網際網路那些技術 | 扒一扒網際網路Markdown的那些事兒
最近感覺到 Markdown 似乎已成為各大社群的編輯器標配所支援的格式,側面看來其設計之初的目標 「 to be used as a format for writing for the web.」 已經成為了現實。不妨就扒一扒網際網路 Markdown 的這些事兒。
Markdown 的演進
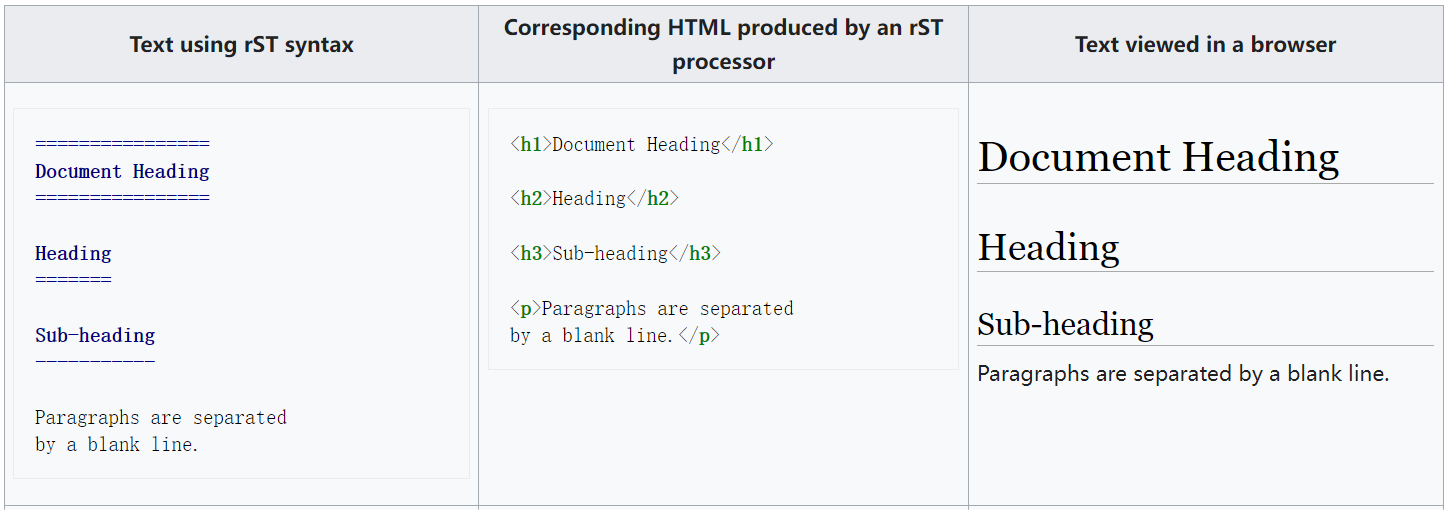
Markdown 是一種標示語言,對比於 HTML 這樣的標示語言來說簡潔很多,因此其描述為輕量級的標示語言(lightweight markup language,簡稱 LML)更為合適。當然,輕量級標示語言並非只有 Markdown,在其之前就有很多種。比如:Setext (Structure Enhanced Text) 用於一些純文字的場景比如 Email、Usenet(新聞組)等。
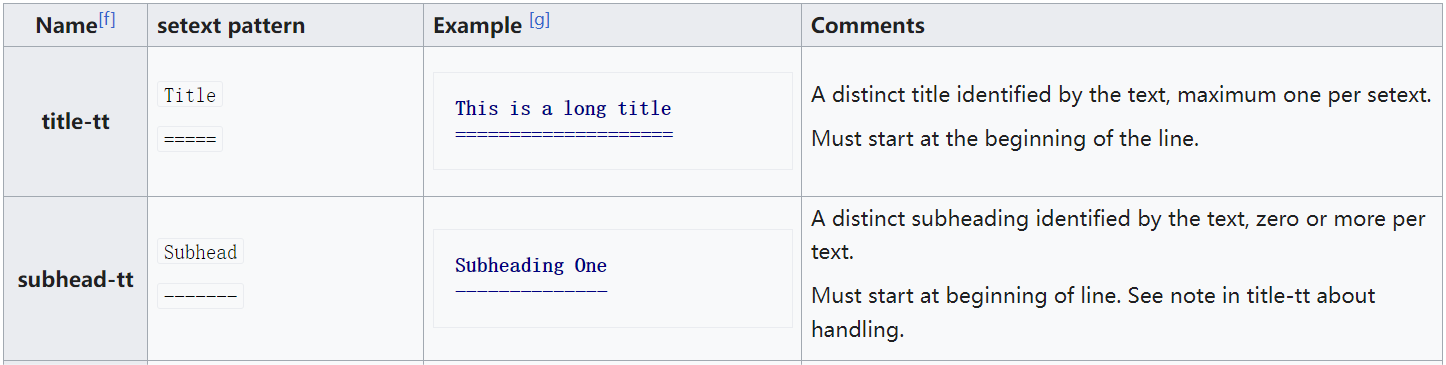
也有能把格式文字轉換為HTML類似早期語言 reStructuredText(rST),為了更好的閱讀 Python原始碼和 Python 技術原始碼而設計。
Markdown 就是在這樣的背景下誕生,在2004年由John Gruber和Aaron Swartz共同建立出來,有興趣的可以看下最初文章《Introducing Markdown》。 這兩個作者也有很多故事,比如Gruber是《The Talk Show》播客節目主持人;Swartz 2013年已經故去,其曾因使用麻省理工頒發給他的訪客使用者帳戶從JSTOR系統下載學術期刊文章,隨後被麻省理工院警方以違反國家和進入國家的指控逮捕。
(PS:筆者並非八卦博主就不多贅述了,感興趣的自行了解)
到了2008年時候 Stack Overflow 的聯合創始人 Jeff Atwood 推其成為 Stack Overflow的編輯方式,並且非常認同其設計;也就是這個時候開始大規模的在程式設計師中流行起來。Github 大概在2009年開始使用 Markdown,並推出擴充套件版 GitHub Flavored Markdown (GFM)。
2012年,Jeff 提議Stack Exchange、GitHub、Meteor、Reddit 等一些存取量大的公司組織一起制定出 Markdown的標準規範和其實現的標準測試用例。2014年的時候釋出了一個Standard Markdown 的專案,不過 Gruber反對使用Markdown的名字,後來最終改成了 CommonMark,其中包含了 600+個測試用例以及 C語言和 JavaScript的實現。
2016年時候 IETF也釋出了徵求意見稿RFC7763,在media type中定義了 test/markdown 的型別;2017年 GFM基於CommonMark Spec正式釋出了 GitHub Flavored Markdown Spec,支援表格、任務列表、禁止HTML等等。
當然到目前 Markdown 演進也遠未結束,除開 GFM 其實還有更多的 基於 CommonMark 的擴充套件,比如微軟的 Markdown for Microsoft Learn 有 !NOTE 的擴充套件語法。
Markdown 解析引擎
Markdown解析引擎也是非常多的,這裡主要介紹一些 JavaScript 開源專案。
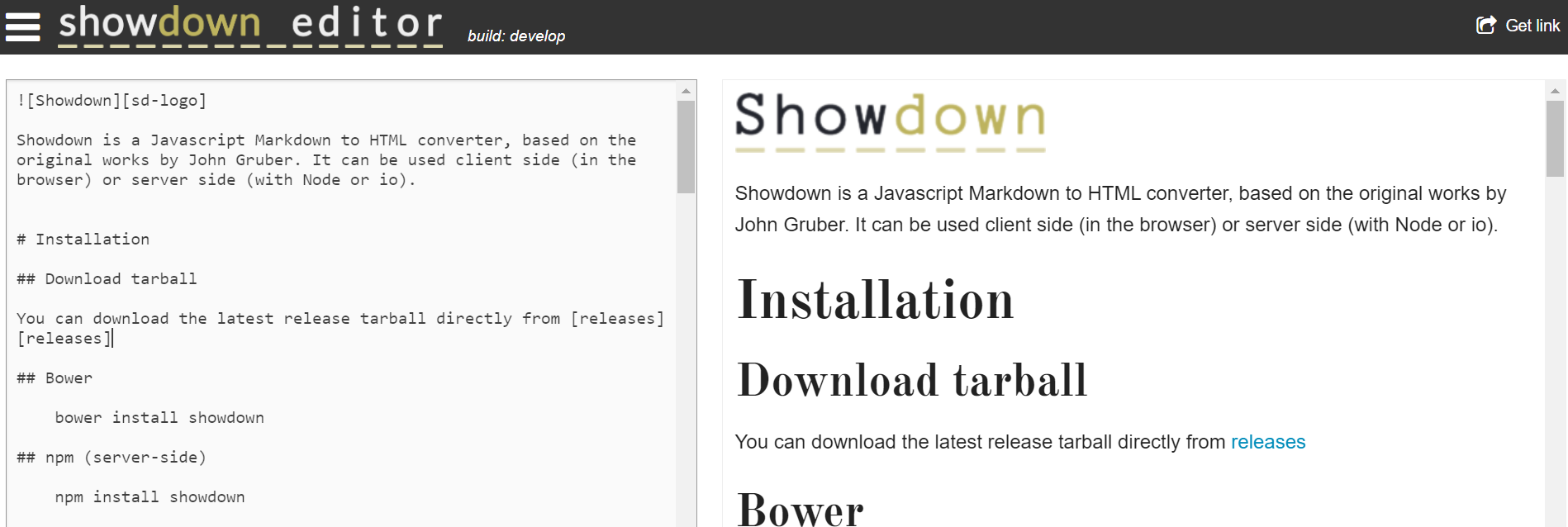
Showdown
正如演進提到的 2004年的時候,Gruber寫了第一個版本的 Markdown 解析引擎 Markdown.pl ; 2007年時候 John Fraser 基於 Gruber的工作成果建立了 Showdown;不過,似乎 Fraser 早已經不再維護了,Corey Innis 將其遷移到了 Github , 從遷移後的提交看 Santos 維護比較多。它除開實現了 Markdown 原始標準外,也支援一些 Atx、Setset的語法規則。比如:# My Heading #等。
基本使用
var showdown = require('showdown'),
converter = new showdown.Converter(),
text = '# hello, markdown!',
html = converter.makeHtml(text);
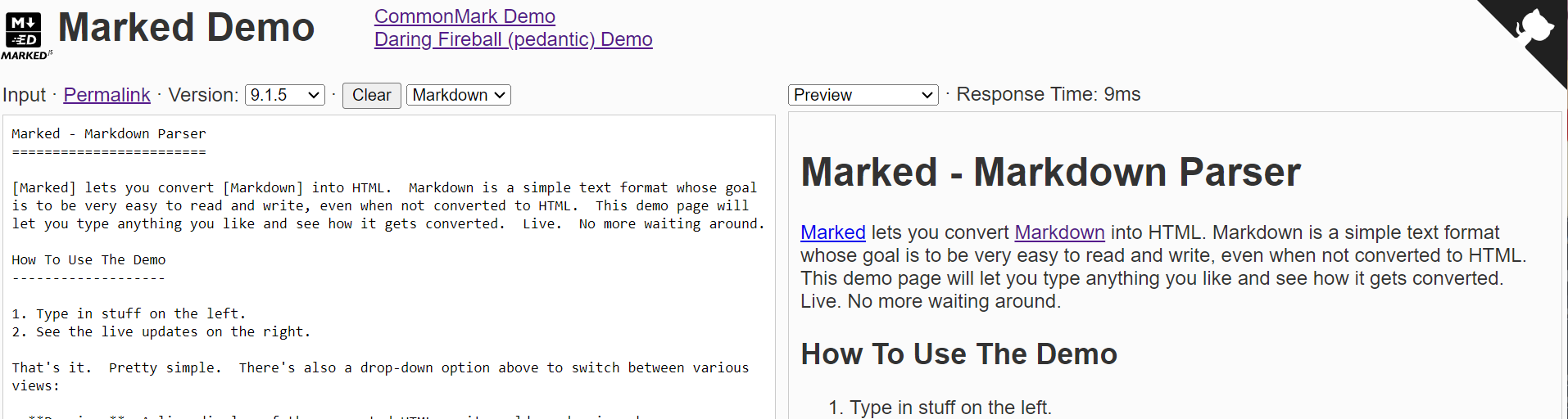
Marked
Marked 同樣也是非常早的 Markdown解析引擎,Christopher Jeffrey在 2011年最早建立的,目前GitHub上已經 30k+ 的收藏。很多產品都在使用,不過雖然其支援CommonMark以及GFM,但是似乎支援的還不夠完整,截至到2022年11月的 V4.2.3 還並沒有 100% 支援到兩大標準。有個有意思的現象,今年其版本更新非常快 2023年3月份還是 V4.3.0 到如今11月份版本迭代到了 V9.1.5。
基本使用
import { marked } from 'marked';
// or const { marked } = require('marked');
const html = marked.parse('# Marked in Node.js');
Commonmark
應該說是 Commonmark Spec的親閨女,John MacFarlane 2014年時候最早建立的,他同時也是標準制定人之一,還是 Pandoc的作者。將Markdown檔案解析成 抽象語法樹(AST),並通過渲染(AST)轉換成 HTML 或者 XML;從筆者測試看其效能非常優異。
基本使用
var reader = new commonmark.Parser();
var writer = new commonmark.HtmlRenderer();
var parsed = reader.parse("Hello *world*"); // parsed is a 'Node' tree
// transform parsed if you like...
var result = writer.render(parsed); // result is a String
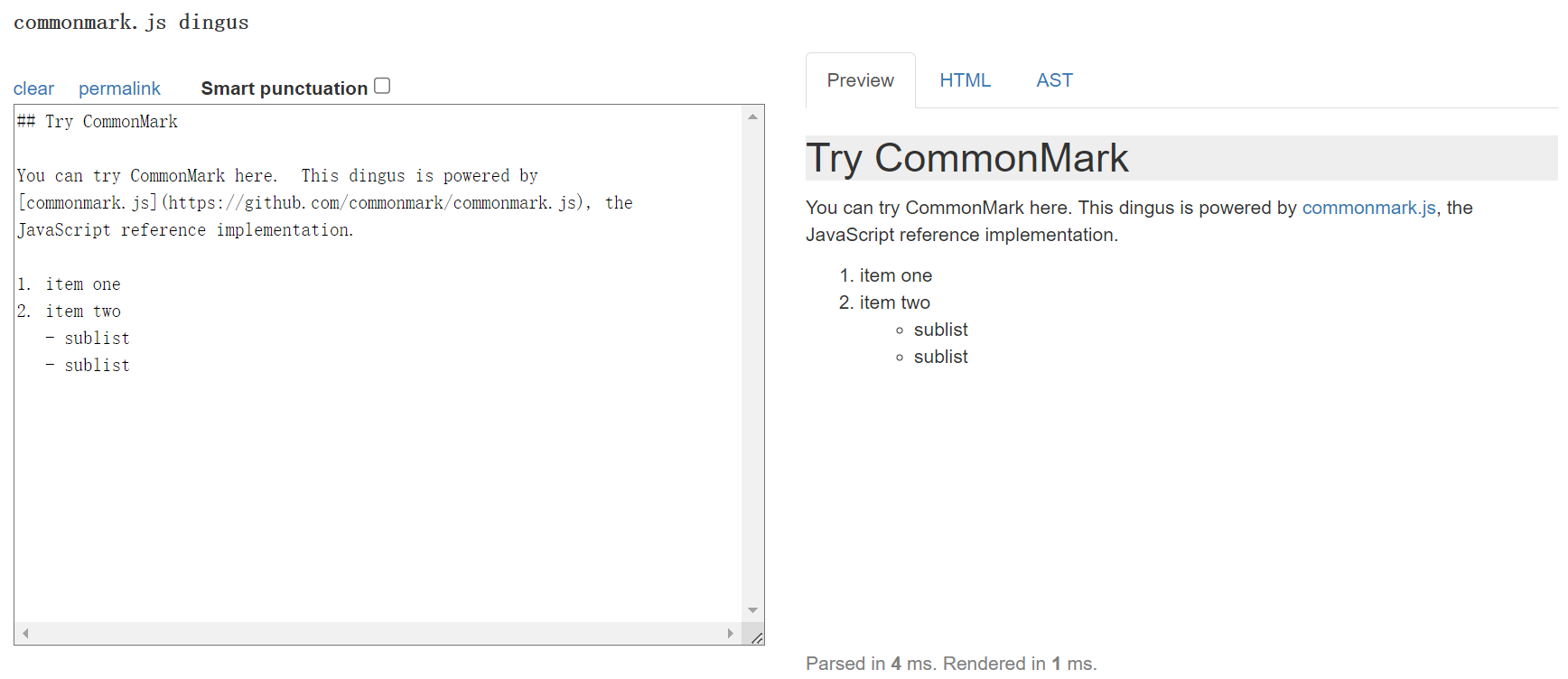
Remarkable 與 Markdown-it
Remarkable 是2014年左右的開源專案,目前已更新很少了;Markdown-it 是 Remarkable 核心兩個作者後面開的開源專案,同時借鑑參考了 MacFarlane 的 Commonmark 的一些實現,也是功能、擴充套件性都非常不錯的 Markdown解析引擎 目前有 16.2k 的收藏。
基本使用
var md = require('markdown-it')();
var result = md.render('# markdown-it rulezz!');
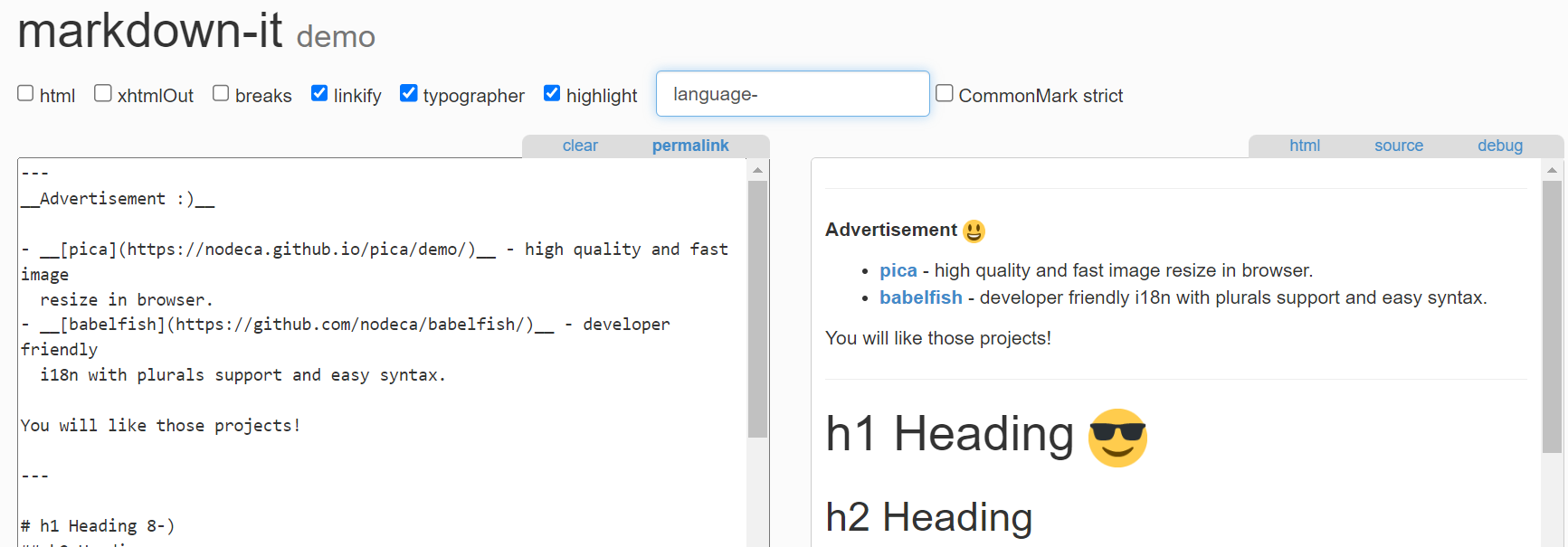
Micromark 與 Remark
Micromark 和 Remark 建立者都是 Titus Wormer(wooorm),14年畢業於阿姆斯特丹大學,同時也是 unified 研發生態的建立者。unified 是一個文書處理庫、外掛和工具的生態系統,其生態內有500+的開源庫,在Github 有1.3m+的專案在使用。
Remark目前就是unified生態中的一員,嚴格說來它還早於unified,是一個Monorepo風格的管理庫,主要包含remark-parse 、remark-stringify、remark、remark-cli ,其功能相信從命名也能看出一二。
- remark-parse — 用於將Markdown文字轉化為語法樹(mdast)的外掛
- remark-stringify — 用於將語法樹(mdast)轉化為Markdown文字的外掛
- remark — 包括unified、remark-parse和remark-stringify,適用於輸入和輸出都是Markdown的情況
- remark-cli — 基於remark的命令列介面工具,用於在指令碼中檢查和格式化Markdown
PS:Markdown Abstract Syntax Tree 簡稱為 mdast
其中最被廣泛使用的是 remark-parse,其解析上也應用了Micromark一些庫。
基本使用
// micromark
import {micromark} from 'micromark'
console.log(micromark('## Hello, *world*!'))
// remark
import {unified} from "unified";
import remarkParse from 'remark-parse'
import remarkRehype from 'remark-rehype'
import rehypeStringify from 'rehype-stringify'
console.log(
unified().use(remarkParse)
.use(remarkRehype)
.use(rehypeStringify)
.processSync("Hellow,*world*").value
);
其他
或許會疑惑為什麼沒有看到 Tiptap、ProseMirror、React-markdown? Tiptap 圍繞 PoroseMirror研發的開源專案,ProseMirror 主要聚焦在富文字編輯器領域 對於 Markdown解析引擎預設使用的是 Markdown-it;React-markdown 聚焦在 React component領域上,Markdown解析引擎用的是 Remark,其實類似還有 Milkdown 等等。而且圍繞 Markdown 解析引擎研發的開源專案非常之多,僅 reamrk-parse 在寫本文時就有 100w+程式碼庫,2k+ Packages在使用。
當然受限於筆者知識也必然會有遺漏的Markdown解析引擎,行文見諒。
要用,選哪個?
這個問題比較直接也比較實際,但其實很難一言論斷。應當從多方面考慮,比如是否需要100%支援 GFM?是否有自定義擴充套件語法的需要?自定義擴充套件語法是否比較複雜?又是否需要相容Atx之類的寫法?是否對效能有很高要求?是否需要使用到 AST抽象語法樹?等等;作為一個嚮往和平與愛的博主,更多的建議還是根據自身需求來選擇開源Markdown引擎,其實每一個產品都有自己獨特的優劣。
當然什麼也不考慮,就只是隨意看看,可能 Commonmark 、unified生態會是一個不錯的選擇。
附上一張文章中提及到的Markdown解析引擎的NPM下載趨勢圖,可以看到近些年來發展非常迅速,特別注意下其數值大小並非代表專案好壞。客觀上說每個專案定位不同、使用範圍不同、年限長度不同,其npm上下載量的自然也就不同;根據自身需求來選擇合適的Markdown解析引擎最為重要。
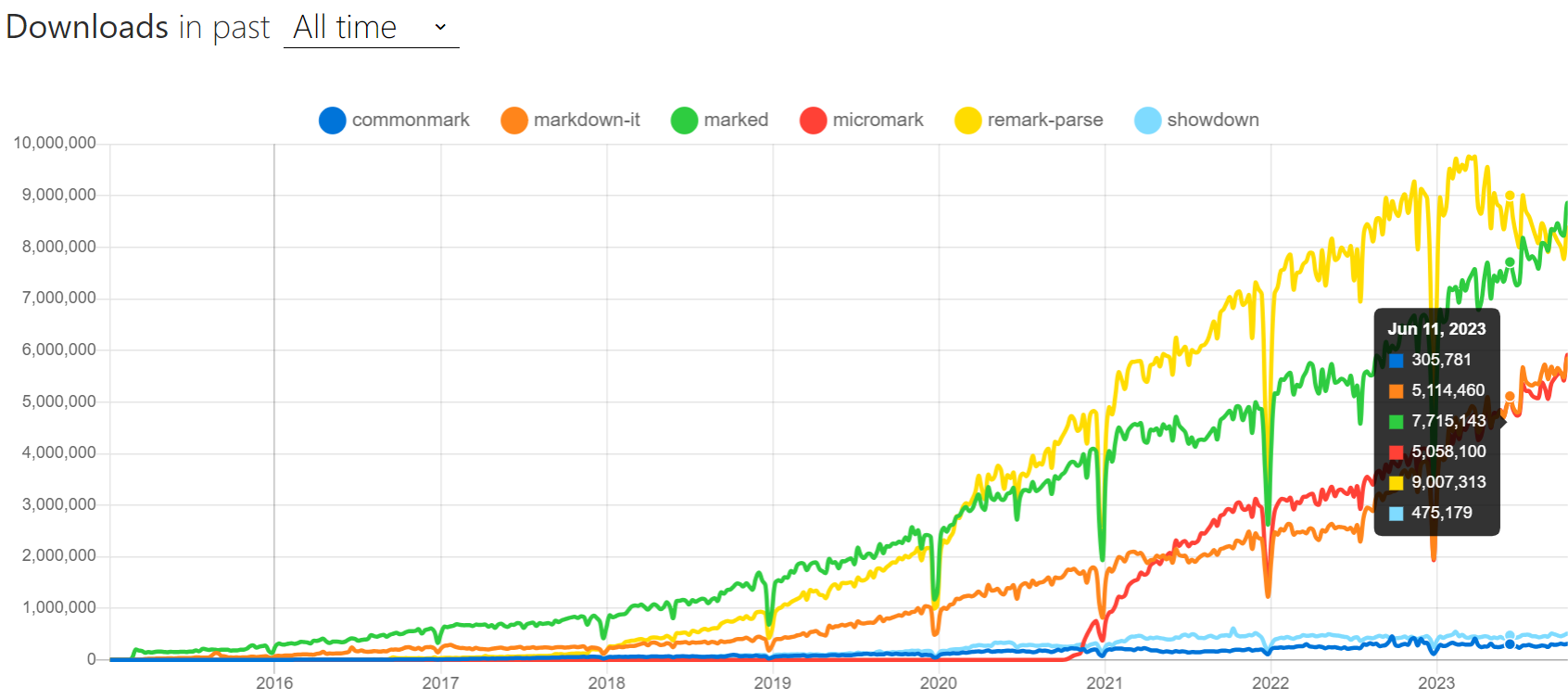
PS:這圖為什麼每年都有個陡降點?12月25日聖誕節
未來呢?
從大量輕量語言的出現,到 Gruber 和 Swartz 建立 Markdown;從 Jeff 對 Markdown 設計的熱愛,推其廣泛應用與制定標準 到 Gruber 反對標準使用 Markdown之名;從 CommonMark、GFM的出現,到 ETF徵求意見稿釋出;還有貫穿其中的各種 Markdown 擴充套件、應用到各種場景的開源專案,演進到如今不可謂不熱鬧,頗有一番春秋戰國百家爭鳴的味道。
即使今天這場「百家爭鳴」也還未停息,目前最熱的技術莫過於AI、AIGC,ChatGPT 預設顯示就是Markdown語法;由於 Markdown 輕量的語法、結構化的文字,助其可能成為了AI時代文字格式的首選之一;此外輕量語言之間仍在相互借鑑,新的擴充套件語法還在不斷湧現,各大開源生態的戰場仍在繼續書寫歷史。
但在 Markdown 演進中可以看到標準制定、基礎解析引擎整體國內身影較少,但隨著國內雲社群、開源社群發展日益火熱,更多的有志青年投身其中,相信未來也是璀璨的;也或許某天會有 Tencent Flavored Markdown Spec(TFM) 的出現。
歡迎關注 Java 研究者部落格、公眾號。
