談談壓測方案的那點事 | 京東物流技術團隊
前言
在現階段大促備戰的壓測不算是一件新鮮事,已經不存在什麼技術瓶頸或者資源問題,每個團隊都有很多人能夠執行效能測試,在一些團隊也已經落地了日常常態化,但壓測也沒有簡單到只在壓測平臺上設定引數、執行指令碼,然後去看壓測報告中某個指標是否滿足壓測目標那麼簡單,我平時也跟一些同學一起做過效能測試,發現在壓測過程中存在一些細節問題,有些同學做但不是很理解,壓測方案對於效能測試來說是尤為重要一環,今天把對於壓測方案方面的一些理解跟大家一起探討一下;
效能測試的本質是模擬生產環境的使用者,構造使用者真實的行為請求,對儘量真實的壓測系統施加壓力,驗證系統效能是否滿足業務需要,是否存在效能瓶頸;
從裡面可以看出核心的幾個點:壓測目標、壓測場景、壓測環境,今天主要從三大塊來說
一、壓測目標
我們在制定壓測方案去說起壓測目標的時候,很多同學都直接的考慮到TPS、QPS、TP99這些,
忽略了很重要的一項內容就是壓測背景,就是因為什麼原因我們要做這次壓測,壓測背景是我們壓測的的方向,如果方向錯了就會導致我們費時費力壓測完成之後,壓測的結論是沒有意義的
那麼壓測背景和壓測目標的關係是啥呢?
說一下我們現在常見的幾種壓測背景:
1、大促期間呼叫量對比平常明顯有增長的業務
目標:是否能夠支承大促預估峰值流量(業務預估+業務增長+大促增長)+單機房承載量+ 介面能支撐多大的呼叫量
結論:xxx設定最優/最大吞吐量xxx,能夠支撐本次大促預估峰值呼叫量xxxx,是否存在風險;
2、上次大促壓測過,但是之後新增/修改過的內容
目標:介面效能是否有變化+是否能夠支撐大促預估峰值流量+介面能支撐多大的呼叫量
3、新增的介面,沒有壓測過,有業務預估呼叫量
目標:介面是否能夠滿足業務預估呼叫量(極限)+ 正常
4、新增的介面,沒有壓測過,沒有業務預估呼叫量
目標:介面效能評估,系統效能是否存在瓶頸?有無優化空間?
5、新增的介面替換老介面
目標:介面效能評估,是否能夠滿足老介面的業務呼叫量+新增業務呼叫量
6、老介面的效能優化
目標:對比優化前優化後的效能指標,是否有優化效果
7、大促期間峰值呼叫量相比日常呼叫量沒有明顯變化,但是高峰時間拉長的業務
目標:峰值流量穩定性壓測
8、沒有太大的呼叫量,但是使用者對於使用者體驗要求比較高
目標:介面響應時間是否有感官上的延遲,關注TP99,是否需要優化
9、不知道系統是否需要擴容
目標:極限壓測,應用伺服器和資料庫資源使用情況是否合理
10、已知鏈路、介面效能比較慢,我需要知道瓶頸在那裡
目標:找到鏈路、介面體系上的薄弱點(可優化內容)

二、壓測場景
業務模型的調研和構建是我們壓測前期工作中最為核心的一個環節,業務模型的建立要以實際生產環境系統業務操作模式為依據,只有模型符合實際的生產業務使用模式,效能測試的結果才能真實有效的反應上線後系統的效能情況,業務建模好壞直接決定效能測試執行的成功與否,也就是我們所說的壓測模型
業務建模的過程中要分析清楚三件事情:
1、產生流量場景有哪些?如何選擇需要壓測的場景?
2、各場景和交易之間流量如何分配和設計?
3、要達成測試目標需要構造鋪地資料需要多大的量,這些鋪地資料該如何分配和部署;另外需要業務模型設計資料,資料要如何分配和構造
其實要做的就是在瞭解清楚業務並在其基礎上完成:業務模型、流量模型及資料模型。
1、業務模型
一般從業務運營視角、技術運營視角、線上問題分析以及測試經驗四個維度進行收集、整理和提煉:
業務運營:從實際業務應用的角度收集使用者實際的使用情況和業務增長的趨勢,比如我們有幾個業務呼叫來源,平時使用者使用最多的場景是那些,使用者操作的高峰時段是什麼時候?
技術運營:從技術運營角度去梳理我們介面實現邏輯的呼叫鏈路,比如說排程工作臺線路展開查詢,線路下任務低於20條的會去調異常介面,高於20條的不調異常介面;比如說查詢介面實現的方式,走快取還是走資料庫;
線上問題:根據使用者反饋和線上問題的收集,結合線上問題修復的方式;比如說一線反饋xxx操作會感知響應比較慢,研發在優化這個的時候會覆蓋哪些使用者操作場景
測試經驗:根據測試經驗來完善業務模型
2、流量模型
在業務場景確定後,就要思考各個場景和交易之間流量如何分配?。
生產環境的使用者操作場景比較複雜的,請求報文的大小和請求路徑也各不一樣,使用單一的請求報文進行壓測是不合理的,在流量模型分析的過程中有兩種思考方式。即使用者行為模型和系統業務模型。
使用者行為模型:通過描述高峰時期使用者行為特點,通過對使用者行為調研分析,歸納總結出使用者行為模型。比較常見的就是現在的流量錄製,在業務高峰時間錄製業務流量,然後進行流量回放,優點是實現起來比較簡單,缺點是錄製的流量使用者行為較難統計分析。
系統業務模型:根據高峰時期系統業務特點,通過系統紀錄檔、資料埋點等方式獲取高峰時段系統業務流量,獲悉使用者的主要流量行為,然後通過自己編寫指令碼和設定流量佔比的方式來實現,優點是使用者的流量佔比比較清晰,缺點是要有資料的人工歸類分析過程
3、資料模型
設計完成業務模型和流量模型,還要清楚需要多少基礎資料(也叫鋪地資料),鋪底資料目的是測試時儘可能的與線上保持一致(至少數量分佈一致),不管是哪類資料庫,對於不同體量的資料,所走的查詢器選擇都是不一樣的。幾百行的資料走全表掃描肯定比走索引要好,但如果是幾百萬行呢?這方便需要我們具體地做評估。一般來說資料量要按照實際生產環境的資料量為多少為基礎,在效能測試環境做等量代換。
總結:多少使用者(WHO)在什麼時間或者持續多長多久(When),在多大的資料量的基礎上(How much),完成了什麼業務(What),最終需要關注怎樣的指標(How)。
舉例:
單介面壓測(呼叫方式不同):
1、預設頁面開啟自動查詢,查詢每頁預設20條記錄,也是最大的使用者形式
2、通過介面呼叫,介面每頁最大返回條數是1000條
單介面快取壓測:
- 走快取 10分鐘
- 不走快取 10分鐘
- 部分命中快取,部分未命中快取,10分鐘經歷5分鐘快取失效
單介面混合場景壓測:
排程工作臺-分頁查詢使用者許可權內線路,不同的使用者行為
1、1天1個區域查詢量
2、1天7個區域查詢量
3、混合場景(7天1個區域10%,1天7個區域20%,1天1個區域70%)三種
單應用多介面混合壓測:
根據呼叫量進行介面呼叫配比
單業務介面混合壓測:
適用場景:
運營指標看板(鏈路大屏頁面,常用使用者大概在150人左右),在使用者存取大屏的同時呼叫五個介面方法:
使用者初始進入頁面後,預設無查詢條件呼叫5個介面
使用者在此頁面停留,每隔30s自動重新整理頁面內容呼叫5個介面
使用者手動錄入查詢條件,點選查詢自動執行查詢操作呼叫5個介面
極限壓測:
【618備戰壓測-執行核心流程極限壓測】測試方案
雙範例線性增長驗證
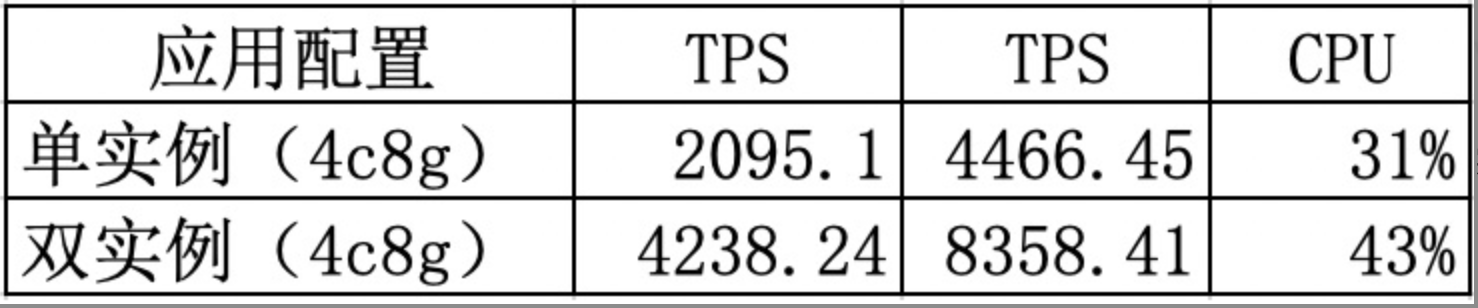
全鏈路壓測:
【備戰618效能測試-運輸ORC接單】效能測試報告
系統穩定性壓測
滿足業務需求後,持續加壓一段時間(4-6)驗證系統穩定性
三、壓測環境
1、優先考慮線上環境
2、壓測環境與生產環境吞吐量差異,單範例壓測和雙範例壓測怎麼選擇
3、壓測環境與生產環境差異
4、鋪底資料量壓測環境與生產環境差異
作者:京東物流 朱飛
來源:京東雲開發者社群 自猿其說Tech 轉載請註明來源