Java實現兩字串相似度演演算法
2023-11-10 12:00:12
1、編輯距離
編輯距離:是衡量兩個字串之間差異的度量,它表示將一個字串轉換為另一個字串所需的最少編輯操作次數(插入、刪除、替換)。
2、相似度
計算方法可以有多種,其中一種常見的方法是將編輯距離歸一化為0到1之間的範圍(歸一化編輯距離(Normalized Edit Distance)),將編輯距離除以較長字串的長度。這樣可以將相似度表示為一個百分比,其中0表示完全不相似,1表示完全相似。
請注意,這種歸一化方法並不是唯一的,也不適用於所有情況。在實際應用中,你可以根據具體需求選擇適合的相似度計算方法。例如,Jaro-Winkler相似度演演算法和Cosine相似度演演算法等都是常用的字串相似度計算方法,它們不一定使用編輯距離作為基礎。
3、相似度分類、測試
- 歸一化編輯距離(Normalized Edit Distance)
- Jaro-Winkler相似度
- 餘弦相似度(Cosine Similarity)
3.1、歸一化編輯距離(Normalized Edit Distance)
-
解釋:常用的,將編輯距離歸一化為0到1之間的範圍
-
使用、測試
String str1 = "h1e2l3l4o";
String str2 = "ddddhello";
//歸一化編輯距離
@Test
void contextLoads() {
// commons-text 包:根據編輯距離計算:相似度
int editDistance = LevenshteinDistance.getDefaultInstance().apply(str1, str2);
double similarity = 1 - ((double) editDistance / Math.max(str1.length(), str2.length()));
System.out.println("commons-text 包:Edit Distance: " + editDistance);
System.out.println("commons-text 包:Similarity: " + similarity);
}
- 結果

3.1.1、資料庫Oracle/DM實現的歸一化編輯距離
-- oracle/dm實現的歸一化編輯距離
SELECT UTL_MATCH.edit_distance_similarity ('h1e2l3l4o', 'ddddhello') AS similarity
- 結果
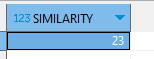
3.2、Jaro-Winkler相似度
-
解釋:我也看不懂,自行取用:https://www.jianshu.com/p/a4af202cb702
-
使用、測試
String str1 = "h1e2l3l4o";
String str2 = "ddddhello";
//Jaro-Winkler相似度
@Test
public void test03()throws Exception{
JaroWinklerSimilarity js = new JaroWinklerSimilarity();
System.out.println("Jaro-Winkler相似度: " + js.apply(str1, str2));
}
- 結果

3.2.1、oracle/dm實現的:Jaro-Winkler相似度演演算法
- 和Java中的一模一樣
-- oracle/dm實現的:Jaro-Winkler相似度演演算法
SELECT UTL_MATCH.JARO_WINKLER_SIMILARITY('h1e2l3l4o', 'ddddhello') AS JaroWinkler相似度;

3.3、餘弦相似度(Cosine Similarity)
- 解釋:我也看不懂,自行取用
餘弦相似度(Cosine Similarity)是通過計算兩個向量之間的夾角來衡量它們的相似度。在這種情況下,我們可以將字串視為向量,其中每個字元對應一個維度。
對於左邊字串"h1e2l3l4o"和右邊字串"hello",我們可以將它們表示為以下向量:
左邊字串向量:[1, 2, 3, 4, 5]
右邊字串向量:[1, 1, 1, 1, 1]
為了計算餘弦相似度,我們需要計算這兩個向量的點積和它們的模長。點積表示兩個向量之間的相似程度,模長表示向量的長度。
左邊字串向量的模長:sqrt(1^2 + 2^2 + 3^2 + 4^2 + 5^2) = sqrt(55)
右邊字串向量的模長:sqrt(1^2 + 1^2 + 1^2 + 1^2 + 1^2) = sqrt(5)
左邊字串向量和右邊字串向量的點積:11 + 21 + 31 + 41 + 51 = 1 + 2 + 3 + 4 + 5 = 15
根據餘弦相似度的公式,餘弦相似度可以計算為點積除以兩個向量的模長的乘積:
餘弦相似度 = 點積 / (左邊字串向量的模長 右邊字串向量的模長)
= 15 / (sqrt(55) sqrt(5))
≈ 0.745
因此,左邊字串"h1e2l3l4o"和右邊字串"hello"的餘弦相似度約為0.745。
- 測試、使用
String str1 = "h1e2l3l4o";
String str2 = "ddddhello";
//餘弦相似度
@Test
public void test02()throws Exception{
// commons-text 包
// 使用Cosine計算兩個字串的餘弦距離
CosineDistance cd = new CosineDistance();
Double apply = cd.apply(str2, str1);
System.out.println("Cosine相似度:" + apply);
}
- 結果:不知道對不對

4、總結
- 上述三種的簡單介紹:
- 其他相似度
1. 編輯距離(Edit Distance):衡量兩個字串之間的差異,通過計算插入、刪除和替換操作的最小次數來確定相似度。
2. Hamming距離(Hamming Distance):用於比較兩個等長字串之間的差異,計算在相同位置上不同字元的數量。
3. Damerau-Levenshtein距離:類似於編輯距離,但允許交換相鄰字元的操作。
4. Jaccard相似度(Jaccard Similarity):用於比較集合之間的相似度,計算兩個集合的交集與並集的比值。
5. Sørensen-Dice相似度:類似於Jaccard相似度,但計算兩個集合的兩倍交集與兩個集合的元素總數之和的比值。
6. Smith-Waterman演演算法:用於比較兩個字串之間的相似性,主要用於序列比對和字串匹配。
7. Longest Common Subsequence(LCS):計算兩個字串之間最長公共子序列的長度,用於衡量字串的相似性。
8. N-gram相似度:將字串分割為連續的N個字元片段,比較兩個字串之間的N-gram的相似性。
9. Cosine相似度(餘弦相似度):用於比較兩個向量之間的夾角,常用於文字相似度計算。
- 都是使用:Apache Commons Text:1.11.0包
// 實現字串相似度演演算法的包
implementation 'org.apache.commons:commons-text:1.11.0'
