每天5分鐘複習OpenStack(九)儲存發展史

上一章節我們介紹了使用本地硬碟做kvm的儲存池,這章開始將介紹下儲存的發展歷程,並介紹什麼是分散式儲存,為什麼HDFS為有中心節點的分散式儲存?
1、儲存發展
- 在單機計算時代(大型電腦、小型機、微機),內部記憶體可以理解為記憶體(即Memory),外部記憶體可以理解為物理硬碟(包括本地硬碟和通過網路對映的邏輯卷.
外部儲存根據連線方式不同,又可以分為DAS(Direct-attached Storage)直連儲存或直接附加儲存。網路化儲存 Fabric-Attached Storage,簡稱FAS);
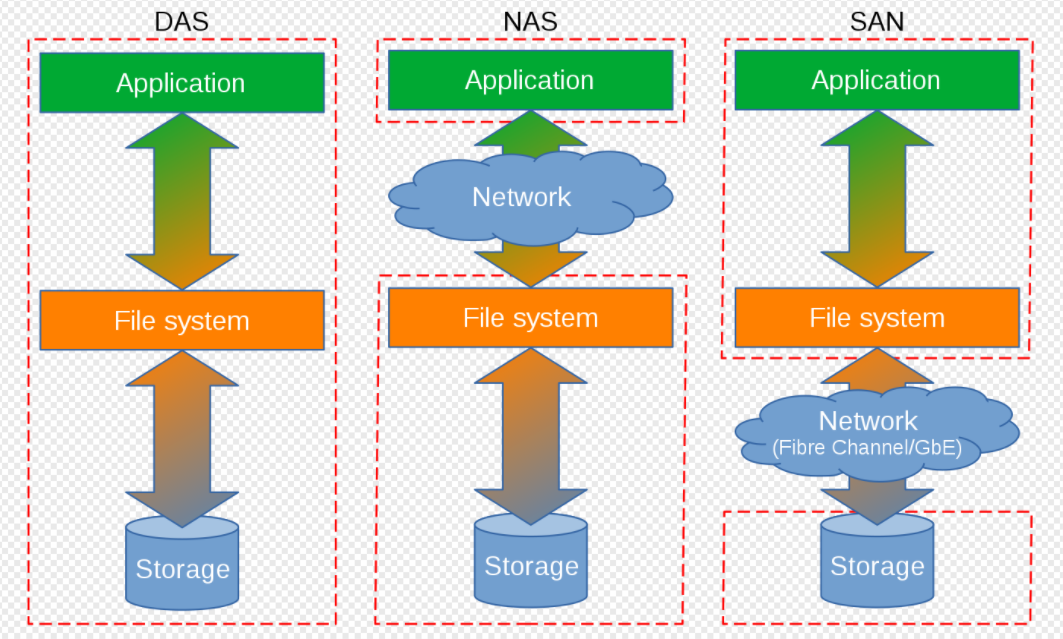
而網路化儲存根據傳輸協定又分為:網路附加儲存 NAS (Network-Attached Storage)和儲存區域網路SAN(Storage Area Network)。 (此概念容易弄混,N對應network 網路, NAS 也可以理解為網路附加儲存,即將儲存協定在常用網路中傳輸。S 開頭 storage 儲存,儲存區域網路其強調的是專用的網路)
其分類如下思維導圖:

- 直接儲存:(DAS)很好理解,一般是通過專用線纜如IDE 、SCSI線直接將外部儲存連在伺服器的內部匯流排上,可以理解為
儲存裝置只與一臺主機互聯。此時常用的介面型別有 IDE、SCSI、SATA、NVMe,如下圖是VMware軟體上新增磁碟時提供的介面選項。

-
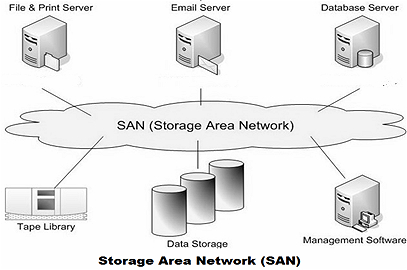
網路化儲存: 則是通過網路傳輸來提供的儲存能力,如果提供的是檔案型別的儲存如NFS、CIFS,則其一般是NAS 儲存。如果提供的是塊裝置的介面型別,則其是SAN儲存。(通常是這樣,但是其分類與提供的磁碟型別無關。)
-
FC-SAN: 而根據傳輸協定的不同,在資料鏈路層有專用的光纖通道協定,依賴儲存裝置組成單獨的網路,大多利用光纖連線,採用
光纖通道協定(Fiber Channel,簡稱FC)。伺服器和儲存裝置間可以任意連線,I/O請求也是直接傳送到儲存裝置。光纖通道協定實際上解決了底層的傳輸協定,高層的協定仍然採用SCSI協定,所以光纖通道協定實際上可以看成是SCSI over FC -
IP-SAN: 如果SAN是基於
TCP/IP的網路,實現IP-SAN網路。這種方式是將伺服器和儲存裝置通過專用的網路連線起來,伺服器通過「Block I/O」傳送資料存取請求到儲存裝置。最常用的是iSCSI技術,就是把SCSI命令包在TCP/IP包中傳輸,即為SCSI over TCP/IP。
(注*在OpenStack 為主的IAAS場景中,IP-SAN和FC-SAN作為專業的儲存裝置與OpenStack進行對接是很常見的場景。瞭解其基本原理還是很有必要的。)
2、FC-SAN VS IP-SAN

總結:
1、IP SAN 通常被認為比 FC SAN 成本更低、更易於管理。
2、FC SAN 需要特殊的硬體,如光纖交換機或主機匯流排介面卡,而 IP SAN 只需要現有的乙太網網路硬體。
3、FC SAN 是許多關鍵業務應用程式的理想儲存平臺。
4、IP SAN 是那些需要經濟高效解決方案的組織的理想選擇。
5、缺點 FC-SAN 和IP-SAN 其都是用的專業的儲存裝置,儲存裝置是集中在固定的幾個儲存伺服器上的,這樣的儲存也稱為集中式儲存。集中式儲存缺點也很明顯,依賴專用的儲存裝置,無法快速的批次部署在普通伺服器上。
3、 分散式儲存
單塊磁碟的效能是固定,如果我們能將資料分割成多塊, 每塊資料,選擇一塊硬碟去儲存,這樣在有N塊硬體的條件下,理論上是可以達到N*單盤效能引數,這就是分散式儲存的理論依據。而將儲存功能和管理與硬體解耦,以軟體的方式部署在普通伺服器上,則是軟體定義儲存的思想。而軟體定義儲存是未來的儲存的趨勢。
分散式儲存特點是將資料分散儲存在多臺計算機或伺服器上的一種儲存方式。它通過將資料劃分為多個塊,並將這些塊分佈儲存在不同的節點上,實現了資料的並行處理和高可靠性。這種儲存方式具有良好的擴充套件性、高吞吐量和可靠性,適用於處理大規模資料集。
Hadoop分散式檔案系統(Hadoop Distributed File System,簡稱HDFS)是一個開源的、高度可靠的分散式儲存系統,被廣泛應用於巨量資料領域。HDFS基於Google的GFS論文設計而來,旨在為大規模資料處理提供高效的儲存解決方案。
HDFS的核心思想是將資料劃分為多個塊,並將這些塊分佈儲存在叢集中的多個節點上。每個塊的預設大小為128MB,可以根據需要進行設定。這種劃分方式使得資料可以在叢集中並行處理,提高了資料處理的效率。
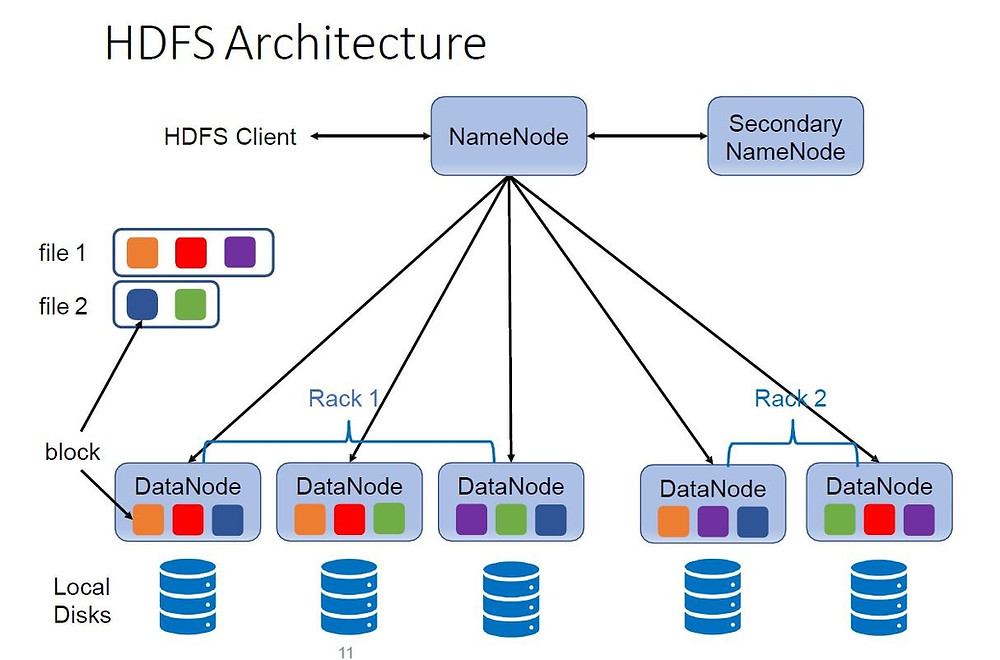
HDFS採用主從架構,包括一個主節點(NameNode)和多個從節點(DataNode)。NameNode負責管理檔案系統的名稱空間、記錄檔案的後設資料資訊(如檔名、檔案目錄結構、檔案屬性等),以及監控整個系統的狀態。DataNode負責儲存實際的資料塊,並根據NameNode的指示完成資料的讀寫操作。
在ext系列的檔案系統中,磁碟塊被分為兩部分資料區和後設資料區,而檔案在儲存時,其inode資訊就存放在後設資料區。客戶存取檔案系統時,在檔案系統樹中表現應該一個路徑如/usr/share/lib/file ,根據該路徑的目錄名去層層查詢inode表,最後查詢到file 檔案對應的inode資訊,而inode資訊記錄了當前資料塊存放在哪些資料區。從這個角度來看後設資料可以理解為是一張路由表,該表中記錄我們怎麼找到真正的資料存放位置。當然其也記錄檔案的屬主、屬組、許可權等資訊。在這樣的一個分割區或者磁碟中,如果我們想把一個大檔案分成多個小檔案,分散儲存在多個節點上時,顯示在這種資料和後設資料在一起的架構上是無法實現的。
隨之我們想到的是將後設資料和資料分離,找一個單獨的節點存放後設資料,而將真正的資料,按一定大小分為固定的塊,塊分散的存放在不同的節點上。而讓後設資料去提供每個塊資料的路由資訊,例如當要儲存一個256M大小的檔案時,其先存取後設資料節點,後設資料節點按固定大小的塊(如128M,則分為2塊),每一塊資料,當做一個獨立的檔案,然後進行路由和排程。從而完成所謂分散儲存的目的。這樣就能充分利用每一個儲存節點的儲存和網路能力,達到了分散式資料儲存的效果。
當讀資料時,也是先存取後設資料節點,後設資料節點記錄了該檔案被切了多少個檔案塊,塊與塊之間是如何偏移的,每個塊是在哪個節點的哪個位置。通過這些資訊組合,從而得到一個完整的檔案資訊,然後從各個資料節點並行讀取所有分散的塊,這也就達到了分散式讀的效果。
而負責後設資料服務的節點就稱為NameNode ,而負責資料存放節點的稱為DataNode.從上述描述中可以看到NameNode的角色是多麼重要,如果宕機了,則檔案都無法存取了,因此其需要高可用部署,其冗餘的節點也稱為 Secondary NameNode;
後設資料是IO密集,但是IO量非常小的IO請求, 為了高效 ,一般都是在記憶體中的,還需要注意的是,磁碟IO的寫一般都是隨機的IO,隨機寫的IO是非常慢的,如何將一次隨機的IO寫變成有序的IO寫請求呢?
我們可以像Mysql binlog 紀錄檔一樣,不直接進行IO的寫,而是記錄寫的操作,這樣就是順序寫,這些寫的操作就是binlog 紀錄檔,將來想要回滾時,只需要將紀錄檔回放即可。
可是即便是這樣我們的後設資料節點同時寫操作也只能在一個NameNOde上進行,IO雖然小,但是在大量資料IO請求過來時,仍然有效能不足的風險。這種結構也稱為有中心節點的分散式儲存。其中心節點就是NameNode. 而Ceph是一個無中心節點的分散式儲存,他們的最大差異點就在於此。
HDFS作為一個分散式儲存,其具有分散式儲存的所有特點;
-
高可靠性:HDFS通過資料冗餘機制實現高可靠性。每個資料塊預設會有三個副本,分別儲存在不同的節點上,以防止單點故障對資料的影響。當某個節點失效時,系統會自動將其副本切換到其他健康的節點上,保證資料的可存取性。
-
高吞吐量:HDFS通過並行處理和資料本地性原則(Data Locality)來實現高吞吐量。資料本地性原則指的是儘可能地將計算任務排程到儲存資料的節點上執行,減少資料傳輸開銷。這種方式可以最大限度地利用叢集的計算和儲存資源,提高整體的處理效率。
-
擴充套件性:HDFS支援橫向擴充套件,可以方便地增加新的節點來擴充套件儲存容量和計算能力。當需要儲存更多資料時,只需新增新的節點即可,而無需對已有的節點進行改動。
-
容錯性:HDFS通過週期性地建立檔案系統的快照(Snapshot)來實現容錯性。快照是檔案系統狀態的一份拷貝,可以用於恢復資料或回滾到某個特定的時間點。當發生錯誤或資料損壞時,可以通過快照來恢復資料的完整性。
總之,HDFS是一個高度可靠、高擴充套件性和高吞吐量的分散式儲存系統,它為大規模資料處理提供了一個穩定而高效的基礎平臺。在巨量資料領域中,HDFS被廣泛應用於資料儲存、資料管理和資料分析等方面,為使用者提供強大的儲存能力和資料處理能力。其與Ceph 都是分散式儲存,兩者最大的區別是Ceph是無中心節點的分散式儲存。那Ceph是如何管理後設資料的,我們在下一章將做詳細介紹。

