深度解析自然語言處理之篇章分析
在本文中,我們深入探討了篇章分析的概念及其在自然語言處理(NLP)領域中的研究主題,以及兩種先進的話語分割方法:基於詞彙句法樹的統計模型和基於BiLSTM-CRF的神經網路模型。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。

一、引言
篇章分析在自然語言處理(NLP)領域是一個不可或缺的研究主題。與詞語和句子分析不同,篇章分析涉及到文字的更高階別結構,如段落、節、章等,旨在捕捉這些結構之間的複雜關係。這些關係通常包括但不限於銜接、連貫性和結構等方面,它們不僅對理解單一文字有重要意義,還在多文字、跨文字甚至跨模態的分析中起到至關重要的作用。從推薦系統的個性化內容生成,到機器翻譯的文字質量優化,再到對話系統的上下文理解,篇章分析的應用場景極為廣泛。
篇章分析的整體理念
篇章分析的核心理念是「高層次的語意和語用分析」。在這個視角下,文字不僅僅是詞和句子的簡單集合,更是資訊和觀點的有機組合。每個篇章元素都在與其他元素互動,形成更大的語意和語用結構。因此,篇章分析的目標不僅是理解各個單元(如句子、段落)如何構成一個統一和連貫的文字,更是在多層次、多維度上理解文字傳達的深層含義。
內容之間的關聯關係
-
篇章的銜接、連貫與結構: 這三個方面是篇章分析的基石。銜接關注句子或段落之間的明確聯絡,如轉折、因果等;連貫性關注文字整體的流暢度和可讀性;結構則從宏觀角度審視文字,探討如何更有效地組織資訊。這三者相互關聯,相互促進,共同構成了高質量的文字。
-
話語分割: 在深入到基於詞彙句法樹和迴圈神經網路的話語分割之前,理解這三個核心方面是至關重要的。話語分割方法試圖在更細粒度上劃分和理解文字,為後續的任務提供基礎。
二、篇章分析的基礎概念
什麼是篇章?
篇章是由兩個或更多的句子構成的,用於表達一個或多個緊密相關的觀點或資訊的文字單元。與單個句子或詞彙不同,篇章包括更復雜的結構和含義,通常需要通過多個句子甚至多個段落來傳達。
範例
比如,在一篇關於氣候變化的文章中,一個篇章可能會專門討論極端天氣現象的增加,從統計資料到具體的事件案例,再到可能的影響,構成一個完整的討論。
篇章分析的重要性
篇章分析是自然語言處理中非常重要的一部分,因為它能夠幫助機器更好地理解人類語言的複雜性和多層次性。篇章分析能夠從宏觀的角度捕捉文字資訊,提供比句法和語意分析更為全面的理解。
範例
拿新聞摘要生成為例,單從句子級別出發,我們可能只能獲取到表面的資訊。但如果能夠進行篇章分析,我們不僅可以抓住文章的主要觀點,還能瞭解各個觀點是如何邏輯排列和相互支援的。
篇章分析在NLP中的應用
篇章分析在NLP的多個應用場景中都有著廣泛的用途。以下是幾個典型的應用場景:
- 資訊檢索: 通過篇章分析,可以更準確地理解使用者的查詢意圖,從而返回更相關的搜尋結果。
- 機器翻譯: 篇章層面的分析能夠幫助機器翻譯系統更準確地把握原文的語境,提高翻譯的自然性和準確性。
- 文字摘要: 除了抓住文章的主要觀點,篇章分析還能捕捉到觀點之間的邏輯關係,生成更為精煉和高質量的摘要。
範例
-
在資訊檢索中,如果使用者查詢「氣候變化的影響」,僅從詞彙或句子級別分析可能會返回關於「氣候」和「影響」的廣泛文章。但通過篇章分析,可以更精確地找到討論「氣候變化影響」的具體篇章或文章。
-
在機器翻譯中,比如一個長句子由多個短句子構成,而這些短句子之間有因果、轉折等複雜關係。篇章分析能幫助機器更準確地捕捉這些關係,從而生成更自然的譯文。
-
在文字摘要中,通過篇章分析,系統可以識別文章的主要觀點,以及這些觀點是如何通過證據和論點串聯起來的,從而生成一個全面而準確的摘要。
三、篇章的銜接
篇章分析中的一個重要概念是銜接(Cohesion)。銜接涉及文字中各個語言成分如何相互關聯,以形成一個整體的、連貫的資訊結構。
語意銜接
銜接主要是一種語意關係,它使篇章的各個組成部分在語意上緊密相連。這通常通過兩種主要方式來實現:詞彙銜接和語法銜接。
詞彙銜接
詞彙銜接主要涉及使用特定的詞彙手段,如重述(Reiteration)和搭配(Collocation)。
重述 (Reiteration)
重述通常是通過詞彙的重複或使用同義詞、近義詞、反義詞、上下位詞等來建立篇章的銜接。
例子:
太陽是生命之源,無論是人類還是動植物,都離不開太陽的照射。因此,陽光是非常重要的。
在這個例子中,"太陽" 和 "陽光" 建立了一種重述關係,增加了篇章的銜接性。
搭配 (Collocation)
搭配關係通常是詞與詞之間的習慣性組合,不僅限於一個句子內,也可能是跨句或跨段。
例子:
他拿起手機,然後開始瀏覽社交媒體。不久後,他發現了一條有趣的推文。
在這裡,"手機" 和 "社交媒體"、"推文" 形成了一種搭配關係,增強了文字的連貫性。
語法銜接
語法銜接主要包括照應(Reference)、替代(Substitution)、省略(Ellipsis)和連線(Conjunction)。
照應 (Reference)
照應是指一個詞或短語與前文或後文中的詞或短語有明確的指代關係。
例子:
小明是個好學生。他總是第一個到校,最後一個離開。
在這裡,「他」明確地指代了「小明」,形成了照應關係。
替代 (Substitution)
替代是用其他詞或短語來代替前文中出現的詞或短語。
例子:
有些人喜歡蘋果,有些人則更偏向於橙子。
在這裡,「更偏向於」替代了「喜歡」,形成了替代關係。
省略 (Ellipsis)
省略是在句子中去除某個不必要的成分,以使表達更簡潔。
例子:
他想吃巧克力,但我不(想吃)。
這裡,「想吃」被省略,但意思仍然清晰。
連線 (Conjunction)
連線是通過使用特定的連線詞來建立邏輯關係,可以分為詳述、延伸和增強三大類。
詳述例子:
她很善良,例如,總是願意幫助別人。
延伸例子:
他是個勤奮的學生。然而,他在數學方面卻總是遭遇困難。
增強例子:
除了是一個優秀的程式設計師,他還是個熱愛音樂的人。
在這些例子中,例如、然而和除了都作為連線詞,增加了句子和段落之間的邏輯關係。
通過以上各種銜接手段,篇章可以形成一個結構嚴謹、語意連貫的整體,從而更有效地傳達資訊和觀點。
四、篇章的連貫
篇章分析是一個複雜且有深度的領域,涉及到語意、語法、修辭和認知等多個層面。特別是在涉及到篇章連貫(Coherence)時,這一複雜性更為明顯。
連貫(Coherence)與連貫性(Coherent)
連貫(Coherence)是指篇章在語意、功能和心理上構成一個整體,圍繞同一個主題或意圖展開。連貫性(Coherent)則是一個衡量篇章質量的指標。
範例:
考慮下列兩個句子:
- 張三參加了馬拉松比賽。
- 他完成了全程42.195公里。
這兩個句子形成了一個連貫的篇章,因為它們都圍繞著「張三參加馬拉松比賽」這一主題展開。
區域性連貫性(Local Coherence)
區域性連貫性涉及篇章中前後相連的命題在語意上的聯絡。這通常需要考慮詞彙、句法和語意等因素。
範例:
考慮以下的句子序列:
- 小明喜歡數學。
- 他經常參加數學競賽。
這兩個句子在區域性層面上是連貫的,因為「小明」和「數學競賽」都與「數學」有直接的語意聯絡。
整體連貫性(Global Coherence)
整體連貫性則更注重篇章中的所有命題與篇章主題之間的聯絡,這一點在長篇文章或論文中尤為重要。
範例:
考慮以下的句子:
- 小紅去了圖書館。
- 她借了幾本關於量子物理的書。
- 她的目標是成為一名物理學家。
這些句子圍繞著「小紅對物理學的興趣和目標」這一主題,展示了整體連貫性。
認知模式與連貫
篇章的語意結構受到人們普遍認知規律的制約,例如從一般到特殊、從整體到區域性。
範例:
考慮以下句子:
- 北京是中國的首都。
- 故宮是北京的一大旅遊景點。
- 故宮的午門是最受遊客歡迎的地方。
這一系列句子符合從整體到區域性的認知模式,先描述北京,再到具體的故宮,最後到更具體的午門。
理論與方法
篇章連貫性的研究有多種方法,包括關聯理論、修辭結構理論(Rhetorical Structure Theory)、圖式理論(Schema Theory)和基於語篇策略(Discourse Strategy)的研究等。
關聯理論
在微觀層面上,關聯理論(Relevance Theory)提供了一種用於理解篇章中資訊如何相互關聯的框架。
修辭結構理論(Rhetorical Structure Theory)
這一理論嘗試通過分析篇章中不同元素之間的修辭性關係,來理解篇章的連貫性。
圖式理論(Schema Theory)
圖式理論主要用於解釋讀者如何使用先前的知識來理解新資訊,從而提供篇章連貫性的一種認知基礎。
基於語篇策略(Discourse Strategy)的研究
這一方向主要研究篇章如何通過不同的語篇策略,如主題句、過渡句等,來增強其連貫性。
五、篇章的結構
篇章不僅是一組簡單地排列在一起的句子,而是一個精心設計的結構,旨在傳達特定的資訊或達到特定的目的。
線性結構與等級結構
首先,篇章有線性結構和等級結構兩種基本形式。線性結構是指句子按照某種邏輯順序或時間順序排列。例如:
「今天早上我起床,刷牙洗臉後吃了早餐。然後我走到公交站,搭乘公交車到達學校。」
這個例子中,句子按照事件發生的時間順序排列,構成了線性結構。
等級結構則意味著句子和段落的組合可以構成更高階別的資訊單元。以學術文章為例,它通常包括引言、主體和結論等部分,這些部分又由多個段落組成,形成了一個等級結構。
篇章超級結構(Superstructure)
篇章超級結構是用於描述篇章如何組織的一種高階結構。例如,在學術論文中,常見的超級結構包括「引言-方法-結果-討論(IMRD)」。這種結構只涉及內容的組織方式,與內容本身無關。
修辭結構理論(Rhetorical Structure Theory, RST)
RST 是一種用於分析篇章結構的理論,它定義了不同文字單元(Text Span)之間的修辭關係。主要分為兩種型別:
- 核心(Nucleus):篇章中最重要的部分,例如:「吸菸有害健康。」
- 輔助(Satellite):用於解釋或支援核心資訊的部分,例如:「據世界衛生組織統計,每年有 800 萬人因吸菸導致的疾病而死亡。」
語篇模式(Textual Pattern)
語篇模式是長期形成的,通常帶有文化背景的篇章組織方式。例如,在西方文化中,「問題-解決(Problem-Solution)」模式非常普遍。
例子:語篇模式在新聞報道中的應用
考慮以下新聞報道:
[1]「新的研究發現,青少年使用社交媒體的時間越長,出現抑鬱症狀的機率越高。」(核心)
[2]「這一發現是基於對 1000 名青少年進行為期一年的跟蹤研究的結果。」(輔助)
這個報道用了「問題-解決」模式。[1]提出了一個問題(青少年使用社交媒體與抑鬱),而[2]給出了該問題的一個解決方案(基於研究的證據)。
通過了解這些不同的結構和模式,作者可以更有效地組織篇章,讀者也能更容易地理解和接收資訊。這也是為什麼篇章的結構是寫作和閱讀中不可或缺的一個方面。
六、基於詞彙句法樹的統計話語分割

話語分割(Discourse Segmentation)是自然語言處理中的一個關鍵任務,它旨在識別篇章中的基本篇章單元(Elementary Discourse Units, EDU)。這是後續進行高階篇章分析的基礎。
話語分割與修辭結構理論
根據修辭結構理論(Rhetorical Structure Theory, RST),篇章的修辭關係是定義在兩個或多個EDU之間的。話語分割的主要目標就是識別這些EDU。
例子
考慮以下句子:
"蘋果很好吃,但是很貴。"
在這裡,"蘋果很好吃" 和 "但是很貴" 可以被認為是兩個不同的EDU。
SynDS 演演算法概述
SynDS 演演算法基於詞彙句法樹來估算一個單詞是否應作為一個EDU的邊界。它使用詞彙中心(Lexical Head)對映規則來提取更多特徵。
最大似然估計
給定句子 (s = w_1, w_2, ..., w_n) 和它的句法樹 (t),該演演算法使用最大似然估計來學習每個詞 (w_i) 作為邊界的概率 ( P(b_i | w_i) ),其中 (b_i \in {0, 1})。0表示非邊界,1表示邊界。
詞彙中心對映
對於每個詞 (w),該演演算法注意到其右側兄弟節點的最高父節點,並使用這個資訊來決定當前詞是否應作為邊界詞。
PyTorch 實現
下面的 PyTorch 程式碼片段展示了這一演演算法的基礎實現。
import torch
import torch.nn as nn
import torch.optim as optim
# 假設我們已經得到了句法樹和詞彙向量
# feature_dim 是特徵維度
class SynDS(nn.Module):
def __init__(self, feature_dim):
super(SynDS, self).__init__()
self.fc = nn.Linear(feature_dim, 2) # 二分類:0表示非邊界,1表示邊界
def forward(self, x):
return self.fc(x)
# 初始化
feature_dim = 128
model = SynDS(feature_dim)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 假設 x_train 是輸入特徵,y_train 是標籤(0或1)
# x_train 的形狀為 (batch_size, feature_dim)
# y_train 的形狀為 (batch_size)
x_train = torch.rand((32, feature_dim))
y_train = torch.randint(0, 2, (32,))
# 訓練模型
optimizer.zero_grad()
outputs = model(x_train)
loss = criterion(outputs, y_train)
loss.backward()
optimizer.step()
# 輸出預測
with torch.no_grad():
test_input = torch.rand((1, feature_dim))
test_output = model(test_input)
prediction = torch.argmax(test_output, dim=1)
print("預測邊界為:", prediction.item())
輸入與輸出
- 輸入:特徵維度為
feature_dim的詞向量。 - 輸出:預測結果,0 或 1,代表是否為EDU邊界。
處理過程
- 使用最大似然估計計算概率。
- 用交叉熵損失函數進行訓練。
- 使用優化器進行權重更新。
七、基於迴圈神經網路的話語分割
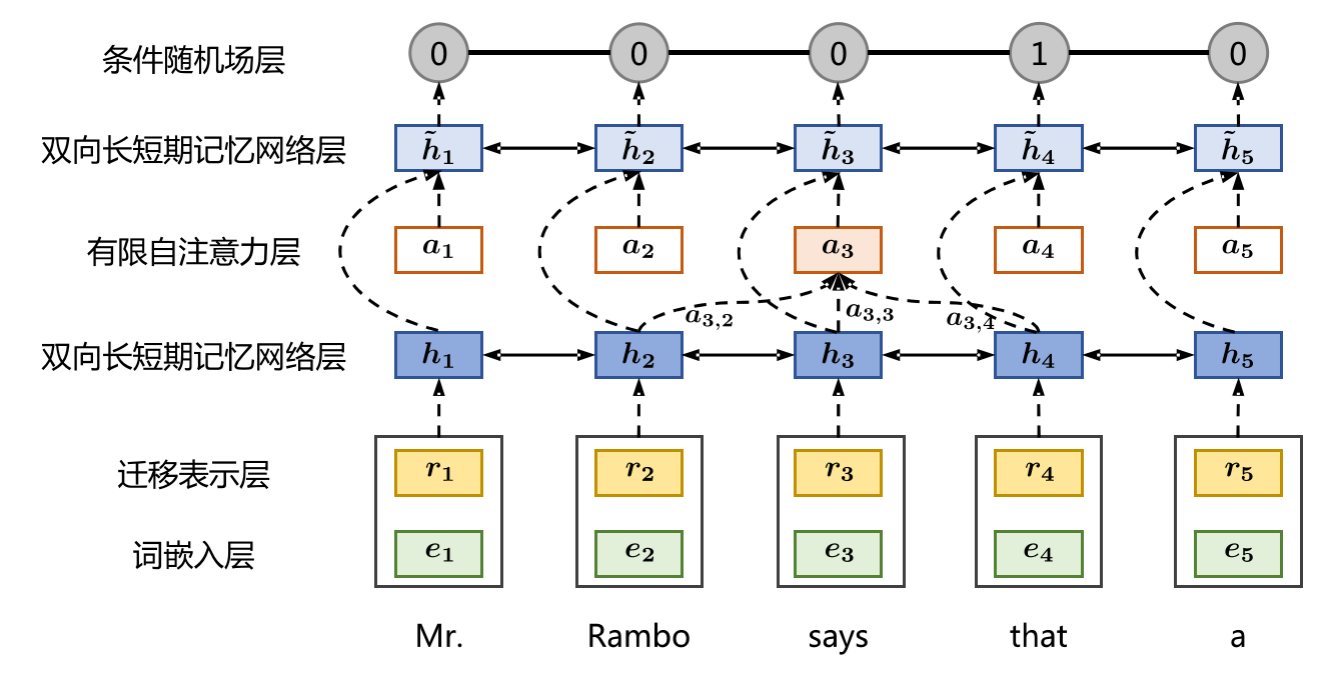
話語分割是識別篇章中基本篇章單元(Elementary Discourse Units,簡稱EDU)的過程,為後續的分析打下基礎。在這一篇章中,我們將專注於使用雙向長短時記憶網路(BiLSTM)和條件隨機場(CRF)進行話語分割的實現。
從序列標註到話語分割
在基於RNN的模型中,話語分割任務可以被重新定義為一個序列標註問題。對於輸入的每一個詞 (x_t),模型輸出一個標籤 (y_t),表示該詞是否是一個EDU的起始邊界。
輸出標籤的定義
- ( y_t = 1 ) 表示 ( x_t ) 是EDU的起始邊界。
- ( y_t = 0 ) 表示 ( x_t ) 不是EDU的起始邊界。
BiLSTM-CRF模型
BiLSTM-CRF結合了BiLSTM的能力來捕獲句子中的長距離依賴關係和CRF的能力來捕獲輸出標籤之間的關係。
BiLSTM層
BiLSTM可以從兩個方向讀取句子,因此它可以捕獲前後文資訊。
CRF層
條件隨機場(CRF)是用於序列標註的概率圖模型,其目標是找到給定輸入序列 ( X ) 下可能的最佳輸出序列 ( Y )。
PyTorch 實現
下面是使用PyTorch實現BiLSTM-CRF模型進行話語分割的範例程式碼:
import torch
import torch.nn as nn
from torchcrf import CRF
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(BiLSTM_CRF, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2, num_layers=1, bidirectional=True)
self.hidden2tag = nn.Linear(hidden_dim, 2) # 2表示兩個標籤:0和1
self.crf = CRF(2)
def forward(self, x):
embeds = self.embedding(x)
lstm_out, _ = self.lstm(embeds.view(len(x), 1, -1))
lstm_feats = self.hidden2tag(lstm_out.view(len(x), -1))
return lstm_feats
# 引數設定
vocab_size = 5000
embedding_dim = 300
hidden_dim = 256
# 初始化模型
model = BiLSTM_CRF(vocab_size, embedding_dim, hidden_dim)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
# 模擬輸入資料
sentence = torch.tensor([1, 2, 3, 4], dtype=torch.long)
tags = torch.tensor([1, 0, 1, 0], dtype=torch.long)
# 前向傳播
lstm_feats = model(sentence)
# 計算損失和梯度
loss_value = -model.crf(lstm_feats, tags)
loss_value.backward()
optimizer.step()
# 解碼:得到預測標籤序列
with torch.no_grad():
prediction = model.crf.decode(lstm_feats)
print("預測標籤序列:", prediction)
輸入與輸出
- 輸入:詞的整數索引序列,長度為 ( T )。
- 輸出:標籤序列,長度也為 ( T ),其中每個元素都是0或1。
處理過程
- 詞嵌入層將整數索引轉換為固定維度的向量。
- BiLSTM層捕獲輸入序列的前後文資訊。
- 線性層將BiLSTM的輸出轉換為適用於CRF的特徵。
- CRF層進行序列標註,輸出每個詞是否是EDU的開始。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。