這是一個講解DDD落地的文章系列,作者是《實現領域驅動設計》的譯者滕雲。本文章系列以一個真實的並已成功上線的軟體專案——碼如雲(https://www.mryqr.com)為例,系統性地講解DDD在落地實施過程中的各種典型實踐,以及在面臨實際業務場景時的諸多取捨。

本系列包含以下文章:
案例專案介紹
既然DDD是「領域」驅動,那麼我們便不能拋開業務而只講技術,為此讓我們先從業務上了解一下貫穿本文章系列的案例專案 —— 碼如雲(不是馬雲,也不是碼雲)。如你已經在本系列的其他文章中瞭解過該案例,可跳過。
碼如雲是一個基於二維條碼的一物一碼管理平臺,可以為每一件「物品」生成一個二維條碼,並以該二維條碼為入口展開對「物品」的相關操作,典型的應用場景包括固定資產管理、裝置巡檢以及物品標籤等。
在使用碼如雲時,首先需要建立一個應用(App),一個應用包含了多個頁面(Page),也可稱為表單,一個頁面又可以包含多個控制元件(Control),比如單選框控制元件。應用建立好後,可在應用下建立多個範例(QR)用於表示被管理的物件(比如機器裝置)。每個範例均對應一個二維條碼,手機掃碼便可對範例進行相應操作,比如檢視範例相關資訊或者填寫頁面表單等,對錶單的一次填寫稱為提交(Submission);更多概念請參考碼如雲術語。
在技術上,碼如雲是一個無程式碼平臺,包含了表單引擎、審批流程和資料包表等多個功能模組。碼如雲全程採用DDD完成開發,其後端技術棧主要有Java、Spring Boot和MongoDB等。
碼如雲的原始碼是開源的,可以通過以下方式存取:
CQRS
CQRS(Command Query Responsibility Segregation)直譯成中文叫命令查詢職責分離,可不要被這個讀起來有些拗口的名字嚇到了,事實上就是讀寫分離的意思,不過這裡的讀寫分離和我們通常所理解的資料庫級別的讀寫分離是兩個不同的概念,CQRS指的讀寫分離是指在應用程式內部的程式碼級別的讀寫分離,在本文中,我將對此做出詳細解釋。
簡單來講,CQRS的提出是基於這麼一種現象:軟體中寫資料的操作和讀資料的操作是兩個很不一樣的過程,它們各有各的特點,因此可以並且應該將它們作為兩個單獨的關注點分別進行處理。「寫資料」的過程也被稱為「命令(Command)」,即表示外界通過向軟體傳送一些列的命令達到更新軟體內部資料的目的,比如更新使用者偏好設定、向電商網站下單等;「讀資料」的過程也被稱為「查詢(Query)」,即從軟體中獲取資料,比如檢視訂單資訊等。讀和寫的不同主要體現在以下幾個方面:
- 業務邏輯的運用主要是在寫資料一側,也就是說,我們在本系列的其他文章中講到的聚合根,實體,值物件,領域服務等領域模型中的概念主要用於「寫資料」的過程,相比之下「讀資料」一側的業務邏輯則相對較少,主要是資料展現邏輯;
- 讀資料是冪等的,即無論通過什麼方式,都不應該修改系統中的資料,也即讀資料相對安全,而在寫資料時則需要始終保證資料的正確性和一致性,否則將導致嚴重Bug;
- 導致讀資料和寫資料過程發生變更的歸因不同,對寫資料側的變更主要基於業務邏輯的變化,而讀資料側的變更則更多基於UI需求的變化,比如根據不同的螢幕尺寸返回不同的資料等;
- 讀資料和寫資料的頻率往往各不相同,對於多數業務來說寫資料的頻率往往低於讀資料的頻率。
事實上,讀寫分離這種思想早在上世紀80年代末便由Bertrand Meyer提出,在他的《Object-Oriented Software Construction》一書中指出:
Every method should either be a command that performs an action, or a query that returns data to the caller, but never both. (一個方法要麼作為一個「命令」執行一個操作,要麼作為一次「查詢」向呼叫方返回資料,但兩者不能共存。)
可以看出,Bertrand Meyer所謂的讀寫分離主要用於物件中的方法(Method),而CQRS將這種思想擴大到了軟體架構層面,接下來讓我們分別看看CQRS中的各種讀寫分離模式。
流程分離
最簡單的讀寫分離模式莫過於讀寫流程的分離了,事實上這也是我們一直在用的一種方式,是的沒錯,你已經在用CQRS了。為此,讓我們來看看一個具體的例子,在碼如雲中,有許可權的成員(Member)可以更新表單(Submission),也可以檢視表單詳情資料,前者是一個寫資料的過程,後者則是一個讀資料的過程。更新表單的應用服務程式碼如下:
//SubmissionCommandService
@Transactional
public void updateSubmission(String submissionId, UpdateSubmissionCommand command, User user) {
Submission submission = submissionRepository.byIdAndCheckTenantShip(submissionId, user);
AppedQr appedQr = qrRepository.appedQrById(submission.getQrId());
App app = appedQr.getApp();
QR qr = appedQr.getQr();
Page page = app.pageById(submission.getPageId());
SubmissionPermissions submissionPermissions = submissionPermissionChecker.permissionsFor(user,
app,
submission.getGroupId());
submissionDomainService.updateSubmission(submission,
app,
page,
qr,
command.getAnswers(),
submissionPermissions.getPermissions(),
user
);
submissionRepository.houseKeepSave(submission, app);
log.info("Updated submission[{}].", submissionId);
}原始碼出處:com/mryqr/core/submission/command/SubmissionCommandService.java
應用服務方法SubmissionCommandService.updateSubmission()通過呼叫領域服務SubmissionDomainService.updateSubmission()完成對錶單的更新,然後再通過SubmissionRepository.houseKeepSave()完成對錶單的持久化。
在檢視表單詳情時的應用服務程式碼如下:
//SubmissionQueryService
public QDetailedSubmission fetchDetailedSubmission(String submissionId, User user) {
Submission submission = submissionRepository.byIdAndCheckTenantShip(submissionId, user);
//將領域物件Submission轉為展現物件QDetailedSubmission
return toSubmissionDetail(submission, user);
}原始碼出處:com/mryqr/core/submission/query/SubmissionQueryService.java
在SubmissionQueryService.fetchDetailedSubmission()方法中,先獲取到需要查詢的表單聚合根物件Submission,然後呼叫toSubmissionDetail()將Submission轉換為展現物件QDetailedSubmission。
在上述2個程式碼例子中,寫資料和讀資料使用了不同的應用服務方法,也即流程分離了。你可能會說「我平時就是這麼做的呀!」,的確如此,這種方式正是大家平時的編碼實現,但是這裡我們更希望強調的原則在於:寫資料的SubmissionCommandService.updateSubmission()返回的是void,也即不會返回任何資料,而讀資料的SubmissionQueryService.fetchDetailedSubmission()則只是獲取資料而未修改任何資料。
此外,雖然SubmissionCommandService和SubmissionQueryService均表示應用服務,但是在編碼實現中被分成了2個單獨的類以示分離。事實上,在碼如雲我們在程式碼的分包層面也做了相應的對讀寫分離的支援,所有與寫資料相關的程式碼被組織在了command包下,而所有與讀資料相關的程式碼則被放在了query包下。
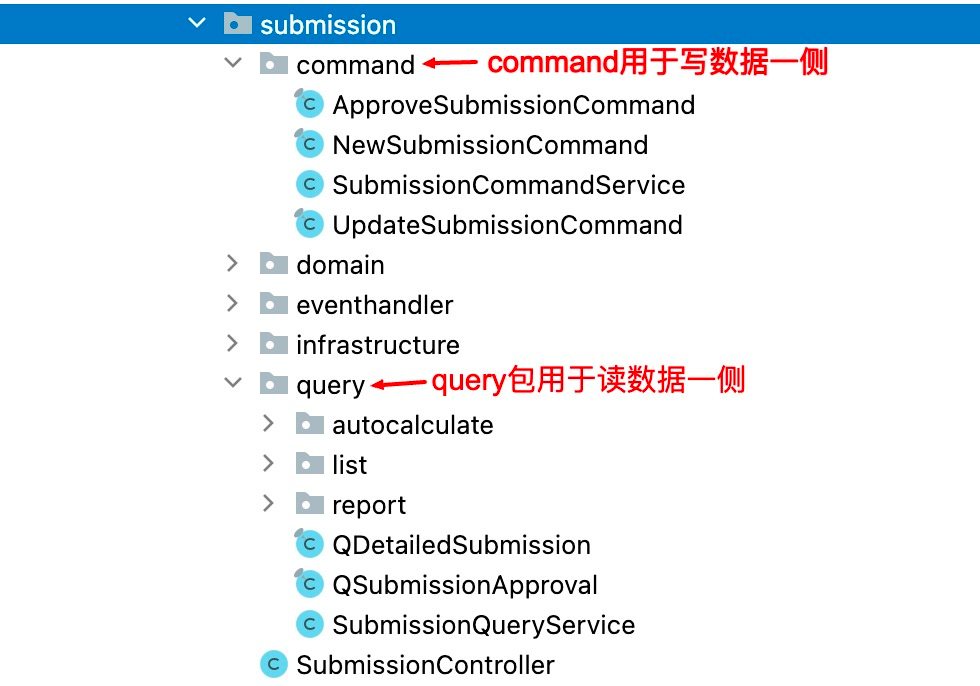
在查詢資料時,先獲取到聚合根物件Submission,再將其轉化為展現物件QDetailedSubmission,也就是說讀資料和寫資料的過程共用了同一個聚合根物件Submission。這種方式對於簡單的查詢場景沒有多大問題,但是對於一些複雜的查詢場景來說並不合適,一是使得讀資料側對寫資料側存在依賴,二是在跨表查詢的時候,需要將多個聚合根物件分別從資料庫中載入到記憶體,導致對資料庫的多次存取,在高並行場景下,這可能影響系統效能。
模型分離
既然業務邏輯主要作用於寫資料側,而讀資料側主要處理的是展現邏輯,那是不是在讀資料時可以繞過領域模型(上例中的Submission)呢?當然可以,這就是模型分離。模型分離的主要特點是:在寫資料時,依然嚴格按照領域模型對業務邏輯的請求處理流程,但是在讀資料時,可以繞過領域模型,直接從資料庫建立相應的讀模型物件。落到編碼層面,在寫資料側可能需要通過ORM等工具完成對聚合根的持久化,但是在讀資料側則不見得,我們全然可以通過直接的SQL語句從資料庫中載入所需查詢的資料。
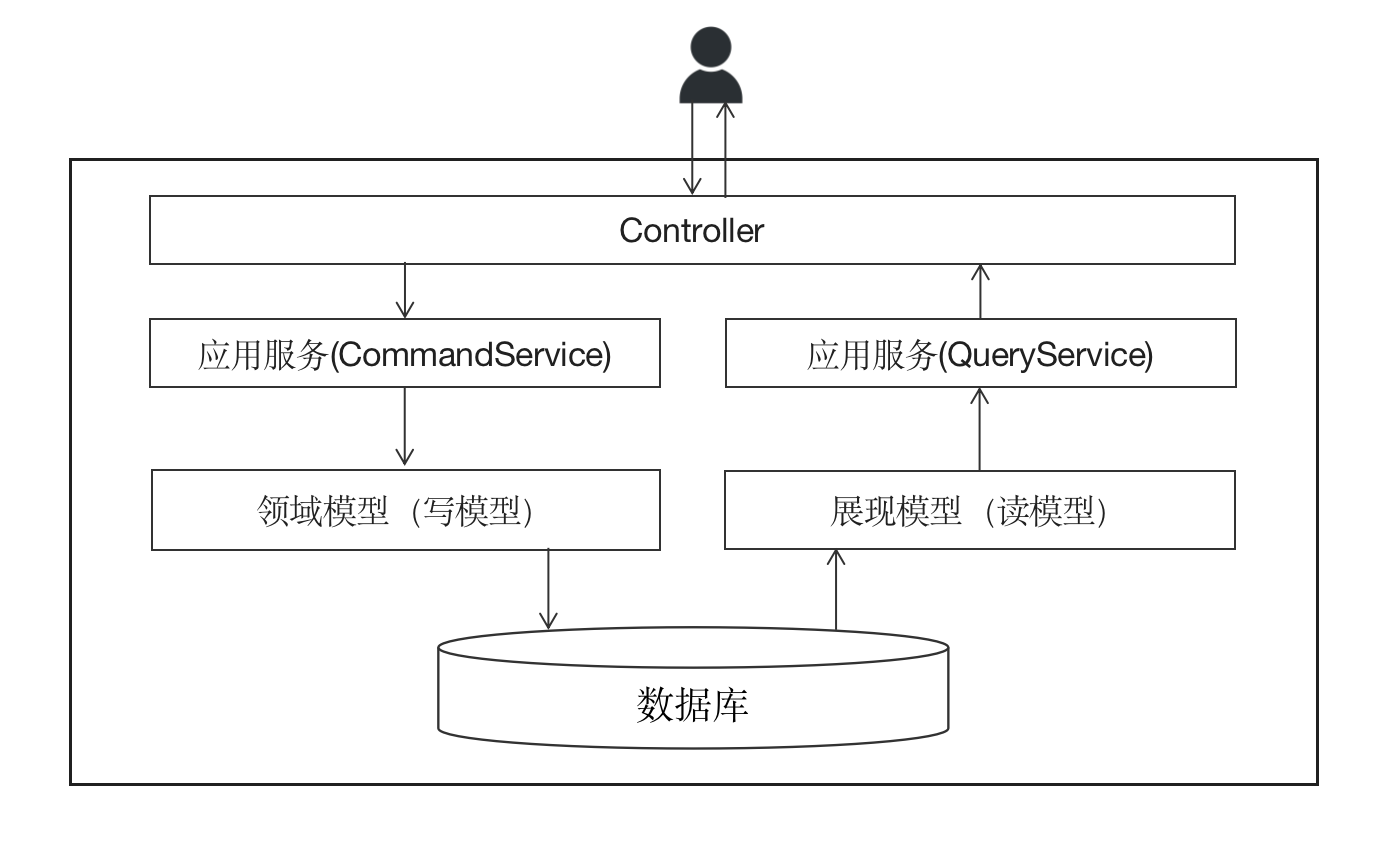
在碼如雲,租戶管理員可以檢視租戶下所有的成員,其查詢實現如下:
//MemberQueryService
public PagedList<QListMember> listMyManagedMembers(ListMyManagedMembersQuery queryCommand, User user) {
String tenantId = user.getTenantId();
Pagination pagination = pagination(queryCommand.getPageIndex(), queryCommand.getPageSize());
String departmentId = queryCommand.getDepartmentId();
String search = queryCommand.getSearch();
Query query = new Query(buildMemberQueryCriteria(tenantId, departmentId, search));
long count = mongoTemplate.count(query, Member.class);
if (count == 0) {
return pagedList(pagination, 0, List.of());
}
query.skip(pagination.skip()).limit(pagination.limit()).with(sort(queryCommand));
//繞過Member,直接將從資料庫中查到的資料建立為QListMember
query.fields().include("name").include("avatar").include("role").include("mobile")
.include("wxUnionId").include("wxNickName").include("email")
.include("active").include("createdAt").include("departmentIds");
List<QListMember> members = mongoTemplate.find(query, QListMember.class, MEMBER_COLLECTION);
return pagedList(pagination, (int) count, members);
}可以看到,在查詢成員列表時,直接通過mongotTemplate(碼如雲使用的是MongoDB)將從資料庫中所查詢到的資料建立為了讀模型QListMember,省去了載入Member並從Member轉化為QListMember的過程。
資料來源分離
模型分離可以解決很大一部分讀寫分離的問題,不過它依然是一種相對簡單的CQRS實現方式,對於更加複雜的查詢場景來說則顯得有些力不從心,主要有以下原因:
- 模型分離事實上只是程式碼層面模型的分離,底層的資料庫模型並未分離,依然是讀寫共用的,對於主要服務於寫資料一側的資料庫來說,可能由於對讀資料一側的「照料不周」而無法滿足某些查詢需求;
- 模型分離只能用於在同一個程序空間之內的查詢,也即所查詢的資料均位於同一個資料庫的場景,但是對於諸如微服務這種需要跨程序查詢的情況則無法滿足,比如對於一個採用微服務架構的電商系統,在使用者首頁需要同時檢視使用者基本資訊和積分,但是前者位於「使用者」服務中,而後者來自於「積分」服務,此時需要分別從2個服務中獲取資料並返回給前端;
- 查詢所需資料不一定能夠直接對映到資料庫中的欄位,而是有可能需要做一些額外的加工,比如將
省份(province)、城市(city)和詳細地址(detailAddress)拼接為最終的地址值等。
資料來源分離便是用來解決這個問題的,在這種方式下,我們為資料查詢側單獨建立一個資料庫,這個資料庫存在的目的僅僅是為了方便查詢用,可以說是為讀資料側量身客製化的,該資料庫中的資料依然來自於寫資料一側,只是經過了一些預先的加工,比如根據查詢端(前端)所需摒棄了一些無用的欄位,或者將多個欄位合併成單個欄位便於前端的直接顯示等。那麼,資料又如何從寫資料一側傳遞到讀資料一側呢?答案是領域事件。
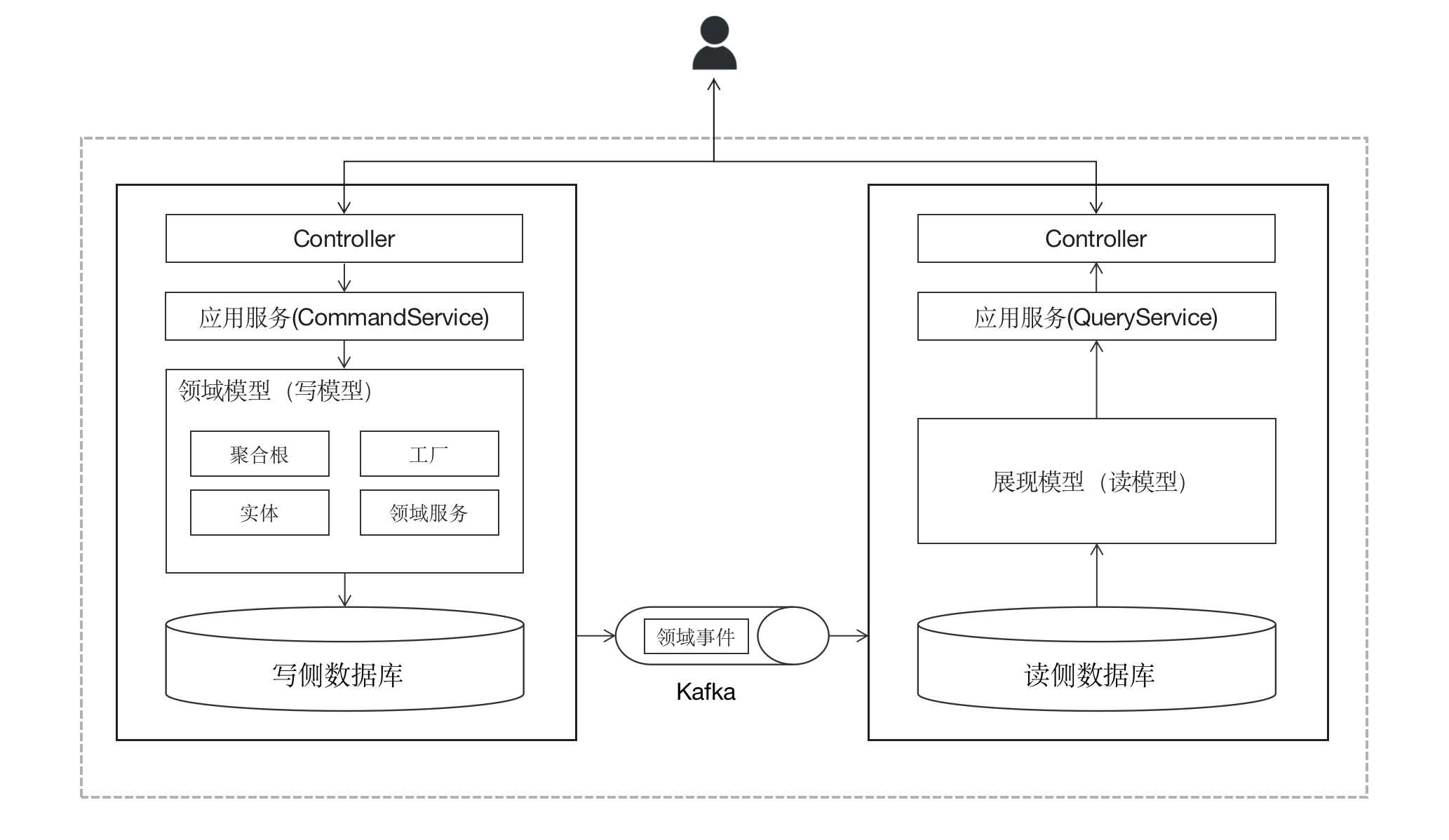
在寫資料時,對業務資料的變更將通過領域事件的形式釋出到訊息佇列(Kafka)中, 讀資料側作為一個獨立的模組通過消費這些領域事件完成對讀模型資料庫的相應更新,之後在查詢資料時,則採用與「模型分離」相似的模式直接從資料庫構建讀模型,最後返回給查詢方(前端)。
在技術棧的選擇上,讀資料側的資料庫不必與寫資料庫保持一致,比如寫資料側可以採用諸如MySQL這種強事務一致性的資料庫(為了保證業務資料的正確性),但是讀資料側可以採用更有利於資料查詢的資料庫,比如ElasticSearch等。
事實上,以上3種CQRS的實現模式並不是彼此互斥的,而是可以同時存在,哪種方式相對簡單則採用哪種方式。比如,在碼如雲我們便同時採用了3種方式。
總結
CQRS即是讀寫分離的意思,它將軟體中的寫資料過程和讀資料過程分開處理,各司其職,是一種可以在很大程度上簡化軟體架構的程式設計模式。在這種模式下,寫資料的過程嚴格遵循DDD的各種原則,而讀資料的過程則可以繞開DDD中的領域模型(主要是聚合根),直接從資料庫構建需要查詢的資料模型。根據具體場景的不同,可以採用不同的CQRS實現模式。