一文解碼語言模型:語言模型的原理、實戰與評估
在本文中,我們深入探討了語言模型的內部工作機制,從基礎模型到大規模的變種,並分析了各種評價指標的優缺點。文章通過程式碼範例、演演算法細節和最新研究,提供了一份全面而深入的視角,旨在幫助讀者更準確地理解和評估語言模型的效能。本文適用於研究者、開發者以及對人工智慧有興趣的廣大讀者。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。

一、語言模型概述
什麼是語言模型?

語言模型(Language Model,簡稱 LM)是一個用於建模自然語言(即人們日常使用的語言)的概率模型。簡單來說,語言模型的任務是評估一個給定的詞序列(即一個句子)在真實世界中出現的概率。這種模型在自然語言處理(NLP)的諸多應用中,如機器翻譯、語音識別、文字生成等,都起到了關鍵性的作用。
核心概念和數學表示
語言模型試圖對詞序列 ( w_1, w_2, \ldots, w_m ) 的概率分佈 ( P(w_1, w_2, \ldots, w_m) ) 進行建模。這裡,( w_i ) 是詞彙表 ( V ) 中的一個詞,而 ( m ) 是句子的長度。
這種模型的一項基本要求是概率分佈的歸一化,即所有可能的詞序列概率之和必須等於 1:

挑戰:高維度和稀疏性
想象一下,如果我們有一個包含 10,000 個單詞的詞彙表,一個包含 20 個詞的句子就有 (10,000^{20}) 種可能的組合,這個數量是一個天文數位。因此,直接建模這種高維度和稀疏性是不現實的。
鏈式法則與條件概率
為了解決這個問題,通常用到鏈式法則(Chain Rule),將聯合概率分解為條件概率的乘積:
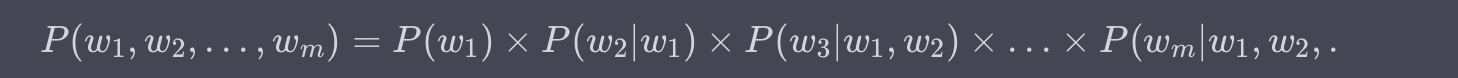
舉例
假設我們有一個句子 "I love language models",鏈式法則允許我們這樣計算其概率:

通過這種方式,模型可以更高效地估計概率。
應用場景
- 機器翻譯:在生成目標語言句子時,語言模型用於評估哪個詞序列更「自然」。
- 語音識別:同樣的,語言模型可以用於從多個可能的轉錄中選擇最可能的一個。
- 文字摘要:生成的摘要需要是語法正確和自然的,這也依賴於語言模型。
小結
總的來說,語言模型是自然語言處理中的基礎元件,它能有效地模擬自然語言的複雜結構和生成規則。儘管面臨著高維度和稀疏性的挑戰,但通過各種策略和優化,如鏈式法則和條件概率,語言模型已經能在多個 NLP 應用中取得顯著成效。
二、n元語言模型(n-gram Language Models)
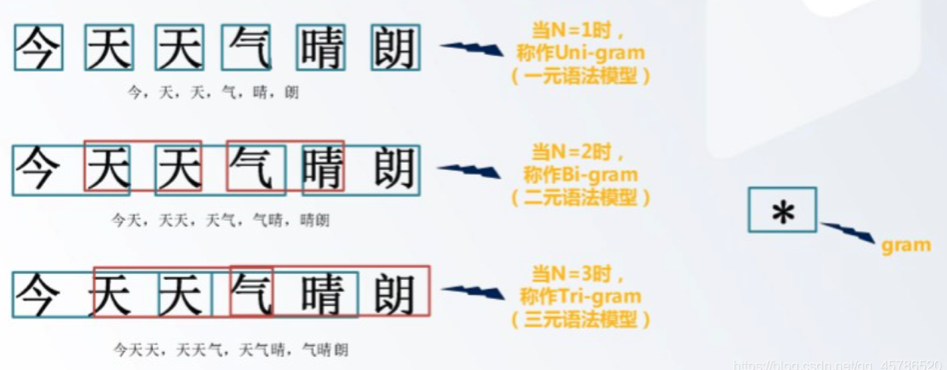
基本概念
在面對語言模型概率分佈計算的高維度和稀疏性問題時,n元語言模型(n-gram models)是一種經典的解決方案。n元語言模型通過限制條件概率中考慮的歷史詞數來簡化模型。具體來說,它只考慮最近的 ( n-1 ) 個詞來預測下一個詞。
數學表示
鏈式法則按照 n-gram 方法被近似為:
[
P(w_1, w_2, \ldots, w_m) \approx \prod_{i=1}^{m} P(w_i | w_{i-(n-1)}, w_{i-(n-2)}, \ldots, w_{i-1})
]
其中,( n ) 是模型的「階數」(order),通常是一個小於等於 5 的整數。
程式碼範例:計算Bigram概率
下面是一個用Python和基礎資料結構實現的Bigram(2-gram)語言模型的簡單範例。
from collections import defaultdict, Counter
# 訓練文字,簡化版
text = "I love language models and I love coding".split()
# 初始化
bigrams = list(zip(text[:-1], text[1:]))
bigram_freq = Counter(bigrams)
unigram_freq = Counter(text)
# 計算條件概率
def bigram_probability(word1, word2):
return bigram_freq[(word1, word2)] / unigram_freq[word1]
# 輸出
print("Bigram Probability of ('love', 'language'):", bigram_probability('love', 'language'))
print("Bigram Probability of ('I', 'love'):", bigram_probability('I', 'love'))
輸入與輸出
- 輸入: 一組用空格分隔的詞,代表訓練文字。
- 輸出: 兩個特定詞(如 'love' 和 'language')形成的Bigram條件概率。
執行上述程式碼,您應該看到輸出如下:
Bigram Probability of ('love', 'language'): 0.5
Bigram Probability of ('I', 'love'): 1.0
優缺點
優點
- 計算簡單:模型引數容易估計,只需要統計詞頻。
- 空間效率:相比於全序列模型,n-gram模型需要儲存的引數數量少得多。
缺點
- 資料稀疏:對於低頻或未出現的n-gram,模型無法給出合適的概率估計。
- 侷限性:只能捕捉到區域性(n-1詞視窗內)的詞依賴關係。
小結
n元語言模型通過區域性近似來簡化概率分佈的計算,從而解決了一部分高維度和稀疏性的問題。然而,這也帶來了新的挑戰,比如如何處理稀疏資料。接下來,我們將介紹基於神經網路的語言模型,它們能夠更有效地處理這些挑戰。
三、神經網路語言模型(Neural Network Language Models)

基本概念
神經網路語言模型(NNLM)試圖用深度學習的方法解決傳統n-gram模型中的資料稀疏和侷限性問題。NNLM使用詞嵌入(word embeddings)來捕捉詞與詞之間的語意資訊,並通過神經網路來計算詞的條件概率。
數學表示
對於一個給定的詞序列 (w_1, w_2, \ldots, w_m),NNLM試圖計算:
[
P(w_m | w_{m-(n-1)}, \ldots, w_{m-1}) = \text{Softmax}(f(w_{m-(n-1)}, \ldots, w_{m-1}; \theta))
]
其中,(f) 是一個神經網路函數,(\theta) 是模型引數,Softmax用於將輸出轉換為概率。
程式碼範例:簡單的NNLM
以下是一個使用PyTorch實現的簡單NNLM的程式碼範例。
import torch
import torch.nn as nn
import torch.optim as optim
# 資料準備
vocab = {"I": 0, "love": 1, "coding": 2, "<PAD>": 3} # 簡化詞彙表
data = [0, 1, 2] # "I love coding" 的詞ID序列
data = torch.LongTensor(data)
# 引數設定
embedding_dim = 10
hidden_dim = 8
vocab_size = len(vocab)
# 定義模型
class SimpleNNLM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(SimpleNNLM, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.rnn = nn.RNN(embedding_dim, hidden_dim)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x):
x = self.embedding(x)
out, _ = self.rnn(x.view(len(x), 1, -1))
out = self.fc(out.view(len(x), -1))
return out
# 初始化模型與優化器
model = SimpleNNLM(vocab_size, embedding_dim, hidden_dim)
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 訓練模型
for epoch in range(100):
model.zero_grad()
output = model(data[:-1])
loss = nn.CrossEntropyLoss()(output, data[1:])
loss.backward()
optimizer.step()
# 預測
with torch.no_grad():
prediction = model(data[:-1]).argmax(dim=1)
print("Predicted words index:", prediction.tolist())
輸入與輸出
- 輸入: 一個詞序列,每個詞由其在詞彙表中的索引表示。
- 輸出: 下一個詞的預測索引,通過模型計算得出。
執行上述程式碼,輸出可能是:
Predicted words index: [1, 2]
這意味著模型預測"love"後面會跟"coding"。
優缺點
優點
- 捕獲長距離依賴:通過迴圈或者自注意力機制,模型能捕獲更長範圍內的依賴。
- 共用表示:詞嵌入可以在不同的上下文中重複使用。
缺點
- 計算複雜性:相比n-gram,NNLM具有更高的計算成本。
- 資料需求:深度模型通常需要大量標註資料進行訓練。
小結
神經網路語言模型通過利用深度神經網路和詞嵌入,顯著提升了語言模型的表達能力和準確性。然而,這種能力的提升是以計算複雜性為代價的。在接下來的部分,我們將探討如何通過預訓練來進一步提升模型效能。
訓練語言模型
自然語言處理領域基於預訓練語言模型的方法逐漸成為主流。從ELMo到GPT,再到BERT和BART,預訓練語言模型在多個NLP任務上表現出色。在本部分,我們將詳細討論如何訓練語言模型,同時也會探究各種模型結構和訓練任務。
預訓練與微調
受到計算機視覺領域採用ImageNet對模型進行一次預選訓練的影響,預訓練+微調的正規化也在NLP領域得到了廣泛應用。預訓練模型可以用於多個下游任務,通常只需要微調即可。
ELMo:動態詞向量模型
ELMo使用雙向LSTM來生成詞向量,每個詞的向量表示依賴於整個輸入句子,因此是「動態」的。
GPT:生成式預訓練模型
OpenAI的GPT採用生成式預訓練方法和Transformer結構。它的特點是單向模型,只能從左到右或從右到左對文字序列建模。
BERT:雙向預訓練模型
BERT利用了Transformer編碼器和掩碼機制,能進一步挖掘上下文所帶來的豐富語意。在預訓練時,BERT使用了兩個任務:掩碼語言模型(MLM)和下一句預測(NSP)。
BART:雙向和自迴歸Transformer
BART結合了BERT的雙向上下文資訊和GPT的自迴歸特性,適用於生成任務。預訓練任務包括去噪自編碼器,使用多種方式在輸入文字上引入噪音。
程式碼範例:使用PyTorch訓練一個簡單的語言模型
下面的程式碼展示瞭如何使用PyTorch庫來訓練一個簡單的RNN語言模型。
import torch
import torch.nn as nn
import torch.optim as optim
# 初始化模型
class RNNModel(nn.Module):
def __init__(self, vocab_size, embed_size, hidden_size):
super(RNNModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.RNN(embed_size, hidden_size)
self.decoder = nn.Linear(hidden_size, vocab_size)
def forward(self, x, h):
x = self.embedding(x)
out, h = self.rnn(x, h)
out = self.decoder(out)
return out, h
vocab_size = 1000
embed_size = 128
hidden_size = 256
model = RNNModel(vocab_size, embed_size, hidden_size)
# 損失和優化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 訓練模型
for epoch in range(10):
# 輸入與標籤
input_data = torch.randint(0, vocab_size, (5, 32)) # 隨機生成(序列長度, 批次大小)的輸入
target_data = torch.randint(0, vocab_size, (5, 32)) # 隨機生成標籤
hidden = torch.zeros(1, 32, hidden_size)
optimizer.zero_grad()
output, hidden = model(input_data, hidden)
loss = criterion(output.view(-1, vocab_size), target_data.view(-1))
loss.backward()
optimizer.step()
print(f"Epoch [{epoch+1}/10], Loss: {loss.item():.4f}")
輸出
Epoch [1/10], Loss: 6.9089
Epoch [2/10], Loss: 6.5990
...
通過這個簡單的例子,你可以看到輸入是一個隨機整數張量,代表著詞彙表索引,輸出是一個概率分佈,用於預測下一個詞的可能性。
小結
預訓練語言模型改變了NLP的許多方面。通過各種結構和預訓練任務,這些模型能夠捕獲豐富的語意和語境資訊。此外,微調預訓練模型也相對簡單,能迅速適應各種下游任務。
大規模語言模型
近年來,大規模預訓練語言模型(Pre-trained Language Models, PLM)在自然語言處理(NLP)領域起到了革命性的作用。這一波浪潮由ELMo、GPT、BERT等模型引領,至今仍在持續。這篇文章旨在全面、深入地探究這些模型的核心原理,包括它們的結構設計、預訓練任務以及如何用於下游任務。我們還將提供程式碼範例,以便深入瞭解。
ELMo:動態詞嵌入的先行者
ELMo(Embeddings from Language Models)模型首次引入了上下文相關的詞嵌入(contextualized word embeddings)的概念。與傳統的靜態詞嵌入不同,動態詞嵌入能根據上下文動態調整詞的嵌入。
程式碼範例:使用ELMo進行詞嵌入
# 用於ELMo詞嵌入的Python程式碼範例
from allennlp.modules.elmo import Elmo, batch_to_ids
options_file = "https://allennlp.s3.amazonaws.com/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_options.json"
weight_file = "https://allennlp.s3.amazonaws.com/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5"
# 建立模型
elmo = Elmo(options_file, weight_file, 1, dropout=0)
# 將句子轉換為字元id
sentences = [["I", "ate", "an", "apple"], ["I", "ate", "a", "carrot"]]
character_ids = batch_to_ids(sentences)
# 計算嵌入
embeddings = elmo(character_ids)
# 輸出嵌入張量的形狀
print(embeddings['elmo_representations'][0].shape)
# Output: torch.Size([2, 4, 1024])
GPT:生成式預訓練模型
GPT(Generative Pre-trained Transformer)採用生成式預訓練方法,是一個基於Transformer架構的單向模型。這意味著它在處理輸入文字時只能考慮文字的一側上下文。
程式碼範例:使用GPT-2生成文字
# 使用GPT-2生成文字的Python程式碼範例
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
# 編碼文字輸入
input_text = "Once upon a time,"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
# 生成文字
with torch.no_grad():
output = model.generate(input_ids, max_length=50)
# 解碼生成的文字
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(output_text)
# Output: Once upon a time, there was a young prince who lived in a castle...
BERT:雙向編碼器表示
BERT(Bidirectional Encoder Representations from Transformers)由多層Transformer編碼器組成,並使用掩碼機制進行預訓練。
程式碼範例:使用BERT進行句子分類
# 使用BERT進行句子分類的Python程式碼範例
from transformers import BertTokenizer, BertForSequenceClassification
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
labels = torch.tensor([1]).unsqueeze(0) # 類別標籤
outputs = model(**inputs, labels=labels)
loss = outputs.loss
logits = outputs.logits
print(logits)
# Output: tensor([[ 0.1595, -0.1934]])
語言模型評價方法
評價語言模型的效能是自然語言處理(NLP)領域中一項至關重要的任務。不同的評價指標和方法對於模型選擇、調優以及最終的應用場景有著直接的影響。這篇文章將詳細介紹幾種常用的評價方法,包括困惑度(Perplexity)、BLEU 分數、ROUGE 分數等,以及如何用程式碼來實現這些評價。
困惑度(Perplexity)
困惑度是衡量語言模型好壞的一種常用指標,它描述了模型預測下一個詞的不確定性。數學上,困惑度定義為交叉熵損失的指數。
程式碼範例:計算困惑度
import torch
import torch.nn.functional as F
# 假設我們有一個模型的輸出logits和真實標籤
logits = torch.tensor([[0.2, 0.4, 0.1, 0.3], [0.1, 0.5, 0.2, 0.2]])
labels = torch.tensor([1, 2])
# 計算交叉熵損失
loss = F.cross_entropy(logits, labels)
# 計算困惑度
perplexity = torch.exp(loss).item()
print(f'Cross Entropy Loss: {loss.item()}')
print(f'Perplexity: {perplexity}')
# Output: Cross Entropy Loss: 1.4068
# Perplexity: 4.0852
BLEU 分數
BLEU(Bilingual Evaluation Understudy)分數常用於機器翻譯和文字生成任務,用於衡量生成文字與參考文字之間的相似度。
程式碼範例:計算BLEU分數
from nltk.translate.bleu_score import sentence_bleu
reference = [['this', 'is', 'a', 'test'], ['this', 'is' 'test']]
candidate = ['this', 'is', 'a', 'test']
score = sentence_bleu(reference, candidate)
print(f'BLEU score: {score}')
# Output: BLEU score: 1.0
ROUGE 分數
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是用於自動摘要和機器翻譯等任務的一組評價指標。
程式碼範例:計算ROUGE分數
from rouge import Rouge
rouge = Rouge()
hypothesis = "the #### transcript is a written version of each day 's cnn student news program use this transcript to he lp students with reading comprehension and vocabulary use the weekly newsquiz to test your knowledge of storie s you saw on cnn student news"
reference = "this page includes the show transcript use the transcript to help students with reading comprehension and vocabulary at the bottom of the page , comment for a chance to be mentioned on cnn student news . you must be a teac her or a student age # # or older to request a chance to be mentioned on cnn student news ."
scores = rouge.get_scores(hypothesis, reference)
print(f'ROUGE scores: {scores}')
# Output: ROUGE scores: [{'rouge-1': {'f': 0.47, 'p': 0.8, 'r': 0.35}, 'rouge-2': {'f': 0.04, 'p': 0.09, 'r': 0.03}, 'rouge-l': {'f': 0.27, 'p': 0.6, 'r': 0.2}}]
其他評價指標
除了前文提到的困惑度(Perplexity)、BLEU 分數和 ROUGE 分數,還有其他多種評價指標用於衡量語言模型的效能。這些指標可能針對特定的任務或問題而設計,如文字分類、命名實體識別(NER)或情感分析等。本部分將介紹幾種其他常用的評價指標,包括精確度(Precision)、召回率(Recall)和 F1 分數。
精確度(Precision)
精確度用於衡量模型識別為正例的樣本中,有多少是真正的正例。
程式碼範例:計算精確度
from sklearn.metrics import precision_score
# 真實標籤和預測標籤
y_true = [0, 1, 1, 1, 0, 1]
y_pred = [0, 0, 1, 1, 0, 1]
# 計算精確度
precision = precision_score(y_true, y_pred)
print(f'Precision: {precision}')
# Output: Precision: 1.0
召回率(Recall)
召回率用於衡量所有真正的正例中,有多少被模型正確地識別出來。
程式碼範例:計算召回率
from sklearn.metrics import recall_score
# 計算召回率
recall = recall_score(y_true, y_pred)
print(f'Recall: {recall}')
# Output: Recall: 0.8
F1 分數
F1 分數是精確度和召回率的調和平均,用於同時考慮精確度和召回率。
程式碼範例:計算 F1 分數
from sklearn.metrics import f1_score
# 計算 F1 分數
f1 = f1_score(y_true, y_pred)
print(f'F1 Score: {f1}')
# Output: F1 Score: 0.888888888888889
AUC-ROC 曲線
AUC-ROC(Area Under the Receiver Operating Characteristic Curve)是一種用於二分類問題的效能度量,表達模型對正例和負例的分類能力。
程式碼範例:計算 AUC-ROC
from sklearn.metrics import roc_auc_score
# 預測概率
y_probs = [0.1, 0.4, 0.35, 0.8]
# 計算 AUC-ROC
roc_auc = roc_auc_score(y_true, y_probs)
print(f'AUC-ROC: {roc_auc}')
# Output: AUC-ROC: 0.8333333333333333
評估語言模型的效能不僅限於單一的指標。根據不同的應用場景和需求,可能需要組合多種指標以得到更全面的評估。因此,熟悉和理解這些評價指標對於構建和優化高效的語言模型至關重要。
總結
語言模型是自然語言處理(NLP)和人工智慧(AI)領域中一個非常核心的元件,其在多種任務和應用場景中起到關鍵作用。隨著深度學習技術的發展,特別是像 Transformer 這樣的模型結構的出現,語言模型的能力得到了顯著提升。這一進展不僅推動了基礎研究,也極大地促進了產業的商業化應用。
評估語言模型的效能是一個複雜且多層次的問題。一方面,像困惑度、BLEU 分數和 ROUGE 分數這樣的傳統指標在某些情境下可能不足以反映模型的全面效能。另一方面,精確度、召回率、F1 分數和 AUC-ROC 等指標雖然在特定任務如文字分類、情感分析或命名實體識別(NER)等方面具有很強的針對性,但它們也不總是適用於所有場景。因此,在評估語言模型時,我們應該採取多維度、多角度的評估策略,綜合不同的評價指標來獲取更全面、更深入的理解。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。