範例講解資料庫的資料去重
本文分享自華為雲社群《GaussDB資料庫SQL系列-資料去重》,作者: Gauss松鼠會小助手2 。
一、前言
資料去重在資料庫中是比較常見的操作。複雜的業務場景、多業務線的資料來源等等,都會帶來重複資料的儲存。本文以GaussDB資料庫為實驗平臺,將為大家詳細講解如何去重。
二、資料去重應用場景
• 資料庫管理(含備份):在資料庫中進行資料去重可以避免資料重複儲存、備份,提高資料庫的儲存效率、降低備份的儲存成本。
• 資料整合:在資料整合的過程中,需要合併多個資料來源的資料,去重可以避免重複的資料對合並結果的影響。
• 資料分析(或挖掘):在進行資料分析或資料探勘時,去重可以避免重複的資料對分析或挖掘結果的干擾,提高分析的準確性。
• 電商平臺:在電商平臺上進行商品去重可以避免重複上架相同的商品,提高平臺的使用者體驗。
• 金融風控:在金融風控領域,去重可以避免重複的資料對風控模型的影響,提高風控的準確性。
三、資料去重案例(GaussDB)
實戰業務場景 + GaussDB資料庫
1、範例場景描述
以保險行業的客戶資訊除重為例,為防止坐席重複聯絡客戶(容易造成客戶投訴),需要將客戶進行唯一身份識別。存在以下兩種情況,需要將其識別成一個人(唯一),這時候就需要進行資料去重的動作。
• 情況一:同一個客戶有不同的來源渠道:客戶即購買了壽險、又購買了產險(兩個不同的來源系統);
• 情況二:同一個客戶多次迴流:客戶在同一個渠道多次購買(續保或者購買同一險種的不同產品)。
2、定義重複資料
通過「姓名+證件型別+證件號」將其識別為一個人,即只要這三個欄位重複,就認為這些資料行為重複資料。 (當然還有更復雜的場景,例如,「姓名+證件型別+證件號+手機號+車牌號」等,本次不做詳細介紹)。

3、制定去重規則
1)多選一
• 隨機:根據去重規則,隨機保留一條資料。
• 優先順序:根據去重規則 + 業務邏輯,保留優先需要的一條資料。例如優先保留「是否有房、是否有車」。
2)多合一
• 將重複資料合併成一條資料,合併規則根據業務邏輯確定。
4、建立測試資料(GaussDB)
客戶資訊欄位主要包含「姓名、性別、出生年月日、證件型別、證件號、來源、是否有車、是否有房、婚姻狀態、手機號、……」等資訊。
--建立客戶資訊表 CREATE TABLE customer( name VARCHAR(20) ,sex INT ,birthday VARCHAR(10) ,ID_type INT ,ID_number VARCHAR(20) ,source VARCHAR(10) ,IS_car INT ,IS_house INT ,marital_status INT ,tel_number VARCHAR(15) ); --插入測試資料 INSERT INTO customer VALUES('張三','1','1988-01-01','1','61010019880101****','壽險','1','1','1',''); INSERT INTO customer VALUES('張三','1','1988-01-01','1','61010019880101****','車險','1','0','1',''); INSERT INTO customer VALUES('張三','1','1988-01-01','1','61010019880101****','','','','','186****0701'); INSERT INTO customer VALUES('李四','1','1989-01-02','1','61010019890102****','壽險','1','1','1',''); INSERT INTO customer VALUES('李四','1','1989-01-02','1','61010019890102****','車險','1','0','1',''); INSERT INTO customer VALUES('李四','1','1989-01-02','1','61010019890102****','','','','','186****0702'); --檢視結果 SELECT * FROM customer;
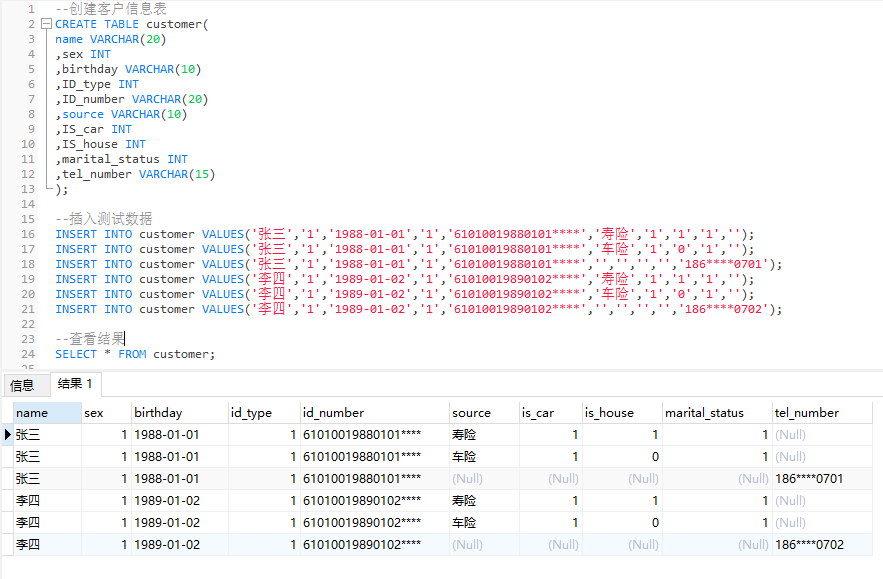
Tip: 部分為INT型別的欄位值取字典表的值,此處省。
5、編寫去重方法(GaussDB)
以下範例中不包含過多的資料淨化、資料脫敏、業務邏輯等的處理,這些步驟均建議進行「前置」處理。本次範例重點描述去重的過程。
1)隨機保留:根據業務邏輯,隨機保留一條記錄。
SELECT * FROM (SELECT * ,ROW_NUMBER() OVER (PARTITION BY name,id_type,id_number ) as row_num FROM customer) WHERE row_num = 1;
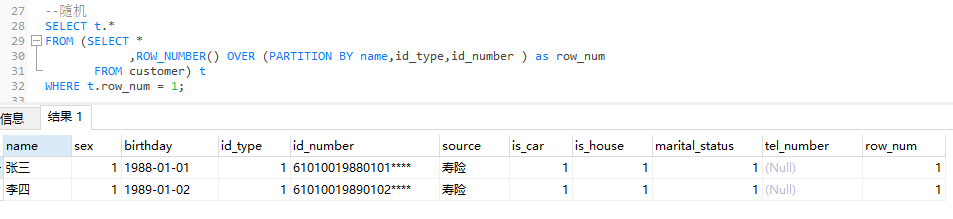
說明:
• ROW_NUMBER(): 從第一行開始,依次為每一行分配一個唯一且連續的編號。
• PARTITION BY col1[, col2...]: 指定分割區的列,例如去重的鍵「姓名、證件型別、證件號碼」。
• WHERE row_num = 1:取ROW_NUMBER()生成的編號1。
2)按優先級保留:根據業務邏輯,優先保留有手機號的一條記錄,如果有多條記錄含有手機號或有沒有手機號,則在此基礎上隨機保留。
--保留含有手機號的記錄行 SELECT t.* FROM (SELECT * ,ROW_NUMBER() OVER (PARTITION BY name,id_type,id_number ORDER BY tel_number ASC) as row_num FROM customer) t WHERE t.row_num = 1;
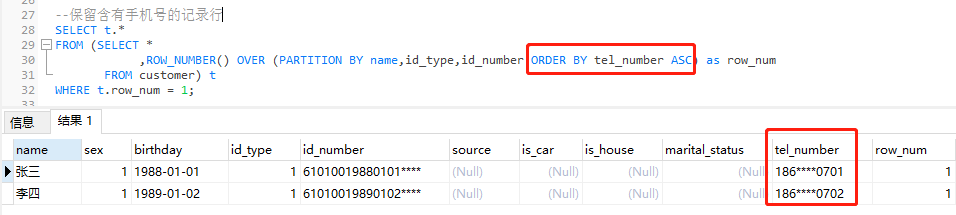
說明:
• ROW_NUMBER(): 從第一行開始,依次為每一行分配一個唯一且連續的號碼。
• PARTITION BY col1[, col2...]: 指定分割區的列,例如去重的鍵「姓名、證件型別、證件號碼」。
• ORDER BY col [asc|desc]: 指定排序的列。升序( ASC )排列指只保留第一行,而降序排列( DESC )則指保留最後一行。
• WHERE row_num = 1:取ROW_NUMBER()生成的編號1。
3)合併保留:根據業務邏輯,合併完整性高、準確性高的欄位資訊。例如優先將含有手機號的記錄行進行補齊,需要補齊的欄位有「是否有車、是否有房、婚姻狀況」,其取值是來源為「車險」的對應記錄。
--合併保留 SELECT t1.name ,t1.sex ,t1.birthday ,t1.id_type ,t1.id_number ,t1.source ,t2.is_car ,t2.is_house ,t2.marital_status ,t1.tel_number FROM (SELECT t.* FROM (SELECT * ,ROW_NUMBER() OVER (PARTITION BY name,id_type,id_number ORDER BY tel_number ASC) as row_num FROM customer) t WHERE t.row_num = 1) t1 LEFT JOIN (SELECT * FROM customer WHERE source ='車險' and is_car IS NOT NULL AND is_house IS NOT NULL AND marital_status IS NOT NULL) t2 ON t1.name =t2.name and t1.id_type=t2.id_type and t1.id_number=t2.id_number
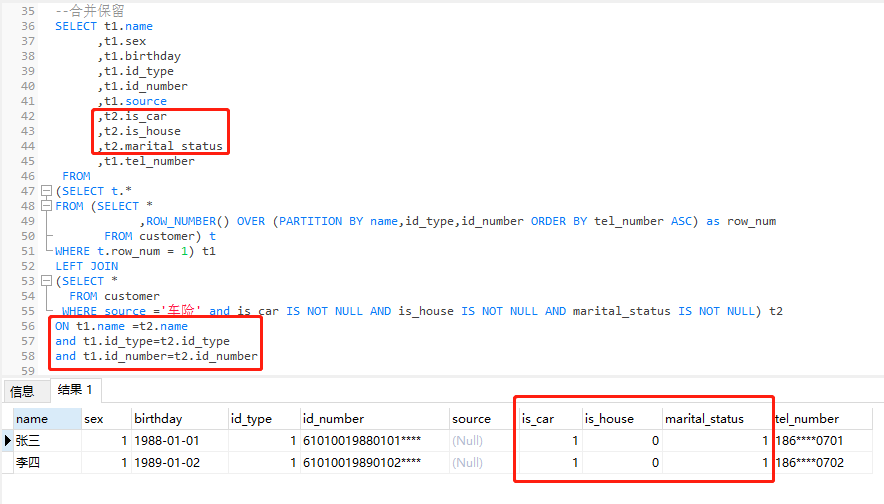
說明:
t1 表是優先保留含有手機的記錄行(去重),並作為主表,t2表是需要補齊的欄位來源表。兩張表通過「姓名+證件型別+證件號碼」進行關聯,然後合併需要的資訊。
6、附:全欄位去重
在資料庫應用時,例如,重複誤操作、資料翻倍等原因造成的全欄位重複,此時也要進行去重。 那除了前面介紹的3種方式外,大家還可以使用關鍵字DISTINCT、UNION 進行去重,但需要注意其資料量及SQL 效能。 (大家自行測試)
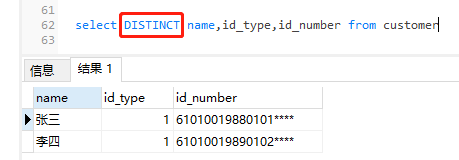
1) DISTINCT (假設全部有如下三個欄位)
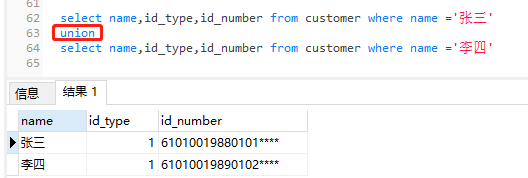
2) UNION(假設全部有如下三個欄位)
四、資料去重效率提升建議
最好的去重其實是在資料來源頭就進行「攔截」。當然了, 因業務流轉也不可能完全避免,但是我們可以提高去重的效率:
• 選擇合適的去重演演算法
根據資料集的特點和規模,選擇適合的去重演演算法,可以大大提高去重效率。
• 優化資料儲存結構
採用合適的資料儲存結構,如雜湊表、B+樹等,可以加快資料的查詢和比較速度,從而提高去重效率。
• 並行化處理
採用並行化處理的方式,將資料集分成多個子集,分別進行去重處理,最後合併結果,可以大大加快去重速度。
• 使用索引加速查詢
對資料集中的關鍵欄位建立索引,可以加速查詢和比較速度,從而提高去重效率。
• 前置過濾
採用前置過濾的方式,先對資料集進行一些簡單的篩選和處理,如去除空值、去除無效字元等,可以減少比較次數,從而提高去重效率。
• 去重結果快取(臨時表)
對去重結果進行快取,可以避免重複計算,從而提高去重效率。
• 不建議重寫(備份)
涉及一些分割區表,等不建議直接將去重後的結果集重寫到生產表,建立臨時換成,或進行備份後操作。
五、總結
資料去重涉及到的面非常廣,包括重複資料的發現、去重規則的定義、去重的方法與效率、去重的困難與挑戰等等。但是,去重原則只有一個,那就是以業務為導向。根據業務需求去定義重複資料、制定去重規則和方案。在GaussDB資料庫的使用過程,我們同樣會遇到去重的場景。本文從應用背景、案例、去重方案等方面給大家做了介紹,歡迎測試、交流。