自然語言處理歷史史詩:NLP的正規化演變與Python全實現
本文全面回顧了自然語言處理(NLP)從20世紀50年代至今的歷史發展。從初創期的符號學派和隨機學派,到理性主義時代的邏輯和規則正規化,再到經驗主義和深度學習時代的資料驅動方法,以及最近的大模型時代,NLP經歷了多次技術革新和正規化轉換。文章不僅詳細介紹了每個階段的核心概念和技術,還提供了豐富的Python和PyTorch實戰程式碼。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。

一、引言
自然語言處理(Natural Language Processing,簡稱NLP)是一個跨學科的領域,它主要關注如何使計算機能夠理解、生成和與人類使用的自然語言進行有效交流。NLP不僅是實現人與計算機之間更緊密合作的關鍵技術,而且也是探究人類語言和思維複雜性的一種途徑。
什麼是自然語言處理?
自然語言處理包括兩個主要的子領域:自然語言理解(Natural Language Understanding,簡稱NLU)和自然語言生成(Natural Language Generation,簡稱NLG)。NLU致力於讓計算機理解自然語言的語意和上下文,從而執行特定任務,如資訊檢索、機器翻譯或者情感分析。而NLG則關注如何從資料或者邏輯表達中生成自然、準確和流暢的自然語言文字。
語言與人類思維
語言是人類區別於其他動物的最顯著特徵之一。它不僅是人們日常溝通的工具,還是邏輯思維和知識傳播的主要媒介。由於語言的複雜性和多樣性,使得自然語言處理成為一個充滿挑戰和機會的領域。
自然語言的複雜性
如果人工智慧(AI)希望真正地與人類互動或從人類知識中學習,那麼理解不精確、有歧義、複雜的自然語言是不可或缺的。這樣的複雜性使NLP成為人工智慧領域中最具挑戰性的子領域之一。
NLP的歷史軌跡
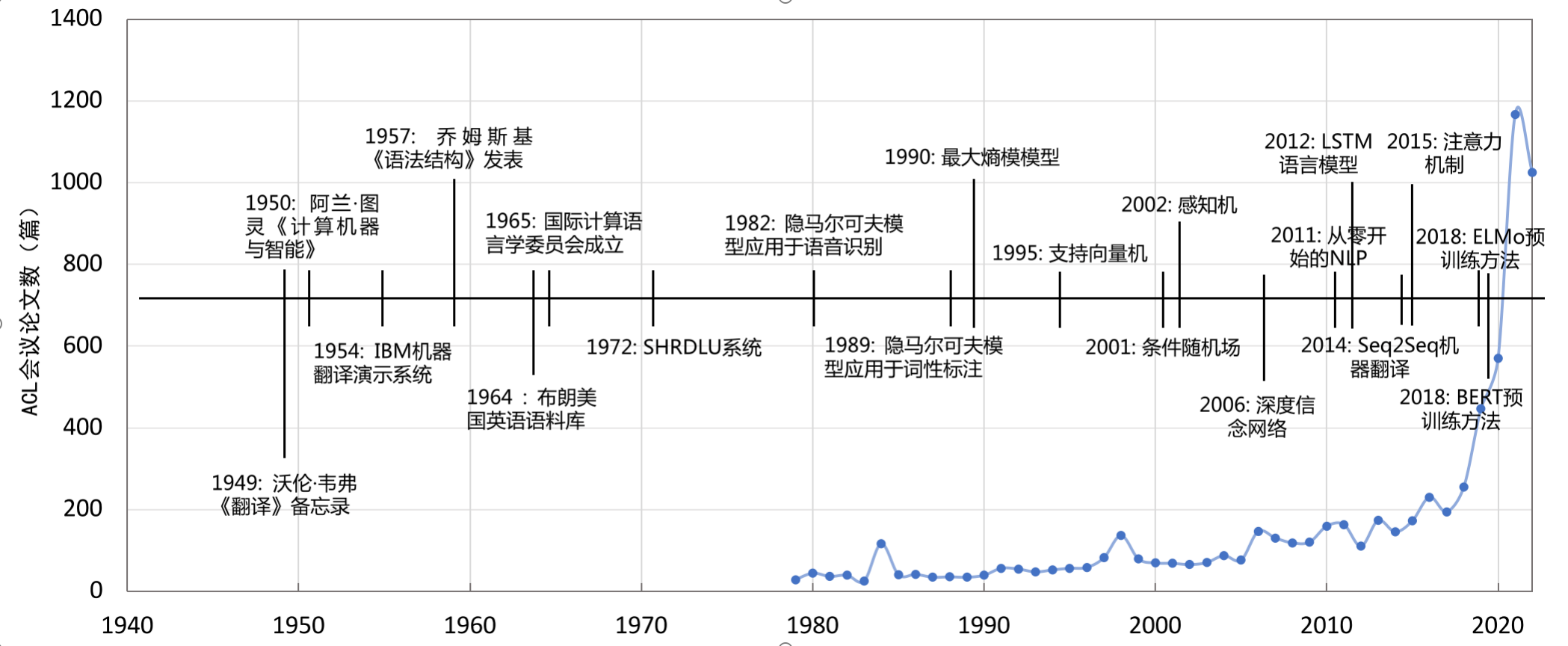
自然語言處理的研究可以追溯到1947年,當時Warren Weaver提出了利用計算機進行語言翻譯的可能性。幾年之後,1950年,Alan Turing發表了開創性的論文《Computing Machinery and Intelligence》,標誌著人工智慧和自然語言處理研究的正式起步。從那時起,NLP經歷了多個發展階段,包括20世紀50年代末到60年代的初創期、70年代到80年代的理性主義時代、90年代到21世紀初的經驗主義時代,以及2006年至今的深度學習時代。
在本文中,我們將深入探索NLP的各個發展階段,分析其歷史背景、主要技術和影響。這將幫助我們更全面地瞭解NLP的發展,以及預見其未來可能的方向。
接下來,讓我們一同啟程,回顧這個令人著迷的學科如何從一個概念走到了今天這一步。
二、20世紀50年代末到60年代的初創期
20世紀50年代末到60年代初是自然語言處理(NLP)的萌芽時期,這一階段主要分為兩大流派:符號學派和隨機學派。在這一段時間內,人們開始意識到計算機的潛能,不僅僅在數學計算上,還包括模擬人類語言和思維。
符號學派
符號學派的核心思想是通過明確的規則和符號來表示自然語言。這種方法強調邏輯推理和形式語法,認為通過精確定義語言結構和規則,計算機可以實現語言理解和生成。
重要的研究和突破
-
1950年:Alan Turing的《Computing Machinery and Intelligence》

這篇論文提出了「圖靈測試」,用以判斷一個機器是否具備智慧。這一標準也被應用於評估計算機是否能夠理解和生成自然語言。 -
1954年:Georgetown-IBM實驗
Georgetown大學和IBM合作進行了一次名為「Georgetown Experiment」的實驗,成功地使用機器將60多個俄語句子翻譯成英文。雖然結果並不完美,但這標誌著機器翻譯和NLP的第一次重大嘗試。
隨機學派
與符號學派側重於邏輯和規則不同,隨機學派注重使用統計方法來解析自然語言。這種方法主要基於概率模型,如馬爾可夫模型,來預測詞彙和句子的生成。
重要的研究和突破
-
1958年:Noam Chomsky的「句法結構」(Syntactic Structures)
這本書對形式語法進行了系統的描述,儘管Chomsky本人是符號學派的代表,但他的這一工作也催生了統計學派開始使用數學模型來描述語言結構。 -
1960年:Zellig Harris的「方法論」(Method in Structural Linguistics)
Harris提出了使用統計和數學工具來分析語言的方法,這些工具後來被廣泛應用於隨機學派的研究中。
這一時期的研究雖然初級,但它們為後來的NLP研究奠定了基礎,包括詞性標註、句法解析和機器翻譯等。符號學派和隨機學派雖然方法不同,但都在試圖解決同一個問題:如何讓計算機理解和生成自然語言。這一時期的嘗試和突破,為後來基於機器學習和深度學習的NLP研究鋪平了道路。
三、20世紀70年代到80年代的理性主義時代
在自然語言處理(NLP)的歷史長河中,20世紀70年代至80年代標誌著一段理性主義時代。在這個階段,NLP研究的焦點從初級的規則和統計模型轉向了更為成熟、複雜的理論框架。這一時代主要包括三大正規化:基於邏輯的正規化、基於規則的正規化和隨機正規化。
基於邏輯的正規化
基於邏輯的正規化主要側重於使用邏輯推理來理解和生成語言。這一方法認為,自然語言中的每個句子都可以轉化為邏輯表示式,這些表示式可以通過邏輯演算來分析和操作。
重要的研究和突破
-
1970年:第一次「邏輯程式設計」(Logic Programming)的引入
在這一年,邏輯程式設計被首次引入作為一種能夠執行邏輯推理的計算模型。Prolog(Programming in Logic)便是這一正規化下的代表性語言。 -
1978年:Terry Winograd的《Understanding Natural Language》

Winograd介紹了SHRDLU,一個能夠理解和生成自然語言的計算機程式,這一程式主要基於邏輯和語意網。
基於規則的正規化
基於規則的正規化主要聚焦於通過明確的規則和演演算法來解析和生成語言。這些規則通常都是由人類專家設計的。
重要的研究和突破
-
1971年:Daniel Bobrow的STUDENT程式
STUDENT程式能解決代數文字問題,是基於規則的自然語言理解的早期嘗試。 -
1976年:Roger Schank的「Conceptual Dependency Theory」
這一理論提出,所有自然語言句子都可以通過一組基本的「概念依賴」來表示,這為基於規則的正規化提供了理論基礎。
隨機正規化
儘管隨機正規化在50至60年代已有所涉獵,但在70至80年代它逐漸走向成熟。這一正規化主要使用統計方法和概率模型來處理自然語言。
重要的研究和突破
-
1979年:Markov模型在語音識別中的應用
儘管不是純粹的NLP應用,但這一突破標誌著統計方法在自然語言處理中的日益增長的重要性。 -
1980年:Brown語料庫的釋出
Brown語料庫的釋出為基於統計的自然語言處理提供了豐富的資料資源,這標誌著資料驅動方法在NLP中的嶄露頭角。
這一時代的三大正規化雖然有所不同,但都有著共同的目標:提升計算機對自然語言的理解和生成能力。在這一時代,研究人員開始整合多種方法和技術,以應對自然語言處理中的各種複雜問題。這不僅加深了我們對自然語言處理的理解,也為後續的研究打下了堅實的基礎。
四、20世紀90年代到21世紀初的經驗主義時代
這個時期代表著自然語言處理(NLP)由理論導向向資料驅動的轉變。經驗主義時代強調使用實際資料來訓練和驗證模型,而不僅僅依賴於人為定義的規則或邏輯推理。在這個時代,NLP研究主要集中在兩個方面:基於機器學習的方法和資料驅動的方法。
基於機器學習的方法

機器學習在這個時代開始被廣泛地應用於自然語言處理問題,包括但不限於文字分類、資訊檢索和機器翻譯。
重要的研究和突破
-
1994年:決策樹用於詞性標註
Eric Brill首次展示瞭如何使用決策樹進行詞性標註,這代表了一種從資料中自動學習規則的新方法。 -
1999年:最大熵模型在NLP中的引入
最大熵模型被首次應用於自然語言處理,尤其在詞性標註和命名實體識別方面取得了突出的表現。
資料驅動的方法
這個正規化主張使用大量的文字資料來「教」計算機理解和生成自然語言,通常通過統計方法或機器學習演演算法。
重要的研究和突破
-
1991年:釋出了Wall Street Journal語料庫
這個廣泛使用的語料庫對許多後續基於資料的NLP研究起到了推動作用。 -
1993年:IBM的統計機器翻譯模型
IBM研究團隊提出了一種革新性的統計機器翻譯模型,標誌著從基於規則的機器翻譯向基於資料的機器翻譯的轉變。
提出邏輯過程
-
資料收集和預處理
隨著網際網路的快速發展,資料變得越來越容易獲取。這促使研究人員開始集中精力預處理這些資料,並將其用於各種NLP任務。 -
模型選擇和優化
選擇適當的機器學習模型(如決策樹、支援向量機或神經網路)並對其進行優化,以提高其在特定NLP任務上的效能。 -
評估和微調
使用驗證集和測試集進行模型評估,並根據需要進行微調。
這個經驗主義時代的主要貢獻是它把自然語言處理推向了一種更為實用和可延伸的方向。依靠大量的資料和高度複雜的演演算法,NLP開始在商業和日常生活中發揮越來越重要的作用。這一時代也為隨後的深度學習時代奠定了堅實的基礎。
五、2006年至今的深度學習時代
自2006年以來,深度學習的興起徹底改變了自然語言處理(NLP)的面貌。與經驗主義和理性主義時代相比,深度學習帶來了巨大的模型複雜性和資料處理能力。這個時代主要集中在兩個方面:深度神經網路和向量表示。
深度神經網路
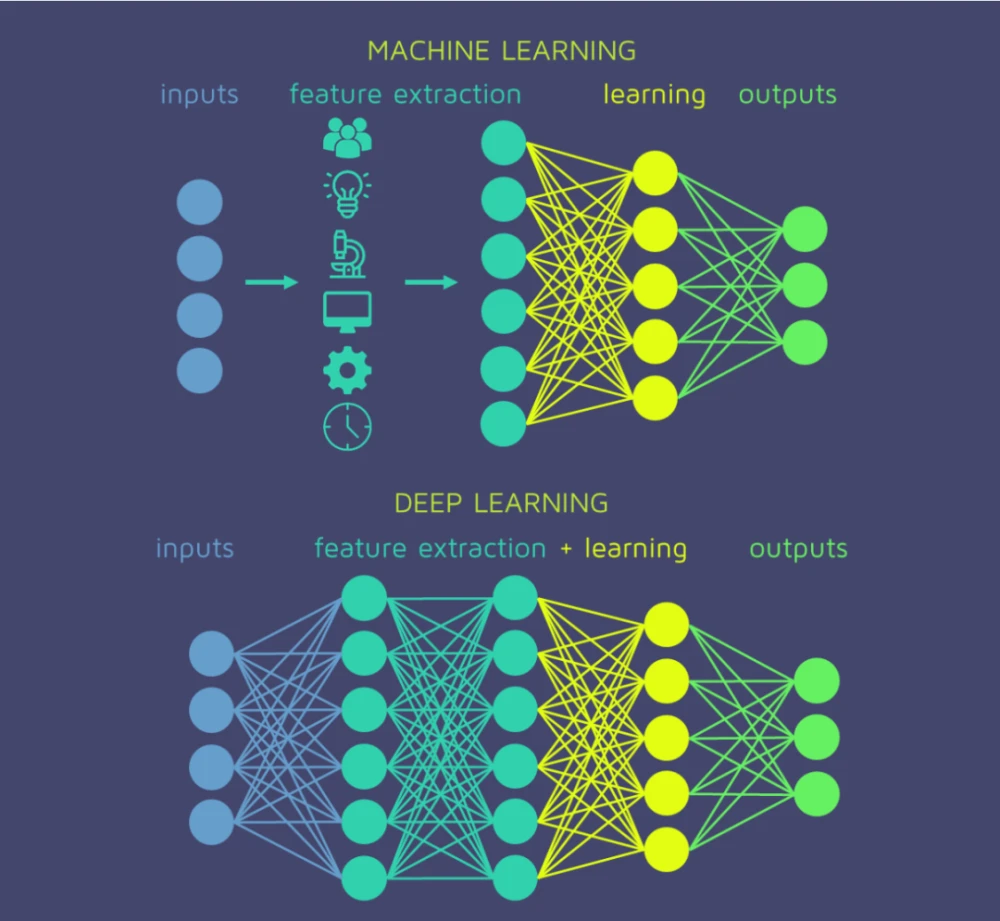
深度神經網路模型由多層(通常大於三層)的網路結構組成,這使它們能夠學習更復雜、更高階的特徵。
重要的研究和突破
-
2008年:遞迴神經網路(RNN)
在這一年,研究人員首次證明了遞迴神經網路能夠有效地處理諸如文字生成和機器翻譯等序列任務。 -
2013年:詞嵌入(Word Embeddings)和Word2Vec模型
Tomas Mikolov等人釋出了Word2Vec,這是一種能有效地將詞語轉換為向量表示的方法。 -
2014年:序列到序列(Seq2Seq)模型
Google的研究團隊提出了序列到序列模型,標誌著NLP應用(尤其是機器翻譯)的一個重要轉折點。 -
2015年:注意力機制(Attention Mechanism)
注意力機制被引入到NLP中,特別是用於解決機器翻譯等序列到序列任務的問題。
向量表示
這裡主要是指將文字和其他語言元素轉換成數學向量,通常用於後續的機器學習任務。
重要的研究和突破
-
2013年:GloVe模型
GloVe(全域性向量)模型被提出,為詞嵌入提供了一種全新的統計方法。 -
2018年:BERT模型
BERT(雙向編碼器表示從變換器)模型被髮布,它改變了我們對文書處理和理解的方式,尤其是在任務如文字分類、命名實體識別和問題回答方面。
提出邏輯過程
-
從淺層模型到深度模型
隨著計算能力的提升和資料量的增加,研究人員開始探索更復雜的模型結構。 -
優化和正則化
針對深度神經網路,研究人員開發了各種優化演演算法(如Adam、RMSprop等)和正則化技術(如Dropout)。 -
預訓練和微調
憑藉大量可用的文字資料,研究人員現在通常會先對一個大型模型進行預訓練,然後針對特定任務進行微調。 -
解釋性和可解釋性
由於深度學習模型通常被認為是「黑箱」,因此後續的研究也開始集中在提高模型可解釋性上。
深度學習時代不僅提高了NLP任務的效能,還帶來了一系列全新的應用場景,如聊天機器人、自動問答系統和實時翻譯等。這一時代的研究和應用無疑為NLP的未來發展打下了堅實的基礎。
六、2018年至今的大模型時代

從2018年開始,超大規模語言模型(例如GPT和BERT)走入人們的視野,它們以其強大的效能和多樣的應用場景在NLP(自然語言處理)領域引發了一場革命。這一時代被大模型所定義,這些模型不僅在規模上大大超過以往,而且在處理複雜任務方面也有顯著的優勢。
超大規模語言模型
在這一階段,模型的規模成為了一種關鍵的優勢。比如,GPT-3模型具有1750億個引數,這使它能夠進行高度複雜的任務。
重要的研究和突破
-
2018年:BERT(Bidirectional Encoder Representations from Transformers)
BERT模型由Google提出,通過雙向Transformer編碼器進行預訓練,並在多項NLP任務上達到了最先進的表現。 -
2019年:GPT-2(Generative Pre-trained Transformer 2)
OpenAI釋出了GPT-2,雖然模型規模較小(與GPT-3相比),但它展示了生成文字的強大能力。 -
2020年:GPT-3(Generative Pre-trained Transformer 3)
OpenAI釋出了GPT-3,這一模型的規模和效能都達到了一個新的高度。 -
2021年:CLIP(Contrastive Language-Image Pre-training)和DALL-E
OpenAI再次引領潮流,釋出了可以理解影象和文字的模型。
提出邏輯過程
-
資料驅動到模型驅動
由於模型的規模和計算能力的增長,越來越多的任務不再需要大量標註的資料,模型自身的能力成為了主導。 -
自監督學習
大規模語言模型的訓練通常使用自監督學習,這避免了對大量標註資料的依賴。 -
預訓練與微調的普遍化
通過在大量文字資料上進行預訓練,然後針對特定任務進行微調,這一流程已經成為業界標準。 -
多模態學習
隨著CLIP和DALL-E的出現,研究開始從純文字擴充套件到包括影象和其他型別的資料。 -
商業應用和倫理考量
隨著模型規模的增加,如何合理、安全地部署這些模型也成為一個重要議題。
趨勢與影響
-
減少對標註資料的依賴
由於大模型本身具有強大的表示學習能力,標註資料不再是效能提升的唯一手段。 -
任務泛化能力
這些大型模型通常具有出色的任務泛化能力,即使用相同的預訓練模型基礎上進行不同任務的微調。 -
計算資源的問題
模型的規模和複雜性也帶來了更高的計算成本,這在一定程度上限制了其普及和應用。
2018年至今的大模型時代標誌著NLP進入一個全新的發展階段,這一階段不僅改變了研究的方向,也對實際應用產生了深遠的影響。從搜尋引擎到聊天機器人,從自動翻譯到內容生成,大模型正在逐漸改變我們與數位世界的互動方式。
七、Python和PyTorch實戰每個時代
在自然語言處理(NLP)的發展歷史中,不同的時代有著各自代表性的方法和技術。在本節中,我們將使用Python和PyTorch來實現這些代表性方法。
20世紀50年代末到60年代的初創期:符號學派和隨機學派
在這個時代,一個經典的方法是正規表示式用於文字匹配。
正規表示式範例
import re
def text_matching(pattern, text):
result = re.findall(pattern, text)
return result
pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,7}\b'
text = "My email is [email protected]"
result = text_matching(pattern, text)
print("輸出:", result)
輸入: 文字和正規表示式
輸出: 符合正規表示式的文字片段
20世紀70年代到80年代的理性主義時代:基於邏輯的正規化、基於規則的正規化和隨機正規化
在這一時代,基於規則的專家系統在NLP中有廣泛應用。
基於規則的名詞短語識別
def noun_phrase_recognition(sentence):
rules = {
'noun': ['dog', 'cat'],
'det': ['a', 'the'],
}
tokens = sentence.split()
np = []
for i, token in enumerate(tokens):
if token in rules['det']:
if tokens[i + 1] in rules['noun']:
np.append(f"{token} {tokens[i + 1]}")
return np
sentence = "I see a dog and a cat"
result = noun_phrase_recognition(sentence)
print("輸出:", result)
輸入: 一句話
輸出: 名詞短語列表
20世紀90年代到21世紀初的經驗主義時代:基於機器學習和資料驅動
這一時代的代表性方法是樸素貝葉斯分類。
樸素貝葉斯文字分類
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.preprocessing import LabelEncoder
texts = ["I love Python", "I hate bugs", "I enjoy coding"]
labels = ["positive", "negative", "positive"]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(labels)
clf = MultinomialNB()
clf.fit(X, y)
sample_text = ["I hate Python"]
sample_X = vectorizer.transform(sample_text)
result = clf.predict(sample_X)
print("輸出:", label_encoder.inverse_transform(result))
輸入: 文字和標籤
輸出: 分類標籤
2006年至今的深度學習時代
這個時代是由深度神經網路和向量表示主導的,其中一個代表性的模型是LSTM。
LSTM文字生成
import torch
import torch.nn as nn
class LSTMModel(nn.Module):
def __init__(self, vocab_size, embed_size, hidden_size):
super(LSTMModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, hidden_size)
self.fc = nn.Linear(hidden_size, vocab_size)
def forward(self, x):
x = self.embedding(x)
output, _ = self.lstm(x)
output = self.fc(output)
return output
# 省略模型訓練和預測程式碼
輸入: 文字的詞索引
輸出: 下一個詞的概率分佈
通過這些例子,我們可以看到各個時代在自然語言處理中的不同方法和應用。這些程式碼範例幫助我們更好地理解這些方法是如何從輸入到輸出進行工作的。
八、總結
自然語言處理(NLP)是一個跨學科的領域,涉及電腦科學、人工智慧、語言學等多個學科。從20世紀50年代至今,該領域經歷了多個不同的發展階段,每個階段都有其獨特的方法論和技術特點。
簡述歷史脈絡
- 20世紀50年代末到60年代的初創期:這一階段以符號學派和隨機學派為代表,主要集中在基礎理論和圖形識別等方面。
- 20世紀70年代到80年代的理性主義時代:基於邏輯的正規化、基於規則的正規化和隨機正規化在這一時期得到了廣泛的研究和應用。
- 20世紀90年代到21世紀初的經驗主義時代:基於機器學習和大量資料的方法開始佔據主導地位。
- 2006年至今的深度學習時代:深度神經網路,特別是迴圈神經網路和Transformer架構,帶來了前所未有的模型效能。
- 2018年至今的大模型時代:超大規模的預訓練語言模型,如GPT和BERT,開始在各種NLP任務中展現出色的效能。
洞見與展望
-
融合多種正規化:儘管每個時代都有其主導的方法論和技術,但未來的NLP發展可能需要融合不同正規化,以達到更好的效果。
-
可解釋性與健壯性:隨著模型複雜度的提高,如何確保模型的可解釋性和健壯性將是一個重要的研究方向。
-
資料多樣性:隨著全球化的推進,多語言、多文化環境下的自然語言處理問題也日益突出。
-
人與機器的互動:未來的NLP不僅需要從大量文字中提取資訊,還需要更好地理解和生成自然語言,以實現更自然的人機互動。
-
倫理與社會影響:隨著NLP技術在各個領域的廣泛應用,其倫理和社會影響也不能忽視。如何避免演演算法偏見,保護使用者隱私,將是未來研究的重要主題。
通過本文,我們希望能給讀者提供一個全面而深入的視角,以理解自然語言處理的歷史發展和未來趨勢。從正規表示式到超大規模語言模型,NLP領域的飛速發展充分展示了其在解決實際問題中的強大潛力,也讓我們對未來充滿期待。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。