🔥🔥你真的知道TCP協定中的序列號確認、上層協定及記錄標識問題嗎?
引言
在前面的內容中,我們已經詳細講解了一系列與TCP相關的面試問題。然而,這些問題都是基於個別知識點進行擴充套件的。今天,我們將重點討論一些場景問題,並探討如何解決這些問題。
序列號確認問題
當A主機與B主機建立了TCP連線後,A主機傳送了兩個TCP報文,分別大小為500和300位元組。第一個報文的序列號為200。那麼當B主機接收到這兩個報文後,返回的確認號應該是多少呢?
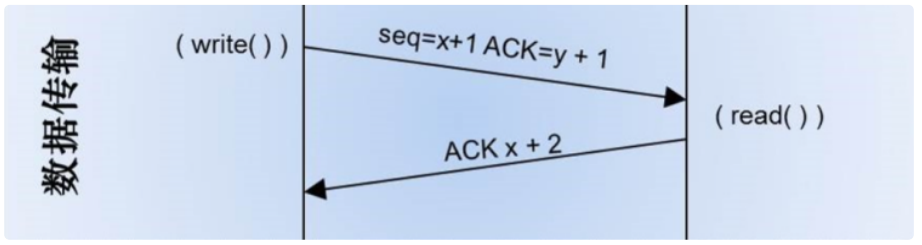
當A主機傳送第一個TCP報文時,序列號為200,大小為500。因此,A主機傳送的資料範圍是200-699(包括200和699)。
當A主機傳送第二個TCP報文時,序列號為700,大小為300。因此,A主機傳送的資料範圍是700-999(包括700和999)。
當B主機接收到這兩個報文後,確認號應該是下一個預期的序列號。根據TCP的規則,下一個預期的序列號應該是接收到的最後一個位元組的序列號加上1。
所以,B主機接收到的最後一個位元組的序列號是999,因此,返回的確認號應該是1000。
為什麼增加的是tcp包的大小而不是單純+1呢?為什麼增加的是TCP包的大小而不是簡單地加1呢?在TCP協定中,確認號是基於接收到的資料位元組數來計算的,而不是簡單地加1。
當B主機接收到A主機傳送的第一個500位元組的TCP報文時,B主機期望下一個位元組的序列號是200 + 500 = 700。由於TCP是面向位元組的傳輸協定,每個位元組都有一個唯一的序列號,因此確認號是基於已接收位元組的累積值。所以,B主機返回的確認號是700。
接著,當B主機接收到A主機傳送的第二個300位元組的TCP報文時,B主機期望下一個位元組的序列號是700 + 300 = 1000。因此,B主機返回的確認號是1000。
如何確定上層協定?
收到一個IP封包後,作業系統中的網路協定棧會進行解析。在解析過程中,有一個關鍵步驟是確定該封包應該投遞到上層的哪個協定(UDP或TCP)。
為了更好地理解這個過程,我們先來看一下分層協定結構示意圖:
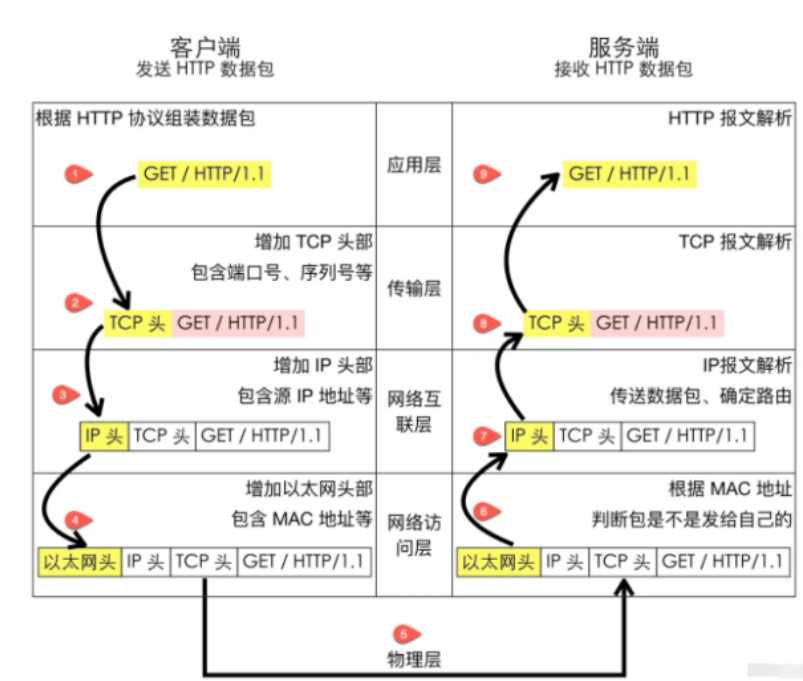
可以看到,在包裝完TCP頭資訊之後,才會包裝IP頭資訊。因此,在IP頭部中應該能夠得知當前是什麼協定的封包。接下來,我們來具體檢視一下IP頭資訊的示意圖:

在IP協定中,協定欄位用於區分上層協定。在Linux系統的/etc/protocols檔案中定義了所有上層協定對應的協定欄位。例如,ICMP的協定欄位為1,TCP的協定欄位為6,UDP的協定欄位為17。
我們知道TCP和UDP是伺服器傳輸資料的常用協定。而ICMP則是用於傳輸網路傳輸過程中的一些中間鏈路的錯誤資訊反饋。正如之前提到的,路由器等網路裝置屬於三層協定,它們可以判定並修改IP頭部中的資訊。
因此,通過對IP頭部中的協定欄位進行解析,作業系統可以確定接收到的封包應該傳遞給哪個上層協定進行處理。
應用程式應該如何提供他們自己的記錄標識?
TCP提供了一種位元組流服務,其中傳送方和接收方都不維護記錄的邊界。這意味著在傳輸過程中,資料可能會被分割成多個TCP段,而接收方需要確定每個段屬於哪個應用程式的記錄。應⽤程式應該如何提供他們自己的記錄標識呢?
為了實現這一點,應用程式可以使用一些方法來提供自己的記錄標識。以下是一些常用的方法:
- 使用特定的協定頭或識別符號:應用程式可以在傳送的資料中新增特定的協定頭或識別符號,以便接收方能夠識別和組合相關的資料段。例如,在Redis的通訊協定(RESP協定)中,每個命令或資料都以特定的控制字元"\r\n"作為結束符,這樣接收方就能夠根據這些結束符來識別和組合記錄。
- 使用固定長度的資料塊:應用程式可以將資料劃分為固定長度的資料塊,並在每個資料塊前新增標識資訊。接收方可以根據這些標識資訊來組合和還原應用程式的記錄。
- 使用訊息邊界標記:應用程式可以在資料中使用特定的訊息邊界標記,例如特殊字元或預定的控制序列。接收方根據這些邊界標記來確定每個記錄的邊界。
通過使用這些方法,應用程式可以在資料傳輸過程中進行分段和還原,從而實現記錄的完整性和可靠性。這些方法能夠提供自定義的記錄標識,使得資料能夠準確地組合和還原為應用程式的記錄。
TCP 和 UDP 的區別
TCP(傳輸控制協定)和UDP(使用者資料包協定)是兩種常見的網際網路傳輸協定,它們在網路通訊中有以下幾個主要的區別:
- 連線性:TCP是面向連線的協定,它在通訊前需要建立一個可靠的連線,然後再進行資料傳輸。而UDP是無連線的協定,它不需要建立連線就可以直接傳送資料。
- 可靠性:TCP提供可靠的資料傳輸,它使用確認機制、重傳機制、流量控制、擁塞控制和序列號等技術來確保資料的完整性和有序性。UDP則不提供可靠性保證,它只是簡單地將封包傳送出去,並不關心是否能夠到達目標。
- 速度:由於TCP提供了可靠性保證和流量控制等機制,因此它的傳輸速度相對較慢。而UDP沒有這些額外的機制,所以傳輸速度比TCP快。
- 佔用資源:TCP需要維護連線狀態和快取等資訊,因此佔用的系統資源較多。而UDP不需要維護連線狀態,所以佔用的系統資源較少。
- 適用場景:由於TCP提供了可靠性保證,所以在需要確保資料完整性和有序性的場景下使用較多,如檔案傳輸、網頁瀏覽等。而UDP適用於實時性要求較高的場景,如視訊和音訊串流媒體、線上遊戲等。
總結
通過本文的講解,我們瞭解了一些關於TCP的場景問題及其解決方法。我們學習瞭如何確定TCP報文的應答號,通過解析IP頭部的協定欄位來確定封包的上層協定,以及應用程式如何提供自己的記錄標識。此外,我們還比較了TCP和UDP的區別,包括連線性、可靠性、速度、資源佔用和適用場景等方面。通過深入理解這些問題,我們可以更好地應對TCP相關的面試和實際應用場景。