使用單卡v100 32g或更低視訊記憶體的卡,使用peft工具qlora或lora混合精度訓練大模型chatGLM2-6b,torch混合精度加速穩定訓練,解決qlora loss變成nan的問題!
最近新換了工作,以後的工作內容會和大模型相關,所以先抽空跑了一下chatGLM2-6b的demo,使用Qlora或lora微調模型
今天簡單寫個檔案記錄一下,順便也是一個簡單的教學,並且踩了qlora loss變成nan訓練不穩定的問題
本教學並沒有寫lora的原理,需要的話自行查閱
1.chatGLM2-6b 模型我已經從huggingface 下載到伺服器,因為我的伺服器不能直接連線huggingface 下載

2.列印模型結構
1 from transformers import AutoModel 2 3 model_name = "/data/tmp/chatGLM2_6b_pretrain" 4 model = AutoModel.from_pretrained(model_name, trust_remote_code=True) 5 print(model)
ChatGLMForConditionalGeneration(
(transformer): ChatGLMModel(
(embedding): Embedding(
(word_embeddings): Embedding(65024, 4096)
)
(rotary_pos_emb): RotaryEmbedding()
(encoder): GLMTransformer(
(layers): ModuleList(
(0-27): 28 x GLMBlock(
(input_layernorm): RMSNorm()
(self_attention): SelfAttention(
(query_key_value): Linear(in_features=4096, out_features=4608, bias=True)
(core_attention): CoreAttention(
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(dense): Linear(in_features=4096, out_features=4096, bias=False)
)
(post_attention_layernorm): RMSNorm()
(mlp): MLP(
(dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)
(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False)
)
)
)
(final_layernorm): RMSNorm()
)
(output_layer): Linear(in_features=4096, out_features=65024, bias=False)
)
)
query_key_value 這個矩陣不是三個方陣拼接到一起,應該是Wq 4096*4096 Wk 4096*256 Wv 4096*256 使用的 group-attention
3.列印新增lora後的模型結構
1 from transformers import AutoTokenizer, AutoModel, AutoConfig 2 from peft import LoraConfig, get_peft_model, TaskType 3 4 model_name = "/data/tmp/chatGLM2_6b_pretrain" 5 model = AutoModel.from_pretrained(model_name, trust_remote_code=True) 6 7 config = LoraConfig( 8 peft_type="LORA", 9 task_type=TaskType.CAUSAL_LM, 10 inference_mode=False, 11 r=8, 12 lora_alpha=16, 13 lora_dropout=0.1, 14 fan_in_fan_out=False, 15 bias='lora_only', 16 target_modules=["query_key_value"] 17 ) 18 19 model = get_peft_model(model, config) 20 print(model)
PeftModelForCausalLM(
(base_model): LoraModel(
(model): ChatGLMForConditionalGeneration(
(transformer): ChatGLMModel(
(embedding): Embedding(
(word_embeddings): Embedding(65024, 4096)
)
(rotary_pos_emb): RotaryEmbedding()
(encoder): GLMTransformer(
(layers): ModuleList(
(0-27): 28 x GLMBlock(
(input_layernorm): RMSNorm()
(self_attention): SelfAttention(
(query_key_value): Linear(
in_features=4096, out_features=4608, bias=True
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=4608, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(core_attention): CoreAttention(
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(dense): Linear(in_features=4096, out_features=4096, bias=False)
)
(post_attention_layernorm): RMSNorm()
(mlp): MLP(
(dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)
(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False)
)
)
)
(final_layernorm): RMSNorm()
)
(output_layer): Linear(in_features=4096, out_features=65024, bias=False)
)
)
)
)
會發現 在query_key_value 矩陣下 多了兩個全連線層,lora_A 和 lora_B ,這兩個全連線層就是要訓練的
4.準備資料集,我們使用的firefly資料集,可以自行去huggingface下載jsonl格式,需要提前劃分好訓練集和測試集 qa_dataset.py
1 # -*- coding: utf-8 -*- 2 from torch.utils.data import Dataset 3 import torch 4 import json 5 import numpy as np 6 7 8 class QADataset(Dataset): 9 def __init__(self, data_path, tokenizer, max_source_length, max_target_length) -> None: 10 super().__init__() 11 self.tokenizer = tokenizer 12 self.max_source_length = max_source_length 13 self.max_target_length = max_target_length 14 self.max_seq_length = self.max_source_length + self.max_target_length 15 16 self.data = [] 17 with open(data_path, "r", encoding='utf-8') as f: 18 for line in f: 19 if not line or line == "": 20 continue 21 json_line = json.loads(line) 22 # {'kind': 'NLI', 'input': '自然語言推理:\n前提:家裡人心甘情願地養他,還有幾家想讓他做女婿的\n假設:他是被家裡人收養的孤兒', 'target': '中立'} 23 kind = json_line["kind"] 24 input = json_line["input"] 25 target = json_line["target"] 26 self.data.append({ 27 "question": input, 28 "answer": "--**"+kind+"**--\n"+target 29 }) 30 print("data load , size:", len(self.data)) 31 def preprocess(self, question, answer): 32 prompt = self.tokenizer.build_prompt(question, None) 33 34 a_ids = self.tokenizer.encode(text=prompt, add_special_tokens=True, truncation=True, 35 max_length=self.max_source_length) 36 37 b_ids = self.tokenizer.encode(text=answer, add_special_tokens=False, truncation=True, 38 max_length=self.max_target_length-1) #因為會補充eos_token 39 40 context_length = len(a_ids) 41 input_ids = a_ids + b_ids + [self.tokenizer.eos_token_id] 42 labels = [self.tokenizer.pad_token_id] * context_length + b_ids + [self.tokenizer.eos_token_id] 43 44 pad_len = self.max_seq_length - len(input_ids) 45 input_ids = input_ids + [self.tokenizer.pad_token_id] * pad_len 46 labels = labels + [self.tokenizer.pad_token_id] * pad_len 47 labels = [(l if l != self.tokenizer.pad_token_id else -100) for l in labels] 48 return input_ids, labels 49 50 def __getitem__(self, index): 51 item_data = self.data[index] 52 53 input_ids, labels = self.preprocess(**item_data) 54 55 return { 56 "input_ids": torch.LongTensor(np.array(input_ids)), 57 "labels": torch.LongTensor(np.array(labels)) 58 } 59 60 def __len__(self): 61 return len(self.data) 62 63 if __name__ == "__main__": 64 with open("/data/tmp/firefly_data/firefly-train-1.1M.jsonl", "r", encoding='utf-8') as f_read,open("/data/tmp/firefly_data/firefly_train80000.jsonl","w",encoding='utf-8') as f_trainx, open("/data/tmp/firefly_data/firefly_train.jsonl","w",encoding='utf-8') as f_train, open("/data/tmp/firefly_data/firefly_test.jsonl","w",encoding='utf-8') as f_test: 65 lines = f_read.readlines() 66 67 f_test.writelines(lines[:1000]) 68 f_train.writelines(lines[1000:]) 69 f_trainx.writelines(lines[1000:81000])
5.訓練lora,使用半精度,佔用視訊記憶體很大,batch_size只能為1,視訊記憶體就要佔用到30g了,而且訓練很久,為了解決這個視訊記憶體佔用大的問題,後面又嘗試了qlora
train_lora.py
1 # -*- coding: utf-8 -*- 2 import pandas as pd 3 from torch.utils.data import DataLoader 4 from transformers import AutoTokenizer, AutoModel 5 from qa_dataset import QADataset 6 from peft import LoraConfig, get_peft_model, TaskType 7 from tqdm import tqdm 8 import torch 9 import os, time, sys 10 import numpy as np 11 12 13 def train(epoch, model, device, loader, optimizer, gradient_accumulation_steps,model_output_dir): 14 model.train() 15 time1 = time.time() 16 losses = [] 17 train_bar = tqdm(loader,total=len(loader)) 18 for index, data in enumerate(train_bar): 19 input_ids = data['input_ids'].to(device, dtype=torch.long) 20 labels = data['labels'].to(device, dtype=torch.long) 21 22 outputs = model( 23 input_ids=input_ids, 24 labels=labels, 25 ) 26 loss = outputs.loss 27 # 反向傳播,計算當前梯度 28 loss.backward() 29 losses.append(loss.item()) 30 # 梯度累積步數 31 if (index % gradient_accumulation_steps == 0 and index != 0) or index == len(loader) - 1: 32 # 更新網路引數 33 optimizer.step() 34 # 清空過往梯度 35 optimizer.zero_grad() 36 37 if index % 300 == 0: 38 model_save_path = os.path.join(model_output_dir,"index_{}".format(index)) 39 if os.path.exists(model_save_path): 40 pass 41 else: 42 os.makedirs(model_save_path) 43 model.save_pretrained(model_save_path) 44 train_bar.set_description("epoch:{} idx:{} loss:{:.6f}".format(epoch,index,np.mean(losses))) 45 46 47 48 def validate(tokenizer, model, device, loader, max_length): 49 model.eval() 50 predictions = [] 51 actuals = [] 52 with torch.no_grad(): 53 for _, data in enumerate(tqdm(loader, file=sys.stdout, desc="Validation Data")): 54 input_ids = data['input_ids'].to(device, dtype=torch.long) 55 labels = data['labels'].to(device, dtype=torch.long) 56 generated_ids = model.generate( 57 input_ids=input_ids, 58 max_length=max_length, 59 do_sample=False, 60 temperature=0 61 ) 62 preds = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True) for g in 63 generated_ids] 64 target = [tokenizer.decode(t, skip_special_tokens=True, clean_up_tokenization_spaces=True) for t in labels] 65 predictions.extend(preds) 66 actuals.extend(target) 67 return predictions, actuals 68 69 70 def main(): 71 model_name = "/data/tmp/chatGLM2_6b_pretrain" 72 train_json_path = "/data/tmp/firefly_data/firefly_train20000.jsonl" 73 val_json_path = "/data/tmp/firefly_data/firefly_test.jsonl" 74 max_source_length = 60 75 max_target_length = 360 76 epochs = 1 77 batch_size = 1 78 lr = 1e-4 79 lora_rank = 8 80 lora_alpha = 32 81 gradient_accumulation_steps = 16 82 model_output_dir = "output" 83 # 裝置 84 device = torch.device("cuda:0") 85 86 # 載入分詞器和模型 87 tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) 88 model = AutoModel.from_pretrained(model_name, trust_remote_code=True) 89 90 # setup peft 91 peft_config = LoraConfig( 92 task_type=TaskType.CAUSAL_LM, 93 inference_mode=False, 94 r=lora_rank, 95 lora_alpha=lora_alpha, 96 lora_dropout=0.1 97 ) 98 model = get_peft_model(model, peft_config) 99 model.is_parallelizable = True 100 model.model_parallel = True 101 model.print_trainable_parameters() 102 # 轉為半精度 103 model = model.half() 104 model.float() 105 106 print("Start Load Train Data...") 107 train_params = { 108 "batch_size": batch_size, 109 "shuffle": True, 110 "num_workers": 0, 111 } 112 training_set = QADataset(train_json_path, tokenizer, max_source_length, max_target_length) 113 training_loader = DataLoader(training_set, **train_params) 114 print("Start Load Validation Data...") 115 val_params = { 116 "batch_size": batch_size, 117 "shuffle": False, 118 "num_workers": 0, 119 } 120 val_set = QADataset(val_json_path, tokenizer, max_source_length, max_target_length) 121 val_loader = DataLoader(val_set, **val_params) 122 123 optimizer = torch.optim.AdamW(params=model.parameters(), lr=lr) 124 model = model.to(device) 125 print("Start Training...") 126 for epoch in range(epochs): 127 train(epoch, model, device, training_loader, optimizer, gradient_accumulation_steps,model_output_dir) 128 # print("Save Model To ", model_output_dir) 129 # model.save_pretrained(model_output_dir) 130 # 驗證 131 print("Start Validation...") 132 with torch.no_grad(): 133 predictions, actuals = validate(tokenizer, model, device, val_loader, max_target_length) 134 # 驗證結果儲存 135 final_df = pd.DataFrame({"Generated Text": predictions, "Actual Text": actuals}) 136 val_data_path = os.path.join(model_output_dir, "predictions.csv") 137 final_df.to_csv(val_data_path) 138 print("Validation Data To ", val_data_path) 139 140 141 if __name__ == '__main__': 142 main()
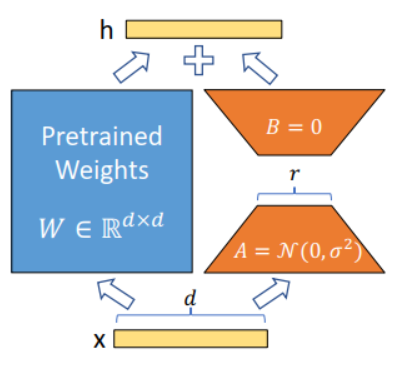
6.有很多同學手裡沒有v100 32g顯示卡,即便batch_size=1 也沒辦法訓練,所以又研究了qlora訓練,qlora相比於lora來說就是多了一個模型量化過程,他會把原模型量化得到4-bit NormalFloat,這就會讓原模型的視訊記憶體佔用很低,就可以讓更多的視訊記憶體來存放lora部分的引數
但是4-bit NormalFloat 結合手動half半精度的混合精度訓練會導致loss很不穩定,可能一跑起來就變成nan了,就連float32結合半精度float16也是不穩定的,所以這塊踩了坑,手動使用model.half() loss總會變成nan值,最後使用torch官方的自動混合精度就好了,它會自動的進行混合精度和梯度縮放,不至於產生超過半精度上下限的nan值。
這裡說明為什麼使用fp16混合精度,而不用float32,實踐發現使用混合精度訓練可以提速5-6倍的訓練時間,在大模型上動不動就要跑很久,時間成本很高。
trian_qlora.py
1 # -*- coding: utf-8 -*- 2 import pandas as pd 3 from torch.utils.data import DataLoader 4 from transformers import AutoTokenizer, AutoModel,BitsAndBytesConfig 5 from qa_dataset import QADataset 6 from peft import LoraConfig, get_peft_model, TaskType,prepare_model_for_kbit_training 7 from tqdm import tqdm 8 import torch 9 import os, time, sys 10 from transformers import ( 11 set_seed, 12 HfArgumentParser, 13 TrainingArguments, 14 AutoModelForCausalLM 15 ) 16 import bitsandbytes as bnb 17 from collections import defaultdict 18 import numpy as np 19 import os 20 21 def verify_model_dtype(model): 22 """ 23 檢視模型種各種型別的引數的情況 24 """ 25 dtype2param_num = defaultdict(int) # 每種資料型別的引數量 26 dtype2param_name = defaultdict(list) # 每種資料型別的引數名稱 27 dtype2trainable_param_num = defaultdict(int) # 每種資料型別參與訓練的引數量 28 dtype2trainable_param_name = defaultdict(list) # 每種資料型別參與訓練的引數名稱 29 for name, p in model.named_parameters(): 30 dtype = p.dtype 31 dtype2param_num[dtype] += p.numel() 32 dtype2param_name[dtype].append(name) 33 if p.requires_grad: 34 dtype2trainable_param_num[dtype] += p.numel() 35 dtype2trainable_param_name[dtype].append(name) 36 # 統計全部引數中,各種型別引數分佈 37 total = 0 38 print('verify all params of the model') 39 for k, v in dtype2param_num.items(): 40 total += v 41 for k, v in dtype2param_num.items(): 42 print(k, v, v / total) 43 for k, v in dtype2trainable_param_name.items(): 44 print(k, v) 45 46 print() 47 # 統計可訓練引數中,各種型別引數分佈 48 print('verify trainable params the model') 49 total_trainable = 0 50 for k, v in dtype2trainable_param_num.items(): 51 total_trainable += v 52 for k, v in dtype2trainable_param_num.items(): 53 print(k, v, v / total_trainable) 54 for k, v in dtype2trainable_param_num.items(): 55 print(k, v) 56 57 def find_all_linear_names(model): 58 """ 59 找出所有全連線層,為所有全連線新增adapter 60 """ 61 cls = bnb.nn.Linear4bit 62 lora_module_names = set() 63 for name, module in model.named_modules(): 64 if isinstance(module, cls): 65 names = name.split('.') 66 lora_module_names.add(names[0] if len(names) == 1 else names[-1]) 67 68 if 'lm_head' in lora_module_names: # needed for 16-bit 69 lora_module_names.remove('lm_head') 70 return list(lora_module_names) 71 72 def train(epoch, model, device, loader, optimizer,scaler, gradient_accumulation_steps,model_output_dir): 73 model.train() 74 time1 = time.time() 75 losses = [] 76 train_bar = tqdm(loader,total=len(loader)) 77 for index, data in enumerate(train_bar): 78 optimizer.zero_grad() 79 with torch.autocast(device_type="cuda",dtype=torch.float16): 80 input_ids = data['input_ids'].to(device, dtype=torch.long) 81 labels = data['labels'].to(device, dtype=torch.long) 82 83 outputs = model( 84 input_ids=input_ids, 85 labels=labels, 86 ) 87 loss = outputs.loss 88 losses.append(loss.item()) 89 90 scaler.scale(loss).backward() 91 # Unscales the gradients of optimizer's assigned params in-place 92 # scaler.unscale_(optimizer) 93 94 # Since the gradients of optimizer's assigned params are unscaled, clips as usual: 95 # torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm) 96 97 # optimizer's gradients are already unscaled, so scaler.step does not unscale them, 98 # although it still skips optimizer.step() if the gradients contain infs or NaNs. 99 scaler.step(optimizer) 100 101 # Updates the scale for next iteration. 102 scaler.update() 103 104 # # 反向傳播,計算當前梯度 105 # loss.backward() 106 # optimizer.step() 107 # 梯度累積步數 108 # if (index % gradient_accumulation_steps == 0 and index != 0) or index == len(loader) - 1: 109 # # 更新網路引數 110 # # optimizer.step() 111 # scaler.step(optimizer) 112 # scaler.update() 113 # # 清空過往梯度 114 # optimizer.zero_grad() 115 116 if index % 300 == 0: 117 model_save_path = os.path.join(model_output_dir,"index_{}".format(index)) 118 if os.path.exists(model_save_path): 119 pass 120 else: 121 os.makedirs(model_save_path) 122 model.save_pretrained(model_save_path) 123 train_bar.set_description("epoch:{} idx:{} loss:{:.6f}".format(epoch,index,np.mean(losses))) 124 # 100輪列印一次 loss 125 # if index % 100 == 0 or index == len(loader) - 1: 126 # time2 = time.time() 127 # tqdm.write( 128 # f"{index}, epoch: {epoch} -loss: {str(loss)} ; each step's time spent: {(str(float(time2 - time1) / float(index + 0.0001)))}") 129 130 131 def validate(tokenizer, model, device, loader, max_length): 132 model.eval() 133 predictions = [] 134 actuals = [] 135 with torch.no_grad(): 136 for _, data in enumerate(tqdm(loader, file=sys.stdout, desc="Validation Data")): 137 input_ids = data['input_ids'].to(device, dtype=torch.long) 138 labels = data['labels'].to(device, dtype=torch.long) 139 generated_ids = model.generate( 140 input_ids=input_ids, 141 max_length=max_length, 142 do_sample=False, 143 temperature=0 144 ) 145 preds = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True) for g in 146 generated_ids] 147 target = [tokenizer.decode(t, skip_special_tokens=True, clean_up_tokenization_spaces=True) for t in labels] 148 predictions.extend(preds) 149 actuals.extend(target) 150 return predictions, actuals 151 152 153 def main(): 154 model_name = "/data/tmp/chatGLM2_6b_pretrain" 155 train_json_path = "/data/tmp/firefly_data/firefly_train80000.jsonl" 156 val_json_path = "/data/tmp/firefly_data/firefly_test.jsonl" 157 max_source_length = 128 158 max_target_length = 512 159 epochs = 1 160 batch_size = 16 161 lr = 1e-4 162 lora_rank = 32 163 lora_alpha = 32 164 gradient_accumulation_steps = 16 165 model_output_dir = "output" 166 # 裝置 167 device = torch.device("cuda:0") 168 lora_dropout = 0.05 169 170 # 載入分詞器和模型 171 tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) 172 # model = AutoModel.from_pretrained(model_name, trust_remote_code=True) 173 # 載入模型 174 model = AutoModelForCausalLM.from_pretrained( 175 model_name, 176 device_map=0, 177 load_in_4bit=True, 178 torch_dtype=torch.float16, 179 trust_remote_code=True, 180 quantization_config=BitsAndBytesConfig( 181 load_in_4bit=True, 182 bnb_4bit_compute_dtype=torch.float16, 183 bnb_4bit_use_double_quant=True, 184 bnb_4bit_quant_type="nf4", 185 llm_int8_threshold=6.0, 186 llm_int8_has_fp16_weight=False, 187 ), 188 ) 189 190 # casts all the non int8 modules to full precision (fp32) for stability 191 model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=True) 192 print(f'memory footprint of model: {model.get_memory_footprint()/(1024*1024*1024)} GB') 193 194 # 找到所有需要插入adapter的全連線層 195 target_modules = find_all_linear_names(model) 196 print("全連線層:",target_modules) 197 # 初始化lora設定 198 peft_config = LoraConfig( 199 r=lora_rank, 200 lora_alpha=lora_alpha, 201 # target_modules=target_modules, 202 target_modules=["query_key_value","dense","dense_h_to_4h","dense_4h_to_h"], 203 lora_dropout=lora_dropout, 204 bias="none", 205 task_type="CAUSAL_LM", 206 ) 207 208 model = get_peft_model(model, peft_config) 209 210 211 # model.is_parallelizable = True 212 # model.model_parallel = True 213 model.print_trainable_parameters() 214 # 轉為半精度 215 # model = model.half() #You shouldn’t call half manually on the model or data. 不使用torch官方的自動混合精度和梯度縮放,手動使用half()半精度會導致模型loss變成nan,使用官方的混合精度需要關閉half()手動半精度,不然會報錯 216 # model.float() 217 model.config.torch_dtype = torch.float32 218 # 檢視模型種各種型別的引數的情況 219 verify_model_dtype(model) 220 221 print(model) 222 223 print("Start Load Train Data...") 224 train_params = { 225 "batch_size": batch_size, 226 "shuffle": True, 227 "num_workers": 0, 228 } 229 training_set = QADataset(train_json_path, tokenizer, max_source_length, max_target_length) 230 training_loader = DataLoader(training_set, **train_params) 231 print("Start Load Validation Data...") 232 val_params = { 233 "batch_size": batch_size, 234 "shuffle": False, 235 "num_workers": 0, 236 } 237 val_set = QADataset(val_json_path, tokenizer, max_source_length, max_target_length) 238 val_loader = DataLoader(val_set, **val_params) 239 240 241 scaler = torch.cuda.amp.GradScaler() 242 optimizer = torch.optim.AdamW(params=model.parameters(), lr=lr) 243 model = model.to(device) 244 print("Start Training...") 245 for epoch in range(epochs): 246 train(epoch, model, device, training_loader, optimizer,scaler, gradient_accumulation_steps,model_output_dir) 247 print("Save Model To ", model_output_dir) 248 model.save_pretrained(model_output_dir) 249 # 驗證 250 print("Start Validation...") 251 with torch.no_grad(): 252 predictions, actuals = validate(tokenizer, model, device, val_loader, max_target_length) 253 # 驗證結果儲存 254 final_df = pd.DataFrame({"Generated Text": predictions, "Actual Text": actuals}) 255 val_data_path = os.path.join(model_output_dir, "predictions.csv") 256 final_df.to_csv(val_data_path) 257 print("Validation Data To ", val_data_path) 258 259 260 if __name__ == '__main__': 261 main()
torch官方的自動混合精度程式碼
# Creates model and optimizer in default precision model = Net().cuda() optimizer = optim.SGD(model.parameters(), ...) # Creates a GradScaler once at the beginning of training. scaler = GradScaler() for epoch in epochs: for input, target in data: optimizer.zero_grad() # Runs the forward pass with autocasting. with autocast(device_type='cuda', dtype=torch.float16): output = model(input) loss = loss_fn(output, target) # Scales loss. Calls backward() on scaled loss to create scaled gradients. # Backward passes under autocast are not recommended. # Backward ops run in the same dtype autocast chose for corresponding forward ops. scaler.scale(loss).backward() # scaler.step() first unscales the gradients of the optimizer's assigned params. # If these gradients do not contain infs or NaNs, optimizer.step() is then called, # otherwise, optimizer.step() is skipped. scaler.step(optimizer) # Updates the scale for next iteration. scaler.update()
qlora在batch=16 lora_rank = 32 target_modules=["query_key_value","dense","dense_h_to_4h","dense_4h_to_h"] 對所有模型矩陣引數都進行lora的情況下才佔用不足29g視訊記憶體


7.使用qlora + torch fp16混合精度訓練可以穩定,模型輸出結果:
[Round 1] 問:在上海的蘋果代工廠,較低的基本工資讓工人們形成了「軟強制」的加班默契。加班能多拿兩三千,「自願」加班成為常態。律師提示,加班後雖能獲得一時不錯的報酬,但過重的工作負荷會透支身體,可能對今後勞動權利造成不利影響。 輸出摘要: 答: --**Summary**-- 蘋果代工廠員工調查:為何爭著「自願」加班 [Round 1] 問:上聯:把酒邀春,春日三人醉 下聯: 答: --**Couplet**-- 梳妝佩玉,玉王點一嬌
actual label
--**Summary**-- 蘋果代工廠員工調查:為何爭著「自願」加班 --**Couplet**-- 梳妝佩玉,玉王點一嬌
8.使用qlora載入模型推理 model_test.py qlora推理佔用的視訊記憶體同樣很低

1 from transformers import AutoTokenizer, AutoModel, AutoConfig,BitsAndBytesConfig 2 from peft import PeftConfig, PeftModel, LoraConfig, get_peft_model, TaskType 3 import torch 4 from transformers import ( 5 set_seed, 6 HfArgumentParser, 7 TrainingArguments, 8 AutoModelForCausalLM 9 ) 10 11 device = torch.device("cuda:0") 12 13 model_name = "/data/tmp/chatGLM2_6b_pretrain" 14 lora_dir = "output" 15 16 # 載入模型 17 model = AutoModelForCausalLM.from_pretrained( 18 model_name, 19 device_map=0, 20 load_in_4bit=True, 21 torch_dtype=torch.float16, 22 trust_remote_code=True, 23 quantization_config=BitsAndBytesConfig( 24 load_in_4bit=True, 25 bnb_4bit_compute_dtype=torch.float16, 26 bnb_4bit_use_double_quant=True, 27 bnb_4bit_quant_type="nf4", 28 llm_int8_threshold=6.0, 29 llm_int8_has_fp16_weight=False, 30 ), 31 ) 32 33 # peft_config = LoraConfig( 34 # r=lora_rank, 35 # lora_alpha=lora_alpha, 36 # # target_modules=target_modules, 37 # target_modules=["query_key_value","dense_h_to_4h"], 38 # lora_dropout=lora_dropout, 39 # bias="none", 40 # task_type="CAUSAL_LM", 41 # ) 42 43 # model = get_peft_model(model, peft_config) 44 45 # model = AutoModel.from_pretrained(model_name, trust_remote_code=True) 46 tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) 47 48 config = PeftConfig.from_pretrained(lora_dir) 49 model = PeftModel.from_pretrained(model, lora_dir) 50 51 model = model.to(device) 52 model.eval() 53 54 while True: 55 text = input("問題:") 56 response, history = model.chat(tokenizer, text, history=[]) 57 print("回答:", response) 58
鄧紫棋在北京鳥巢開演唱會,唱了音樂《 畫》 。 請找出這段話中的實體 回答: --NER-- 北京鳥巢,鄧紫棋