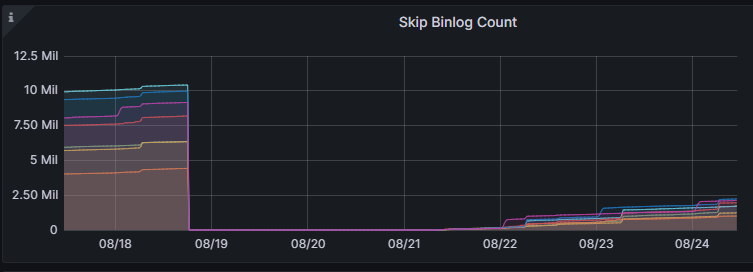
從監控看到,在8月18號下午6點左右 Skip Count 突然從高位掉到0,正是因為上一次重啟 TiDB server 修復了故障。往後到21號早上左右,Skip Count 又開始出現,那麼就要重點分析這個時間點的紀錄檔。
進一步分析監控,發現 Skip Count 上升趨勢和 Critical Error 相吻合,說明在21號早上07:06左右開始出現大量的 binlog 寫入異常,接下來根據這個時間點去排查 pump 的紀錄檔。
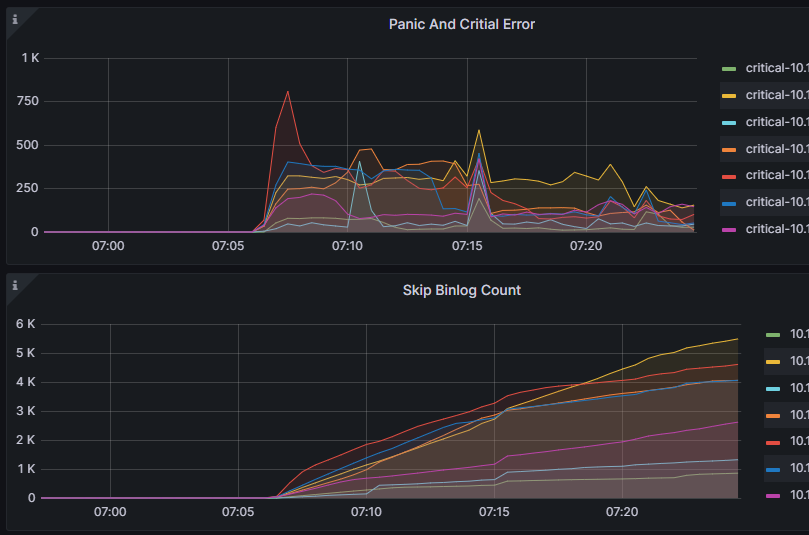
根據精確的時間點,很快就在 pump 紀錄檔中定位到了panic的位置,在panic之後紀錄檔發現了一個非常有用的資訊:

紀錄檔顯示,binlog 確實停止寫入了,同時指出停止寫入的原因是磁碟空間不夠,這裡有個關鍵資訊StopWriteAtAvailableSpace,也就是說 pump 所在的磁碟可用空間小於這個引數時就會停止寫入。我們用edit-config看一下 pump 的設定引數:
pump:
gc: 2
heartbeat-interval: 2
security:
ssl-ca: ""
ssl-cert: ""
ssl-key: ""
storage:
stop-write-at-available-space: 1 gib
發現紀錄檔和設定引數可以對應上,確實是磁碟不夠了。反手就是一個df -h看看什麼情況:
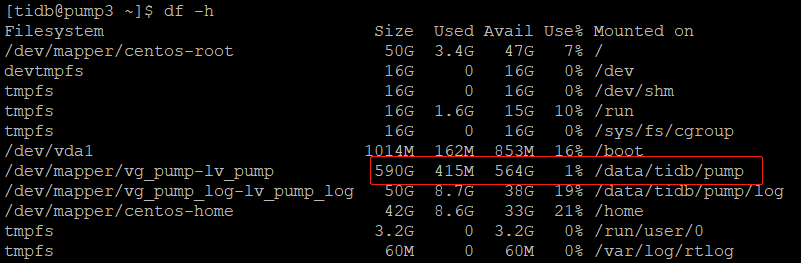
意外的是,上圖顯示 pump 的資料盤只用了1%,還有大把的空間沒被使用,貌似和紀錄檔報錯原因不符。
到這裡我忽略了一個重要的時間因素,就是介入排查的時候離 pump 故障已經過去了3天(從前面第一章監控圖可以看到),而 pump gc時間設定的是2天,那麼意味著在排查的時候 pump 之前記錄的binlog 已經被 gc 掉了,至於這些 binlog 有沒有被 drainer正常消費還不得而知。好在 Grafana 監控裡面有一個面板記錄了 pump storage 的變化情況,路徑是:Binlog->pump->Storage Size。
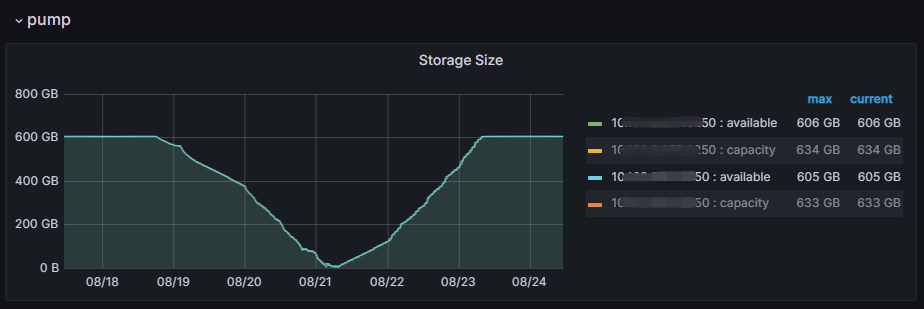
從上面這個曲線聯想最近兩次的故障,貌似問題一下子清楚了:18號下午6點左右重啟 TiDB Server 恢復 binlog 寫入,pump 可用空間開始變少,到21號早上7點左右幾乎被使用完畢,觸發StopWriteAtAvailableSpace異常,binlog 停止寫入變成 skipping狀態,但與此同時 pump gc 還在工作,且沒有新的 binlog 進來,兩天後存量資料被 gc 完畢在23號早上7點左右恢復到空盤水平,持續到現在。
半途接手的叢集,各種背景資訊也不是很瞭解,經常奇奇怪怪問題一查就是查半天,這就是oncall人的日常。。