搓一個Pythonic list
總所周知,Python語言當中的list是可以儲存不同型別的元素的,對應到現代C++當中,可以用std::variant或者std::any實現類似的功能。而Python官方的實現當中用到了二級指標,不過拋開這些,我們也可以自己設計一個list的架構,實現多型別值的儲存容器。
下圖是自己實現的list的架構,按照這個架構,我們來逐步分析程式碼。不過為了節省篇幅,我僅僅只實現了一部分的方法,比如append,但是這裡我們著重的是容器的設計。
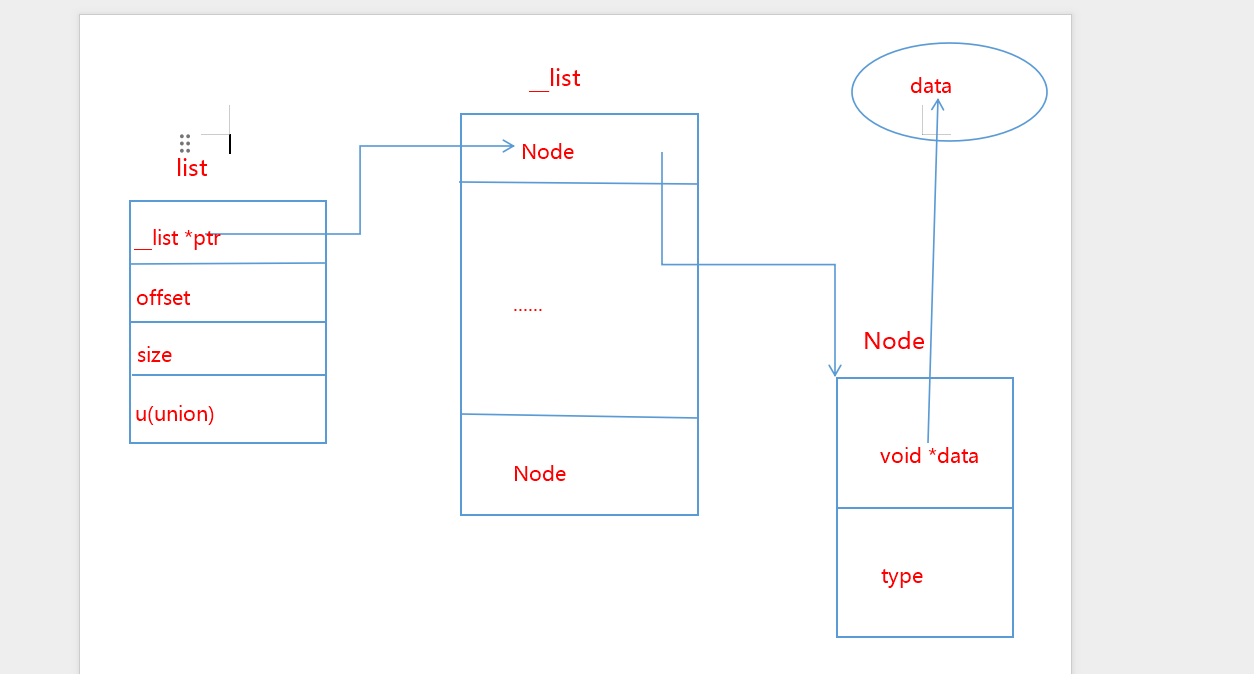
我們自頂向下分析。list這個結構體是最終要實現的容器,裡面包含了一個指向__list的指標,__list裡面存著一系列的Node節點。除了指標,還有offset偏移量,記錄當前__list指標ptr的偏移量,size是list的元素大小,而最後一個聯合體u則為了實現多值儲存而塞的一個成員。Node這邊,含有一個void型別的指標,它可以指向任意元素的地址,待會我們會將它轉換回對應的元素型別,從而獲取其指向的值。type記錄該指標指向的具體型別。
以下對應了這三個結構體的實現。
struct Node {
void *data = nullptr;
int type;
};
struct __list {
Node node;
};
struct list {
__list *ptr;
int offset{};
int size;
U u;
list(int size) : size(size) {
ptr = static_cast<__list *>(malloc(sizeof(__list) * (size + 1)));
}
list(const list& other) = default;
~list() {
ptr -= offset;
free(ptr);
}
}在分配記憶體的時候,要注意額外分配多一個空位,因為ptr是指向list最後元素的下一個位置。解構函式的時候也要記得將ptr回退到最開始的位置,不然會出現記憶體方面的問題。
在型別方面,這裡僅寫了幾種常用的型別,可以按照實際需要補充更多的型別上去。
enum {
INT,
UINT,
CHAR,
UCHAR,
FLOAT,
DOUBLE
};append函數,這裡我沒有使用泛型實現,而是使用了函數過載,覺得比較好寫,以下是int型別的實現,其它型別同理,只需要稍微改改。
void append(uint& __data) {
ptr->node.data = static_cast<void *>(&__data);
ptr->node.type = UINT;
if (offset + 1 <= size) {
++ptr;
++offset;
}
else
std::cout << "The list has achived it's capacity\n";
}另外,還過載了[]運運算元,這裡就用到了前面所提到的union了,這裡設定了返回值為union,這樣可以比較巧妙的處理不同返回值的情況。
U operator[](int index) {
auto it = ptr - offset + index;
auto __data = it->node.data;
int type = it->node.type;
switch (type) {
case INT: {
u.intData = *(static_cast<int *>(__data));
u.type = INT;
break;
}
case UINT: {
u.uintData = *static_cast<uint *>(__data);
u.type = UINT;
break;
}
case CHAR: {
u.charData = *static_cast<char *>(__data);
u.type = CHAR;
break;
}
case UCHAR: {
u.ucharData = *static_cast<u_char *>(__data);
u.type = UCHAR;
break;
}
case FLOAT: {
u.floatData = *static_cast<float *>(__data);
u.type = FLOAT;
break;
}
case DOUBLE: {
u.doubleData = *static_cast<double *>(__data);
u.type = DOUBLE;
break;
}
default: {
assert(0);
}
}
return u;
}為了最終可以遍歷元素並且輸出出來,還需要對union進行過載一下。
struct U {
union {
int intData;
uint uintData;
char charData;
u_char ucharData;
float floatData;
double doubleData;
};
// To figure out which type we're using
int type;
friend std::ostream& operator<<(std::ostream& os, const U& u) {
int type = u.type;
switch (type) {
case INT: {
os << u.intData;
break;
}
case UINT: {
os << u.uintData;
break;
}
case CHAR: {
os << u.charData;
break;
}
case UCHAR: {
os << u.ucharData;
break;
}
case FLOAT: {
os << u.floatData;
break;
}
case DOUBLE: {
os << u.doubleData;
break;
}
default: {
assert(0);
}
}
return os;
}
};(能用switch代替if else就儘量代替)
到這裡,所設計的list就差不多了,剩下的函數可以由讀者來拓展。不過還有侷限性,可以看看它怎麼使用。
int main() {
list lst{3};
std::vector v{1, 2, 3};
for (int i{}; i < v.size(); ++i)
lst.append(v[i]);
for (int i{}; i < lst.size; ++i)
std::cout << lst[i] << ' ';
}由於沒有寫對右值資料的處理,所以只能先將想要存的資料存入另一個容器當中。我們再來測試一下。
int main() {
list lst{3};
int a = 1;
double b = 1.1;
char c = 'c';
lst.append(a);
lst.append(b);
lst.append(c);
for (int i{}; i < lst.size; ++i)
std::cout << lst[i] << ' ';
}執行結果是1, 1.1, c,符合預期。
以下是完整程式碼
#include <iostream>
#include <cstdlib>
#include <cassert>
#include <vector>
#include <type_traits>
enum {
INT,
UINT,
CHAR,
UCHAR,
FLOAT,
DOUBLE
};
struct U {
union {
int intData;
uint uintData;
char charData;
u_char ucharData;
float floatData;
double doubleData;
};
// To figure out which type we're using
int type;
friend std::ostream& operator<<(std::ostream& os, const U& u) {
int type = u.type;
switch (type) {
case INT: {
os << u.intData;
break;
}
case UINT: {
os << u.uintData;
break;
}
case CHAR: {
os << u.charData;
break;
}
case UCHAR: {
os << u.ucharData;
break;
}
case FLOAT: {
os << u.floatData;
break;
}
case DOUBLE: {
os << u.doubleData;
break;
}
default: {
assert(0);
}
}
return os;
}
};
struct Node {
void *data = nullptr;
int type;
};
struct __list {
Node node;
};
struct list {
__list *ptr;
int offset{};
int size;
U u;
list(int size) : size(size) {
ptr = static_cast<__list *>(malloc(sizeof(__list) * (size + 1)));
}
list(const list& other) = default;
list& operator=(const list& other) = default;
~list() {
ptr -= offset;
free(ptr);
}
void append(int& __data) {
if (offset + 1 <= size) {
ptr->node.data = static_cast<void *>(&__data);
ptr->node.type = INT;
++ptr;
++offset;
}
else
std::cout << "The list has achived it's capacity\n";
}
void append(float& __data) {
ptr->node.data = static_cast<void *>(&__data);
ptr->node.type = FLOAT;
if (offset + 1 <= size) {
++ptr;
++offset;
}
else
std::cout << "The list has achived it's capacity\n";
}
void append(double& __data) {
ptr->node.data = static_cast<void *>(&__data);
ptr->node.type = DOUBLE;
if (offset + 1 <= size) {
++ptr;
++offset;
}
else
std::cout << "The list has achived it's capacity\n";
}
void append(char& __data) {
ptr->node.data = static_cast<void *>(&__data);
ptr->node.type = CHAR;
if (offset + 1 <= size) {
++ptr;
++offset;
}
else
std::cout << "The list has achived it's capacity\n";
}
void append(u_char& __data) {
ptr->node.data = static_cast<void *>(&__data);
ptr->node.type = UCHAR;
if (offset + 1 <= size) {
++ptr;
++offset;
}
else
std::cout << "The list has achived it's capacity\n";
}
void append(uint& __data) {
ptr->node.data = static_cast<void *>(&__data);
ptr->node.type = UINT;
if (offset + 1 <= size) {
++ptr;
++offset;
}
else
std::cout << "The list has achived it's capacity\n";
}
U operator[](int index) {
auto it = ptr - offset + index;
auto __data = it->node.data;
int type = it->node.type;
switch (type) {
case INT: {
u.intData = *(static_cast<int *>(__data));
u.type = INT;
break;
}
case UINT: {
u.uintData = *static_cast<uint *>(__data);
u.type = UINT;
break;
}
case CHAR: {
u.charData = *static_cast<char *>(__data);
u.type = CHAR;
break;
}
case UCHAR: {
u.ucharData = *static_cast<u_char *>(__data);
u.type = UCHAR;
break;
}
case FLOAT: {
u.floatData = *static_cast<float *>(__data);
u.type = FLOAT;
break;
}
case DOUBLE: {
u.doubleData = *static_cast<double *>(__data);
u.type = DOUBLE;
break;
}
default: {
assert(0);
}
}
return u;
}
};到這裡,一個Pythonic的list就成型了,剩下的其它函數實現方式也就大同小異。在設計list的時候,由於設計到指標,因此對於記憶體洩露方面需要比較謹慎。以上的實現僅僅涉及到了一級指標,Python官方實現是採用二級指標,感興趣的話可以去學習學習別人是怎麼實現的~