NLP文字生成全解析:從傳統方法到預訓練完整介紹
本文深入探討了文字生成的多種方法,從傳統的基於統計和模板的技術到現代的神經網路模型,尤其是LSTM和Transformer架構。文章還詳細介紹了大型預訓練模型如GPT在文字生成中的應用,並提供了Python和PyTorch的實現程式碼。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。

1. 引言
1.1 文字生成的定義和作用
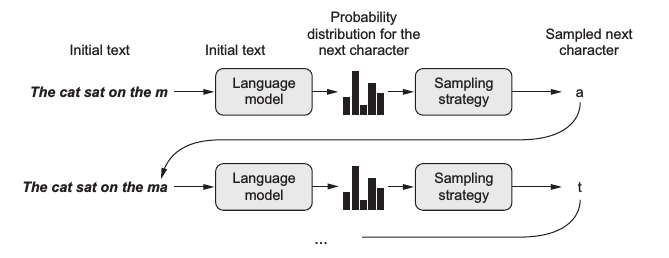
文字生成是自然語言處理的一個核心子領域,它涉及使用模型來自動建立自然語言文字。這種生成可以是基於某些輸入的響應,如影象或其他文字,也可以是完全自主的創造。
文字生成的任務可以是簡單的,如自動回覆郵件,也可以是更復雜的,如編寫新聞文章或生成故事。它通常包括以下步驟:
- 確定目標和約束:明確生成文字的目標和約束條件,如風格、語言和長度等。
- 內容的生成:基於預定義的目標和約束條件來生成內容。
- 評價和優化:使用不同的評價指標來測試生成的文字,並進行必要的優化。
例子:
- 自動回覆郵件:根據收到的郵件內容,系統可以生成一個簡短的、相關的回覆。
- 新聞文章生成:利用已有的資料和資訊來自動生成新聞文章。
- 故事生成:建立一個可以根據輸入的提示來生成故事的系統。
1.2 自然語言處理技術在文字生成領域的使用
自然語言處理技術為文字生成提供了強大的工具和方法。這些技術可以用於解析輸入資料、理解語言結構、評估生成文字的質量,以及優化生成過程。
-
序列到序列模型:這是一個廣泛應用於文字生成任務的框架,如機器翻譯和摘要生成。模型學習將輸入序列(如句子)轉化為輸出序列(如另一種語言的句子)。
-
注意力機制:在處理長序列時,注意力機制可以幫助模型關注輸入資料的關鍵部分,從而產生更準確的輸出。
-
預訓練語言模型:像BERT和GPT這樣的模型通過大量的文字資料進行預訓練,之後可以用於各種NLP任務,包括文字生成。
-
優化技術:如束搜尋和取樣策略,它們可以幫助生成更流暢、準確的文字。
例子:
- 機器翻譯:使用序列到序列模型,將英語句子轉化為法語句子。
- 生成摘要:利用注意力機制從長篇文章中提取關鍵資訊,生成簡短的摘要。
- 文字填充:使用預訓練的GPT模型,根據給定的開頭生成一個完整的故事。
隨著技術的進步,自然語言處理技術在文字生成中的應用也越來越廣泛,為我們提供了更多的可能性和機會。
2 傳統方法 - 基於統計的方法
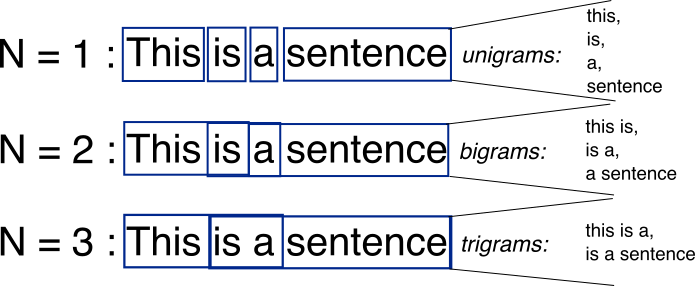
在深度學習技術盛行之前,文字生成主要依賴於基於統計的方法。這些方法通過統計語料庫中的詞語和短語的頻率,預測下一個詞或短語的出現概率。
2.1.1 N-gram模型
定義:N-gram模型是基於統計的文字生成方法中的一種經典技術。它基於一個假設,即第N個詞的出現只與前面的N-1個詞有關。例如,在一個trigram(3-gram)模型中,下一個詞的出現只與前兩個詞有關。
例子:考慮句子 "我愛學習人工智慧",在一個bigram(2-gram)模型中,"人工" 出現後的下一個詞可能是 "智慧"。
from collections import defaultdict, Counter
import random
def build_ngram_model(text, n=2):
model = defaultdict(Counter)
for i in range(len(text) - n):
context, word = tuple(text[i:i+n-1]), text[i+n-1]
model[context][word] += 1
return model
def generate_with_ngram(model, max_len=20):
context = random.choice(list(model.keys()))
output = list(context)
for i in range(max_len):
if context not in model:
break
next_word = random.choices(list(model[context].keys()), weights=model[context].values())[0]
output.append(next_word)
context = tuple(output[-len(context):])
return ' '.join(output)
text = "我 愛 學習 人工 智慧".split()
model = build_ngram_model(text, n=2)
generated_text = generate_with_ngram(model)
print(generated_text)
2.1.2 平滑技術
定義:在統計模型中,我們經常會遇到一個問題,即語料庫中可能有一些N-grams從未出現過,導致其概率為0。為了解決這個問題,我們使用平滑技術來為這些未出現的N-grams分配一個非零概率。
例子:使用Add-1平滑(Laplace平滑),我們將每個詞的計數加1,來保證沒有詞的概率為0。
def laplace_smoothed_probability(word, context, model, V):
return (model[context][word] + 1) / (sum(model[context].values()) + V)
V = len(set(text))
context = ('我', '愛')
probability = laplace_smoothed_probability('學習', context, model, V)
print(f"P('學習'|'我 愛') = {probability}")
通過使用基於統計的方法,雖然我們可以生成文字,但這些方法有其侷限性,尤其是在處理長文字時。隨著深度學習技術的發展,更先進的模型逐漸取代了傳統方法,為文字生成帶來了更多的可能性。
3. 傳統方法 - 基於模板的生成
基於模板的文字生成是一種早期的文字生成方法,依賴於預定義的句子結構和詞彙來建立文字。這種方法雖然簡單直觀,但其生成的文字通常缺乏變化和多樣性。
3.1 定義與特點
定義:模板生成方法涉及到使用預先定義的文字模板和固定的結構,根據不同的資料或上下文填充這些模板,從而生成文字。
特點:
- 確定性:輸出是可預測的,因為它直接基於模板。
- 快速生成:不需要複雜的計算,只需簡單地填充模板。
- 侷限性:輸出可能缺乏多樣性和自然感,因為它完全基於固定模板。
例子:在天氣預報中,可以有一個模板:「今天在{城市}的最高溫度為{溫度}度。」。根據不同的資料,我們可以填充該模板,生成如「今天在北京的最高溫度為25度。」的句子。
def template_generation(template, **kwargs):
return template.format(**kwargs)
template = "今天在{city}的最高溫度為{temperature}度。"
output = template_generation(template, city="北京", temperature=25)
print(output)
3.2 動態模板
定義:為了增加文字的多樣性,我們可以設計多個模板,並根據上下文或隨機性選擇不同的模板進行填充。
例子:針對天氣預報,我們可以有以下模板:
- 「{city}今天的溫度達到了{temperature}度。」
- 「在{city},今天的最高氣溫是{temperature}度。」
import random
def dynamic_template_generation(templates, **kwargs):
chosen_template = random.choice(templates)
return chosen_template.format(**kwargs)
templates = [
"{city}今天的溫度達到了{temperature}度。",
"在{city},今天的最高氣溫是{temperature}度。"
]
output = dynamic_template_generation(templates, city="上海", temperature=28)
print(output)
儘管基於模板的方法為文字生成提供了一種簡單和直接的方式,但它在處理複雜和多樣化的文字生成任務時可能會顯得力不從心。現代深度學習方法提供了更強大、靈活和多樣化的文字生成能力,逐漸成為主流方法。
4. 神經網路方法 - 長短時記憶網路(LSTM)
長短時記憶網路(LSTM)是一種特殊的遞迴神經網路(RNN),專為解決長期依賴問題而設計。在傳統的RNN中,隨著時間步的增加,資訊的傳遞會逐漸變得困難。LSTM通過其特殊的結構來解決這個問題,允許資訊在時間步之間更容易地流動。
LSTM的核心概念
定義:LSTM的核心是其細胞狀態,通常表示為(C_t)。與此同時,LSTM包含三個重要的門:遺忘門、輸入門和輸出門,這三個門共同決定資訊如何被更新、儲存和檢索。
- 遺忘門:決定哪些資訊從細胞狀態中被遺忘或丟棄。
- 輸入門:更新細胞狀態,決定哪些新資訊被儲存。
- 輸出門:基於細胞狀態,決定輸出什麼資訊。
例子:假設我們正在處理一個文字序列,並想要記住某個詞彙的性別標記(如「他」或「她」)。當我們遇到一個新的代詞時,遺忘門可能會幫助模型忘記舊的性別標記,輸入門會幫助模型儲存新的標記,而輸出門則會在下一個時間步輸出這個標記,以保持序列的一致性。
PyTorch中的LSTM
使用PyTorch,我們可以輕鬆地定義和訓練一個LSTM模型。
import torch.nn as nn
import torch
# 定義LSTM模型
class LSTMModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)
self.linear = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
# 初始化隱藏狀態和細胞狀態
h0 = torch.zeros(num_layers, x.size(0), hidden_dim).requires_grad_()
c0 = torch.zeros(num_layers, x.size(0), hidden_dim).requires_grad_()
out, (hn, cn) = self.lstm(x, (h0.detach(), c0.detach()))
out = self.linear(out[:, -1, :])
return out
input_dim = 10
hidden_dim = 20
output_dim = 1
num_layers = 1
model = LSTMModel(input_dim, hidden_dim, output_dim, num_layers)
# 一個簡單的例子,輸入形狀為 (batch_size, time_steps, input_dim)
input_seq = torch.randn(5, 10, 10)
output = model(input_seq)
print(output.shape) # 輸出形狀為 (batch_size, output_dim)
LSTM由於其在處理時間序列資料,尤其是在長序列中保留關鍵資訊的能力,已經在多種自然語言處理任務中取得了顯著的成功,例如文字生成、機器翻譯和情感分析等。
5. 神經網路方法 - Transformer
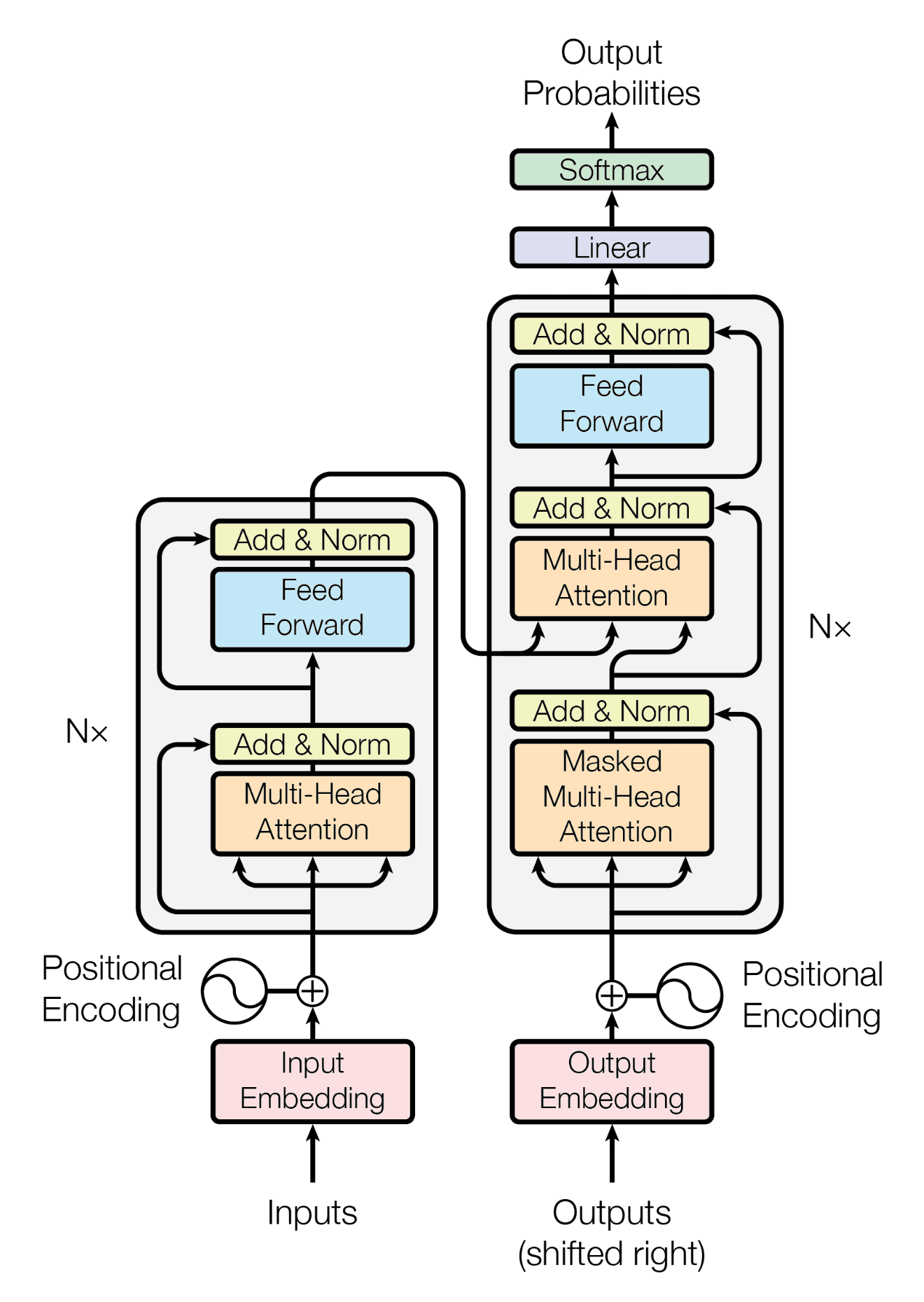
Transformer 是近年來自然語言處理領域的重要進展,它摒棄了傳統的遞迴和折積結構,完全依賴自注意力機制來處理序列資料。
Transformer的核心概念
定義:Transformer 是一個基於自注意力機制的深度學習模型,旨在處理序列資料,如文字。其核心是多頭自注意力機制,可以捕捉序列中不同位置間的依賴關係,無論它們之間有多遠。
多頭自注意力:這是 Transformer 的關鍵部分。每個「頭」都學習序列中的不同位置的表示,然後將這些表示組合起來。
位置編碼:由於 Transformer 不使用遞迴或折積,因此需要額外的位置資訊來了解序列中詞的位置。位置編碼將這種資訊新增到序列的每個位置。
例子:考慮句子 "The cat sat on the mat." 如果我們想強調 "cat" 和 "mat" 之間的關係,多頭自注意力機制使 Transformer 可以同時關注 "cat" 和距離較遠的 "mat"。
PyTorch中的Transformer
使用 PyTorch,我們可以使用現成的 Transformer 模組來定義一個簡單的 Transformer 模型。
import torch.nn as nn
import torch
class TransformerModel(nn.Module):
def __init__(self, d_model, nhead, num_encoder_layers, num_decoder_layers):
super(TransformerModel, self).__init__()
self.transformer = nn.Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers)
self.fc = nn.Linear(d_model, d_model) # 範例中的一個簡單的線性層
def forward(self, src, tgt):
output = self.transformer(src, tgt)
return self.fc(output)
d_model = 512
nhead = 8
num_encoder_layers = 6
num_decoder_layers = 6
model = TransformerModel(d_model, nhead, num_encoder_layers, num_decoder_layers)
# 範例輸入,形狀為 (sequence_length, batch_size, d_model)
src = torch.randn(10, 32, d_model)
tgt = torch.randn(20, 32, d_model)
output = model(src, tgt)
print(output.shape) # 輸出形狀為 (tgt_sequence_length, batch_size, d_model)
Transformer 由於其強大的自注意力機制和並行處理能力,已經在多種自然語言處理任務中取得了突破性的成果,如 BERT、GPT 和 T5 等模型都是基於 Transformer 架構構建的。
6. 大型預訓練模型 - GPT文字生成機制
近年來,大型預訓練模型如 GPT、BERT 和 T5 等已成為自然語言處理領域的標準模型。它們在多種任務上都展現出了卓越的效能,尤其在文字生成任務上。
大型預訓練模型的核心概念
定義:大型預訓練模型是通過在大量無標籤資料上進行預訓練的模型,然後在具體任務上進行微調。這種「預訓練-微調」正規化使得模型能夠捕捉到自然語言的豐富表示,併為各種下游任務提供一個強大的起點。
預訓練:模型在大規模文字資料上進行無監督學習,如書籍、網頁等。此時,模型學習到了詞彙、語法和一些常識資訊。
微調:在預訓練後,模型在特定任務的標記資料上進行有監督學習,如機器翻譯、文字生成或情感分析。
例子:考慮 GPT-3,它首先在大量的文字上進行預訓練,學習到語言的基本結構和資訊。然後,可以用很少的樣本或無需任何額外的訓練,直接在特定任務上生成文字。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。