有效降低資料庫儲存成本方案與實踐
背景
隨著平臺的不斷壯大,業務的不斷髮展,後端系統的資料量、儲存所使用的硬體成本也逐年遞增。從發展的眼光看,業務與系統要想健康的發展,成本增加的問題必須重視起來。目前業界普遍認同開源節流大方向,很多企業部門也針對資料庫儲存降低成本進行了嘗試,有的刪資料、有的刪索引、有的做壓縮、有的做冷熱分離,方式方法層出不窮,不一而足,然而不是因為收效甚微而導致沒有達到預期,就是由於改造成本過大,投入週期過長,導致投產比不高,虛耗人力。筆者目前所在部門也正好面臨同一問題,一個賬單系統,儲存資料超過100T,佔用40臺物理機,40庫,一個分表就有20480張,這樣的分表有4個,這種儲存架構相對臃腫,要想實踐降低成本的訴求,難度很高。
本文主要介紹方法,方案也會涉及,但不會特別細緻的展開。
挑戰
核心挑戰有以下幾個:
資料安全問題:無論是刪資料,做壓縮,冷熱分離,對於已經佔據100T磁碟空間的儲存系統都是困難的操作,一個不小心,資料丟失了,或者無法正常獲取資料了,這些問題對部門、對公司都會造成巨大損失。
系統穩定性問題:一些有效的降低儲存空間的方案,如資料序列化、壓縮等,無外乎是用時間換空間,犧牲效能換取磁碟空間的降低,那麼從實際業務影響來看,使用者看到頁面的耗時增高了(讀延時),或使用者看到自己的資料遲遲未更新(寫延時),使用者的使用體驗會降低。從系統影響的角度來看,讀寫耗時的增高,對於系統本身飽和度會產生影響,寫方面,吞吐量下降了,讀方面,耗時增加了,這些變化會導致系統執行緒數增高甚至導致執行緒堆積,cpu佔用也會相應增高,最終可能會產生系統拒絕請求,系統夯住等問題。
收益問題:中文網際網路上,資料庫儲存成本降低方案永遠能看到一些詞彙,如「刪索引」,「後設資料清理」,「冷熱分離」等,這些眼熟的詞彙,看似收益不錯,大家也常提起。然而,刪索引的收益受到實際使用索引的情況,收益浮動非常之大。我們都知道索引有單欄位索引,有多欄位的聯合索引,聯合索引會產生笛卡爾積的複雜度,如5歲的張三,6歲的張三,5歲的李四,10歲的李四等等,這樣則不好測算刪除某個索引所帶來的正向收益。因此刪除索引這個方案通常是在索引濫用的情況下使用,在清理濫用索引的過程中,附帶降低了一些磁碟佔用。而「冷熱分離」是另一種極端,它改變了原有系統的儲存架構,架構合理性也許會提升,但這個系統改造成本是巨大的,如冷熱資料的同步機制,冷資料的遷移方案,原資料庫冷資料清理方案,冷資料壓縮方案、生產灰度方案等。改造成本非常高,週期長,耗費人力大,風險還非常高,唯一值得欣慰的是效果通常能夠達到預期。
體系化方法
| 欄位 | 表 | 庫 | |
|---|---|---|---|
| 刪 | 刪除無效表 | ||
| 減 | 減少無效資料 減少無效索引 | ||
| 縮 | 大欄位壓縮 | 大表壓縮 | 冷熱分離 |
中文網際網路上的縮減資料庫磁碟空間的方案很多,但大多是方案的陳述,對於如何針對目標系統制定適合的縮減方案的內容很少,其實按照麥肯錫切分法的邏輯切分法就可進行一個方法總結。上圖的九宮格,就是按照筆者的實踐經驗,總結出一個體系化成本降低的方法。
九宮格
按邏輯梳理的辦法,方案可針對欄位、表和庫3個維度,結合刪、減、縮3種策略進行梳理,如刪除表、清理部分表資料、壓縮部分表的儲存空間等。結合系統的實際情況,按照表格進行梳理,就能得到適合目標系統的成本降低方案了。
筆者通過表格,結合賬單系統實際情況,梳理出的執行的方案,1、大表壓縮,2、大JSON欄位序列化,3、刪除無效資料,4、無效表刪除,5、無效索引刪除,6、冷熱分離。
這麼多的方案,總不能囫圇吞棗的瞎幹吧,優先幹哪個呢?他們的收益又是怎麼樣的呢?
收益測算
在實際的方案階段,都需要對方案產生的收益進行度量,再按照投產比,決定方案執行的優先順序。
測算方法
無論何種方案,測算起來無外乎抽樣、估算減少量、計算佔比幾個過程。
舉個例子
以大JSON欄位序列化為例,某個欄位儲存的是大json串,佔用的字元比較多,因此對該欄位做壓縮,能夠有效的降低磁碟佔用空間。這個方案如何測算呢?思路是這樣的,首先計算出目標大json欄位佔一條資料字元長度的比例,然後根據壓縮比,得出壓縮後該欄位減少的字元數佔比,之後抽樣此表的data檔案佔的磁碟空間(如3g),得出單表通過壓縮後下降的磁碟空間(如1.2g),最終再乘以該表的數量(如20480),就能估算出最終減少的磁碟空間。最終計算公式: [壓縮後減少的字元數/總字元數]_單表空間_表數量=[大json字元數*(1-壓縮比)/總字元數]_單表空間_表數量=12t 磁碟減少佔比:12t/95.9t=12%
如何得到欄位的字元數?
可運用select LENGTH語法得出。具體計算可參照下表:

最終賬單系統各方案的測算結果,大表壓縮32%,大JSON欄位序列化12%,刪除無效資料10%,無效表刪除與無效索引刪除都在1%左右。通過測算情況,我們就可以建立方案執行的優先順序了,step1大表壓縮,step2大JSON欄位序列化,step3刪除無效資料等。冷熱分離有收益,但是成本太高,可在日後架構升級中,再去考慮。
資料安全與系統穩定性
前文提到過,無論採用何種方案,資料安全與系統穩定性都需要驗證的,資料丟失、或系統不可用、或降低使用者體驗下降過多都是不可接受的。因此需要保障這些情況儘量不要發生,或即使發生了,問題也在可控、可接受範圍內。
方法
黃金指標
任何穩定性或安全性問題,都可通過google SRE的4個黃金指標去歸納,即異常(exception)、耗時(tp99等)、流量(tps)、飽和度(cpu、記憶體、磁碟、網路等)。
可以結合目標系統的關鍵時段來看這4個黃金指標,例如大表壓縮方案,那就可以關注壓縮時的異常、耗時等,壓縮後的異常耗時等等。
結合實際驗證項
壓縮時:1、讀寫耗時是否增加?2、吞吐量是否受到影響?3、壓縮是否會產生異常?4、異常後壓縮過程能否正常回滾?5、壓縮是否會導致資料丟失?
壓縮後&大促高峰期:1、讀寫耗時是否增加?2、吞吐量是否受到影響?3、壓縮後大促流量是否能夠應對?
這些問題如果有一項未驗證或驗證未通過,都不能執行壓縮方案,因為方案執行後可能會對資料安全與系統穩定造成影響。
如何驗證呢?
最嚴重的問題壓縮是否會導致資料丟失,想通過一些方法驗證這個問題非常困難的,只能通過mysql的壓縮過程原理去分析。

從官方檔案中提煉出了Online DDL的4個步驟,從圖中可看出,在任何階段原表資料都不會丟失,直到完成切換後,原表才會被定期清理,因此壓縮過程中資料是安全的。
第二個需要驗證的是壓縮時、壓縮後與大促高峰期整個系統的讀寫耗時與吞吐量。
第一步:搭建等比驗證環境
以文中賬單系統實踐為例,將生產的一個分庫完全複製到一個新的物理機上,這樣就以20:1的比例搭建了驗證庫。
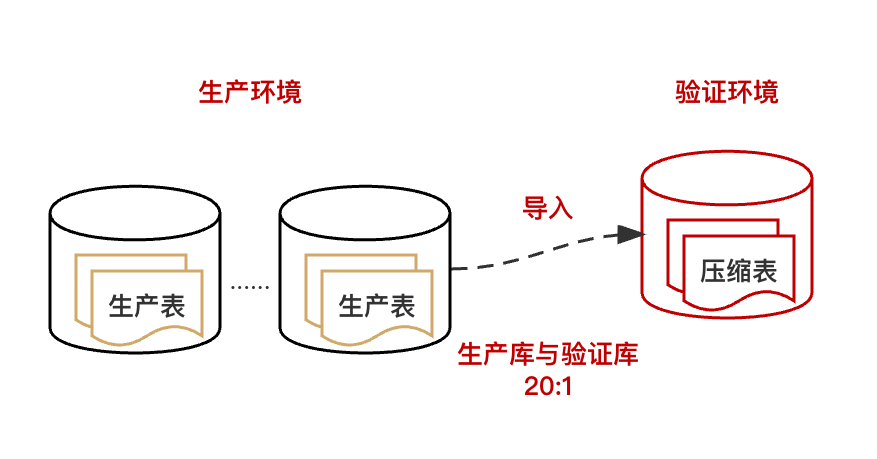
第二步:模擬流量
這一步,需要結合目標系統的實際情況,完全模擬系統高峰期的流量,文中的賬單系統是通過改造程式碼來達到流量預期的,如果所在部門原本就具備壓測條件,可直接調整壓測robot的流量開啟壓測程式來達到流量預期。

流量達標後,通過觀察壓縮時或壓縮後系統的吞吐量、寫入的耗時以及慢sql等情況,來判斷壓縮對系統及資料庫的影響。如果此步發現了明顯的慢sql或吞吐量異常,就需要考量這些情況是否會影響系統的SLA指標,同時還要考量系統及業務能否容忍壓縮所帶來的負面影響。
壓縮回滾問題
賬單系統在做模擬流量壓測時,意外的發生了異常,導致了壓縮過程回滾。這也變相驗證了,壓縮過程是可回滾的。異常比較常見,duplicate key,這個異常是唯一索引重複導致。這個問題需要重視,因為賬單系統會接收各種業務方的mq訊息,難免會有這種重複下發過來的mq,如果經常出現這種異常,最壞的情況是某些相關表永遠無法壓縮成功。如下圖

解決這個問題的方法很多,這裡不贅述,但異常情況是做壓縮過程中必須避免的。
方案落地
灰度
在方案的落地過程中,需要有灰度過程,來觀察方案在生產環境中的執行是否會產生意料之外的問題。灰度的方法應視具體情況而定,但任何的灰度方案都應該至少考慮故障、業務與效能3個方面。
(故障)影響範圍控制:以小見大,第一階段的灰度一定是以最細顆粒度方案進行落地的,以便觀察系統是否穩定、業務是否正常,這樣即使出現意料之外的問題,影響的使用者也是非常少的,不至於引起輿情。以表壓縮為例,剛開始只壓縮一張表,觀察情況,隨時準備回滾。
(業務)全場景安全:遵循灰度週期遞減的方式,第一階段灰度開始時,經歷的時間要足夠長,確保新的內容已經經歷過所有生產場景(all story)的考驗,這樣能夠保障新的內容在業務上是正確的,之後可以逐步的縮短驗證週期,加快灰度程序。
(效能)高流量驗證:高峰期考驗,每個灰度階段都至少經歷一個流量高峰期,來驗證新內容的效能是否能夠承受高峰流量。為什麼每個灰度階段都要經歷高峰期流量,第一階段灰度的時候已經經歷過一次高峰期流量驗證了嗎?這樣做驗證邏輯是有漏洞的,系統作為一個整體,當其中大部分內容替換成新內容後,整個系統飽和度會隨之產生變化,如表壓縮場景,是用時間換空間,因此可能影響系統的吞吐量,起初壓縮一張表時,高峰期系統吞吐量可能並沒有什麼影響,之後壓縮100張表後,高峰期系統開始有些流量積壓,到最後10000張表壓縮後,高峰期系統可能產生大量積壓。像吞吐量這種宏觀指標,在每個灰度階段都必須關注。因此每個灰度階段,都必須經歷至少一個流量高峰期,才能證明系統的效能是沒問題的。
回滾
在方案的灰度過程中,必須有相應的回滾手段,以便灰度產生問題後,能夠及時的回滾止損。回滾方案中,需要注意的有兩點,1是及時,2是有效,如壓縮方案中的回滾方案是解壓縮命令(通過alter),及時提工單即可執行。
總結
本文主要以介紹方法為主,落地過程可以歸納為方案->收益測算->資料安全驗證->系統穩定性驗證->灰度與回滾。文中的賬單系統通過step1大表壓縮32%,step2大JSON欄位序列化12%,step3刪除無效資料10%,3個方案的順利落地,有效的減少了50.7%的磁碟空間,成本下降也非常顯著。最後,希望此文能夠給還在迷茫,不知從何處下手落地資料庫儲存成本降低的同學一些啟發和靈感,以上。
作者:京東科技 李陽
來源:京東雲開發者社群 轉載請註明來源