InfiniBand 的前世今生
今年,以 ChatGPT 為代表的 AI 大模型強勢崛起,而 ChatGPT 所使用的網路,正是 InfiniBand,這也讓 InfiniBand 大火了起來。那麼,到底什麼是 InfiniBand 呢?下面,我們就來帶你深入瞭解 InfiniBand。
InfiniBand的發展歷史
InfiniBand(也稱為「無限頻寬」,縮寫為 IB)是一個用於高效能運算的計算機網路通訊標準,它具有極高的吞吐量和極低的延遲,用於計算機與計算機之間的資料互連。InfiniBand 也用作伺服器與儲存系統之間的直接或交換互連,以及儲存系統之間的互連。隨著人工智慧的興起,它也是 GPU 伺服器的首選網路互連技術。
我們來看下 InfiniBand 的發展歷程:
1999 年,一家名為 InfiniBand Trade Association(IBTA)的組織釋出了 InfiniBand 架構,該架構的目的是為了取代 PCI 匯流排,旨在提供一種高效能、低延遲的計算和儲存互連技術。
2000年,InfiniBand架構規範的 1.0 版本正式釋出。緊接著在 20021 年,首批 InfiniBand 產品問世,多家廠商也開始推出支援 InfiniBand 的產品,包括伺服器、儲存系統和網路裝置等。
2003 年,InfiniBand 轉向一個新的應用領域——計算機叢集互聯,並在當時的 TOP500 超級計算機中得到了廣泛應用。
在接下來的幾年中,InfiniBand 多次引入新的特性和改進,支援雙倍頻寬的 DDR(Double Date Rate)、遠端直接記憶體存取和更好的虛擬化支援,這些新特性為高效能運算和儲存系統提供了更多的靈活性和效能優勢。
到 2019 年的 TOP500 超級計算機中,已經有 181 個採用了 InfiniBand 技術,當時的 Ethernet(乙太網)仍然是主流。而到了 2015 年,InfiniBand 技術在 TOP500 超級計算機中的佔比首次超過了50%,達到 51.4%。這標誌著 InfiniBand 技術首次實現了對乙太網技術的逆襲,成為超級計算機中最受歡迎的內部連線技術。
InfiniBand的架構
InfiniBand 是處理器和 I/O 裝置之間資料流的通訊鏈路,支援多達 64,000 個可定址裝置。InfiniBand 架構 (IBA) 是一種行業標準規範,定義了用於互連伺服器、通訊基礎設施、儲存裝置和嵌入式系統的對等交換輸入/輸出框架。
InfiniBand的網路架構
InfiniBand 具有普遍性、低延遲、高頻寬和低管理成本,非常適合在單個連線中連線多個資料流(叢集、通訊、儲存、管理),具有數千個互連節點。最小的完整 IBA 單元是子網,多個子網通過路由器連線起來形成一個大的 IBA 網路。
InfiniBand 系統由通道介面卡、交換機、路由器、電纜和聯結器組成。CA 分為主機通道介面卡(HCA)和目標通道介面卡(TCA)。IBA 交換機在原理上與其他標準網路交換機類似,但必須滿足 InfiniBand 的高效能和低成本要求。HCA 是 IB 端節點(例如伺服器或儲存裝置)連線到 IB 網路的裝置點。TCA 是一種特殊形式的通道介面卡,主要用於儲存裝置等嵌入式環境。
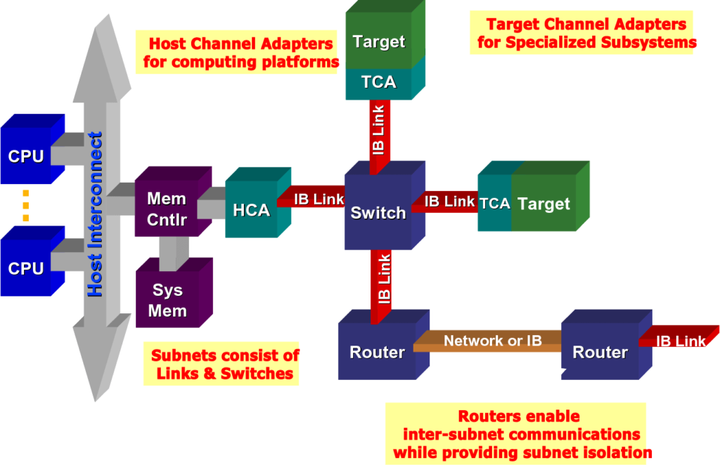
△ InfiniBand 的網路拓撲結構
InfiniBand的分層架構
InfiniBand 架構分為多個層,每個層彼此獨立執行。InfiniBand 分為以下幾層:物理層、鏈路層、網路層、傳輸層和上層。
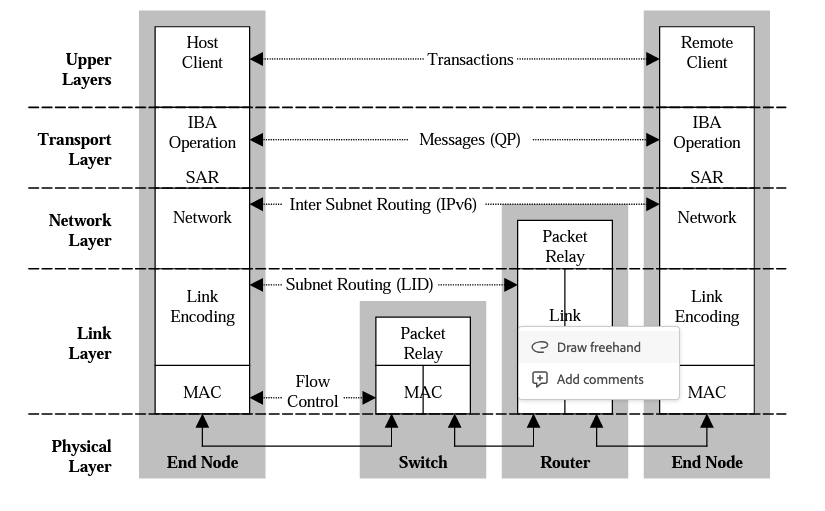
物理層:物理層服務於鏈路層並提供這兩層之間的邏輯介面。物理層由埠訊號聯結器、物理連線(電和光)、硬體管理、電源管理、編碼線等模組組成,
鏈路層:鏈路層負責處理分組中鏈路資料的傳送和接收,提供定址、緩衝、流量控制、錯誤檢測和資料交換等服務。服務質量(QoS)主要由這一層體現。
網路層:網路層負責在 IBA 子網之間路由封包,包括單播和多播操作。網路層不指定多協定路由(例如,非 IBA 型別上的 IBA 路由),也不指定原始封包如何在 IBA 子網之間路由。
傳輸層:每個 IBA 資料都包含一個傳輸頭。傳輸頭包含端節點執行指定操作所需的資訊。通過操縱 QP,傳輸層的 IBA 通道介面卡通訊使用者端形成「傳送」工作佇列和「接收」工作佇列。
上層:上層協定和應用層負責處理更高階別的通訊功能和應用需求。上層協定可以包括諸如TCP/IP(傳輸控制協定/網際網路協定)、UDP(使用者資料包協定)、MPI(訊息傳遞介面)等常見的網路協定。它們利用底層提供的基礎通訊能力,通過InfiniBand網路進行資料傳輸和通訊,用於實現應用程式之間的通訊和資料交換。此外,上層還包括執行在 InfiniBand 網路上的應用程式。
InfiniBand的特點及優勢
InfiniBand 最突出的一個優勢,就是率先引入了 RDMA (Remote Direct Memory Access)協定。RDMA 是一種繞過遠端主機而存取其記憶體中資料的技術,解決網路傳輸中資料處理延遲而產生的一種遠端記憶體直接存取技術。
在傳統的 TCP/IP 網路通訊中,資料傳送方需要將資料進行多次記憶體拷貝,並經過一系列的網路協定的封包處理工作;資料接收方在應用程式中處理資料前,也需要經過多次記憶體拷貝和一系列的網路協定的封包處理工作。
而 RDMA 允許應用與網路卡之間的直接資料讀寫,允許接收端直接從傳送端的記憶體讀取資料,RDMA 可以顯著降低傳輸延遲,加快資料交換速度,並可以減輕 CPU 負載,釋放 CPU 的計算能力。
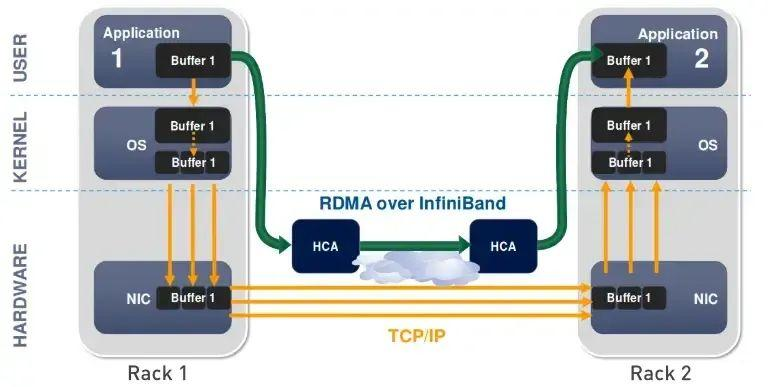
△ 傳統傳輸 VS RDMA
除了 InfiniBand 對 RDMA 協定的支援,還有以下優勢:
- 低延遲:InfiniBand 網路以其極低的延遲而著稱。RDMA 零拷貝網路減少了作業系統開銷,使得資料能夠在網路中快速移動,InfiniBand 網路延遲可達到 0.7 微秒。
- 高頻寬:InfiniBand 網路提供高頻寬的資料傳輸能力。它通常支援數十Gb/s甚至更高的頻寬,取決於網路裝置和設定。高頻寬使得節點之間可以以高速進行資料交換,適用於大規模資料傳輸、平行計算和儲存系統等應用。
- 可延伸性:IB網路具有出色的可延伸性,適用於構建大規模計算叢集和資料中心。它支援多級拓撲結構,如全域性互連網路、樹狀結構和扁平結構,可以根據應用需求和規模進行靈活設定和擴充套件。此外,IB網路還支援多個子網的互連,使得不同子網之間的節點可以進行通訊和資料交換。這種可延伸性使得IB網路能夠應對不斷增長的計算和儲存需求。
- 高吞吐量:由於低延遲和高頻寬的特性,IB網路能夠實現高吞吐量的資料傳輸。它支援大規模資料流的並行傳輸,同時減少了中間處理和拷貝操作,提高了系統的整體效能。高吞吐量對於需要大規模資料共用和平行計算的應用非常重要,如科學模擬、巨量資料分析和機器學習。
在看了上文後,相信你對 InfiniBand 已經有了一定的瞭解。根據行業機構的預測,InfiniBand 的市場規模在 2029 年將達到 983.7 億美元,相比 2021 年的66.6億美元,增長 14.7 倍。在高效能運算和 AI 的強力推動下,InfiniBand 的發展前景令人期待。