umich cv-6-2 注意力機制
這節課中介紹了迴圈神經網路的第二部分,主要引入了注意力機制,介紹了注意力機制的應用以及如何理解,在此基礎上建立了注意力層以及transformer架構
注意力機制
上次我們沒有提到sequence to sequence的RNN結構:

以文字翻譯應用為例,我們可以看到它由編碼器與解碼器組成,先是將我們要翻譯的句子拆分成一個個輸入向量,和之前vanilla架構做的事情一樣,經過權重矩陣不斷生成新的隱藏層,最終得到最初的解碼狀態與一個上下文向量,相當於把原始的資訊都編碼到這兩個結果之中,然後解碼器再利用上下文向量與s,不斷生成新的s,同時將輸出的y作為新輸入向量。
但是這種結構的問題在於解碼器使用的是同一個固定大小的上下文向量,當我們這個輸入向量很長很長,比如有1000或者10000時,那麼此時一個上下文向量很難去儲存所有的編碼資訊。
我們可以想到,如果,我們為解碼器的每一層都建立一個上下文向量,就可以解決上述問題,這就引入了注意力機制:

我們使用一個全連線網路計算s與不同隱藏層之間的匹配程度,得到e11,e12......,然後再經過一個softmax,得到一個概率分佈a11,a12.....,我們可以用這個概率分佈去對隱藏層進行線性組合,這樣就產生了第一個上下文向量,這些權重就被稱為注意力權重
這裡的直覺是不同的上下文向量可以去關注輸入向量最匹配的部分,從而去理解不同部分的資訊
然後我們將上述部分擴大成迴圈形式即可,之前是用s0生成c1,然後我們用s1生成c2,再用c2計算s2與y2:

我們將上述結構參照到語言翻譯中,並且視覺化注意力權重的結果:

可以看到對角線上重合的說明這些英語單詞與法語單詞是按照順序相對應的,中間有一部分雖然英語與法語單詞不是按照順序對應,但是注意力機制也還是發現了它們之間的關係,紅色部分就是對應出現錯誤的部分
應用與理解
我們其實可以發現注意力機制並不關心輸入向量以及隱藏層是否按照順序,這種性質可以使它應用到更廣泛的領域:
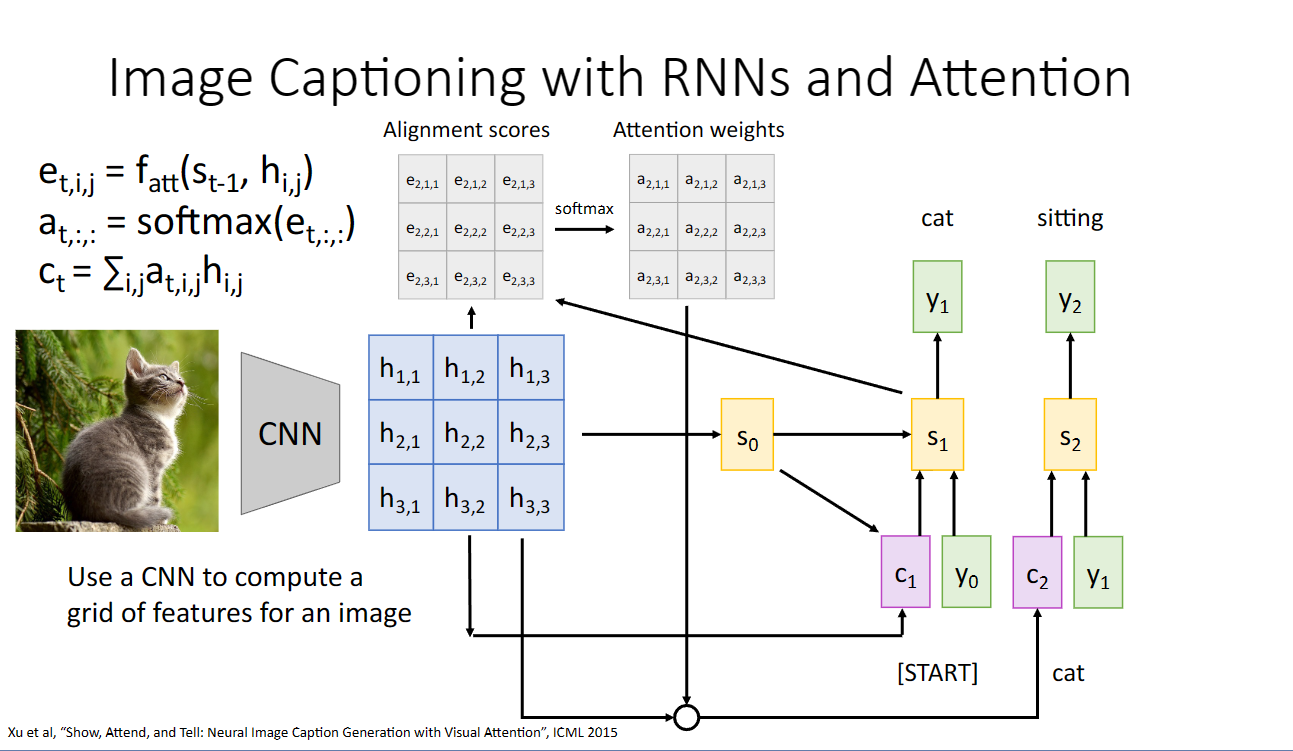
我們可以將隱藏層替換為使用cnn從影象中提取的特徵圖,應該注意力機制,我們可以關注影象的不同區域,並且將不同區域翻譯為對應的語言:

這裡的理解是注意力機制很像人的眼睛,因為人眼只有在某些方向上才能看清,所以我們的眼睛看東西的時候經常處於運動掃視的狀態,和注意力機制關注在不同的step關注不同的區域很像:

注意力層
引入了注意力機制,我們自然想能夠把其抽象為更模組化的注意力層,這樣我們就能夠將其嵌入到不同的神經網路之中
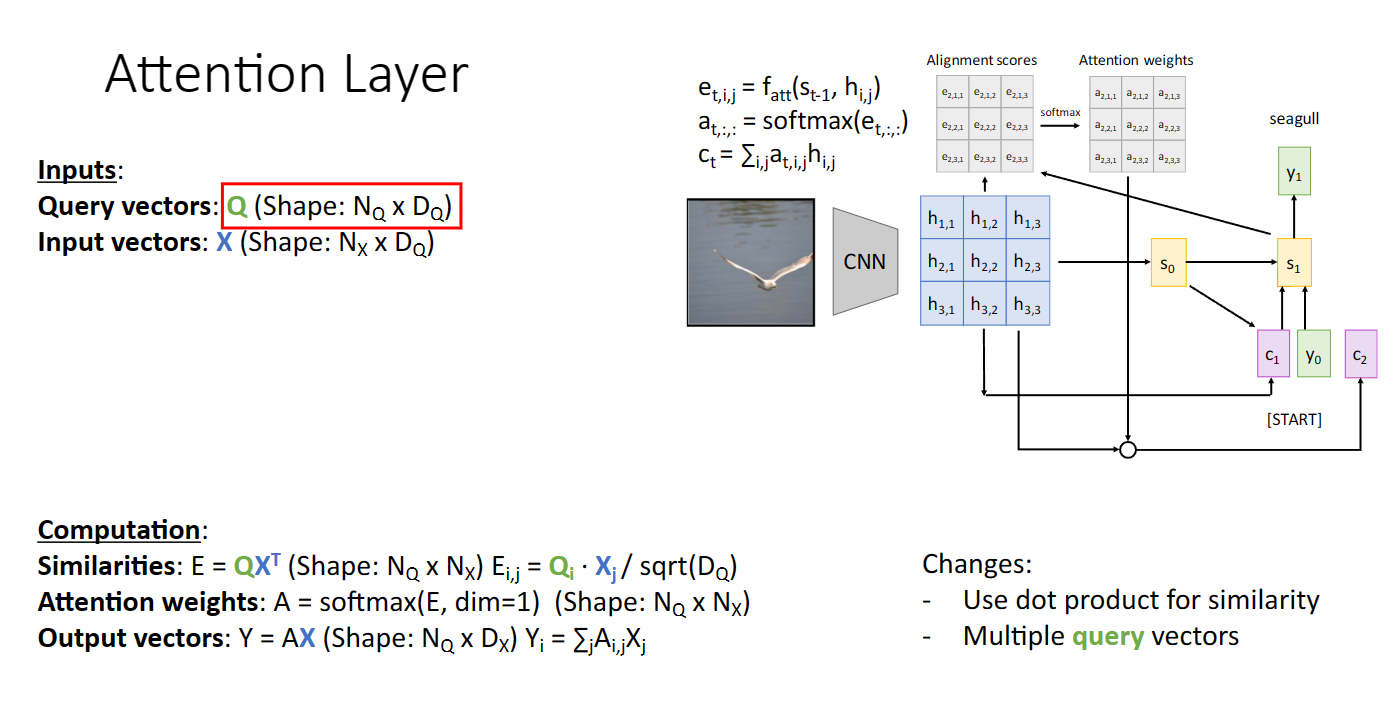
我們先理解一下注意力層中的三個重要概念:查詢,鍵,與值(下圖來自沐神ai):

注意力層相較於我們之前的結構主要有三個變化:
首先是我們要將之前的全連線層判斷相似性換成點積,並且是控制大小的點積,回憶softmax函數的性質,顯然過大的數位會導致梯度消失:

其次是我們要引入多個查詢向量:
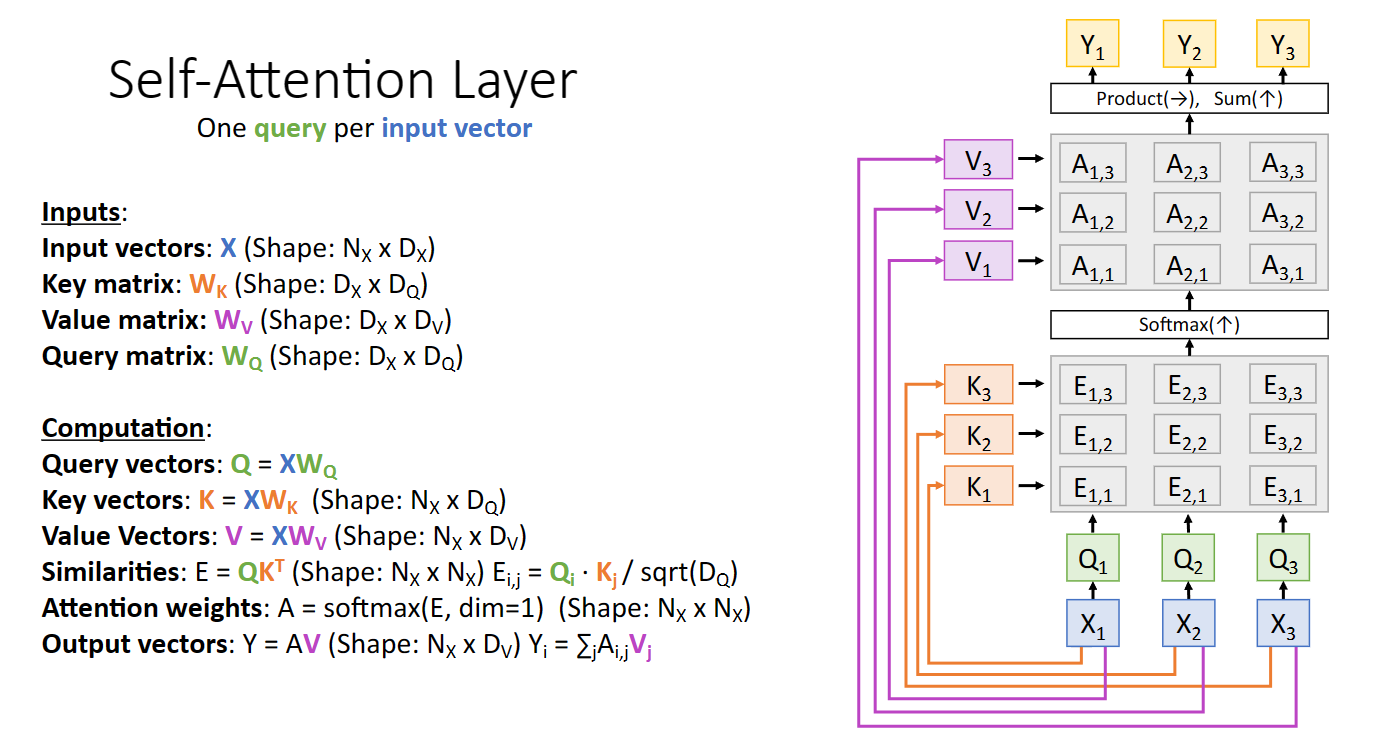
最後由於之前輸入向量組X有兩個作用,一個是計算key,一個是計算最終輸出結果的value,我們可以將其分開,通過引入兩個可學習的矩陣,分別計算key vector與value vector:

更進一步地,我們可以定義查詢向量組也由x得到,這樣我們就有了key matrix value matrix與query matrix三個可學習矩陣
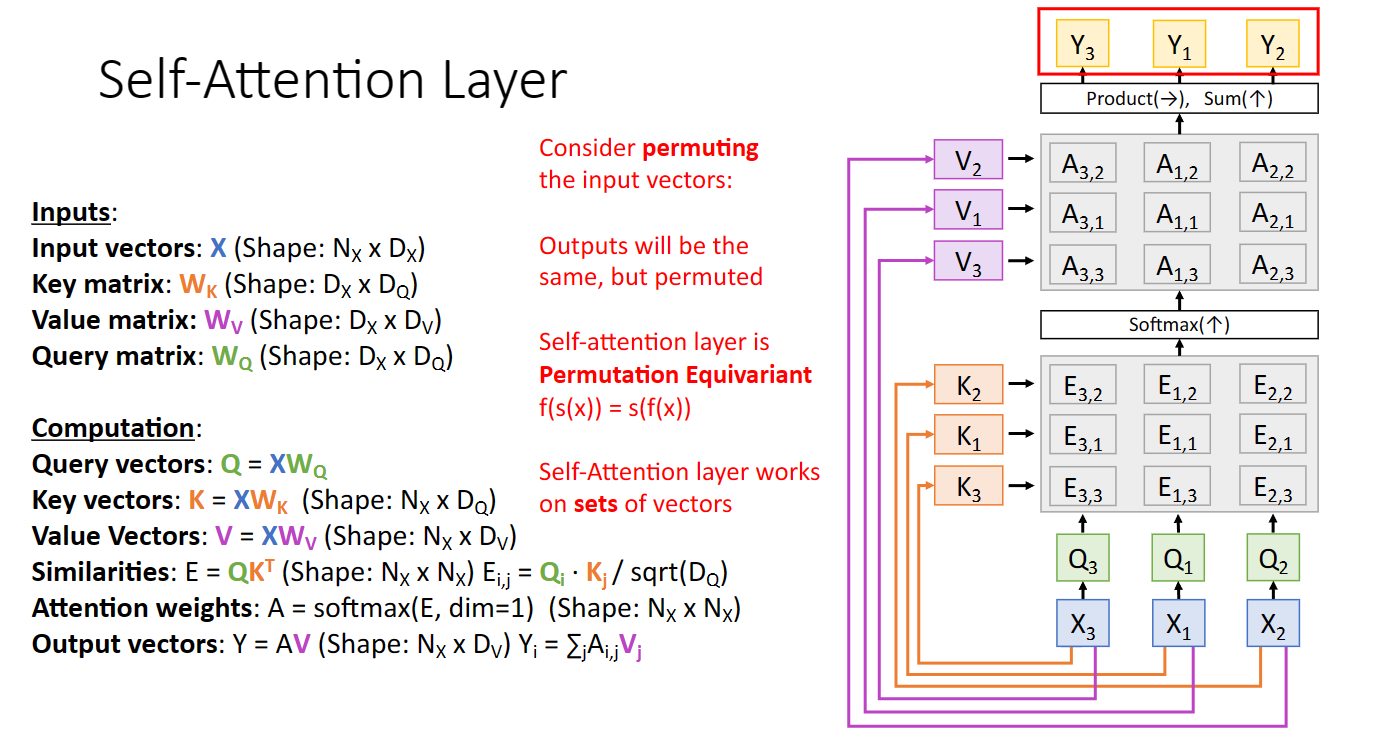
同時我們也可以發現,交換輸入向量的順序,輸出向量順序也會改變:
注意力層還有很多變體,比如masked attention layer,把相似矩陣中的某些值設定為無窮小,這樣能夠遮蔽掉某些輸入向量的影響,使得我們的輸出值只與之前的某些輸入有關:

多頭注意力層,我們可以使用不同的可學習的權重矩陣得到不同的注意力對應的輸出,再將它們拼接在一起,這樣可以幫助我們關注輸入的不同部分,同時也有利於平行計算

折積神經網路與注意力層結合:
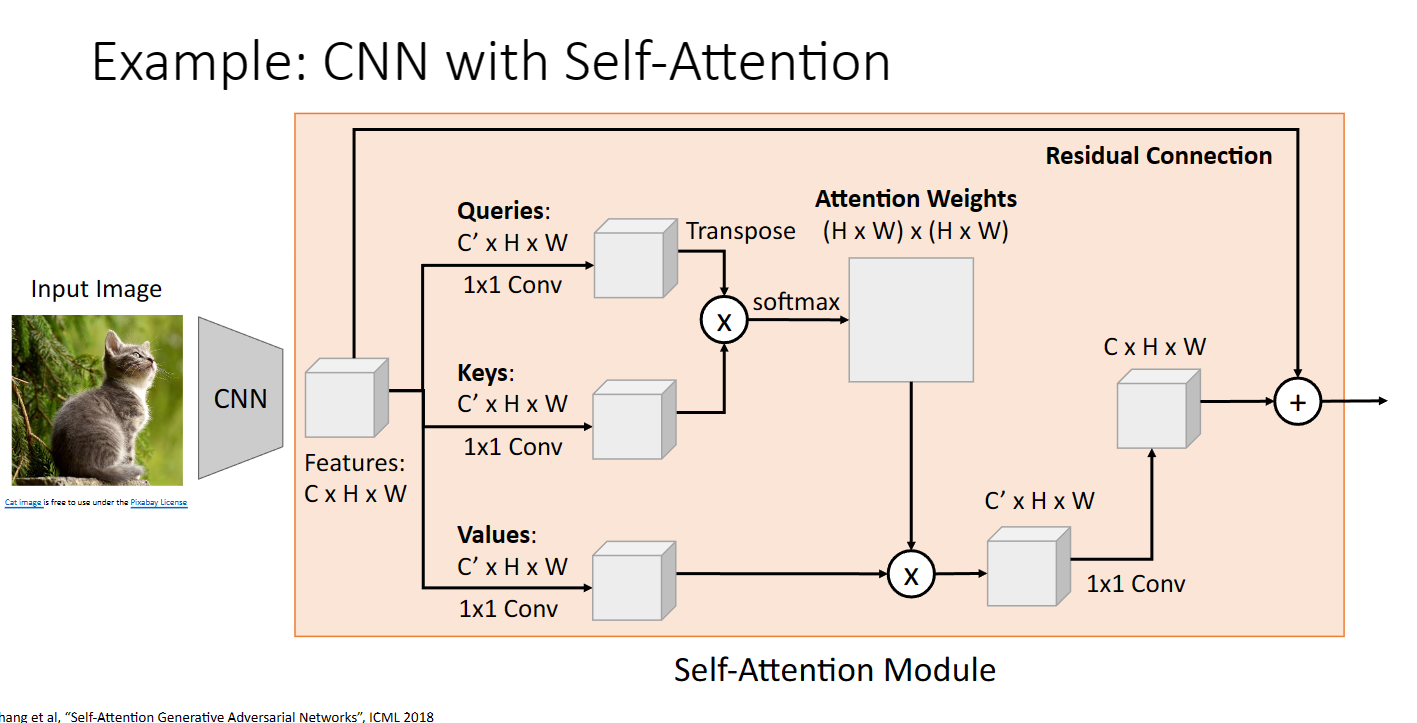
transformer
利用注意力層我們就可以去構建transformer結構:

輸入向量先經過注意力層,經過layer normalization,每個標準化的向量經過不同的mlp,再經過layer normalization輸出,同時在適當的地方加入殘差連線
將上述的transformer block多個拼接起來,我們就得到了僅僅使用注意力機制的transformer架構(常常使用多頭注意力):

使用遷移學習,我們可以訓練transformer架構,並且將其應用到nlp領域的任務:
