聊聊RNN與Attention
RNN系列:
聊聊RNN&LSTM
聊聊RNN與seq2seq
attention mechanism,稱為注意力機制。基於Attention機制,seq2seq可以像我們人類一樣,將「注意力」集中在必要的資訊上。
Attention的結構
seq2seq存在的問題
seq2seq中使用編碼器對時序資料進行編碼,然後將編碼資訊傳遞給解碼器。此時,編碼器的輸出是固定長度的向量。從正常的理解來看,固定長度的編碼器輸出遲早會有溢位上下文資訊的情況。
編碼器的改進
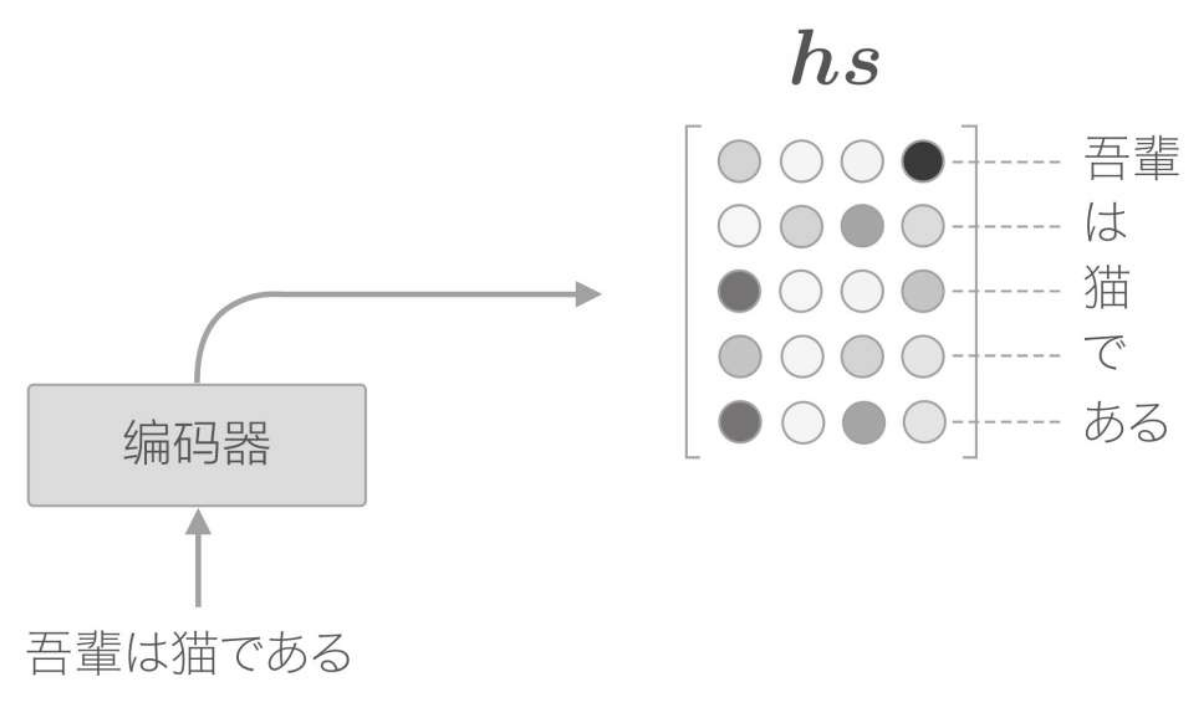
目前的seq2seq結構,只將LSTM層的最後的隱藏狀態傳遞給解碼器,但是編碼器的輸出的長度應該根據輸入文字的長度相應地改變。因此我們可以使用LSTM各個時刻(各個單詞)輸出的隱藏狀態向量,可以獲得和輸入的單詞數相同數量的向量。使用編碼器各個時刻(各個單詞)的LSTM層的隱藏狀態(這裡表示為hs):
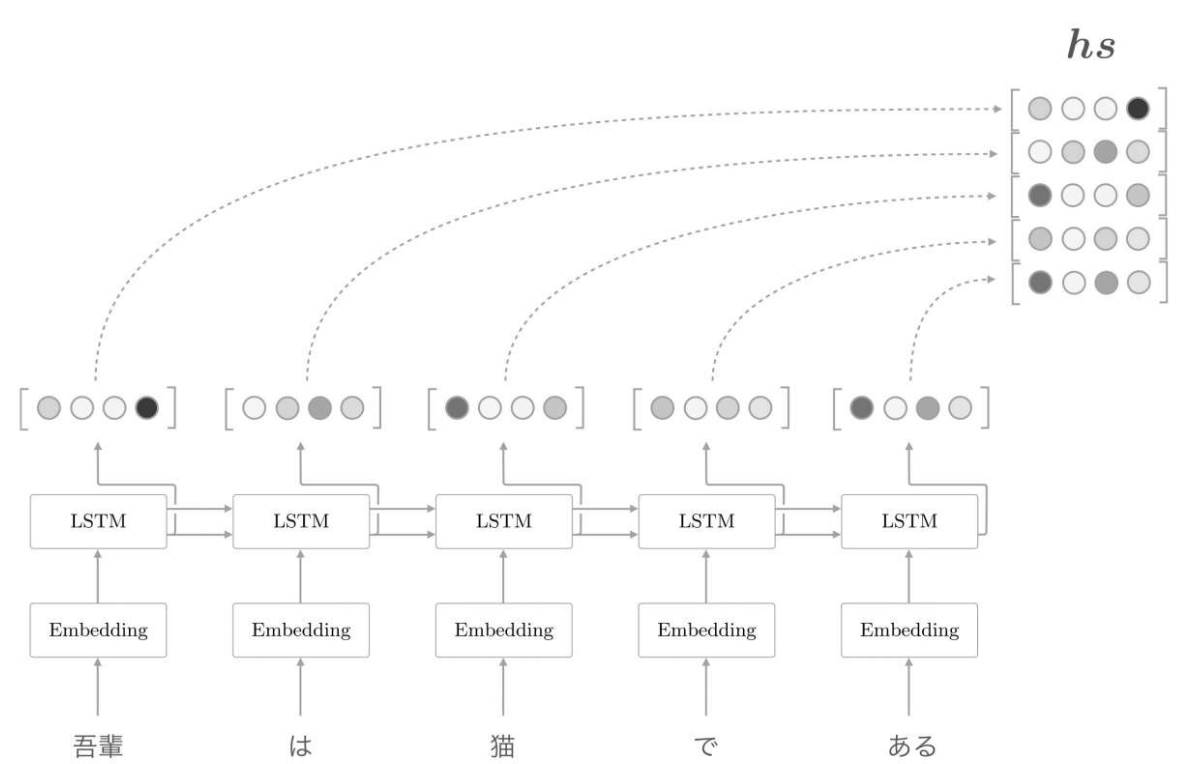
有一點可以確定的是,各個時刻的隱藏狀態中包含了大量當前時刻的輸入單詞的資訊。因此,最終編碼器的輸出hs具有和單詞數相同數量的向量,各個向量中蘊含了各個單詞對應的資訊:
解碼器的改進
改進一
由於編碼器的輸出包含了各個時刻的隱藏狀態向量,因此解碼器的輸入,也需要增加這一層輸入。因此解碼器中就包含了某個時刻下,當前單詞的主要資訊,而如果可以找到這些主要資訊並提取出來,對其做翻譯,就能實現我們的目標。
從現在開始,我們的目標是找出與「翻譯目標詞」有對應關係的「翻譯源詞」的資訊,然後利用這個資訊進行翻譯。也就是說,我們的目標是僅關注必要的資訊,並根據該資訊進行時序轉換。這個機制稱為Attention。
以上的邏輯流程其實就是在模仿人在翻譯單詞時的過程,尤其是中式翻譯;逐字/成對的將中文漢字轉換為對應的英語講出來,我想這種例子在我們身邊是很常見的。哈哈哈哈,很有畫面感!
這個過程,也被稱為 "對齊"。
改進二
增加一個表示各個單詞重要度的權重(記為a)。此時,a像概率分佈一樣,各元素是0.0~1.0的標量,總和是1。然後,計算這個表示各個單詞重要度的權重和單詞向量hs的加權和,可以獲得目標向量。其計算流程如下:
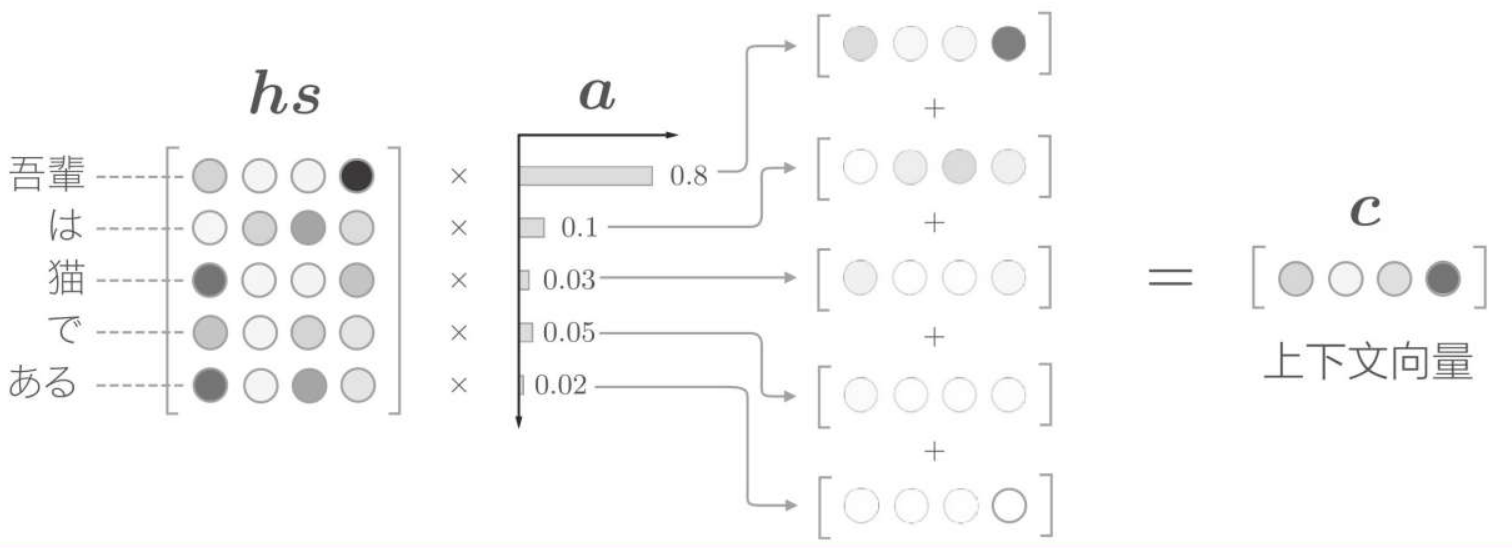
即 hs 向量 與 a 權重向量 的內積
計算單詞向量的加權和,這裡將結果稱為上下文向量,並用符號c表示。
改進三
有了表示各個單詞重要度的權重a,就可以通過加權和獲得上下文向量,從而獲取到主要資訊。那麼,怎麼求這個a呢?
首先,從編碼器的處理開始,到解碼器第一個LSTM層輸出隱藏狀態向量的處理為止,流程如下
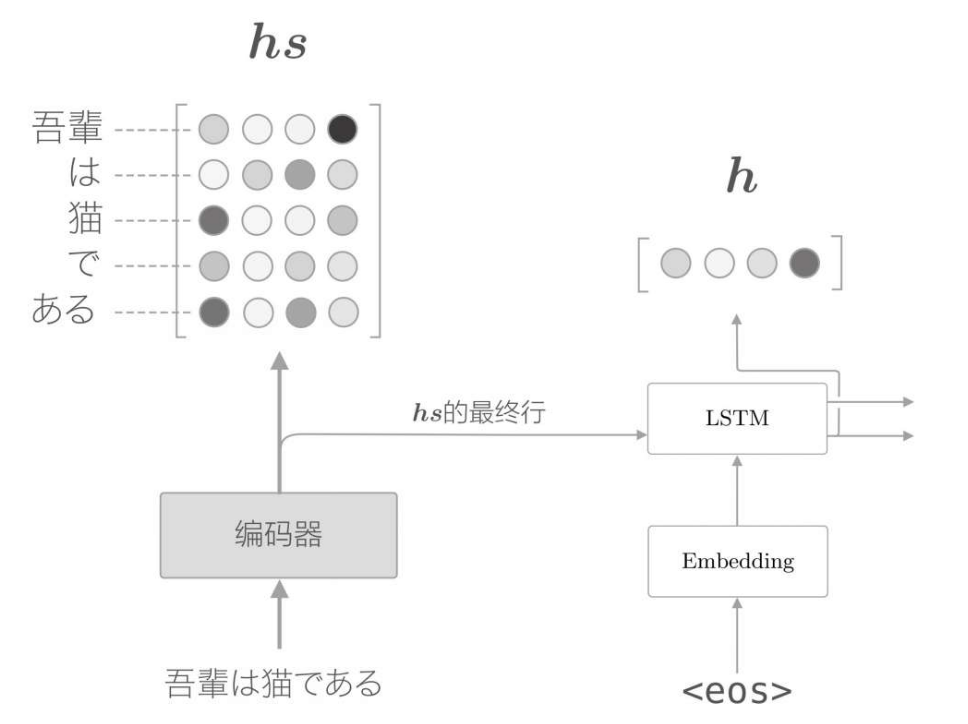
用h表示解碼器的LSTM層的隱藏狀態向量。此時,我們的目標是用數值表示這個h在多大程度上和hs的各個單詞向量「相似」。
因此,可以直接將隱藏狀態向量h 與編碼器全時刻向量hs做點積
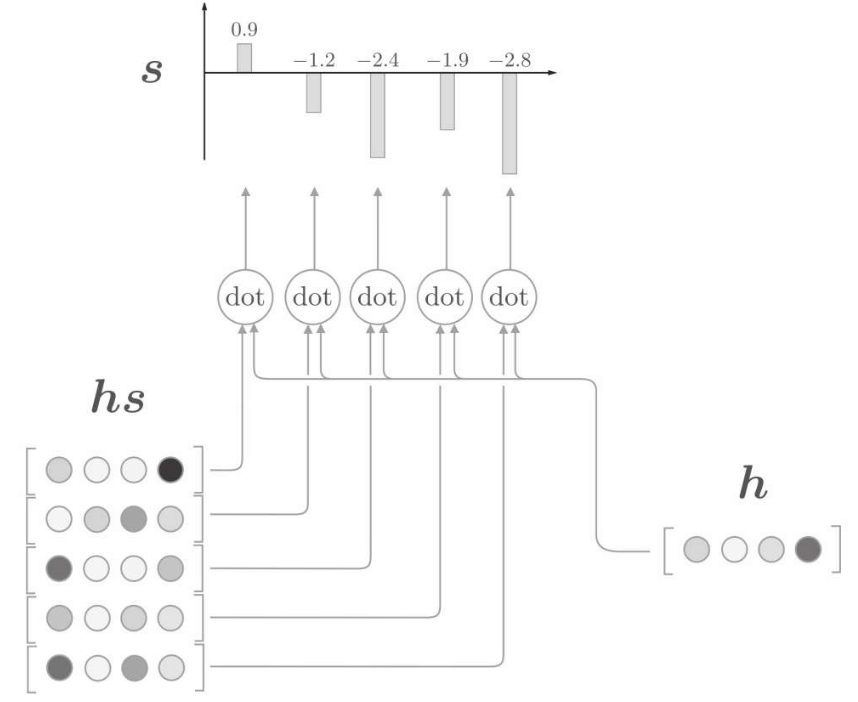
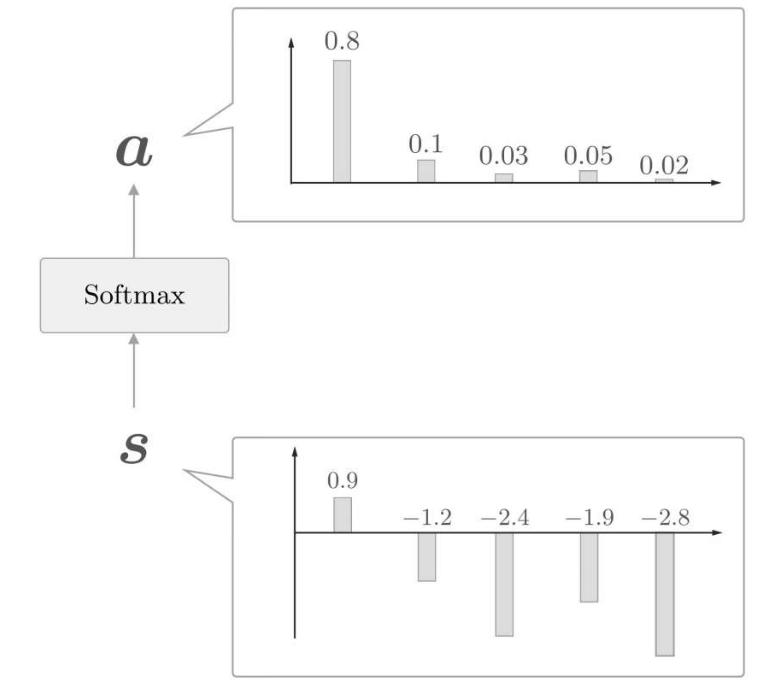
這裡通過向量內積算出h和hs的各個單詞向量之間的相似度,並將其結果表示為s。不過,這個s是正規化之前的值,也稱為得分。再經過softmax函數對點積結果歸一化
計算各個單詞權重的計算圖
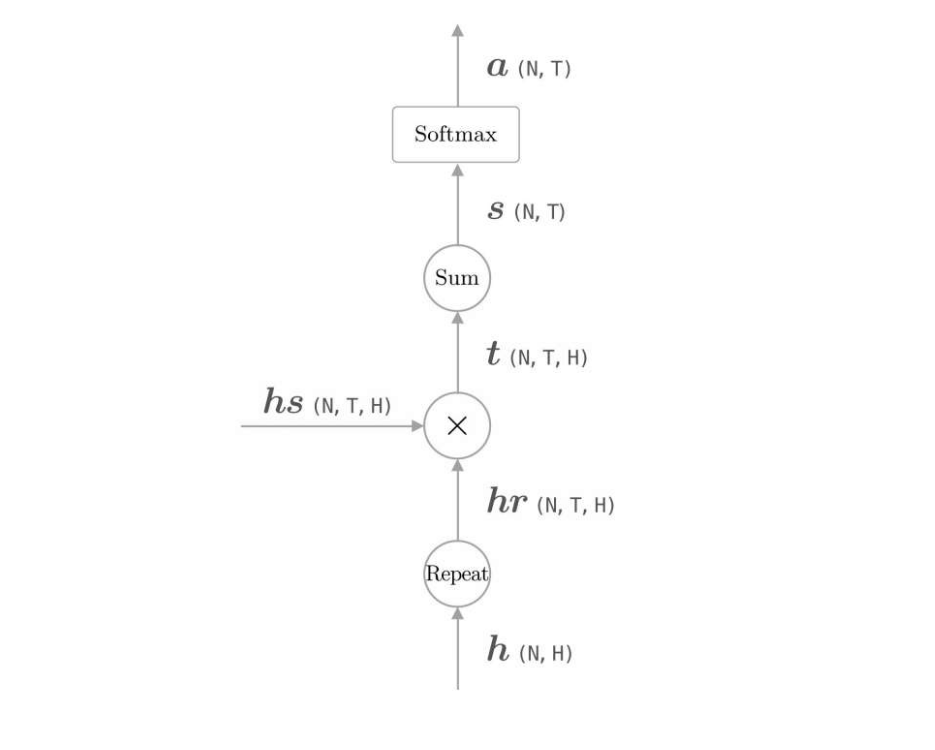
hr向量只是擴大了h向量的部分,使其與hs向量行列一致。
彙總
如上,現在將單詞權重的計算與權重加權兩層邏輯合併起來,如下展示了獲取上下文向量c的計算圖的全貌
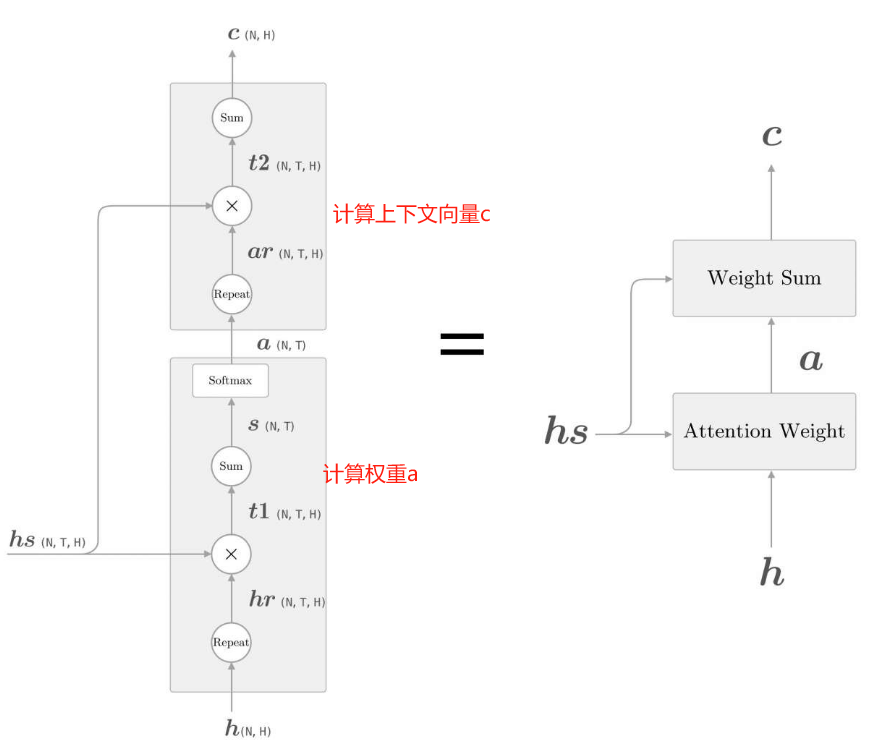
圖中分為Weight Sum層和Attention Weight層進行了實現。
這裡進行的計算是:Attention Weight層關注編碼器輸出的各個單詞向量hs,並計算各個單詞的權重a;
Weight Sum層計算a和hs的加權和,並輸出上下文向量c。我們將進行這一系列計算的層稱為Attention層。
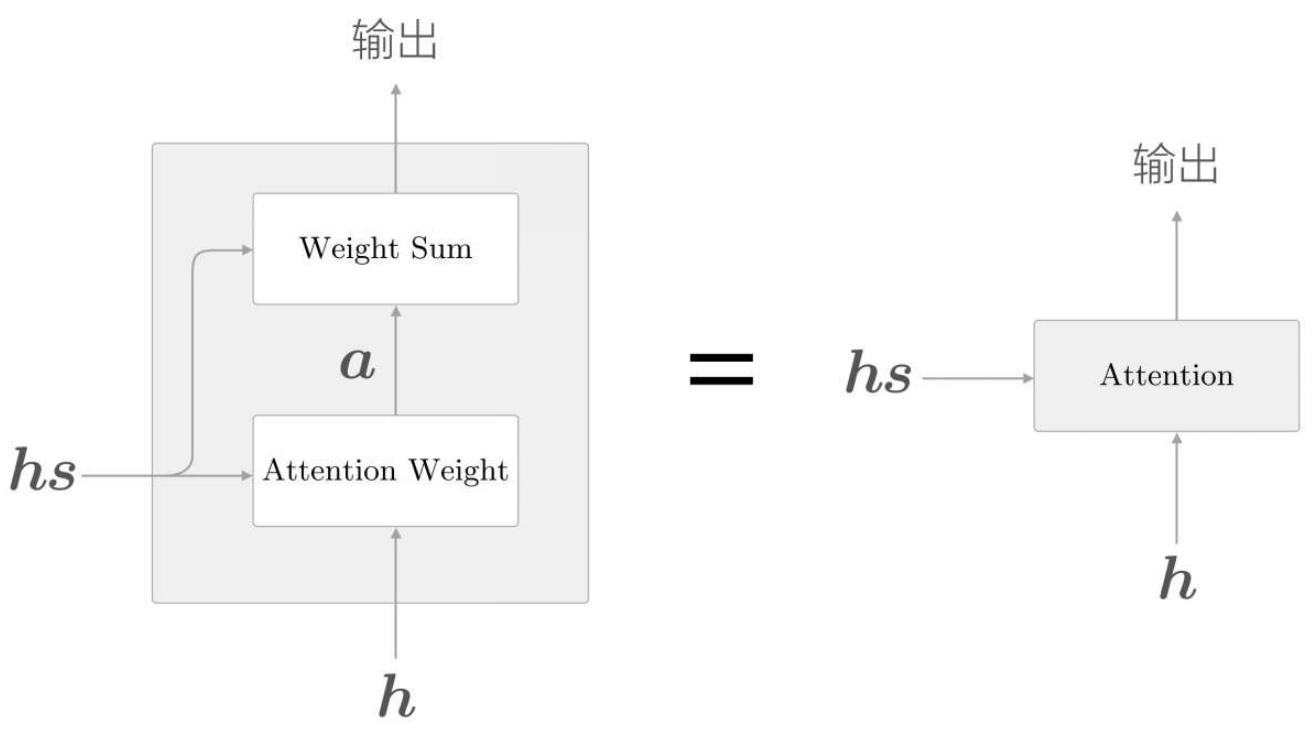
以上就是Attention技術的核心內容。關注編碼器傳遞的資訊hs中的重要元素,基於它算出上下文向量,再繼續流轉傳遞。
編碼器的輸出hs被輸入到各個時刻的Attention層,並輸出當前時刻的上下文向量資訊。最終,具有Attention層的解碼器的層結構,如下所示,
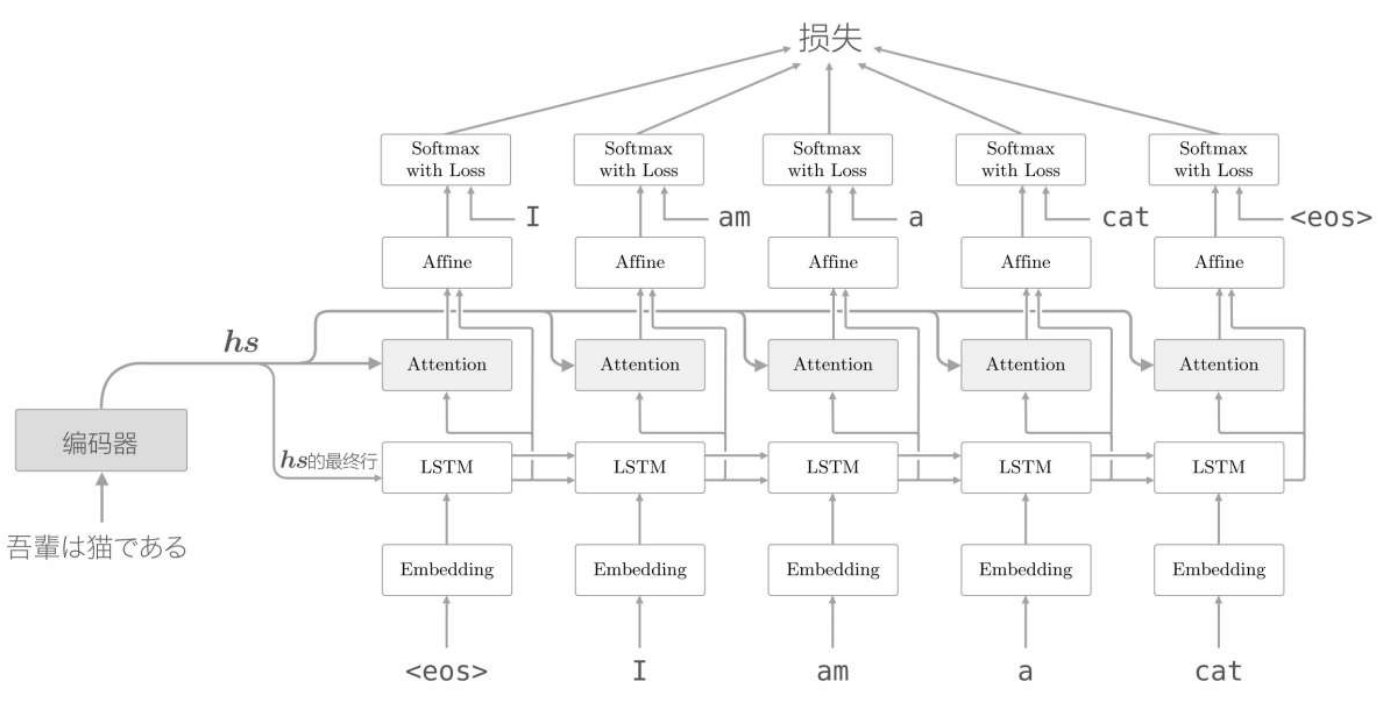
總結
編碼器層輸出各個時刻的向量資訊資料,不僅可以伸縮編碼層的長度限制,更是儲存了更重要的時序時刻資料資訊。
而解碼器層,根據Attention架構(注意力機制),增加權重矩陣a,計算出當前時刻的上下文向量資訊,提取出對齊單詞,進行翻譯。