線上SQL超時場景分析-MySQL超時之間隙鎖
前言
之前遇到過一個由MySQL間隙鎖引發線上sql執行超時的場景,記錄一下。
背景說明
分散式事務訊息表:業務上使用訊息表的方式,依賴本地事務,實現了一套分散式事務方案
訊息表名:mq_messages
資料量:3000多萬
索引:create_time 和 status
status:有兩個值,1 和 2, 其中99%以上的狀態都是2,表示分散式事務全部已經執行完成,可以刪除。
訊息表處理邏輯:
1. 啟動一個獨立的定時任務,刪除status=2的歷史資料,具體的sql如下:
delete from mq_messages where create_time<xxx and status=2 limit 200
2. 定時任務執行頻率:3分鐘跑一次任務,一個任務執行200次 刪除。這個條件基本上篩選出了90%以上的資料
業務邏輯:線上業務在執行時,不斷的往表裡插入status=1的資料,主鍵id隨著時間是遞增的
sql超時產生的場景
一次大型促銷活動流量峰值的時候,出現了一次資料庫連線被打滿的情況,初步定位是資料量太大了導致鎖表導致的。為了防止資料庫連線被再次打滿,需要儘快的刪除狀態為2的資料,手動執行定時任務,刪除資料,具體sql為:
delete from mq_messages where status=2 limit 2000
三分鐘執行一次任務,一個任務執行200次刪除。
然後,資料庫連線馬上被打滿,資料庫掛了。
覆盤分析
線上是否存在表鎖?
初始化表結構(簡化後的表結構)
CREATE TABLE `my_test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` int(11) NOT NULL,
`b` int(11) NOT NULL,
`state` int(11) NOT NULL DEFAULT '1',
PRIMARY KEY (`id`),
KEY `a` (`a`),
KEY `state` (`state`) USING BTREE
)
ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
儲存過程準備測試資料
DELIMITER $$
CREATE PROCEDURE pro_copy_date()
BEGIN
SET @i=1;
WHILE @i<=100000 DO
INSERT INTO my_test VALUES(@i,@i,@i,1);
SET @i=@i+1;
END WHILE;
END $$
call pro_copy_date();
UPDATE my_test SET state =2 WHERE id <= 99990;
驗證
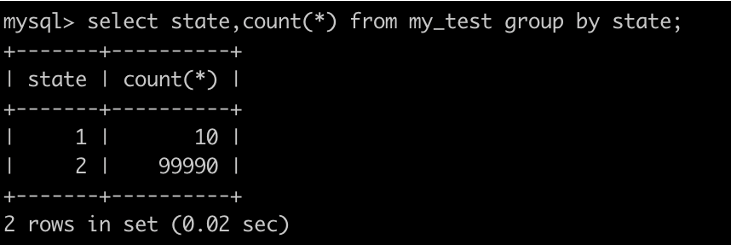
1. 資料基本情況
表中一共有10萬條資料,只有後10條的state=1(id>99990)
2. 事務隔離級別可重複讀
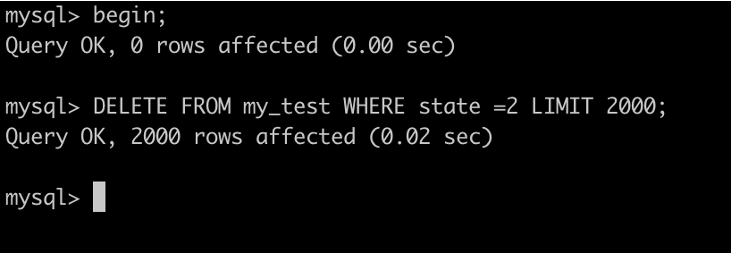
3. 開啟一個事務A,並且不提交
執行 DELETE FROM my_test WHERE state =2 LIMIT 2000;
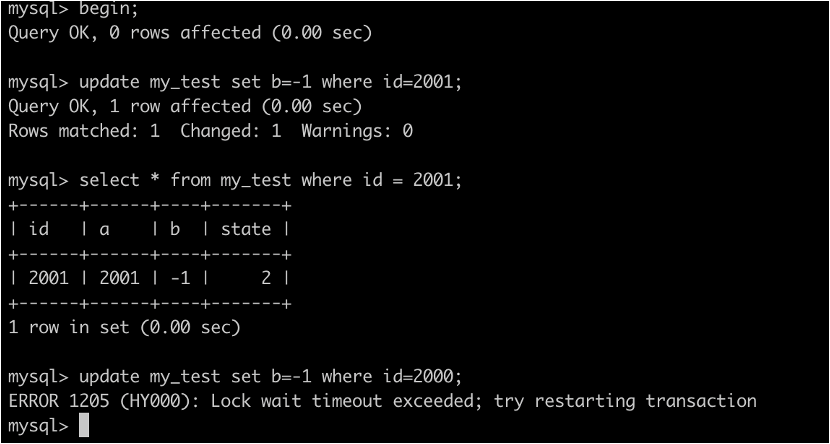
4. 開啟另一個事務B
• 更新id=2001的資料,可以更新成功
• 更新id=2000的資料,被阻塞
• 說明沒有表鎖
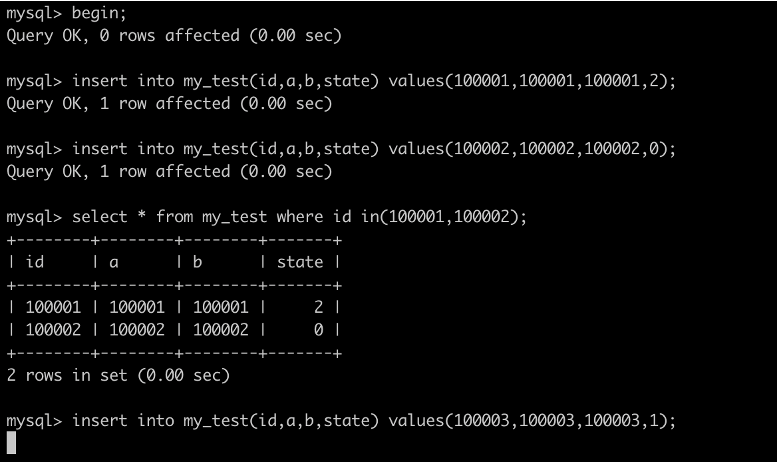
5. 開啟另一個事務C
• 插入狀態為2的資料,可以插入成功
• 插入狀態為0的資料,可以插入成功
• 插入狀態為1的資料,被阻塞
• 說明state的1和2的間隙被鎖導致不能插入
結論
線上不存在表鎖,而是間隙鎖。
間隙鎖
線上間隙鎖場景分析
表中state一共兩個值1和2。因此會產生三個間隙 (-∞, 1), (1, 2), (2, +∞) 和兩個孤值1和2。根據前開後閉原則,對應的臨建鎖區間為 (-∞, 1], (1, 2],(2, +∞)
執行DELETE FROM my_test WHERE state =2 LIMIT 2000時,掃描到的行數為(state=2, id=1)到(state=2,i d=2000)。state=2落在區間](1,2]。因此鎖住的範圍是(state=1,id=100000) 到 (state=2,id=2000),如圖所示:
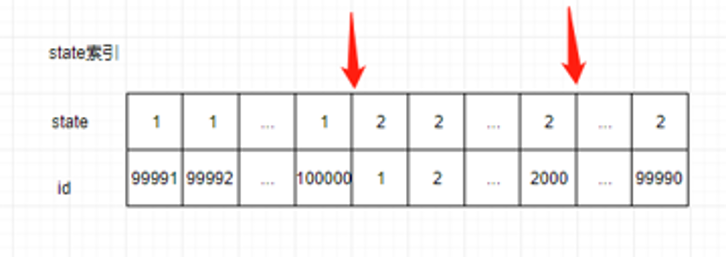
對於線上場景鎖的範圍是(state=1, id=status為1的最大id) 到 (state=2, id=要刪除的記錄中id的最大值)。由於線上只會插入state=1而且,id是遞增的。新插入的id是表的最大值,所以新插入的記錄一定會落在鎖區間,所以新插入的記錄都會被阻塞。
間隙鎖作用
解決幻讀
幻讀指的是一個事務在前後兩次查詢同一個範圍的時候,後一次查詢看到了前一次查詢沒有看到的資料行。
幻讀專門指的是新插入的資料。
在可重複讀隔離級別下,普通的查詢是快照讀,是不會看到別的事務插入的資料的。幻讀在「當前讀」下才會出現。innodb解決幻讀的方法,間隙鎖。
幻讀帶來的問題
新建測試表:
CREATE TABLE `my_test2` (
`id` INT (11) NOT NULL,
`b` INT (11) DEFAULT NULL,
`c` INT (11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE = INNODB;
-- 插入測試資料
NSERT INTO my_test2 VALUES(0, 0, 0),(5, 5, 5),(10, 10, 10),(15, 15, 15);
測試sql 1
begin;
select * from t where b=5 for update;
這個語句會命中 b=5 的這一行,對應的主鍵 id=5,因此在 select 語句執行完成後,id=5 這一行會加一個寫鎖,這個寫鎖會在執行 commit 語句的時候釋放。
由於欄位 b 上沒有索引,因此這條查詢語句會做全表掃描。那麼,其他被掃描到的不滿足條件的記錄上,會不會被加鎖呢?
假如只會在id為5的記錄上加鎖:
| 事務A | 事務B | 事務C | |
|---|---|---|---|
| T1 | BEGIN; SELECT * FROM my_test2 where b=5 FOR UPDATE; 結果(5,5,5) | ||
| T2 | UPDATE my_test2 SET b=5 WHERE id = 0; | ||
| T3 | SELECT * FROM my_test2 where b=5 FOR UPDATE; 結果(0,5,0)(5,5,5) | ||
| T4 | INSERT INTO my_test2(1,5,1) | ||
| T5 | SELECT * FROM my_test2 where b=5 FOR UPDATE; 結果(0,5,0)(1,5,1)(5,5,5) | ||
| T6 | commit |
| 事務A | 事務B | |
|---|---|---|
| T1 | BEGIN; SELECT * FROM my_test2 where b=5 FOR UPDATE; | |
| T2 | UPDATE my_test2 SET b=5 WHERE id = 0; UPDATE my_test2 SET c=5 WHERE id = 0; | |
| T3 | commit |
假如只會在id為5的記錄上加鎖,會破壞事務A的加鎖宣告,即「把所有 b=5 的行鎖住,不準別的事務進行讀寫操作」
| 事務A | 事務B | 事務C | |
|---|---|---|---|
| T1 | BEGIN; SELECT * FROM my_test2 WHERE b=5 FOR UPDATE; UPDATE my_test2 SET c=10 WHERE b=5; | ||
| T2 | UPDATE my_test2 SET b=5 WHERE id = 0; | ||
| T3 | INSERT INTO my_test2(1,5,1) | ||
| T4 | commit |
T1時刻: id=5的這行資料,的c的值改成了10,事務還沒提交,binlog還沒寫
T2時刻:id=0 這一行變成 (0,5,0), 變更寫入binlog;
T3時刻:id=1 這一行變成 (1,5,1), 變更寫入binlog;
T4時刻:事務A提交,寫入binlog。
此時主庫的資料為(0,5,0),(1,5,1),(5,5,10)
因此binlog寫入的紀錄檔為:
UPDATE my_test2 SET b=5 WHERE id = 0;
INSERT INTO my_test2(1,5,1)
UPDATE my_test2 SET c=10 WHERE b=5;
從庫執行完成binglog後資料就變成了(0,5,10),(1,5,10),(5,5,10),因此出現了資料的不一致
出現資料不一致的原因,是只鎖了那一刻需要變更的行,並不能阻擋現有資料變成b=5。
如果把掃描到的行全部加鎖會如何哪?由於b沒有索引,索引得掃描全表才知道那一行需要更新,所以表中的每一條記錄都會被鎖住。
| 事務A | 事務B | 事務C | |
|---|---|---|---|
| T1 | BEGIN; SELECT * FROM my_test2 where b=5 FOR UPDATE; UPDATE my_test2 SET c=10 WHERE b=5; | ||
| T2 | UPDATE my_test2 SET b=5 WHERE id = 0; (block) | ||
| T3 | INSERT INTO my_test2(1,5,1) | ||
| T4 | commit |
T1時刻: id=5的這行資料,的c的值改成了10,事務還沒提交,binlog還沒寫
T2時刻:id為0的行被鎖住,不能更新,等待鎖釋放;
T3時刻:id=1 這一行變成 (1,5,1), 變更寫入binlog;
T4時刻:事務A提交,寫入binlog。
T5時刻:事務A已提交,id=0的鎖被釋放,事務B更新成功,變成 (0,5,0),寫入binlog
此時主庫的資料為(0,5,0),(1,5,1),(5,5,10)
因此binlog寫入的紀錄檔為:
INSERT INTO my_test2(1,5,1)
UPDATE my_test2 SET c=10 WHERE b=5;
UPDATE my_test2 SET b=5 WHERE id = 0;
從庫執行完成binglog後資料就變成了(0,5,0),(1,5,10),(5,5,10),因此還是存在資料不一致
鎖定了查詢過程中掃描的行,有效的避免了修改帶來的資料不一致問題。資料之間的間隙插入的資料依然會出現b=5的資料,因此要向解決這個問題我們還需在資料的間隙加鎖。
| 事務A | 事務B | 事務C | |
|---|---|---|---|
| T1 | BEGIN; SELECT * FROM my_test2 b=5 FOR UPDATE; UPDATE my_test2 SET c=10 WHERE b=5; | ||
| T2 | UPDATE my_test2 SET b=5 WHERE id = 0; (block) | ||
| T3 | INSERT INTO my_test2(1,5,1) (block) | ||
| T4 | commit |
T1時刻: id=5的這行資料,的c的值改成了10,事務還沒提交,binlog還沒寫
T2時刻:id為0的行被鎖住,不能更新等待鎖釋放;
T3時刻:間隙(0,5)被鎖住,不能插入等待鎖釋放;
T4時刻:事務A提交,寫入binlog。
T5時刻:事務A已提交,id=0的鎖被釋放,事務B更新成功,變成 (0,5,0),寫入binlog
T6時刻:事務A已提交,(0,5)的間隙鎖被釋放,事務C寫入成功,變成 (1,5,1),寫入binlog
此時主庫的資料為(0,5,0),(1,5,1),(5,5,10)
因此binlog寫入的紀錄檔為:
UPDATE my_test2 SET c=10 WHERE b=5;
UPDATE my_test2 SET b=5 WHERE id = 0;
INSERT INTO my_test2(1,5,1)
從庫執行完成binglog後資料就變成了(0,5,0),(1,5,1),(5,5,10),完美解決了資料不一致
通過上面兩個情況分析,如果只鎖對應修改的行,會出現兩個問題
1. 破壞加鎖宣告
2. 資料的不一致性
幻讀的解決方法
通過上面案例分析,即使把所有的記錄都加上鎖,還是阻止不了新插入的記錄。行鎖只能鎖住行,但是新插入記錄這個動作,要更新的是記錄之間的「間隙」。因此,為了解決幻讀問題,InnoDB 只好引入新的鎖,也就是間隙鎖 (Gap Lock)。
間隙鎖,鎖的就是兩個值之間的空隙,表中一共有4條資料,因此會產生五個間隙 (-∞, 0), (0, 5), (5, 10), (10, 15), (15, +∞),在掃描確認要修改的行時,不僅僅要鎖住掃描到的行,兩邊的間隙也要加上鎖。
間隙鎖和行鎖合稱 next-key lock(鄰鍵鎖),每個 next-key lock 是前開後閉區間。因此上述情況會有五個鄰鍵鎖(-∞,0],(0,5],(5,10],(10,15],(15, +∞)
間隙鎖可以被多個事務同時加
間隙鎖和行鎖有區別,行鎖只能被一個事務加上,但是間隙鎖可以被多個事務加上。
如下圖:開啟兩個事務,
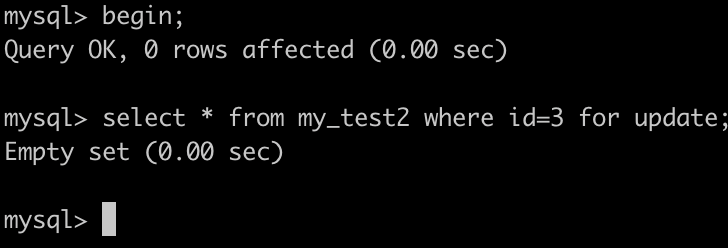

1. 事務A執行:SELECT * FROM my_test2 WHERE id=2 for UPDATE; 會鎖住(0,5)這個間隙。
2. 事務B執行SELECT * FROM my_test2 WHERE id=3 for UPDATE;,同樣也會鎖住(0,5)這個間隙,而且可以成功。
間隙鎖的目前是保護這個間隙不能插入資料,但他們不衝突。
加鎖規則
原則1:加鎖的基本單位是 next-key lock,next-key lock 是前開後閉區間。
原則2:查詢過程中存取到的物件才會加鎖。
優化1:索引上的等值查詢,給唯一索引加鎖的時候,next-key lock 退化為行鎖。
優化2:索引上的等值查詢,向右遍歷時且最後一個值不滿足等值條件的時候,next-key lock 退化為間隙鎖。
唯一索引上的範圍查詢會存取到不滿足條件的第一個值為止
加鎖規則—等值查詢間隙鎖
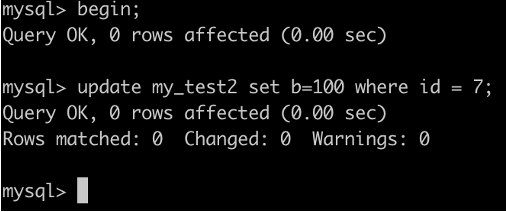
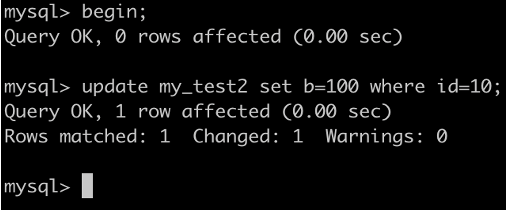
事務A執行UPDATE my_test2 SET b=100 WHERE id =7;
根據原則1,加鎖的區間應該為(5,10].
根據優化2,這是一個等值查詢 ,而 id=10 不滿足查詢條件,next-key lock 退化成間隙鎖,因此最終加鎖的範圍是 (5,10)。
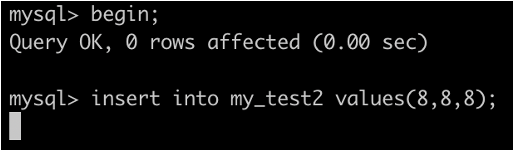
因此:事務B的插入會被阻塞,事務C的更新可以成功
事務A:
事務B:
事務C:
加鎖規則—非唯一索引等值查詢
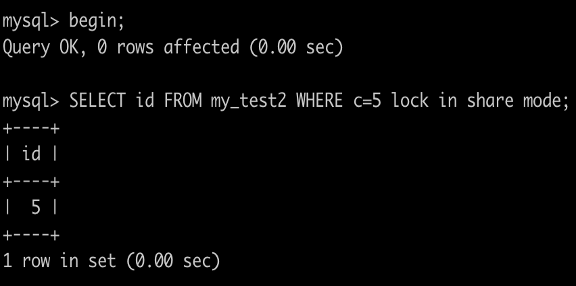
事務A執行SELECT id FROM my_test2 WHERE c=5 lock in share mode``;
根據原則1,加鎖的區間應該為(0,5],由於c不是唯一索引還得往後掃描,因此(5,10]也會被加鎖。根據優化2,會退化成(5,10)。因此索引c上的鎖區間為(0,10)。
由於這個查詢走的是索引覆蓋,並不需要去主鍵索引查資料,因此id=5的行並不會被鎖住 。
所以更新會成功,插入不會成功
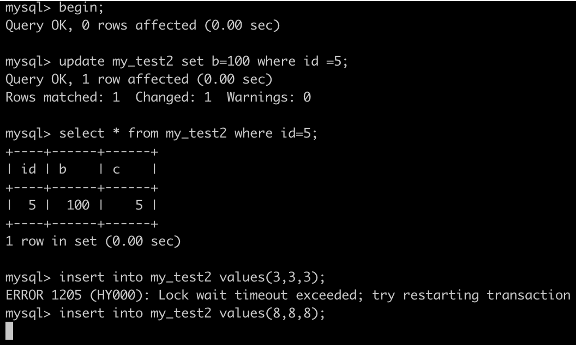
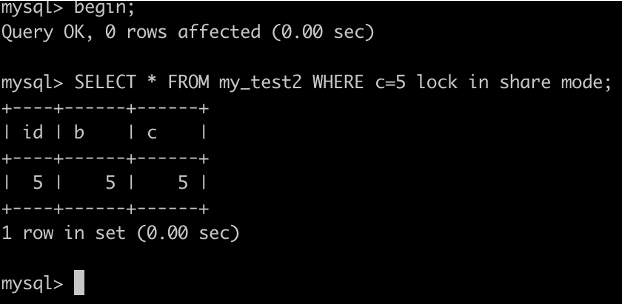
事務A執行SELECT * FROM my_test2 WHERE c=5 lock in share mode;
由於 查詢全部的資料就需要,去主鍵索引上查詢id=5的資料,根據原則2,id=5的這行資料也要被鎖住,因此更新會被阻塞。
注意,如果執行的語句為SELECT id FROM my_test2 WHERE c=5 for UPDATE;雖然這個語句也會走索引覆蓋,但是用for update mysql會認為你接下來要更新這行,因此順便會給id=5的這行加鎖。
加鎖規則—非唯一索引,存在等值
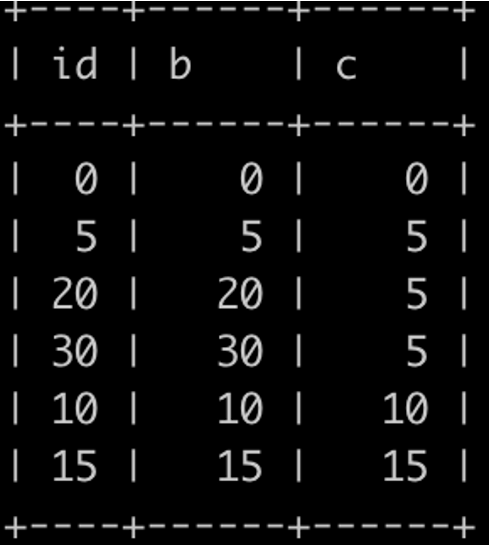
新插入兩條數資料(20,20,5)和(30,30,5)
執行sql: DELETE FROM my_test2 WHERE c=5 LIMIT 2;
根據加鎖原則,只會掃描c=5的資料,因此加鎖區間為
(c=0,id=0) 到 (c=5,id=20)
INSERT INTO my_test2 VALUES(-1,0,0); //不阻塞
INSERT INTO my_test2 VALUES(1,0,0); //阻塞
INSERT INTO my_test2 VALUES(19,0,5); //阻塞
INSERT INTO my_test2 VALUES(21,0,5); //不阻塞
執行結果驗證:
資料庫底層實現博大精深,本文所述,根據線上場景進行了一些研究和探討,希望能為相關場景提供一些啟示。文章中難免會有不足之處,希望讀者能給予寶貴的意見和建議。謝謝!
作者:京東物流 劉浩
來源:京東雲開發者社群 自猿其說Tech 轉載請註明來源