深入探索智慧問答:從檢索到生成的技術之旅
在本文中,我們深入探討了自然語言處理中的智慧問答系統,從其發展歷程、主要型別到不同的技術實現。文章詳細解析了從基於檢索、對話到基於生成的問答系統,展示了其工作原理和具體實現。通過對技術和應用的深度剖析,旨在幫助讀者對這一令人興奮的領域有更全面的認識。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。

一、智慧問答概述
智慧問答 (Intelligent Question Answering, IQA) 是自然語言處理(NLP)中的一個核心子領域,旨在設計和開發可以解析、理解並回答使用者提出的自然語言問題的系統。這些系統的目標不僅僅是返回與問題相關的文字,而是提供精確、凝練且直接的答案。

1. 語意理解
智慧問答系統的核心元件之一是語意理解,即系統需要深入地理解使用者提問的意圖和背後的意義。
例子:當用戶問:「金星是太陽系的第幾顆行星?」而不是簡單地返回與「金星」和「太陽系」相關的一段文字,系統應理解使用者的真正意圖並回答:「金星是太陽系的第二顆行星。」
2. 知識庫和資料庫
為了回答問題,智慧問答系統通常需要存取大型的知識庫或資料庫,這些知識庫包含了大量的事實、資料和資訊。
例子:當用戶詢問:「蘋果公司的創始人是誰?」系統會查詢其知識庫,並返回:「蘋果公司的創始人是史蒂夫·喬布斯、史蒂夫·沃茲尼亞克和羅納德·韋恩。」
3. 上下文感知
高階的智慧問答系統可以感知上下文,這意味著它們可以根據前面的對話或提問為使用者提供更相關的答案。
例子:如果使用者首先問:「巴黎位於哪個國家?」得到答案後,又問:「那裡的官方語言是什麼?」系統應該能夠識別出「那裡」指的是「巴黎」,並回答:「官方語言是法語。」
4. 動態學習和自適應
隨著時間的推移,優秀的智慧問答系統能夠從使用者的互動中學習,並改進其回答策略和準確性。
例子:如果一個系統頻繁地收到關於某一新聞事件的問題,並且使用者對其回答表示滿意,系統應該能夠識別這一事件的重要性,並在未來的查詢中更加重視與之相關的資訊。
二、發展歷程

智慧問答的歷史是自然語言處理和電腦科學發展史的一個縮影。從最初的基於規則的系統到現在的深度學習模型,它不斷地推動技術界前進,試圖更好地理解和迴應人類語言。
1. 基於規則的系統
在20世紀60、70年代,早期的問答系統主要依賴於寫死的規則和固定的模式匹配。這些系統是基於人類定義的明確規則來識別問題並提供答案。
例子:一個基於規則的系統可能有一個簡單的查詢表,當用戶詢問「日本的首都是什麼?」時,它會匹配「首都」和「日本」的關鍵詞,然後返回儲存的答案「東京」。
2. 統計方法的興起
隨著巨量資料和計算能力的增長,90年代和21世紀初,研究人員開始使用統計方法來改進問答系統。這些方法通常基於從大量文字中提取的概率來預測答案。
例子:當用戶詢問「誰寫了《哈利·波特》?」系統會搜尋大量的檔案,統計與「哈利·波特」和「作者」相關的句子,最後確定「J.K.羅琳」是最可能的答案。
3. 深度學習和神經網路的突破
近十年來,隨著深度學習技術的突破,問答系統得到了質的飛躍。神經網路,尤其是迴圈神經網路(RNN)和Transformer架構,使得模型可以處理複雜的語意結構和長距離依賴。
例子:BERT模型可以處理複雜的問題,如:「《安徒生童話》中描述的‘皇帝的新裝’的寓意是什麼?」BERT可以深入分析文字內容,識別出該故事是關於虛榮和盲目從眾的。
4. 預訓練模型
近年來,預訓練模型如GPT-4、GPT-3.5、T5和XLNet等,已經在各種NLP任務上取得了前所未有的成果。這些模型首先在大量文字上進行預訓練,然後可以通過遷移學習快速地適應特定的任務,如智慧問答。
例子:使用GPT-4,當用戶提出抽象問題,如:「人生的意義是什麼?」GPT-3可以返回哲學、文學和各種文化背景下的多個觀點,提供深入而全面的回答。
三、智慧問答系統的主要型別

智慧問答系統因應用場景、資料來源和技術手段的不同而存在多種型別。以下是其中的一些主要型別及其特點:
-
基於知識庫的問答系統:
-
依賴預定義的知識庫來檢索答案。
-
需要大量的知識工程師來維護和更新知識庫。
-
在特定領域(如醫學、法律)中表現較好,因為它們可以提供準確的、基於事實的答案。
例子:醫學問答系統可能有一個知識庫,其中包含各種疾病、症狀和治療方法的資訊。
-
-
基於檢索的問答系統:
-
從大量文字資料中檢索與問題相關的片段。
-
依賴高效的資訊檢索技術。
-
能夠處理開放領域的問題,但答案的準確性可能受限於資料來源的質量。
例子:當用戶詢問某個歷史事件的詳細情況時,系統會從網際網路上檢索相關文章或百科全書來提供答案。
-
-
基於對話的問答系統:
-
與使用者進行多輪對話,以便更好地理解其問題。
-
可以處理複雜和上下文依賴的問題。
-
通常依賴深度學習和上下文感知的模型。
例子:當用戶問:「你知道巴黎嗎?」系統回答:「當然,你想知道巴黎的哪方面資訊?」使用者繼續:「它的歷史建築。」系統再進行具體的答覆。
-
-
基於生成的問答系統:
-
不是從固定的資料來源檢索答案,而是實時生成答案。
-
通常使用神經網路,如序列到序列模型。
-
可以提供個性化和創造性的答案,但可能缺乏事實上的準確性。
例子:當用戶詢問:「如果莎士比亞是現代人,他會怎麼評價智慧手機?」系統可能生成一個富有創意的答案,儘管這不是基於真實事實的答案。
-
四、基於知識庫的問答系統

基於知識庫的問答系統是一種專為解答基於事實和資料的問題而設計的系統。它們依賴於預定義的知識庫,這些知識庫通常包含大量的事實、關係和其他結構化資訊。
定義:基於知識庫的問答系統主要依賴於一個結構化的知識庫,將使用者的問題對映到知識庫中的相關實體和關係,從而找到或生成答案。
例子:考慮一個知識庫,其中包含關於國家、首都和地理位置的資訊。對於問題「巴西的首都是什麼?」,系統查詢知識庫並返回「巴西利亞」。
一個簡單的基於知識庫的問答系統實現如下:
# 定義簡單的知識庫
knowledge_base = {
'巴西': {'首都': '巴西利亞', '語言': '葡萄牙語'},
'法國': {'首都': '巴黎', '語言': '法語'},
# 更多的條目...
}
def knowledge_base_qa_system(question):
# 簡單的字串解析來提取實體和屬性(真實系統會使用更復雜的NLP技術)
for country, attributes in knowledge_base.items():
if country in question:
for attribute, answer in attributes.items():
if attribute in question:
return answer
return "我不知道答案。"
# 測試問答系統
question = "巴西的首都是什麼?"
print(knowledge_base_qa_system(question)) # 輸出:巴西利亞
在這個簡單範例中,我們定義了一個知識庫,其中包含一些國家及其屬性(如首都和官方語言)。問答系統通過簡單地解析問題字串來查詢知識庫並找到答案。實際上,真實的基於知識庫的問答系統會使用更復雜的自然語言處理和知識圖譜查詢技術來解析問題和查詢答案。
五、基於檢索的問答系統
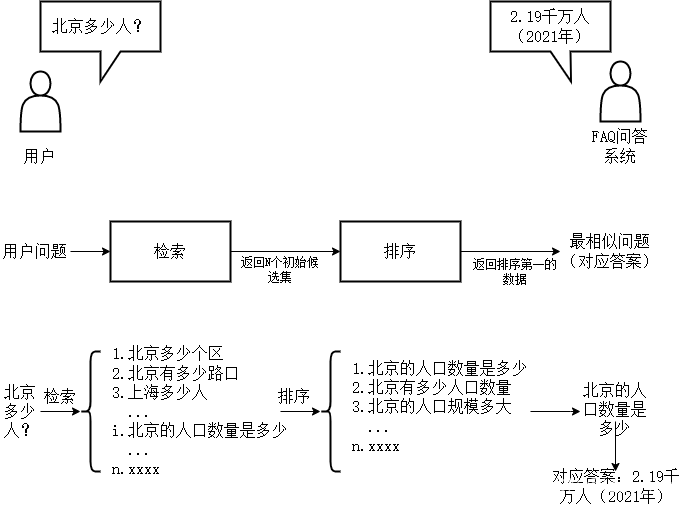
基於檢索的問答系統是指根據使用者問題的語意資訊,從一個預先存在的大型檔案或FAQ集中檢索並返回最相關的答案。與基於知識庫的問答系統不同,基於檢索的系統不依賴於結構化資料,而是依賴於大量的文字資料。
定義:基於檢索的問答系統使用語意搜尋技術,對使用者的問題和資料集中的問題進行比較,從而找到最匹配的答案。
例子:在一個包含醫學文獻的資料集中,對於問題「怎樣預防流感?」,系統可能會返回一個相關醫學研究中的段落,如「接種流感疫苗是預防流感的最有效方法。」
下面是一個簡單的基於檢索的問答系統的實現:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 定義一個簡單的檔案集合
documents = [
"接種流感疫苗是預防流感的最有效方法。",
"貓是可愛的寵物。",
"巴黎是法國的首都。",
# 更多檔案...
]
vectorizer = TfidfVectorizer()
document_vectors = vectorizer.fit_transform(documents)
def retrieval_based_qa_system(question):
question_vector = vectorizer.transform([question])
similarities = cosine_similarity(question_vector, document_vectors)
best_match = documents[similarities.argmax()]
return best_match
# 測試問答系統
question = "如何避免得流感?"
print(retrieval_based_qa_system(question)) # 輸出:接種流感疫苗是預防流感的最有效方法。
在這個簡化的範例中,我們首先使用TF-IDF方法將檔案轉換為向量。當接收到一個問題時,我們同樣將其轉換為向量並使用餘弦相似度來確定哪個檔案與問題最為相似。然後返回最匹配的檔案作為答案。
實際應用中,基於檢索的問答系統可能會採用更復雜的深度學習模型、BERT等預訓練模型來提高檢索的準確性。
六、基於對話的問答系統
基於對話的問答系統不僅僅回答單一的問題,而是能與使用者進行持續的互動,理解並維護對話上下文,從而為使用者提供更加準確和個性化的答案。
定義:基於對話的問答系統是一種可以處理多輪對話、維護和利用對話上下文的系統,從而在與使用者互動時提供更有深度和持續性的回答。
例子:使用者可能會問:「推薦一部好看的電影。」系統回答:「你喜歡哪種型別的電影?」使用者回答:「我喜歡科幻。」系統隨後推薦:「那你可能會喜歡《星際穿越》。」
以下是一個簡單的基於對話的問答系統的實現:
import random
# 對話上下文和推薦資料
context = {
'genre': None
}
recommendations = {
'科幻': ['星際穿越', '銀河系漫遊指南', '阿凡達'],
'愛情': ['泰坦尼克號', '愛情公寓', '羅馬假日'],
# 更多類別...
}
def dialog_based_qa_system(question):
if "推薦" in question and "電影" in question:
return "你喜歡哪種型別的電影?", context
if context.get('genre') is None:
for genre, movies in recommendations.items():
if genre in question:
context['genre'] = genre
return f"那你可能會喜歡{random.choice(movies)}。", context
return "對不起,我不確定如何回答。", context
# 測試問答系統
question1 = "推薦一部好看的電影。"
response1, updated_context = dialog_based_qa_system(question1)
print(response1) # 輸出:你喜歡哪種型別的電影?
question2 = "我喜歡科幻。"
response2, updated_context = dialog_based_qa_system(question2)
print(response2) # 輸出:那你可能會喜歡星際穿越。
這是一個非常簡化的例子。在這裡,我們使用一個簡單的上下文字典來跟蹤對話中的狀態。實際應用中,基於對話的問答系統可能會使用RNN、Transformer或其他深度學習架構來維護和利用對話上下文。此外,更高階的系統還可能包括情感分析、個性化推薦等特性。
七、基於生成的問答系統

與基於檢索或對話的問答系統不同,基於生成的問答系統的目標是生成全新的答案文字,而不是從預先定義的答案集或檔案中選擇答案。這些系統通常使用深度學習模型,特別是序列到序列(seq2seq)模型。
定義:基於生成的問答系統使用深度學習技術(如RNN、LSTM或Transformer)從頭開始生成答案,而不是從現有檔案或資料庫中檢索答案。
例子:當問到「太陽是什麼?」時,系統可能會生成答案「太陽是一個主序星,位於我們的太陽系中心,它通過核聚變產生能量。」
下面是一個簡化的基於PyTorch的生成問答系統的範例:
import torch
import torch.nn as nn
import torch.optim as optim
# 假設我們有一個預訓練的seq2seq模型
class Seq2SeqModel(nn.Module):
def __init__(self):
super(Seq2SeqModel, self).__init__()
# ... 模型定義(如編碼器、解碼器等)
def forward(self, input):
# ... 前向傳播
pass
model = Seq2SeqModel()
model.load_state_dict(torch.load("pretrained_seq2seq_model.pth"))
model.eval()
def generate_based_qa_system(question):
question_tensor = torch.tensor(question) # 將問題轉化為張量
with torch.no_grad():
generated_answer = model(question_tensor)
return generated_answer
# 測試問答系統
question = "太陽是什麼?"
print(generate_based_qa_system(question))
這只是一個高階的框架,實際的生成問答系統會涉及許多其他複雜性,包括詞嵌入、注意機制、解碼策略等。實際的seq2seq模型實現也要複雜得多。使用如BERT、GPT-2或T5等預訓練模型可以進一步提高生成問答系統的效能。
八、總結
經過深入的探索和技術解析,我們對自然語言處理中的智慧問答系統有了更加深入的瞭解。從簡單的基於檢索的問答系統,到能與使用者進行復雜多輪對話的對話系統,再到具備生成全新答案能力的生成式問答系統,我們目睹了問答技術的迅猛發展和應用廣泛性。
然而,背後的技術進步並不僅僅是演演算法的改進或計算能力的增強。關鍵在於,隨著大量資料的積累和開放,我們的機器學習模型得以在更加真實和多樣的資料上進行訓練。這也反映了一個核心原則:真實世界的多樣性和複雜性是無法通過簡單規則來完全捕獲的。只有當我們的模型能夠在真實的、多樣的資料上進行學習,它們才能更好地為我們服務。
但我們也需要意識到,無論技術如何進步,真正的挑戰並非僅僅在於如何構建一個更高效或更準確的問答系統。更為根本的挑戰在於,如何確保我們的技術在為人類提供幫助的同時,也能夠尊重使用者的隱私、確保資訊的真實性並避免偏見。在AI的發展中,技術和倫理應該並行發展。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。