資料結構與演演算法—緒論
前言
資料結構與演演算法是程式設計師內功體現的重要標準之一,且資料結構也應用在各個方面,業界更有程式=資料結構+演演算法這個等式存在。各個中介軟體開發者,架構師他們都在努力的優化中介軟體、專案結構以及演演算法提高執行效率和降低記憶體佔用,在這裡資料結構起到相當重要的作用。此外資料結構也蘊含一些物件導向的思想,故學好掌握資料結構對邏輯思維處理抽象能力有很大提升。
為什麼學習資料結構與演演算法?如果你還是學生,那麼這門課程是必修的,考研基本也是必考科目。工作在內卷嚴重的大廠中找工作資料結構與演演算法也是面試、筆試必備的非常重要的考察點。如果工作了資料結構和演演算法也是內功提升一個非常重要的體現,對於程式設計師來說,想要得到滿意的結果,資料結構與演演算法是必備功力!
資料結構
概念
資料結構是計算機儲存、組織資料的方式。資料結構是指相互之間存在一種或多種特定關係的資料元素的集合。通常情況下,精心選擇的資料結構可以帶來更高的執行或者儲存效率。
簡言之,資料結構是一系列的儲存結構按照一定執行規則、配合一定執行演演算法所形成的高效的儲存結構。在我們所熟知的關聯式資料庫、非關聯式資料庫、搜尋引擎儲存、訊息佇列等都是比較牛的大型資料結構良好的運用。當然這些應用中介軟體不單單要考慮單純的結構問題。還考慮實際os、網路等其他因素。
而對於資料結構與演演算法這個專欄。我們程式設計師更要掌握的首先是在記憶體中執行的抽象的資料結構。是一個相對比較單一的資料結構型別,比如線性結構、樹、圖等等.
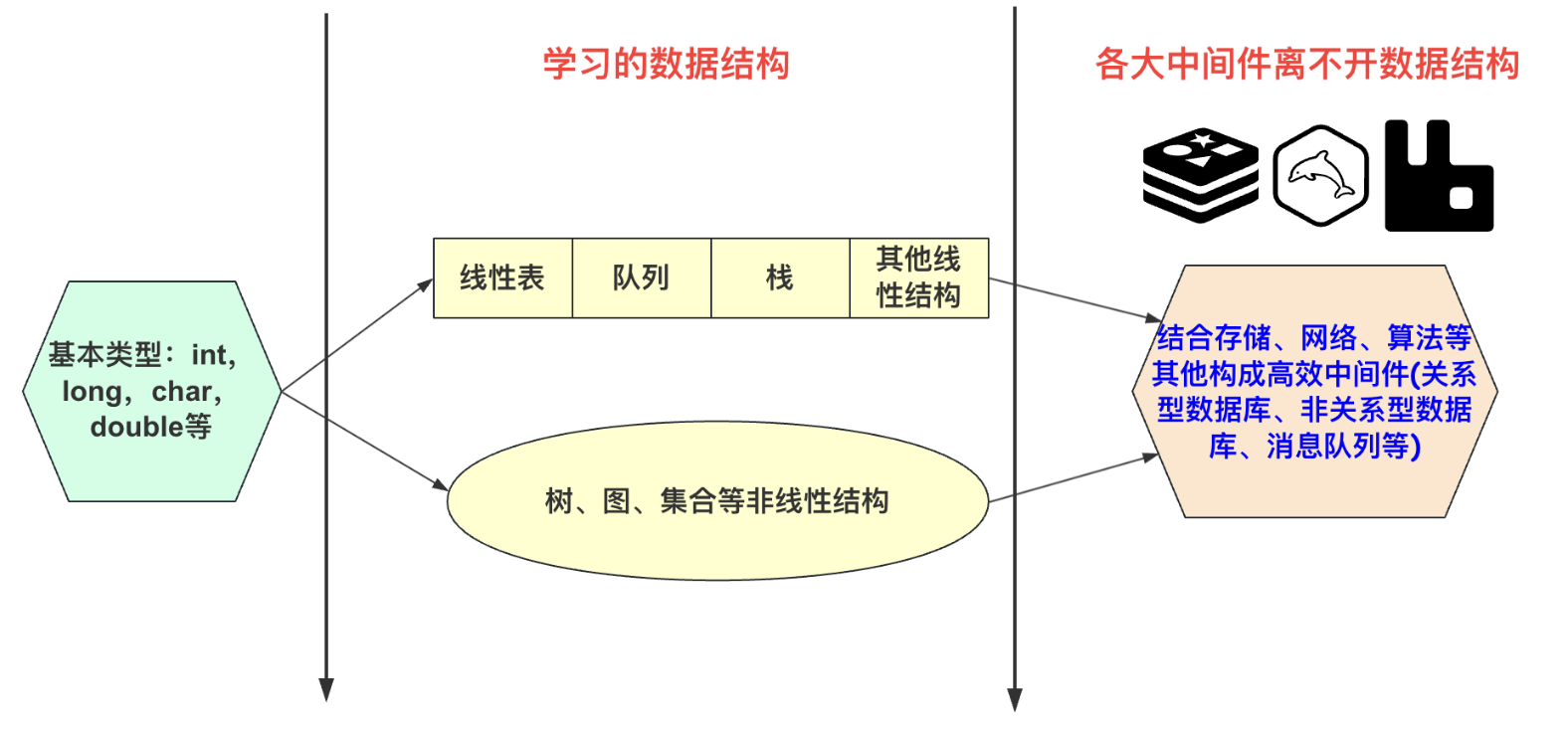
相關術語
在資料結構與演演算法中,資料、資料物件、資料元素、資料項很多人搞不清其中的關係。通過畫一張圖來捋一捋,然後下面舉個例子給大家分享一下。
使用者資訊表users
| id | name | sex |
|---|---|---|
| 001 | bigsai | man |
| 002 | smallsai | man |
| 003 | 菜虛鯤 | woman |
Users的pojo物件
class User
{
//略
int id;
String name;
String sex;
}
//list和woman是資料
List<User>users;//資料物件list
List<User>women;//資料物件women
users.add(new User(001,"bigsai","man"));//新增資料元素 一個user由(001,bigsai,man)三個資料項組成
users.add(new User(002,"smallsai","man"));//資料元素
users.add(new User(003,"菜虛鯤","woman"));//資料元素
woman.add(users.get(2));//003,"菜虛鯤","woman"三個資料項構成的一個資料元素
資料:對客觀事物的符號表示,指所有能輸入到計算機中並被計算機程式處理的符號的集合總稱。上述表中的三條使用者資訊的記錄就是資料(也可能多表多集合這裡只有一個)。這些資料一般都是使用者輸入或者是自定義構造完成。當然,還有一些影象、聲音也是資料。
資料元素:資料元素是資料的基本單位。一個資料元素由若干資料項構成!可認為是一個pojo物件、或者是資料庫的一條記錄。比如菜虛鯤那條記錄就是一個資料元素。
資料項: 而構成使用者欄位/屬性的有id、name、sex等,這些就是資料項.資料項是構成資料元素的最小不可分割欄位。可以看作一個pojo物件或者一張表(people)的一個屬性/欄位的值。
資料物件:是相同性質資料元素的集合。是資料的一個子集,比如上面的users表、list集合、woman集合都是資料物件。單獨一張表,一個集合都可以是一個資料物件。
總的捋一捋,資料範圍最廣,所有資料即資料,而資料物件僅僅是有相同性質的一個集合,這個集合是資料的子集,但並不是資料的基本單位,而資料元素才是資料的基本單位。舉個例子表cat和表dog都是資料,然後表cat是個資料物件(因為都描述cat這種物件),但是資料的基本單位並不是貓和狗,而是他們的具體的每一條記錄,比如小貓咪1號,大貓咪二號,哈士奇1號,藏獒2號這些每一條記錄才是資料的基本單位。
還有資料型別,抽象資料型別也在下面講一講。
資料型別
-
原子型別:其值不可再分的型別。比如int,char,double,float等。
-
結構型別:其值可以再分為若干成分的資料型別。比如結構體構造的各種結構等。
抽象資料型別(ADT):抽象資料型別(ADT)是一個實現包括儲存資料元素的儲存結構以及實現基本操作的演演算法。使得只研究和使用它的結構而不用考慮它的實現細節成為可能。比如我們使用List、Map、Set等等只需要瞭解它的API和性質功能即可。而具體的實現可能是不同的方案,比如List的實現有陣列和連結串列不同選擇。
三要素
邏輯結構:資料元素之間的邏輯關係。邏輯結構分為線性結構和非線性結構。線性結構就是順序表、連結串列之類。而非線性就是集合、樹、圖這些結構。
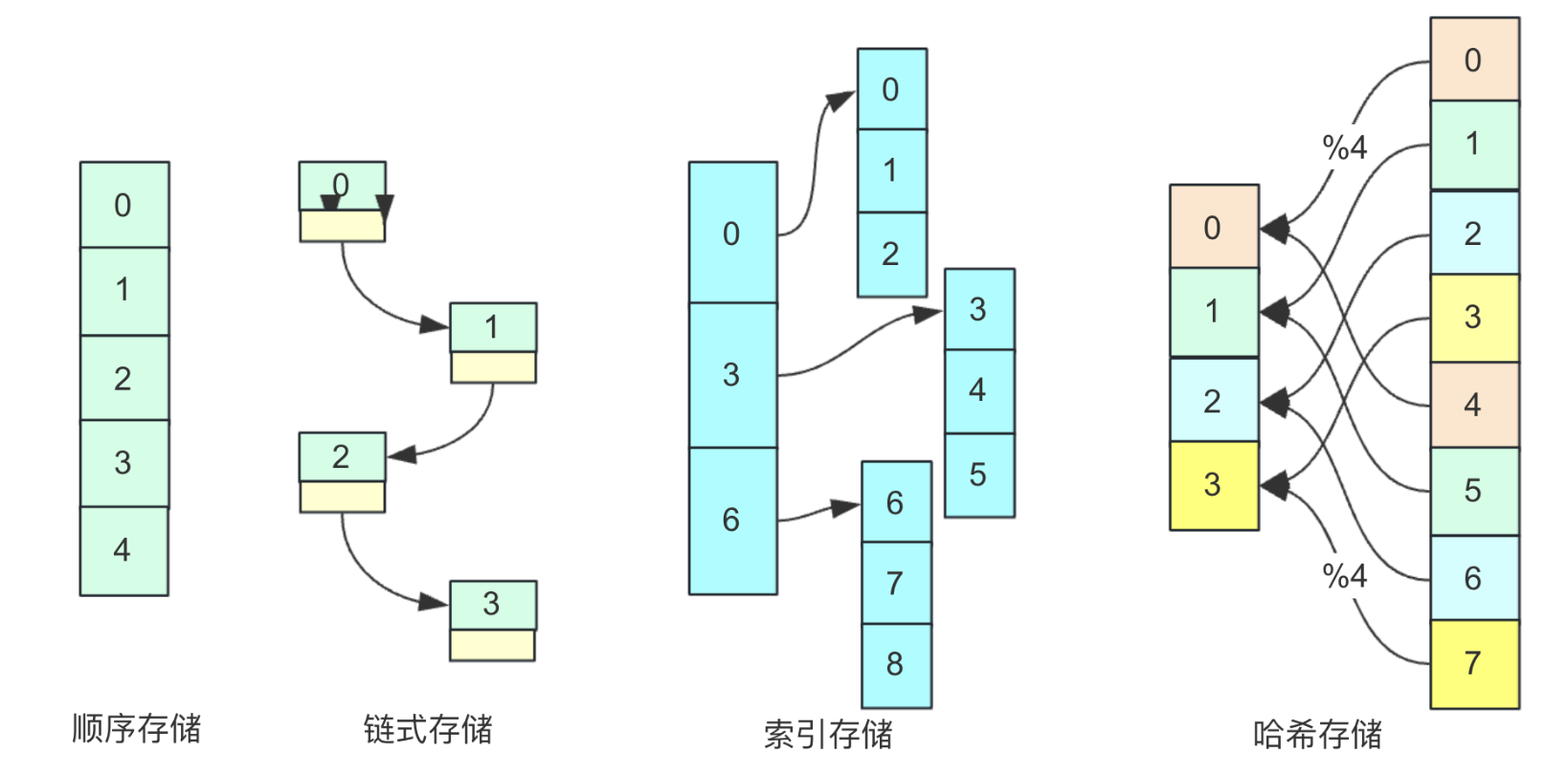
儲存結構:資料結構在計算機中的表示(又稱映像,也稱物理結構),儲存結構主要分為順序儲存、鏈式儲存、索引儲存和雜湊(雜湊)儲存,這幾種儲存通過下面這張圖簡單瞭解一下(僅僅為理解不考慮更多):
資料的運算:施加在資料上的運算包括運算的定義和實現,運算的定義基於邏輯結構,運算的實現基於儲存結構。
在這裡容易混淆的是邏輯結構與儲存結構的概念。對於邏輯結構,不難看得出邏輯二字,邏輯關係也就是兩者存在資料上的關係而不考慮實體地址的關係,比如線性結構和非線性結構,它描述的是一組資料中聯絡的方式和形式,他針對的是資料。看中的是資料結構的功能,比如線性表就是前後有序的,我需要一個有序的集合就可以使用線性表。
而儲存結構就是跟實體地址掛鉤的。因為同樣邏輯結構採用不同儲存結構實現適用場景和效能可能不同。比如同樣是線性表,可能有多種儲存結構的實現方式。比如順序表和連結串列(Arraylist,Linkedlist)它們的儲存結構就不同,一個是順序儲存(陣列)實現,一個是鏈式儲存(連結串列)實現。它關注的是計算機執行實體地址的關係。但通常同一類儲存結構實現的一些資料結構有一些類似的共同點和缺點(線性易查難插、鏈式易插難查等等)。
演演算法分析
上面講了資料結構相關概念,下面對演演算法分析的一些概念進行描述。
演演算法的五個重要特徵:有窮性、確定性、可行性、輸入、輸出。這些從字面意思即可理解,其中有窮性強調演演算法要有結束的時候不能無限迴圈;而確定性是每條指令有它意義,相同的輸入得到相同的輸出;可行性是指演演算法每個步驟經過若干次執行可以實現;輸入是0個或多個輸入(可0);輸出是1個或多個輸出(一定要有輸出)。
而一個好的演演算法,通常更要著重考慮的是效率和空間資源佔用(時間複雜度和空間複雜度),通常複雜度更多描述的是一個量級程度而很少用具體數位描述。
空間複雜度
概念:是對一個演演算法在執行過程中臨時佔用儲存空間大小的量度,記做S(n)=O(f(n))
空間複雜度其實在演演算法的衡量佔比是比較低的(我們經常使用犧牲空間換時間的資料結構和演演算法),但是不能忽視空間複雜度中重要性。無論在刷題還是實際專案生產記憶體都是一個極大額指標。對於Java而言更是如此。本身記憶體就大,如果採用的儲存邏輯不太好會佔用更多的系統資源,對服務造成壓力。
而演演算法很多情況都是犧牲空間換取時間(效率)。就比如我們熟知的字串匹配String.contains()方法,我們都知道他是暴力破解,時間複雜度為O(n^2),不需要藉助額外記憶體。而KMP演演算法在效率和速度上都原生暴力方法,但是KMP要藉助其他陣列(next[])進行標記儲存運算。就用到了空間開銷。再比如歸併排序也會藉助新陣列在遞迴分冶的適合進行逐級計算,提高效率,但增加點影響不大的記憶體開銷。
當然,演演算法的空間花銷最大不能超過jvm設定的最大值,一般為2G.(2147483645)如果開二維陣列多種多維資料不要開的太大,可能會導致heap OutOfMemoryError。
時間複雜度
概念:電腦科學中,演演算法的時間複雜度是一個函數,它定性描述了該演演算法的執行時間。這是一個關於代表演演算法輸入值的字串的長度的函數。時間複雜度常用大O符號表述,不包括這個函數的低階項和首項係數。使用這種方式時,時間複雜度可被稱為是漸近的,它考察當輸入值大小趨近無窮時的情況。
時間複雜度的排序:O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(n^3) < O(2^n) <O(n!) < O(n^n)
常見時間複雜度:對於時間複雜度,很多人的概念是比較模糊的。下面舉例子說明一些時間複雜度。
O(1): 常數函數
a=15
O(logn): 對數函數
for(int i=1;i<n;i*=2)
分析:假設執行t次使得i=n;有2^t=n; t=log2~n,為log級別時間複雜度為O(logn)。- 還有典型的二分查詢,拓展歐幾里得,快速冪等演演算法均為O(logn)。屬於高效率演演算法。
O(n): 線性函數
for (int i=0;i<n;i++)- 比較常見,能夠良好解決大部分問題。
O(nlogn):
for (int i=1;i<n;i++)
for (int j=1;j<i;j*=2)- 常見的排序演演算法很多正常情況都是nlogn,比如快排、歸併排序。這種演演算法效率大部分也還不錯。
O(n^2)
for(int i=0;i<n;i++)
for(int j=0;j<i;j++)- 其實O(n2)的效率就不敢恭維了。對於大的資料O(n2)甚至更高次方的執行效果會很差。
當然如果同樣是n=10000.那麼不同時間複雜度額演演算法執行次數、時間也不同。
| 具體 | n | 執行次數 |
|---|---|---|
| O(1) | 10000 | 1 |
| O(log2n) | 10000 | 14 |
| O( n^1/2) | 10000 | 100 |
| O(n) | 10000 | 10000 |
| O(nlog2 n) | 10000 | 140000 |
| O(n^2) | 10000 | 100000000 |
| O(n^3) | 10000 | 1000000000000 |
降低演演算法複雜度有些會靠資料結構的特性和優勢,比如二叉排序樹的查詢,線段樹的動態排序等等,這些資料結構解決某些問題有些非常良好的效能。還有的是靠演演算法策略解決,比如同樣是排序,氣泡排序這種笨而簡單的方法就是O(n2),但快排、歸併等聰明方法就能O(nlogn)。要想變得更快,那就得掌握更高階的資料結構和更精巧的演演算法。
時間複雜度計算
時間複雜度計算一般步驟:1、找到執行次數最多的語句; 2、計算語句執行的數量級 ; 3、用O表示結果。並且有兩個規則:
加法規則: 同一程式下如果多個並列關係的執行語句那麼取最大的那個,eg:
T(n)=O(m)+O(n)=max(O(m),O(n));
T(n)=O(n)+O(nlogn)=max(O(n),O(nlogn))=O(nlogn);
乘法規則:迴圈結構,時間複雜度按乘法進行計算,eg:
T(n)=O(m)*O(n)=O(mn)
T(n)=O(m)*O(m)=O(m^2)(兩層for迴圈)
當然很多演演算法的時間複雜度還跟輸入的資料有關,分為還會有最優時間複雜度(可能執行次數最少時),最壞時間複雜度(執行次數最少時),平均時間複雜度,這在排序演演算法中已經具體分析,但我們通常使用平均時間複雜度來衡量一個演演算法的好壞。
資料結構與演演算法學習
捋過資料結構與演演算法基本概念的介紹,在學習資料結構與演演算法方面,個人把經典的資料結構與演演算法學習過程步驟寫在下面,希望能給大家一個參考:
資料結構
-
單連結串列(帶頭結點、不帶頭結點)設計與實現(增刪改查),雙連結串列設計與實現
-
棧設計與實現(陣列和連結串列),佇列設計與實現(陣列和連結串列)
-
二元樹概念學習,二元樹前序、中序、後序遍歷遞迴、非遞迴實現 ,層序遍歷
-
二叉排序樹設計與實現(插入刪除)
-
堆(優先佇列、堆排序)
-
AVL(平衡)樹設計與實現(四種自旋方式理解實現)
-
伸展樹、紅黑樹原理概念理解
-
B、B+原理概念理解
-
哈夫曼樹原理概念理解(貪心策略)
-
雜湊(雜湊表)原理概念理解(幾種解決雜湊衝突方式)
-
並查集/不相交集合(優化和路徑壓縮)
-
圖論拓撲排序
-
圖論dfs深度優先遍歷、bfs廣度優先遍歷
-
最短路徑Dijkstra演演算法、Floyd演演算法、spfa演演算法
-
最小生成樹prim演演算法、kruskal演演算法
-
其他資料結構線段樹、字尾陣列等等
經典演演算法
- 遞迴演演算法(求階乘、斐波那契、漢諾塔問題)
- 二分查詢
- 分治演演算法(快排、歸併排序、求最近點對等問題)
- 貪婪演演算法(使用較多,區間選點問題,區間覆蓋問題)
- 常見動態規劃(LCS(最長公共子序列) LIS(最長上升子序列)揹包問題等等)
- 回溯演演算法(經典八皇后問題、全排列問題)
- 位運算常見問題(參考劍指offer和LeetCode問題)
- 快速冪演演算法(快速求冪乘、矩陣快速冪)
- kmp等字串匹配演演算法
- 一切其他數論演演算法(歐幾里得、拓展歐幾里得、中國剩餘定理等等)
相信看完這篇文章,你應該對資料結構與演演算法有個不錯的認知。資料結構與演演算法有著非常密切的關聯,資料結構是為了實現某種演演算法,演演算法是核心目的。學習資料結構與演演算法之前,可以先參考書本或者部落格先了解其功能,再研究其執行原理,再動手實戰(編寫資料結構或者相關題目)這樣層次漸進,想要深入的學習資料結構與演演算法光理解是不行的,需要有大量程式碼實戰才可。並且這條路是沒有止境的,活到老,學到老,刷到老。
開源倉庫:bigsai-algorithm倉庫
針對以前寫的資料結構與演算法系列重寫(針對文字描述、圖片、錯誤修復),改動會比較大,一直到更新完為止,如果感興趣希望持續關注,有錯誤也歡迎指正