向量資料庫Chroma極簡教學
引子
向量資料庫其實最早在傳統的人工智慧和機器學習場景中就有所應用。在大模型興起後,由於目前大模型的token數限制,很多開發者傾向於將資料量龐大的知識、新聞、文獻、語料等先通過嵌入(embedding)演演算法轉變為向量資料,然後儲存在Chroma等向量資料庫中。當用戶在大模型輸入問題後,將問題本身也embedding,轉化為向量,在向量資料庫中查詢與之最匹配的相關知識,組成大模型的上下文,將其輸入給大模型,最終返回大模型處理後的文字給使用者,這種方式不僅降低大模型的計算量,提高響應速度,也降低成本,並避免了大模型的tokens限制,是一種簡單高效的處理手段。此外,向量資料庫還在大模型記憶儲存等領域發揮其不可替代的作用。
由於大模型的火熱,現在市面上的向量資料庫眾多,主流的向量資料庫對比如下所示:
| 向量資料庫 | URL | GitHub Star | Language |
|---|---|---|---|
| chroma | https://github.com/chroma-core/chroma | 7.4K | Python |
| milvus | https://github.com/milvus-io/milvus | 21.5K | Go/Python/C++ |
| pinecone | https://www.pinecone.io/ | ❌ | ❌ |
| qdrant | https://github.com/qdrant/qdrant | 11.8K | Rust |
| typesense | https://github.com/typesense/typesense | 12.9K | C++ |
| weaviate | https://github.com/weaviate/weaviate | 6.9K | Go |
本文重點圍繞向量資料庫Chroma的使用和實戰,主要包括以下內容:
- Chroma設計理念
- Chroma常見概念(資料集,檔案,儲存,查詢,條件過濾)
- Chroma快速上手
- Chroma支援的Embeddings演演算法
- 實戰:在Langchain中使用Chroma對中國古典四大名著進行相似性查詢
Chroma快速上手
設計理念
Chroma的目標是幫助使用者更加便捷地構建大模型應用,更加輕鬆的將知識(knowledge)、事實(facts)和技能(skills)等我們現實世界中的檔案整合進大模型中。
Chroma提供的工具:
- 儲存檔案資料和它們的後設資料:store embeddings and their metadata
- 嵌入:embed documents and queries
- 搜尋: search embeddings
Chroma的設計優先考慮:
- 足夠簡單並且提升開發者效率:simplicity and developer productivity
- 搜尋之上再分析:analysis on top of search
- 追求快(效能): it also happens to be very quick

目前官方提供了Python和JavaScript版本,也有其他語言的社群版本支援。
完整Demo
首先需要Python環境(Chroma官方原生支援Python和JavaScript,本文用Python做範例)
pip install chromadb
直接執行如下程式碼,便是一個完整的Demo:
import chromadb
chroma_client = chromadb.Client()
collection = chroma_client.create_collection(name="my_collection")
collection.add(
documents=["This is a document about engineer", "This is a document about steak"],
metadatas=[{"source": "doc1"}, {"source": "doc2"}],
ids=["id1", "id2"]
)
results = collection.query(
query_texts=["Which food is the best?"],
n_results=2
)
print(results)
上面的程式碼中,我們向Chroma提交了兩個檔案(簡單起見,是兩個字串),一個是This is a document about engineer,一個是This is a document about steak。若在add方法沒有傳入embedding引數,則會使用Chroma預設的all-MiniLM-L6-v2 方式進行embedding。隨後,我們對資料集進行query,要求返回兩個最相關的結果。提問內容為:Which food is the best?
返回結果:
{
'ids': [
['id2', 'id1']
],
'distances': [
[1.5835548639297485, 2.1740970611572266]
],
'metadatas': [
[{
'source': 'doc2'
}, {
'source': 'doc1'
}]
],
'embeddings': None,
'documents': [
['This is a document about steak', 'This is a document about engineer']
]
}
結果顯示,兩個檔案都被正確返回,且id2由於是steak(牛排),相關性與我們的提問更大,排在了首位。還列印了distances。
簡單,易理解。
資料持久化
Chroma一般是直接作為記憶體資料庫使用,但是也可以進行持久化儲存。
在初始化Chroma Client時,使用PersistentClient:
client = chromadb.PersistentClient(path="/Users/yourname/xxxx")
這樣在執行程式碼後,在你指定的位置會新建一個chroma.sqlite3檔案。
這個sqlite3的資料庫裡包含的表如下圖,從中可以窺見一部分Chroma的資料儲存思路:
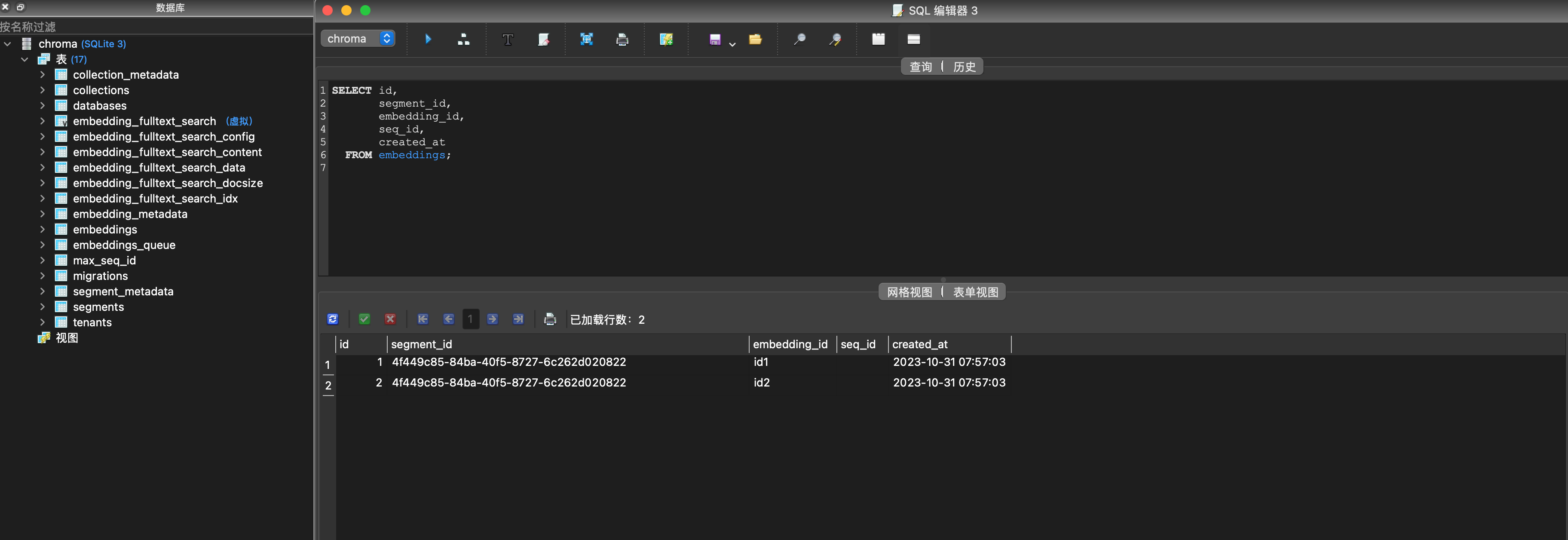
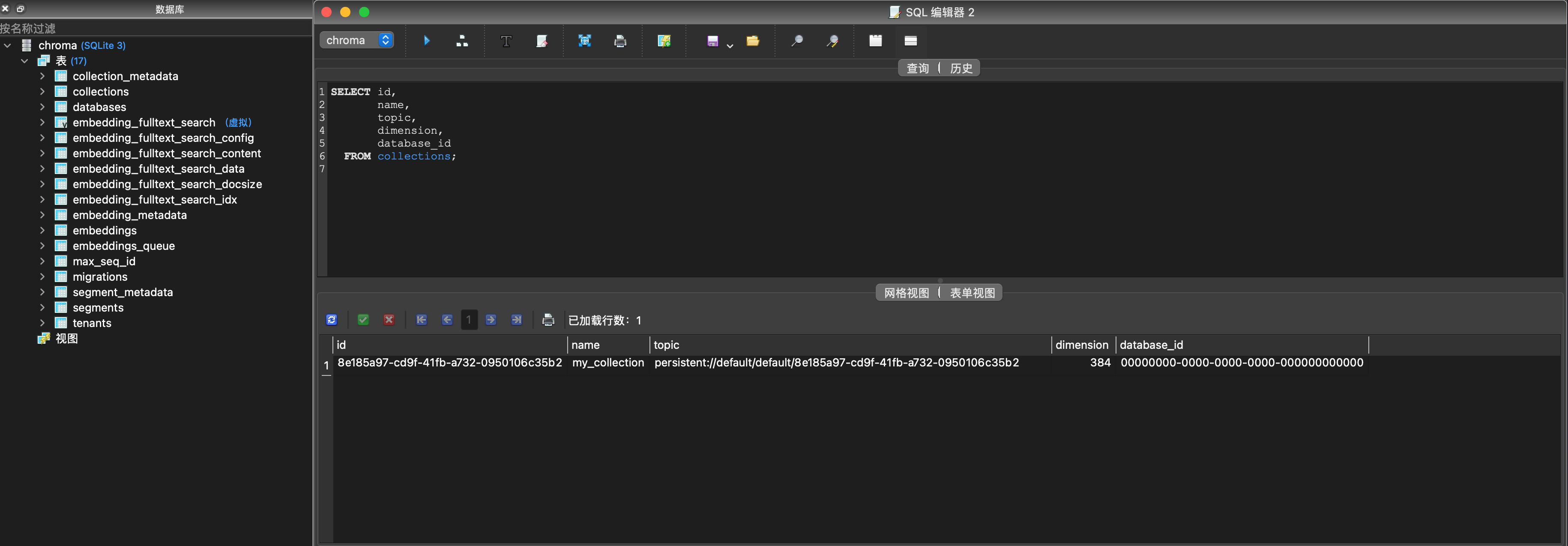
Chroma Client還支援下面兩個API:
client.heartbeat() # returns a nanosecond heartbeat. Useful for making sure the client remains connected.
client.reset() # Empties and completely resets the database. ⚠️ This is destructive and not reversible.
此外,Chroma還支援伺服器端,使用者端模式,用於跨程序通訊。詳見:
https://docs.trychroma.com/usage-guide
資料集(Collection)
collection是Chroma中一個重要的概念,下面的程式碼和註釋簡單介紹了collection的主要功能和使用方法。
collection = client.get_collection(name="test") # Get a collection object from an existing collection, by name. Will raise an exception if it's not found.
collection = client.get_or_create_collection(name="test") # Get a collection object from an existing collection, by name. If it doesn't exist, create it.
client.delete_collection(name="my_collection") # Delete a collection and all associated embeddings, documents, and metadata. ⚠️ This is destructive and not reversible
collection.peek() # returns a list of the first 10 items in the collection
collection.count() # returns the number of items in the collection
collection.modify(name="new_name") # Rename the collection
collection支援傳入一些自身的後設資料metadata:
collection = client.create_collection(
name="collection_name",
metadata={"hnsw:space": "cosine"} # l2 is the default
)
collection允許使用者自行切換距離計算函數,方法是通過設定cellection的metadata中的「hnsw:space」:
collection = client.create_collection(
name="collection_name",
metadata={"hnsw:space": "cosine"} # l2 is the default
)
| Distance | parameter | Equation |
|---|---|---|
| Squared L2 | 'l2' | $d = \sum\left(A_i-B_i\right)^2$ |
| Inner product | 'ip' | $d = 1.0 - \sum\left(A_i \times B_i\right) $ |
| Cosine similarity | 'cosine' | $d = 1.0 - \frac{\sum\left(A_i \times B_i\right)}{\sqrt{\sum\left(A_i^2\right)} \cdot \sqrt{\sum\left(B_i^2\right)}}$ |
檔案(Document)
在上面的Demo中,我們使用了預設的add函數。
def add(ids: OneOrMany[ID],
embeddings: Optional[OneOrMany[Embedding]] = None,
metadatas: Optional[OneOrMany[Metadata]] = None,
documents: Optional[OneOrMany[Document]] = None) -> None
除此之外,你還可以有如下傳參:
- ids: 檔案的唯一ID
- embeddings(可選): 如果不傳該引數,將根據Collection設定的embedding_function進行計算。
- metadatas(可選):要與嵌入關聯的後設資料。在查詢時,您可以根據這些後設資料進行過濾。
- documents(可選):與該嵌入相關聯的檔案,甚至可以不放檔案。
範例:
collection.add(
embeddings=[[1.2, 2.3, 4.5], [6.7, 8.2, 9.2]],
documents=["This is a document", "This is another document"],
metadatas=[{"source": "my_source"}, {"source": "my_source"}],
ids=["id1", "id2"]
)
簡單查詢
輸入檔案內的文字進行相似性查詢,可以使用query方法
collection.query(
query_embeddings=[[11.1, 12.1, 13.1],[1.1, 2.3, 3.2], ...],
n_results=10,
where={"metadata_field": "is_equal_to_this"},
where_document={"$contains":"search_string"}
)
若想要通過id查詢,可以使用get方法
collection.get(
ids=["id1", "id2", "id3", ...],
where={"style": "style1"}
)
與此同時,你可以客製化返回結果包含的資料
# Only get documents and ids
collection.get({
include: [ "documents" ]
})
collection.query({
queryEmbeddings: [[11.1, 12.1, 13.1],[1.1, 2.3, 3.2], ...],
include: [ "documents" ]
})
條件查詢
Chroma 支援按後設資料和檔案內容過濾查詢。
where 欄位用於按後設資料進行過濾
{
"metadata_field": {
<Operator>: <Value>
}
}
支援下列操作操作符:
$eq- equal to (string, int, float)
$ne- not equal to (string, int, float)
$gt- greater than (int, float)
$gte- greater than or equal to (int, float)
$lt- less than (int, float)
$lte- less than or equal to (int, float)
# is equivalent to
{
"metadata_field": {
"$eq": "search_string"
}
}
where_document 欄位用於按檔案內容進行過濾
# Filtering for a search_string
{
"$contains": "search_string"
}
使用邏輯運運算元
可以在查詢條件中使用邏輯運運算元
{
"$and": [
{
"metadata_field": {
<Operator>: <Value>
}
},
{
"metadata_field": {
<Operator>: <Value>
}
}
]
}
{
"$or": [
{
"metadata_field": {
<Operator>: <Value>
}
},
{
"metadata_field": {
<Operator>: <Value>
}
}
]
}
使用in/not in
in將返回metadata中包含給出列表中屬性值的檔案:
{
"metadata_field": {
"$in": ["value1", "value2", "value3"]
}
}
not in則與其相反:
{
"metadata_field": {
"$nin": ["value1", "value2", "value3"]
}
}
更新檔案
帶上ids,其他引數和add方法類似
collection.update(
ids=["id1", "id2", "id3", ...],
embeddings=[[1.1, 2.3, 3.2], [4.5, 6.9, 4.4], [1.1, 2.3, 3.2], ...],
metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}, {"chapter": "29", "verse": "11"}, ...],
documents=["doc1", "doc2", "doc3", ...],
)
刪除檔案
提供ids,還允許附帶where條件進行刪除
collection.delete(
ids=["id1", "id2", "id3",...],
where={"chapter": "20"}
)
Chroma Embeddings演演算法
預設Embeddings演演算法
Chroma預設使用的是all-MiniLM-L6-v2模型來進行embeddings
官方預訓練模型
你也可以直接使用官方預訓練的託管在Huggingface上的模型
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('model_name')
The all-* models where trained on all available training data (more than 1 billion training pairs) and are designed as general purpose models. The all-mpnet-base-v2 model provides the best quality, while all-MiniLM-L6-v2 is 5 times faster and still offers good quality. Toggle All models to see all evaluated models or visit HuggingFace Model Hub to view all existing sentence-transformers models.
選擇非常多,你可以點選官網檢視每種預訓練模型的詳細資訊。
https://www.sbert.net/docs/pretrained_models.html

其他第三方Embeddings演演算法
你還可以使用其他第三方模型,包括第三方平臺,例如:
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key="YOUR_API_KEY",
model_name="text-embedding-ada-002"
)
其他包括Cohere,HuggingFace等。
自定義Embeddings演演算法
你甚至可以使用自己的本地Embeddings演演算法,Chroma留有擴充套件點:
from chromadb import Documents, EmbeddingFunction, Embeddings
class MyEmbeddingFunction(EmbeddingFunction):
def __call__(self, texts: Documents) -> Embeddings:
# embed the documents somehow
return embeddings
實戰:在Langchain中使用Chroma對中國古典四大名著進行相似性查詢
很多人認識Chroma是由於Langchain經常將其作為向量資料庫使用。不過Langchain官方檔案裡的Chroma範例使用的是英文Embeddings演演算法以及英文的檔案語料。官方檔案連結如下:
https://python.langchain.com/docs/modules/data_connection/vectorstores.html?highlight=chroma
既然我們是華語區部落格,這本篇文章中,我們就嘗試用中文的語料和Embeddings演演算法來做一次實戰。
先貼上完整程式碼,我們再來逐步解釋:
from langchain.document_loaders import TextLoader
from langchain.embeddings import ModelScopeEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
import chardet
# 讀取原始檔案
raw_documents_sanguo = TextLoader('/Users/rude3knife/Desktop/三國演義.txt', encoding='utf-16').load()
raw_documents_xiyou = TextLoader('/Users/rude3knife/Desktop/西遊記.txt', encoding='utf-16').load()
# 分割檔案
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=0)
documents_sanguo = text_splitter.split_documents(raw_documents_sanguo)
documents_xiyou = text_splitter.split_documents(raw_documents_xiyou)
documents = documents_sanguo + documents_xiyou
print("documents nums:", documents.__len__())
# 生成向量(embedding)
model_id = "damo/nlp_corom_sentence-embedding_chinese-base"
embeddings = ModelScopeEmbeddings(model_id=model_id)
db = Chroma.from_documents(documents, embedding=embeddings)
# 檢索
query = "美猴王是誰?"
docs = db.similarity_search(query, k=5)
# 列印結果
for doc in docs:
print("===")
print("metadata:", doc.metadata)
print("page_content:", doc.page_content)
準備原始檔案
我下載了三國演義和西遊記的全文字txt,作為我們的知識庫,兩個文字都在1.5MB左右。
在這裡還遇到一個小插曲,本以為下載下來的文字時UTF-8編碼,程式碼寫成了encoding='utf-8',結果TextLoader怎麼讀取都報編碼錯誤,用眼睛也沒法一下子判斷是什麼編碼,問了GPT,可以用Python的chardet編碼庫判斷。如果你也遇到同樣的問題,可以也嘗試用該方法獲取編碼。
import chardet
def detect_file_encoding(file_path):
with open(file_path, 'rb') as f:
result = chardet.detect(f.read())
return result['encoding']
file_path = '/Users/rude3knife/Desktop/三國演義.txt'
encoding = detect_file_encoding(file_path)
print(f'The encoding of file {file_path} is {encoding}')
# 輸出
The encoding of file /Users/yangzhendong/Desktop/三國演義.txt is UTF-16
分隔檔案
通常來說檔案都是很大的,比如名著小說,法律檔案,我們通過langchain提供的CharacterTextSplitter來幫我們分割文字:
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=0)
embedding
我們選擇魔搭平臺ModelScope裡的通用中文embeddings演演算法(damo/nlp_corom_sentence-embedding_chinese-base)來作為我們的embedding演演算法。他有768維的向量。

為啥要選擇魔搭而不選擇Huggingface,因為...在程式碼裡跑Langchain,連魔搭平臺比較快,連不上Huggingface的原因你懂得。而且魔搭畢竟是達摩院的,自家人平臺的還得支援一下。
query
將兩個檔案準備好後,我們進行提問,「美猴王是誰?」 要求返回5個相似答案。下面的返回的答案,可以看到,5個檔案都是取自西遊記.txt中的文字。
==========
metadata: {'source': '/Users/yangzhendong/Desktop/西遊記.txt'}
page_content: 美猴王一見,倒身下拜,磕頭不計其數,口中只道:「師父,師父!我弟子志心朝禮,志心朝禮!」祖師道:「你是那方人氏?且說個鄉貫姓名明白,再拜。」猴王道:「弟子乃東勝神洲傲來國花果山水簾洞人氏。」祖師喝令:「趕出去!他本是個撒詐搗虛之徒,那裡修什麼道果!」猴王慌忙磕頭不住道:「弟子是老實之言,決無虛詐。」祖師道:「你既老實,怎麼說東勝神洲?那去處到我這裡,隔兩重大海,一座南贍部洲,如何就得到此?」猴王叩頭道:「弟子飄洋過海,登界遊方,有十數個年頭,方才訪到此處。」祖師道:「既是逐漸行來的也罷。你姓什麼?」猴王又道:「我無性。人若罵我我也不惱,若打我我也不嗔,只是陪個禮兒就罷了,一生無性。」祖師道:「不是這個性。你父母原來姓什麼?」猴王道:「我也無父母。」祖師道:「既無父母,想是樹上生的?」猴王道:「我雖不是樹上生,卻是石里長的。我只記得花果山上有一塊仙石,其年石破,我便生也。」祖師聞言暗喜道:「這等說,卻是個天地生成的,你起來走走我看。」猴王縱身跳起,拐呀拐的走了兩遍。
==========
metadata: {'source': '/Users/yangzhendong/Desktop/西遊記.txt'}
page_content: 太宗更喜,教:「光祿寺設宴,開東閣酬謝。」忽見他三徒立在階下,容貌異常,便問:「高徒果外國人耶?」長老俯伏道:「大徒弟姓孫,法名悟空,臣又呼他為孫行者。他出身原是東勝神洲傲來國花果山水簾洞人氏,因五百年前大鬧天宮,被佛祖困壓在西番兩界山石匣之內,蒙觀音菩薩勸善,情願皈依,是臣到彼救出,甚虧此徒保護。二徒弟姓豬,法名悟能,臣又呼他為豬八戒。他出身原是福陵山雲棧洞人氏,因在烏斯藏高老莊上作怪,即蒙菩薩勸善,虧行者收之,一路上挑擔有力,涉水有功。三徒弟姓沙,法名悟淨,臣又呼他為沙和尚。他出身原是流沙河作怪者,也蒙菩薩勸善,秉教沙門。那匹馬不是主公所賜者。」太宗道:「毛片相同,如何不是?」三藏道:「臣到蛇盤山鷹愁澗涉水,原馬被此馬吞之,虧行者請菩薩問此馬來歷,原是西海龍王之了,因有罪,也蒙菩薩救解,教他與臣作腳力。當時變作原馬,毛片相同。幸虧他登山越嶺,跋涉崎嶇,去時騎坐,來時馱經,亦甚賴其力也。」
==========
metadata: {'source': '/Users/yangzhendong/Desktop/西遊記.txt'}
page_content: 第七十回 妖魔寶放煙沙火 悟空計盜紫金鈴
卻說那孫行者抖擻神威,持著鐵棒,踏祥光起在空中,迎面喝道:「你是那裡來的邪魔,待往何方猖獗!」那怪物厲聲高叫道:「吾黨不是別人,乃麒麟山獬豸洞賽太歲大王爺爺部下先鋒,今奉大王令,到此取宮女二名,伏侍金聖娘娘。你是何人,敢來問我!」行者道:「吾乃齊天大聖孫悟空,因保東土唐僧西天拜佛,路過此國,知你這夥邪魔欺主,特展雄才,治國祛邪。正沒處尋你,卻來此送命!」那怪聞言,不知好歹,展長槍就刺行者。行者舉鐵棒劈面相迎,在半空裡這一場好殺:
棍是龍宮鎮海珍,槍乃人間轉鍊鐵。凡兵怎敢比仙兵,擦著些兒神氣洩。大聖原來太乙仙,妖精本是邪魔孽。鬼祟焉能近正人,一正之時邪就滅。那個弄風播土唬皇王,這個踏霧騰雲遮日月。丟開架子賭輸贏,無能誰敢誇豪傑!還是齊天大聖能,乒乓一棍槍先折。
==========
metadata: {'source': '/Users/yangzhendong/Desktop/西遊記.txt'}
page_content: 菩薩引眾同入裡面,與玉帝禮畢,又與老君、王母相見,各坐下,便問:「蟠桃盛會如何?」玉帝道:「每年請會,喜喜歡歡,今年被妖猴作亂,甚是虛邀也。」菩薩道:「妖猴是何出處?」玉帝道:「妖猴乃東勝神洲傲來國花果山石卵化生的。當時生出,即目運金光,射衝斗府。始不介意,繼而成精,降龍伏虎,自削死籍。當有龍王、閻王啟奏。朕欲擒拿,是長庚星啟奏道:‘三界之間,凡有九竅者,可以成仙。’朕即施教育賢,宣他上界,封為御馬監弼馬溫官。那廝嫌惡官小,反了天宮。即差李天王與哪吒太子收降,又降詔撫安,宣至上界,就封他做個‘齊天大聖’,只是有官無祿。他因沒事幹管理,東遊西蕩。朕又恐別生事端,著他代管蟠桃園。他又不遵法律,將老樹大桃,盡行偷吃。及至設會,他乃無祿人員,不曾請他,他就設計賺哄赤腳大仙,卻自變他相貌入會,將仙餚仙酒盡偷吃了,又偷老君仙丹,又偷御酒若干,去與本山眾猴享樂。朕心為此煩惱,故調十萬天兵,天羅地網收伏。這一日不見回報,不知勝負如何。」
==========
metadata: {'source': '/Users/yangzhendong/Desktop/西遊記.txt'}
page_content: 行者道:「實不瞞師父說,老孫五百年前,居花果山水簾洞大展英雄之際,收降七十二洞邪魔,手下有四萬七千群怪,頭戴的是紫金冠,身穿的是赭黃袍,腰繫的是藍田帶,足踏的是步雲履,手執的是如意金箍棒,著實也曾為人。自從涅脖罪度,削髮秉正沙門,跟你做了徒弟,把這個金箍兒勒在我頭上,若回去,卻也難見故鄉人。師父果若不要我,把那個《鬆箍兒咒》念一念,退下這個箍子,交付與你,套在別人頭上,我就快活相應了,也是跟你一場。莫不成這些人意兒也沒有了?」唐僧大驚道:「悟空,我當時只是菩薩暗受一卷《緊箍兒咒》,卻沒有什麼鬆箍兒咒。」行者道:「若無《鬆箍兒咒》,你還帶我去走走罷。」長老又沒奈何道:「你且起來,我再饒你這一次,卻不可再行凶了。」行者道:「再不敢了,再不敢了。」又伏侍師父上馬,剖路前進。
卻說那妖精,原來行者第二棍也不曾打殺他。那怪物在半空中,誇獎不盡道:「好個猴王,著然有眼!我那般變了去,他也還認得我。這些和尚,他去得快,若過此山,西下四十里,就不伏我所管了。若是被別處妖魔撈了去,好道就笑破他人口,使碎自家心,我還下去戲他一戲。」好妖怪,按聳陰風,在山坡下搖身一變,變成一個老公公,真個是:
總結
目前向量資料庫在AI中的應用越來越重要,但很多廠商更傾向於將向量資料庫隱藏在產品內部,使用者感知不到很多向量資料庫的使用細節。但大模型的學習終究是建立在開原始碼之上的,學習Chroma可以讓我們快速瞭解向量資料庫的基本原理,也有利於我們未來更好地理解大模型。
參考
https://guangzhengli.com/blog/zh/vector-database/#特徵和向量
https://luxiangdong.com/2023/09/19/emb/#/Redis-VSS演示
https://blog.csdn.net/engchina/article/details/131868860
https://github.com/chroma-core/chroma