將強化學習引入NLP:原理、技術和程式碼實現
本文深入探討了強化學習在自然語言處理(NLP)中的應用,涵蓋了強化學習的基礎概念、與NLP的結合方式、技術細節以及實際的應用案例。通過詳細的解釋和Python、PyTorch的實現程式碼,讀者將瞭解如何利用強化學習優化NLP任務,如對話系統和機器翻譯。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。

1. 強化學習簡介
強化學習是機器學習的一個分支,涉及智慧體(agent)如何在一個環境中採取行動,從而最大化某種長期的累積獎勵。
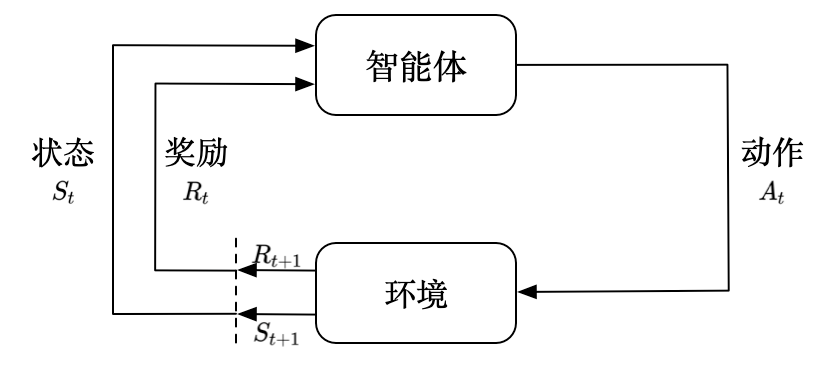
1.1 什麼是強化學習?
強化學習的核心思想是:一個智慧體在一個環境中採取行動,每個行動會導致環境的某種反饋(通常是獎勵或懲罰)。智慧體的目標是學習一個策略,該策略指定在每個狀態下應該採取什麼行動,從而最大化未來的累積獎勵。
例子:想象一個訓練機器人在迷宮中尋找出口的場景。每當機器人走到一個新的位置,它都會得到一個小的獎勵或懲罰,取決於這個位置距離出口的遠近。機器人的目標是學習一個策略,使其能夠最快地找到迷宮的出口,並累積最多的獎勵。
1.2 強化學習的核心元件
1.2.1 智慧體 (Agent)
智慧體是在環境中採取行動的實體,其目標是最大化長期獎勵。
例子:在玩電子遊戲(例如Flappy Bird)的強化學習模型中,智慧體是一個虛擬的「玩家」,它決定什麼時候跳躍,以避免障礙物。
1.2.2 狀態 (State)
狀態描述了環境在某一時刻的情況。它是智慧體採取決策的基礎。
例子:在國際象棋的遊戲中,狀態可以是棋盤上每個棋子的位置。
1.2.3 動作 (Action)
動作是智慧體在給定狀態下可以採取的行為。
例子:在上述的迷宮機器人例子中,動作可以是向上、向下、向左或向右移動。
1.2.4 獎勵 (Reward)
獎勵是對智慧體採取某個動作後,環境給予其的即時反饋。它旨在指導智慧體做出有利於其長期目標的決策。
例子:在自動駕駛車的強化學習模型中,如果車輛遵循交通規則並平穩駕駛,則可能獲得正獎勵;而如果車輛撞到障礙物或違反交通規則,則可能獲得負獎勵。
2. 強化學習與NLP的結合
當我們談論自然語言處理(NLP)時,我們通常指的是與人類語言相關的任務,如機器翻譯、情感分析、問答系統等。近年來,強化學習已成為NLP領域的一個熱門研究方向,因為它為處理一些傳統困難的NLP問題提供了新的視角和方法。
2.1 為什麼在NLP中使用強化學習?
許多NLP任務的特點是其輸出是結構化的、順序的,或者任務的評估指標不容易進行微分。傳統的監督學習方法可能在這些任務上遇到挑戰,而強化學習提供了一個自然的框架,使得模型可以在任務中進行探索,並從延遲的反饋中學習。
例子:考慮對話系統,其中機器需要生成一系列的回覆來維持與使用者的對話。這不僅需要考慮每一句的合理性,還要考慮整體對話的連貫性。強化學習允許模型在與真實使用者互動時探索不同的答案,並從中學習最佳策略。
2.2 強化學習在NLP中的應用場景
2.2.1 對話系統
對話系統,特別是任務驅動的對話系統,旨在幫助使用者完成特定的任務,如預訂機票或查詢資訊。在這裡,強化學習可以幫助模型學習如何根據上下文生成有意義的回覆,並在多輪對話中實現任務的目標。
例子:一個使用者向餐廳預訂系統詢問:「你們有素食選單嗎?」強化學習模型可以學習生成有助於預訂過程的回覆,例如:「是的,我們有素食選單。您想預訂幾位?」而不是簡單地回答「是的」。
2.2.2 機器翻譯
儘管機器翻譯經常使用監督學習,但強化學習可以優化那些與直接翻譯質量評估相關的指標,如BLEU分數,從而提高譯文的質量。
例子:考慮從英語翻譯到法語的句子。「The cat sat on the mat」可能有多種合理的法語譯文。強化學習可以幫助模型探索這些可能的譯文,並根據外部評估器的反饋來優化輸出。
2.2.3 文字生成
文字生成任務如摘要、故事生成等,要求模型生成連貫且有意義的文欄位落。強化學習為這類任務提供了一個自然的方式來優化生成內容的質量。
例子:在自動新聞摘要任務中,模型需要從長篇新聞中提取關鍵資訊並生成一個簡短的摘要。強化學習可以幫助模型學習如何權衡資訊的重要性,並生成讀者喜歡的摘要。
3. 技術解析
深入探討強化學習與NLP結合時所使用的關鍵技術和方法,理解這些技術是如何工作的、它們如何為NLP任務提供支援。
3.1 策略梯度方法
策略梯度是一種優化引數化策略的方法,它直接估計策略的梯度,並調整引數以優化期望的獎勵。
概念
策略通常表示為引數化的概率分佈。策略梯度方法的目標是找到引數值,使得期望獎勵最大化。為此,它估計策略關於其引數的梯度,並使用此梯度來更新引數。
例子:在機器翻譯任務中,可以使用策略梯度方法優化譯文的生成策略,使得翻譯的質量或BLEU分數最大化。
3.2 序列決策過程
在許多NLP任務中,決策是序列性的,這意味著在一個時間點的決策會影響後續的決策和獎勵。
概念
序列決策過程通常可以用馬爾可夫決策過程(MDP)來描述,其中每一個狀態只依賴於前一個狀態和採取的動作。在這種情況下,策略定義了在給定狀態下選擇動作的概率。
例子:在對話系統中,系統的回覆需要考慮到之前的對話內容。每次回覆都基於當前的對話狀態,並影響後續的對話流程。
3.3 深度強化學習
深度強化學習結合了深度學習和強化學習,使用神經網路來估計價值函數或策略。
概念
在深度強化學習中,智慧體使用深度神經網路來處理輸入的狀態,並輸出一個動作或動作的概率分佈。通過訓練,神經網路可以從大量的互動中學習到有效的策略。
例子:在文字生成任務中,可以使用深度強化學習來優化生成的文字內容。例如,使用神經網路模型根據當前的文章內容預測下一個詞,而強化學習部分可以根據生成內容的質量給予獎勵或懲罰,從而優化模型的輸出。
4. 實戰案例 - 對話系統
對話系統的核心目標是與使用者進行有效的互動,為使用者提供所需的資訊或協助。在此,我們將通過一個簡單的對話系統範例,展示如何利用強化學習優化對話策略。
4.1 定義狀態、動作和獎勵
4.1.1 狀態 (State)
對話系統的狀態通常包括當前對話的歷史記錄,例如前幾輪的對話內容。
例子:如果使用者問:「你們有素食選單嗎?」,狀態可以是["你們有素食選單嗎?"]。
4.1.2 動作 (Action)
動作是系統可以採取的回覆。
例子:系統的可能回覆包括:「是的,我們有。」、「不好意思,我們沒有。」或「你想要預定嗎?」等。
4.1.3 獎勵 (Reward)
獎勵是基於系統回覆的效果給出的數值。例如,如果回覆滿足使用者需求,可以給予正獎勵;否則,給予負獎勵。
例子:如果使用者問:「你們有素食選單嗎?」,系統回覆:「是的,我們有。」,則可以給予+1的獎勵。
4.2 強化學習模型
我們可以使用PyTorch來實現一個簡單的深度強化學習模型。
import torch
import torch.nn as nn
import torch.optim as optim
# 定義一個簡單的神經網路策略
class DialoguePolicy(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(DialoguePolicy, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
return torch.softmax(self.fc2(x), dim=1)
# 初始化模型和優化器
input_size = 10 # 假設狀態向量的大小為10
hidden_size = 32
output_size = 3 # 假設有三個可能的回覆
policy = DialoguePolicy(input_size, hidden_size, output_size)
optimizer = optim.Adam(policy.parameters(), lr=0.01)
# 模型的輸入、輸出
state = torch.rand((1, input_size)) # 假設的狀態向量
action_probabilities = policy(state)
action = torch.multinomial(action_probabilities, 1) # 根據策略選擇一個動作
print("Action Probabilities:", action_probabilities)
print("Chosen Action:", action.item())
4.3 互動和訓練
模型與環境(使用者模擬器)互動,獲取獎勵,然後根據獎勵優化策略。在實際應用中,可以使用真實使用者的反饋來優化策略。
5. 實戰案例 - 機器翻譯
機器翻譯的目標是將一種語言的文字準確地轉換為另一種語言。強化學習可以優化生成的翻譯,使其更為流暢和準確。接下來,我們將探討如何使用強化學習來優化機器翻譯系統。
5.1 定義狀態、動作和獎勵
5.1.1 狀態 (State)
機器翻譯的狀態可以是原文的部分或全部內容,以及已生成的翻譯。
例子:原文:「How are you?」,已生成的翻譯:「你好」,狀態可以是["How are you?", "你好"]。
5.1.2 動作 (Action)
動作是模型決定的下一個詞或短語。
例子:基於上面的狀態,可能的動作包括:「嗎?」、「是」、「的」等。
5.1.3 獎勵 (Reward)
獎勵可以基於生成的翻譯的質量,例如BLEU分數,或其他評價指標。
例子:如果生成的完整翻譯是:「你好嗎?」,與參考翻譯相比,可以計算出一個BLEU分數作為獎勵。
5.2 強化學習模型
使用PyTorch實現簡單的深度強化學習策略模型。
import torch
import torch.nn as nn
import torch.optim as optim
# 定義一個簡單的神經網路策略
class TranslationPolicy(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(TranslationPolicy, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
return torch.softmax(self.fc2(x), dim=1)
# 初始化模型和優化器
input_size = 100 # 假設狀態向量的大小為100 (原文和已生成翻譯的嵌入表示)
hidden_size = 64
output_size = 5000 # 假設目標語言的詞彙表大小為5000
policy = TranslationPolicy(input_size, hidden_size, output_size)
optimizer = optim.Adam(policy.parameters(), lr=0.01)
# 模型的輸入、輸出
state = torch.rand((1, input_size)) # 假設的狀態向量
action_probabilities = policy(state)
action = torch.multinomial(action_probabilities, 1) # 根據策略選擇一個動作
print("Action Probabilities:", action_probabilities[0, :10]) # 列印前10個動作的概率
print("Chosen Action:", action.item())
5.3 互動和訓練
模型生成翻譯,並與環境(這裡可以是一個評價系統)互動以獲得獎勵。之後,使用這些獎勵來優化翻譯策略。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。