kubernetes驅逐機制總結
概述
k8s的驅逐機制是指在某些場景下,如node節點notReady、node節點壓力較大等,將pod從某個node節點驅逐掉,讓pod的上層控制器重新建立出新的pod來重新排程到其他node節點。這裡也將kube-scheduler的搶佔排程納入到了驅逐的討論範圍內,因為當排程高優先順序的pod時發現資源不足,會驅逐掉node節點上原有的低優先順序的pod。
根據發起驅逐的元件,驅逐可以分為3類:
(1)由kubelet發起的驅逐:節點壓力驅逐;kubelet週期性檢查自身節點資源壓力,當節點壓力較大時,會驅逐自身node節點上的pod,以回收資源,降低節點資源壓力;
(2)由kube-controller-manager發起的驅逐:當開啟了汙點驅逐時,node上有NoExecute汙點後,立馬驅逐不能容忍汙點的pod,對於能容忍該汙點的pod,則等待pod上設定的汙點容忍時間裡的最小值後,pod會被驅逐;當未開啟汙點驅逐時,node的ready Condition值為false或unknown且已經持續了一段時間(通過kcm啟動引數--pod-eviction-timeout設定,預設5分鐘)後,對該node上的pod做驅逐操作;
(3)由kube-scheduler發起的驅逐:搶佔排程驅逐;當一個高優先順序的pod排程失敗後,kube-scheduler會驅逐走(刪除)某個Node 上的一些低優先順序的pod,這樣一來就可以保證高優先順序pod的排程。
1.kubelet發起的驅逐
kubelet發起的驅逐為kubelet節點壓力驅逐;
kubelet監控叢集節點的 CPU、記憶體、磁碟空間和檔案系統的inode 等資源,根據kubelet啟動引數中的驅逐策略設定,當這些資源中的一個或者多個達到特定的消耗水平,kubelet 可以主動地驅逐節點上一個或者多個pod,以回收資源,降低節點資源壓力。
驅逐訊號
節點上的memory、nodefs、pid等資源都有驅逐訊號,kubelet通過將驅逐訊號與驅逐策略進行比較來做出驅逐決定;
驅逐策略
kubelet節點壓力驅逐包括了兩種,軟碟機逐和硬驅逐;
軟碟機逐
軟碟機逐機制表示,當node節點的memory、nodefs等資源達到一定的閾值後,需要持續觀察一段時間(寬限期),如果期間該資源又恢復到低於閾值,則不進行pod的驅逐,若高於閾值持續了一段時間(寬限期),則觸發pod的驅逐。
硬驅逐
硬驅逐策略沒有寬限期,當達到硬驅逐條件時,kubelet會立即觸發pod的驅逐,而不是優雅終止。
pod驅逐流程
(1)根據kubelet啟動引數設定,獲取驅逐策略設定;
(2)從cAdvisor、CRIRuntimes獲取各種統計資訊,如節點上各個資源的總量以及使用量情況、容器的資源宣告及使用量情況等;
(3)比對驅逐策略設定以及上述的各種資源統計資訊,篩選出會觸發驅逐的驅逐訊號;
(4)將上面篩選出來的驅逐訊號做排序,將記憶體驅逐訊號排在所有其他訊號之前,並從排序後的結果中取出第一個驅逐訊號;
(5)主動嘗試回收fs、inode資源,如果回收的資源足夠,則直接return,不需要往下執行驅逐pod的邏輯;
(6)根據最終篩選出來的那一個驅逐訊號,使用對應的排序函數給pod列表進行排序;
(7)遍歷排序後的pod列表,嘗試驅逐pod;
幾個注意點:
(1)每次的驅逐流程,最多隻驅逐一個pod;
(2)一次驅逐流程完成後,如果本次流程有驅逐pod,則馬上繼續迴圈執行pod驅逐流程,如果本次驅逐流程沒有驅逐pod,則等待10s後再回圈執行pod驅逐流程;
(3)驅逐pod,只是將pod.status.phase值更新為Failed,並附上驅逐reason:Evicted以及觸發驅逐的詳細資訊,不會刪除pod;而pod.status.phase值被更新為Failed後,replicaset controller會再次建立出新的pod呼叫到其他節點上,達到驅逐pod的效果;
2.kube-controller-manager發起的驅逐
kube-controller-manager驅逐主要依靠NodeLifecycleController以及其中的TaintManager;
kube-controller-manager驅逐分類
(1)開啟了汙點驅逐:node上有NoExecute汙點後,立馬驅逐不能容忍汙點的pod,對於能容忍該汙點的pod,則等待pod上設定的汙點容忍時間裡的最小值後,pod會被驅逐;
(2)未開啟汙點驅逐:當node的ready Condition值為false或unknown且已經持續了一段時間(通過kcm啟動引數--pod-eviction-timeout設定,預設5分鐘)時,對該node上的pod做驅逐操作;
NodeLifecycleController
NodeLifecycleController主要負責以下工作:
(1)定期檢查node的心跳上報,某個node間隔一定時間都沒有心跳上報時,更新node的ready condition值為false或unknown,開啟了汙點驅逐的情況下,給該node新增NoExecute的汙點;
(2)未開啟汙點驅逐時的pod驅逐工作;
(3)根據kcm啟動引數設定,決定是否啟動TaintManager;
TaintManager
TaintManager負責pod的汙點驅逐工作,當node上有NoExecute汙點後,立馬驅逐不能容忍汙點的pod,對於能容忍該汙點的pod,則等待pod上設定的汙點容忍時間裡的最小值後,pod會被驅逐;
3.kube-scheduler發起的驅逐
kube-scheduler發起的驅逐為搶佔排程驅逐;
當一個高優先順序的pod排程失敗後,kube-scheduler會驅逐走(刪除)某個Node 上的一些低優先順序的pod,這樣一來就可以保證高優先順序pod的排程。
關於pod優先順序,具體請參考:https://kubernetes.io/zh/docs/concepts/scheduling-eviction/pod-priority-preemption/
搶佔發生的原因,一定是一個高優先順序的pod排程失敗。
kube-scheduler搶佔排程功能可通過設定控制是否開啟。
kube-scheduler搶佔排程驅逐流程
優先順序和搶佔機制,解決的是 Pod 排程失敗時該怎麼辦的問題。
正常情況下,當一個 pod 排程失敗後,就會被暫時 「擱置」 處於 pending 狀態,直到 pod 被更新或者叢集狀態發生變化,排程器才會對這個 pod 進行重新排程。
但是有的時候,我們希望給pod分等級,即分優先順序。當一個高優先順序的 Pod 排程失敗後,該 Pod 並不會被「擱置」,而是會「擠走」某個 Node 上的一些低優先順序的 Pod,這樣一來就可以保證高優先順序 Pod 會優先排程成功。
關於pod優先順序,具體請參考:https://kubernetes.io/zh/docs/concepts/scheduling-eviction/pod-priority-preemption/
搶佔發生的原因,一定是一個高優先順序的 pod 排程失敗,我們稱這個 pod 為「搶佔者」,稱被搶佔的 pod 為「犧牲者」(victims)。
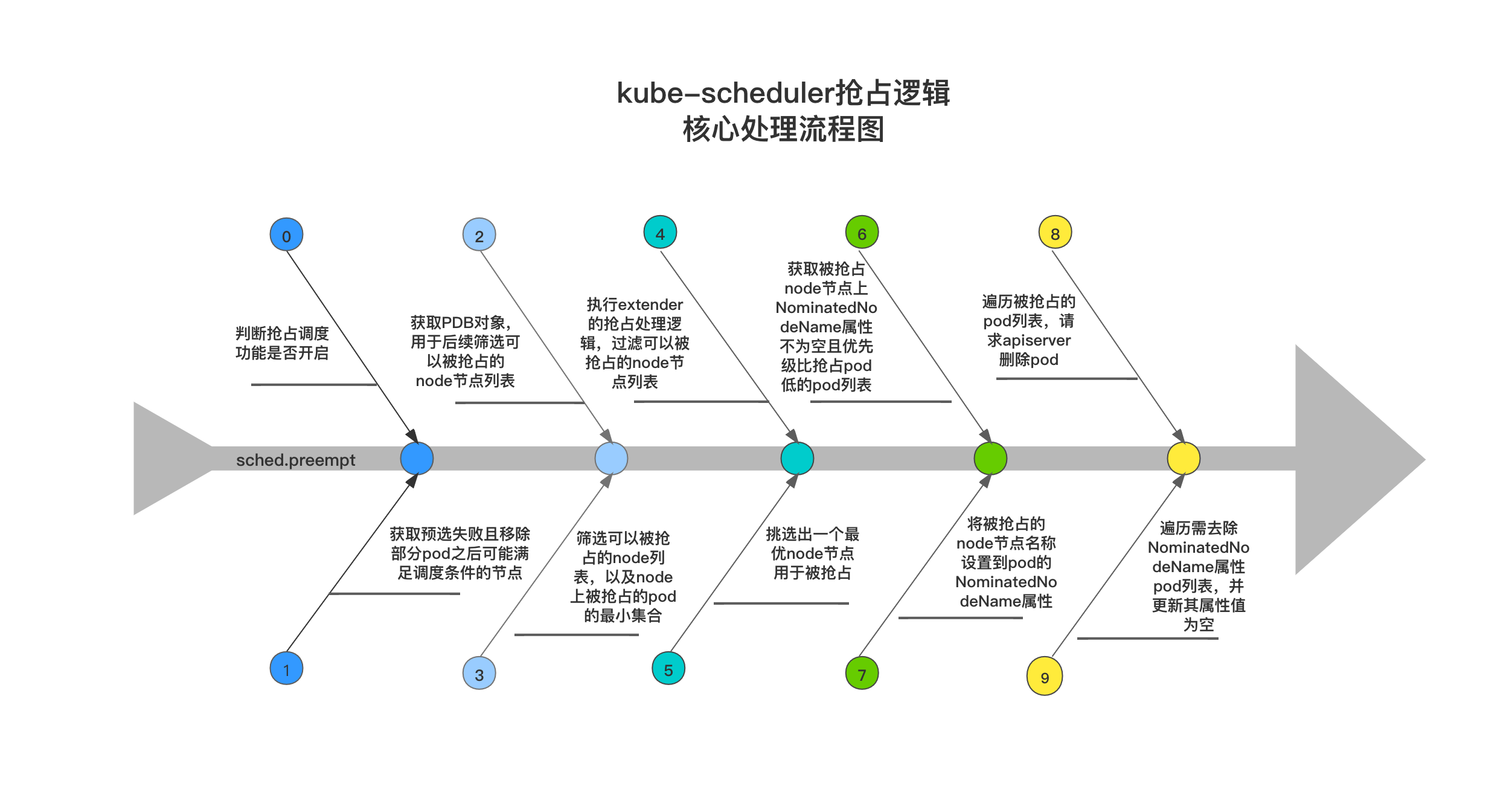
搶佔排程驅逐的核心處理流程
下方處理流程圖展示了kube-scheduler搶佔排程驅逐的核心處理步驟,在開始搶佔邏輯處理之前,會先進行搶佔排程功能是否開啟的判斷。
k8s驅逐機制詳細分析
https://www.cnblogs.com/lianngkyle/tag/k8s驅逐/
原理分析目錄
(1)k8s QoS與pod驅逐;
(2)kubelet節點壓力驅逐分析;
(3)kube-scheduler搶佔排程驅逐分析;
(4)kube-controller-manager驅逐分析;
原始碼分析目錄
(1)kubelet節點壓力驅逐-eviction manager原始碼分析;
(2)kube-scheduler搶佔排程原始碼分析;
(3)kube-controller-manager驅逐原始碼分析;
(4)kube-controller-manager TaintManager原始碼分析;