ChatGLM3-6B:新一代開源雙語對話語言模型,流暢對話與低部署門檻再升級
ChatGLM3-6B:新一代開源雙語對話語言模型,流暢對話與低部署門檻再升級
1.ChatGLM3簡介
ChatGLM3 是智譜AI和清華大學 KEG 實驗室聯合釋出的新一代對話預訓練模型。ChatGLM3-6B 是 ChatGLM3 系列中的開源模型,在保留了前兩代模型對話流暢、部署門檻低等眾多優秀特性的基礎上,ChatGLM3-6B 引入瞭如下特性:
- 更強大的基礎模型: ChatGLM3-6B 的基礎模型 ChatGLM3-6B-Base 採用了更多樣的訓練資料、更充分的訓練步數和更合理的訓練策略。在語意、數學、推理、程式碼、知識等不同角度的資料集上測評顯示,ChatGLM3-6B-Base 具有在 10B 以下的基礎模型中最強的效能。
- 更完整的功能支援: ChatGLM3-6B 採用了全新設計的 Prompt 格式,除正常的多輪對話外。同時原生支援工具呼叫(Function Call)、程式碼執行(Code Interpreter)和 Agent 任務等複雜場景。
- 更全面的開源序列: 除了對話模型 ChatGLM3-6B 外,還開源了基礎模型 ChatGLM3-6B-Base、長文字對話模型 ChatGLM3-6B-32K。以上所有權重對學術研究完全開放,在填寫問卷進行登記後亦允許免費商業使用。
ChatGLM3 開源模型旨在與開源社群一起推動大模型技術發展,懇請開發者和大家遵守開源協定,勿將開源模型和程式碼及基於開源專案產生的衍生物用於任何可能給國家和社會帶來危害的用途以及用於任何未經過安全評估和備案的服務。目前,本專案團隊未基於 ChatGLM3 開源模型開發任何應用,包括網頁端、安卓、蘋果 iOS 及 Windows App 等應用。
儘管模型在訓練的各個階段都盡力確保資料的合規性和準確性,但由於 ChatGLM3-6B 模型規模較小,且模型受概率隨機性因素影響,無法保證輸出內容的準確。同時模型的輸出容易被使用者的輸入誤導。本專案不承擔開源模型和程式碼導致的資料安全、輿情風險或發生任何模型被誤導、濫用、傳播、不當利用而產生的風險和責任。
1.1 模型列表
| Model | Seq Length | Download |
|---|---|---|
| ChatGLM3-6B | 8k | HuggingFace | ModelScope |
| ChatGLM3-6B-Base | 8k | HuggingFace | ModelScope |
| ChatGLM3-6B-32K | 32k | HuggingFace | ModelScope |
對 ChatGLM3 進行加速的開源專案:
- chatglm.cpp: 類似 llama.cpp 的量化加速推理方案,實現筆電上實時對話
- ChatGLM3-TPU: 採用TPU加速推理方案,在算能端側晶片BM1684X(16T@FP16,記憶體16G)上實時執行約7.5 token/s
1.2評測結果
1.2.1 典型任務
我們選取了 8 箇中英文典型資料集,在 ChatGLM3-6B (base) 版本上進行了效能測試。
| Model | GSM8K | MATH | BBH | MMLU | C-Eval | CMMLU | MBPP | AGIEval |
|---|---|---|---|---|---|---|---|---|
| ChatGLM2-6B-Base | 32.4 | 6.5 | 33.7 | 47.9 | 51.7 | 50.0 | - | - |
| Best Baseline | 52.1 | 13.1 | 45.0 | 60.1 | 63.5 | 62.2 | 47.5 | 45.8 |
| ChatGLM3-6B-Base | 72.3 | 25.7 | 66.1 | 61.4 | 69.0 | 67.5 | 52.4 | 53.7 |
Best Baseline 指的是截止 2023年10月27日、模型引數在 10B 以下、在對應資料集上表現最好的預訓練模型,不包括只針對某一項任務訓練而未保持通用能力的模型。
對 ChatGLM3-6B-Base 的測試中,BBH 採用 3-shot 測試,需要推理的 GSM8K、MATH 採用 0-shot CoT 測試,MBPP 採用 0-shot 生成後執行測例計算 Pass@1 ,其他選擇題型別資料集均採用 0-shot 測試。
我們在多個長文字應用場景下對 ChatGLM3-6B-32K 進行了人工評估測試。與二代模型相比,其效果平均提升了超過 50%。在論文閱讀、檔案摘要和財報分析等應用中,這種提升尤為顯著。此外,我們還在 LongBench 評測集上對模型進行了測試,具體結果如下表所示
| Model | 平均 | Summary | Single-Doc QA | Multi-Doc QA | Code | Few-shot | Synthetic |
|---|---|---|---|---|---|---|---|
| ChatGLM2-6B-32K | 41.5 | 24.8 | 37.6 | 34.7 | 52.8 | 51.3 | 47.7 |
| ChatGLM3-6B-32K | 50.2 | 26.6 | 45.8 | 46.1 | 56.2 | 61.2 | 65 |
2.快速使用
2.1 環境安裝
首先需要下載本倉庫:
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
然後使用 pip 安裝依賴:
pip install -r requirements.txt
其中 transformers 庫版本推薦為 4.30.2,torch 推薦使用 2.0 及以上的版本,以獲得最佳的推理效能。
2.2 ChatGLM3 Web Demo
- 安裝
我們建議通過 Conda 進行環境管理。
執行以下命令新建一個 conda 環境並安裝所需依賴:
conda create -n chatglm3-demo python=3.10
conda activate chatglm3-demo
pip install -r requirements.txt
請注意,本專案需要 Python 3.10 或更高版本。
此外,使用 Code Interpreter 還需要安裝 Jupyter 核心:
ipython kernel install --name chatglm3-demo --user
- 執行
執行以下命令在本地載入模型並啟動 demo:
streamlit run main.py
之後即可從命令列中看到 demo 的地址,點選即可存取。初次存取需要下載並載入模型,可能需要花費一定時間。
如果已經在本地下載了模型,可以通過 export MODEL_PATH=/path/to/model 來指定從本地載入模型。如果需要自定義 Jupyter 核心,可以通過 export IPYKERNEL=<kernel_name> 來指定。
- 使用
ChatGLM3 Demo 擁有三種模式:
- Chat: 對話模式,在此模式下可以與模型進行對話。
- Tool: 工具模式,模型除了對話外,還可以通過工具進行其他操作。
- Code Interpreter: 程式碼直譯器模式,模型可以在一個 Jupyter 環境中執行程式碼並獲取結果,以完成複雜任務。
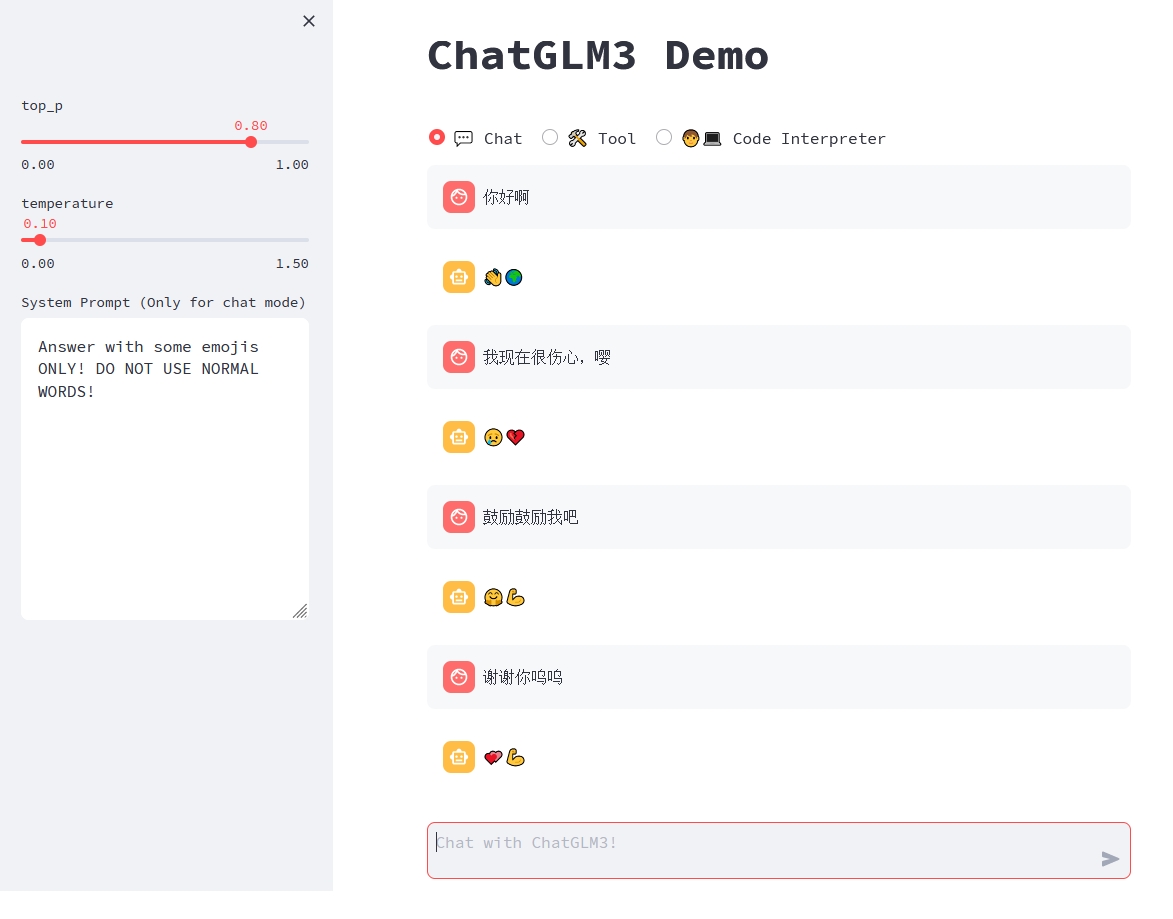
- 對話模式
對話模式下,使用者可以直接在側邊欄修改 top_p, temperature, System Prompt 等引數來調整模型的行為。例如
- 工具模式
可以通過在 tool_registry.py 中註冊新的工具來增強模型的能力。只需要使用 @register_tool 裝飾函數即可完成註冊。對於工具宣告,函數名稱即為工具的名稱,函數 docstring 即為工具的說明;對於工具的引數,使用 Annotated[typ: type, description: str, required: bool] 標註引數的型別、描述和是否必須。
例如,get_weather 工具的註冊如下:
@register_tool
def get_weather(
city_name: Annotated[str, 'The name of the city to be queried', True],
) -> str:
"""
Get the weather for `city_name` in the following week
"""
...
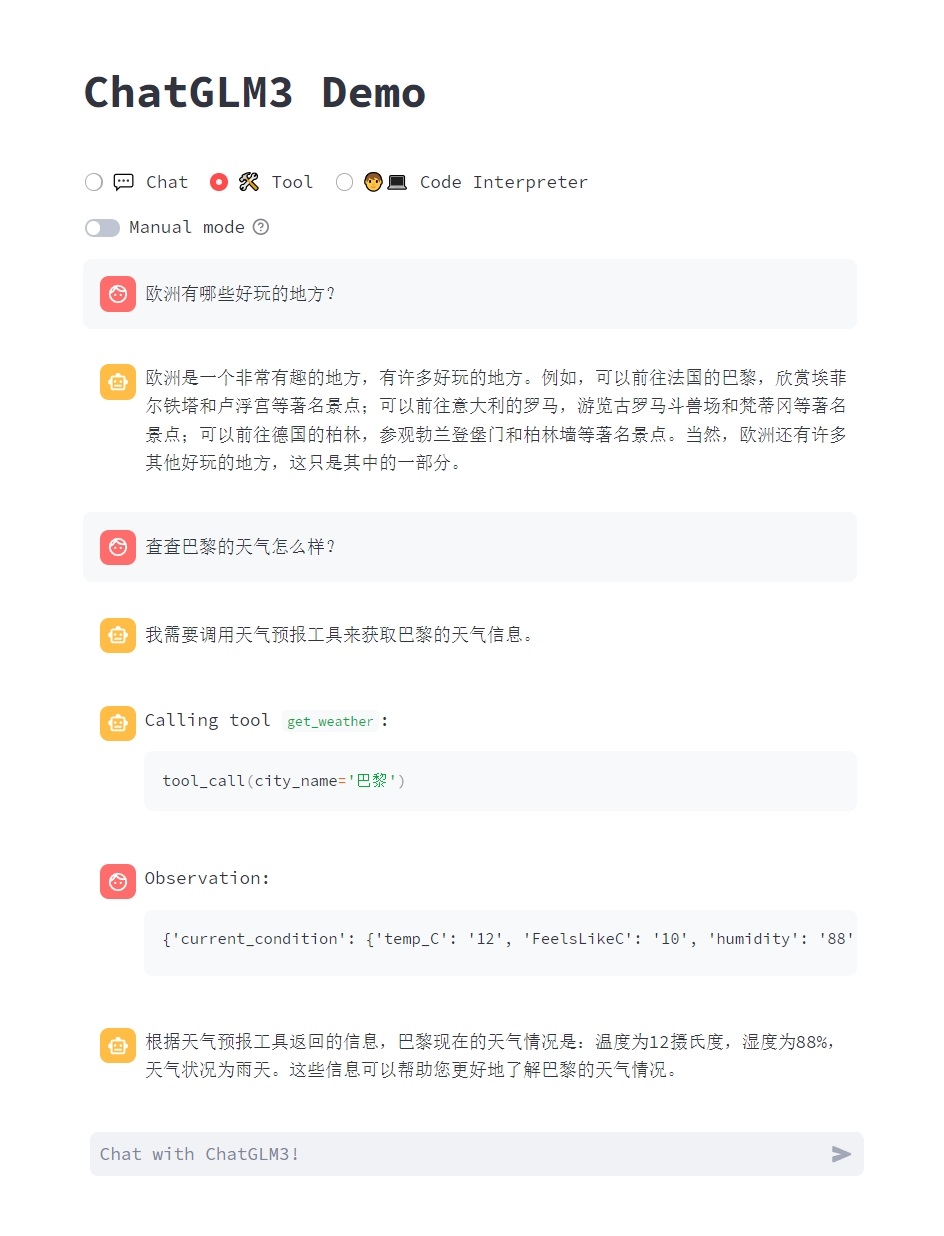
此外,你也可以在頁面中通過 Manual mode 進入手動模式,在這一模式下你可以通過 YAML 來直接指定工具列表,但你需要手動將工具的輸出反饋給模型。
- 程式碼直譯器模式
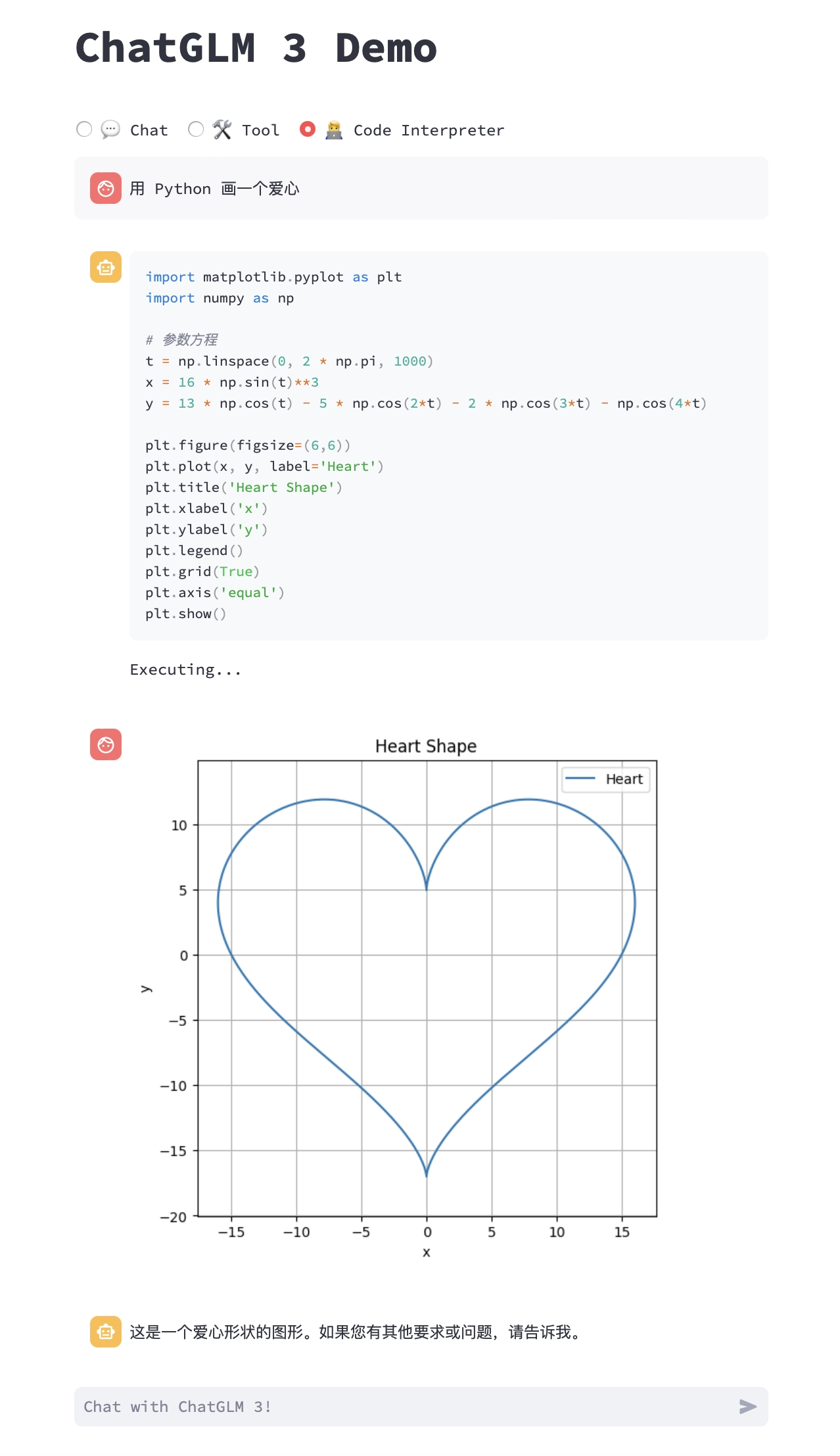
由於擁有程式碼執行環境,此模式下的模型能夠執行更為複雜的任務,例如繪製圖表、執行符號運算等等。模型會根據對任務完成情況的理解自動地連續執行多個程式碼塊,直到任務完成。因此,在這一模式下,你只需要指明希望模型執行的任務即可。
例如,我們可以讓 ChatGLM3 畫一個愛心:
- 額外技巧
- 在模型生成文字時,可以通過頁面右上角的
Stop按鈕進行打斷。 - 重新整理頁面即可清空對話記錄。
2.3 程式碼呼叫
可以通過如下程式碼呼叫 ChatGLM 模型來生成對話:
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True, device='cuda')
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好